
一种基于改进DOPE 算法的螺栓位姿检测方法
2023-10-24 09:42:02王向周梅云鹏郑戍华
北京理工大学学报 2023年10期
王向周,梅云鹏,郑戍华
(北京理工大学 自动化学院,北京 100081)
螺栓紧固机器人在对准或夹持螺栓时需要具备一定环境感知能力[1],实时获取场景中目标螺栓的位置和姿态信息是其中的关键环节.在面对非结构化的作业场景时,基于深度学习的位姿检测算法,如PoseCNN[2]、PVNet[3]等,具有较强的鲁棒性,在基准数据集[4]上取得了较好的结果.但由于涉及语义分割、目标检测与分类等多种下游视觉任务,上述算法在不同任务场景之间的可迁移性较差.DOPE 算法[5]使用基于关键点的轻量化检测框架,在基准数据集中80%的物体上检测效果超过PoseCNN.在不引入额外任务的情况下,该方法以热度图(heatmap)的形式检测物体的二维关键点,并通过直接线性变换(direct linear transformation, DLT)算法求解物体姿态,其可迁移性高、网络结构轻巧、检测过程耗时短,更加适合在低功耗设备上部署.
对于螺栓等具有旋转对称性的物体,由于从不同方位可能产生相同的观察结果,如何唯一地预测对称物体的姿态是姿态检测算法所面临的主要问题之一[6].目前,一些学者尝试在预测模型中加入不同的数据处理方式以解决该问题.例如:KEHL 等[7]在物体对称轴的单侧半球上进行采样,通过避免采集到物体的对称姿态来保证预测结果的唯一性,但该方法无法应对物体具有多重对称轴的情况.BB8 方法[8]将训练集的标注位姿与图像逐一转换到固定的范围,虽消除了物体对称姿态的影响,但数据处理工作量大,且也无法从根本上解决对称性问题.
针对手动标记大量含有对象姿态的训练数据困难的问题,WANG 等[9]提出在标准坐标空间(normalized object coordinate space,NOCS)中获取姿态数据集,但结构化的场景会导致样本间呈现出明显的相关性.TREMBLAY 等[10]提出域随机化(domain randomization,DR)概念,其核心是通过随机采样的方式持续对环境施加干扰,迫使网络将注意力聚焦于检测目标本身的特征.在此基础上,DOPE 算法使用基于虚幻4引擎开发的NVIDIA 深度学习数据集合成器 (NVIDIA deep learning dataset synthesizer,NDDS)工具进行数据合成,使模型学习在多种环境下对目标进行识别以提高算法泛化性.然而,该数据合成方法制作的数据集拟真度不高,对于螺栓类小型目标的姿态检测效果不太理想.
针对机器人抓取螺栓的姿态识别问题,本文提出一种改进自DOPE 算法的姿态检测方法.针对螺栓具有旋转对称性且本身尺寸较小的特点,设计了一种具有高分辨率和通道注意力机制的并行特征提取网络,提高了模型对于螺栓目标语义信息的利用率.为了克服螺栓对称性给网络训练带来的影响,提出一种考虑物体所有潜在对称姿态的损失函数Symloss.对于螺栓姿态数据集,本文利用Bullet 仿真工具与NVISII 渲染引擎[11]合成包含螺栓姿态的高质量拟真数据,提高了模型的泛化性能.通过改进网络结构和数据集制作,提升了在不同视距下螺栓目标的姿态检测性能.
1 DOPE 姿态检测算法
DOPE 算法[5]是一个典型的基于RGB 图像关键点的神经网络姿态检测算法框架.该算法以单张RGB 图像作为输入,利用关键点检测网络预测物体的二维关键点,通过直接线性变换算法对目标姿态进行预测,其流程如图1 所示.
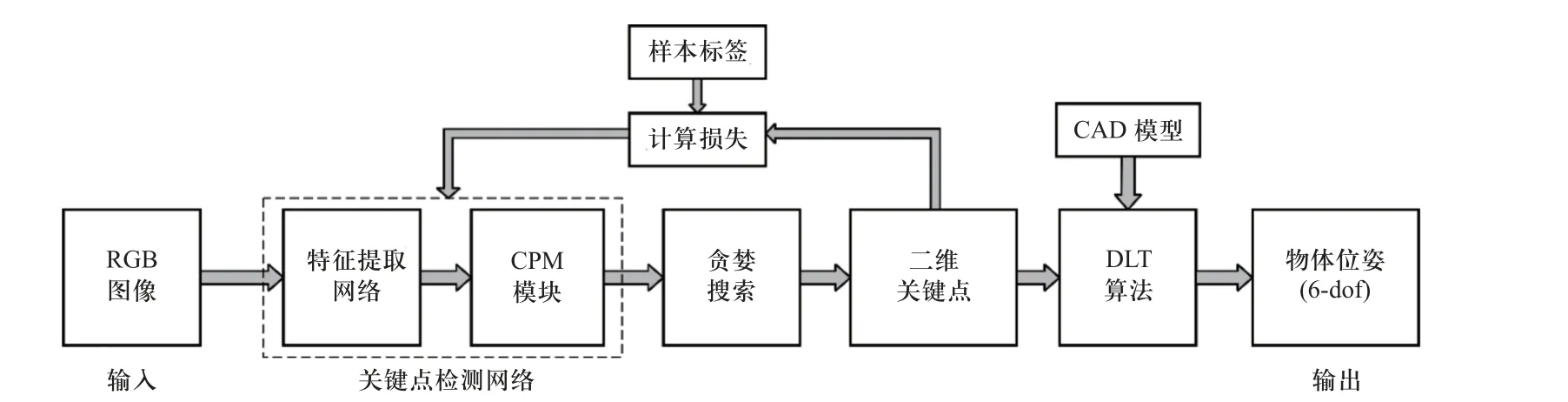
图1 DOPE 算法流程图Fig.1 Flow chart of DOPE algorithm
1.1 关键点预测
DOPE 算法将关键点定义为物体模型包围框的8 个顶点与模型中心点,将它们在观察视角二维平面上的投影作为二维关键点.使用特征提取网络和卷积姿态网络(convolutional pose machine, CPM)对物体的二维关键点进行预测.其中,特征提取网络由VGG-19 骨干网络的前15 层构成,姿态网络由多级全卷积结构构成,用于预测关键点的置信图(belief maps)与亲和力场(affinity maps),其预测结果会经历6 个连续的细化阶段,最终通过贪婪算法确定物体关键点的像素坐标.置信图是物体2D 关键点的热度图,共9 张,分别对应物体的9 个二维关键点.亲和力场是同一物体不同关键点之间的特征表示,共16 张,除模型中心点外的每个关键点对应两个亲和力场.亲和力场用于在关键点检测结果中搜索属于对应物体的关键点,避免图中存在多个目标时不同物体之间关键点产生错误的联系.
1.2 数据集合成
DOPE 算法使用基于虚幻4 引擎开发的NDDS工具合成数据集.该方法在每个样本数据中将对象的数量、外观、干扰物、背景、相机视角与环境光等属性进行随机化,使模型可以学习丰富的合成环境来提高检测鲁棒性.该工具通过异步多线程方式在场景中以50~100 Hz 的频率渲染生成图片,并记录每张图片中物体相对于相机坐标系的位置与姿态信息.
2 改进的DOPE 算法
DOPE 算法虽然在Linemod 基准数据集上取得了良好的效果,但将其直接应用于螺栓姿态检测时效果并不理想.主要原因为:与基准数据集中的物体不同,螺栓目标具有旋转对称性,其所有潜在对称姿态均为预测结果的可行解.关键点检测结果最终可能分布于物体的不同对称姿态中,进而影响算法对物体姿态的判断[6],这是DOPE 算法的主要缺陷之一.其次,数据集质量在很大程度上决定了算法的表现.DOPE 算法通过NDDS 工具实现了批量合成待检测物体的姿态数据集,但该数据集拟真度不高[11],在面临实际任务时训练效果不够理想.
为将DOPE 算法应用于螺栓姿态检测任务,针对上述问题改进如下:对于网络结构,使用带有通道注意力机制与横向连接(lateral connections)结构的网络提取目标特征,提高网络对于小目标的检测效果,并提出一种考虑物体潜在对称姿态的损失函数Symloss 来处理对称性引起的问题.对于姿态数据集,在NDDS 工具的基础上提出一种高质量螺栓姿态数据集合成方法,来提升算法的泛化性能.
2.1 改进的网络结构
2.1.1 特征提取网络
本实验选取M24 螺栓作为检测对象.在分辨率为400×400 的图像中,螺栓目标的占比最小可达40×40 像素.传统的VGG 骨干网络对小物体特征的提取效果不太理想,主要是因为:①小目标像素占比少,在下采样过程中会导致小目标语义信息丢失[12].②图像中含有大量的背景信息,模型对目标本身的关注度有限.小目标与常规目标相比可利用的像素较少,特征提取较为困难.随着网络不断下采样,其特征信息会进一步丢失.这要求特征提取网络能够充分利用待测对象不同深度的语义信息.因此,使用一种高分辨率的特征提取网络代替DOPE 算法中的VGG-19 网络.为融合不同深度特征层之间的语义信息,网络的主干部分在前向传播中采用横向连接结构.为避免网络前向传播时存在大量无关冗余特征图,使网络关注于检测目标本身,网络中引入了通道注意力模块,利用一个旁路网络获取输入特征中每个通道的重要程度,并依据重要性赋予每个通道权重,其原理如图2 所示.为了直观地展示整个特征提取网络结构,图3 以模块化的方式对网络模型进行了描述,其中CBA 模块是由卷积层、批归一化 (Batch-Norm)层、SiLU 激活函数组成的特征提取模块,SE(squeeze-and-excitation)模块为通道注意力模块,正号代表该操作对特征通道进行升维,负号代表对特征通道进行降维,多个正负号表示该模块通道升降维尺度相较于单个符号的情形时更大.Bottom、Top、M1、M2 模块的具体结构如表1 所示.M1,M2 模块的结构相似,其区别在于:部分M1 模块中存在步长为2 的下采样卷积层,用于降低特征图尺寸.M2 模块仅用于提取和传递高维特征而不作为下采样模块,其通道升降维尺度大于M1 模块.网络共进行三次下采样,分别由Bottom 模块和第1、第4 个M1 模块实现.每次下采样特征图的分辨率缩小一倍,最终输出的特征图分辨率大小为50×50.该网络结构可对目标特征图按重要性进行筛选,融合不同层次的特征,以提取小型目标的高维语义信息.

表1 网络中各模块结构Tab.1 Structure of each module in network
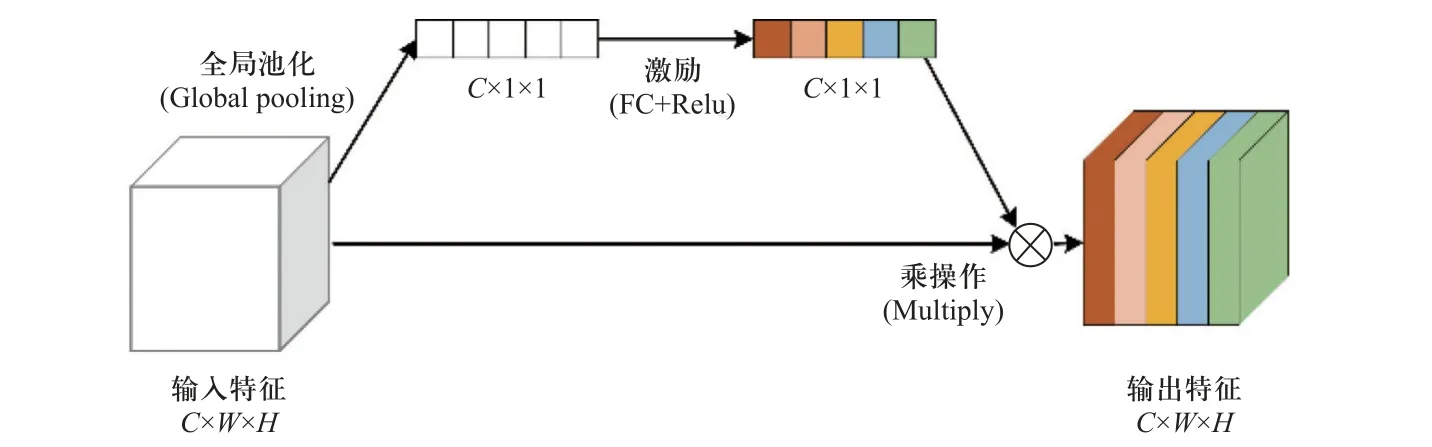
图2 通道注意力结构Fig.2 Structure of the channel attention module
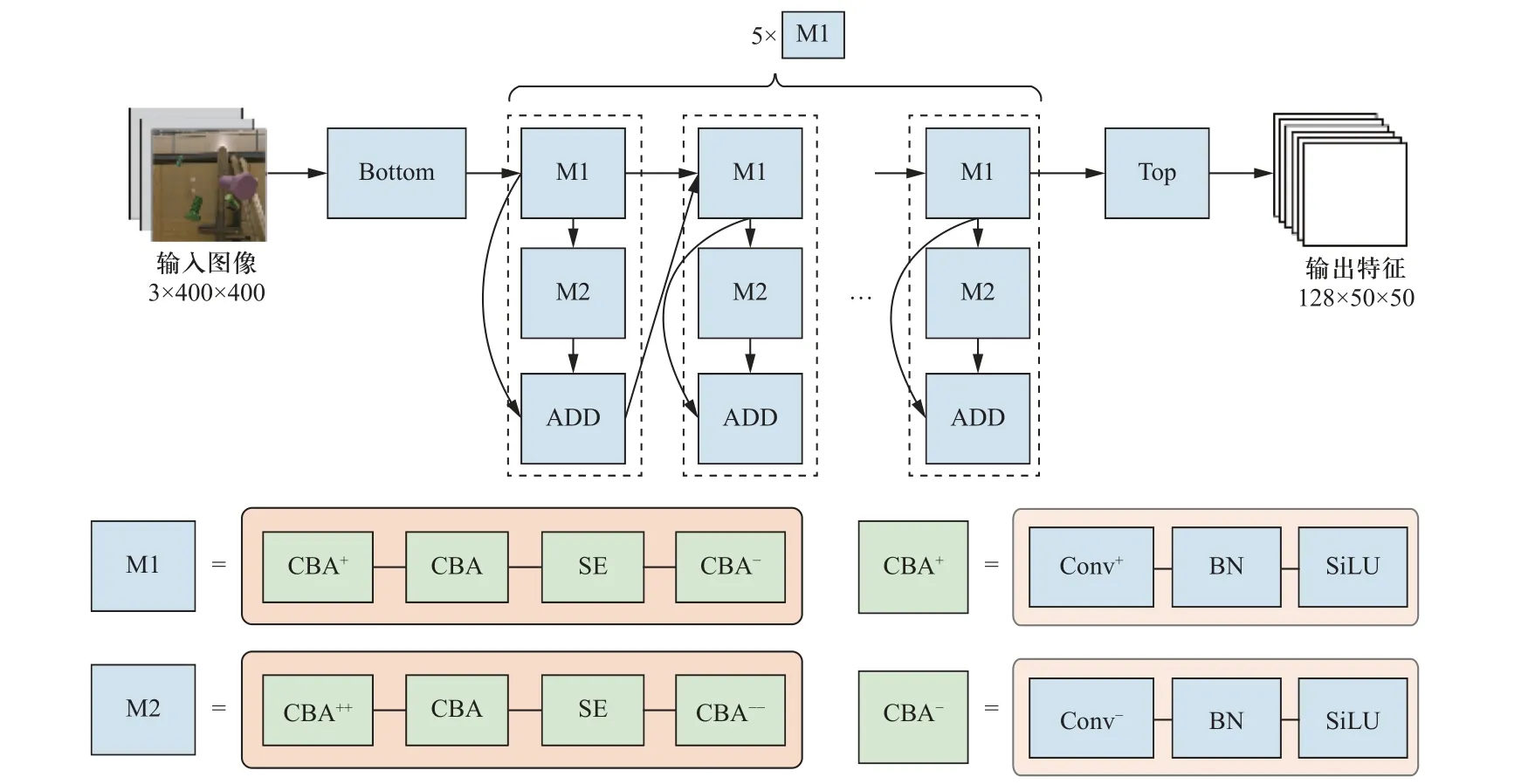
图3 特征提取网络结构Fig.3 Structure of the feature extraction network
算法中卷积姿态网络结构与DOPE 算法类似,但使用串联的M1 模块代替了原方法中全卷积堆叠的模式,并去掉一个细化阶段以减少参数冗余.修改后的卷积姿态网络如图4 所示.各阶段中特征分辨率保持为50×50,阶段2~5 的网络结构相同.
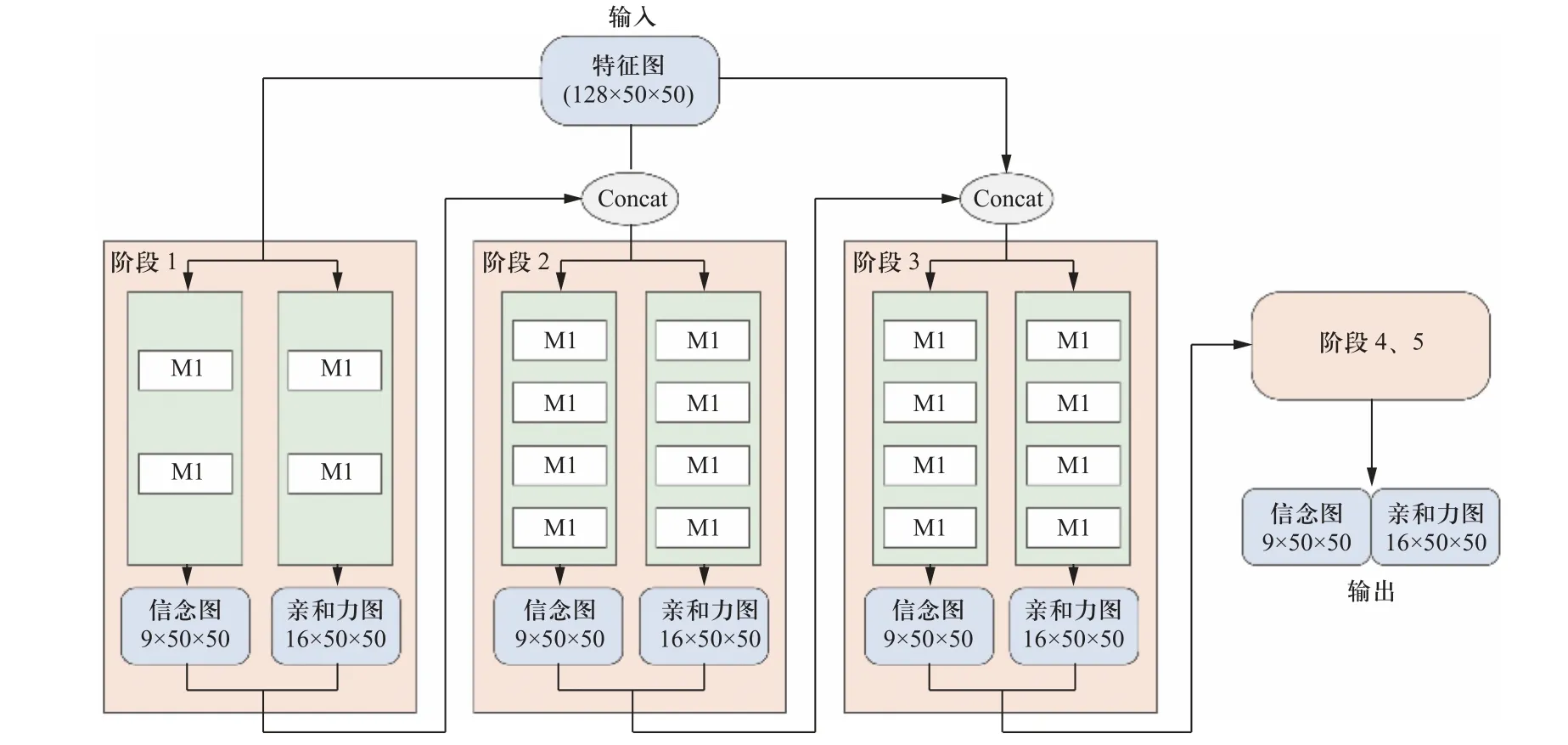
图4 卷积姿态预测网络Fig.4 Convolutional attitude prediction network
2.1.2 损失函数Symloss
DOPE 算法在检测对称物体的姿态时会在关键点预测结果置信图上产生多峰值,分别位于物体潜在对称姿态的对应关键点位置.DOPE 算法的网络的损失函数由置信图误差和亲和力场误差两部分组成[5],其计算方法为
为消除螺栓对称性在训练过程中带来的影响,将目标所有潜在对称姿态考虑为可行解,提出一种可根据物体对称性强弱进行调节的损失函数,在训练过程中针对目标的对称情况动态调整姿态网络的预测误差.改进后的损失函数会在训练过程中依据物体的真实姿态与对称轴重数建立目标潜在对称姿态集合,通过物体坐标系与相机坐标系的转换关系,将物体对称姿态的3D 关键点集依次投影至图像上.集合中每个潜在姿态对应的关键点集逐一与2D 关键点集预测结果计算误差,取最小值作为该阶段上的置信图(亲和力图)误差.该损失函数称为Symloss,用Lsym表示,其计算方法如下
2.2 改进的数据合成方法
改进的数据集合成方法,采用NVISII 渲染引擎与物理仿真工具Bullet 的组合来合成姿态数据集,并采用图片-姿态标签对的形式保存数据.本文与DOPE算法的NDDS 工具合成相比,合成图像渲染原理对比如图5 所示,主要区别在于:①数据采样背景使用墨卡托投影的高动态范围(high-dynamic range image, HDRI)全景图片,而DOPE 中的NDDS 方法使用COCO 数据集中的RGB 图像作为背景.全景HDRI图片由于保留了场景在真实世界中观察到的亮度而具有更高的动态范围,同时将场景背景投影至以相机为中心的球域表面,渲染得到的图片具有更加逼真的场景表现.②基于NDDS 的数据合成方法在相邻两帧之间保持目标物体位姿上的绝对独立,相机每次采样后立即销毁当前场景并使用新的背景、不同数量的目标和随机目标位姿对场景进行重构,如图5(a)中的采样过程所示.在本方法中,使用Bullet 创建真实的三维物理空间,每次生成场景时在以相机为中心的球域内创建若干个(本实验中为0~6 个)具有随机位置、姿态与初速度的对象,对象在场景中随机运动并由相机多次进行采样,如图5(b)中的采样过程所示.目标物体在每帧上的位姿由物体的运动状态与采样间隔决定,其运动轨迹可追踪,有助于模型学习物体姿态上微小变化带来的影响.
实验中,物体每个运动过程以0.2 s 为间隔采样20 次,然后销毁并重构场景,届时将重新选择背景图片与目标的数量、初始位姿与物体被施加的外力(用于赋予物体初速度).由于物体位姿受到物理运动的约束而不会发生突变,本方法可以看作是物体在空间位置上受限的域随机化方法.
3 实验与结果分析
3.1 评价标准与实验准备
实验中,使用所述数据合成方法合成20 000 张螺栓姿态数据用于网络训练,螺栓CAD 模型由Handyscan 700 激光扫描仪获取,同时手动采集300 张真实数据进行对比试验,实验使用的相机为Intel® Real-Sense™ Depth Camera D435i.网络训练的平台环境为Ubuntu16.04+2xGeforce GTX 1 080 Ti+pytorch,处理器型号为Intel(R) Core(TM) i5-10300H.
参照Linemod 基准数据集中的验证方法在真实场景中进行算法测试,使用模型点平均距离(average detection distance,ADD)[4]作为检测效果的评价指标.实验中采用考虑物体对称性的模型点平均距离实现(ADD-S)来评价预测结果,其计算方法如下
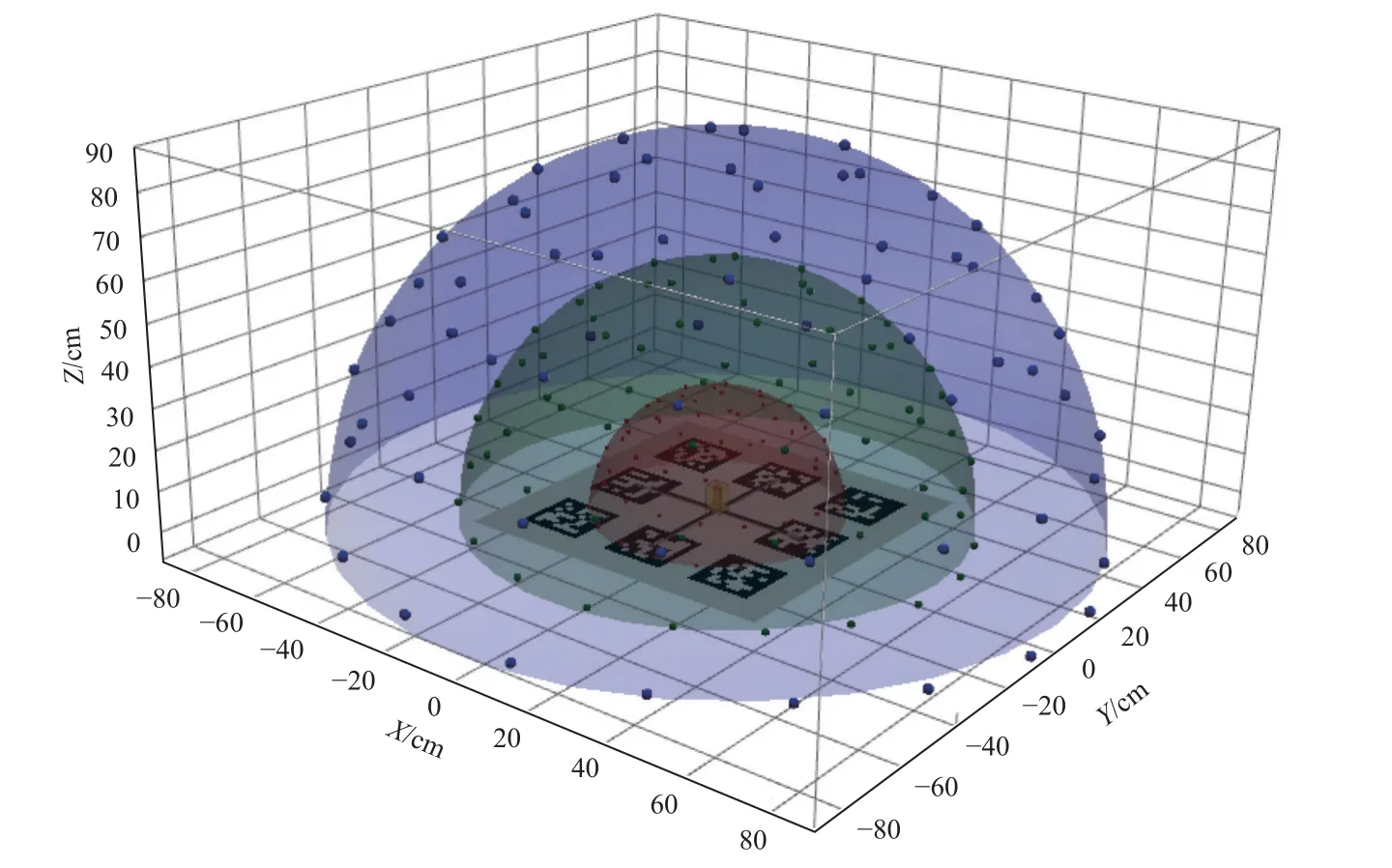
图6 螺栓姿态与采样视点分布Fig.6 Bolt pose and sampling viewpoint distribution
算法1:基于Aruco 标记的姿态验证算法
输入:
①PWObj:螺栓顶点在世界坐标系下的坐标集合;
②PWAru:Aruco 标记的中心在世界坐标系下的坐标集合;
输出:
EADD
①:模型平均点预测误差.
步骤1:摄像机获取一帧图像,检测其所包含的Aruco标记个数n以及这些标记的中心在相机坐标系下的坐标PCAru;
步骤2:若n≥4,继续.否则重新执行步骤1;
步骤3:计算检测到的Aruco 标记在摄像机坐标系下的坐标PCAru与它们在世界坐标系下坐标PWAru之间的旋转矩阵RWC与平移矩阵TWC,获取相机坐标系与所建世界坐标系之间的转换关系;
步骤4:根据Aruco 标记在世界与相机坐标系间的转换关系,将螺栓坐标由世界坐标系转移到相机坐标系下,计算螺栓在相机坐标系下的坐标PCObj=RWCPWObj+TWC作为螺栓的真实姿态值;
步骤5:在相机坐标系下计算标定板上螺栓的顶点坐标PCObj与算法预测得到的螺栓顶点坐标PˆCObj之间的顶点距离平均误差EADD;
在三种视距下分别对算法的姿态检测效果进行验证,以待测螺栓为中心构建半径为30、65 和100 cm的球体,每个球体表面上分布120 个采样点,物体的真实姿态示意图与物体的上半部分采样视点分布如图6 所示.在进行验证时,首先将螺栓正立放置,对上半区域内的视点进行采样,然后倒置螺栓并重复此过程,获取物体下半区视点上的预测结果.
3.2 消融实验
为了增强对比实验的可信度,使用相同的策略对本算法与DOPE 算法进行训练.根据前期预训练的经验,采用以下参数配置对网络进行训练:设定最大训练轮次为300,初始学习率为1×10-3并在每50个轮次后衰减10%,批处理数据量设为24,训练集输入分辨率为400×400.
采用消融实验方法,共设7 个对照组,如表2 所示.可以看出,本文提出的数据集合成方式对检测通过率的影响最大,在单项消融实验中平均较DOPE算法提高27.2%,对应实验1、3.特征提取网络采用SNet 在不同距离下分别使检测通过率提高4.9%,7.5%,8.4%,检测距离越远,S-Net 对检测效果的提升越明显.这一实验结果符合本文设计S-Net 以提升网络对小目标检测能力的初衷.并且,S-Net 使网络更加轻量化,较DOPE 算法每秒可多处理1.51 帧图像,对应实验3、4.使用Symloss 损失函数使算法的准确率在不同距离下分别提高6.6%、4.2%和1.7%,对应实验3、5.在同时使用S-Net 骨干网络、Symloss 损失函数以及本文所提数据合成方式的情况下,算法TADD10通过率与检测速度达到最高.与DOPE 算法检测性能相比,在均不使用人工标注数据集的情况下,改进后算法在不同距离下的TADD10通过率分别提高41.7%,34.1%和36.6%,对应实验1、6;在同时使用人工标注数据集的情况下分别提高14.2%,20.8%和33.3%,对应实验2、7.实验结果表明了本文在网络结构、损失函数与数据集合成方式上改进的有效性.
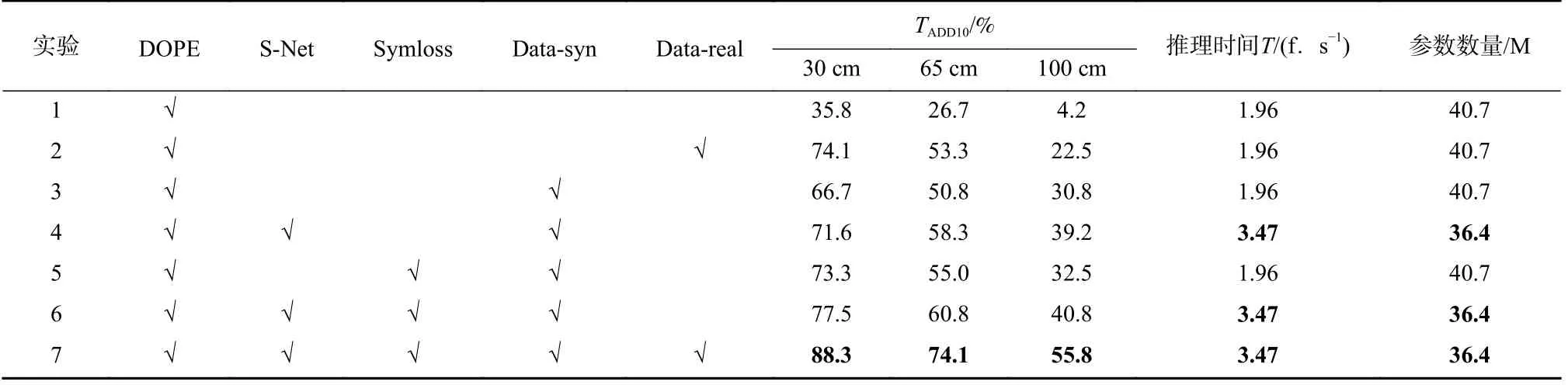
表2 消融实验结果Tab.2 Ablation study results
为了分析网络的工作原理及决策过程,将改进前后算法的检测效果进行可视化对比,结果如图7所示.在以图7(a)为输入图像的情况下,分别将DOPE算法与改进后算法的特征提取网络深层卷积上的激活映射图(activation mapping)进行可视化,以解释神经网络得到图中决策结果的原因.DOPE 算法在VGG-19 网络的最后一个卷积层上的激活映射如图7(b)所示,本文所提骨干网络在第5 个M1 模块中最后一个卷积层上的激活映射如图7(c)所示.可以看出,相较于DOPE 中的骨干网络结构,本算法采用的特征提取网络对目标物体所在区域更加敏感,网络的关注区域更加集中在目标物体上.在图7(a)包含的6 个螺栓中,DOPE 算法检测到其中4 个螺栓的姿态,如图7(d)所示.本算法检测到全部6 个螺栓的姿态,如图7(e)所示.借助于螺栓的CAD 模型,将姿态检测结果中两个关键点受遮挡的螺栓位姿包围框进行可视化,如图中黄色框线所示.可以看出,本算法的姿态预测结果相较于DOPE 算法更加接近物体姿态的真实值.

图7 DOPE 算法与本算法检测效果对比Fig.7 Comparison of detection results between DOPE and improved algorithm
为了分析引入Symloss 损失函数对关键点定位的影响,在图8 所示的场景中将网络对螺栓关键点预测信念图进行可视化.实验结果表明,在不使用Symloss 的情况下,螺栓的关键点信念图在其旋转对称位置周围呈环状分布,收敛性较差,如图8(a)所示.这是由于螺栓目标具有旋转对称性,其潜在的对称姿态会对关键点预测产生误导,此时关键点预测结果不准确.使用Symloss 时,网络输出关键点位置的最优解并抑制其他潜在对称姿态上可能产生的解,信念图峰值收敛到螺栓包围框8 个关键点附近,如图8(b)所示.由于关键点信念图是关键点定位的依据,信念图不收敛可能导致算法获取错误的关键点位置,并最终可能使DLT 方法失效.在使用Symloss的情况下,物体所有对称姿态都被作为可行解考虑在优化过程中,网络对于其中任一姿态做出正确预测时都将使网络损失降至最低,因此关键点置信度峰值仅会出现在一个可行姿态上.

图8 使用Symmloss 前后物体关键点检测效果对比Fig.8 Comparison of object keypoint detection effect with Symmloss before and after
3.3 不同阈值与纬度下的实验结果
为具体分析两种算法的性能差异,将本算法与DOPE 算法在不同准确度阈值下进行对比(对应实验2、7 中的情形).不同阈值下两种方法的平均模型点距离准确率如图9 所示,纵坐标表示通过当前阈值的视点数量占全部视点数量的比例.虚线位置表示TADD10阈值为6.4 mm.实验结果显示,相同视距下,本算法大于2 mm 误差阈值时的TADD10通过率显著高于DOPE 算法,在三种检测距离下达到的性能上限均高于对应条件下DOPE 算法达到的性能上限,且视距越远这一差距越明显.由于二维码板的印刷工艺以及相机标定存在一定误差,在0~3 mm 误差段两种方法的检测通过率均较低.
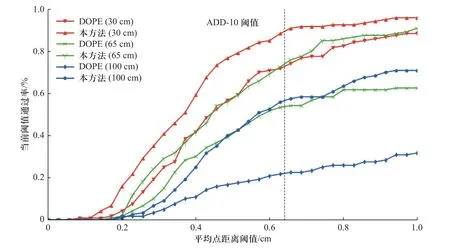
图9 本文所提算法与DOPE 算法的准确度-阈值曲线Fig.9 Accuracy-threshold comparison curves of proposed method with DOPE
由于一些视角下螺栓的可视部分遮挡较为严重,在这类视角附近检测目标姿态较为困难,导致两种方法均存在一定性能上限.例如,在纬度为180°的视点上,螺栓的可见部分为一个具有金属光泽的六边形,此时算法很难识别到画面中的螺栓.为了探究不同视角对算法性能带来的影响,从不同纬度对算法的检测效果进行验证.以螺栓包围框中心为原点,在30、65、100 cm 为半径的球体上分布的9 个纬度位置分别检测算法的TADD10通过率.考虑螺栓正立放置的情况,0°(俯视)、90°(平视)和180°(仰视)纬度处遮挡较为严重,在上述纬度检测螺栓姿态较为困难.称上述三个纬度为“遮挡纬度”,并在这三个纬度设置了15°采样浮动容限以避免出现检测通过率为0%的情形,其他纬度浮动为3°.实验中共设置了9 个纬度采样范围,在每个纬度采样范围中随机采样55 次,实验结果如表3 所示.可以看出,DOPE 算法在30、65、100 cm 视距处位于“遮挡纬度”的平均TADD10通过率分别为52.1%、36.4%和15.8%,较图6 中全部视点TADD10通过率平均下降15.2%,“遮挡纬度”下DOPE算法的检测性能受限严重.本算法在不同视距的“遮挡纬度”下TADD10通过率为73.3%、64.2%和49.7%,高于DOPE 算法在这些视角下的通过率,并且相较于本算法的全视点TADD10通过率均值仅下降10.3%,可见本算法对视角遮挡情况的鲁棒性更强.此外,视距由30 cm 提高至65 cm 时,DOPE 算法TADD10通过率平均下降19.8%,本算法TADD10通过率平均下降10.3%.视距由65 cm 提高至100 cm 时,DOPE 算法TADD10通过率平均下降27.1%,本算法TADD10通过率平均下降16.4%.综合图9 中的实验结果,可表明DOPE 算法对检测距离更加敏感,当视距提高时检测效果会明显下降.本算法受视距影响更小,在提高检测效果的同时降低了视距对算法性能的影响.
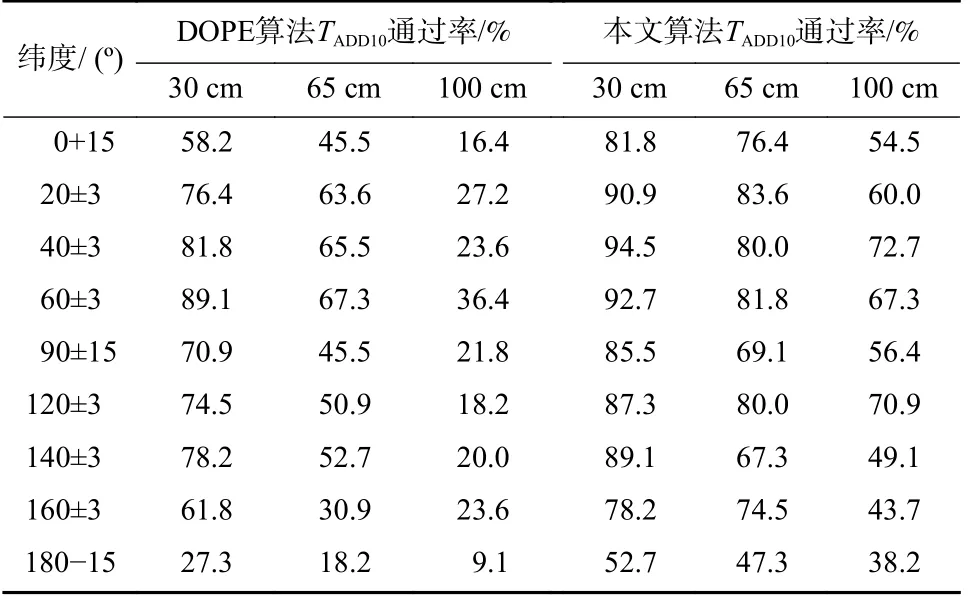
表3 DOPE 算法与本算法在不同纬度下的TADD10 通过率Tab.3 TADD10 pass rate of DOPE and proposed algorithm at different latitudes
4 结 论
针对螺栓紧固机器人获取螺栓姿态的问题,提出了一种基于改进DOPE 算法的螺栓姿态检测算法.该算法使用横向连接策略结合注意力机制的网络获取目标特征,有效提高了高视距下网络对于小目标的检测能力,在100 cm 视距下可使算法的TADD10通过率提高8.4%;提出了一种损失函数Symloss,解决了螺栓目标的对称姿态在训练过程中产生歧义并影响检测效果的问题,消除了关键点置信图预测结果上的错误峰值,可使算法的TADD10通过率提高6.6%,为具有旋转对称性的物体提供了一种可行的网络训练方法.此外,本文提出一种基于NVISII 渲染引擎的3D 姿态数据集合成方法,该方法在真实场景中的表现显著优于DOPE 算法使用的NDDS 数据合成工具.在训练过程中加入本方法合成的数据使算法的TADD10通过率平均提高27.2%,可提高模型的泛化性能.该数据合成方案具有一定任务迁移能力,在降低3D 姿态数据集获取难度的同时为算法在不同任务中部署创造了有利条件.
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11 09:52:44
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
学生天地(2020年3期)2020-08-25 09:04:16
汽车观察(2018年9期)2018-10-23 05:46:40
现代营销(创富信息版)(2018年10期)2018-10-12 03:01:46
中国自行车(2018年8期)2018-09-26 06:53:44
中国卫生(2014年2期)2014-11-12 13:00:16
卫生职业教育(2014年16期)2014-05-16 03:47:50
安徽医专学报(2014年6期)2014-03-20 13:08:03
