
结合ERNIE2.0 和多尺度网络的数字图书馆文本分类研究
2023-10-05 08:10陈丽春
电子设计工程 2023年19期
陈丽春
(西安音乐学院 图书馆,陕西西安 710061)
随着图书数量的急剧增加,人工分类效率低,易错分类[1]。快速且准确地区分图书类别有助于馆方管理和方便读者查阅[2]。
机器学习方法[3-4]无法确保获取特征的准确性。文献[5]提出了基于CNN 网络的分类模型,Word2vec无法表示多义词。文献[6]提出了BERT-BiLSTM 混合方法,BiLSTM 模块仅能捕捉文本序列信息。文献[7]提出了ALBERT-CRNN 模型,提升了文本分类性能。文献[8]提出了BERT-BiGRU-AT 模型,软注意力能关注到重点词语。
该文采用ERNIE2.0 提取动态文本特征矩阵;构建多尺度网络以捕获不同层次的情感语义;软注意力负责识别关键情感特征。
1 数字图书馆文本分类模型
1.1 模型架构
通过结合预训练模型ERNIE2.0、多尺度网络和软注意力机制三者的特点,从文本特征表示和特征学习等方面提升模型整体性能表现,最后由线性层输出图书类别。分类模型整体结构如图1 所示。
1.2 ERNIE2.0预训练模型
预训练模型ERNIE2.0[9]采用持续性多任务的增量学习策略,结合词的上下文语境学习到动态语言表征,有效捕捉词汇、句法和语义信息,增强模型语义理解能力。模型结构如图2 所示。
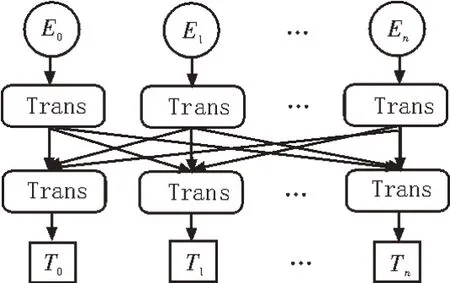
图2 ERNIE2.0模型结构
其中,Trans 表示Transformer 编码器,主要由自注意力机制[10]和前馈神经网络构成。输入向量E=(E1,E2,E,…,En)由字向量、位置向量和分句向量相加而成,Et表示第t个词的向量表示,起始位置为句字整体语义向量[CLS]。字向量为句子中每个词通过查询词汇表对应序列表示得到,不存在的则用[UNK]替代;位置向量的加入是为了弥补Transformer编码器无法捕捉时序信息;该文图书类型识别为单句分类任务,因此分句向量全为0,表示第一句。输入向量E经多层编码器捕捉每个词在具体上下文语境的动态含义,生成特定的语义表征向量T=(T1,T2,Tt,…,Tn),Tt表示第t个词的动态词向量表征,作为多尺度网络的输入。
1.3 多尺度网络
多尺度网络由有序神经元长短时记忆ONLSTM[11]和多尺度卷积神经网络MCNN 构成。ONLSTM 负责捕捉文本中上下文序列信息和层级结构特征。MCNN 模块通过不同大小的卷积核对文本特征矩阵进行卷积操作,获取词和短语级别的局部语义特征。
传统的循环模型如LSTM[12]只能学习到文本的语义特征,无法提取句子内部的层级结构信息,ONLSTM 模型将神经元经过特定排序后,利用神经元的顺序和层级差异特点以提取句子的语法结构信息。主要计算过程如式(1)-(4)所示。
其中,σ代表sigmoid 函数;ft、it和ot分别表示遗忘门、输入门和输出门;xt为当前输入信息。W和U为可学习的权重参数矩阵,b为偏置项。权重参数矩阵中存放着每个要素关联的实际值,是神经网络的主要优化目标。权重参数矩阵W和U采用Xavier均匀化方式进行随机初始化,通过保持输入和输出的方差一致以避免梯度消失和爆炸问题[13]。
MCNN 模块负责提取不同尺度下的文本局部语义。设置不同大小的卷积核心进行局部信息抽取,采用最大池化策略选取重点特征,得到多尺度局部语义特征C。计算过程如式(10)、(11)所示。
其中,w表示卷积核;m代表滑动窗口大小;⊗为卷积操作;Ti:i+m-1表示T中第i到i+m-1 行故障文本向量。该文设置卷积核为(2,3,4),得到局部语义特征c2、c3和c4。卷积操作过程如图3 所示。
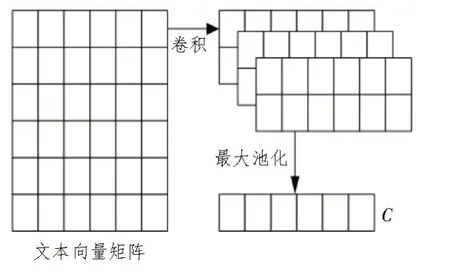
图3 卷积操作过程
1.4 软注意力机制和线性输出层
软注意力层负责计算多尺度卷积操作输出特征向量Ci的相应权重大小ai,加权求和后得到整体的注意力特征V。其计算过程如式(12)-(14)所示。
分类层通过全连接神经网络将注意力特征V映射到实例分类空间,得到分类概率P,Top 函数取每行最大概率对应标签为图书类型结果Result,过程如式(15)、(16)所示。
2 实 验
2.1 数据集和评价指标
为验证模型在图书馆文本分类任务上的有效性,采用清华大学提供的文本分类数据集[14]以及构建了新的图书馆文本分类数据集,将两者合并得到更全面的图书馆文本数据集。实验数据集共有20个类别,样本训练标签为当前样本类型,由人工进行逐条标记。训练内容为图书名称和摘要描述,采用符号“ ”与标签隔开。按照8∶1∶1 划分训练集、测试集和验证集。数据集详情如表1 所示。

表1 数据集详情
实验采用评价指标准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1 分数,具体计算过程如式(17)-(20)所示。
其中,TP 表示预测正确的正面样本数量,TN 表示预测正确的负面样本数量,FP 表示预测错误的正面样本数量,FN 表示预测错误的负面样本数量。
2.2 实验环境与参数设定
模型训练参数会影响分类性能,经多次实验调整参数后得到最优参数设定如下:ONLSTM 隐藏层单元数为256 个,层数为2;为防止训练过拟合,设置随机失活系数为0.4;软注意力维度为512。MCNN模块卷积核大小为(2,3,4),特征图数量为100。该文实验软硬件环境如表2 所示。

表2 实验环境
采用结合RAdam[15]和LookAhead[16]策略的优化器Ranger 自动调整学习率大小,通过预热操作抵消过度方差问题,提升模型训练效果。综合训练参数设置如表3 所示。

表3 综合训练参数
2.3 实验结果分析
为全方位验证该文模型的有效性,分别从词向量效果对比、消融实验和与近期表现优秀模型对比3 个方面开展实验,并对比不同优化器的性能以及卷积核大小对分类准确率的影响。固定随机数种子,避免随机误差对结果产生影响,采用10 次冷启动实验结果的平均值作为最终结果。模型实验结果对比如表4 所示。

表4 模型实验结果
由表4 结果可知,该文模型ERNIE2.0-MSNAT 准确率达到97.85%,高于实验对比的优秀模型,较BERT-BiLSTM、ALBERT-CRNN 和BERTBiGRU-AT 准确率分别提升了2.48%、2.43%和1.53%,证明了ERNIE2.0、多尺度网络和软注意力模块三者结合的有效性,能够提升图书馆文本分类性能。
为验证ERNIE2.0 模型提取文本动态特征向量的有效性,采用Word2vec[17]和BERT[18]词向量模型作为对比实验,结果表明,ERNIE2.0 用作词嵌入层效果更佳,较Word2vec-MSN 和BERT-MSN 模型准确率分别提升了2.29%和0.73%,表明ERNIE2.0 通过持续增量多任务学习策略能够学习到语义表示更为准确的词向量表征,解决一词多义问题。
设置消融实验以验证每个模块对整体性能的贡献程度,与单一特征抽取模型ERNIE2.0-ONLSTM 和ERNIE2.0-MCNN相比,多尺度模型准确率分别提高了0.93%和0.79%,证明了ONLSTM 和MCNN 模块通过捕捉不同层次的语义特征,增强模型特征捕捉的完整性。
为验证不同优化器的训练效果,分别采用Adam、RAdam、LookAhead 与Ranger 进行实验对比。各个优化器在验证集上的准确率变化如图4 所示。
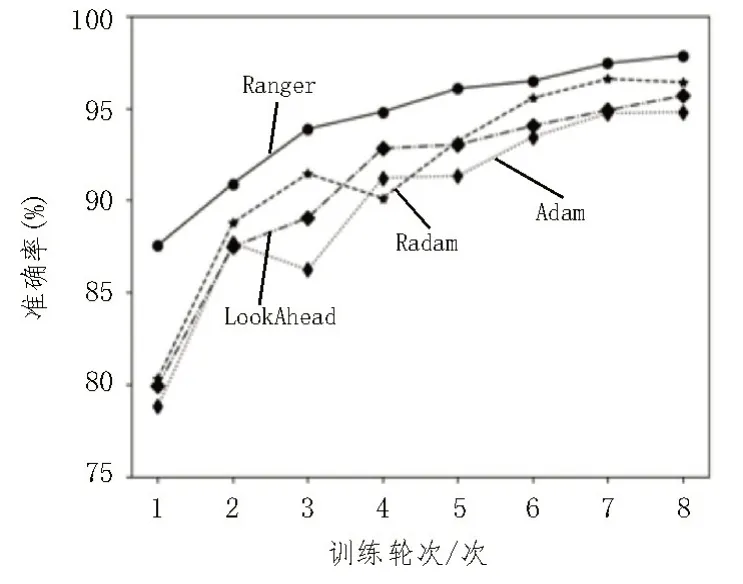
图4 优化器性能对比图
由图4 结果得知,优化器Ranger 训练过程准确率稳定上升,模型分类性能表现最佳,优于对比的其他优化策略。RAadm 作为Adam 的增强版,能够自动调整学习率大小并加入了预热策略,训练效果优于Adam。
卷积核数目过多会增加模型参数量,但对性能提高无明显帮助。设置MCNN 模块卷积核数量为3,分别采用(2,3,4)、(2,3,5)、(2,4,5)和(3,4,5)卷积核组合进行实验。实验结果如图5 所示。

图5 卷积核大小性能对比图
由图5 可知,当卷积组合为(2,3,4)时,模型准确率最高,参数设定需要根据不同任务进行相应调整[19-21]。
3 结论
针对图书馆文本分类任务,提出了结合ERNIE2.0和多尺度网络的数字图书馆文本分类模型。ERNIE2.0模型结合当前词的具体上下文获取动态向量表征,提升了词向量语义表达的准确性,应用效果优于BERT 和Word2vec;多尺度网络通过整合局部语义和全局序列特征,增强模型捕捉特征的全面性,通过消融实验证明多尺度网络优于单一网络,软注意力机制作为通用模块能有效提升模型分类性能。通过实验证明了ERNIE2.0-MSN-AT 模型的优异性能,能准确区分图书文本类别。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
太空探索(2016年5期)2016-07-12
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
电视技术(2014年19期)2014-03-11
