
一种改进YOLOv5 的小目标检测算法
2023-10-05 08:10韩镇洋王先兰
电子设计工程 2023年19期
韩镇洋,王先兰
(1.武汉邮电科学研究院,湖北武汉 430074;2.武汉邮电科学研究院研究生部,湖北武汉 430074)
目标检测的核心任务在于分类、定位、检测和分割,其基于深度学习的算法主要分为Two stage 和One stage 两类[1],而YOLO 系列就是One stage 的代表性算法,其包 括v1、v2、v3[2]、v4[3]、v5,其中YOLOv5 作为最新代的YOLO 算法,其对目标的检测精度及速度相比YOLOv4 均有所提升。但是随着无人机[4]及自动驾驶[5]技术的发展与普及,在某些小目标检测场景下YOLOv5 仍满足不了相应的需求。
1 YOLOv5网络
YOLOv5 结构分为输入端、Backbone、Neck、Prediction 四部分,其中输入端包括Mosaic 数据增强、自适应锚框计算、自适应图片缩放;Backbone 包括Focus[6]结构和CSP[7]结构;Neck 包括FPN 和PAN 结构;Prediction 包括GIoU Loss[8]。
其中在自适应锚框计算部分,YOLOv5 将此功能嵌入到模型代码中,每次训练时模型会自动计算不同训练集中的最佳锚框参数。
而在自适应图片缩放部分,YOLOv5 对代码进行了修改,对输入图像自适应地添加最少的黑边。填充后的图像两端的黑边变少了,在推算时计算量也相应减少了,从而提升了目标检测速度。
除上述几个方面的改进之外,YOLOv5 还有一些细节方面也存在差异。
2 改进后的YOLOv5-Sobj算法
YOLOv5 具有检测性能好、速度快、灵活性强的优点,但是在需要小目标检测的场景中仍存在识别精度不足[9]的问题,因此考虑从以下三方面进行算法改进:
1)改变Backbone 结构;
2)改变Neck 结构;
3)其他方面。
将改进后的算法命名为“YOLOv5-Sobj”,即YOLOv5-Smallobject。
2.1 Backbone
模型中的Backbone 部分即主干部分。该主干网络常认为提取特征的网络,其作用是提取图片中的信息,以供后面的网络使用。
尝试用两个Backbone 替代YOLOv5 中原有的一个Backbone,下面对这两个替换的Backbone 进行简单介绍。
深度残差网络(Deep Residual Network,ResNet)的提出是CNN 图像发展史上的一件重要事件,其原理是通过引入残差连接将输入数据直接传递到输出端,从而跨越了多个神经网络层。
不同于ResNet 解决了深层神经网络的梯度消失问题,密集卷积网络(Dense Convolutional Network,DenseNet)则是从特征入手,通过对特征的充分利用实现了以更少的参数达到更好的效果。DenseNet 使用类似的连接,在网络中尽可能多地保存信息。实现这些功能需要确保特征图尺寸正确,因此必要时需要修改模型的深度缩放系数和宽度缩放系数。
在这两种情况下,为了保持结构本身的复杂性,要避免修改后的层数与原始的层数相差过大。因此,最终选择了ResNet 中的ResNet50,并且成比例缩小了DenseNet 来确保其核心功能不变。此外,在原有模型中还利用了Backbone 和Neck 之间的空间金字塔池化层(Spatial Pyramid Pooling,SPP),但在实际实验中没有对该部分进行修改。
2.2 Neck
模型中的Neck 部分是位于Backbone 和Head 之间的结构,其作用是将Backbone 中提取到的信息反馈到Head 之前尽可能多地聚合这些信息。Neck 部分能够有效提高特征图的分辨率,可以聚合从Backbone 传递来的不同层特征,从而提升整体模型的检测性能[10]。
尝试将原有模型中的PAN-Net替换为bi-FPN[11]。虽然两者具有的特征相似,但两者的复杂性不同,因此所需的层数和连接数也就不同。
2.3 其他方面
Head 部分主要负责特征的捕获,并通过从Neck捕获的聚合特征来预测边界框和类。Head 部分对小目标检测影响不大,因此实验中无需修改该结构。
除了上述三个方面,还有其他一些因素会影响小目标检测的性能。可从输入图像的大小,还可以修改模型的深度和宽度,从而改变推算的主要方向。此外,为了检测特定的特征图也可以通过手动改变Neck 和Head 的层连接方式来实现。
对于层连接方式的改变,可利用高分辨率特征的重定向将特征直接反馈到Neck 和Head。要达到该效果可以通过以下两种方法来实现:
1)扩充Neck 部分以适应额外的特征图;
2)替换最低分辨率特征图以适应新的特征图。
如图1 展现了这两个可能的方向以及原有布局的对比示例图。
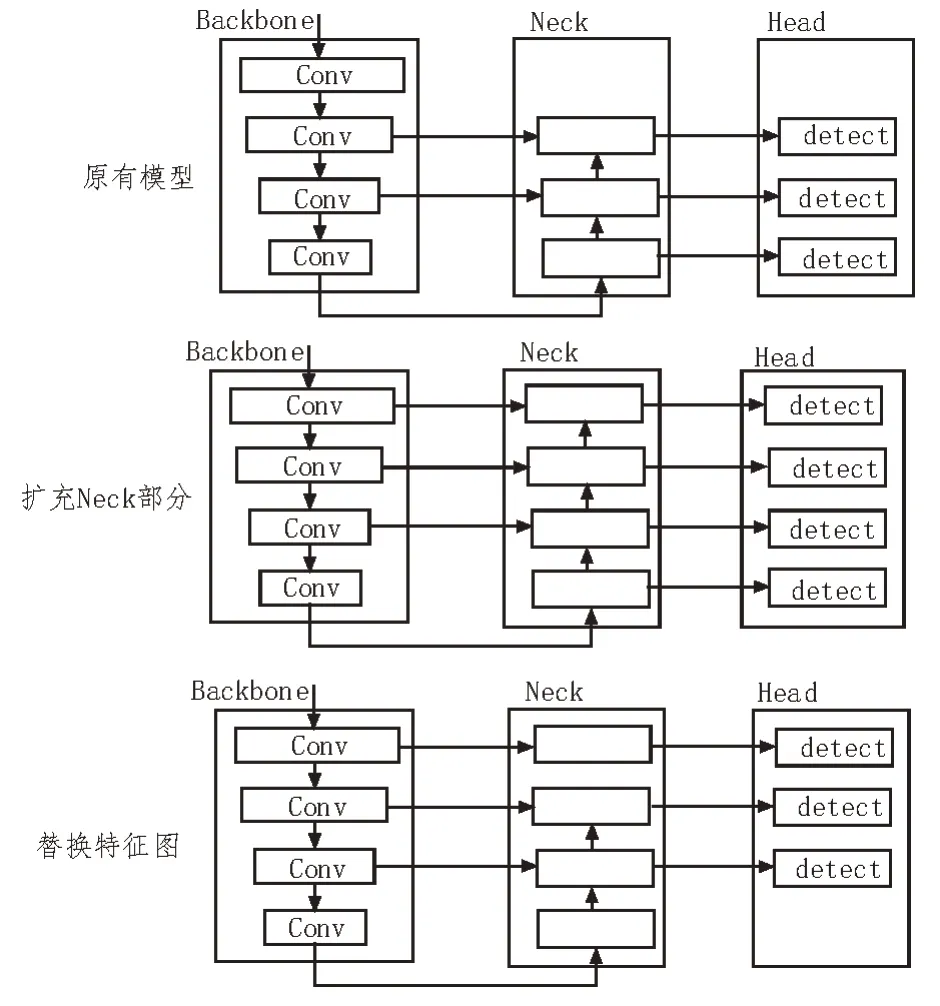
图1 两种可能方向和原有布局对比示例图
3 模型的训练及评估
3.1 实验环境
研究中的所有实验均在如表1 所示的硬件环境中完成:

表1 实验电脑的配置
3.2 数据集和实验设置
为了训练改进后的模型并为实验提供信息,实验选取了一个以自动驾驶车辆视角拍摄的路障数据集[12]。该数据集原本的目的是利用路障的不同颜色来指导自动驾驶车辆选择行车路径。如图2所示,该数据集中包括四种不同颜色的路障,总计接近4 000张图片。

图2 数据集中各颜色实例数
数据集中包括数据增强图像和恶劣天气条件下的图片,因此可以更好地模拟自动驾驶汽车在真实行驶环境中遇到的复杂情况。此外,也可以用包含交通标志[13]的小目标数据集替代路障数据集。
尽管数据集中包含路障的图片并不多,但路障的目标密度[14]却非常高,总共有超过10 000 个标记目标,因此并不存在目标数不足的问题。
与自动驾驶场景中的其他物体(如行人和车辆)相比,路障很小。实验得到的关系图3 显示了数据集中路障目标边界框的位置、高度和宽度,由图可见该数据集具有高度集中的较小目标框,这种高密度的小目标数据集给研究小目标检测带来了诸多好处[15],同时也克服了网络上许多流行数据集在小目标检测[16]上的问题(如MS COCO)。
将数据集按7∶1∶2 的比例分为训练集、验证集和测试集,并取模型的多次测试的平均性能作为代表。

图3 实例的中心点位置(横坐标x、纵坐标y)、高度和宽度关系图
3.3 评价标准
YOLOv5 的原始模型在目标的边界框区域和联合交集(Intersection over Unions,IoU)提供了与COCO的兼容性,因此按COCO 数据集来定义小目标的尺寸大小。
由于这些指标默认只与COCO 数据集兼容,因此在测试代码中重新尝试实现,以便在使用任何数据集时为研究获得更有价值的数据。测试模块将会计算大、中、小目标的值以及整体性能。目标大小的判定为:小目标(目标面积小于32 平方像素)、大目标(目标面积大于96 平方像素)、中目标(目标面积介于大、小目标之间)。
3.4 实验结果
由图2 可知橙色和绿色路障数据更为集中,因此仅选择两者展示性能。

表2 对四种YOLOv5-Sobj模型的改进
3.4.1 改进效果分析
图4(a)所示为以50% IoU 得到的所有目标mAP(mean Average Precision),图4(b)是以50% IoU 得到的小目标mAP,图4(c)是以每秒帧数为单位的推算速度。横坐标中lr02 代表将学习率更改为0.02,lr005则为0.005;用ResNet50替换Backbone,DenseNet表示将Backbone 更改为DenseNet;3anch 指每个尺度自动生成3 个锚框,5anch 指生成自动生成5 个。fpn是将Neck 更改为fpn 的Neck,bifpn 则是将Neck 更改为bifpn 的Neck;deep 指增加模型深度,wide 则指增加模型宽度;XS_inc 指扩充Neck 部分以适应额外的特征图,XS_ex 指替换最低分辨率特征图以适应新的特征图。此外,图中每个横坐标对应的四条柱状线从左至右依次为S、M、L、X 模型下的实验结果。

表3 YOLOv5-Sobj与YOLOv5性能参数对比
分析改变Backbone 结构带来的影响,可以发现随着模型的逐渐增大,DenseNet 的推算时间也在小幅固定增加(大约3 ms),但其检测性能也得到了显著的改进。对比之下,ResNet 在大多数情况下性能会下降,而且推算时间也明显更长。
分析改变Neck 结构带来的影响,fpn 仅在S 模型中性能优于bifpn,而bifpn 的推算时间和YOLOv5 原有模型近似。这表明保持特征图相对不变对于简单的模型来说可能更有益,但对于相对复杂些的模型就需要对特征图额外处理。
在特征图方面,研究发现,重定向被送到Head和Neck 的特征图对性能有着明显的影响。用更高分辨率的特征图替换最低分辨率的特征图在性能上带来的成效显著。
在锚框数量方面,根据数据集生成锚框在性能上确实是有效的,并且其推算时间和原有模型近似。然而,性能提升的大小似乎受到模型大小的影响。
在其他方面,研究发现,更大的学习率确实可以更好地利用模型,但这可能会随小学习率训练模型的epoch数量变化而变化。此外,与更深的模型相比,更宽的模型对小尺度目标检测效果更好。这些类型的改进对推算速度有着明显的负面影响,因此不考虑使用。

图4 单独结构更改对模型性能的影响
3.4.2 实验总结
对于上述提出的改进进行技术组合之后,就得到了一种基于YOLOv5 优化针对小目标检测的算法并将其命名为YOLOv5-Sobj。实验证明,YOLOv5-Sobj 在以50% IoU 得到的所有目标绝对mAP 上实现了平均2.4%的性能提升,在以50% IoU 得到的小目标绝对mAP 上实现了5.3%的提升,同时付出了推算时间平均增加大约3 ms 的代价,但这是可以接受的。
4 结束语
在对YOLOv5 小目标检测算法的改进中提出了几种架构修改,与原有模型相比,以相对较低的成本实现了较大的性能改进,而且保证了推算速度与原有模型基本近似。虽然实验提出的架构有着不错的改进效果,但实验结论的普遍性还应进一步研究。最后,还有很多的方向和技术在文章中没有提及,这也是需要进一步研究的地方。
猜你喜欢
信号处理(2022年11期)2022-12-26
计算机与生活(2022年11期)2022-11-15
计算机工程与科学(2022年8期)2022-08-20
中南民族大学学报(自然科学版)(2022年3期)2022-05-08
疯狂英语·新策略(2019年10期)2019-12-13
再生资源与循环经济(2019年10期)2019-11-23
当代陕西(2019年10期)2019-06-03
新高考(英语进阶)(2018年1期)2018-04-18
环球时报(2018-02-28)2018-02-28
环球时报(2018-01-04)2018-01-04
