
基于多模态的急性肾衰竭预测模型
2023-07-30 13:30邓未,周昉
华东师范大学学报(自然科学版) 2023年4期
邓 未,周 昉
(华东师范大学 数据科学与工程学院,上海 200062)
0 引言
急性肾衰竭(acute kidney injury,AKI)是一种经常发生于重症监护室(intensive care units,ICU)住院病人的疾病.它通常作为其他疾病的并发症,使患者的病情更加复杂.据报道每年约1 300 万人发生AKI(其中发展中国家的患者占85.0%),约170 万人死于AKI 及其并发症,全球成人住院患者急性肾损伤的发生率高达21.6%[1].因此,及早发现AKI 潜在患者可以帮助医生对其给予及时的医疗干预,减少医院医疗资源的消耗,降低AKI 的发病率和死亡率.
随着电子健康病历的不断推广,越来越多的AKI 预测模型依靠电子健康病历来预测患者潜在的健康风险[2-5].电子健康病历包含了患者的静态数据和动态数据.静态数据是指患者的性别、年龄等人口统计学数据和被医生诊断的疾病数据.动态数据是指患者入院后24 h 内的人体生理指标数据(如血压、体温等指标).
因此,如何利用静态数据和动态数据去捕捉患者的健康状态是一件棘手的事情,主要存在以下两个方面的问题.
(1)如何解决人体生理指标数据中存在的稀疏性和不规则性问题.医护人员往往不能以固定的周期去记录每项生理指标,这是因为不同的指标有不同的检测频率.例如,患者的心率指标可以每小时被记录一次,而血糖指标在同一天中可能被采集7 次,分别是三餐前、三餐后2 h 和睡前的血糖值.这导致了不同的生理指标可能在不同的时间点存在缺失记录,并且数据采集的时间间隔也不一定相同.此外,不同疾病的患者在相同的生理指标上可能存在不同的检测频率,例如,糖尿病患者会比其他疾病患者更频繁的血糖检测.通过分析指标的检测频率变化有助于模型更准确地捕获患者的健康状态.然而,大多数AKI 预测模型没有考虑数据中的稀疏性和不规则性问题,只是将患者人体生理指标数据聚合后输入模型[2-5].虽然解决了数据中存在的稀疏性和不规则性问题,但是忽略了数据中存在的时序性特点,导致不能准确地捕捉各项生理指标的数值变化和检测频率变化.对于患者健康风险预测模型来说,大多数模型忽略了数据的稀疏性和不规则性问题[6-9],少数模型考虑到生理指标的采样间隔,但仍用均值或最近邻值填充缺失值,阻碍了模型对于缺失信息的学习[10-11].
(2)如何解决多模态数据问题.电子健康病历包含了患者人口统计学数据、疾病数据和人体生理指标数据.不同的模态数据存在不同的数据形式,例如,人体生理指标数据是动态的时序数据,而疾病数据和人口统计学数据是静态的检测数据.此外,不同模态的数据具有关联性,例如,糖尿病和血糖指标具有很强的关联性.因此,既要考虑各个模态的数据特点,捕捉每个模态对于患者健康风险的关键信息,又要考虑各个模态的相关性,各个模态互相学习以生成更好的患者表征.但是,目前的AKI 预测模型[2-5]只是简单将多模态数据特征拼接后输入模型中,忽略了各模态的数据特点和模态之间的相关性.
为了解决以上问题,本文提出了基于多模态的急性肾衰竭预测模型(multimodal disease prediction model,MUDIP).本文所提出的模型分为两个部分: ①多模态数据的处理.对于人体生理指标数据,MUDIP 中的基于掩码和时间差的LSTM 网络(mask and time span LSTM,MT-LSTM)对各个生理指标单独建模,学习指标的缺失信息和时间间隔,捕获生理指标的数值变化和检测频率变化,消除由人体生理指标数据稀疏性和不规则性导致的模型性能上的限制.而对于人口统计学数据和疾病数据,MUDIP 通过全连接层分别捕获两个模态的特征.② 多模态数据的融合.MUDIP 引入了多头自注意力机制交互学习各个模态的表征[12].多头自注意力机制可以提取各个表征之间的相互依赖关系,并让每个表征从其他表征中挖掘自身潜在的关键信息.将重构后的所有表征融合,以获得患者的健康风险表征.
本文的结论总结如下.
(1)提出了一个基于多模态的急性肾衰竭预测模型(MUDIP).该模型能通过患者人口统计学数据、疾病数据和人体生理指标数据等多模态数据预测患者潜在的健康风险.多模态数据可以帮助模型提取更加全面的患者健康信息,提高模型的预测能力.
(2)设计了基于掩码和时间差的LSTM 网络(MT-LSTM),解决了人体生理指标数据中存在的稀疏性和不规则性问题.MT-LSTM 能学习生理指标缺失信息和时间间隔,并捕获各指标的数值变化和检测频率变化.
(3)引入多头自注意力机制,促进了各模态表征的相互学习.多头自注意力机制能提取各个表征之间的相互依赖关系,并让每个表征从其他表征中挖掘自身潜在的关键信息.
(4)在真实的数据集上进行了AKI 预测问题和死亡风险预测问题,实验结果证明了MUDIP 的有效性和合理性.
1 相关工作
1.1 AKI 预测相关工作
鉴于AKI 预测的重要性,目前有大量的研究致力于通过电子健康病历来判断患者是否患AKI.主流的方法是采取均值、最大值和最小值等统计值聚合动态的人体生理指标数据,通过多模态数据并使用LR(logistic regression),RF(random forest)和XGBoost(extreme gradient boosting)等经典的机器学习模型去预测患者AKI 风险[2-5].
这些模型存在以下两点的局限性: 一是通过统计的方法来聚合患者的人体生理指标数据,这种方法虽然处理了数据中存在的稀疏性和不规则性问题,但是忽略了数据中存在的时序性特点.人体生理指标数据反映了患者住院期间的健康状态,根据生理指标的变化有助于模型判断患者的健康状态.二是没有考虑模态融合,只是简单将所有模态数据合并输入模型中,忽视了模态之间的相关性.在本文中,MUDIP 不仅可以捕获人体生理指标数据存在的时序性特点,还引入了多头自注意力机制学习各模态表征之间的相互依赖关系.
1.2 基于时序数据的健康风险预测相关工作
近年来,随着基于深度学习方法的不断发展,越来越多的研究通过人体生理指标数据预测患者的健康风险,并取得很好的效果.鉴于优秀的时序性捕获能力,RNN(recurrent neural networks)通常被应用于时序数据.其中,GRU(gated recurrent unit)网络和LSTM 网络是被应用最广的两种基于RNN 网络变体.
一些工作在基于RNN 网络的基础上提出了基于时序数据的健康风险预测模型[6-9].文献[7-8]在RNN 网络基础上引入注意力机制学习患者每次就诊的权重.Baytas 等[6]和Gao 等[9]通过改造LSTM 网络中的细胞状态捕获短期历史信息和长期历史信息.总的来说,上述研究虽然在患者健康风险预测问题上取得良好效果,但是都忽视了人体生理指标数据中存在的稀疏性和不规则性问题[6-9].
目前一些研究考虑到了人体生理指标数据存在的稀疏性和不规则性问题[10-11,13],Ren 等[13]考虑了通过预训练的方法提升模型对数据稀疏性和不规则性问题的鲁棒性.Che 等[10]和Zheng 等[11]发现了患者不仅存在不定期的就医记录,同时每次就医不一定会检测所有生理指标.这两项研究都通过将每个生理指标相邻时间差作为特征对历史信息进行衰竭[10-11],并考虑最近邻值或均值填充缺失值,然而这种做法仍存在一些局限性.一是将各生理指标的时间间隔信息作为特征输入模型,没有考虑到不同的指标对于时间间隔的影响是不一样的.二是采用缺失值填充的方法,阻碍了模型对于缺失信息的学习.MUDIP 对各个生理指标单独建模从而减少指标之间相互影响,学习生理指标缺失信息和时间间隔,捕获指标的数值变化和检测频率变化.
2 模型
2.1 问题定义
本文所研究的问题是根据患者入院后24 h 内的电子健康病历数据,预测患者入院后第24 小时到第72 小时内是否存在以下健康风险:
2.2 模型描述
图1 展示了本文所提出的MUDIP 框架图.MUDIP 分为两部分: 多模态数据表征学习和多模态表征融合.
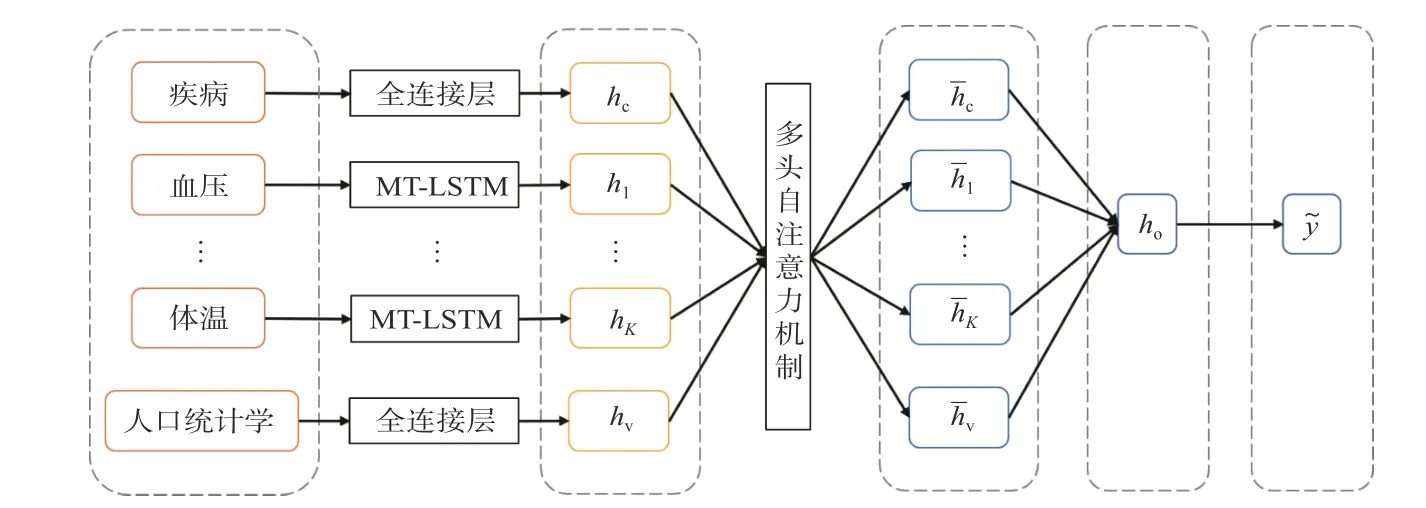
图1 MUDIP 框架图Fig.1 The frame diagram of MUDIP
(1)多模态数据表征学习.不同模态数据具有不同的数据特点,MUDIP 根据不同模态数据特点分别建模.考虑到人体生理指标数据存在的稀疏性和不规则性问题,将每个生理指标独立建模,并通过基于掩码和时间差的LSTM 网络(MT-LSTM)提取人体生理指标数据表征矩阵Mx=(h1,h2,···,hK) .考虑到人口统计学不同类型的特征和疾病之间的关联性,采用全连接层提取人口统计学表征hv和疾病表征hc.
(2)多模态表征融合.MUDIP 引入多头自注意力机制促进每个人体生理指标表征、人口统计学表征和疾病表征之间的相互学习,得到重构后的表征矩阵,级联重构后的表征矩阵得到患者健康风险表征ho[12].模型通过患者健康风险表征ho判断患者未来是否存在健康风险
2.3 多模态数据表征学习
2.3.1 人体生理指标表征的学习
人体生理指标数据反映了患者24 h 内的健康状态变化,不同的生理指标具有不同的健康风险信息.例如,一个患者的血压测量值高于正常范围就有可能患有高血压.此外,患者的人体生理指标数据也存在不规则性和稀疏性等问题.针对这些问题,本文设计了基于掩码和时间差的LSTM 网络(MTLSTM).
将患者的每个生理指标序列独立看待成不同的时间序列,并对其分别建模.在医学中,每个生理指标序列有独特的信息,通过独立建模的方式可以捕捉指标隐含的患者健康状态变化,减少不同生理指标之间的相互干扰.
由于人体生理指标数据存在稀疏性问题,缺失标记M作为掩码被纳入MT-LSTM 网络中以控制细胞状态和隐状态的更新.对于t时刻的第k个指标,当mt,k=1 时才允许当前时刻细胞状态ct,k和当前时刻的隐状态ht,k更新;当mt,k=0 时当前时刻细胞状态ct,k和当前时刻的隐状态ht,k仍然继承上一时刻细胞状态ct-1,k和上一时刻的隐状态ht-1,k.
LSTM 网络在时序数据中有很强的分类能力,但是其隐含了一个假设,即时间序列记录之间的时间间隔均匀分布.然而在真实生活中,患者的每项指标很难保证以相同的时间间隔来记录.此外,数据采集的时间间隔蕴含着患者潜在信息,例如,如果医生认为患者患糖尿病的风险较低,那么会减少患者血糖的测量次数,导致血糖连续记录之间的时间间隔更长.
因此时间间隔标记Δ被纳入MT-LSTM 网络中,使MT-LSTM 网络能学习生理指标序列的时间间隔.受T-LSTM 模型[6]启发,根据时间间隔标记Δt,k对上一时刻细胞状态ct-1,k进行折扣.首先通过全连接层提取细胞状态的短期记忆.然后考虑到每个人体生理指标有独立的医学信息,每个生理指标受到时间间隔的影响并不相同,通过全连接层去学习每个指标的时间间隔有助于找到合适的短期记忆衰减程度.最后根据衰减后细胞状态的短期记忆对上一时刻细胞状态ct-1,k进行折扣.
综上所述,MT-LSTM 网络公式为
2.3.2 人口统计学表征和疾病表征的学习
患者的人口统计学数据含有两种不同类型的数据: 一种是年龄和身高等数值类型数据;另一种是基于one-hot 向量表示的性别和种族数据.本文通过全连接层学习人口统计学数据v提取出患者人口统计学表征hv,公式为
式中:Wv是全连接层的权重;bv是一个偏置项.
疾病数据是医生对患者健康状态的经验判断,是判断患者健康状态的重要依据.疾病数据含有丰富的疾病关联信息,不同的疾病组合所蕴含的患者健康状态是不同的.患者的疾病数据由multihot 向量c表示,本文通过全连接层捕获各个疾病之间的关联,挖掘患者疾病数据的潜在信息.通过这种方式,得到患者的疾病信息矩阵Mc,公式为
式中:Wm是全连接层的权重.
考虑到不是所有的疾病组合信息都是重要的,因此使用MaxPooling 的方式去捕获疾病信息矩阵每一维最重要的信息,得到患者疾病信息向量.本文采用全连接层学习患者疾病信息向量,生成患者的疾病表征hc,公式为
式中:Wc是全连接层的权重;bc是一个偏置项.
2.4 多模态表征融合
基于2.3 节的多模态数据表征学习工作,获得了患者人体生理指标数据表征矩阵Mx=(h1,h2,···,hK),人口统计学数据表征hv和疾病表征hc.根据患者多模态表征,构造多模态矩阵Mh=(h1,h2,···,hK,hv,hc) .MUDIP 引入了多头自注意力机制[12](记为FM)提取各个表征之间的相互依赖关系,促进每个表征之间的相互学习.每个表征都捕获了预测患者健康风险的重要信息,表征之间的相互学习有助于挖掘其他表征的潜在信息,以此来增强自身表征对于健康风险预测的能力.经过多头自注意力机制,得到重构后的多模态矩阵Mh,公式为
式中:Wy是全连接层的权重;by是一个偏置项.
二分类问题通常使用交叉熵函数来作为模型的损失函数L,公式为
3 实 验
3.1 数据集和数据预处理
MIMIC-Ⅲ[14]是一个大型的综合性临床数据库,该数据库整合了波士顿贝斯以色列女执事医疗中心46 000 多名患者的ICU 住院数据.参考Wang 等[15]提出的数据预处理方法,本文提取了3 种模态的数据.对于人体生理指标数据,本文参考了文献[2-4]的数据预处理方法并提取了44 个可能与AKI 有关的指标,并保留了每个患者入院后24 h 内的检测记录.对于患者疾病数据,本文提取了由ICD-9 编码组成的患者疾病数据.ICD-9 编码具有层次结构.为了避免信息过载,参考了Qiao 等[16]的数据预处理方法,本文根据ICD-9 编码的前3 位数字提取了1 070 个疾病类.最后本文提取了患者年龄、性别、身高等12 个人口统计学记录.
对于AKI 标签,本文根据KDIGO[17]定义识别AKI 患者.KDIGO 定义判断患者患AKI 的标准:48 h 内SCr(serum creatinine)增加不少于 0.3 mg/dL 或者7 d 内SCr 与最低值相比增加不低于50%.因此,本文将符合上述定义的患者住院记录标记为具有AKI 风险的住院记录.而对于死亡标签,本文将患者入院后第24 小时到第72 小时内死亡的患者住院记录标记为具有死亡风险的住院记录.
为了减少干扰,根据Gong 等[2]和Zimmerman 等[4]的数据预处理方法在数据集中排除了一些特殊患者.例如,本文排除了年龄小于18 岁、ICU 住院时间短于1 d、入院SCr 高于 4 mg/dL、ICU 前24 h无SCr 记录、前24 h 发生AKI 和做了肾透析的患者.
最后,30 133 例ICU 住院记录被纳入研究,其中5 197 例ICU 住院记录为AKI 记录,占总数的17%,3 048 例ICU 住院记录为死亡记录,占总数10%.本文按照70∶15∶15 的比例将所构建的数据集随机分成训练集、验证集和测试集,并在验证集上确定模型的最佳参数,在测试集上报告模型性能.
3.2 评价指标
由于AKI 预测问题和死亡风险预测问题都是经典的二分类问题,因此本文采用常用于二分类任务的评价指标,即准确率(记为A),召回率(记为R),精确率(记为P),F1分数(记为F1)和AUC(area under curve).令:nTP表示正类样本预测为正类的数量,nFP表示正类样本预测为负类的数量,nFN表示负类样本预测为正类的数量,nTN表示负类样本预测为负类的数量.准确率、召回率、精确率、F1分数的计算公式分别为
AUC 指标是ROC(receiver operating characteristic curve)曲线下方与坐标轴围成的面积,而ROC 曲线是根据一系列不同的二分类方式,以假正率为横坐标,真正率为纵坐标绘制的曲线.其中假正率为实际标签为负类的样本被预测错误占样本总数的比例,真正率为实际标签为正类的样本被预测正确占样本总数的比例.
3.3 对比模型
为了证明本文所提出模型的有效性和优越性,MUDIP 将和被应用于AKI 预测问题的模型,如LR,RF 和XGBoost 等模型进行对比,同时MUDIP 也和被应用于患者健康风险预测问题的模型,如GRU,Dipole(diagnosis prediction model),StageNet(stage-aware neural network model),ConCare(capturing the healthcare context)等模型进行对比.最后MUDIP 比较了同样考虑了人体生理指标数据稀疏性和不规则性问题的GRU-D(deep learning model based on GRU),FLTD(feature-level time decay model)和RAPT(represent attention by pre-training time-aware transformer)模型.下面对这些模型进行简单介绍.
LR 是一种流行的线性回归模型,常用于数据挖掘领域的分类任务.
RF 是一种基于Bagging 的集成学习方法,它通过组合多个弱分类器克服了单个决策树的过度拟合问题,提高了模型的泛化能力.
XGBoost 是一种梯度增强树算法.梯度提升是一种有监督的学习算法,它试图通过组合一组更简单、更弱的模型的估计值来准确预测目标变量.
GRU 是LSTM 网络的一种效果很好的变体,比LSTM 网络的结构和计算更加简单.
Dipole[8]是在双向RNN 网络的基础上,通过注意力机制对每一个时间步分配一个注意权重.
StageNet[9]是一种基于LSTM 网络的改进模型,通过对细胞状态的修改使模型可以区分细胞状态的短期进展信息和长期进展信息.
ConCare[7]采用GRU 网络和注意力机制对每个生理指标进行训练.
GRU-D[10]是一种基于GRU 网络的改进模型,引入了生理指标是否缺失作为输入特征,并捕获特征级时间差对历史信息和缺失填充值进行衰减.
FLTD[11]是一种基于GRU 网络的改进模型,引入特征级时间差特征作为权重对GRU 网络的更新门进行修改.
RAPT[13]是一种采用预训练方法和基于时间感知注意力机制的模型.
根据Gong 等[2]的数据预处理方法,本文提取了每个生理指标的第一个值,最后一个值,最小值、最大值、均值和斜率作为LR、RF 和XGBoost 等模型的输入;而对于其他的基线模型,根据Zheng 等[11]的数据预处理方法,本文使用最近邻值去填充人体生理指标中缺失的数据.
3.4 实验环境和实验参数
本文实验的操作系统平台为CentOS 7.5 版本.硬件环境为2 个Intel Xeon Gold 6240R 处理器,每个处理器为24 核2.40 GHz 主频,以及4 块NVIDIA Tesla V100 显卡,每块显卡的显存容量为32 GB.所有的机器学习算法基于Scikit−Learn 来实现,所有的深度学习算法基于Pytorch 来实现.
本文使用Adam 算法优化所有深度学习模型,min-batch 大小设置为196,学习率设置为0.001,dropout 设置为0.5.为了公平地比较不同的模型,本文对数据进行了标准化操作,并采用网格搜索策略对模型的超参数进行调优.每个模型都进行了5 次随机运行实验,并报告了测试性能的平均值和标准差(standard deviation,SD).
3.5 实验结果
3.5.1 人体生理指标数据对比实验
表1 和表2 分别展示了各个模型基于人体生理指标数据在AKI 预测问题上和在死亡风险预测问题上的平均结果,括号内的值为标准差.显然,MUDIP 和其他模型相比取得了最好的效果.在AUC上,MUDIP 在两个问题上都优于所有基线模型.这展示了即使在类不平衡的情况下,MUDIP 也能展现较好的分类能力.

表1 基于人体生理指标数据在AKI 预测问题上的平均结果Tab.1 Mean results on AKI prediction based on physiological variable data
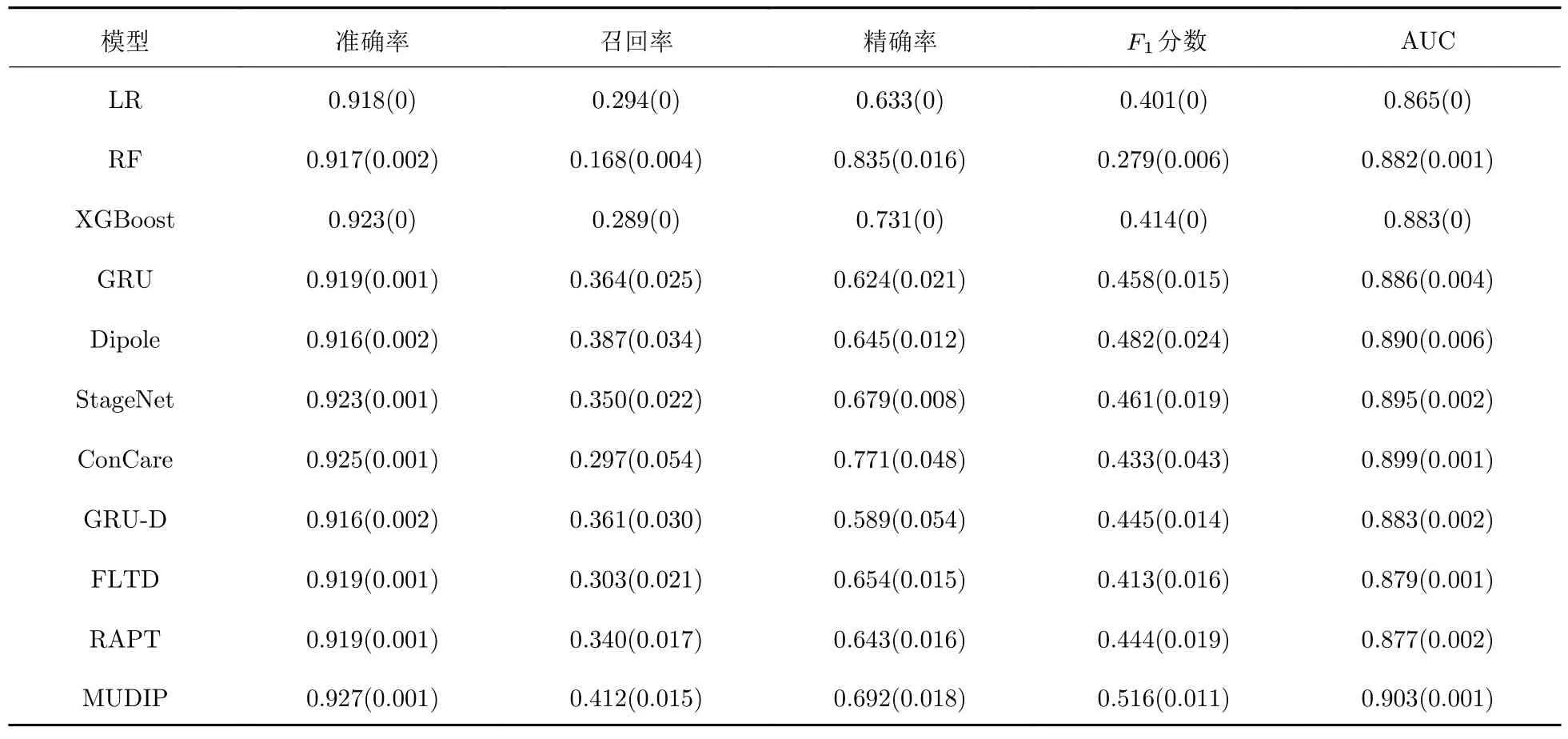
表2 基于人体生理指标数据在死亡风险预测问题上的平均结果Tab.2 Mean results on mortality risk prediction based on physiological variable data
相较于其他4 个评价指标,召回率是最重要的.因为预防疾病的成本总低于治疗疾病的成本,模型具有越高的召回率就越能帮助医生更早发现患者的病情.在召回率上,MUDIP 也是所有基线模型中最高的.在AKI 预测问题上,MUDIP 召回率达到0.275,比模型FLTD 的召回率高.在死亡风险预测问题上,MUDIP 召回率达到0.412,比模型Dipole 的召回率更高.在AKI 预测问题上和在死亡风险预测问题上MUDIP 的F1分数也是最高的,体现了本文所提出模型具有良好的预测能力.
对于LR、RF 和XGBoost 等模型,这些模型在AKI 预测问题上和在死亡风险预测问题上的表现都比MUDIP 更差一些.这是因为它们聚合的方法处理动态的人体生理指标数据,忽略了数据具有时序性的特点,很难捕捉各项生理指标的时序变化.而MUDIP 考虑了生理指标的时序性,因此能产生更好的效果.
对于GRU,Dipole,StageNet 和ConCare 等模型,这些模型在AKI 预测问题上和在死亡风险预测问题上的表现也差于MUDIP.这是因为通过最近邻值填充缺失值并不能很好地解决人体生理指标数据存在的稀疏性和不规则性问题,尤其在AKI 预测任务上表现较差.对于AKI,一些生理指标在预测上有着更重要的作用.此外,这些生理指标的检测频率较低,填充缺失值阻碍了模型对于生理指标数值变化的学习.MUDIP 没有采用缺失值填充,而是考虑了生理指标缺失信息和时间间隔,增强了模型的预测能力.
对于GRU-D,FLTD 和RAPT 等模型,这些模型在AKI 预测问题上和在死亡风险预测问题上的表现也差于MUDIP.这3 个模型能处理人体生理指标数据稀疏性和不规则性问题,因此在AKI 预测问题上优于其他基于深度学习的患者健康风险预测模型.但是在死亡风险预测问题上,每个生理指标都有可能影响患者的死亡风险.此外,不同患者在死亡风险预测上的关键生理指标并不一定相同.而GRU-D,FLTD 和RAPT 没有考虑到不同生理指标之间的相互干扰,导致模型预测效果不佳.MUDIP 通过对每个生理指标独立建模,减少生理指标之间的相互干扰,准确地捕获每个生理指标的数值变化和检测频率变化.
3.5.2 多模态数据对比实验
表3 和表4 分别展示了各个模型基于多模态数据在AKI 预测问题上和在死亡风险预测问题上的平均结果,括号内的值为标准差.在AKI 预测问题上和在死亡风险预测问题上,MUDIP 展示出更加出色的性能,AUC、召回率、F1分数和准确率等评价指标上都比基线模型更高.例如,在死亡风险预测问题上,MUDIP 的AUC 达到0.931,比效果最好的基线模型XGBoost 的AUC 更高.MUDIP 的召回率达到0.521,比效果最好的基线模型LR 的召回率更高.

表3 基于多模态数据在AKI 预测问题上的平均结果Tab.3 Mean results on AKI prediction based on multimodal data

表4 基于多模态数据在死亡风险预测问题上的平均结果Tab.4 Mean results on mortality risk prediction based on multimodal data
MUDIP 取得这么好的效果主要有以下几点原因: ①考虑了不同模态数据的数据特点.与基线模型相比,MUDIP 分别对各个模态的数据进行建模,而不是把原始数据输入模型.针对各个模态的数据特点分别处理,尽可能捕获每个模态对于患者健康风险预测的重要信息.② 考虑了模态融合的问题.MUDIP 通过引入多头自注意力机制能充分交互各个模态的表征,每个表征通过其他表征挖掘自身潜在信息,增强对患者健康风险预测的能力.
此外,对比表1 和表2 的实验结果,可以发现所有模型在引入多模态数据之后AUC 都得到较大程度的提升.这是因为多模态数据和单模态数据相比,每个模态数据都有预测患者健康风险的关键信息.多模态数据能帮助模型捕获更加全面的患者健康信息,从而提高模型对于患者健康风险的预测能力.
3.5.3 消融实验
在本节中重点关注MUDIP 和MUDIP 变体之间的性能差异,以便清晰地了解每个变体对于模型最终性能的贡献.
(1) LSTM 是指仅考虑人体生理指标数据,用最近邻值填充数据的缺失值,并对每个生理指标分别采用LSTM 网络进行学习,最后通过级联的方式合并所有表征的模型.
(2) MUDIP-MT-LSTM 是指仅考虑人体生理指标数据,对每个生理指标分别采用MT-LSTM 网络进行学习,最后通过级联的方式合并所有表征的模型.
(3) MUDIP-lab 是指在MUDIP-MT-LSTM 的基础上,引入了多头自注意力机制.
通过网格搜索策略对模型和模型变体的超参数进行了微调,仍然进行了5 次随机运行实验,并报告了测试性能的平均值和标准差.
表5 和表6 分别展示了MUDIP 和MUDIP 变体在AKI 预测问题上和在死亡风险预测问题上的消融实验平均结果,括号内的值为标准差.显然,MUDIP 展示出更加出色的性能.
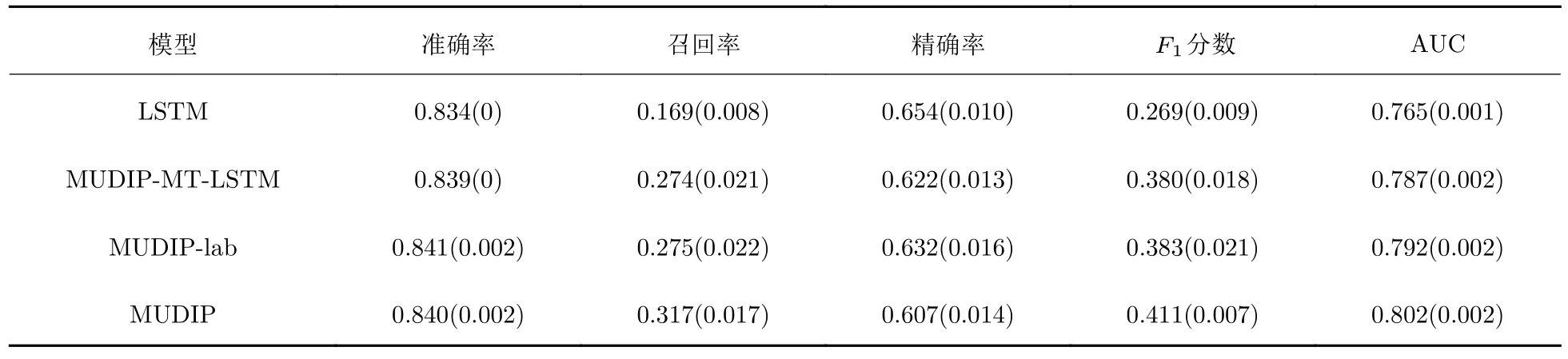
表5 消融实验在AKI 预测问题上的平均结果Tab.5 Mean results of ablation study on AKI prediction

表6 消融实验在死亡风险预测问题上的平均结果Tab.6 Mean results of ablation study on mortality risk prediction
MUDIP-MT-LSTM 与LSTM 相比,在AKI 预测问题上和在死亡风险预测问题上的AUC 都有提升.这是因为人体生理指标数据缺失值填充方法阻碍了模型对于各个生理指标序列的学习.而MUDIP-MT-LSTM 只考虑每个生理指标的真实值,尽可能捕捉其时序变化.在AKI 预测问题上,MUDIP-MT-LSTM 的召回率和F1分数比LSTM 的召回率和F1分数有较大提高.这是因为AKI 预测问题由少量的关键的生理指标决定,这些生理指标比较稀疏,且检测时间间隔并不一致.MUDIP-MTLSTM 捕获了每次生理指标的时间间隔和缺失信息,提升了模型的预测能力.
MUDIP-lab 在MUDIP-MT-LSTM 基础上引入了多头自注意力机制可以促进各个表征的相互学习.引入了多头自注意力机制,在死亡风险预测问题上MUDIP-lab 的AUC 和召回率比MUDIP-MTLSTM 的AUC 和召回率都有提升.这是因为与AKI 预测问题局限于某些关键的生理指标不同,死亡风险预测问题上大部分生理指标都对结果有重要影响.此外,不同患者在死亡风险预测上的关键生理指标并不一定相同.因此,通过多头自注意力机制可以发现人体生理指标之间的依赖关系,重新编码每个人体生理指标表征,增强了模型识别健康风险患者的能力.
MUDIP 与MUDIP-lab 相比,增加了捕获患者人口统计学数据表征和疾病数据表征的模型.显然,引入多模态数据使得在AKI 预测问题上和在死亡风险预测问题上MUDIP 的AUC 和召回率比MUDIP-lab 模型的AUC 和召回率都有提升,增强了模型的分类能力.总的来说,表5 和表6 体现了MUDIP 各个模块的有效性.
4 结论
本文提出了一个基于多模态的急性肾衰竭预测模型(MUDIP).MUDIP 分为两个部分: ①多模态数据的处理.对于人体生理指标数据,MUDIP 中的基于掩码和时间差的LSTM 网络(MT-LSTM)对各个生理指标单独建模,学习生理指标缺失信息和时间间隔,捕获指标的数值变化和检测频率变化.对于人口统计学数据和疾病数据,MUDIP 分别通过全连接层去捕获人口统计学和疾病模态的特征.② 多模态数据的融合.MUDIP 引入了多头自注意力机制交互学习各个模态的表征.多头自注意力机制可以提取各个表征之间的相互依赖关系,并让每个表征从其他表征中挖掘自身潜在的关键信息.在真实的数据集上进行了AKI 预测和死亡风险预测问题的实验.实验结果表明,与基线模型相比,MUDIP 在AKI 预测问题上和在死亡风险预测问题上有着更好的表现,这体现了本文所提出的捕获稀疏性、不规则性和多模态性等数据特点的模型能有效地提高预测患者健康风险的能力.
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
世界科学(2020年1期)2020-02-11
中国生物医学工程学报(2019年5期)2019-07-16
Coco薇(2017年5期)2017-06-05
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
现代电生理学杂志(2015年4期)2015-07-18
上海电机学院学报(2015年4期)2015-02-28
