
跨语言摘要研究综述
2023-08-29 02:02潘航宇席耀一陈宇飞
小型微型计算机系统 2023年8期
潘航宇,席耀一,陈宇飞,曹 蓉,南 煜
(战略支援部队信息工程大学,郑州 450001)
1 引 言
互联网的飞速发展使人们得以便捷地获取信息.但随着大数据时代的到来,文本包含的冗余和无效信息愈发增多,人们反而难以及时有效地获取所需信息.文本资源的爆炸式增长,使一种高效的自动化摘要系统成为迫切需要[1].自动文本摘要(Automatic Text Summarization,ATS)技术能够为文本生成简洁易读的摘要[2],帮助人们获取互联网中的海量信息[3].在全球化背景下,人们接触到的语种日益增多,极可能因不熟悉语言而无法准确获得信息.事实上,人们更擅长使用母语、第二外语等熟悉语种来获取信息.如何有效获取外语文本的关键信息已经成为了一个研究热点问题.跨语言摘要(Cross-Lingual Summarization,CLS)能将一种语言的文本总结为另一种语言的摘要,旨在将陌生语言的文本总结为人们所熟悉语言的摘要,使人们快速准确地获取外语文本的关键信息.
ATS按照产生方式可分为抽取式(Extractive)和生成式(Abstractive)[4].抽取式摘要[5-8]指根据一定标准,从文本中选择句子或短语,不加改动地组成摘要[9].该方法简单易行,目前发展已较为成熟,缺点是无法确保摘要的连贯性和衔接性[10].生成式摘要[11-23]指编码文本后逐字生成摘要[24],优点是可以产生新词,使摘要流畅自然.与抽取式摘要相比,生成式摘要更具灵活性,因为可以生成更丰富、更吸引人的内容[25].早期的CLS方法大多属于抽取式[26-31],但由于抽取式摘要的明显缺陷以及神经网络和深度学习技术在自然语言处理领域(Natural Language Processing,NLP)取得的巨大成功[32-39],目前的CLS研究主要在生成式摘要上进行.
本文详尽地查阅整理了近年来包括人工智能、计算语言学、NLP等领域的国内外学术会议和期刊在内的相关工作.经调研发现,当前CLS的研究综述十分稀缺,仅有一篇近期发表的工作[40].为给相关研究者们提供一份系统性的研究总结,帮助其在现有工作基础上取得更好进展,本文对CLS研究现状进行全面梳理和分析.Wang等人[40]的工作重点对CLS的数据集、方法以及未来发展方向进行了详细的总结和分析,而本文从方法、数据集、评价方法以及未来研究方向等4个方面展开更系统地综述.具体地,本文首先对CLS方法进行全面梳理,概括为“先翻译后摘要”、“先摘要后翻译”、间接学习方法、辅助学习方法以及特征增强方法等5大类,并进行优缺点分析.其次对CLS数据集的构建方法进行归纳和分析,并且全面整理现有的CLS数据集.然后对CLS评价方法进行系统地总结和分析.最后对未来研究方向进行进一步讨论.
2 跨语言摘要的定义
生成式CLS通常采用序列到序列模型(Sequence-to-sequence,Seq2Seq)[41].编码器(Encoder)首先将输入文本编码为上下文向量w,然后传入解码器(Decoder)产生输出文本,流程如图1所示.则生成式CLS模型生成Ytgt的输出分布为:

图1 基于Seq2Seq模型的生成式CLS的示意图
(1)
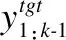
3 跨语言摘要方法
CLS是一项跨语言技术与ATS技术的交叉领域的新兴研究课题,与机器翻译(Machine Translation,MT)和单语摘要(Monolingual Summarization,MS)任务密切相关.近年来出现了许多杰出的研究工作,本节将其归纳为管道方法和端到端方法两大类.早期方法主要是管道方法.近年来,随着大数据时代的到来和深度学习技术的飞速发展,研究者们提出端到端方法.在其他研究领域,端到端方法已被证明优于管道方法[42,43].从众多CLS研究结果上看,端到端方法的确效果更好.本节还将管道方法进一步划分为“先翻译后摘要”方法和“先摘要后翻译”方法,将端到端方法进一步划分为间接学习方法、辅助学习方法以及特征增强方法.下面本文将系统地介绍每类方法的现有研究工作,并对各方法进行对比以提供更深入的分析.
3.1 管道方法
管道方法由MT和MS两个过程组成,独立进行语义等价转换(跨语言对齐)和信息压缩(摘要生成),按顺序可分为“先翻译后摘要”[26,27,30,31,44-48]或“先摘要后翻译”[28,29]两类,如图2所示,涉及源语言文本、上下文向量、中间文本、上下文向量以及目标语言摘要等5种主要对象.管道方法可视为由两个Seq2Seq模型组合而成的Seq2Seq2Seq模型,其中前一个Seq2Seq模型将源语言文本转换为中间文本,后一个Seq2Seq模型将中间文本转换为目标语言摘要.该方法的优点是思路简单,可进行零样本CLS.
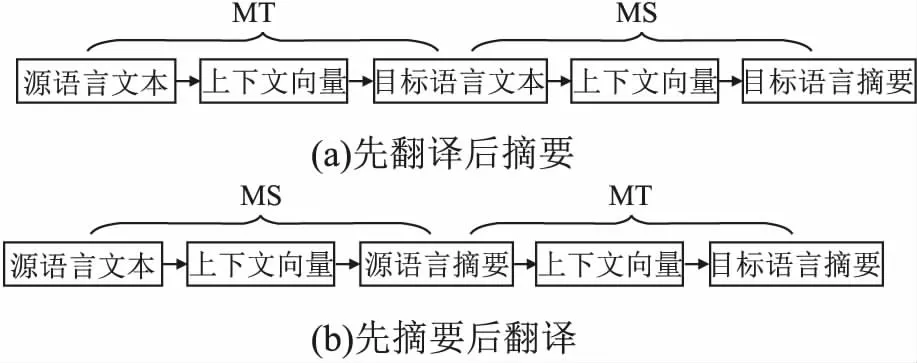
图2 管道方法的示意图
3.1.1 先翻译后摘要
“先翻译后摘要”指首先将源语言文本翻译为中间文本,即目标语言文本,然后将中间文本总结为目标语言摘要,流程如图2(a)所示.
Leuski等人[26]使用统计MT模型将印地语文本翻译为英文,然后使用抽取式摘要系统NeATS[49]产生摘要.Siddharthan和McKeown[27]将一组相同或相关主题的阿拉伯语文本翻译为英文,利用信息冗余纠正翻译误差,然后进行抽取式摘要.Wan等人[44]使用MT和MS方法[50]提取候选摘要,然后基于排序支持向量机(Ranking Support Vector Machine,Ranking SVM)[51]的top-k集成排序方法,对候选摘要集排序,选择排名靠前的摘要作为最终摘要,流程如图3所示.Ouyang等人[45]以{带噪的英文文本-无噪的英文摘要}样本对训练一个生成式MS模型——指针生成网络(Pointer-generator Networks)[18],进行CLS时,首先将源语言文本翻译为英语,再用该模型生成摘要,利用该模型的鲁棒性降低翻译误差的影响.
图3 候选摘要的提取和排序
上述研究在摘要时只考虑了目标语言信息,该信息对CLS能力的提升有限.为了解决该问题,研究者们开始同时利用源、目标语言的双语对齐信息来帮助提升CLS性能.Wan[30]针对摘要过程提出了两种基于图的抽取式摘要方法(SimFusion和CoRank).SimFusion方法计算中文句子相似度时,将对应的英文句子相似度线性融合,从而利用英文信息对中文句子排序.CoRank方法对英文句子和中文译句同时排序.两种方法分别将PageRank算法[52]和HITS算法[53]的思想融入了统一框架中.Boudin等人[47]首先将英语文本翻译为法语,然后利用SVM[54]回归方法根据双语特征预测每句话的翻译质量,并基于一种改进的PageRank算法[52]选择预测质量高的句子,最后将选定句子中的多余句子去除后组成摘要.受到基于短语的MT的启发,Yao等人[31]设计了一个基于双语短语对齐的句子评分函数为译句打分,还使用贪心算法获得可用于精确动态规划的最优子结构近似解,同时进行句子选择和压缩.Zhang等人[46]将源语言文本翻译为目标语言,然后从双语对齐文本中构建双语概念/事实池,将源端的谓词-参数结构(Predicate-argument Structures,PAS)的双语元素与整数线性规划算法[55]融合,生成摘要句.Pontes等人[48]提出一种法-英CLS框架,在单句和多句级别考虑了双语词汇块,使用Wan[30]对双语文档的联合分析来选择最相关的句子.
3.1.2 先摘要后翻译
“先摘要后翻译”指首先将源语言文本总结为中间文本,即源语言摘要,然后将中间文本翻译为目标语言摘要,流程如图2(b)所示.
Orasan和Chiorean[28]首先使用最大边际关联法(Maximal Marginal Relevance,MMR)[56]对罗马尼亚新闻进行摘要,然后使用MT服务eTranslator(1)https://www.etranslator.ro将结果翻译为英文.为了缓解MT结果质量低的问题,Wan等人[29]利用SVM预测英文句子的翻译质量,选择其中信息量大且翻译质量高的句子,通过谷歌翻译服务(2)https://cloud.google.com/translate翻译为中文从而组成摘要.
3.1.3 两类方法对比
“先翻译后摘要”方法在摘要时可以利用翻译过程得到源语言文本和对应目标语言文本的双语文本来增强摘要结果,但缺点是翻译整个文本会产生更多开销.“先摘要后翻译”方法仅在拥有源语言的摘要语料库时才可使用,若源语言为摘要语料的低资源语言,则难以构建可用的摘要系统.因此,“先翻译后摘要”方法通常比“先摘要后翻译”方法获得更好的性能[40].
3.2 端到端方法
虽然管道方法的思路简单直接,MT和MS的相关研究也相对成熟,但仍存在两个问题:1)误差传递问题,即前一过程的误差会传入后一过程;2)推理时存在延迟.由于机器学习和深度学习技术得到飞速发展与运用,端到端方法被提出以解决上述问题.该方法将翻译的语义等价转换过程和摘要的信息压缩过程统一至一个Seq2Seq模型中完成,涉及源语言文本、上下文向量以及目标语言摘要3种主要对象,优点是生成的摘要流畅性更高,并且对带噪文本输入的泛化性能高,缺点是需要大量样本.
3.2.1 间接学习方法
间接学习方法采用知识蒸馏中的教师-学生框架[57-59],以CLS相关的自然语言生成(Natural Language Generation,NLG)任务的模型为教师,教导学生(CLS模型)对其输出分布、隐含状态等有监督信号进行拟合,从而在无CLS样本的环境下间接学习CLS能力,流程如图4(a)所示.该类方法的显著优点是能够在零样本环境下进行CLS.
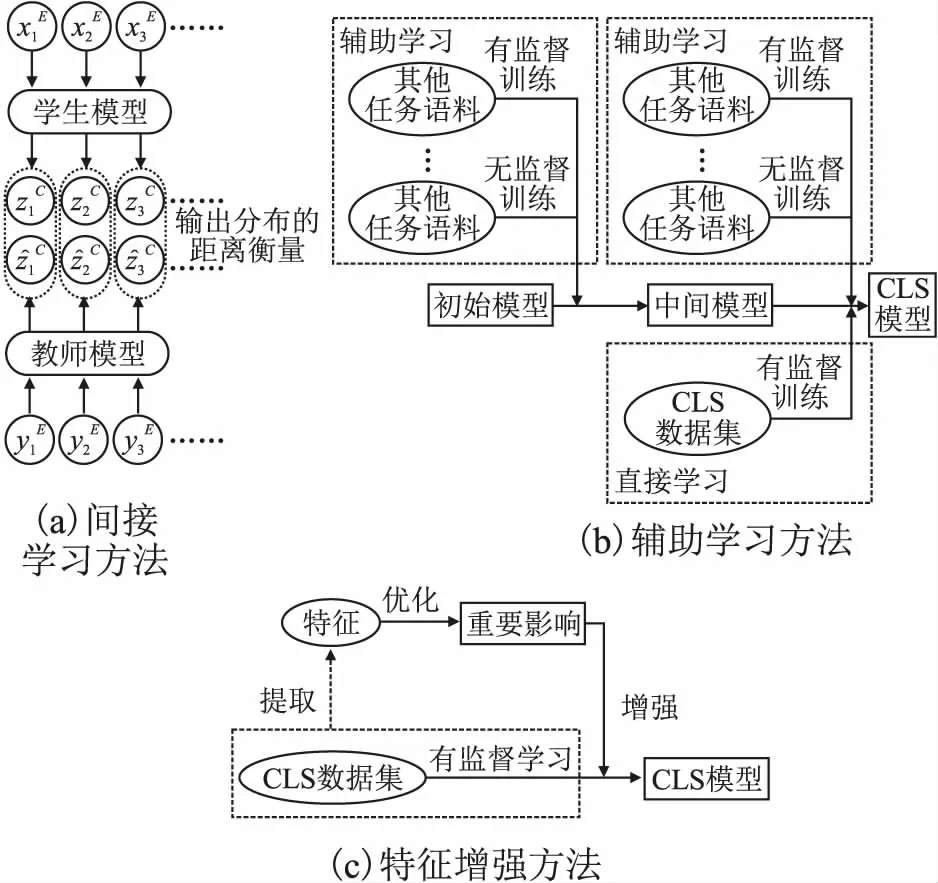
图4 端到端方法
Ayana等人[60]将基于双向GRU模型[61]的MS模型和MT模型作为教师,教导CLS模型拟合其输出分布,目标函数是词粒度的KL散度[62].随着深度学习的发展,Duan等人[63]将基于Transformer模型[32]的目标语言MS模型作为教师来教导CLS模型,以二者输出分布的交叉熵[64]与注意力权重的欧几里得距离的加权作为目标函数.
3.2.2 辅助学习方法
由于CLS数据集的稀缺,间接学习方法不直接训练CLS任务,所得模型的性能依赖于教师.相比于CLS样本直接提供的监督信号,教师由于自身存在误差,其监督信号的准确性和可靠性更低,故间接学习方法所得CLS模型的性能十分有限.近年来随着大规模CLS数据集的出现以及深度学习技术的迅速发展,研究者们能够直接训练CLS任务,从而避免上述问题.为了进一步提升性能,辅助学习方法在训练CLS任务时,将与之相关的其他任务作为辅助直接训练,流程如图4(b)所示.该类方法使用其他任务辅助CLS任务的训练,各任务间的训练策略和目标函数权重十分关键,优点是利用了其他任务的有用知识来提升模型的语义理解、跨语言对齐和文本生成能力.
Cao等人[65]进行了首个无监督的端到端CLS研究,分别训练源、目标语言的基于Transformer的MS模型以及跨语言映射器,将源语言MS模型的编码器、跨语言映射器和目标语言MS模型的解码器组成CLS模型.映射器在双语文本上通过生成对抗方式[66]训练,从而学习两种语言单语表征的同构性.该方法中源、目标语言的地位完全相等,训练时角色可交换.王剑等人[67]借鉴Cao等人[65]提出的框架进行汉-越CLS,使用半监督对抗学习在汉越双语词典上显式训练跨语言映射器.
上述研究在训练时的跨语言对齐是通过映射器显式完成的,仍未完全成为端到端模型.为解决该问题,研究者们进行了更深入的研究,使跨语言对齐通过解码器的编解码注意力(Encoder-decoder Attention)隐式完成.Zhu等人[23]提出首个端到端的神经网络CLS模型NCLS(Neural Cross-lingual Summarization).作者使用Transformer模型在MT、MS和CLS任务上进行多任务学习[68],训练时共享编码器但不共享解码器.不同任务的解码器相互独立会导致在捕获多个任务间的关系方面存在局限性.为解决该问题,Takase和Okazaki[69]给MT、MS样本添加具体任务标记,从而在MT、MS和CLS任务上共同训练Transformer.该框架共享了编、解码器,以任务标记控制解码器输出,拥有零样本CLS能力.Bai等人[70]将MS作为CLS的前提,训练共享编、解码器的Transformer生成MS输出和CLS输出的顺序拼接,增强了不同语言间的交互作用,隐含地涉及跨语言对齐、语义相似性以及不同语言摘要间的模式,促进知识从高资源语言向低资源语言转移.Bai等人[71]引入压缩率以统一MT和CLS数据集,并将压缩率编码到源文本表示向量中.Liang等人[72]使用共享编、解码器的条件变分自编码器(Conditional Variational Auto-Encoders,CVAE)[73]进行MT、MS和CLS任务的多任务学习,在局部层面构造两个潜在变量,分别用于翻译和摘要,在全局层面构造一个用于CLS的潜在变量.
受预训练模型的启发,为了从大规模无监督文本中学习一般语言知识并加以利用,Ladhak等人[74]先后在MT、CLS数据集上微调多语言预训练模型mBART[75]以进行CLS.Xu等人[76]首先对Transformer进行掩码语言模型(Masked Language Model,MLM)、去噪自编码器(Denoising Auto-encoder,DAE)、MS、跨语言掩码语言模型(Cross-Lingual Masked Language Model,CMLM)以及MT等5种无监督和有监督任务的多任务预训练,然后进行MS和CLS的多任务微调.预训练阶段通过海量无标签文本和特定任务的有标签文本来提高模型的语义理解、跨语对齐以及文本生成能力.Dou等人[77]首先进行MT、MS和CLS任务的多任务预训练,然后通过优化生成摘要和源语言参考摘要之间的双语语义相似度来提升CLS性能.Wang等人[78]提出mDIALBART模型,在预训练模型mBART-50上进行二次预训练,以更好地适应CLDS任务.
为了将间接学习方法和辅助学习方法结合,Nguyen和Luu[79]以教师、学生输出分布之间的Sinkhorn散度[80]与CLS任务目标函数的加权作为目标函数.
3.2.3 特征增强方法
辅助学习方法虽然借助了其他任务提升了CLS模型性能,但多种辅助任务的训练代价非常高.为了缓解该问题,特征增强方法对CLS过程的内部特征进行提取、优化,再将其作用于模型,增强模型的语义理解、跨语言对齐和文本生成能力,流程如图4(c)所示.该方法的优点是增强了CLS任务内部特征的影响,不依赖其他任务,缺点是对内部特征进行利用的算法的复杂度高.
Zhu等人[81]从源文本中选择关键词,通过概率双语词典获得其翻译分布,最后使用Transformer的输出分布和翻译分布共同产生摘要.该方法扩大了源文本关键词对生成最终摘要的影响.殷明明等人[82]在Transformer中加入了对比注意力机制.该注意力由Transformer内部的参数和权重计算得到,增加对目标语言参考摘要和源语言文本之间不相关信息的关注.该方法扩大了模型参数和权重对生成最终摘要的影响.Jiang等人[83]首先提取源语言文本的关键词、命名实体等关键线索,通过设计线索引导算法将源语言文本转化为文本图,然后构建一个图编码器和一个线索编码器分别编码文本图和关键线索,将图编码器和线索编码器的输出传入解码器不同的编解码注意力模块中以产生输出分布,最后与Zhu等人[81]一样,使用输出分布和翻译分布共同生成摘要.该方法扩大了关键线索对生成最终摘要的影响.
3.2.4 讨论
间接学习方法和辅助学习方法虽然都通过MT、MS等与CLS相关的任务来增强模型的CLS能力,但二者相关任务的角色作用存在不同.前者只利用教师模型提供的唯一的监督信号,使模型完全朝着相关任务的方向学习,而后者的相关任务为CLS模型提供辅助的监督信号,模型朝着相关任务和CLS任务的方向学习.特征增强方法通过挖掘模型在CLS训练过程中自身的重要特征,增强其影响,从而提高训练效果.
虽然间接学习方法完全依赖于教师模型,而且只会将有限的知识从教师转移到学生手中[84],辅助学习方法训练多种任务的成本太高,特征增强方法能够利用的特征有限且利用过程复杂度高,但是此3类方法几乎无交集.故为了合理利用每类方法优势的同时降低方法自身缺点带来的影响,后续研究应该考虑将任意两类方法甚至3类方法进行结合.
3.3 小 结
根据上述梳理总结,本文将各类方法的研究情况及其优缺点对比总结至表1.管道方法适用于CLS数据集稀缺的零样本或少样本环境,其面临的主要挑战是误差传递问题导致的性能损失;端到端方法适用于CLS样本充足的环境,其面临的主要挑战是高昂的CLS数据集获取成本和CLS系统训练成本.在“先翻译后摘要”方法的研究工作中,研究者们在摘要时选择了抽取式或生成式摘要,而在“先摘要后翻译”方法的研究工作中,研究者们均选择抽取式摘要.辅助学习方法的研究工作中,研究者们已经证明了预训练范式和多语言预训练模型适用于CLS.希望研究者们在后续研究中继续探索,将更多先进的多语言预训练模型结合到CLS中.端到端方法逐渐成为主流研究方向.这使得CLS与MT、生成式MS之间的联系愈发密切.除上述研究工作外,本文认为将NMT或生成式MS的算法模型迁移到CLS中,也是一种可靠且有研究价值的思路.NMT与CLS的关键差异是模型输出序列长度,故在迁移NMT方法时,需要重点关注如何对模型输出长度进行缩减.生成式MS与CLS的关键差异是处理语言的不同,故在迁移生成式MS方法时,需要重点关注如何将模型的处理范围从单语空间拓展到双语空间.
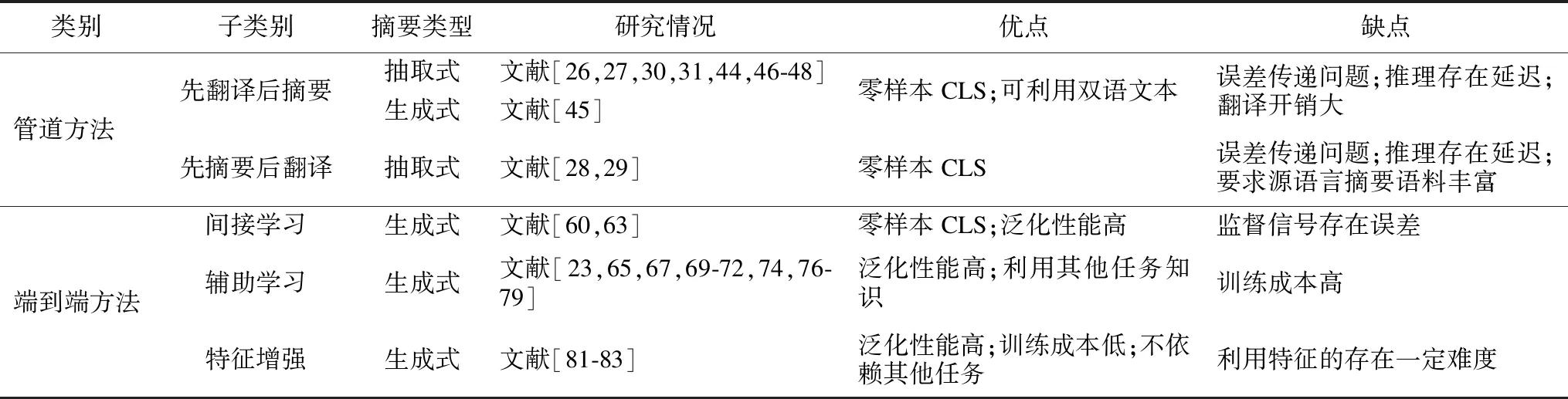
表1 CLS研究方法概述
在研究方法方面,Zhu等人[23]将CLS的研究方法简单划分为管道方法和端到端方法.Wang等人[40]将端到端方法进一步划分为了4种框架:多任务框架、知识蒸馏框架、资源增强框架以及预训练框架.多任务框架指使用CLS的相关任务(如MT和MS)与CLS任务一起训练统一的模型;知识蒸馏框架指在知识蒸馏框架下使用MS或MT教师模型来教导CLS学生模型;资源增强框架指利用额外的资源来丰富源语言文本信息,模型的输出分布取决于编码后的信息和丰富后的信息;预训练框架指将通用的预训练模型应用于CLS下游任务.Zhu等人[23]和Wang等人[40]的工作对CLS方法的类别划分十分准确合理,本文沿用了该分类方式.但本文不仅对CLS现有研究工作的梳理更为全面,而且以不同的逻辑对端到端方法进行了更详细的划分.本文的间接学习方法与Wang等人[40]的知识蒸馏框架有共通之处,但间接学习方法中不包含对CLS任务的直接训练,而知识蒸馏框架[40]使学生模型除了从教师模型的输出和隐藏状态中学习,还可以从CLS标签中学习.预训练任务能够使模型学习到对CLS有益的能力,本质上仍属于CLS的相关任务,只是相关性没有MT和MS任务那么明显和直接.故本文的辅助学习方法所指CLS相关任务,可以是有监督或无监督任务,也可以预训练或与CLS联合训练,进而从本质上统一了Wang等人[40]的多任务框架和预训练框架.本文的特征增强方法与Wang等人[40]的资源增强框架的划分标准不同,重点关注在CLS过程中对模型自身参数、权重的利用.
4 跨语言摘要数据集
本章将CLS数据集的构建方法归纳为收集法和转换法,并对研究工作中构建的数据集进行梳理和总结.
4.1 构建方法
4.1.1 收集法
收集法指人工或使用计算机从互联网等资源平台获取文本数据,并整理为{源语言文本-目标语言摘要}样本对的CLS数据集,流程如图5所示.

图5 收集法的示意图
4.1.2 转换法
转换法指利用相关任务现成数据集获得CLS数据集.根据数据源的不同,转换法还可分为基于翻译的转换法和基于摘要的转换法.
基于翻译的转换法将MS数据集转换为CLS数据集,流程见图6,具体步骤如下:
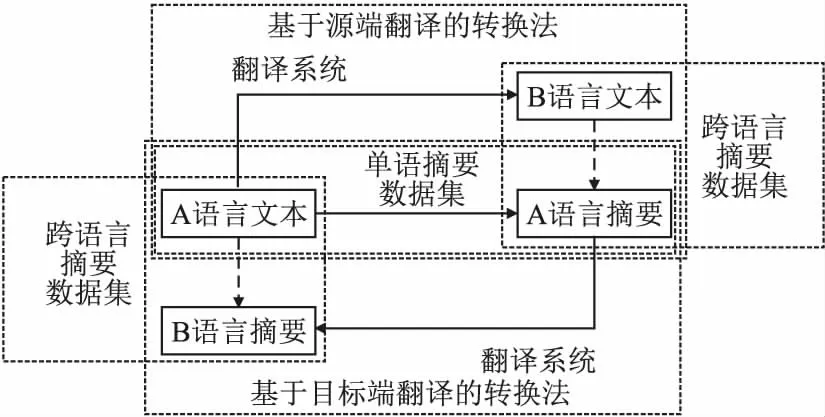
图6 基于翻译的转换法的示意图
1)使用MT系统(人工或计算机),对A语言MS数据集的文本(或摘要)进行翻译,得到B语言文本(或摘要);
2)与对应的A语言摘要(或文本)匹配,得到B语言文本-A语言摘要(或A语言文本-B语言摘要)样本对.
基于摘要的转换法将MT数据集转换为CLS数据集,流程见图7,具体步骤如下:
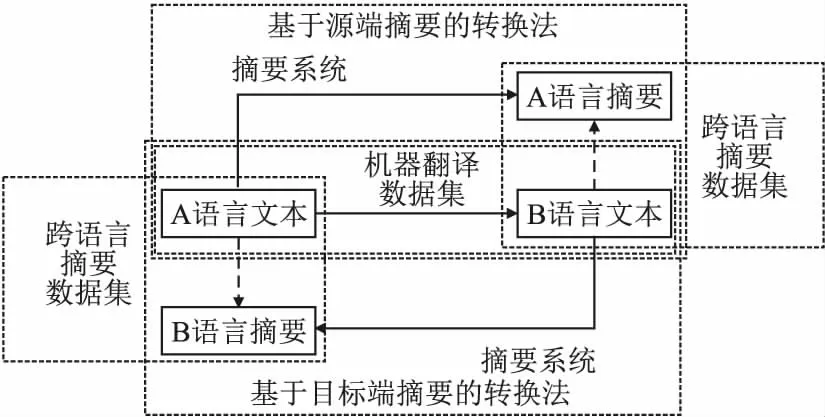
图7 基于摘要的转换法的示意图
1)使用MS系统(人工或计算机),对MT平行语料的A语言(或B语言)文本进行摘要,得到A语言(或B语言)摘要;
12https://github.com/harvardnlp/sent-summary
13https://www-nlpir.nist.gov/projects/duc/data/2003_data.html
14https://duc.nist.gov/duc2004/tasks.html
2)与对应的B语言(或A语言)文本匹配,得到B语言文本-A语言摘要(或A语言文本-B语言摘要)样本对.
4.2 数据集
近年来,研究者们通过上述两种方法构建了一些CLS数据集.本节对其进行详细梳理,基本情况如表2所示.目前,NCLS数据集的使用最为广泛,可视为本领域的基准集.Global Voices(3)https://forms.gle/gpkJDT6RJWHM1Ztz9是由Nguyen和Daume[85]采用收集法从Global Voices网站人工获得的多语种CLS数据集,包含gv-snippet数据集和gv-crowd数据集.gv-snippet数据集的源语言是英语,目标语言共有15种语言.gv-crowd数据集的源语言共有15种语言,目标语言是英语.WikiLingua(4)https://github.com/esdurmus/Wikilingua是由Ladhak等人[74]采用收集法从WikiHow网站获得的多语种CLS数据集,包含了18种语言.Fatima和Strube[86]采用收集法从Spektrum der Wissenschaft和维基百科中获得了一个数据集,其中包含英-德CLS数据集WSD(5)https://github.com/MehwishFatimah/wsd.WSD中包含了测试集来源于维基百科的W-CLS数据集和测试集来源于Spektrum der Wissenschaft并经过人工校正的S-CLS数据集.XWikis(6)https://github.com/lauhaide/clads是由Perez-Beltrachini和Lapata[87]采用收集法,通过将维基百科的导语和不同语言的相应正文配对而得到的多语种CLS数据集.CrossSum(7)https://github.com/csebuetnlp/CrossSum是Hasan等人[88]通过跨语言检索将多语种MS数据集XL-Sum[89]中不同语言的相同文章自动对齐而得到的多语种CLS数据集.XL-Sum中的文本-摘要对是从BBC网站中收集的.
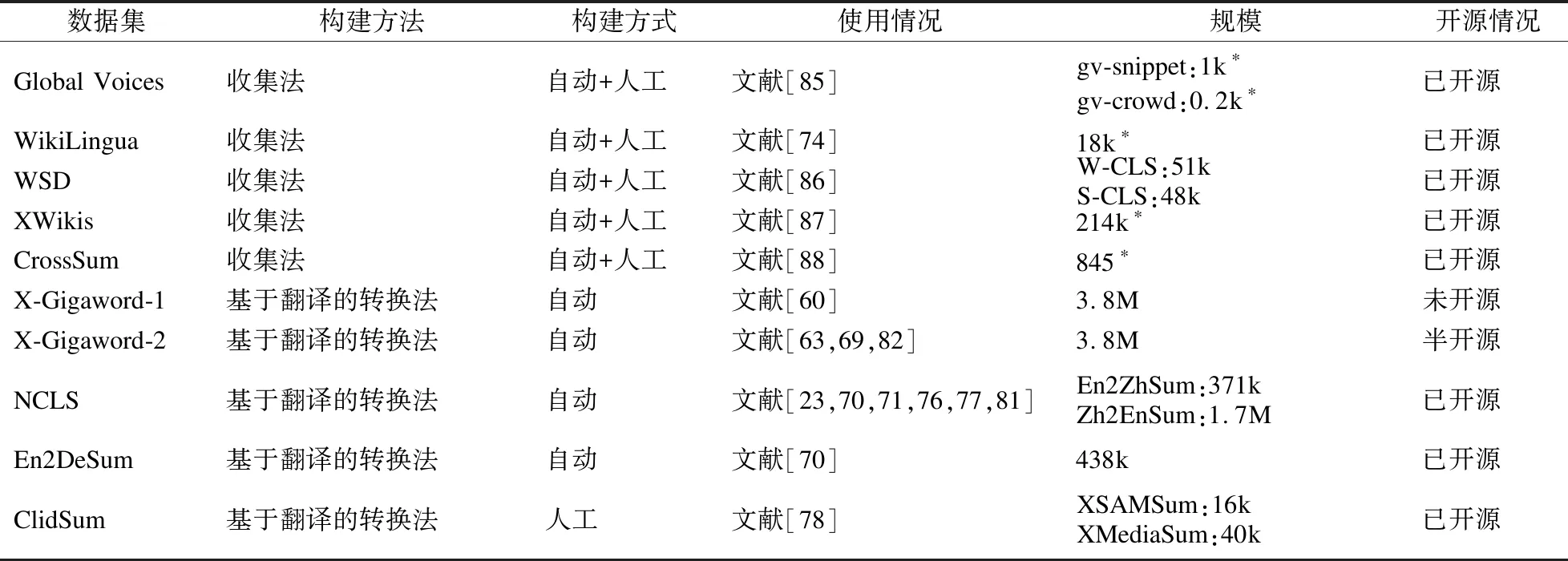
表2 CLS数据集基本情况
X-Gigaword-1是由Ayana等人[60]采用基于翻译的转换法,从英文语料Gigaword(8)https://catalog.ldc.upenn.edu/LDC2012T21,需付费申请.[90]和英文摘要数据集DUC[91]中构建的英-中句子摘要数据集,构建过程如表3所示.X-Gigaword-2(9)https://github.com/KelleyYin/Cross-lingual-Summarization是由Duan等人[63]采用基于翻译的转换法,从英文语料Gigaword和英文摘要数据集DUC中构建的中-英句子摘要数据集,构建过程如表4所示.NCLS(10)https://github.com/ZNLP/NCLS-Corpora是Zhu等人[23]采用基于翻译的转换法和RTT策略构建的CLS数据集,包含了英-中文本摘要数据集En2ZhSum和中-英句子摘要数据集Zh2EnSum及其人工校正测试集后的版本En2ZhSum*和Zh2EnSum*.其中,En2ZhSum来自CNN/Daily Mail数据集[92]和MSMO数据集[93],Zh2EnSum来自LCSTS数据集[94],基本信息如表5所示.En2DeSum(11)https://github.com/WoodenWhite/MCLAS是由Bai等人[70]采用基于翻译的转换法,通过机器翻译模型WMT′19 English-German Winner[95]将英文语料Gigaword(12)https://catalog.ldc.upenn.edu/LDC2011T07,付费申请翻译为德语而得到的英-德CLS数据集.ClidSum数据集(13)https://github.com/krystalan/ClidSum是Wang等人[78]采用基于翻译的转换法,分别将SAMSum数据集[96]和MediaSum数据集[97]的英文摘要人工翻译为汉语、德语而得到的CLDS数据集.
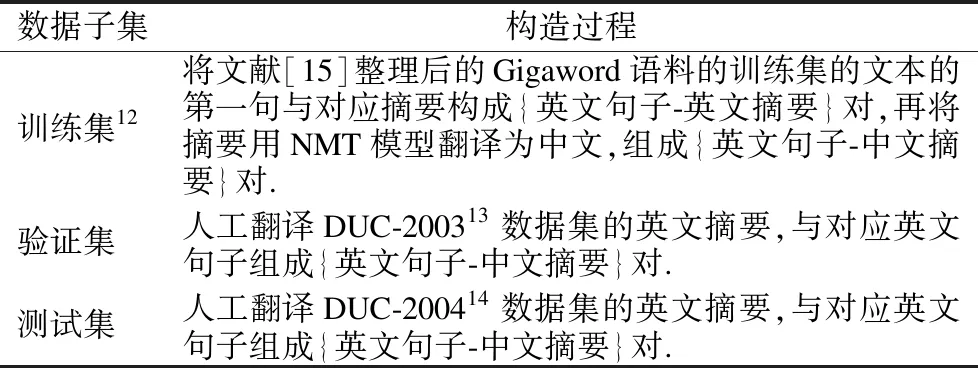
表3 X-Gigaword-1的构建过程
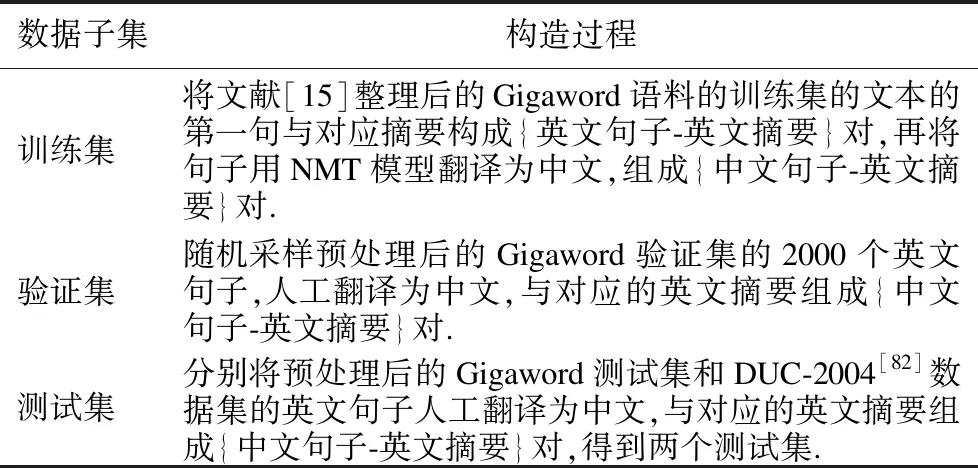
表4 X-Gigaword-2的构建过程
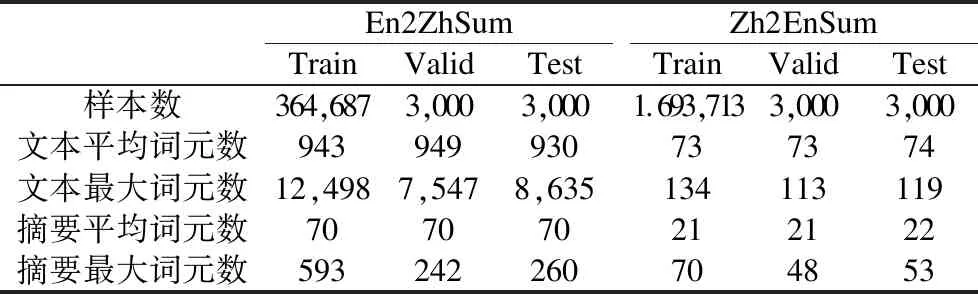
表5 NCLS统计信息
4.3 小结
在构建CLS数据集时,研究者需要在规模和质量之间进行权衡.收集法的优点是文本资源广泛,样本质量较高,缺点是构建成本高且规模一般较小.转换法的优点是利用现成数据集,降低了构建成本.缺点是严重依赖转换系统性能,此外,现成数据集一般规模较大,手动翻译或后期编辑所需的成本十分高昂.因此,一般使用机器学习模型进行自动转换,质量有限.收集法在实际工作中使用较少,相反,研究者们主要选择转换法.两类方法的优缺点对比见表6.

表6 数据集构建方法的优缺点
从转换法的步骤中可知,通过转换法构建源语言-目标语言CLS数据集,共有图8所示4种方案(由上至下为方案1~4).CLS、MT等条件文本生成(Conditional Text Generation)[98]任务对解码器的能力要求远高于编码器.编码器只需理解语义,无需考虑词元顺序,甚至可以遗漏部分信息,而解码器生成文本时必须逐字生成,需要考虑语序、语法等要素.MT的回译法[99]将目标语言文本y翻译回源语言文本x′,并用(x′,y)训练,使得仅编码器得到伪数据,保证解码器得到真实数据,避免对真实输出引入噪声.其作用是加强了解码器获得的信息,提升了生成质量,同时尽量不影响编码器的能力.方案1所得数据集的质量理论上优于方案2,因为翻译系统存在误差,翻译的文本越长,引入的误差越多.由于转换法与回译法的思路相似,所以转换法也应避免对输出文本引入噪声,但方案1、方案3和方案4都会对输出数据引入噪声.故方案2是相对最优的转换法方案,相当于CLS中的回译法,建议在未来研究中优先使用.

图8 不同途径的转换法
在数据集方面,Wang等人[40]根据数据源和构建过程将CLS数据集划分为合成数据集和多语种网站数据集两大类,并据此概括出构建CLS数据集的3种方法:1)手动翻译MS数据集;2)自动翻译MS数据集;3)自动收集多语种网站的文本和摘要.但本文对CLS数据集的构建方法进行了更系统地总结和进一步拓展,并对CLS数据集进行了更全面的整理.本文将CLS数据集的构建方法归纳为收集法和转换法.其中,收集法的定义既包含了Wang等人[40]的第3种方法,又包含了人工收集的方式;Wang等人[40]的前两种方法仅以MS数据集作为数据源,而本文的转换法还进行了扩展,根据MT、MS任务与CLS任务的密切关系,拓展出了以MT数据集作为数据源的构建方法.
5 跨语言摘要评价方法
CLS的评价目标旨在衡量参考摘要和生成摘要的相似性.这与MS、MT任务一致.本文将可用的CLS评价方法归纳为人工评价和自动化评价两大类,下面对其进行详细介绍.
5.1 人工评价
最直接有效的评价方法当属人工评价,即组织评价人员直接根据具体任务要求对生成摘要的特征如信息量、简洁性、流畅性、符合事实性以及忠于原文性等进行打分.
5.2 自动化评价
自动化评价指用某种评价指标对生成摘要的质量进行自动化地评价,又可分为内部评价和外部评价两类.
5.2.1 内部评价
内部评价指以参考摘要为基准评价生成摘要的质量,是一种直接的评价方式.生成摘要与参考摘要越吻合,质量越高.
(1)ROUGE
ROUGE是由Lin[100]提出的一组基于统计的ATS评价指标.其基本思想是通过统计参考摘要和生成摘要之间的n元语法(n-gram)数目,以计算相似度,从而衡量生成摘要质量.常用的ROUGE指标类型为ROUGE-1、ROUGE-2和ROUGE-L的F1分数,其中1、2和L分别代表1元语法、2元语法和最长公共子列(Longest Common Subsequence,LCS).
ROUGE最初可以通过ROUGE-1.5.5.perl脚本计算,如今Python的rouge-metric(14)https://github.com/li-plus/rouge-metric、pyrouge(15)https://pypi.python.org/pypi/pyrouge等库也对其进行了实现.
需要注意的是,原始的ROUGE指标只能评价英文.为了将其用于其他语言,研究者可以应用一些工具包,例如multi-lingual ROUGE(16)https://github.com/csebuetnlp/xl-sum/tree/master/multilingual_rouge_scoring、MLROUGE(17)https://github.com/dqwang122/MLROUGE等,或者根据语言特点对摘要进行预处理,例如评价中文摘要时,可将摘要按字符粒度划分词元,然后用空格符拼接,或者将中文词元转换为数字id等.
(2)BERTScore
BERTScore(18)https://github.com/Tiiiger/bert_score是由Zhang等人[101]提出的基于单语语义相似度的文本生成任务评价指标.将其应用于CLS的基本思想是使用预训练模型BERT[33]编码参考摘要和生成摘要,计算其表示向量的相似度,从而衡量生成摘要质量.具体计算过程如下:
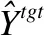
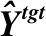
(2)
(3)
(4)
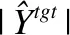
(3)MoverScore
MoverScore(19)https://github.com/AIPHES/emnlp19-moverscore是由Zhao等人[102]提出的基于单语语义相似度的文本生成任务评价指标.将其应用于CLS的基本思想是使用上下文词嵌入(Contextual Embedding)来编码参考摘要和生成摘要,计算其表示向量的距离,从而衡量生成摘要质量.具体计算过程如下:
Zhao等人还证明了可将BERTScore视为一种非优化的移动距离(Mover Distance),从而将BERTScore归纳为MoverScore的一种特例.为了便于使用,他们还将MoverScore指标的计算作为web服务提供(20)http://tiny.cc/vsqtbz.
(4)XSIM
XSIM是由Dou等人[77]提出的基于双语语义相似度的CLS评价指标.其基本思想是使用句子嵌入(Sentence Embedding)来编码目标语言生成摘要和源语言参考摘要,计算其表示向量的相似度,从而衡量生成摘要质量.具体计算过程如下: 1)采用一种句子嵌入学习方法[104],从MT平行语料中学习到跨语言句子嵌入;
2)使用该句子嵌入来编码目标语言生成摘要和源语言参考摘要;
3)计算二者表示向量的余弦相似度.
(5)PPL
困惑度(Perplexity,PPL)用于度量一个概率分布或概率模型预测样本的好坏程度,可以用来评估生成摘要的模型的好坏.
5.2.2 外部评价
外部评价指不使用参考摘要,以生成摘要代替原文本完成与原文本相关的任务(如文本检索、文本分类等),是一种间接的评价方式.能够提升任务性能的生成摘要被视为质量高.
5.3 评价方法的对比与分析
本文在表7中对上述评价方法的衡量角度、优缺点以及在CLS研究中的使用情况进行了对比,并对研究中使用过的5种评价指标的优缺点进行了详细分析.
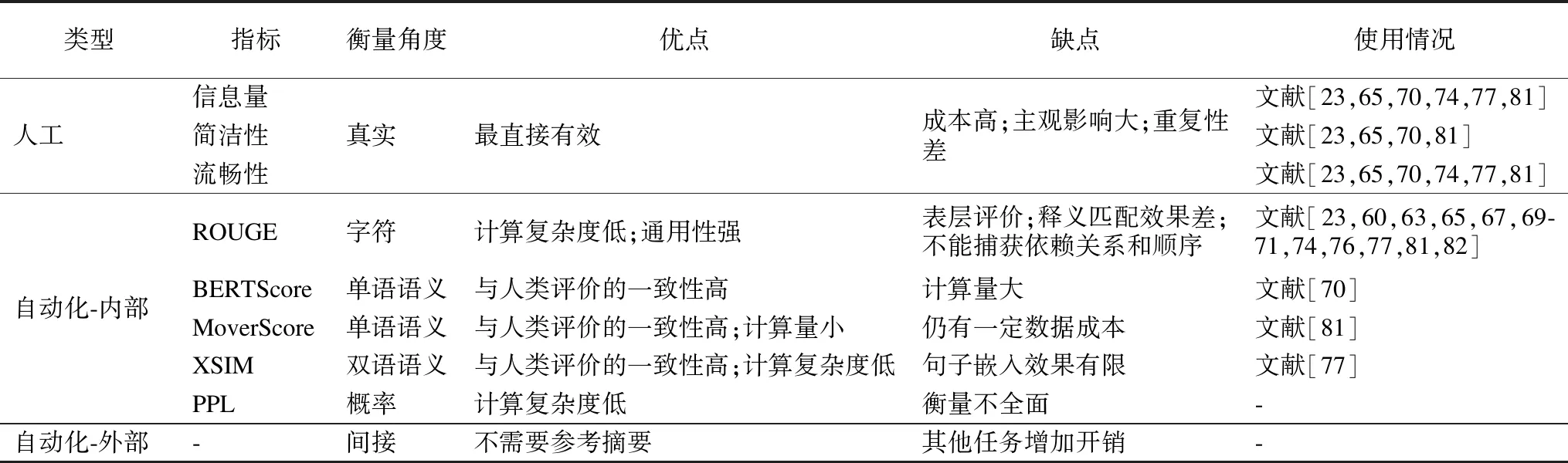
表7 CLS评价方法概述
尽管人工评价能很好地判定生成摘要质量,但仍存在3个显著缺点:1)人力成本高;2)评价人员主观影响大;3)评价结果难以复现.ROUGE的优点是计算简单、通用性强,缺点是只从字符层面进行评价,未涉及语义[105],无法覆盖语义相同但形式不同的表达.而且基于n-gram的指标还存在两个常见问题:1)不能很好地匹配释义;2)不能捕获遥远的依赖关系和顺序[106].BERTScore解决了上述的两个问题,优点是直接从语义层面衡量生成摘要质量,避免了仅从字符层面衡量可能导致的过拟合.其缺点是对单词进行一对一的硬对齐[102],计算量较大.MoverScore优于BERTScore,因为MoverScore对单词进行多对一的软对齐而不是硬对齐[102].MoverScore的另一优点是计算了从生成摘要的词频分布到参考摘要的词频分布的“移动距离”,能够更好地捕捉相似性.其缺点是仍需参考摘要作为标准(有监督CLS),数据成本较高.XSIM的优点是避免了构造参考摘要时可能引入的误差,缺点是句子嵌入的学习模型较为简单,效果存在上限.基于语义的评价指标更符合人类的评价标准,但前提是必须真实、准确地衡量语义.
5.4 小结
以ROUGE为代表的基于统计的评价指标仅能从字符形式(如语言、语法等)进行衡量,存在一定缺陷.虽然近年来已有研究者提出基于语义的评价指标从语义层面进行衡量,但基于统计的评价指标不可或缺.因为基于语义的评价指标只能进行语义度量,是一种潜在表示,所以仅用基于语义的评价指标无法评价生成摘要质量.而从以往研究中可知,只用基于统计的评价指标是可行的.故本文认为基于统计的评价指标与基于语义的评价指标的地位并不相等,基于语义的评价指标更应作为辅助来增强基于统计的评价指标的衡量效果.在未来的研究中,应该结合二者的优点从字符和语义两个层面共同评价生成摘要质量.由于目标函数与评价指标的密切关系,上述观点同样适用于CLS的目标函数.同时,本章列出的人工评价以及自动化评价中的外部评价等方法,虽然在现有研究中尚未被使用,但在后续研究中可以作为辅助手段,增强评价结果的可信度.
在评价指标方面,Wang等人[40]仅梳理了ROUGE、MoverScore、BERTScore这3种指标,而本文从人工/自动、内部/外部、基于字符/语义等不同方面对CLS评价方法进行了更系统、全面地梳理总结,并进行了对比分析.
6 未来研究方向
Wang等人[40]对CLS未来的发展方向进行了详细地讨论.与之不同的是,本文从现有研究中面临的亟需解决的问题出发,对CLS的下一步研究方向提出较为具体的方案.
前人的工作为CLS研究奠定了坚实的基础.但CLS数据集存在语言种类匮乏、样本质量不高等问题.同时,当前研究最常用的Transformer模型对语料质量和规模的要求很高但又存在性能瓶颈,可能导致训练效果不理想.这反映出当前研究面临的3个关键问题:1)数据集质量不高且规模不足的问题;2)基于数据集的文档级跨语言对齐效果不佳的问题;3)基于Transformer的系统训练效果不理想的问题.结合以上问题,本文提出了一些未来值得深入探索的研究点,希望给其他研究者带来启发.
6.1 数据集
CLS数据集提供最直接的跨语言对齐信息,其规模和质量对性能的影响十分明显.目前研究者们虽然已经构建了一些可用的数据集,但仍缺乏高质量且大规模的不同语种的CLS数据集.转换法是一种在低成本下获得大规模语料的有效方法,但由于转换系统的性能误差,该过程不可避免地会引入噪声.
为了基于转换法产生高质量且大规模的数据集,未来可以考虑从以下两个方向进行:1)研究数据集筛选算法,过滤掉转换法所得数据集中的低质量样本对;2)研究基于生成对抗网络[66,107]等技术的数据增强算法,对转换法结果进行数据增强[108],同时提高数据规模和质量.
6.2 跨语言对齐
由于对文本的语义理解(自然语言理解)和文本生成能力(NLG)的研究已较为成熟,所以跨语言对齐能力是在语料充足条件下影响性能的最关键因素.跨语言对齐方式可分为基于词、基于句子以及基于文档的对齐.目前大多数研究采用基于文档对齐的有监督学习方法,让模型自主学习源语言文本和目标语言摘要整体间的跨语言对齐信息.然而,由于源、目标端词元并不是一一对齐,以及模型的输入长度限制、自身学习能力等因素的影响,这种方式的对齐效果可能并不理想.
关键词元双语词典是一种源文本的关键词元在源语言和目标语言中的映射关系,蕴含着颗粒度更细且更为准确的基于词的跨语言对齐信息.为了更有效地跨语言对齐,未来可以考虑采用跨语言实体对齐算法[94]等方法构建关键词元双语词典,作为外部知识融入模型,促使源文本的关键词元在摘要中出现,确保生成关键信息.
6.3 模型框架
Transformer模型与预训练语言模型相比,存在一定性能上限.这是限制CLS性能的一个主要原因.此外,常用的交叉熵目标函数仅表面地学习参考摘要字符形式的监督信息,没有有效利用更深层、抽象的语义信息,容易导致刻板的学习结果.
海量文本促进了预训练语言模型的产生.预训练语言模型是在大量无监督文本上采用自监督任务训练的[109].近年来,预训练语言模型的出现使多项NLP任务取得了突破[34-39].Lample和Conneau[110]以及Chi等人[111]已经证明预训练-微调范式对跨语言学习的有效性.Ladhak[74]等人首次利用预训练语言模型进行CLS.此外,语义相似度能够计算文本在语义层面的相似性,从语义上反映生成摘要与参考摘要的匹配程度.语义相似性度量通常是完全可微分的,因此可以将语义监督信息融入训练过程,从更深层、抽象的语义层面减少生成摘要与参考摘要间的差异.为了利用更先进的Seq2Seq模型和深度学习技术以及优化训练过程,未来可以考虑用多语言预训练模型作为基本框架,充分利用其强大的语义理解、跨语言对齐和文本生成能力.同时,在微调中融入语义相似度,同时从具象的字符形式和抽象的语义形式为模型提供有监督信息,从而提高模型性能.
6.4 评价指标
ROUGE能够从具象的字符形式衡量文本相似性,但忽略了对抽象的语义相似性的度量.为了在评价时考虑文本语义的匹配程度,未来可以考虑设计一个综合评价指标,既计算基于表层字符形式的ROUGE得分,又提出特定算法计算基于深层语义的相似度得分,加权得到最终得分,作为对生成摘要质量的全面衡量.
7 总 结
近年来,深度学习取得的巨大成功使自动文本摘要研究得以高速发展.跨语言摘要作为自动文本摘要的拓展研究领域,也随之快速发展.跨语言摘要属于自然语言处理领域的自然语言生成任务,其社会价值使其在自然语言处理领域中占据重要的地位,是一个极具研究价值的新兴课题.其研究成果不仅可以推广到跨语言舆情分析、跨境电商决策、内容推荐等应用场景,还可以迁移到自然语言处理的机器翻译、情感分析等其他研究领域.从整体发展趋势上看,跨语言摘要研究正从抽取式转向生成式,从翻译和摘要过程分离的管道方法转向两个过程聚合的端到端方法.从结果上看,端到端方法的摘要质量更好,而且模型泛化性能更强.虽然该方法在模型框架、目标函数、可解释性等方面还存在不足,但是必将成为跨语言摘要研究未来的主流方向.
跨语言摘要是一个兼具理论性和实践性的多学科交叉研究课题(社会学、语言学、统计学、计算机科学等),在大数据时代和全球化背景下充满了机遇与挑战,相信必定会吸引更多优秀研究者的关注和研究.
猜你喜欢
中学生数理化·八年级物理人教版(2022年6期)2022-06-05
中学生数理化·八年级物理人教版(2021年6期)2021-11-22
开放教育研究(2020年2期)2020-03-31
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
现代语文(2016年21期)2016-05-25
中学课程辅导·教师通讯(2015年14期)2015-09-29
考试周刊(2015年36期)2015-09-10
大连民族大学学报(2015年2期)2015-02-27
外语学刊(2011年1期)2011-01-22
