
面向边缘计算的服务解耦与部署策略
2023-05-22 11:59李丽颖张润泽魏同权
计算机研究与发展 2023年5期
李丽颖 张润泽 魏同权
1(华东师范大学计算机科学与技术学院 上海 200062)
2(南京理工大学计算机科学与工程学院 南京 210094)
随着物联网和5G 无线网络的快速发展,万物互联已经成为一种趋势,促进了各个领域新兴应用的发展[1].与此相对应的是边缘设备及其产生的数据量迅速增长.麦肯锡全球研究报告称,预计到2025 年,物联网连接的设备将超过300 亿个,相关的数据量也从2016 年的96 ZB/月增长到了2021 年的278 ZB/月[2].这些海量而多样的设备和数据连接物与物、物与人,最终实现“万物互联”[3].
关键技术的蓬勃发展也使得分布式的用户请求数量迅速增加.然而,当前的服务模式大多是将应用程序的功能封装为独立的单元并将该单元部署在云服务器上.分布式的用户向云端服务器发送服务请求,云端服务器运行相应的应用程序并向用户反馈结果.然而,这种集中式的服务往往会带来巨大的服务响应延迟和带宽开销,降低服务质量(quality of service,QoS)[4].
解决上述问题的一种有效的方法是将这种集中式服务解耦为子服务.例如,Auer 等人[5]提出了一个基于问卷调查的评估框架,他们通过问卷调查归纳出将集中式服务解耦并部署到子服务架构上的重要指标,并根据问卷调查的结果来推断具体的集中式服务具体如何解耦并部署到子服务架构中.然而,这种基于问卷调查的解耦方案受限于问卷设计,通常都比较主观,其效果和普适性较差,并且会耗费大量的人力和时间成本.为了解决上述问题,Arisholm 等人[6]提出了动态耦合度的概念用于衡量应用程序在实际运行时的相关程度.Poshyvanyk 等人[7]提出了一种用于衡量程序的类之间的标识符和相关性的耦合度.然而,这些现有的工作忽略了服务自身的特性(如服务的字段等),因而效果不佳.
除了对集中式服务进行解耦,将解耦后的子服务部署到边缘计算架构中也是一个能够有效降低时延的解决方案.边缘计算利用终端设备的计算能力,可以显著减少传输到云服务器的数据量和服务请求的响应时间[8-9].然而,由于边缘设备的存储空间和计算能力有限,如何将解耦后的子服务部署在边缘服务器上是亟待解决的问题.现有关于边缘计算架构下的服务部署的相关工作如文献[10-12],并没有同时考虑边缘服务器本身的异构性和服务器之间的负载均衡,并且脆弱的边缘设备也带来了严重的安全性问题.首先,对于大多数边缘计算相关技术(如无线网络和分布式系统等),不仅需要保护其中的组件免受网络攻击,还需要协调不同等级的安全机制.其次,对边缘计算而言,在异构的系统下提供稳定的连接和高可访问性是提供高质量服务的基础[13].因此,边缘服务器在保证网络安全的条件下及时响应用户的服务请求就显得尤为重要.
移动设备数量的爆炸式增长推动了传统的边缘计算向移动边缘计算(mobile edge computing,MEC)的方向发展.移动边缘计算[14]将云端的计算能力推向了边缘端,即在移动设备和无线接入网的边缘部署计算平台,使得移动设备可以就近使用所需服务和云端计算功能[15].尽管移动边缘计算可以显著地降低端到端的延迟,但是设备移动的不可预测性给部署服务带来了新的挑战[16].Wang 等人[17]设计了一种服务迁移策略来解决顺序决策服务的部署问题.Taleb 等人[18]基于马尔可夫链模型提出了一种面向移动设备的边缘计算部署策略.然而,文献[14-18]所述工作都没有考虑到移动边缘计算服务部署的成本问题.
本文提出了一种2 阶段的服务质量优化方案以解决移动边缘计算架构下的服务部署问题.在第1 阶段,本文考虑了服务的解耦和边缘服务器的负载均衡问题,对服务部署问题进行建模,提出了一种集中式服务的实时解耦方案,并且设计了一种静态部署策略;在第2 阶段,本文考虑了边缘设备的移动性,设计了一种设备移动感知的服务部署策略,优化了移动边缘计算架构下的服务质量.具体来说,本文的主要贡献包括3 个方面:
1)在考虑边缘服务器负载均衡的前提下提出了一种面向集中式服务的解耦策略,并设计了一种基于分解的多目标进化算法的服务部署策略以优化服务质量.该策略能够在保证服务器负载均衡和安全性的前提下,优化服务请求的响应时间.
2)进一步考虑了边缘设备的移动性,提出了一种动态服务部署策略.首先,为了适应移动的服务请求,建模动态用户的服务部署问题.然后,提出了一种设备移动感知的实时服务放置策略以进一步优化服务请求的响应时间.
3)为了验证所提方法的有效性,本文进行了一系列的仿真实验.实验结果表明,与多种基准方法相比,在保证系统安全以及服务器负载均衡的前提下,本文所提出的面向集中式服务静态部署策略能够服务请求的响应时间降低36%,所提出的动态部署策略能进一步降低13%的服务响应时间.
1 系统模型
本节主要介绍本文主要用到的相关模型,包括系统架构模型、服务模型、耦合度模型和传输成本模型.
1.1 系统架构模型
不失一般性,本文采用常见的移动边缘计算系统架构.假设该架构硬件上包含1 个云服务器、Nes个边缘服务器、Nbs个基站和Ntd个终端设备.基站之间通过有线连接,终端设备与基站之间通过无线连接,终端具有可移动性.边缘服务器的集合用ES={ES1,ES2,…,}表示,其中ESi(1≤i≤Nes)为第i个边缘服务器.基站的集合用Vbs表示,终端设备的集合用Vt表示.系统架构图如图1 所示,其拓扑关系可以用无向图G={V,E}表示,其中V=Vbs∪Vtd,E=Ewire∪Ewireless,其中Ewire为2 基站之间所有的有线连接组成的集合,Ewireless为所有基站和终端设备之间的无线连接所组成的集合.
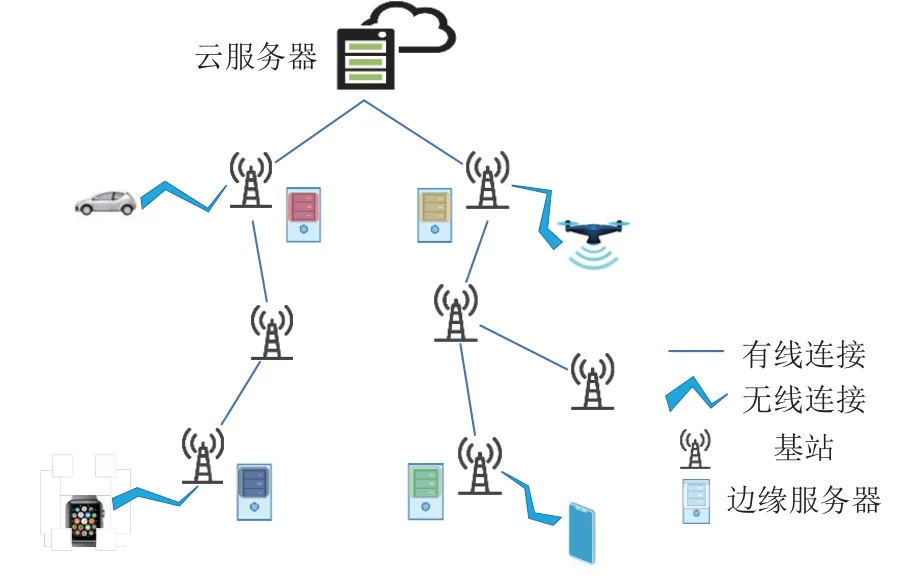
Fig.1 System architecture图 1 系统架构
在云端服务器上维护完整的集中式服务,并且负责将集中式服务解耦为Nser个子服务并且将这些子服务部署/卸载到Nes个边缘服务器上.每个边缘服务器通过使用子服务来快速响应终端设备的服务请求,这些边缘服务器在计算能力和存储空间上是异构的.由于基站数量的不断增加,在所有的基站上部署边缘服务器会带来巨大的成本,因此并不是所有的基站附近都会部署边缘服务器,即Nes≤Nbs.在本文中,使用文献[19]所提出的方法将Nes个边缘服务器部署在Nbs个基站上.基站会负责接收邻近终端设备的服务请求,这个基站被称为这些终端设备的本地基站,对应的边缘服务器被称为这些终端设备的本地边缘服务器.如果终端设备的本地基站部署了边缘服务器,且终端设备的服务请求可以在本地边缘服务器上处理,则请求将直接在本地边缘服务器上处理,否则这个服务请求将被转发到可以处理该请求的边缘服务器上,结果会被返回给终端设备.
1.2 服务及耦合度模型
假设云服务器维护Nser个服务,服务集合S={S1,S2,…,},每个服务Sj(1≤j≤Nser)包含Mj个字段.定义一个Mj×Nes大小的矩阵Ij来表示服务中各个字段的被订阅情况:
对于边缘服务器ESi(1≤i≤Nes),定义一个对服务Sj中字段m的影响因子:
其中ωdel,ωadd,ωupd分别为删除、增加和更新字段m对服务Sj影响的权重因子.需要注意的是,这3 种对服务中字段的操作都是原子操作.也就是说,在每次对字段的操作中,有且只有上述3 种操作的其中一种.服务的耦合度用于判定服务是否需要被解耦的依据.将服务Sj在边缘服务器ESi上的耦合度定义为
因此,服务Sj的耦合度为
从式(6)(7)的定义可以看出,一个服务的耦合度越高,其中的字段操作越频繁.如果不对这种高耦合度的服务进行解耦,产生的传输成本就会越高.因此,本文的方案倾向于解耦对高耦合度的服务.
1.3 安全性模型
本文定义了一个包含了K种不同类型的安全服务的集合,该集合用A={A1,A2,…,AK}表示.假设seci(1≤i≤K)为服务Sj使用安全服务Ai后的安全等级.T(Ai,Sj)为服务Sj使用安全服务Ai时的开销:
其中Ci为常数系数,取决于具体的安全服务算法.本文采用指数模型[20]计算服务Sj采用安全服务Ai失败的概率为
整个系统的安全性可以被定义为各个服务的安全性的乘积:
因此,为所有服务提供安全服务的总耗时为
其中Cost(S j)为传输服务S j所带来的开销,在1.4 节详细定义了该值.
1.4 传输成本模型
为了将服务从云服务器卸载到边缘服务器,一般会将服务封装到Internet 协议数据包中.因此,除了要考虑服务本身的大小,还需要考虑一些额外信息(如头部信息等)所产生的开销.假设这类开销用Costhead表示,则传输服务S j所带来的开销被计算为
其中,Cost(m)为服务S j中第m个字段的大小.
在传输成本方面,假设设备通过无线连接与服务器进行通信,服务器之间通过电缆或者光纤的有线连接方式传输信息.2 个边缘服务器ESi和ES j(1 ≤i≤Nes,1 ≤j≤Nes)之间的传输时延为
其中Wi,j和Bi,j分别为边缘服务器ESi和ES j之间需要传输的数据量和带宽大小.而这2 个服务器之间的传播时延为
其中,Di,j为ESi和ES j之间根据路由的物理链路距离,θ为电缆/光缆中电信号的传播速率.因此,可以定义ESi和ES j之间的有线总时延:
设备i与服务器ES j之间的无线传输时延为
2 集中式服务的实时解耦方案以及部署策略
本文所提方案用于解决移动边缘计算架构下的服务安全部署问题.本节主要介绍所提方法的第1 阶段.具体来说,在这个阶段,我们考虑了服务的安全性和边缘服务器的负载均衡问题,对服务部署问题进行建模,提出了一种集中式服务的实时解耦方案以及部署策略.
2.1 基于K-Means 算法的服务实时解耦
根据1.2 节对服务耦合度的定义可知,如果一个服务的耦合度越高,其中的字段被进行增加、修改和删除的操作越频繁.如果不对这种高耦合度的服务进行解耦,会产生较高的传输成本.因此,本文所提方案仅对高耦合度的服务进行解耦.具体来说,定义一个服务的耦合度阈值Fth.如果服务Sj的耦合度FSj>Fth,则Sj被认为是高耦合度服务,需要被解耦;反之,则认为服务Sj为低耦合度服务,不需要被解耦.
在对服务进行耦合度分类后,采用文献[22]中所提出的算法ISODATA(iterative self-organizing data analysis techniques algorithm),对服务进行初始解耦.这种解耦方法原理简单且易于实现,然而,该解耦方式本质上是一种离线的解耦,不适合增加、删除和修改操作频繁的移动感知应用场景,其对应的响应时延也较长.因此,本文提出了一种基于加权K-Means算法的服务解耦方案,该方案可以实现对服务的实时解耦.
K-Means 是一种迭代求解的聚类分析算法,是基于欧氏距离的聚类算法.K-Means 算法认为2 个目标的距离越近,相似度越大.具体来说,该算法首先会随机选择初始化后的K个样本作为初始聚类中心这些聚类中心被表示为{C1,C2,…,CK}.对于每个待聚,类的样本,首先计算该样本和每一个聚类中心的欧氏距离,然后将样本分类到与其距离最小的聚类中心对应的类别,最后算出每个类别的平均值以更新聚类中心.
我们只对高耦合度的服务进行解耦.具体来说,定义了一个耦合度阈值Fth,对于每一个服务S j,采用式(7)计算其对应的耦合度FSj.若FSj>Fth,则服务Sj为高耦合度服务,需要采用解耦算法进行解耦;反之,服务Sj为低耦合度服务,不需要被解耦.提出的基于加权K-Means 算法的实时服务解耦方案将ISODATA产生的结果作为初始解,实时地根据对服务中字段的操作(增加、删除和更新),不断地实时更新每一个服务的解耦方案,在考虑边缘服务器节点负载均衡的条件下优化服务请求的响应时间.
所提出的基于K-Means 的服务解耦算法对应的伪代码如算法1 所示.
算法1.基于K-Means 的服务解耦算法.
算法1 以耦合度阈值Fth和 服务集合S={S1,S2,…,SNser}作为输入,并输出对每一个服务的解耦方案.算法1 首先初始化需要被解耦的服务的集合为空集,该集合用Ω表示;然后将聚类中心的个数K设为预计解耦得到的子服务的个数Nsub(算法1 的行①).对于每一个服务Sj,首先将其耦合度FSj初始化为0,然后采用式(7)计算服务Sj的耦合度(算法1 的行③④).如果服务Sj的耦合度大于耦合度阈值,则认为Sj为高耦合度服务,此时需要对服务进行解耦,因此将Sj加入集合Ω,并采用ISODATA 算法[22]得到初始解耦方案和K个聚类中心的初始取值;否则认为Sj为低耦合度服务,不需要对其进行解耦(算法1 的行②~⑪).对集合Ω中每一个服务Sj,如果此时需要增加其中的字段,则算法1 首先计算增加的字段与此时每一个聚类中心之间的欧氏距离,然后将增加的字段加入与之最近的对应的子服务,并根据式(20)更新(算法1 的行⑬~⑰).如果此时需要删除/更新服务Sj中的字段,则从对应的子服务中删除/更新相应字段,并根据式(20)更新(算法1 的行⑱~㉑).需要注意的是,如果相应的操作是更新,则式(20)中=0.也就是说,此时相应子服务中的字段数量不会改变.迭代结束后,算法1 会返回对每一个服务的解耦方案.
2.2 基于MOEA/D 的服务静态放置策略
在对服务进行解耦之后,我们设计了一种静态的服务部署策略将解耦后的子服务部署到边缘服务器上以优化服务质量.具体来说,首先将子服务的部署问题建模为一个多目标优化问题(multi-objective optimization problem,MOP),然后采用基于分解的多目标进化算法(multi-objective evolutionary algorithm based on decomposition,MOEA/D)去解决该问题,以保证在服务器负载均衡和安全性的前提下,优化服务请求的响应时间.
结合第1 节的建模,可以将本文所关注的问题建模为一个多目标优化问题,该多目标优化问题表示为
其中FM:Y→RM由M个实值函数组成,Y为决策空间,RM为目标空间.为了便于表述,给出2 个定义.
定义1.如果存在2 个向量u,v∈RM,任意i=1,2,…,M,都满足ui<vi,则称u支配v.
MOEA/D 算法将式(22)中的目标函数分解为M个实值函数的优化问题,然后通过解决这M个实值函数的优化问题得到式(22)中的帕累托集合.使用基于切比雪夫的分解算法来解决多目标优化问题,具体来说,首先定义目标优化问题:
基于切比雪夫的MOEA/D 算法,在每一轮迭代中更新4 个内容:
1)分解成的子问题数量M以及子问题i的当前解xi∈Y;
《关于推动传统出版和新兴出版融合发展的指导意见》(新广发〔2015〕32号)的发布,标志着国家开始重视出版融合发展,支持力度逐年加大,积极鼓励传统期刊企业试水,探索出版媒体融合新模式。2017年,随着国家政策的大力倡导,以及出版单位的积极努力,开拓融合出版发展的主体应运而生,无论是国家认证的融合发展实验室,还是各主体自身的融合发展研发部门,甚至是企业的单个融合发展项目,都纷纷涌现出来。互联网数字出版模式已基本形成,并培养出大量极具粘性的用户群(具备互联网使用习惯)。
2)定义FVi=FM(xi),∀i=1,2,…,M;
3)z={z1,z2,…,zM},其中zi是到目前函数fi(x)的最优值;
4)在搜索过程中存储的非支配解的集合,该集合被表示为EP.
本文提出了基于MOEA/D 的集中式服务放置算法来探索集中式服务配置到边缘服务器的解决策略.具体来说,随机选择交叉算子和变异算子作为本文的遗传算子:
1)交叉算子.本文所关注的多目标优化问题为,在保证服务器负载均衡和安全性的前提下,将云服务器维护Nser个服务中每一个服务对应的Nsub个子服务部署至Nes个边缘服务器上,以优化服务请求的响应时间.因此,该问题的解空间为[0,Nes-1]Nsub,并在这个解空间内随机生成一个整数作为交叉算子.为了便于理解,以子服务个数Nsub=7、边缘服务器个数Nes=3 的情况为例.假设随机生成的交叉算子为3,即从位置3 开始进行交叉(子服务编号从0 开始),则交叉情况如图2 所示.
2)变异算子.本文使用基于正态分布的随机数生成方式进行变异操作.具体来说,对于染色体i的每个位置,先以Pmutation的概率判断是否会发生变异,若发生变异,则在该位置加上一个正态分布的随机数 τ,并将结果调整到限定范围内,即

Fig.2 An example of chromosome crossover process图 2 染色体交叉过程示例
所提出的基于MOEA/D 的子服务放置算法的伪代码如算法2 所示.
3 设备移动感知的动态服务部署策略
现实生活中,越来越多的终端设备会随着用户一边移动一边进行服务请求.为了进一步考虑边缘设备的移动性,本文提出了一种设备移动感知的动态服务部署策略.首先,为了适应移动的服务请求,建模了服务迁移成本队列解耦动态用户的服务部署问题;然后,提出了一种基于响应时间优先的实时服务放置策略.
图3 展示了用户移动情况下,在移动边缘计算架构下一个用户移动轨迹的示例[23].在该架构下,考虑网络运营商设置了Nmes个MEC 节点来服务Nuser个移动用户.每个MEC 节点都通过高速局域网与邻近的基站或是无线接入点相连接.每个用户携带一个移动设备,在移动设备上运行的应用程序的服务配置文件将分配到给定的边缘服务器的专用虚拟机[24]或容器[25].将系统的运行均分成若干时隙,其时间线被离散成若干时间帧t∈{0,1,…,T}.在每个离散时隙,每个移动用户向本地MEC 节点发送服务请求,由软件定义网络控制器(SDN 控制器)收集所有用户的服务请求信息并根据当前全局系统确定最佳MEC 节点为相应用户提供服务.

Fig.3 An example of a user's movement trajectory under the mobile edge computing architecture图 3 在移动边缘计算架构下用户的移动轨迹示例
用户的移动通常是不规律的,为了使用户可以获得高质量的QoS 服务,每个用户的服务配置文件应该随着用户移动性动态迁移.定义xi,j(t) 表示在时隙t用户j的服务配置文件是否部署在MEC 节点i上,如果是,则xi,j(t)=1,否则xi,j(t)=0.
其中,Mi,j为用户i在MEC 节点j上的服务配置文件的大小,Pj为节点j的计算能力.
因此,在时隙t时所有用户的服务迁移成本Costtotal(t)计算为
定义队列QL(t)表示从零时隙到时隙t时累计超出给定的长期平均期望预算的度量.由式(26)(29)可得,QL(t+1)可由时隙t时的QL(t)、时隙t时的服务迁移成本以及长期平均期望预算推导得出:
为了保证迁移成本的平均值不超过长期平均期望预算,则QL(t)的长期平均值应趋向于0.因此,QL(t+1)≥QL(t)+Costtotal(t)-Costavg(t)成立.定义二次李雅普诺夫函数为
其中 α 和 β为常数.
本文所提出的设备移动感知的动态服务部署策略的伪代码如算法3 所示.
算法3.设备移动感知的动态服务部署策略.
算法3 以状态空间d(t)和最大迭代轮次Tmax作为输入,并输出最优服务放置策略d*.算法3 首先初始化迭代轮次为0,并随机生成一个服务部署策略d,该部署策略d将每个服务配置文件随机分配到Nmes个MEC 节点上(算法3 的行①).对于每一次迭代,首先随机选择一个用户的服务配置文件,对于在此时服务放置策略的状态空间d(t)中除了d以外的每一个部署策略d′,使用式(26)计算成本函数(算法3 的行⑤~⑦).接着算法3 根据式(29)计算得到的概率选择一种放置策略并通过将服务放置到新的MEC 节点来更新现有的服务放置策略(算法3 的行⑧~⑩).设使得Costtotal(t)最小的服务放置策略为d*,该策略d*即为最佳放置策略,d*会在每一轮迭代中被更新(算法3 的行⑩).最后,算法3 会返回迭代结束后得到的最佳服务放置策略(算法3 的行⑬).
4 实 验
本文在2 个数据集上进行实验以验证所提方案的有效性.具体来说,首先介绍了相关的实验设置;然后以传输开销为评价标准来衡量所提的基于KMeans 的服务解耦算法的有效性;接着,在多个方面将所提的基于MOEA/D 的服务静态放置策略与3 种基准算法相比较,以验证所提的静态放置策略的有效性;最后,在多个方面将所提的设备移动感知的动态服务部署策略与3 种基准方法相比较,以验证所提的动态服务部署策略的有效性.
4.1 实验设置
本文的实验环境使用Windows 10 操作系统,8GB 内 存,AMD Ryzen 5 4500U @ 2.38GHz 处理器,并使用Python3.7 的运行环境.
在数据集方面,本文采用2 个数据集进行实验.第1 个数据集是1990 年美国人口普查公开数据集(以下简称数据集1)[28],该数据集包含了大约20 万条1990 年美国人口的普查结果,其包含年龄等68 种基本特征.我们将该数据集分为10 个服务,并由68个边缘设备对这些服务中的字段进行订阅.第2 个数据集是由上海交易中心信息技术有限公司提供的真实数据集(以下简称数据集2).该数据集提供了上海交易中心信息技术有限公司真实的20 个设备对15个服务对应的所有字段的订阅情况.我们对每一个服务的耦合度进行计算,并采用所提出的实时解耦策略对这2 个数据集中的服务进行解耦.删除、增加和更新这3 个指示变量,均设为1.为了比较离线算法与在线算法节省的带宽,将头部信息的大小设置为10b,并假设每条数据为200b.
在开销方面,本文所提出的策略所带来的开销分为2 个部分:算法的运行时间和因传输解耦后的服务所带来的传输开销.因此,本文在4.2~4.4 节对这2 个方面的开销进行了详细的分析和对比.
4.2 基于K-Means 的服务实时解耦策略验证
为了验证基于K-Means 的服务实时解耦策略,本文对比了解耦前后的传输开销.数据集1 和数据集2的解耦前后传输开销分别如图4 和图5 所示.从图4可以看出,编号1 在解耦后的所有服务的通信开销平均减少了29.04%;对编号3 的服务解耦效果最为明显,其通信开销减少了44.20%.从图5 可以看出,与解耦前相比,所有服务在解耦后的传输开销平均减少了24.71%,其中传输开销减少可高达29.92%.这是因为解耦后,边缘服务器减少了大量无关子服务的订阅数,因此减少了大量不必要的通信开销.只有少数服务(如编号8 的服务)在解耦前后通信开销变化不大.这是因为这些服务解耦后边缘服务器仍然订阅了大量的子服务.如果某服务订阅了解耦后服务集合的所有子服务,会由于解耦增加的额外成本导致解耦后的字段开销大于解耦前的字段开销.在实际应用中,可以考虑不对该服务进行解耦.图6 对比了在数据集2 上增加字段时ISODATA[22]和所提出的基于K-Means 的实时解耦策略的运行时间.在不改变划分结果的条件下,在线算法的运行时间远小于离线算法的运行时间.在数据集2 的10 组数据中,在线算法的算法运行时间平均减少了78.14%,最多减少高达80.35%.这是因为在线算法只需要遍历1 遍数据即可完成对整个服务的划分,而离线算法通常要迭代很多轮才能收敛得到最终的划分结果.

Fig.4 Comparison of the transmission overhead for dataset 1 before and after decoupling图 4 对比数据集1 解耦前后的传输开销
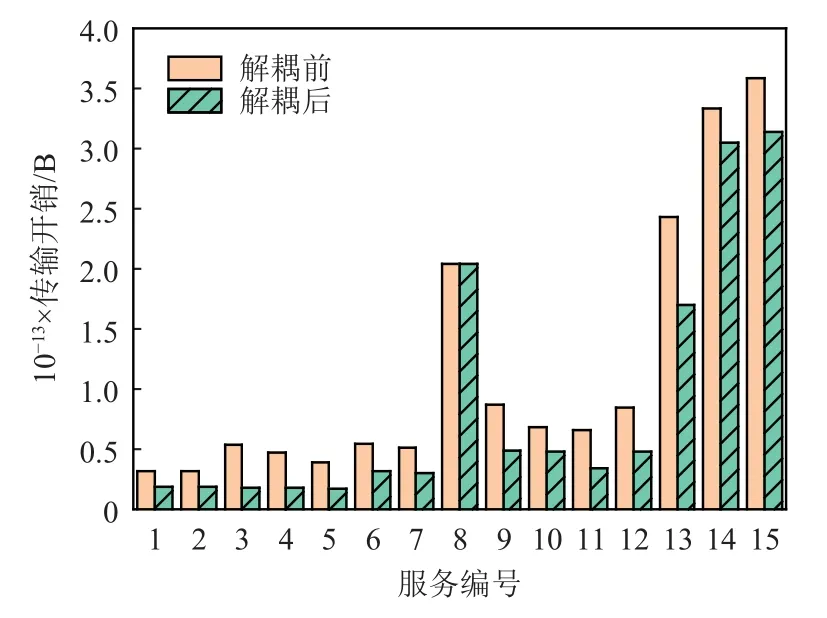
Fig.5 Comparison of transmission overhead for dataset 2 before and after decoupling图 5 对比数据集2 解耦前后的传输开销

Fig.6 Computation time of ISODATA and the proposed strategy when conducting add operation on dataset 2图 6 对比在数据集2 上增加字段时ISODATA 和所提策略的运行时间
图7 展示了字段个数分别为2 万、4 万、8 万以及12 万时ISODATA[22]和所提出的基于K-Means 的实时解耦策略的运行时间.相比于ISODATA 算法,4种不同字段个数的在线算法的算法运行时间分别减少了78.95%,85.37%,86.06%,85.35%.由于算法的时间复杂度与字段个数呈正相关,字段个数越大,在线算法节省的时间也就越多.因此,我们认为,所提出的基于K-Means 的实时解耦策略比较适合服务体量较大也就是字段个数较大的情况.在这种情况下,所提算法能够节约的处理时间较多,效果更好.但是当服务较小或子服务耦合度较低时,所提方法反而可能会导致较大的开销.这是因为所提方法需要传输解耦后的服务,而这会带来较大的传输延迟.
图8 展示了数据集2 在删除字段的场景ISODATA算法和所提的基于K-Means 的实时解耦策略的运行时间比较.在解耦结果一致的条件下,所提实时解耦算法的运行时间远小于ISODATA 算法的运行时间.具体来说,在数据集2 上所提出的实时解耦算法的运行时间平均减少了73.02%,最多减少高达75.80%.
4.3 基于MOEA/D 的服务静态放置策略验证
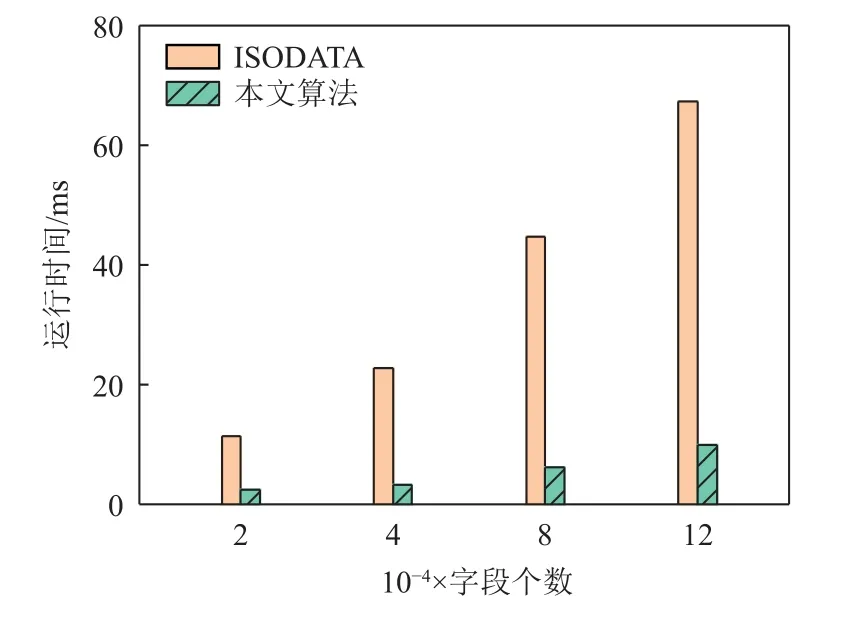
Fig.7 Computation time of ISODATA and the proposed strategy under different numbers of adding segments图 7 当增加字段量不同时ISODATA 和所提策略的运行时间
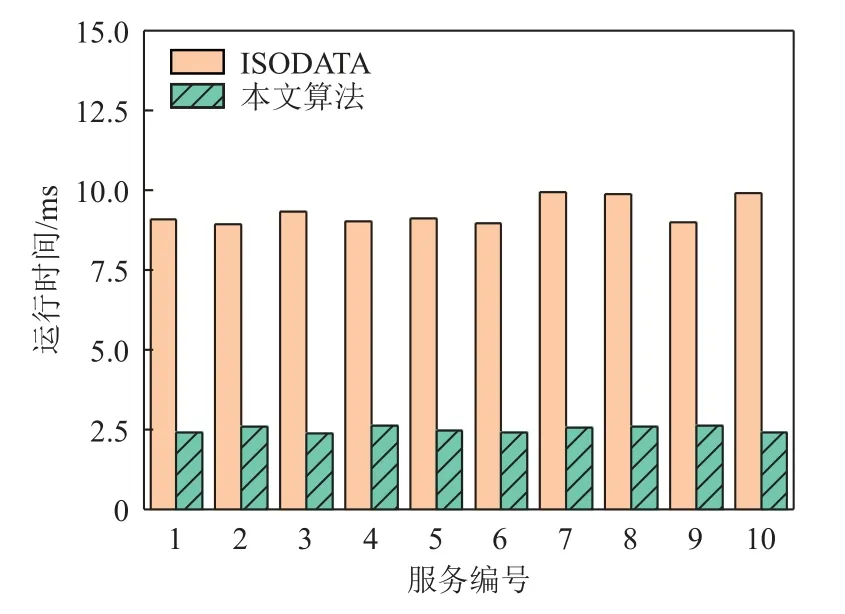
Fig.8 Computation time of ISODATA and the proposed strategy when conducting delete operation on dataset 2图 8 对比在数据集2 上删除字段时,ISODATA 和所提策略的运行时间
为了验证所提的基于MOEA/D 的集中式服务静态放置算法的有效性,本实验比较并分析了基于MOEA/D 策略(本文算法)和3 种基准算法的集中式服务静态放置结果,其中3 种基准算法分别是基于随机的算法(RAND)、遗传算法(GA)[29]和粒子群算法(PSO)[30].这3 种基准算法的原理为:
1)RAND.随机选取每个服务部署的边缘节点放置服务.
2)GA.遗传算法基于染色体自然进化,对染色体编码后,使用交叉和变异生成新的染色体,并基于适应度函数评估染色体的质量,最后根据最优染色体得到最优解以放置服务.
3)PSO.粒子群优化是一种使用粒子模拟一群寻找食物的鸟的算法.具有“速度”和“位置”的粒子是目标函数空间中的搜索个体,算法会基于所有粒子的历史最优位置调整速度.最后将所有粒子当前位置的最优解视为全局最优解.
图9 对比了当设备数量分别为3,5,10 时,使用本文算法、PSO、GA、RAND 得到的平均服务响应时间.服务响应时间是由本文算法运行时间和终端设备请求服务的响应时间组成,终端设备的响应时间由服务请求的通信时延、服务加密消耗的时间以及服务在边缘服务器运行所需的时间组成.由图9 可以看出,与PSO,GA,RAND 这3 种基准算法相比,本文算法分别平均优化了9.23%,10.33%,15.07%,最高优化分别为24.89%,25.94%,35.55%.这是因为本文算法的运行时间以及服务放置策略均优于这3 种基准算法.

Fig.9 Average service response time of the 4 algorithms under different numbers of devices图 9 不同设备数量下对比4 种算法的平均服务响应时间
图10 展示了当设备数量分别为3,5,10 时,使用本文算法、PSO、GA、RAND 算法得到的负载均衡平均优化率.将本文算法的负载均衡平均优化率设置为1,与PSO,GA,RAND 这3 种基准算法相比,本文算法分别平均优化了3.28%,29.15%,66.97%,最高优化分别为89.67%,87.91%,96.10%.虽然当边缘服务器数量为5 时,PSO 算法的负载均衡平均优化率小于1,然而此时其响应时间比本文算法高10.18%.由于PSO 和GA 难以找到优化问题的全局最优解,因此使用PSO 和GA 算法得到的负载均衡平均优化率不如本文算法.因此,由图10 可以看出,本文所提的基于MOEA/D 的服务静态放置策略适合被应用于设备数量较多、需要进行负载均衡的场景中.此时,本文算法相较于基准算法,能够取得更好的优化效果.

Fig.10 Load balancing average optimization rate of the 4 algorithms under different numbers of devices图 10 不同设备数量下对比4 种算法的负载均衡平均优化率
4.4 设备移动感知的动态服务部署策略验证
为了验证所提设备移动感知的动态服务部署策略的有效性,本文所提方案与“总是迁移”(always migration,AM)、“从不迁移”(no migration,NM)以及“随机迁 移K个服务”(randomK-service migration,RKM)三种基准方法进行了对比.这3 种方法的原理简介如下:
1)AM.在每个时隙中,用户的服务配置文件总是迁移到距离用户最近的MEC 节点上.
2)NM.在每个时隙中,用户的服务配置文件总保持在初始的MEC 节点不迁移.
3)RKM.在每个时隙中,随机选取K个服务配置文件迁移到当前最优的MEC 节点上.
本节使用2007 年由芬兰国家土地调查局提供的赫尔辛基市区的街道进行仿真[31].假设终端设备在该市区街道上进行移动,我们将该市区街道划分成64个正方形区域,每块大小500 m×500 m,在每块区域的中心位置部署MEC 服务器提供移动服务,其中每台MEC 服务器具有多个CPU 核,其计算频率为25 GHz,存储空间为100~160 GB,2 个MEC 节点的距离使用曼哈顿距离.假设街道上有2 种类型的移动用户:一种是行人,速度在0.5~1.5 m/s;一种是车载用户,速度在5.56~11.11 m/s,假设行人的数量占总人数的比率是7/8.本实验仿真100 个时隙,每个时隙是5 min,在每个时隙t内,假设用户的服务配置文件所在的MEC 节点保持不变,响应用户所需要的服务大小均匀分布在0.8~1 GB.
图11 展示了AM,NM,RKM 和响应时间优先的算法(本文算法)得到的总时延,该总时延为服务的通信时延、加密时延以及计算时延之和.RKM 算法中选取的配置文件个数K取总人数的10%.与AM,NM,RKM 这3 种基准算法相比,本文算法的总时延分别平均减少了8.52%,10.64%,2.78%,最多减少可分别达10.78%,12.70%,3.74%.这是由于NM 算法从不迁移服务配置文件,因此其服务总时延基本与初始化服务配置文件放置结果有关;而AM 算法虽然一直将服务配置文件迁移到距离用户最近的位置,然而当一个局部地区的人数过多时,迁移到同一MEC 服务器上会给服务器的计算带来较大的压力,每个服务分得的资源也会减少,甚至会出现资源不够的情况;RKM 算法每轮随机选取K个服务配置文件进行迁移,然而当K过小时,其性能会接近NM 算法,且可能会导致无法优化部分服务配置文件的放置,而当K过大时会接近AM 算法,同样可能出现资源分配不当的问题.

Fig.11 Comparison of the total latency of four deployment methods图 11 对比4 种部署方案的总时延
图12 展示了AM,NM,RKM 和响应时间优先的算法(本文算法)的服务迁移成本,其中平均期望预算被设定为200.从图12 中可以看出,AM 算法由于频繁地进行服务配置文件的迁移,其服务迁移成本远超过长期平均期望预算;虽然NM 算法不进行服务配置文件的迁移,但其服务的总时延过高,且与初始化的结果有很大的关系,通常会导致服务质量不高;而RKM 算法没有充分利用服务迁移预算,使其服务迁移成本一直保持在较低的水平;而本文算法其服务迁移成本保持在长期平均期望预算的迁移成本之内的条件下,能够取得最优的服务总时延.

Fig.12 Comparison of the migration costs of four deployment methods图 12 对比4 种部署方案的迁移成本
5 结 论
本文提出了一种2 阶段的服务质量优化方案以解决移动边缘计算架构下的服务安全部署问题.在第1 阶段,本文考虑了服务的安全性和边缘服务器的负载均衡问题,对服务部署问题进行建模,提出了一种基于K-Means 的服务实时解耦方案,并设计了一种基于MOEA/D 的服务部署策略;在第2 阶段,本文考虑了边缘设备的移动性,设计了一种设备移动感知的服务部署策略,优化了移动边缘计算架构下的服务质量.实验结果表明,与多种基准方法相比,在保证系统安全以及服务器负载均衡的前提下,本文所提出的面向集中式服务部署策略能够使服务请求的响应时间降低36%,所提出的动态部署策略能进一步降低13%的服务响应时间.
作者贡献声明:李丽颖提出了算法思路并撰写论文;张润泽负责完成实验;魏同权提出指导意见并修改论文.
猜你喜欢
干旱气象(2022年5期)2022-11-16
江苏科技信息(2022年16期)2022-07-17
电脑爱好者(2022年12期)2022-05-30
防爆电机(2022年1期)2022-02-16
生产力研究(2020年5期)2020-06-10
电脑爱好者(2019年20期)2019-12-10
网络安全和信息化(2018年5期)2018-11-09
摄影之友(影像视觉)(2016年2期)2016-08-16
衡阳师范学院学报(2016年3期)2016-07-10
图书馆建设(2015年10期)2015-02-13
