
针对冗余零的跨平台细粒度性能分析技术
2023-05-22 12:00:02杨海龙雷克伦孔祥浩栾钟治钱德沛
计算机研究与发展 2023年5期
游 心 杨海龙 雷克伦 孔祥浩 徐 筠 栾钟治 钱德沛
1(北京航空航天大学计算机学院 北京 100191)
2(北京仿真中心航天系统仿真重点实验室 北京 100854)
如今,无论是生产软件还是科学计算应用都变得越来越复杂,其中软件包含的大量库依赖项以及复杂的控制和数据流使得软件效率难以得到保证.并且,如此高的复杂性很容易导致意料之外的低执行效率,从而阻碍软件达到最佳性能.软件效率低下往往涉及冗余操作,例如从内存中反复加载相同的值[1]、写入从未使用过的值[2]、使用从未使用过的中间值来覆盖同一位置的值[3]以及重复计算相同的值[4-5].此外,大量的应用将稀疏数据作为输入,而使用稠密数据结构处理该稀疏数据将会导致资源的大量浪费[6-8].以往的研究已经证明上述低效率的根本原因之一是一些指令和数据结构经常处理冗余零[9].
目前已经有大量的真实应用报告了大量冗余零的存在并对其进行针对性优化来达到更好的效果.例如在深度神经网络领域,研究人员[7-8]已经提出了软件或者硬件的优化方法来实现对神经网络中稀疏性的自动检测以及特定的稀疏优化来达到更好的性能;在视频编码领域,研究人员[6]提出了一些全0 块(all-zero block)检测方法来跳过这些块的计算从而达到更高的性能.而这些方法都是针对特定领域上的工作,并不能对其他领域的应用提供冗余零的检测或优化指导.
此外,现代编译器优化无法识别访存和计算操作中涉及的冗余零以进行进一步的代码优化.而诸如perf[10],HPCToolkit[11],VTune[12],Gprof[13],CrayPat[14],Oprofile[15]这些性能分析工具也不会识别与冗余零相关的低效率行为,从而无法提供相应的优化指导.ZeroSpy[9]虽然能够正确识别冗余零相关的低效行为并给出相应的指导建议,其检测方法仍然局限于Intel 平台,且不支持目前逐渐流行的ARM 计算平台.此外,ZeroSpy 的高性能开销也大大加剧了真实应用的性能分析开销.而目前ARM 架构在高性能领域已经越来越受到重视,在Top500 中取得世界第一性能的富岳超级计算机[16]的中央处理器就是基于ARMv8架构设计的,而目前并没有一款编译器或性能分析工具可以在ARM 平台识别冗余零相关的低效行为,从而错失大量潜在的性能优化机会.
因此,本文提出了DrZero[17],它是一款基于冗余零检测的可跨平台的、具有更低分析开销的性能分析工具.DrZero 实现了一种检测应用程序执行过程中冗余零的方法,包括:1)识别由于数据结构使用不当、数据宽度过大以及无用计算造成的冗余零;2)提示冗余零发生的源代码行与执行上下文来提供直观的优化指导;3)依据应用检测出的冗余零信息进行针对性优化显著提高应用的执行性能或能效.此外,DrZero 基于Dynamorio 二进制动态插桩框架[18]实现,并通过基于数据流分析的数据类型推断来识别ARM访存指令读取的数据类型,以及实现在线细粒度缓存迹分析方法来进一步减少性能开销.相较于ZeroSpy,DrZero 支持跨平台的冗余零检测,并拥有更低的开销以及更加友好的报告界面来提示足够充分的冗余零信息以及对应的优化建议.
1 冗余零的定义与来源
类似文献[9]中所提出的冗余零定义,本文也使用冗余映射(redmap)以及冗余零比例(redundant zeros fraction)作为冗余零的检测目标.其中,冗余零为指令读取值的高位0 值,因此理论上完全消除冗余零对值的表达与计算的正确性不会造成任何影响.因此高冗余零比例表示具有较大的优化空间,冗余映射则展现读取值的模式,从而为优化策略的设计提供参考.其中,冗余零主要来自3 个方面:数据宽度过大、数据结构使用不当以及0 值相关的无用计算.
1)数据宽度过大是造成访存过程中某个指令或者从某个数据对象读取的值中高位字节总是为0 的主要原因之一.例如,访存指令频繁地从内存读取64b整型值(占8B),且该值的高7B 总是为0,即该访存指令访问了大量的冗余零.造成该冗余零现象的主要原因就是数据宽度过大,该数据使用8b 整型(占1B)即可保证数值的等价性,而不必使用过长的64b整型来存储、访问该数据.这些冗余零会造成有限的多级缓存资源的浪费,从而造成潜在的性能损失.
2)使用不当的数据结构也会造成大量的冗余零,从而造成大量的资源浪费.如图1 所示,使用稠密数据结构与稠密算法对该稀疏数据进行处理会造成大量的完全冗余零.而如果应用稀疏数据结构以及对应的稀疏算法会大幅度减少存储、访存开销,并避免大量无用的0 值相关的计算,从而得到更好的性能.
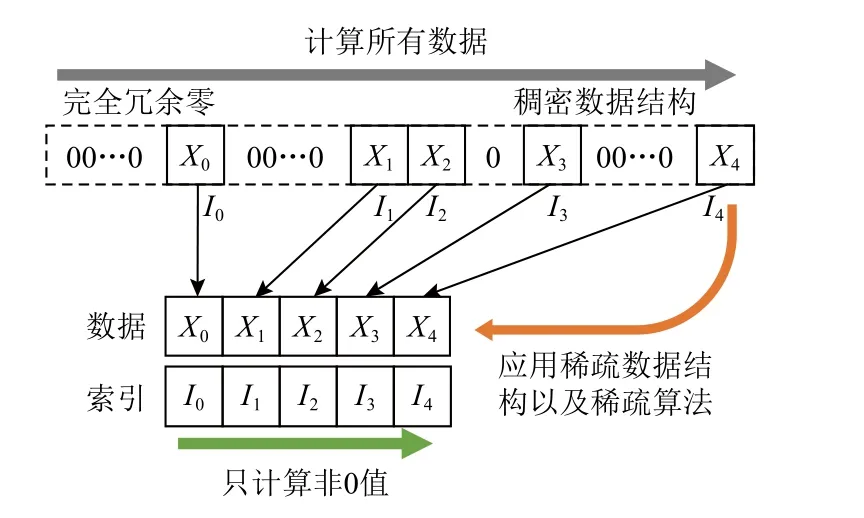
Fig.1 An illustration of software inefficiency by inappropriate use of data structure图 1 使用不当的数据结构导致的软件低效行为示例
3)0 值相关的无用计算则是另一类常见的冗余零来源.图2 展示了bwaves 应用程序中0 值相关的无用计算示例代码.通过DrZero 检测以及人工插桩等细致分析后,该示例代码中u,v,w这3 个变量常常读取完全冗余零(0 值),从而进一步造成在计算mu变量值时引入繁重的0 值相关的无用计算.0 值相关的无用计算并不是所有的冗余零都值得进行优化,原则上高冗余零比例的、复杂且高计算开销的操作更加值得进一步优化.

Fig.2 An example of zero-agonistic computation图 2 0 值相关的无用计算示例
2 相关工作
值得注意的是,传统的基于硬件计数器的性能分析工具[10-15,18]往往由于其中存在的大量冗余访存与计算反而会充分利用硬件资源,从而得到较好的性能结果.因此,若含有大量冗余零的访存、计算操作浪费了大量资源,基于硬件计数器的性能分析工具并不能有效地识别类似冗余零的资源浪费导致的软件低效行为,从而无法给出有效的优化建议.
值分析器(value profiler)的开发是为了查明软件中含有的冗余计算.值分析器最早由Calder 等人[19]提出,它可以检测程序代码并查明存储在寄存器或存储器中的不变变量或半不变变量.其后续研究提出了此值分析器的一种变体[20].Wen 等人[4]开发了一种细粒度的探查器(RedSpy)来识别静默写入(scilent writes)并给出相关指导优化.RedSpy 不但检测到计算结果以及数据移动中的冗余,还可以通过报告调用上下文及其在源代码中的位置来报告冗余,从而精确定位冗余代码区域.此外,Su 等人[1]开发了另一个细粒度的探查器LoadSpy,以识别软件中的冗余负载,他们声称,在软件的指令中加载相同的值效率很低.LoadSpy 跟踪每个加载指令以查明这些冗余负载,并报告涉及冗余负载的指令对.此外,Tan 等人[21]开发了CIDetector,并证明即使使用现代的优化编译器,无效操作和冗余操作仍然存在.ZeroSpy[9]可以查明与零相关的冗余算术和内存操作,但ZeroSpy 基于Intel Pin[22]实现,且ARM 指令集与x86 指令集不同,访存与计算是分离的,所以不能通过指令来识别访问内存数据的类型.因此,ZeroSpy 的检测方法与实现手段都局限在Intel 平台,不能直接应用在跨平台冗余零检测中.
另外,有一些方法致力于通过减少数据类型的长度来利用冗余零.Stephenson 等人[23]提出了一种位宽分析方法来静态标识变量的最大所需位宽,从而尽可能减少数据类型的长度.当在目标FPGA 平台上进行评估时,他们的方法可能对面积、速度和功耗产生积极影响.另一方面,Precimonious[24]工具可用来权衡浮点精度和性能.这些方法与工具都只能检测数据长度中的冗余,而DrZero 还可以检测不适当的数据结构以及零相关导致的冗余计算.此外,DrZero 也不需要任何源代码即可进行冗余零检测.
3 冗余零检测方法
本文提出并实现了针对冗余零的跨平台细粒度性能分析工具DrZero.具体来讲,DrZero 基于Dynamorio动态二进制插桩框架[25]实现.相较ZeroSpy 选用的Intel Pin[22],Dynamorio 具有可跨平台(支持x86 与ARM)、支持细粒度的分析与插桩、开源等特性,从而可以支持跨平台更加细粒度的插桩、分析工具.Dynamorio框架是基于事件来触发分析与插桩过程,例如线程启动和终止、基础块载入等事件.当事件发生时,Dynamorio会触发初始化时注册的回调函数来对目标事件进行分析、插桩.其中,当基础块载入事件发生时,Dynamorio可以获取该基础块将要执行的所有指令,因此DrZero基于各个基础块对所有包含内存读取操作的指令进行分析,并进行基础块级别的动态二进制插桩.DrZero的跨平台冗余零检测技术总览如图3 所示,包含:①基于数据流分析的数据类型推断;②细粒度缓存迹插桩与在线分析.其中,根据检测目标的不同,在线分析又分为以代码为中心的分析模式和以数据为中心的分析模式.在目标程序执行完毕后,DrZero 会生成一系列报告文件,并通过定制的VSCode 扩展来将冗余零报告可视化,并基于检测结果提供优化建议.下文将对DrZero 的各个核心技术进行详细讲解.
3.1 基于数据流的数据类型推断
与x86 指令集不同,ARM 指令集集中访存与计算为不同的指令,即计算操作不能直接访问内存,而同一访存指令可能读取整型值或浮点值.此外,通用寄存器除了保存整型值以外,也可能保存浮点值并在计算时移动到浮点寄存器来进行浮点计算,因此也不能只通过内存读取操作的目标寄存器类型来判断读取值是浮点值还是整型值.为了解决上述挑战,DrZero 采用基于数据流的数据类型推断来尽可能推断出读取值的数据类型,从而可以采用对应的冗余零分析策略来获取冗余映射以及冗余零比例.

Fig.3 An overview of the cross-platform redundant zeros detection techniques of DrZero图 3 DrZero 跨平台冗余零检测技术总览
基于数据流的数据类型推断算法如算法1 所示.由于数据类型中的数据宽度可以直接由访存宽度直接获取,因此算法1 的主要目的在于推断该指令读取值是否为浮点数.首先,算法1 根据目标寄存器类型推断是否为浮点指令(行①).如果目标寄存器为浮点寄存器则推断为浮点指令,返回真值.由于本文主要关注访存指令中存在的冗余零现象,因此只在指令读取内存中的值时才进一步基于数据流进行推断(行②).若该指令读取内存值,算法则枚举所有目标寄存器对象,并对每个目标寄存器对象查找该基础代码块中在该指令后执行的所有指令的源寄存器中是否存在定义-使用关系(行③~⑫),若存在,则返回使用目标寄存器的指令的类型(行⑬).如果上述数据流分析过程都没有找到定义-使用关系,则返回先前推断的instr指令类型(行⑳).
算法1.数据类型推断算法.
在ARM 平台上,算法1 可以有效地识别大部分浮点数内存访问指令,从而应用适当的冗余零分析方法来建立冗余映射并识别冗余零.但由于程序执行过程的不确定性,基础代码块最后的跳转指令的目标地址往往无法静态确定,因此基于数据流的数据类型推断仅受限于单个基础代码块,从而某些存在跨基础代码块的定义-使用关系的浮点值读取指令时可能仍会推断为读取整型值.然而,由于时空局部性的存在,这些推断错误依旧可以认为是较少的,不会影响最终报告的冗余映射与冗余零比例.
3.2 在线细粒度缓存迹分析
为了分析得到所有访存操作读取内存值的冗余映射与冗余零信息,本文提出了在线细粒度缓存迹分析在细粒度缓存区中缓存一定量的访存操作信息并基于该缓存区进行针对冗余零的在线分析来检测冗余零导致的软件低效行为.具体来讲,该过程主要分为4 步:细粒度缓存区的创建、细粒度缓存迹插桩、细粒度缓存迹更新以及在线冗余零分析.
在工具初始化时,DrZero 需要创建细粒度缓存区来保存程序运行过程中内存读取操作的信息,包括目标地址、调用上下文以及读取的值.为了避免插桩后的代码执行时频繁检查读取值的数据类型从而造成繁重的分支操作,DrZero 对每个可能的数据类型都建立缓存区,包括1b,2b,4b,8b 整型值,单、双精度浮点值以及128b,256b 整型向量,单、双精度浮点向量.对于每个缓冲区,DrZero 分配大小为4 096个元素的缓冲区.
在目标应用程序执行时,Dynamorio 会触发基础代码块载入事件.在经过3.1 节所述的数据类型推断后,DrZero 向基础代码块中插入细粒度缓存迹更新以及在线冗余零分析代码.由于读取内存值的数据类型可静态推断,DrZero 根据推断的数据类型来插入相应的指令,向对应缓存区存储目标内存地址、调用上下文句柄(通过DrCCTProf[26]获取)以及读取值.例如,图3 中内存读取操作被推断为32b 浮点类型(FP32),然后插入指令将相应信息缓存到FP32 对应的细粒度缓存迹中以便后续在线分析.此外,在每个基础代码块级别都需要静态推断各个细粒度缓存迹将要填充的数量,并对每个将要填充的细粒度缓存迹都在基础代码块入口进行插桩:
1)插入指令,检查是否将满或溢出;
2)插入条件跳转指令与函数调用,从而保证在将满或溢出时调用在线冗余零分析代码;
3)在在线冗余零分析后清空该缓存迹.
在插桩完成后,Dynamorio 将会负责执行插桩后的代码,因此所有内存读取操作的信息都会被记录到细粒度缓存迹中,并及时更新细粒度缓存迹,以及在将满或溢出时触发在线冗余零分析.该过程也称为细粒度缓存迹更新.在线冗余零分析过程根据检测模式的不同分为以代码为中心的在线分析和以数据为中心的在线分析.由于具体DrZero 的冗余零检测算法与ZeroSpy[9]中的冗余零检测算法类似,本文仅介绍在线分析的核心思想.
1)以代码为中心(code-centric)的在线分析.该分析过程旨在发现指令级别的冗余零现象,可以检测冗余零导致的无用计算以及数据宽度过长导致的资源浪费.由于触发在线分析的细粒度缓存迹都已经静态确定其数据类型,在线分析过程中便不用检查其类型并直接进行冗余零检测.在冗余零检测后,所有检测数据都被记录、累计在以调用上下文句柄为键值的散列映射表中.
2)以数据对象为中心(data-centric)的在线分析.该分析过程旨在发现数据对象级别的冗余零现象,可以检测数据结构使用不当以及数据宽度过长的问题.类似以代码为中心的在线分析,在线分析过程中不用检查其数据类型.数据对象信息则在在线分析过程中通过缓存迹中的目标内存地址从DrCCTProf获取数据对象信息,包括静态数据对象的变量名以及动态数据对象分配时的调用上下文.由于只有静态数据对象与动态数据对象可以获取到足够的调试信息以供后续优化,本文只对静态与动态数据对象进行冗余零检测与报告.
相较ZeroSpy[9]的检测方法,在线细粒度缓存迹分析拥有3 点优势:1)尽可能避免频繁、高开销的算数状态保存操作;2)避免对每次内存读取的值进行分析、记录,从而减轻工具对应用的缓存污染;3)集中批处理冗余零检测与记录操作,具有更好的时空局部性.
3.3 冗余零报告与性能优化指导的可视化界面
为了更好地展示冗余零检测结果,DrZero 提供基于VSCode 的插件来将检测结果可视化.DrZero 的性能报告分为总览(metric overview)和按线程划分的详细报告(detailed metrics).如图4 所示,ZeroSpy 用户界面的总览页面分为全局整数冗余零字节(total integer redundant byte)以及全局浮点数冗余零字节(total floating point redundant byte)两个部分,并分别列出了冗余零与总访问字节.此外,各个线程所统计的冗余零数量以及冗余零比例也可以在此页面查看.按线程划分的详细报告则可通过图4 中“detail”链接查看.DrZero 可以分别生成以代码为中心的分析模式与以数据对象为中心的分析模式报告,其线程详细报告页面如图5 所示.
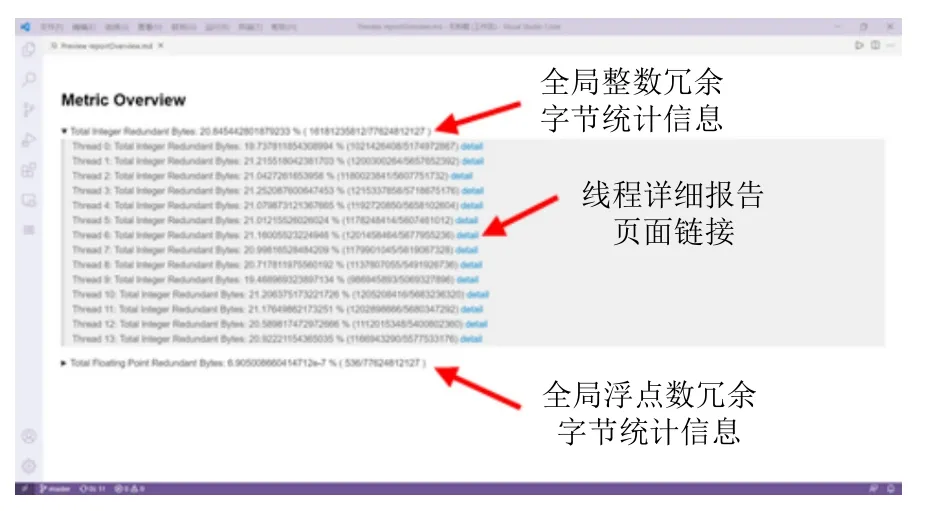
Fig.4 Metric overview page reported by DrZero GUI图 4 DrZero 用户界面报告的总览页面

Fig.5 The detailed report of each thread by DrZero GUI图 5 DrZero 用户界面的线程详细报告页面
1)以代码为中心的分析模式.如图5 所示,各个线程的以代码为中心模式的报告页面分为整数冗余信息以及浮点冗余信息2 个部分.对于以代码为中心的模式报告,页面将会显示发生冗余的程序指令的记录,且每条记录是按照检测到的冗余字节数量从高到低排列.对于每条记录,“Redundancy”是该指令的冗余零在所有检测到的冗余零中的比例,“local redundancy”则是该指令的冗余零在所有执行该特定指令检测到的冗余零中的比例.使用者可以进一步点击每条记录以显示更多冗余零信息,包括完全冗余零占比、指令的冗余映射(从最低到最高).此外,每条记录会给出包含源代码行号与文件路径的调用上下文信息,从而指导开发者进一步的代码优化.
2)以数据对象为中心的分析模式.如图5 所示,各个线程的以数据对象为中心的模式报告页面同样分为整数冗余信息以及浮点冗余信息2 个部分.对于以数据对象为中心的模式报告,页面将会显示发生冗余的静态或动态数据对象的记录,且每条记录是按照检测到的冗余字节数量从高到低排列.对于静态数据对象,每一条记录都会显示对象的名称,以帮助使用者在源代码中定位该静态数据对象.对于动态分配的数据对象,报告会提供其调用上下文信息(CCT info)指示其动态数据对象创建的位置.每条记录均会显示静态或动态数据对象的数据大小、以字节为单位的未访问数据比例信息以及冗余零比例信息.此外,使用者还可以点击“redmap”字样以跳转到链接的数据对象的以字节为单位的冗余映射热力图,如图6 所示.

Fig.6 The heatmap of the dynamic data object with significant redundant zeros in NPB-IS program图 6 NPB-IS 程序中报告大量冗余零的动态数据对象的热力图
4 实验结果与分析
4.1 实验设置
本文使用如表1 所示的x86 和ARM 实验平台对DrZero 进行评测.为了检验DrZero 的跨平台冗余零检测的性能开销以及检测效果,本文选用NASParallel Benchmarks(NPB-3.4)[27]和Rodinia[28]基准测试程序集进行评测.其中NPB 基准测试使用C CLASS输入问题规模.此外,为了评测实际应用规模的冗余零检测能力,本文也选用SPEC CPU2017[29]中的NAB生命科学应用(ref 输入大小)以及Fotonik3D 计算电磁学应用(ref 输入大小)作为案例研究来详细讲解DrZero 的冗余零检测结果以及优化流程.所有程序都使用GCC 11.0-O3-g-fopenmp 编译,并在单个CPU 上(x86 平台上14 线程,ARM 平台上32 线程)并行执行.

Table 1 The Detailed Software and Hardware Configurations of Evaluated X86 and ARM Platform表 1 x86 和ARM 评测平台详细软硬件配置信息
4.2 冗余零识别效果
DrZero 在x86 和ARM 平台上的冗余零检测结果分别如表2 和表3 所示.其中,CC 表示以代码为中心的冗余零分析模式,其冗余零比例按照所有整数或浮点数累计的冗余零数量除以总访问字节数得到,CC 数值越大表明执行过程中冗余零相关的冗余计算、资源浪费越严重;DC 表示以数据为中心的冗余零分析模式,其冗余零比例按照所有数据对象中含有的冗余零数量除以所有数据对象的数量大小之和得到,DC 数值越大表明数据对象的稀疏性越高或潜在的数据宽度过长问题越严重.此外,在x86 和ARM平台上DrZero 使用以代码为中心(CC)以及以数据为中心(DC)的冗余零分析模式的评测,结果对比分别如图7、图8 所示.评测结果证明DrZero 拥有跨平台检测冗余零导致的软件低效行为的能力.此外,本文还展示了在x86 平台上ZeroSpy 与DrZero 报告的冗余零比例的比较,如图7 所示.其中,由于ZeroSpy报告中冗余零比例在CC 与DC 模式下的计算方式相同,本文仅展示CC 模式下的冗余零比例检测比较.DrZero 在大部分测试程序中检测的冗余零比例与ZeroSpy 相当.然而,有些程序的冗余零比例则有较明显的差距(如heartwall).通过细致分析发现,DrZero与ZeroSpy 所检测的冗余零数量差别不大.而由于Dynamorio 不能完全识别所有的指令,DrZero 可能会将有些特殊的访存指令识别为空指令(nop),从而大大低估了总访问字节数.此外,通过图7 所示的同一代码在不同平台上的冗余零比例对比,本文发现虽然某些代码在不同平台上展现一定的冗余零比例的一致性,但仍然有一些基准测试程序在同样的代码、不同平台下的冗余零情况具有较大的差异性(例如LU).这表明x86 和ARM 指令集对程序的针对冗余零的低效行为拥有不同的敏感度.不同指令集之间的冗余零发散现象需要进一步详细研究.
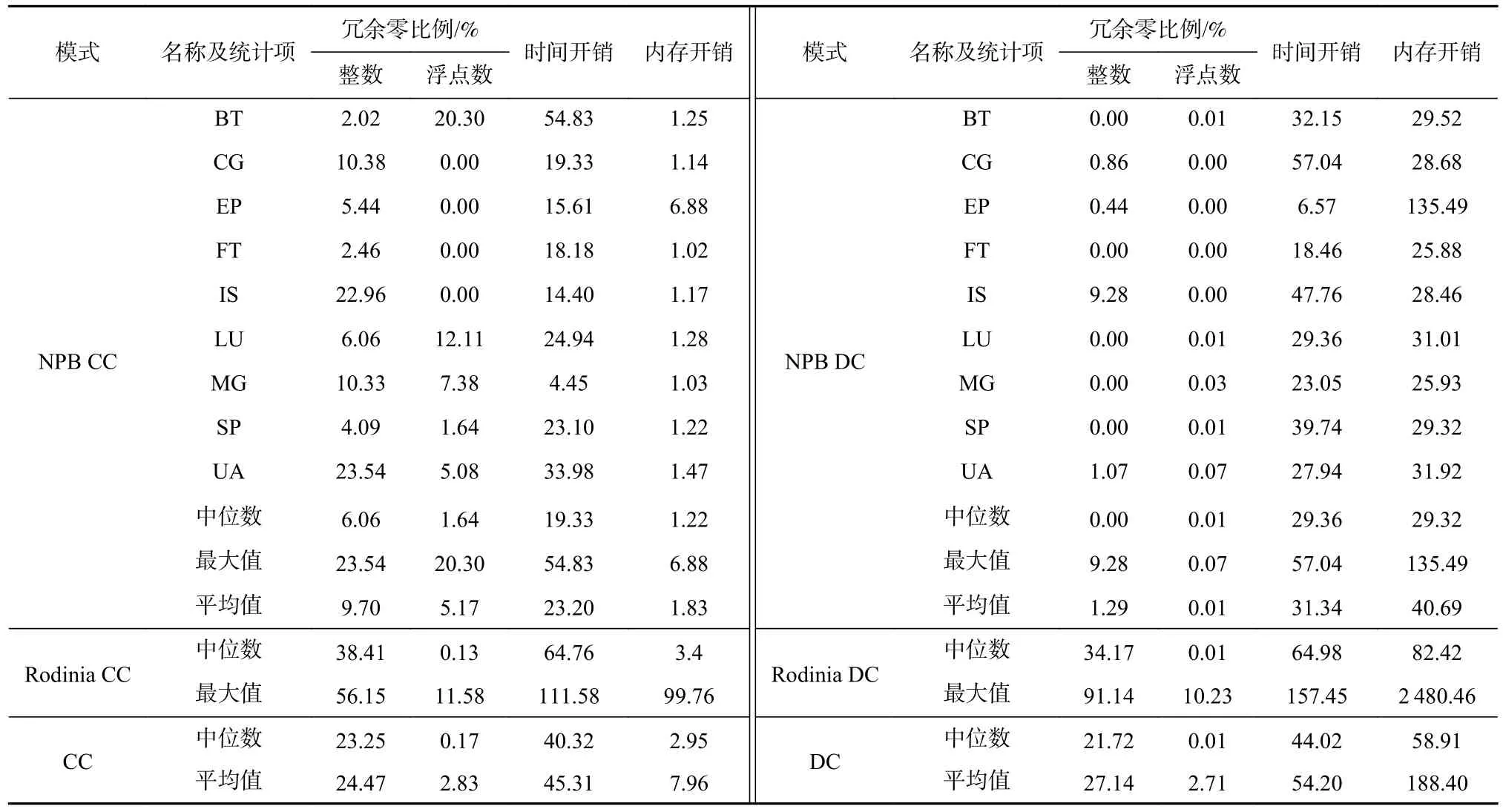
Table 2 Fraction of Redundant Zero and Profiling Overheads Reported by DrZero on x86 Platform表 2 DrZero 报告在x86 平台上的冗余零比例以及检测分析开销

Table 3 Fraction of Redundant Zero and Profiling Overheads Reported by DrZero on ARM Platform表 3 DrZero 报告在ARM 平台上的冗余零比例以及检测分析开销

Fig.7 Fraction of integer(INT)and floating point(FP)redundant zeros reported by DrZero CC mode on x86 and ARM platforms图 7 DrZero CC 模式下分别在x86 和ARM 平台上检测的整型(INT)以及浮点(FP)类型的冗余零含量

Fig.8 Fraction of integer(INT)and floating point(FP)redundant zeros reported by DrZero DC mode on x86 and ARM platforms图 8 DrZero DC 模式下分别在x86 和ARM 平台上检测的整型(INT)以及浮点(FP)类型的冗余零含量
4.3 性能与内存开销
本文评测的DrZero 的性能与内存开销如表2 与表3 所示.实验结果表明DrZero 在x86 平台上的以CC 与DC 性能开销的中位数分别为40.32 倍与44.02倍.与ZeroSpy 所报告的性能开销的中位数64.17 倍(CC)与99.52 倍(DC)相比[9],DrZero 的平均性能开销分别降低了37.2%和55.8%.此外,在ARM 平台,DrZero的CC 和DC 的平均性能开销仅为14.12 倍和13.40 倍,性能开销中位数则仅分别为8.76 倍和10.20 倍.DrZero的性能开销与常见的二进制插装工具[1-4]持平甚至更低,因此具有良好的应用前景.
ZeroSpy(x86 平台运行)、DrZero-x86(x86 平台上运行)以及DrZero-ARM(x86 平台上运行)之间在以代码为中心的和以数据对象为中心的分析模式下的详细性能开销对比分别如图9 与图10 所示.实验结果表明,本文提出的DrZero 在大部分程序下CC 和DC 的性能开销都优于ZeroSpy,并且DrZero 在ARM平台上相较在x86 平台具有更低的性能开销.更低的性能开销主要来自2 个方面:1)DrZero 调用上下文采集基于DrCCTProf 实现,使用性能开销更低的指令内联方式来获取调用上下文,且DrCCTProf 也针对ARM 平台进行高度优化,因此DrZero 调用上下文采集开销相较依赖Intel Pin 的CCTLib[30]更低;2)DrZero的在线细粒度缓存迹分析方法可以有效避免冗余且高开销的频繁算数、寄存器状态缓存操作,从而带来可观的性能提升.

Fig.9 Comparison of the performance overhead of CC mode caused by ZeroSpy,DrZero-x86,and DrZero-ARM图 9 在CC 模式下ZeroSpy,DrZero-x86,DrZero-ARM 上的性能开销对比
如图11 所示,DrZero 在CC 模式下,在x86 平台和ARM 平台上内存开销都普遍低于ZeroSpy.然而,如图12 所示,DrZero 在DC 模式下则相反,其内存开销都普遍高于ZeroSpy.具体情况如表2 所示,DrZero在x86 平台上的CC 和DC 的内存开销中位数分别为2.74 倍和55.68 倍.相较ZeroSpy 所报告的内存开销中位数4.47 倍(CC)和6.56 倍(DC),DrZero 在CC 模式下具有更低的内存开销(降低38.7%),而在DC 模式下具有更高的内存开销(升高8.49 倍).经过进一步分析,DC 模式下DrCCTProf[26]为了更高的性能,将所有已静态、动态分配内存的数据对象的所有地址空间通过影射内存(shadow memory)方法按字节映射、存储其数据对象信息.该方法相较ZeroSpy 依赖的基于Intel Pin 的CCTLib[30]支持的基于树的实现拥有更大的内存开销.此外,由于需要DrZero 的DC 模式下的冗余零检测需要数据对象的起、止内存地址,在扩展DrCCTProf 的数据对象信息实现后,每个数据对象在每个影射位需要存储的信息变为原来的3 倍,使得内存开销问题变得更为严重,甚至在ARM 平台上NPB FP 会超出内存容量(out of memory,OOM)从而无法采集冗余零信息.因此,未来工作需要提出更加内存友好且能保持低开销的数据对象采集方法来替代DrCCTProf 的影射内存方法,以获取更低的内存开销.
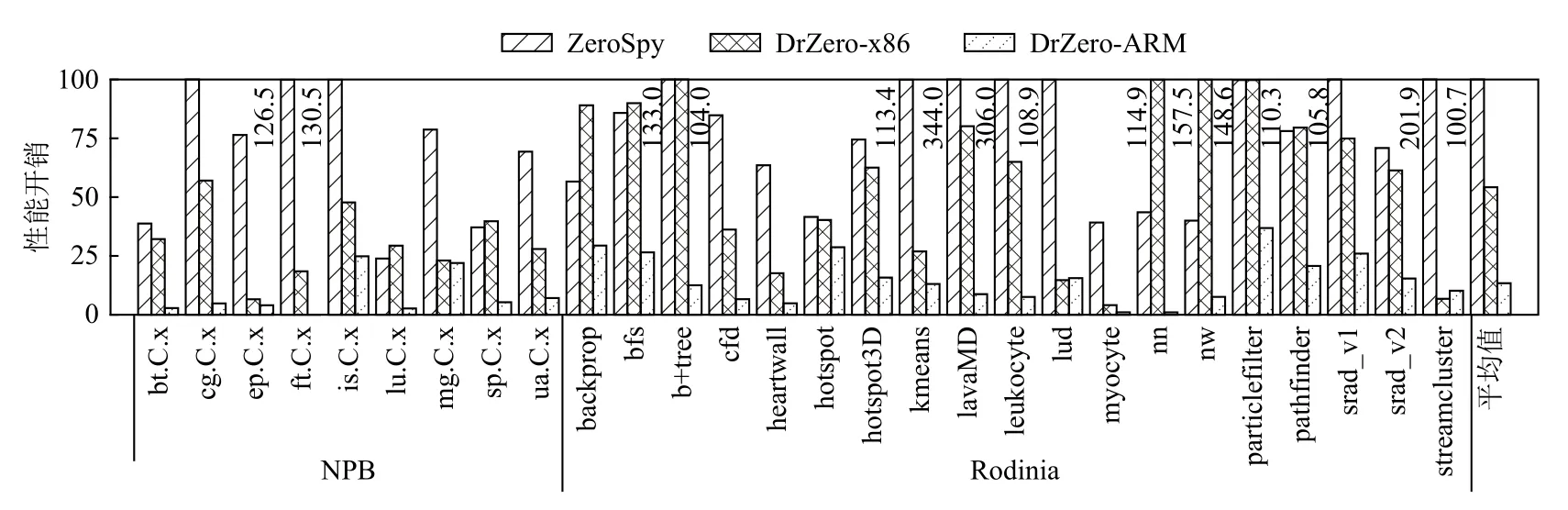
Fig.10 Comparison of the performance overhead of DC mode caused by ZeroSpy,DrZero-x86,and DrZero-ARM图 10 在DC 模式下ZeroSpy,DrZero-x86,DrZero-ARM 上的性能开销对比

Fig.11 Comparison of the memory overhead of CC mode caused by ZeroSpy,DrZero-x86,and DrZero-ARM图 11 在CC 模式下ZeroSpy,DrZero-x86,DrZero-ARM 上的内存开销对比

Fig.12 Comparison of the memory overhead of DC mode caused by ZeroSpy,DrZero-x86,and DrZero-ARM图 12 在DC 模式下ZeroSpy,DrZero-x86,DrZero-ARM 上的内存开销对比
4.4 NAB 案例研究
NAB 是一个包含在SPEC CPU2017 基准测试套件[29]中的分子建模程序.NAB 是生命科学模拟领域典型的计算密集型程序.由于DrZero 报告的NAB 冗余零情况在x86 和ARM 平台上都类似,因此本文仅展示x86 上的冗余零报告结果.DrZero 的以代码为中心的冗余零分析模式检测出NAB 包含11.52%的整数冗余零和6.57%的浮点冗余零.DrZero 报告NAB中产生最多浮点冗余零的指令信息以及其对应于源代码中的位置如图13 所示.
产生冗余零的代码区域如图14 所示,其中*kappa的值频繁为0.由于完全冗余零的比例很高,本文使用基于条件判断的方法(如图15 所示的if/else 语句)来跳过处理冗余零的无用计算.此外,该优化方法还可以通过在进入2 个嵌套循环之前判断*kappa的值来进一步减少分支开销.优化后的代码如图15 所示,类似的优化也应用于具有类似冗余的其他代码区域.经过我们的优化,NAB 在x86 平台实现9.7%的性能加速,ARM 平台上实现6.08%的性能加速.

Fig.13 The operation with the most significant redundant zeros in NAB reported by DrZero CC mode图 13 DrZero CC 模式报告中NAB 产生最多浮点冗余零的指令
4.5 Fotonik3D 案例研究

Fig.14 Code snippet containing the most significant redundant zeros in the egb function of NAB图 14 NAB 的函数egb 中包含最多冗余零的程序片段

Fig.15 Code snippet in the egb function of NAB after optimization图 15 NAB 的函数egb 优化后的程序片段
Fotonik3D 是一个包含在SPEC CPU2017 基准测试套件[29]中的计算电磁学程序,其中包含了计算电磁学程序中常见的计算模式.Fotonik3D 使用麦克斯韦方程组的有限差分时域(FDTD)方法计算光子波导的传输系数.在本文的评测中,Fotonik3D 使用SPEC套件中提供的ref 输入数据集进行评测.由于Fotonik3D在x86 和ARM 上检测的冗余零含量类似,本文仅给出x86 上的DrZero 的冗余零检测结果.DrZero 的以代码为中心的冗余零检测结果表明,Fotonik3D 的执行过程中含有8.76%的整型冗余零以及32.30%的浮点冗余零.通过进一步分析发现,其中数组Ex,Ey,Ez相关的计算都含有大量的完全冗余零.具体情况如图16 中左图所示,在计算过程中,数组Ex,Ey,Ez由大量完全冗余零构成,且其中大量x-z平面数据往往为0,即该数组是结构化稀疏的.因此,稀疏数据使用稠密数据结构以及稠密算法是造成Fotonik3D 应用程序中大量完全冗余零及其相关无用计算的根本原因.

Fig.16 Large fraction of redundant zeros in Fotonik3D图 16 Fotonik3D 中含有大量冗余零
为了优化并消除冗余零造成的冗余计算,本文针对该应用数据特点对结构化稀疏数据结构以及对应的算法进行设计.如图16 中右图所示,原Ex,Ey,Ez数组的三维数据存储格式由原来的(x,y,z)的存储顺序改为按照(x,z,y)顺序存储,使得x-z平面在内存中得以连续存储;此外,数组稀疏存储格式按照类似稀疏矩阵格式[31]进行存储,即数组中仅存储非零x-z平面,并将对应y轴方向上的坐标值记录在下标向量Indexy中.经过本文所提出的优化,Fotonik3D 在x86 平台上实现1.76 倍的性能加速,在ARM 平台上实现2.12 倍的性能加速.
5 结束语
本文提出了一个针对冗余零的跨平台细粒度性能分析工具DrZero.为了适配访存、计算指令分离的ARM 指令集,本文提出了基于数据流分析的数据类型推断方法来自动推断访存指令读取内存数据的数据类型.此外,为了更低的性能开销,本文也提出了在线细粒度缓存迹分析来检测、记录冗余零相关的指标.DrZero 也提供了基于VSCode 的可视化插件来展示冗余零检测报告以及相应的优化建议.本文的实验展示了DrZero 跨平台检测冗余零的能力.DrZero在以代码、数据为中心的冗余零分析中,分别以x86和ARM 平台45.31 倍、54.20 倍和14.12 倍、13.40 倍平均性能开销检测冗余零并给出优化建议.基于DrZero 给出的性能优化指导,本文优化的应用程序在x86 和ARM 上分别达到了最高1.76 倍和2.12 倍的性能加速.DrZero 的实现代码已经开源:https://github.com/buaa-hipo/ZeroSpy-drcctprof.
在未来,我们认为还有3 个问题需要解决.首先,在ARM 平台上数据对象信息采集需要过大的内存开销,这导致运行使用较多内存的应用无法使用以数据为中心的分析模式进行分析,从而错失一些潜在的优化机会.其次,本文发现的x86 和ARM 平台之间同一代码下冗余零的发散现象需要进一步研究其原因,以便挖掘更多的性能优化机会.最后,希望将来更多的ARM 平台(例如天河三号原型机中使用的国产ARM 处理器FT2000+)中测试本文提出的DrZero工具来发现更多的性能优化机会.
作者贡献声明:游心提出研究思路,设计实现研究方案,撰写论文;杨海龙负责论文起草以及最终版本修订;雷克伦负责采集实验数据并实现可视化界面;孔祥浩负责实现ARM 平台部分功能;徐筠、栾钟治、钱德沛负责最终版本修订.
猜你喜欢
红外技术(2022年11期)2022-11-25 03:20:40
电子元器件与信息技术(2021年5期)2021-07-27 03:48:14
高技术通讯(2021年1期)2021-03-29 02:29:24
数码世界(2020年5期)2020-06-23 00:14:36
当代陕西(2019年13期)2019-08-20 03:54:22
电脑与电信(2018年11期)2018-02-16 05:41:32
信息安全研究(2016年3期)2016-12-01 06:06:41
测绘科学与工程(2014年5期)2014-02-27 07:06:14
电脑爱好者(2009年13期)2009-07-07 09:52:52
智能计算机与应用(2005年5期)2005-04-29 00:44:03
