
基于PON 接入系统的网络质差分析方法的研究
2023-10-05 08:10郑航飞张显峰周成龙
电子设计工程 2023年19期
郑航飞,张显峰,周成龙
(1.武汉邮电科学研究院,湖北武汉 430073;2.烽火通信科技股份有限公司,湖北武汉 430073)
随着通信技术的发展,网络已经自然而深刻地融入人类的日常生活和工作。人们希望借助于网络,随时随地通过语音、图像以及视频等多种方式进行灵活通信。随着网络的普及性越来越高,网络的用户群体也在逐渐扩大,这些用户群体对网络使用过程中的满意度是很重要的。因此对网络中的数据流量进行分析也成了至关重要的一个环节。
传统的网络流量分类都是通过传输层的端口号进行区分不同的业务,但是随着网络的不断发展,网络中的业务急速增长,传统的网络流量分类已经满足不了移动互联网中大量业务的解析,进而有了深度报文检测技术,这种技术能够更深层次地对报文进行解析,从而能够更精确地对网络中的数据流量进行识别分类。但是,深度报文分析能做到的只是对网络流量进行识别,无法对识别到的数据流量进行分析计算。
该文基于PON 接入系统,提出了一种网络质差分析方法,该方法与传统报文检测方法不同的是,在网络流量经过OLT(光线路终端)时,对现网中的网络流量进行动态分析,通过特征库将网络中的流量分为视频流量、线上办公流量、游戏流量、在线教育流量等,进一步对这些数据流量进行计算,从而精确地得出相关的网络问题[1-4]。
1 架构设计
质差分析方法架构图如图1 所示,系统部署在OLT 上,用户上网的网络流量会经过OLT 的主控盘交换芯片的镜像功能进行镜像,将所有的网络流量镜像到网络资源板卡。
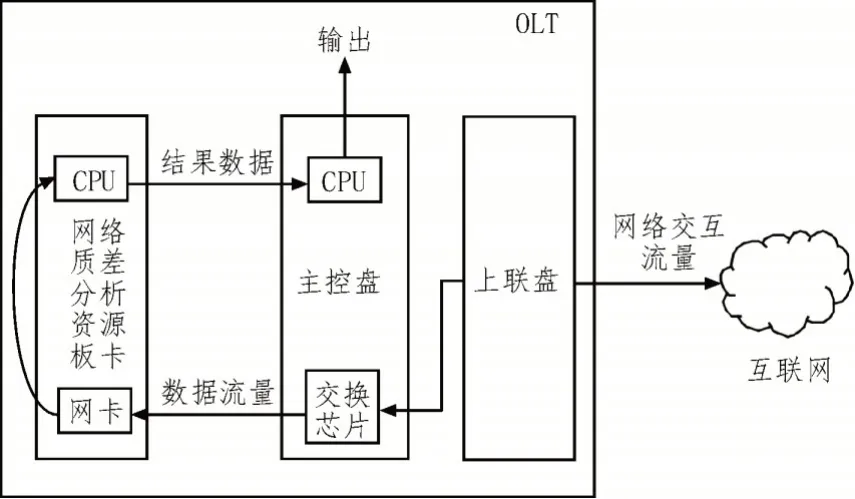
图1 质差分析方法架构设计图
在网络质差分析设备的底层收包,采用了DPDK(Data Plane Development Kit)架构,DPDK 的主要职责是管理网卡,将网卡收到的数据包进行处理。在传统的网络协议栈中,网络报文会通过网卡接收和发送,传统的报文接收发送都需要向CPU 发送中断,而且每次中断都需要保存、恢复处理器状态,同时运行中断程序,这样的操作会消耗大量的时间,对于这样数据量大、高性能的方法,处理速度将会成为整个方法的性能瓶颈。因此,在底层收包的处理上选用了DPDK,其采用轮询模式驱动的方式直接操作网卡的接收和发送队列,将报文直接拷贝到用户内存空间[5-9]。
在DPDK 收包处理之后,原始的数据报文会进入到网络流量质差分析方法中进行深度报文分析以及相关网络指标的计算,在程序运行的过程中,会将计算的结果上报到主控盘的CPU,然后输出计算的结果。
2 方法模块
方法模块图如图2 所示,首先在现网中获取到一些应用的域名,然后将这些域名手动配置进特征库,在DPDK 做了收包处理以后,首先会结合配置的特征库对该数据流进行识别,在将数据流进行了初步识别之后,将收到的数据包进行深度报文解析,根据不同报文的端口、标识号不同等特点,进行不同的解析。解析部分分为DNS 报文解析以及MAC 地址同步。在将数据报文深度解析得到需要的数据之后,就进入到最重要的网络KPI计算部分,该部分用到了一些现阶段比较优秀的算法,根据特征库配置的应用来进行计算[10-11],然后将分析计算出来的数据存放在共享内存中,最后将计算结果上报到主控盘。
2.1 报文解析
2.1.1 MAC地址同步
整个网络流量分析方法部署在OLT,OLT 的主控盘会定时向网络流量分析资源板卡发送MAC 地址同步报文,这种报文采用的是UDP 报文格式。在OLT 上进行组包时,只打包了OLT 下所挂的ONU(光网络单元)的基本信息,如OLT 的IP 地址,ONU 的MAC地址,所属的OLT编号、槽位号以及VLAN号等。
在DPDK 收包处理以后,报文解析模块会收到原始报文,在经过深度报文分析,可以解析获得OLT封装在报文中的ONU 信息。
2.1.2 DNS解析
DNS 解析是很重要的一个部分,在这个部分,DNS 解析模块同样能收到网络中的原始报文,在这个模块会根据DNS 报文的特点,逐层解包。根据数据报文的格式,在收到报文后,先将报文中的以太头剥离,获取到数据报文中的源Mac 地址和目的Mac地址,同时还将获取数据包的类型。DNS 数据报文属于UDP 数据报文的一种,因此在进行DNS 解析时,会优先过滤掉其他类型的报文,提高后续的处理效率。
在经过多次剥离报文后,DNS 数据报文中携带的DNS 信息会暴露出来,然后将报文中的数据解析出来。主要需要获取的指标有该DNS 交互的ONU的MAC 地址、域名、IP 地址列表以及响应时间。在获取到ONU 的MAC 地址后,根据上述的MAC 地址同步获取到ONU 信息,并更新DNS 信息,将DNS 信息与对应的ONU 信息绑定。完成了DNS 解析后,将解析所获取的IP 地址列表回填到特征库。
2.2 流处理
与传统的深度报文检测不同的是流处理,对网络指标进行计算。流处理阶段将计算现网中的用户在对不同的应用进行访问时,所产生的不同的丢包、时延、抖动等指标。
在这个模块中,根据不同的协议类型在网络中传输的特点,分别计算丢包、时延、抖动。在收到数据报文以后,会初步将报文分为TCP、UDP、ICMP 三种报文。在分包处理时,由于TCP 传输会进行三次握手,并且有报文顺序等特点,所以这里只对正常报文之间的时延以及抖动进行计算,将其他的重传报文、乱序报文不作计算时延抖动的处理,而这些重传乱序报文将会进行丢包计算的处理。而对所有的UDP、ICMP 报文都只计算时延与抖动[12]。
2.2.1 时延、抖动计算
在计算算法方面,三种报文对于时延抖动的计算采用的是一种计算方法。主要计算的指标有平均往返时延(rtt_mean)、平均往返时延抖动(rtt_jitter)以及TCP 数据流的超时重传时间(Retrans_rto)。当数据经过报文解析的数据报文进入到流处理模块时,首先在提前创建好的数据流中查询这个数据报文的上一个符合要求的数据报文进行计算,这里先计算出两个报文之间的采样时间,即往返时间(SampleRTT),如果在数据流中没有找到符合要求的数据报文,那么当前处理的这个数据报文将继续挂在数据流尾部供下面到来的数据报文进行计算。
计算表达式如下[13]:
1)平均往返时延:
2)平均往返时延抖动:
3)采用滚动迭代的方法对两种参数进行计算,初始时,rtt_mean=SampleRTT,后续每计算出一次SampleRTT 就更新得出一次rtt_mean,直到统计周期结束,得出最终rtt_mean。对于抖动,同样也是采用滚动迭代的方式进行计算,初始时,rtt_jitter=1/2 SampleRTT,后续每计算出一次SampleRTT 就更新一次,直到最终计算出rtt_jitter。
对于TCP 数据报文,还会存在重传超时时间,对于重传超时时间,计算表达式如下:
根据RFC6289,并经过多次测试计算,在参数α取1/8,β取1/4,μ取1,γ取4 时,计算结果最佳。
2.2.2 丢包计算
从数据报文的特点出发,主要计算TCP 数据报文的丢包率。根据现网中数据流的方向可以初步将网络流量分成上下行,如果收到的数据报文的目的MAC 地址为网络侧的MAC 地址,则判断为上行数据报文,如果收到的数据报文源MAC 地址为网络侧的MAC 地址,则判断为下行数据报文。
其次,对于网络故障定位功能来说,仅做上下行判断的准确性远远不够,因此,除了判断上下行之外,还对丢包做了更加精确的定位处理。以监测点为基准,除了将数据报文分为上下行外,还在上下行的基础上将数据报文分为网络侧和用户侧,网络侧数据报文即监测点到服务器之间的数据报文,用户侧数据报文即监测点到客户端之间的数据报文。从而可以将数据报文更精确地分为上行用户侧数据报文、上行网络侧数据报文、下行用户侧数据报文、下行网络侧数据报文。因此,基于监测点,丢包可以分为上行用户侧丢包、上行网络侧丢包、下行用户侧丢包、下行网络侧丢包。
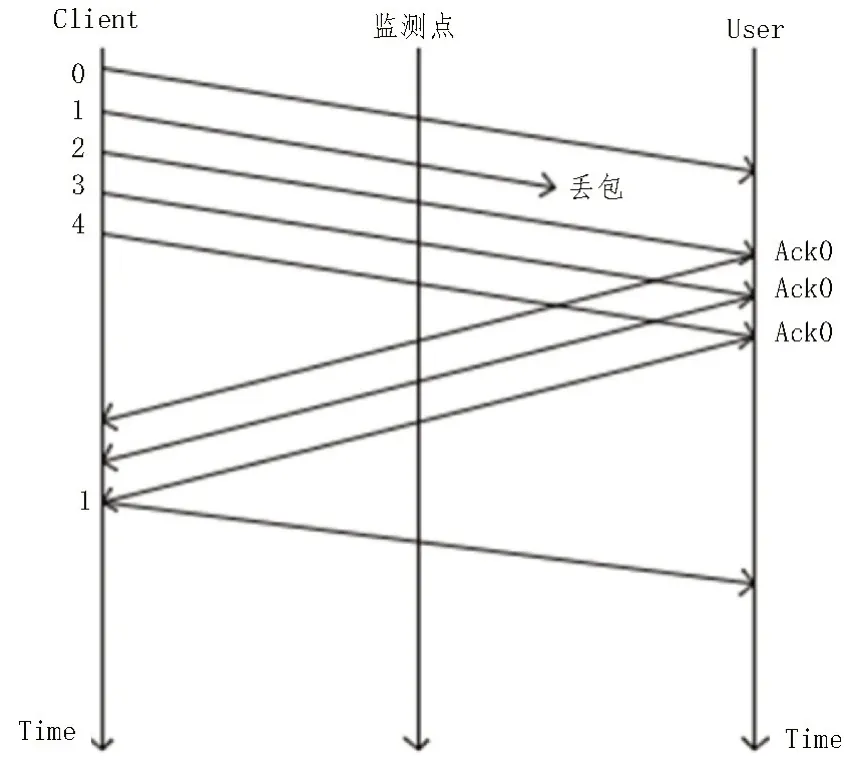
下行数据丢包分为下行网络侧丢包和下行用户侧丢包,即发送端为Client 端时,发送的报文丢失,为下行数据丢包。下行网络侧丢包如图3 所示,当1 号报文发生下行网络侧丢包时,User 端会在未收到1号报文的情况下,会持续向服务器发送0 号报文的Ack 报文,Client 端在持续收到三个0 号报文的Ack报文后,重新发送1 号数据报文,此时,设置的监测点上就会检测到1 号报文的重传报文。下行用户侧丢包如图4 所示,1 号报文在监测点与User 端发生了丢失,此时监测点能检测到一次1 号数据报文,但是User 端还是会向Client 端发送0 号数据报文的Ack报文,Client 继而重发1 号数据报文,那么在监测点就能再次检测到1 号数据报文。
同理,上行数据丢包也分为上行网络侧丢包和上行用户侧丢包,即发送端为User 端时,发送的报文丢失,为下行数据丢包[14-15]。
根据TCP 数据报文存在IP 首部ID 号(ID(i))、TCP报文首部序号(seq(i))以及超时重传,基于方法中对于各种丢包的定义,在判定TCP 报文是否发生丢包之前,先定义如下表达式[16]:
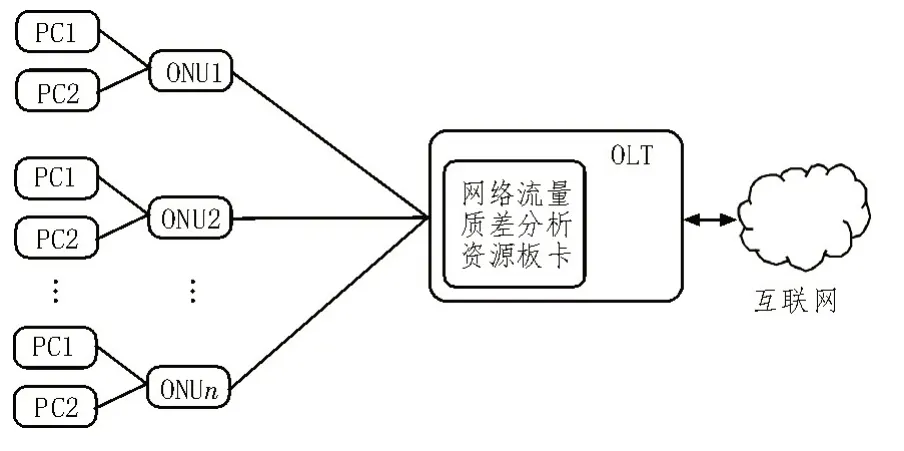
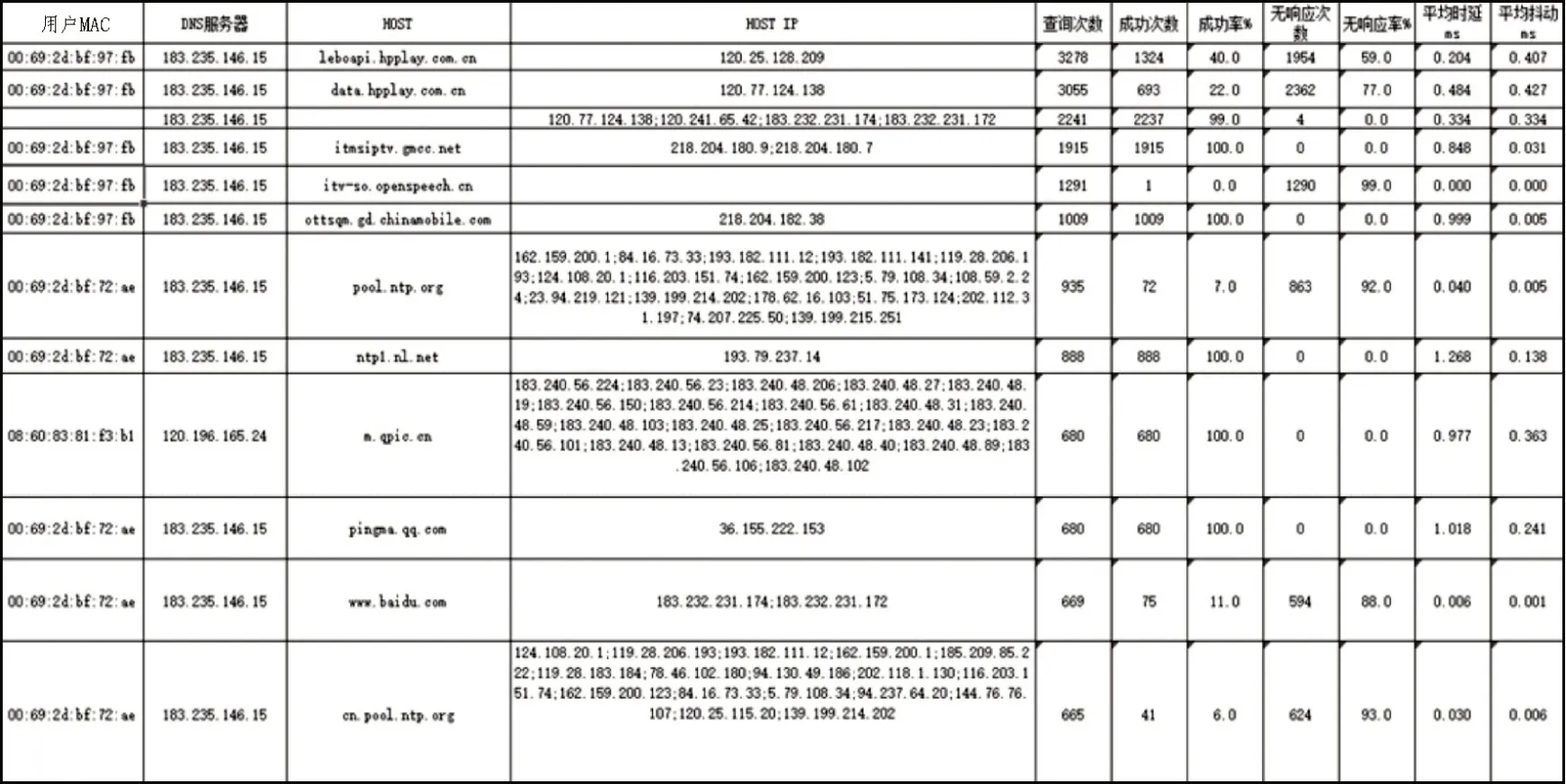
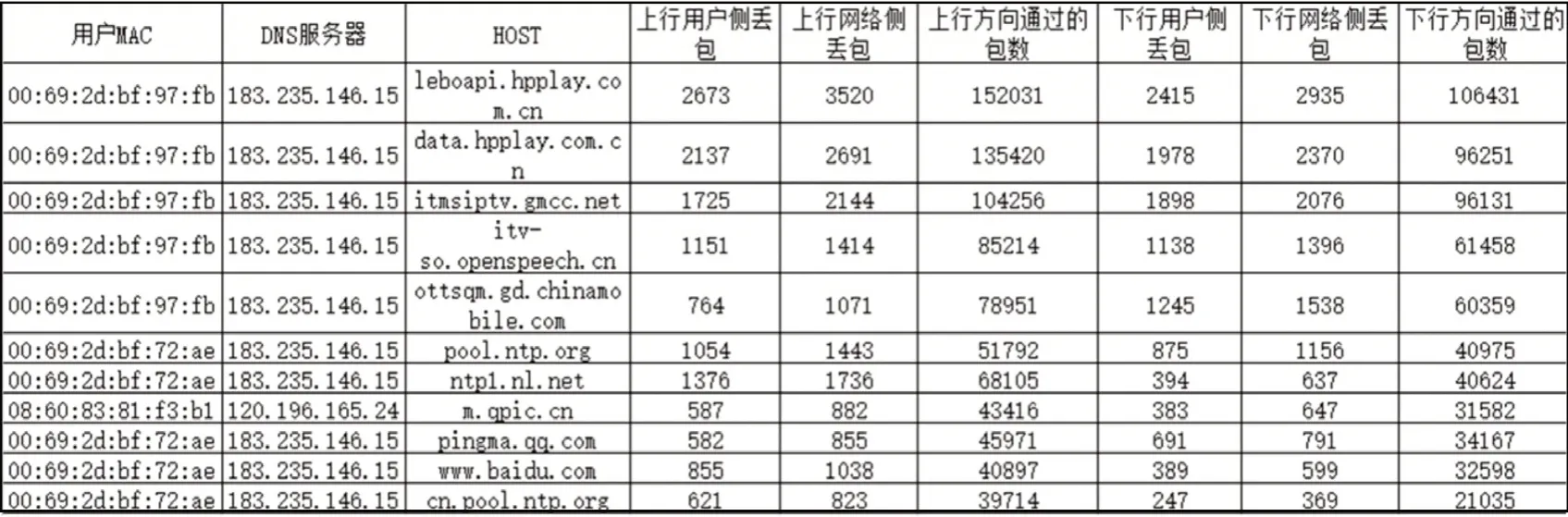
①seq(i) 图3 下行网络侧丢包 图4 下行用户侧丢包 ②seq(i)=seq(j) ③T(i,j)>Retrans_rto(Retrans_rto 为上述重传超时时间,T(i,j)为两个数据报文之间的时间间隔) ④ID(i)-ID(j)>=3(ID为对应报文IP 首部的ID号) 如果当前处理的数据报文使表达式①and{③or④}为真时,那么对于上行数据报文来说就是产生上行用户侧丢包,对于下行数据报文来说就是产生了下行网络侧丢包。如果当前处理的数据报文使表达式②and{③or④}为真时,对于上行就是产生上行网络侧丢包,对于下行就是产生下行用户侧丢包。 实验环境主要依赖于OLT,实验拓扑环境如图5 所示,首先搭建模拟现网中的上网环境,在网关下面连接OLT,在OLT 下面连接多个ONU,然后在每个ONU 下面挂多个终端进行上网,产生上网流量,然后将检测点设置到OLT 上,使用OLT 的镜像功能,将OLT 正常的上网流量全部镜像到质差分析系统上,然后DPDK 进行收包处理,之后开始对这些数据流量进行分析。 图5 实验拓扑环境 网络流量质差分析方法基于上述网络拓扑进行了实际的测试,在对数据流量进行了初步的识别之后,统计并列举出访问域名的一些识别信息,如图6所示。 结果显示,该网络流量质差分析方法能将从OLT 经过的网络流量进行识别分类,每个域名会对应多个IP 地址,同时这种方法可以统计访问该域名的次数以及成功的次数与未响应的次数,然后对每一种应用的数据流进行时延、抖动计算。并对这些流量进行TCP 的丢包、重传的计算,部分结果数据如图7 所示。 在将数据流初步识别之后,将每一种应用的数据流进行分类,然后根据分类后的数据流进行计算,最后得出访问不同的应用时,网络出现的丢包、时延、抖动等参数指标。 基于PON 接入系统,该文提出了一种网络流量质差分析方法,对现网中的数据流量进行质差分析,能将网络流量根据业务类型进行分类,该方法在对数据报文识别分类的基础上能计算出这些数据流量的时延、抖动、丢包等网络性能参数,并能定位到出现网络故障的地方。同时用到了几种参数的计算算法,这些算法能够很好地解决在计算时延、抖动、丢包等方面的问题。 尽管该方法能够识别出现网中大部分类型的流量,但是还存在许多不足,比如目前只支持IPv4 数据报文的解析与识别,暂不支持IPv6 的数据报文进行识别。同时,参数计算准确率还有待提高。在后续,将针对IPv6 业务进行完善,并改进计算算法,以提高参数计算的准确率。 图6 流量识别信息截图(部分) 图7 流量KPI计算结果截图(部分)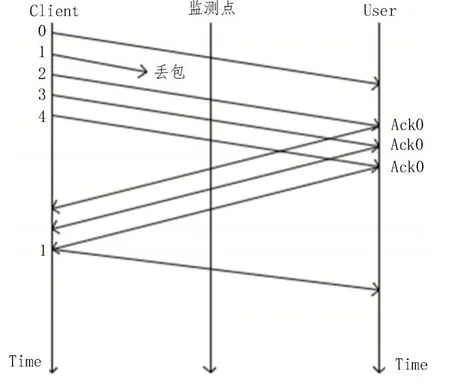
3 实验结果分析
3.1 实验拓扑环境
3.2 实验结果数据分析
4 结束语
猜你喜欢
汽车电器(2022年9期)2022-11-07
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
微型电脑应用(2021年3期)2021-03-31
铁道通信信号(2020年4期)2020-09-21
汽车维修与保养(2020年11期)2020-06-09
中国外汇(2019年11期)2019-08-27
电脑与电信(2018年12期)2018-03-23
北京航空航天大学学报(2017年7期)2017-11-24
铁道通信信号(2016年8期)2016-06-01
西北工业大学学报(2015年3期)2015-12-14
