
基于大数据的高职院校家庭经济困难学生精准资助机制
2023-10-16 03:26田慧芬
中国新通信 2023年15期
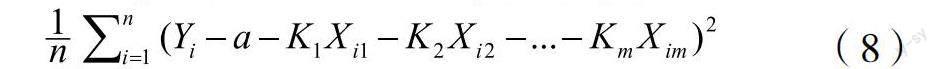
摘要:高校家庭经济困难学生的资助工作已经从单纯解决经济问题发展为物质帮扶、道德浸润、能力拓展和精神激励等多方面的资助。如何利用大数据技术实现对资助对象识别、资助需求确认以及资助过程的精确实施,以确保需要帮助的学生“一个不能少”和不应助学生“一个不能有”,成为资助亟待解决的问题。
关键词:大数据;高职院校;家庭经济困难学生;精准资助机制
在脱贫攻坚的基础上,要推进学生精准资助,利用大数据手段从资助对象识别、资助需求确认到资助过程实施,全方位、全过程地构建应助学生“一个不能少”和不应助学生“一个不能有”的精准资助机制,保障家庭经济困难学生“按需资助和充分资助”,从而实现教育公平,让每个孩子都有人生出彩的机会。
一、精准资助对象识别
现阶段高职院校分布广泛且在不同省份招生,不同地域的经济发展水平不同,同一地域的不同地区学生的家庭经济状况相差很大,同时学生生源呈现多样化、复杂化趋势。同时,不同学校对家庭经济困难学生的认定标准不统一,认定评议过程中的主观因素等都对家庭经济困难学生的认定结果带来外因影响。学生对自身家庭经济情况的情感认知及对家庭经济困难生认定的信息采集内容理解也以内因的形式影响资助对象的确认,例如有的家庭经济困难学生自立自强,自己做多份兼职赚取生活费,自己再苦再累也不愿给学校和国家添麻烦;有的学生家庭经济虽然困难,但碍于面子,怕同学瞧不起,不但不申请困难学生认定还向父母额外要钱装富摆阔,加重了家庭经济的困难;有的学生家庭在当地是中等收入家庭,学生却认为自己家很困难,迫切需要资助。种种因素都对资助对象的精准确认造成影响。
目前高职院校普遍采用的家庭经济困难学生认定模式是“学生自主申报,评议小组民主评议”,采用信用承诺制,以学生的自主申报为基础,综合评议小组的民主评议,自评与他评相结合,有效提升了认定结果的准确度。但学生按照申报信息并结合自己的理解进行申报,申报信息的全面性和准确性及学生对申报信息的理解会影响学生家庭经济得分,进而影响认定结果的准确性。要解决这个问题,可以用大数据和机器学习的算法来优化学生家庭经济信息采集量化指标体系,通过迭代学习计算将每项分值对应的权重计算出来,使家庭经济困难生认定标准更加科学合理,认定结果更加精准。对于民主评议环节,评议小组根据对申报学生的了解进行主观评议,评议项目的设置和评议小组成员对申报学生的了解及与申报学生的关系都会影响评议结果。怎样聚合民主评议的各项内容特征,减少主观因素对认定结果的影响是提高家庭经济困难学生认定结果精准度的关键。
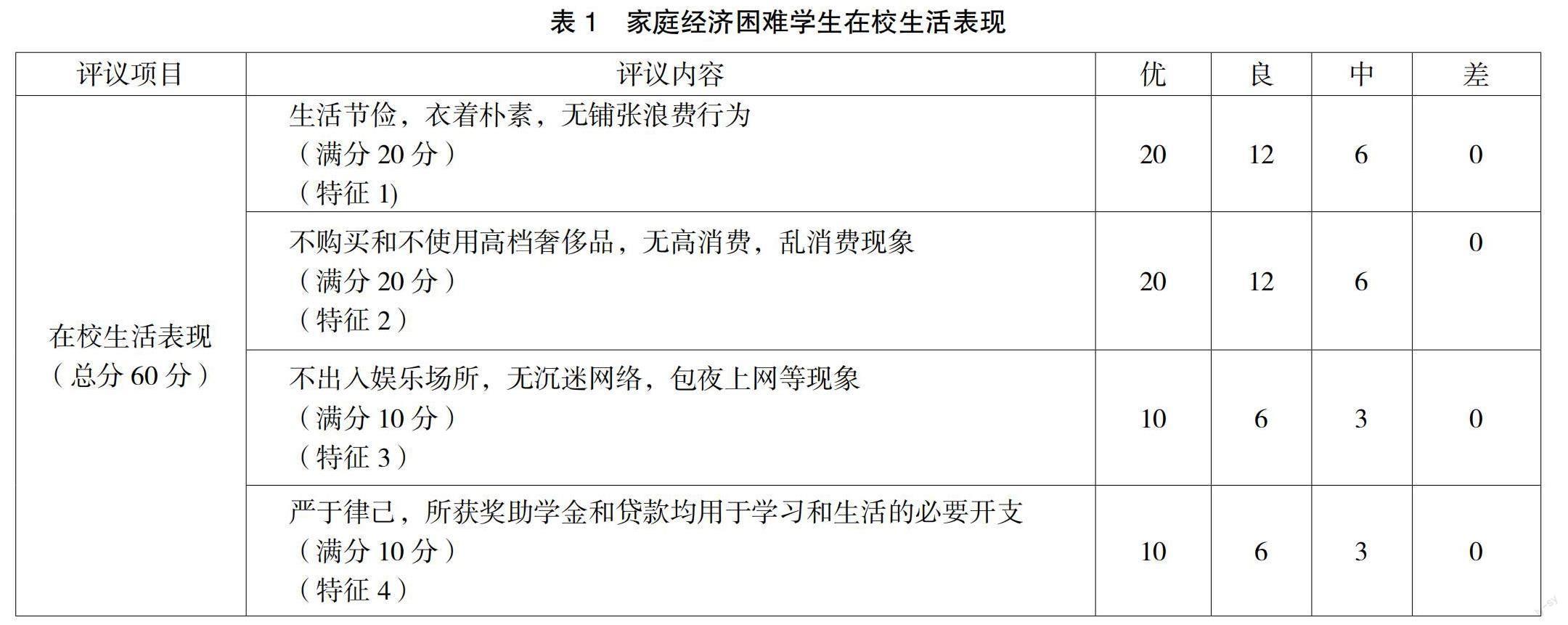
举例说明:表1是家庭经济困难学生认定民主评议中的在校生活表现项目,包含四个具体评议内容,每个评议内容根据学生表现及评议小组成员的了解分优、良、中、差四个等级,每个等级对应不同的分数。从表中可以看到,“生活节俭,衣着朴素”等这些评议内容,不同的人有不同的评判标准,没办法用具体的数据来表达。但是家庭经济困难的学生确实存在比如“生活节俭、衣着朴素”这样的一些共性特征,在此提出用大数据与机器学习的K-均值算法来聚合不同困难程度学生的共性特征,以此来实现家庭经济困难学生的精准认定。
表1把学生的在校表现定义了四个特征,让评议小组对不同学生进行打分,然后把所打的分值与此特征的满分求比值,进行归一化处理,如特征1中,评议小组成员1对张三同学打18分,那么张三同学的特征1的比值就是18/20=0.9。如果评议小组有5名同学进行打分,按照以上的办法对张三同学的各项打分如表2所示。
按照平均值的方法计算各个特征的中心:
特征X聚类中心=(X1+X2+X3+X4+X5)/5 (1)
特征Y聚类中心=(Y1+Y2+Y3+Y4+Y5)/5 (2)
特征Z聚类中心=(Z1+Z2+Z3+Z4+Z5)/5 (3)
特征W聚类中心=(W1+W2+W3+W4+W5)/5 (4)
令:
S=(X-特征X聚类中心)2+(Y-特征Y聚类中心)2+(Z-特征Z聚类中心)2+(W-特征W聚类中心)2 (5)
评议值与聚类中心的欧式距离的公式为毕达哥拉斯公式,即勾股定理公式:
以特征中心的各个分量组合为聚类的中心,按照点与点之间的欧式距离来计算评议值与聚类中心的距离。
由表2可以看出,通过随机选择K个点,作为子聚类的中心,每个学生的评分值与子聚类中心的欧式距离通过公式(6)计算出来,然后把每个评分值分配到与此评分值的欧式距离最近的子聚类中。这样就把评议小组对所有学生的评分值第一次分割成K个聚类,距离远的分配到其他的子聚类中,最后所有的聚类中心都是由欧式距离最近的点组成,经过不断的迭代,就能找出不同困难等级的学生的特征,进而精准认定家庭经济困难学生的困难等级。
二、精准资助需求确认
不同年级、不同时段学生的资助需求不同。李亚员教授在“按需助学:新时代高校发展型资助模式创新”一文中把大学生分成三个阶段:大一是适应阶段,大二是独立阶段,大三、大四是全面发展阶段。资助要根据学生不同时段的具体需求努力做到“掌握需求,按需、分级、分段进行资助”,让学生充分享受“定制化”的资助红利。针对处于适应期的一年级家庭经济困难学生,可以从生活补贴、交通补贴、助学金、适应性教育、学业职业规划等方面进行基础性资助;处于独立期的二年级家庭经济困难学生可以从助学奖学金、专业技能提升、素质能力拓展等方面进行对口资助;對处于全面发展期的三年级家庭经济困难学生应更多地从就创业能力提升、求职面试指导、就业及招聘会信息提供与组织等方面进行资助。同时宏观上要加强政策宣传,提升资助政策的知晓度,让更多的学生知政策、用政策。可以成立教师资助政策宣讲团,选聘学生资助宣传大使,开展学生家庭走访送政策、回母校宣传政策、招生宣传现场政策解读等,使资助政策“入脑入心”;建立动态管理机制,分时段、分学段、分类型组织召开家庭经济困难学生座谈会,开展需求问卷调查,设立需求信箱、许愿池等,及时掌握学生所需所盼,有的放矢,按需资助。聚合校内外资源,强化学校、社会、家庭、个人等多方责任共担,确保资助政策和信息充分共享,从生活帮困、学习帮助、心理帮扶等方面开展资助需求调研,根据困难学生实际制定“一人一案”资助方案,建立“标准化”和“定制化”的资助方式。
三、精准资助资金分配
目前高职院校大部分资助资金基本上按照困难等级进行统一发放,不能按照每个学生的具体情况进行“定制化”资助,发挥资助资金最大的效能。如何运用大数据方法,具体评估学生的实际情况,合理分配有限的资助资金,是进行精准资助迫切需要解决的问题。
可以通过对学生校内生活成本分析,学习费用分析,估测学生基本的学习生活费用,然后对所有列入资助范围的学生用大数据算法进行精确计算,来合理确定每个学生的受助资金,真正把有限的资助资金最大限度资助给家庭经济困难学生,达到精准资助的目的。
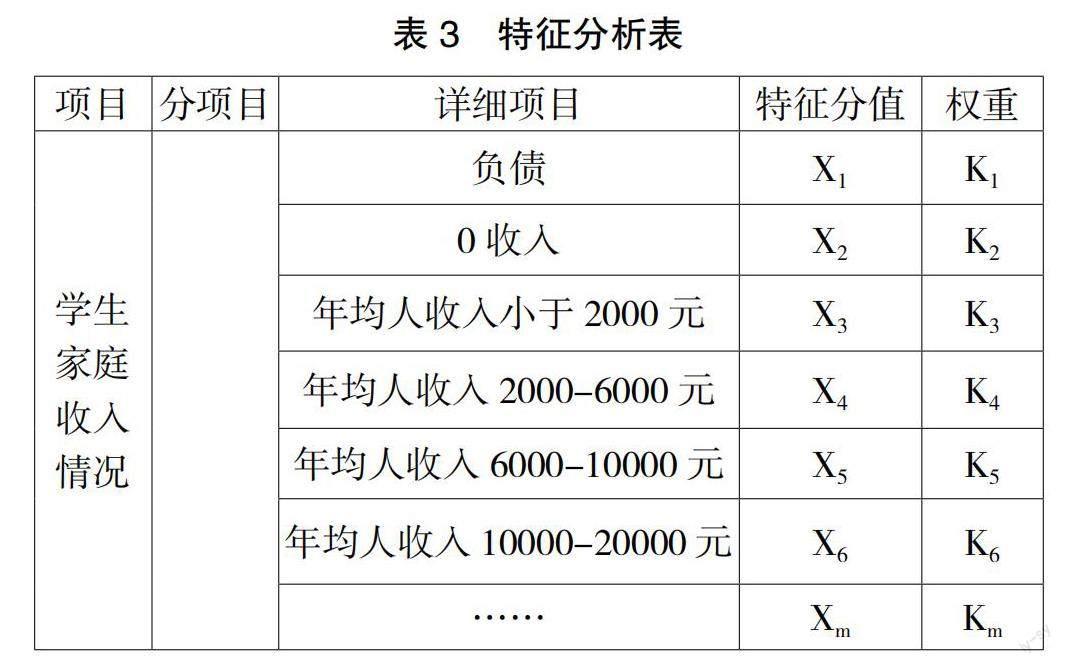
举例:以表3中的特征为指标进行预测,通过多特征的线性回归来预测学生需要获得的资金支持。用Y表示一个学生学习与生活需要的资金值,可以知道
公式中a为偏置项,为预测误差项。K1到Km为权重,X1到Xm为特征分值,a和Kj(1≤j≤m)取值为最小化均方误差的结果,这个均方误差表示如下:
式(8)中,Yi和Xij分别是第i个学生需求资金值和第i个学生的第J个特征所获得的分值。
在单一特征中,可以利用微积分的求导数的方法来判断最小值的条件,但是在这个具有多个特征的应用中,可以将式(8)作为代数矩阵模型来计算求解,从而得到每个学生所需要的学习与生活资金数值,精准进行资金的估算与分配。当特征值更多时,用矩阵模型的方法计算的时间复杂度和空间复杂度会提高很多,可以改用梯度下降算法来求解会更方便。
四、结束语
综上所述,目前高职院校家庭经济困难学生的资助,已经由单纯地通过经济资助解决学生的学习生活困难,发展为物质帮扶、道德浸润、能力拓展、精神激励全方位的资助,在这个资助过程中家庭经济困难学生的精准识别是基础,学生需求的精准确认是手段,学生能力素质的精准服务是目的。
通过家庭经济困难学生资格认定分析和资助资金分配预估,利用信息化与大数据的便利,用大数据与机器学习的方法进行精准分析、精确判断,改变大水漫灌的方式,让有限的资助资金发挥最大的资助效益;通过对家庭经济困难学生学习、心理、就业、能力等方面的需求的研判,有针对性地对他们的需求进行“滴灌”式精准扶植,解学生所困,助学生所需,提高精准资助水平,让党的资助政策“有的放矢”,惠及每个家庭经济困难学生,让他们都拥有出彩的机会。
作者单位:田慧芬 南京铁道职业技术学院
参 考 文 献
[1]王秋月, 覃雄派 ,趙素云 ,等.人工智能与机器学习[M].中国人民大学出版社,2020.
[2]许珂.大数据时代高职大学生精准资助的问题与对策[J].湖北职业技术学院学报,2020(9):45-48.
[3]窦苏明,荆敏菊.大数据视域下高校贫困生精准资助管理机制探究[J].机械职业教育,2020(11):13-16.
[4]罗丽琳.大数据视域下高校贫困生精准资助研究[M].知识产权出版社,2018.
[5]冀津.精准构建新时期高校家庭经济困难学生资助体系[J].北京教育(高教),2022(06):62-64.
[6]张勇,卓泽林.从保障到发展:我国高校学生资助资源的现状、影响因素与对策建议[J].教育探索,2023(01):36-41.
[7]李亚员.按需助学:新时代高校发展型资助模式创新[J].高校辅导员学刊,2022(03):41-48.
猜你喜欢
知音励志·社科版(2016年11期)2016-12-20
新教育时代·教师版(2016年27期)2016-12-06
商(2016年32期)2016-11-24
中国市场(2016年38期)2016-11-15
科技视界(2016年20期)2016-09-29
科技视界(2016年20期)2016-09-29
科技视界(2016年20期)2016-09-29
科技视界(2016年20期)2016-09-29
大众理财顾问(2016年8期)2016-09-28
