
软件系统漏洞预测技术分析
2023-10-12 23:27韩鹏军
中国新通信 2023年16期


摘要:软件系统运行漏洞是常见的实际问题。系统漏洞不仅会带来经济损失,也会影响软件运行质量与软件功能发挥。研究软件系统漏洞预测技术,有利于及时发现漏洞出现区域、有效定义漏洞类型。通过漏洞预测,可以为软件评估工作与提升软件质量的提供保障。通过本文实践分析可知,软件系统漏洞预测技术应用要点包括明确漏洞预测技术内涵、构建漏洞预测模型,以及結合专业理论研究漏洞倾向性预测方法。只有结合实际情况打好理论基础,并对针对性预测技术进行了解,才能进行有效的分析研究,找到软件系统漏洞预测科学路径。
关键词:软件系统;漏洞预测;模型构建;漏洞倾向性
软件系统漏洞预测技术在实践应用中,需经过专业模型构建和针对性的理论分析,并且通过既定步骤作为支撑,为软件系统漏洞预测奠定基础。在实践预测工作落实开展中,主要针对漏洞倾向性进行预测,按照预测既定流程做好特征指标选择和数据处理工作,为提升模型构建合理性、优化模型构建质量效果奠定基础。
一、漏洞预测技术实施要点分析
(一)基于漏洞发现过程进行建模
在不同类型漏洞中,安全漏洞对系统运行会产生直接影响。当系统总体漏洞数量增加后,安全漏洞数量也会呈现上升趋势。漏洞数据库也会基于数据采集分析,形成更加集中和多样的漏洞形式。因此,针对漏洞进行研究发现,需要通过建模的方式提高可靠性和针对性[1]。具体来说,漏洞发现过程建模中可用的模型包括以下几种。
一是安德森热力学模型。此模型主要针对软件可靠性进行研究,发生漏洞问题后,可实现基于漏洞立即修复,且不会引入新漏洞。安德森热力学模型的漏洞预测公式具体如下:
其中,k、γ以及C属于常数参数,模型会随着时间t的增加,呈现出漏洞数量累积特征。
二是逻辑斯蒂模型。此模型构建要点为建立逻辑斯蒂函数,具体的函数表达式如下:
在此公式中,C是常数参数,A和B分别代表可以根据经验设定的具体参数。在此模型中,逻辑斯蒂函数发挥主导作用,其主要特征表现为当t趋向无穷大时,漏洞总数会无限接近B,这意味着在最终统计时漏洞数量会达到一个上限[2]。
(二)基于模型构建进行实验分析与评价
在选择一种模型进行漏洞预测分析时,首先需要对模型的有效性进行实验分析。在验证模型有效性时,需要考虑不同类型的参数指标和软件系统,并使用模拟观察的方式来构建漏洞增长过程,并确认模型参数的取值。下表1是基于生长曲线进行构建的预测模型验证数据[3]。这种模型被称为PMGTV模型。可以使用最小二乘法来确定对模型参数的初始取值。关于模型评价方法,也需选择专业技术方法以达到评价目标。具体来说,常用的模型评价方法有残差平方合法以及卡方值法。根据模型评价结果进行总结分析可知,从拟合效果入手进行评价分析时,可清晰判断对数模型和指数模型不容易取得良好的拟合效果,无法准确反映漏洞发现数量随时间变化的具体规律。相对来说,生长理论模型在漏洞发现过程中能够发挥更好作用,这也是本文选择基于生长理论进行模型构建研究的重要原因[4]。
二、系统漏洞发现预测模型分析
(一)软件系统漏洞发现基本规律分析
发现漏洞出现的基本规律对于解决漏洞和相关实际问题有重要作用。在系统软件发布上市后,漏洞具有一定的变化规律和系统,软件漏洞的发现速度也具有波动性特征。同时,漏洞也呈现出一定的基本规律。影响漏洞发现速度的因素主要包括以下两个方面:用户规模大小和是否受到黑客攻击。
从基本特征的分析可知,使用软件的用户群体规模越大,越容易发现漏洞。从黑客角度来看,在攻击软件系统时,他们也会优先选择具备大规模用户群体的系统。但是,随着软件运行时间的增长,系统功能的完善性也会不断提升,系统中的漏洞逐步减少,因此发现漏洞的速度也会同步降低。
根据实际情况分析可知,常见系统软件漏洞的发现速度可分为三个基本阶段。首先,在软件发布及上市初级阶段,漏洞的增长速度较慢。其次,在软件系统进入市场运行段时间后,漏洞发现速度会出现高速增长,但不具备持续性。最后,在成熟阶段,漏洞发现速度逐步下降,漏洞增加频率也同步减少。基于这一特征绘制的曲线被称为软件漏洞系统生长曲线。
(二)漏洞预测模型描述方法分析
在描述漏洞预测模型时,需要考虑基础数据计算并结合系统功能要求对预测模型的特征进行定位。通过描述漏洞预测模型,有助于帮助分析人员更准确和全面地了解漏洞的发展趋势。在描述漏洞预测模型时,可以采用Logistic方程。此方程主要依据生物学原理设定假设前提,并建立相关微分方程与模型。然后可以代入初始条件与临界条件,求解整体生长过程中的变化趋势。这个模型的整体变化过程具有较强的逻辑性和实际应用价值,整个曲线呈现出S型。
在实际应用中,可以设定一个固定的时刻t,并将漏洞发现的数量记为y。由于漏洞发现速度具有波动性特征,需要结合生长理论建立一个关于发现数量的函数来描述漏洞发现的增长速度。具体表达式如下:
在实践分析中,需要设置相关定值来构建分支关系式,以描述漏洞预测的整体趋势。只要数据计算精准有效,分析公式全面完善,就能充分发挥出模型的具体作用。在实践分析中,还需要确保数据的准确性,有效地进行计算,并验证所使用的分析方法和公式,以确保模型的准确性和可靠性。
最终,通过正确设置定值、构建分支关系式,并进行精准计算和完善的公式分析,可以使漏洞预测模型在实践中发挥出应有的作用,并提供全面有效的预测结果。
三、软件系统漏洞倾向性预测方法研究
(一)高斯过程核运算研究
关于高斯内核主要功能在于定义数据之间的相似程度[5]。在训练模型时,高斯模型的训练采用单核训练模式,基于不同函数表达式对训练效果可能会产生客观差异。相比之下,多核学习更具灵活性,能够根据复杂的漏洞数据来预测其分布状态。在本文研究中,主要通过引入新的多核函数来改善模型的构建准确性和映射能力,从而获得更显著的分类效果。多核合成主要是通过对多个基本函数进行线性组合,最终得到求和核表达式,具体表达如下。
此公式主要通过将平方二次有理核以及平方指数核公式进行合成,得到新的核函数,此函数表达式作为本文模型训练所用的核。
(二) GP模型预测漏洞倾向分析
基于高斯过程理论的软件漏洞分析预测中,需要对漏洞进行二分类。随后,新模型可用作预测,实践预测结果映射在区间0~1范围内,实现对软件漏洞倾向性预测目标。将这个预测模型称为GP-VTPM。模型构建要点包括四个部分:样本处理、GP模型试验、阈值设定和漏洞倾向性预测。整体预测流程如下图1所示。
在本文实践研究中,选择了两个数据集进行模型验证:NASA漏洞数据集和Linux漏洞数据集。倾向性预测工作需依据现有漏洞数据样本特征进行分析研究。随后,使用应用机器学习模型完成训练学习过程,最终对新的模块进行漏洞倾向评估工作。漏洞倾向性的本质是利用机器学习解决分类问题的过程。主要是通过对代码源文件或程序模块进行分类,形成有漏洞区域与无漏洞区域的机器学习模型。主要通过高斯过程机器学习模式进行实践训练,并最终使用训练完成的高斯过程模型对新源文件或程序进行漏洞发生倾向评估工作。
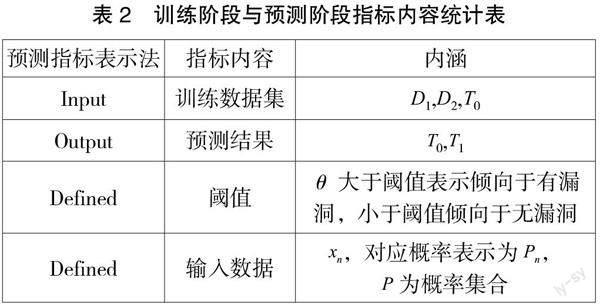
在实践操作过程中,训练与预测两阶段,按照十字交叉法进行互动验证。在具体分析时,需将有漏洞的源文件样本设置为D1,D1={(x1,1),(x2,1),...,(xn,1)},不带漏洞的源文件样本设置为D2,D2={(x1,0),(x2,0),...,(xn,0)}。另外,还包括不带标签测试数据集,命名为T0={ x1, x2..., xn}。下表2为基于训练模型训练阶段与预测阶段指标内容统计表。
在具体的训练阶段中,首先需要将训练集送入模型内部进行训练。训练集是由具有已知漏洞的样本和没有漏洞的样本组成。模型通过学习这些样本的特征和标签之间的关系来建立模型。训练完成后,将测试集输入到模型中进行预测。预测结果将被存储在相应的集合中。经过一系列的学习和预测过程,预测结果将分别进入有漏洞倾向样本合集与无漏洞倾向样本合集。
(三)特征选择阶段分析
特征选择阶段主要通过将一组带有标签样本输入进行有效的特征选择。独立样本实例都具有独立特征向量对其进行描述,但不是所有独立特征向量都对漏洞预测起作用。部分特征还可能对模型分析效果与性能造成负面影响。因此,需通过特征选择保证分类准确性,减少特征的负面影响并提高数据模型计算效率。在实践操作环节中,选择合适的度量元是特征选择的典型代表。常见度量元包括环路复杂度度量、科学度量以及CK度量等。目前广泛应用的软件漏洞数据集,如美国航空航天局设置并对外公布的NASA數据集,具体数据及数量有13个,包括软件模型、度量属性、度量值、软件模块和标签等多个内容,数据集在实践应用中存在度量特征冗余量过大、无关特征数量较多的问题。因此,需结合传统数据集和模型结构对特征选择阶段具体度量元进行优化设计。当大量特征数据涌入后,可能会造成维数灾难现象,影响数据模型预测性能。因此,需要解决这一问题,应用特征选择或特征提取方式对重点特征进行定位规划[6]。针对一部分特征模型度量指标进行筛选,找出最优子集。选取时,采用排列聚类结合方式进行选择操作。随后,结合专业算法对独立特征进行明确并进一步完成俳句操作,在独立子项目类别中,选出全局排序靠前的基本特征加入新特征集中,最终得到最优集合。
(四)数据预处理分析
数据预处理是模型训练开展前,需把握的重要环节是利用机器学习中所选取的数据预处理方式进行预测模型数据信息筛选与优化。预处理在实践操作时,不同的特征度量单位有所不同。因此,度量值也会产生相应差异。度量结果数量及差别较大,评价指标在相应评价单位评价侧重点上也有一定差异。这会直接影响到数据分析结果。为了消除这种影响,需要实施数据标准化处理。标准化处理后,所有数据指标数量级保持在同等水平下,样本中若存在异样,样本数据预处理时,也需进行标准化操作。具体来说,标准化操作方法为Z-score。处理时,需对原始数据均值与标准差进行确认,并以此为依据进行数据标准化处理,确保处理后的数据符合正态分布特征。
(五)模型评价指标分析
模型评价是对模型分析功能效果进行观察时,需要执行的关键环节。结合本文实践分析结果观察可知,本文所实现的模型构建以分类模型为本质特征。程序模块分类有漏洞倾向样本,属于负样本性质。而无漏洞倾向样本则被定义为正样本,评估效果时可选用混淆矩阵对n元素进行分类。完成上述模型构建、模型指标评价分析后,可借助专业计算机软件系统,依托上文分析相关算法进行模型构建、模型环境模拟,最终获得计算数据对软件系统漏洞发展趋势进行预测分析。为取得更好模型预测功能观察效果,还需设置对照组进行对照样本分析。由此可见,利用样本学习以及漏洞预测核心技术模型进行数据分析具有非常显著的应用适宜性。只要结合不同类型的数据模型,选取相应的计算方法和分析方法,就能在软件系统中获得良好的漏洞发展趋势预测效果。
四、结束语
综合本文实践分析可知,软件系统漏洞发现与倾向性预测过程中,需结合模型构建、数据计算、数据处理和对比分析几个要点环节,做好组织实施工作。结合软件系统漏洞发展趋势,对系统风险进行进一步明确。在具体的模型构建和数据分析环节工作推进落实过程中,应结合多样化数据进行筛选分析,明确数据特征,做好数据标准化预处理,为最终创建实验环境,提升实践分析有效性奠定基础。
参 考 文 献
[1]郑建云,庞建民,周鑫等.基于约束推导式的增强型二进制漏洞挖掘[J].计算机科学,2021,48(03):320-326.
[2]白首华,胡天彤.微型嵌入式软件静态缺陷预测系统优化设计[J].现代电子技术,2020,43(10):97-99.
[3]曾嘉麒,刘外喜,卢锦杰.软件定义数据中心基于残差网络的大象流预测机制[J].小型微型计算机系统,2021,42(09):1938-1943.
韩鹏军(1975.06-),男,汉族,硕士,国家能源集团国能信息技术有限公司网安中心总经理,工程师,研究方向:信息安全、信息化。
猜你喜欢
学会(2016年12期)2017-01-13
科技创新导报(2016年23期)2016-12-23
科技创新导报(2016年21期)2016-12-17
中学教学参考·理科版(2016年9期)2016-12-15
亚太教育(2016年31期)2016-12-12
考试周刊(2016年89期)2016-12-01
科教导刊·电子版(2016年15期)2016-06-25
无线互联科技(2015年9期)2016-03-05
黑龙江教育学院学报(2015年3期)2015-05-12
