
基于openGauss 的异构算子加速技术
2023-09-22 01:09陈现森
华东师范大学学报(自然科学版) 2023年5期
陈现森, 徐 辰
(华东师范大学 数据科学与工程学院, 上海 200062)
0 引 言
近年来, 随着互联网、人工智能、大数据等技术与实体经济互相演进和融合, 许多行业在信息化进程中将数据库作为其重要的数据基础设施. 随着数据规模的扩大和分析型应用需求的不断增长,OLAP (on-line analytical processing) 查询变得越发重要. 现代企业需要从海量数据中提取有价值的信息来辅助业务的决策, OLAP 查询则是加速该流程的高效的数据分析方法.
由于功耗墙、内存墙的问题, 以CPU (central processing unit)为计算核心的通用数据库系统在执行OLAP 负载时可能会出现性能不佳的情况. 相较于CPU, GPU (graphics processing unit) 具有支持大规模并行计算的能力, 且显存性能也强于CPU 主存. 如何在数据库系统OLAP 查询处理过程中发挥GPU 等新硬件带来的异构计算能力受到学术界和工业界的广泛关注. 对于GPU 加速数据库查询,早期研究主要聚焦于理论验证[1]、模拟和原型设计(如 GPUDB[2]、 GDB[3]、Ocelot[4]), 之后出现了许多学术研究原型与商用型异构数据库.
商用型异构数据库系统可分为面向GPU 重新设计的数据库和支持GPU 计算的通用数据库. 面向GPU 重新设计的数据库通过GPU 完成全部或大部分的查询执行. 此类系统完全摆脱了传统数据库, 仅聚焦于OLAP 负载而忽略OLTP (on-line transactional processing)负载. 支持GPU 计算的通用数据库系统通常使用GPU 来执行计算密集型算子. 此类工作可以结合到现有数据库生态中, 周边工具更为丰富, 加速OLAP 负载执行的同时也保留了通用数据库对OLTP 负载的支持.
作为通用数据库系统, openGauss[5]目前尚无法使用GPU 加速查询处理, 因此有必要增加支持异构计算的能力以更有效地应对OLAP 负载. openGauss 内核源于PostgreSQL, PostgreSQL 社区中目前已经有了GPU 加速插件PG-Strom. 然而, openGauss 在演进过程中产生了越来越多与PostgreSQL之间的差异, 使得PG-Strom 已经无法直接适配openGauss. 此外, PG-Strom 本身设计当中的局限性导致简单移植到openGauss 中带来的性能提升有限. 具体来讲, 本文的主要内容如下.
(1)针对PG-Strom 无法适配openGauss 的多线程并行方式的问题, 提出了一种基于分块读取和按键分发的CPU-GPU 协同并行方案. GPU Scan 算子通过分块读取的方式可以缩短读取时间. 对于GPU Join 算子, 考虑与多种负责数据分发的Stream 算子组合, 生成更多的物理执行计划. 这种并行方案可以缩短数据读取时间, 有效提高CPU、GPU 的利用率, 还可扩展到多GPU 环境下.
(2)针对PG-Strom 中的GPU 算子实现并未考虑向量化执行引擎的问题, 本文设计了向量化自定义算子框架并基于此实现了向量化异构算子. 本文实现了可嵌入openGauss 向量化执行引擎的自定义算子框架, 并基于此设计了可处理列存数据并嵌入向量化执行引擎中的GPU Scan 算子, 可以加速列存数据的计算.
(3)本文实现了CPU-GPU 协同并行、兼容向量化引擎的异构算子加速的原型系统, 基于此通过实验验证了本文方案的效果.
1 相关工作
GPU 加速查询的研究原型的系统改进并非针对整体性能, 而是对系统局部问题的优化[6], 如复杂算子[7-9]、执行计划等层面的优化[10-11]. 商用型异构数据库系统需要考虑整体系统平衡, 关键问题在于权衡多方面因素以构建完整的系统. 此类系统可按照其最初的构建理念划分为面向GPU 重新设计的数据库和支持GPU 加速查询的通用数据库. 面向GPU 重新设计的数据库如RateupDB[6]、HeavyDB[12]等性能更高. 但此类工作对OLTP 负载的支持不够友好. 支持GPU 加速查询的通用数据库相较于面向GPU 重新设计的数据库保留了对OLTP 负载的良好支持. 由于通用数据库的周边生态更为完善,用户基数也更大.
基于通用数据库系统的异构数据库包括基于开源数据库 PostgreSQL 的PG-Strom、BrytlytDB和基于闭源数据库DB2 的DB2 BLU GPU[13]. 此类异构数据库系统可复用原数据库的功能模块, 如PG-Strom 和BrytlytDB 复用了PostgreSQL 的查询优化器, 给GPU 算子指定代价计算方案以在查询执行中选择合适的异构算子.
PG-Strom 将查询计划的部分计算密集型算子卸载到GPU 上进行加速. 由于体系结构上的差距,PG-Strom 无法结合列式存储等应对OLAP 分析任务行之有效的优化方法[14], PG-Strom 的整体性能提升不如面向GPU 重新设计的数据库. 图1 展示了openGauss 的架构图, 可以看到其内核中拥有列存储引擎以及与其对应的向量化执行引擎. 而PostgreSQL 中只有行存储引擎及对应的火山模型执行引擎. 此外, 与PostgreSQL 不同, openGauss 的执行模型为多线程模型. 因此与PG-Strom 不同, 本文基于openGauss 展开研究, 不仅考虑了向量化执行引擎以及列式存储引擎的优化, 还考虑了涉及CPU 算子执行模型的适配. 此外, 除了使用GPU 对数据库进行加速, 还有基于其他专用硬件的研究,如利用FPGA 进行压缩解压缩[15-16]、加密[16]等操作.
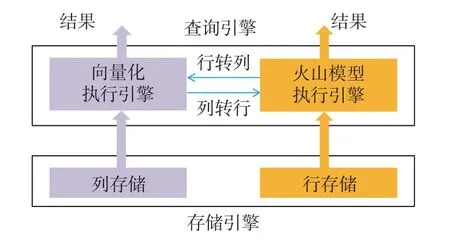
图1 openGauss 架构Fig. 1 openGauss architecture
2 CPU-GPU 协同的异构并行方案
本章首先分析了移植PG-Strom 到openGauss 后的资源浪费问题, 然后设计了CPU-GPU 协同的异构并行方案.
2.1 资源浪费的问题分析
由于历史遗留问题, PostgreSQL 的系统实现采用多进程架构. openGauss 的内核虽然源于PostgreSQL, 但其在架构上进行了大量改造. openGauss 实现了多线程并行计算. 图2(a)是PostgreSQL 服务器执行并行查询时的状态图, 该查询由3 个并行实例组成, 不同进程中的算子使用共享内存相互协调和通信, 3 个进程在不同分片的数据上进行计算. 而由图2(b)可以看出, openGauss 执行并行实例的粒度是线程. 各线程中的算子可以直接进行同步和通信. 显然, PostgreSQL 和openGauss 在算子间数据交换方式上存在明显的差异. 对于单个查询的并行执行算子, PostgreSQL 采用了多进程并行, 并通过共享内存实现数据交换.
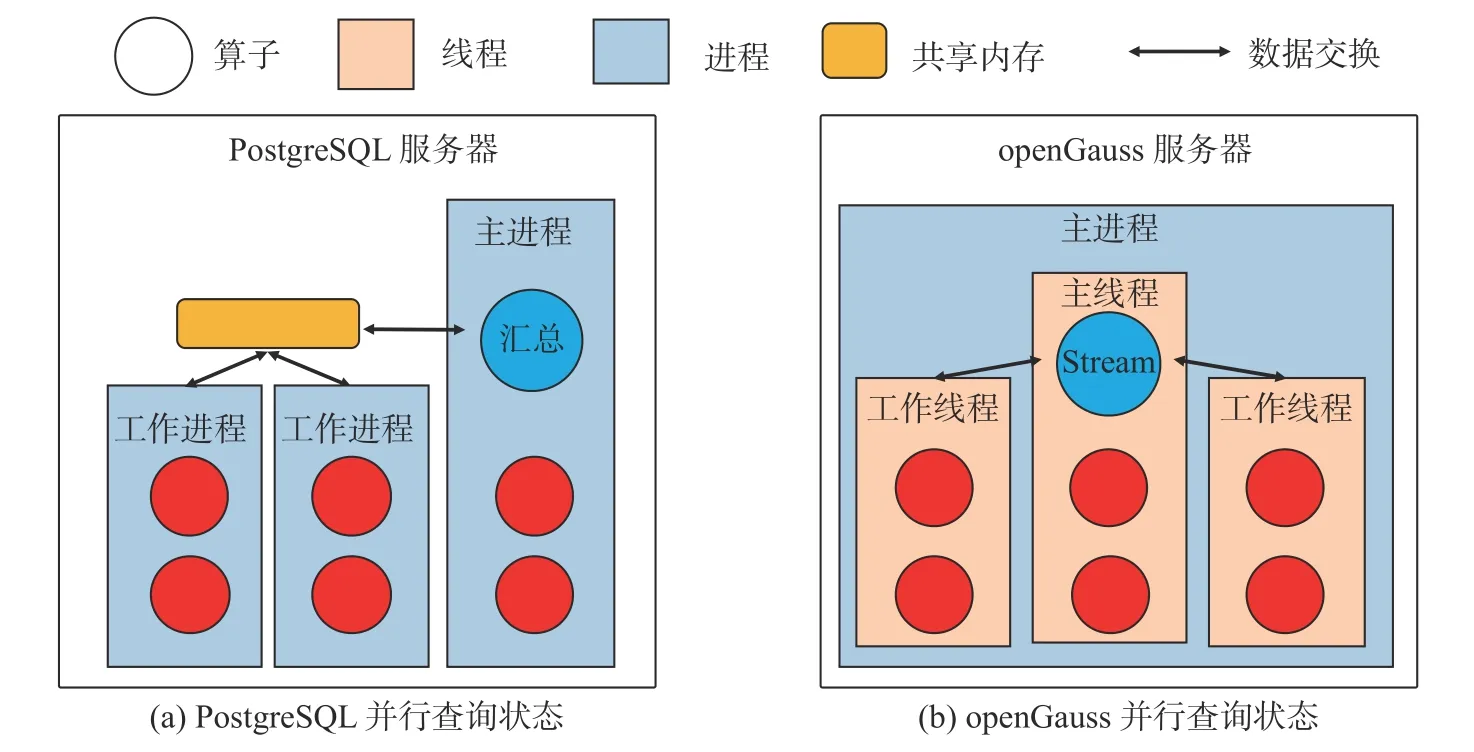
图2 并行实例间的数据交换Fig. 2 Data exchange between parallel instances
PG-Strom 作为PostgreSQL 的插件, 同样使用共享内存的方式与并行的CPU 算子进行数据交换.而openGauss 采用的多线程并行方案通过Stream 算子 (即Exchange 算子[17]) 进行数据交换. 两者数据交换的方式不同, 进而在实现上二者考虑如何进行数据交换的时机也不同. 这导致了PG-Strom 无法直接对接openGauss 中的并行CPU 算子, 而且PG-Strom 中原有的GPU 算子无法以多线程实例的方式在openGauss 中并行执行. 因此这限制了GPU 算子在CPU 端的并行执行能力, 会造成CPU、内存带宽资源的闲置, 从而影响到系统查询执行性能.
2.2 基于分块读取的多实例GPU Scan
本文在移植了 GPU Scan 算子的基础上, 为使GPU Scan 算子适应openGauss 的多线程并行技术、提高查询的执行效率, 对GPU Scan 算子进行了进一步改造. 具体来说, 方案涉及并行感知的查询优化和基于分块读取的查询执行两部分.
对于并行感知的查询优化, 本文在添加候选算子执行路径时, 会考虑表的分布信息和并行度等信息, 并且重新考虑了并行后的代价. 在添加并行感知的GPU Scan 算子路径和其他Scan 算子到候选路径中之后, openGauss 会通过自底向上的路径搜索来确定当前层的最优物理执行算子. 当openGauss的执行引擎接收到包含GPU Scan 算子的执行计划树后, 会按照自定义算子的内部实现逻辑来执行.
GPU 加速模块会在自定义算子进行初始化时, 按照线程的并行任务ID 来分配块号以供读取线程使用. 在完成数据读取ID 的分配以及算子初始化的其他步骤后, 执行计划树的上层算子逐层调用至GPU Scan 算子. 在GPU Scan 算子被调用后, 算子内部的读取线程将读取一批数据并封装成任务发送到GPU 任务队列中, 等候执行线程的消费. 在图3 中, 主线程负责块0 到块G-1 的读取, 工作线程0负责块G到块 2 (G-1) 的读取, 工作线程1 负责块 2G到块 3 (G-1) 的读取. 主线程完成所负责的块的读取后, 会跳至块 3G并负责读取此后的G个块, 其余2 个工作线程类似. 当读取线程读取了一批次块后,这些数据会被封装成任务交给GPU 进行计算.
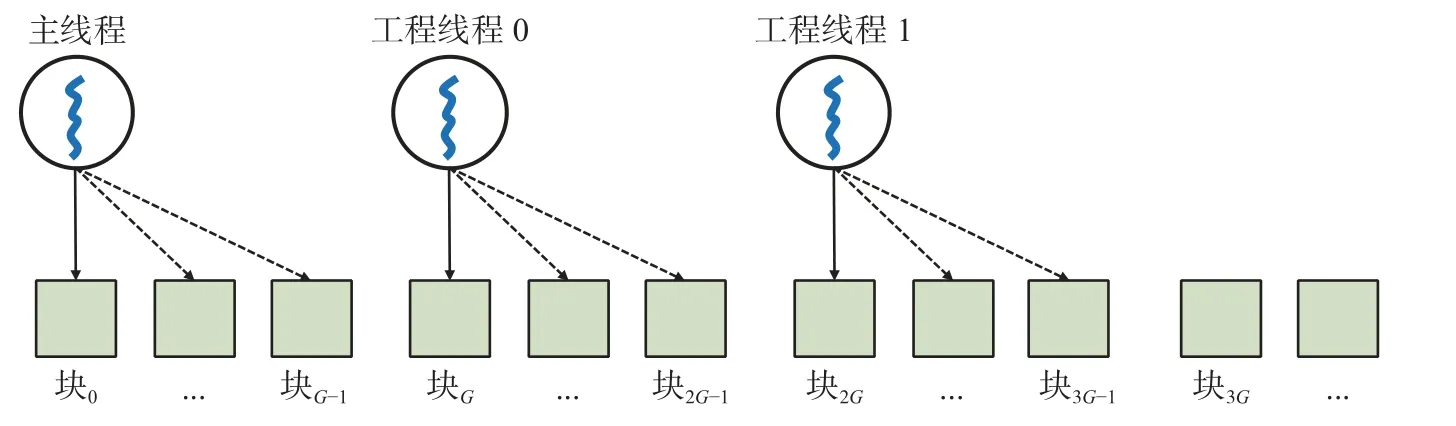
图3 GPU Scan: 并行读取数据Fig. 3 GPU Scan: Parallel reading of data
2.3 基于按键分发的多实例GPU Join
并行多实例的GPU Join 算子需要考虑下层Stream 算子的多种组合, 多种组合代表更多种类的执行计划. 自定义的Join 算子需要通过钩子函数 (Hook 函数) 在处理两表连接时尝试添加到候选执行路径中. 并行开启后, 由于GPU Join 算子的各个实例在内部独立执行, 因此需要通过Stream 算子进行数据交换以获取底层的Scan 算子的数据, Stream 算子的选择会根据连接子句以及内外表的分布信息来决定表数据是需要广播还是重新分布.
此处的Scan 算子可以是本文实现的GPU Scan 算子, 亦可以为数据库中原有Scan 算子. 如图4所示, 第一个执行计划是读取T1 和T2 表的数据并执行GPU Join. 开启并行后, 执行计划可变成随后的三个其中之一. 可以看到, 在Join 算子和Scan 算子中间插入的Stream 算子类型是负责将表数据进行重分发的Redistribute 算子或将表数据广播到各个线程的Broadcast 算子.

图4 GPU Join 算子和 Stream 算子的多种组合Fig. 4 Various combinations of GPU Join operators and Stream operators
本工作的GPU Join 算子使用的算法为哈希连接算法. 该算法在CPU 环境下的限制是对小表构建的哈希表需完全放在内存中, 在GPU 环境下就要求哈希表在显存中能够放得下. 然而目前显存相对内存容量有限, 因此需要一种方法可使得GPU Join 算子能够支持多GPU 环境以扩大显存. GPU Scan 算子由于可以通过限制同一时刻在GPU 上运行的任务数量来限制显存的使用, 因此无须进行特殊处理. 经过在查询优化阶段对GPU Join 算子进行了并行感知的优化后, 每个GPU Join 算子需要计算的数据量变小, 并且可以根据GPU 的显存使用状态、任务数据的规模等信息选择可用GPU 来放置当前GPU Join 算子.
3 兼容向量化引擎的异构算子加速技术
本章首先分析了openGauss 缺少向量化自定义算子的问题, 然后设计了向量化自定义算子并基于此实现了向量化GPU Scan 算子.
3.1 架构差异问题分析
向量化模型需要与列式存储配合使用才能发挥其性能. 为了更好地应对OLAP 负载, openGauss相较于PostgreSQL 在内核中增加了列存储引擎以及相对应的向量化执行引擎.
如图5 所示, openGauss 的火山模型执行引擎中可以嵌入自定义算子, 而openGauss 的列式存储引擎对应的向量化执行引擎中缺少能够嵌入的向量化自定义算子. openGauss 的列式存储引擎与配套的向量化执行引擎为GPU 加速提供了更多的可能性, 而简单移植过后的PG-Strom 并不支持openGauss 的列式数据. 同时, openGauss 缺乏能嵌入向量化引擎的自定义算子. 因此本工作需要先实现融入向量化引擎的自定义算子框架, 再实现加速列式数据处理的GPU 算子.

图5 缺少向量化自定义算子的架构Fig. 5 Lack of architecture for vectorized custom operators
3.2 融入向量化引擎的自定义算子框架
openGauss 原有的自定义算子框架提供了一种在执行器引擎中实现自定义算子的方法, 使得用户可以在不改变数据库内核代码的情况下扩展系统功能. 但是, 当前GPU 算子的实现基于火山模型, 无法合并到向量化执行引擎中. 因此, 本文提出了向量化的自定义算子.
自定义算子背后的设计思想是提供一个灵活的、可扩展的框架来建立新的处理节点, 这些节点可以与现有的查询处理基础结构结合. 向量化自定义算子同理, 不过其需要基于列式数据模型和列式文件的压缩单元进行设计.
本文对openGauss 内核进行了修改, 提供了调用开发者实现的向量化自定义算子的功能, 修改后的执行流程如图6 所示. 对于算子初始化而言, ExecInitVecExtenPlan 会在调用开发者实现的BeginVecExtenPlan 前做一些预备工作, 如申请内存、设置表达式上下文、初始化表达式等工作.VecExecExtenPlan 直接调用ExecVecExtenPlan. ExecEndVecExtenPlan 在调用了开发者实现的逻辑后会进行清空表达式上下文、释放内存清除执行节点等工作.
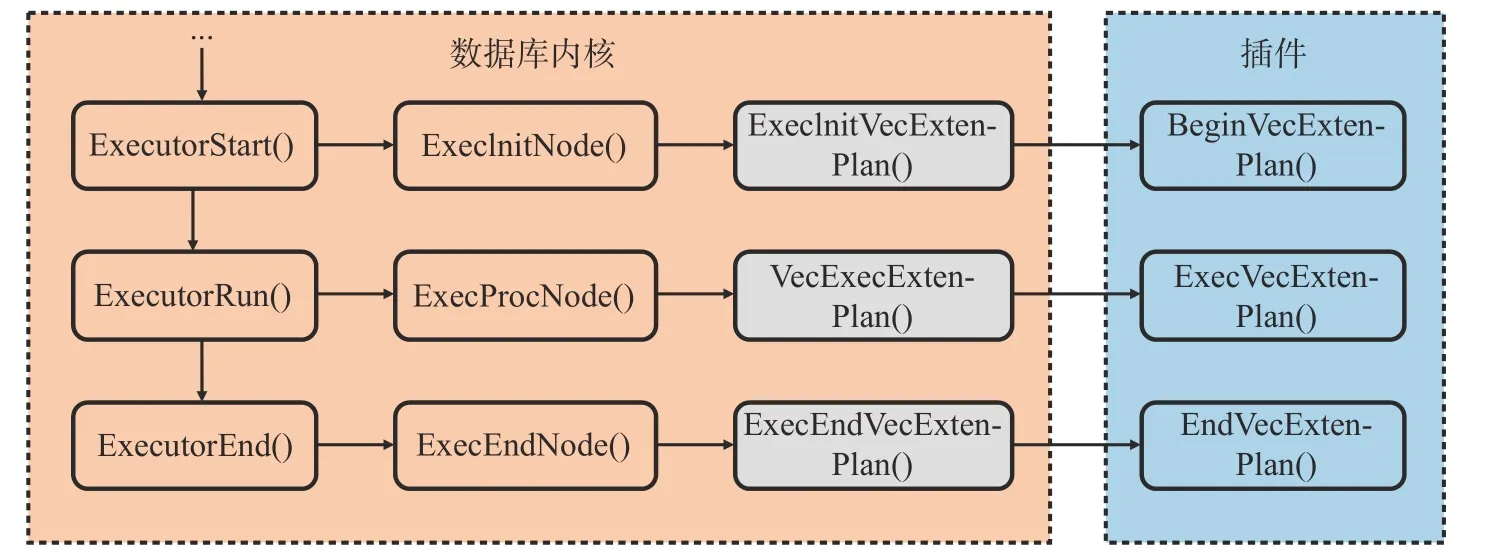
图6 向量化自定义算子框架调用流程Fig. 6 Vectorized custom operator framework invocation process
3.3 处理列存数据的向量化GPU Scan 算子
向量化GPU Scan 算子作为执行计划树的叶子节点, 向下直接读取数据文件, 向上返回数据给其他算子. 本文实现的向量化GPU Scan 算子所涉及的数据组织格式有3 种, 分别是压缩单元CU 列存文件格式、向量化GPU Scan 算子内部处理格式以及供向量化引擎使用的向量数组格式. 如图7 所示,向量化GPU Scan 算子会读取列存文件中的数据, 并将其进行处理. 经过GPU 计算后, 数据会被处理为一个向量数组, 以供上层的向量化算子使用.
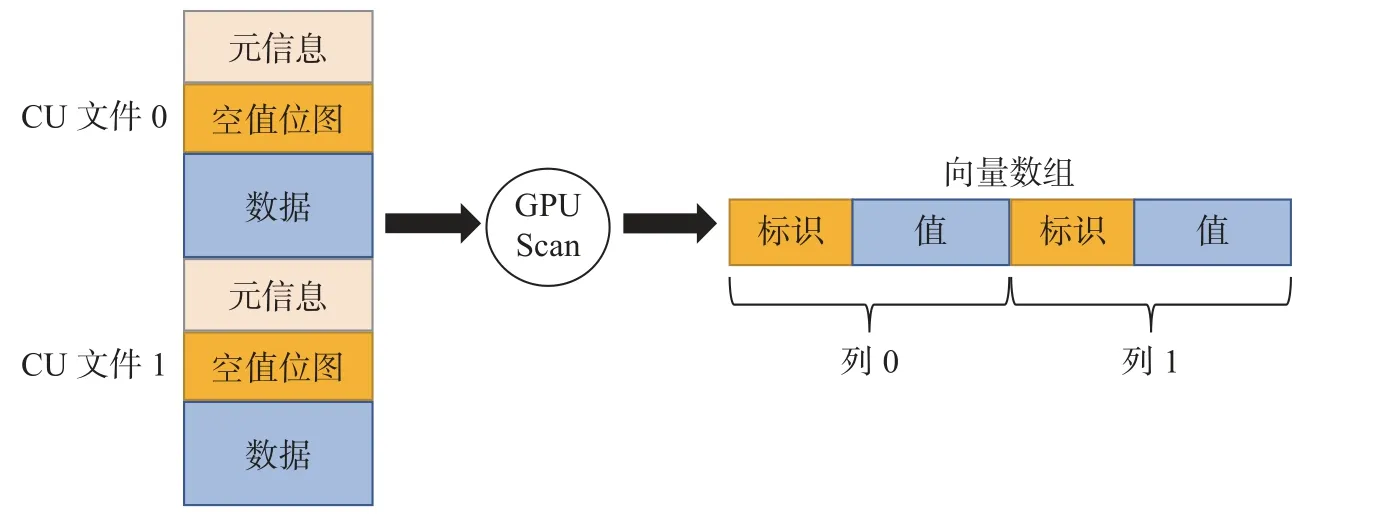
图7 向量化 GPU Scan 算子的数据流转Fig. 7 Data flow of the vectorised GPU Scan operator
为了尽量与压缩单元的格式保持一致, 减少格式间的转换代价, 本文设计了向量化GPU Scan 算子的内部数据处理格式 (简称GPU 列式数据块). GPU 列式数据块由元信息和值数据组成. 将openGauss 的列存文件数据读取并封装成GPU 列式数据块后, GPU 加速模块可围绕其进行计算层面的处理. 本文提出的向量化GPU Scan 算子在内部执行时, 由读取线程读取数据后封装成GPU 任务放入任务队列中, 执行线程消费任务队列中的任务并启动GPU 核函数进行后续计算. 在openGauss中, 表达式默认的执行方式类似于查询计划树的解释执行. 然而这种执行方式在数据量较大时的性能不佳, 每条数据都要经过表达式树的递归计算才能得到结果, 会有函数调用开销和分支预测失败导致的性能损失. 此外, 这种递归的求值方式并不适合在GPU 执行, GPU 更适合执行判断逻辑简单的代码. 因此, 向量化GPU Scan 算子的表达式执行采用编译执行, 在算子初始化阶段对表达式进行分析,生成可执行的CUDA (compute unified device architecture)代码供后续使用.
基于上述内容, 本文围绕GPU 列式数据块设计和实现了GPU 端的Scan 逻辑. 目的是基于CUDA 实现对GPU 列式数据块的扫描过滤. 对待计算数据块中的每个元组列执行以下步骤: ①过遍历元组列获取元组字段数组; ②判断其是否符合where 子句内容; ③计算线程组里所有符合条件的元组数量; ④线程组中的起始线程负责更新数据块信息, 即统计符合条件的数量; ⑤如果元组符合条件,则获取投影后元组的值和对应类型, 将结果的每列数据插入结果数据块.
4 实验分析
4.1 实验设置
本文实验的硬件环境是一台物理机服务器, 配有Intel(R) Xeon(R) Gold 6126 CPU @ 2.60 GHz 48 核处理器, 主存容量为256 GB, 磁盘容量为8 TB. 此外, 服务器配有两张Nvidia Tesla V100 显卡(32 GB 显存). 服务器软件环境如表1 所示. 本文采用借助 TPC-H 工具生成的数据集和查询语句. 数据规模为10 GB、20 GB、40 GB 和80 GB.

表1 软件环境Tab. 1 Software environment
4.2 CPU-GPU 异构协同并行性能实验
本节采用4 种方法来测试本文方案性能. openGauss 单并行: 不开启并行, 不采用GPU 进行加速.openGauss 多并行: 并行度为24, 不采用GPU 进行加速. GPU 单并行: 采用面向openGauss 移植后的PG-Strom 执行查询, 利用GPU 加速查询, 但算子并行度为1. GPU 多并行: 采用面向openGauss移植后的PG-Strom 执行查询, 利用GPU 加速查询, 且开启并行查询. 为了验证本工作实现的多实例GPU Scan 的性能, 本节展示了TPC-H 中的Q1、Q3、Q19 这几条具有代表性的查询. Q1 为单表查询,执行计划由“扫描-聚合”组成. Q3 为三表查询, 执行计划包含扫描、连接、聚合、排序算子. Q19 为两表查询, 执行计划包含扫描、连接、聚合算子.
如图8 所示, openGauss 多并行以及GPU 多并行相对于未开启并行均有明显性能收益, 且GPU 多并行对于openGauss 多并行也有性能收益. 对于TPC-H Q1, GPU 多并行相对于GPU 单并行有接近12 倍的性能提升, 此处的性能提升主要得益于数据读取可以多线程并行执行. GPU 多并行相对于openGauss 多并行有1.30 倍的性能提升, 此处的性能提升得益于GPU 的加速效果, 数据在openGauss 中是逐条元组计算, 而GPU 加速可以攒批后并行计算. 对于TPC-H Q3 和Q19, GPU 多并行相对于openGauss 多并行也分别有1.41 倍、1.50 倍的性能提升.

图8 40 GB 数据规模下多实例GPU 算子性能对比Fig. 8 Multi-instance GPU algorithm performance comparison with 40 GB data scale
图9 展示了TPC-H Q19 在不同数据规模上的优化效果. 从实验结果可以观察到, 数据规模越大,GPU 多并行相对于openGauss 多并行的加速效果越好, 性能是后者的1.08~1.50 倍. 当数据规模增大时, openGauss 多并行中逐条计算的时间在总执行时间的占比升高, 因此使用GPU 加速的效果越好.实验验证了本文提出的多实例GPU 算子的有效性.

图9 不同数据规模下多实例 GPU 算子性能对比Fig. 9 Multi-instance GPU algorithm performance comparison with different data scale
4.3 向量化GPU Scan 算子性能实验
本实验采用两种方法测试本文提出的兼容向量化引擎的异构加速技术. openGauss 向量化: 采用列存表存储数据, 不使用GPU. 向量化GPU: 采用向量化GPU Scan 算子.
如图10 所示, 本节的向量化GPU 方案相对openGauss 向量化均有性能收益. 对于Q1、Q3、Q19 这3 条查询, 性能收益分别为1.12、1.31 和1.24. 本文提出的向量化GPU Scan 算子加速的是数据加载与过滤阶段, Q3 的扫描算子在整体执行时间的占比最大, 因此使用GPU 加速的收益也最高.
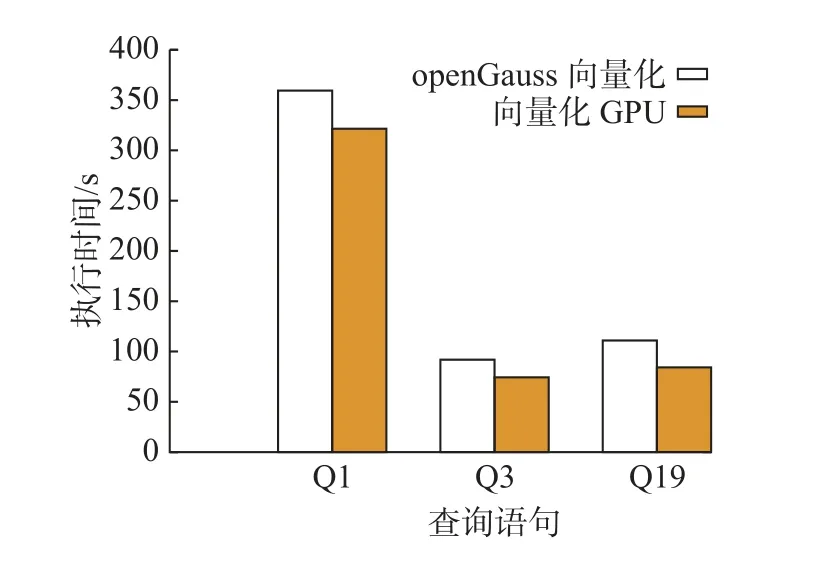
图10 40 GB 数据规模下向量化 GPU Scan 算子性能对比Fig. 10 Vectorized GPU Scan operator performance comparison with 40 GB data scale
为了体现在不同数据规模上的优化效果, 本节同样采用了TPC-H Q19 作为查询, 展示了两种方案的性能对比结果. 如图11 所示, 随着数据规模的增大, 向量化GPU 方案相对于原有的openGauss向量化方案的性能收益增大, 性能收益为1.26~1.34 倍. 当数据规模增大时, GPU 处理的数据量增大,使用GPU 加速的效果更好.
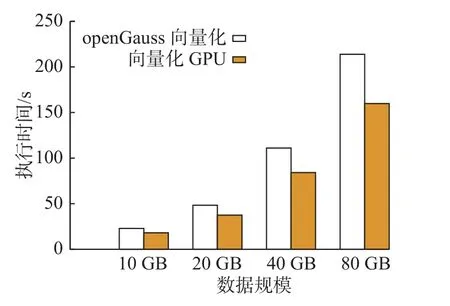
图11 执行Q19 时向量化 GPU Scan 算子性能对比Fig. 11 Vectorized GPU Scan operator performance comparison for executing Q19
5 总结与展望
openGauss 作为通用数据库系统, 目前已在我国许多行业中展开应用. 针对openGauss 与PostgreSQL 执行粒度和体系结构的差异, 本文提出了基于分块读取和按键分发的CPU-GPU 协同并行方案以及兼容向量化引擎的异构算子加速技术. 具体来说: ①为了使GPU 算子在openGauss 中的CPU 侧能够并行执行, 本文提出了CPU-GPU 协同的并行方案, 该方案由基于分块读取的多实例GPU Scan 算子和基于按键分发的多实例GPU Join 算子组成. 在查询优化阶段, 对于两种算子分别实现了并行感知的异构算子路径的添加. 在查询执行阶段, 对于GPU Scan 算子采用了分块读取的执行方式, 对于GPU Join 算子实现了结合Stream 算子进行按键分发执行机制. 使用本文提出的方法,提升了资源利用率, 提高了GPU 算子的执行性能. 通过实验验证了本文提出的方法可以缩短整体的执行时间. ②为了使 openGauss 的列式数据处理可以利用 GPU 加速, 本文将 GPU 算子嵌入了其向量化执行引擎中. 为了解决 openGauss 向量化执行引擎中无自定义算子的问题, 本文首先设计了向量化的自定义算子框架. 然后为了利用 GPU 加速列存数据的读取和过滤, 本文基于该框架设计并实现了向量化 GPU Scan 算子. ③本文基于 openGauss 和 PG-Strom 实现了原型系统 GsStrom, 该系统集成了基于分块读取和按键分发的多实例 GPU 算子, 提出向量化自定义算子框架并基于此实现了向量化的 GPU Scan 算子. 该原型系统验证了前述技术点的有效性.
目前, 由于成本和硬件依赖性的问题, 现有的GPU 数据库并未在工业界得到广泛应用. 然而, 全面上云为GPU 数据库提供了未来的发展机遇. 在云上, GPU 可以通过超卖的方式降低云厂商和用户的成本, GPU 数据库的获取门槛也因此会变得更低. 对于未来研究方向, 可以考虑为异构环境下多条查询设计合理的调度策略, 以及探索如何配合一致性互连硬件加速数据库的查询执行.
猜你喜欢
小学教学研究(2022年5期)2022-04-28
教师·下(2017年10期)2017-12-10
中国洗涤用品工业(2017年2期)2017-04-16
环球市场(2017年36期)2017-03-09
读写算·小学低年级(2017年1期)2017-02-06
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
计算机工程与科学(2013年2期)2013-06-07
云南教育·小学教师(2012年10期)2012-11-22
吉林建筑大学学报(2012年3期)2012-08-15
