
图书馆中文图书编目外包数据质量控制分析
2022-07-17 09:07徐新邦
江苏科技信息 2022年16期
徐新邦
(中国国家图书馆 中文采编部,北京 100081)
0 引言
业务外包(Outsourcing)也叫资源外包、资源外置,从20世纪80年代开始流行,是一种全新的企业经营管理模式。业务外包主要指企业保留内部核心业务资源,将原来由内部员工完成的一些非核心业务活动交由外面的企业或机构来完成。这样不仅可以降低企业经营成本,还能发挥外包团队的专业优势,更快更好地完成外包工作,提高企业效率,节省企业的时间成本[1]。
20世纪90年代开始,业务外包以其独特的优势以及在IT外包领域的成功运用,逐渐吸引了西方国家图书馆领域的关注,并很快获得西方各国图书馆的使用推广,取得巨大的成功。直到20世纪90年代后期,中国图书馆界开始效仿西方国家图书馆界,逐渐引进业务外包这一全新模式,并将其运用于图书馆各项业务中。近二十几年来国内图书馆业务外包实现快速发展,不仅在各大高校图书馆中获得认可,还在许多公立图书馆得到不同程度的实施,业务外包应用的范围也越来越广[2]。
1 图书编目业务外包及其优势
和其他图书馆不同,目前国家图书馆采取的外包模式是馆内加工模式。根据图书编目的标准和要求,业务外包公司派出自己的编目人员到国家图书馆内进行图书分类、著录、标引等工作,将图书制作成合格的MARC数据。在这种外包模式下,图书馆提供一些场地、设施和设备供业务外包公司使用,但图书编目所需的材料成本和人工费用由业务外包公司自己负担。为了保证编目数据的质量,国家图书馆提供专业审校人员,对业务外包公司编目人员提交的MARC数据进行抽样检查,并撰写验收报告[3]。
图书馆引进图书编目业务外包的方式具有以下优势:(1)减少图书馆编目人员的数量,节省了大量的人力资源,可以提升图书馆编目人员个人能力,让其主要从事书目数据校对、质量控制和维护数据库等工作。(2)缩减经费投入,节省下来的经费可以用于商业数据库、图书、期刊等采购工作,丰富馆藏资源,更好地服务读者。(3)提高图书上架的速度,降低时间成本,解决新书大量积压问题,让新书更快地从入馆到读者手上。(4)对于业务外包公司而言,其数据库的MARC数据稍加修改,就可以适用于各种不同类型的图书馆需求,避免整个社会劳动力的重复浪费。(5)图书馆编目人员可以从繁复的工作中脱离出来,专注于核心业务发展,提高工作积极性,进行更深层次的研究工作,这样可以促进整个图书馆界发展。(6)通过对业务外包公司书目数据的审校,密切关注书目数据质量,并定期开展针对外包公司编目人员的书目数据制作培训,提高其编目能力,加强与业务外包公司之间的沟通交流[3-5]。
2 中文图书书目外包数据错误及分类
本文收录整理了2018年4—9月抽校的3家编目外包公司提交的中文图书书目数据,按照字段类型分为0XX字段、1XX字段、2XX字段、3XX字段、4XX字段、5XX字段、6XX字段、7XX字段。为了分析书目数据不同字段错误之间的关系,将编目数据错误分为普通错误和关联错误,而普通错误主要分为缺失错误、多余错误、错著错误3类。
缺失错误主要包括书目数据中字段、子字段的缺失,还包括字段中部分著录或标引内容的遗漏。如:009443956(陈劲松著),300字段漏著“国家自然科学基金”,需补充;009471155(李明主编),外包公司提交数据中没有312字段,需要补充312字段封面英文题名,同时添加一个510字段;009511979(佐克西亚季斯著),200字段$f中“帕季米特里乌”少了一个“帕”字,最后改为“帕帕季米特里乌”。
多余错误不仅包括书目数据中字段、子字段或者内容的重复,还包括出现一些额外的字段、子字段或者内容。如:009564067(刘铁主编),外包公司编目人员著录了两个701字段“刘铁主编”,需要删除其中一个701字段;009549293(王清远著),105字段内容特征代码,图书中并无书目资料目录,而编目人员错误录为“az”,最后改为“z”。
错著错误主要包括书目数据中字段、子字段的错误使用,还包括内容的错误著录等。如:009487527(霍德尼斯著),102 字段$b出版地区代码“230100”错误,最终改为“230000”;009460337(袁尔铭主编),图书中原文为“建制沿革”,而编目人员在330字段中错误录作“建置沿革”;009578889(郑安然著),编目人员同样在330字段将“自强自立、自得自乐”错著为“自强自立、自得其乐”;009579378(杨秀清著),701字段$4责任说明 “编著”,被外包公司编目人员错误写成“清著”。
关联错误主要指由于一些字段或子字段的错误,引起其他字段或者子字段的错误著录或标引。如:009503018(温布兰特著),根据中文书目数据制作规则,200字段$e子字段首字母应小写,单词“Toothsome”改为“toothsome”,同时也要改正510字段,所以510字段的错误是由于200字段$e子字段的错误引起的,属于关联错误;009609536(蒂瓦里主编),编目人员在690字段分类号标引为TB332,正确标引为TB383,而090字段$a子字段和690字段密切相关,也需要改正;009529712(张宇庆著),100字段阅读对象代码em改为kem,同时105字段内容特征代码z改为v,105字段的错误是由于100字段的错误引起的,属于关联错误。
3 中文图书书目外包数据抽检统计及数据分析
3.1 3家编目外包公司中文图书书目数据错误数量统计及数据分析
本文选取了3家不同编目外包公司在2018年4—9月提交的中文图书书目数据(共90车,约29 000条),对其中的编目数据错误按照0XX,1XX,2XX,3XX,5XX,6XX,7XX字段(4XX字段太少,不具备统计性)的顺序分别进行统计,结果见表1。

表1 3家编目外包公司中文图书书目数据错误数量统计
可以看出,3家编目外包公司在各个不同字段均出现著录或标引错误。其中4XX字段由于字段数量太少,大部分图书在书目数据制作的过程中不涉及,不具备统计性,所以未进行统计。从表1中可以看到,外包公司1书目数据错误的数量明显多于其他两家,而外包公司3的错误数据数量最少。但是外包公司1大概提交了13 000条中文图书书目数据,外包公司2提交了约10 500条中文图书书目数据,外包公司3完成的中文图书书目数据在3家外包公司中最少,约5 500条数据。经过对比,可以看出:虽然外包公司3的数据错误数量最少,但外包公司1和2数据质量反而优于外包公司3。
图1是3家编目外包公司中文图书书目错误数据数量在不同字段下的柱状对比图。可以看出,3家编目外包公司中文图书书目错误数量上均呈现出中间高、两头低的现象。3XX字段是每一家外包公司出现数据错误最多的字段,而0XX和7XX字段是著录错误出现较少的字段。这表明中文图书书目外包数据审校工作的重点在中间部分,涉及3XX字段、2XX字段、5XX字段、6XX字段。
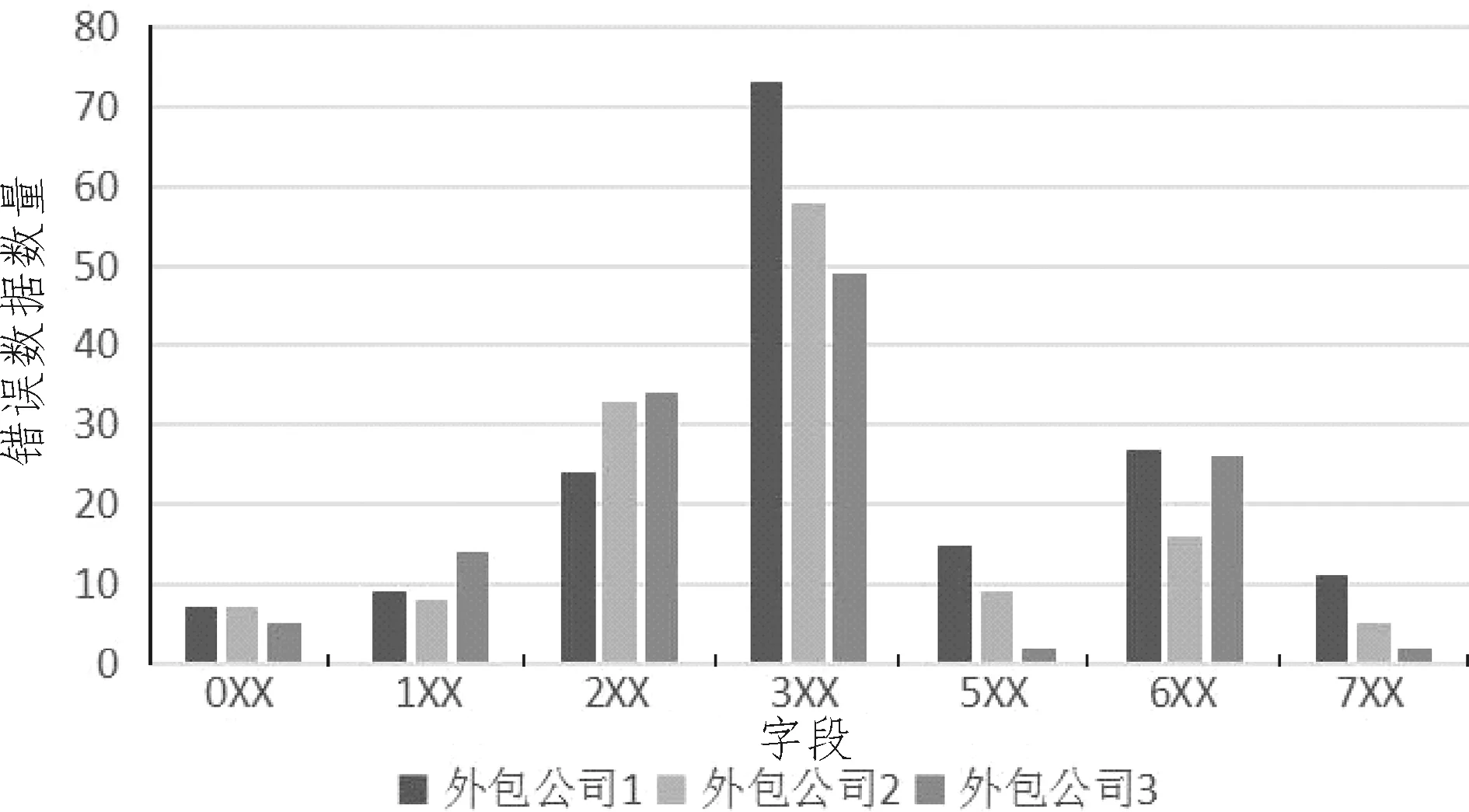
图1 编目外包公司中文图书书目错误数据数量在不同字段下的柱状对比
分析上述情况,在中文图书书目数据中,0XX和7XX字段的种类较少,制作时确定性较强。而3XX字段包含300,304,305,306,310,312,314,330等字段,编目人员需要一定的工作经验,不然很容易在著录的过程中混淆,将本应著录在304字段的信息放在312或者314字段中,或者把应该放在305字段的内容错误放在306字段里。另外330字段内容提要工作量较大,直接影响中文图书书目数据制作的快慢,而编目外包公司一般实行计件工资,编目人员薪酬与完成书目数据的数量密切相关,这就促使编目人员在著录330字段过程中容易为了追求数量而忽略了质量。

图2 各字段中文图书书目错误数据数量分布

图3 各字段关联错误和普通错误占比
图2为各字段中文图书书目错误数据数量分布图,可以看出3XX,2XX,6XX字段错误数量位列前三。2XX字段包括200,205,210,215等,其中200字段既是重点字段,也是难点字段。在题名选取过程中,编目人员要在不违背基本著录规则的情况下,从多个角度考虑问题,将复杂的题名信息判断出来,正确地放在200字段中每一个题名子字段中[6]。6XX字段错误数量较大,表明编目人员对中国图书馆分类法以及如何进行分类标引不熟悉,需要进一步的业务培训和指导工作。
3.2 编目外包公司中文图书书目错误数据数量分类统计及数据分析
本文在统计3家编目外包公司中文图书书目错误数据数量过程中,将普通错误和关联错误分开进行统计,结果见表2。
从表2可以看出,1XX字段、2XX字段关联错误数据数量为0,出现关联错误的数量明显少于其他字段,而3XX字段和6XX字段关联错误的数量也不多,出现最多关联错误数据的字段则是5XX字段。由图2可知,3XX字段、2XX字段、6XX字段著录或标引的错误数量排名前三,但从表2发现3XX字段、2XX字段、6XX字段关联错误数量很少,这表明3XX字段、2XX字段、6XX字段更多的是自身性错误,受其他字段数据的影响较弱,相互之间也不容易影响。减少3XX字段、2XX字段、6XX字段错误数据数量,将显著降低书目数据错误数量,大幅提升编目外包公司中文图书书目数据的质量。

表2 编目外包公司中文图书书目错误数据数量分类统计
为了研究不同字段中关联错误在编目错误中的占比,本文根据表2中的数据进行计算,结果见图3。
5XX字段主要包括510,512,516,517,540等字段,这些字段受其他字段影响较大。在图3中,5XX字段关联错误在编目错误中占比接近90%,在所有字段中比重最高。5XX字段中使用最多的是510字段、517字段,而它们的著录跟200字段、312字段密切相关。只要200字段、312字段在著录过程中出现错误,510,517字段也必然出现错误。另外0XX字段也有类似的情况,当690字段、701字段、711字段出现著录错误时,090字段也会错误著录。另外,在1XX,2XX,3XX,6XX字段中,关联错误的占比极低。这表明:书目数据质量控制工作的关键点不能放在0XX字段、5XX字段上,而应该重点放在3XX,2XX,6XX字段上。减少3XX字段、2XX字段、6XX字段的数据错误量,不仅可以减少其自身的错误数量,还能减少0XX字段、5XX字段等其他字段的数据错误量,这样可以更快地减少中文图书编目错误数据数量,大幅提高图书馆书目数据整体质量。
4 总结
在图书馆编目业务外包的实施过程中,图书馆界有效释放人力资源短缺的压力,增加馆藏资源,服务更多的读者,促进了图书馆多元化发展。本文在总结某一段时间3家编目外包公司的抽校报告过程中,对其中最关键的错误数据进行统计分析,同时将错误数据进行分类。经过对错误数据的数理统计可以看出,中文图书书目错误数据分布呈现出中间高、两头低的现象。在错误数据数量上,3XX字段处于绝对领先的地位,而2XX字段和6XX字段其次,0XX和7XX最少。同时通过对关联错误数据的统计分析,0XX字段、5XX字段错误数据数量较多,受其他字段的影响较大。虽然3XX字段、2XX字段、6XX字段编目错误数据数量排前三,但关联错误数据数量非常少,而且其关联错误数据数量在编目错误中占比很低。所以3XX字段、2XX字段、6XX字段编目错误无论在数量上还是关联性上,都处于最重要的位置,为书目数据质量控制工作指明了方向。在数据审校以及业务培训中,要加强编目人员对3XX字段、2XX字段、6XX字段的理解,让其熟练掌握3XX字段、2XX字段、6XX字段的著录或标引,这样不仅能减少3XX字段、2XX字段、6XX字段的数据错误量,还可以相应减少0XX字段、5XX字段的数据错误量,更快地减少中文图书编目错误数据数量,大幅提高图书馆书目数据整体质量。
猜你喜欢
都市人(2022年3期)2022-04-27
天一阁文丛(2020年0期)2020-11-05
办公室业务(2019年13期)2019-08-01
戏曲研究(2017年3期)2018-01-23
图书馆学刊(2015年8期)2015-12-26
办公室业务(2015年23期)2015-11-26
图书馆建设(2015年10期)2015-02-13
新世纪图书馆(2014年7期)2014-09-19
图书馆建设(2014年3期)2014-02-12
中国民间疗法(2012年1期)2012-07-27
