
基于公共情感特征压缩与融合的轻量级图文情感分析模型
2023-05-22 11:59:46甘臣权冯庆东祝清意
计算机研究与发展 2023年5期
甘臣权 付 祥 冯庆东 祝清意
1(重庆邮电大学通信与信息工程学院 重庆 400065)
2(重庆邮电大学网络空间安全与信息法学院 重庆 400065)
情感分析原本是指提取分析文本中表达的态度、情绪和观点,是自然语言处理的一项基础性任务[1],一直以来都受到国内外学者的广泛关注.近年来,随着网络的迅速发展和社交平台的普及,人们不再满足于使用单一的文本而更乐于联合图像和文本等多种载体表达自我和相互沟通.由于图像也反映了用户的观点,联合图文的多模态数据包含了更加丰富的情感信息.因此,对图文等多模态数据的情感分析有助于进一步了解人们对热门话题或某些重要事件的立场和态度,这在民意调查[2]、票房预测[3]、产品分析[4]和推荐系统[5]等方面存在巨大的应用价值.
传统的情感分析大多只针对文本[6-9],其中一些工作通过训练词向量[6]完成对文本的情感分析,另一些则在此基础上利用深度学习的方法改进了模型性能[7-9].然而,这些工作都忽略了图像包含的情感和观点.随着多模态数据在其他自然语言处理任务上的应用取得成功[10],许多学者也尝试同时提取文本和图像中的观点信息进行情感分析[11-12],但他们忽略了文本和图像之间的信息关联.于是,通过深度学习在特征层面上融合图文信息进行情感分析的方法取得了不错的效果[13-19],然而这些方法需要消耗较多的资源提取融合图文特征,且不能准确快速地学习数据的情感倾向.因此,如何准确有效地融合文本特征和图像特征是图文情感分析的一大挑战.而如何减少模型参数,让模型快速地学习图文的情感倾向,并用于工业部署则是另外一个值得研究的问题.
为解决上述问题,本文提出了一种轻量级的图文情感分析模型.在该模型中,降低了图文特征维度,提取融合了包含图文共享情感信息的公共情感特征,并通过情感分类器实现图文情感分析.概括来说,本文贡献主要有3 个方面:
1)提出了一种基于公共情感特征压缩与融合的轻量级图文情感分析模型,通过压缩图文特征后再融合公共情感特征,更有效地提取图文的情感信息,从而实现了有效的情感分析;
2)采用图文特征压缩模块降低特征维度,并提出一种门控机制的公共情感特征融合模块提取并融合包含图文共享情感信息的公共情感特征,减少了冗余信息,降低了模型参数量;
3)在Twitter,Flickr,Getty Images 这3 种真实世界的基线数据集上对本文模型进行了验证,与早期和最新模型相比,本文模型能够以更小的参数量获得更优的情感分析性能.
1 相关工作
1.1 文本情感分析
早期的文本情感分析侧重识别每个词的情感语义.如在文献[6]中,就提出了一种混合有监督和无监督的混合模型,它通过学习词向量来捕捉文本的语义信息和情感内容.这种方式虽然简单迅速,但忽略了词间关系,在长文本上的情感分析中并不理想.于是,Atzeni等人[7]提出采用一种依赖注意力机制和双向长短期记忆(bi-directional long short-term memory,BiLSTM)的模型,在微调后的词向量上获取词间关系,学习情感分布.此外,在文献[8]的工作中,词向量被分别送入卷积神经网络(convolutional neural network,CNN)和双向门控循环单元(bi-directional gated recurrent unit,BiGRU)中来提取文本的局部特征和词间关系,丰富了文本的特征表达.类似地,文献[9]将词向量分别送入BiLSTM 和BiGRU 中获取词间关系,再由CNN对文本特征进行降维,进而实现情感分析.这些模型都通过深度学习较为有效地学习了文本的词间关系,实现了情感倾向分类.然而,在文献[7]中,微调词向量的单独训练和维度较高的文本特征会加大后续处理的资源开销;文献[8]中并行使用CNN 和BiGRU的方式难以减少文本特征中的冗余信息;文献[9]中将BiLSTM 和BiGRU 的输出送到CNN 中的方式在降维之前或许会消耗较多资源,提取不相关的信息.这些工作为本文的文本特征提取部分提供了思路.
1.2 图文情感分析
有研究发现,利用多种模态信息(如图像和文本)比只利用文本信息的情感分析更加有效[20].一些学者尝试采用晚期融合的方法,通过集成图像和文本情感分类器的分类结果提高情感分析的正确率[11-12].早在2013 年,文献[11]就通过分别对图文情感分类器预测的情感得分分配不同的权重并相加来判断情感倾向,但该工作采用的手工图文特征在大数据环境下并不能有效捕捉情感分布.于是,文献[12]通过深度学习获取图文特征并分别用于文本情感分析、图像分析和图像内容分析,与文献[11]类似,再将这3个部分的得分进行加权融合,提升了模型性能.虽然这类晚期融合的方法在一定程度上提高了模型在图文情感分析任务上的表现,但由于这种方法是独立地对图文信息进行分析,忽略了图文之间的情感相关性,使得模型不能有效地联合利用图文信息.You等人[13]在2016 年将微调CNN 提取的图像特征与词向量组成多模态特征,并采用跨模一致性回归进行训练,进而实现图文情感分析,但由于其提取特征的方式较为简单,致使多模态特征中包含的图文情感信息不够丰富,无法有效提升模型的情感倾向分类能力.后来,文献[14]采用深度CNN 分别提取了更加丰富的图文特征,并将它们连接成联合特征送入到分类器学习情感分布.相比于晚期融合,这种在特征层面融合图文信息的早期融合方式对图文信息的联合利用更加深入,但其忽略了图文特征间存在的异构性,使得在融合过程中容易引入噪声和冗余.
上述对图文信息进行联合分析的2 类方法由于自身的局限性导致它们在情感分类的性能提升上并不理想.于是,另一些学者尝试改进融合方式或设计不同的注意力机制,加深图文信息的融合程度,从而提高模型性能[15-19].文献[15]除了分别应用深度CNN和长短期记忆(long short-term memory,LSTM)进行图像情感分析和文本情感分析,还融合了提取的图文特征进行多模态情感倾向分类,最后采用晚期融合的方式综合这3 个部分的结果,这样在特征层面和决策层面融合图文信息,能较深地获取图文间的关系,提高情感分析的准确率.文献[16]将图像的视觉特征映射到文本特征空间,通过视觉语义注意力机制提取与文本相关的特征来获取图文间的情感相关性,并设计了一种门控长短记忆力网络来融合图文特征,通过自注意力机制进一步提取情感信息,这种方法在一定程度上消除了图文特征间的异构性,减少了冗余信息.区别于文献[15-16],Zhang 等人[17]从图像重要的视觉区域中提取特征,采用注意力机制将这些视觉特征与文本特征融合,并通过一种类别词典来建立图像内容对文本语义的依赖,获得更丰富的情感信息.此外,文献[18]提出的双向多级注意力模型先将图像分割成不同的目标,再通过注意力机制学习更丰富的图文相关信息.类似地,Yang 等人[19]通过图神经网络提取文本特征和图像的目标特征、场景特征,并采用多头注意力交互机制学习特征间的相关性的同时进行特征融合.
这些模型更加深入地学习了图文之间的相关性,提高了模型性能.但它们基本采用VGG19[21]或ResNet-50[22]等模型先行提取图像特征,使得特征维数较高,并且学习的图文相关信息较为模糊.为更全面地学习图文相关信息,需要提取更丰富的特征,这使得模型参数量增大,不利于部署应用.而在其他多模态任务如多模态聚类中,一些学者将不同模态的信息划分为共享信息和私有信息来更加清晰地学习模态间的相关信息[23].类似地,在视频多模态情感分析中,Wu等人[24]利用Transformer 获取不同特征间的共享表示和私有表示来提升模型性能,增强模型的健壮性.文献[23-24]证明了模态间的共享信息和私有信息对情感分析的积极作用,其中,共享信息的作用尤为显著.
受此启发,本文提出了一种基于公共情感特征压缩与融合的轻量级图文情感分析模型.此模型针对上述图文情感分析模型特征维度高等问题,提出了一种图文特征压缩模块,利用卷积层和全连接层在提取图文特征的同时也进行压缩,降低了特征维度.此外,还设计了一种公共情感特征融合模块,通过将压缩后的图文特征映射到相同的情感空间来消除特征异构性,进一步提取并融合包含图文共享情感信息的公共情感特征,减少冗余信息.结合这2 种模块,使得本文模型在提高性能的同时大大减少了参数量,更易于实际部署应用.
2 本文所提模型
如图1 所示,本文提出的基于公共情感特征压缩融合的轻量级图文情感分析模型主要包含3 个部分:特征提取、公共情感特征融合和情感分类.在特征提取部分,设计了文本特征压缩模块和图像特征压缩模块分别对文本特征和图像特征压缩降维,减少模型参数.在公共情感特征融合部分,设计了公共情感特征融合模块提取并融合图文公共情感特征,去除冗余信息,提高模型效率.在情感分类部分,将公共情感特征送入到分类器实现情感倾向的预测.
2.1 特征提取
特征提取分为文本特征提取与压缩、图像特征提取与压缩2 个部分,分别用于提取压缩文本特征和图像特征.
2.1.1 文本特征提取与压缩
文本是情感最主要的表现形式之一,在图文情感分析中,文本特征的提取直接影响到模型的性能.
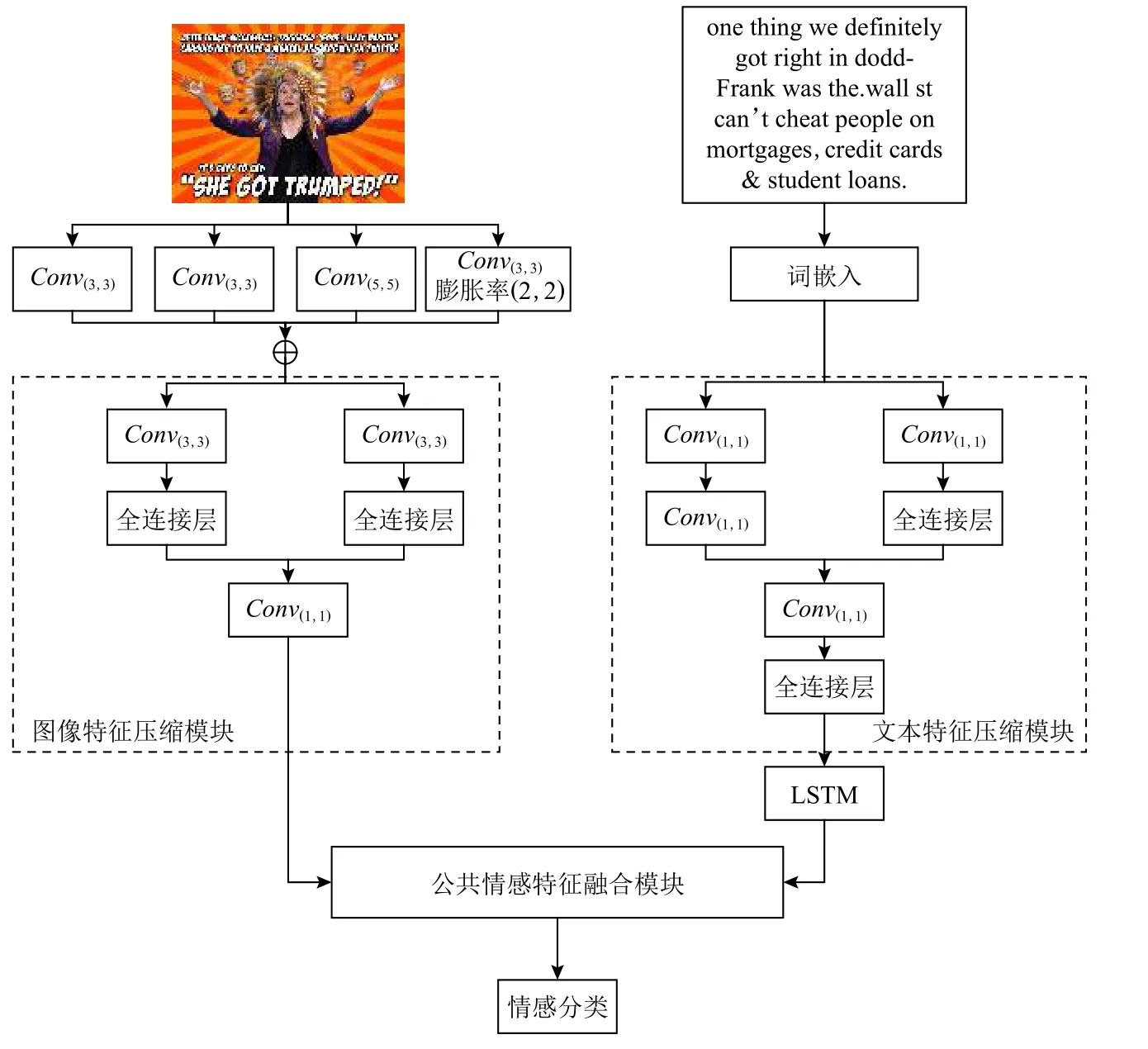
Fig.1 Model processing flow chart图 1 模型处理流程图
对于输入的原始文本,本文所提模型采用词嵌入的方式将文本w1,w2,…,wm映射为词向量t1,t2,…,tm,其中m代表文本的单词数.为方便处理,对于长度大于k和小于k的文本,分别通过裁剪和零填充的方式处理使输入文本长度固定为k.于是,输入的文本词向量矩阵T表示为
其中 ⊕为连接符号,T∈Rd×k,d代表词向量维度.由于输入的词向量矩阵不一定契合模型,故需要对其进行微调,微调后的词向量矩阵将被送入文本特征压缩模块提取文本特征.如图1 所示,文本特征压缩模块主要由卷积层和全连接层组成,该模块采用卷积层提取文本特征P1和P2.由于P1和P2维度较高,不便于计算,故采用全连接层和卷积层分别从整体和局部压缩特征:
其中W1,b1是全连接层的训练参数.为保证特征的丰富性,将连接Q1和Q2得到的特征送入到卷积层和全连接层充分融合:
其中W2,b2是全连接层的训练参数,Q是对Q1和Q2充分融合后的特征.
不同于文献[8-9],由于Q是经过压缩后的特征,故采用LSTM[25]即可建模特征序列的依赖关系,提取出包含词间关系的文本特征E:
其 中LLSTM(·)代表LSTM 函数,θ是LSTM 中的训练参数.
2.1.2 图像特征提取与压缩
图像应用广泛,可以承载丰富的情感信息.在图文情感分析中,图像可以对文本情感信息进行补充,提高模型对情感倾向的判别能力.
为方便本文所提模型处理不同图像,输入的原始图像需要先处理成相同的形状.在图像特征提取中,首先采用不同卷积提取图像I不同尺度的低级特征以获取丰富的情感信息,然后进行加权加性融合,得到多尺度低级特征.
2.2 公共情感特征融合
多数情况下,2.1.2 节提取的图像特征G和文本特征E中的情感信息并不完全一致,而图文情感分析任务主要关注的是图像与文本的公共情感倾向.因此,为提取公共情感特征和提高模型判别效率,本文设计了一种基于门控机制的公共情感特征融合模块,其结构如图2 所示.
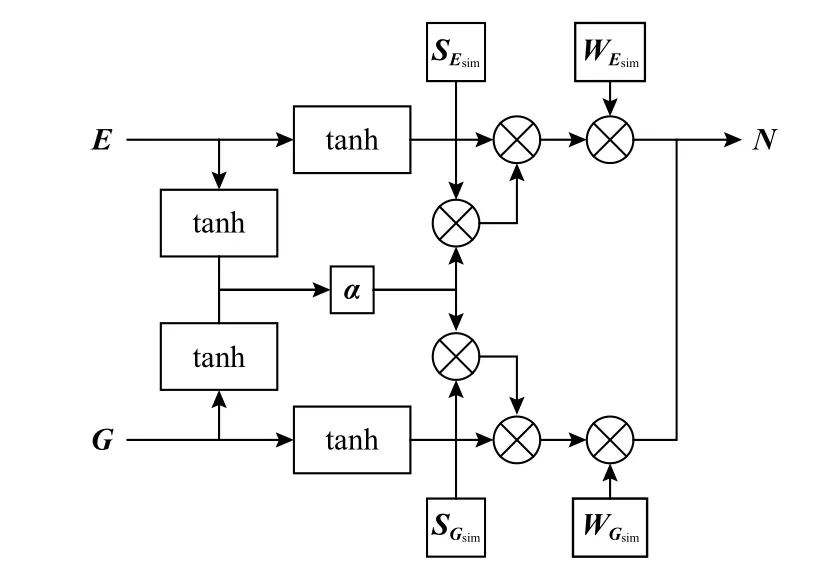
Fig.2 Structure of public emotion feature fusion module图 2 公共情感特征融合模块结构
在提取图文公共情感特征前,为消除不同模态特征的异构性,需要将文本特征和图像特征映射到相同的情感空间中,具体为
为提取图文公共情感特征,首先采用谷本系数(Tanimoto coefficient)[26]计算不同模态特征间的相似度 α:
其中Esim,Gsim分别代表文本公共情感特征与图像公共情感特征.
为充分有效利用图文特征中的共享情感信息,采用加权连接的方式融合图文特征Esim,Gsim,得到公共情感特征N:
2.3 情感分类
在得到公共情感特征N后,本文利用一个情感分类器计算情感概率分布,实现情感分析.
首先,将送入的公共情感特征N映射到情感倾向的判决空间.然后,为了增强模型的鲁棒性和改善分类效果,添加了1 个偏置项来调整公共情感特征N的分布.最后,通过激活函数softmax计算概率分布M.具体为
其中WM,bM分别是分类器的训练权重和偏置.为保证分布结果的一致性和优化的高效性,采用交叉熵作为损失函数:
其中Mij表示1 个批次中第i个样本的情感概率分布M在第j个维度上的数值,Yij表示1 个批次中第i个样本编码后的真实标签在第j个维度上的数值,n代表每个训练批次的大小.于是,利用反向传播,就可以通过最小化损失函数来训练模型.
3 实验分析
为验证本文所提模型的有效性,本文模型与最新的图文分析模型[13,15-17]进行了对比验证,并进行了自我消融实验分析与样例分析.
3.1 数据集
本文搜集了Twitter,Flickr,Getty Images 这3 个基线数据集用于实验验证,数据集详情如表1 所示.
1)Twitter.从文献[27]中收集10 万条带有图像的推文,采用VADER[28]进行情感标注,并过滤掉重复低质量的样本,选取VADER 评分靠前的样本组成图文数据集.
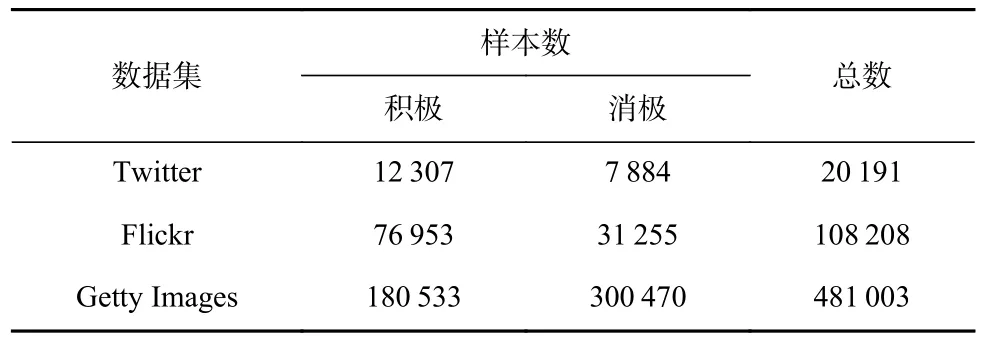
Table 1 Dataset Distribution表 1 数据集分布
2)Flickr.删除从Flickr[29]收集数据中的文本超过100 个单词和少于5 个单词的样本后重新组成的数据集.
3)Getty Images.Getty Images 是一家图片库机构,其中的图像通常带有文本描述,并可通过搜索系统查询.受文献[29]启发,从平衡情感词表中收集37 个积 极(positive)词 和64 个消极(negative)词用于 在Getty Images 查询得到数据样本,组成数据集.
3.2 对比模型
为全面评估模型,本文选取了最先进的图文情感分析模型作为对比进行实验分析,并去掉所提模型的关键部分作为消融对比模型进行消融实验分析.
选取的最先进的图文情感分析模型具体为:
1)图像情感分析模型OIG[22].用微调后的预训练模型ResNet50[22]提取图像特征,通过softmax分类器实现情感分析.
2)文本情感分析模型OTT[30].将词向量矩阵[30]送入softmax分类器实现情感分析.
3)早期融合模型EFIT[22,30].将OIG 中的图像特征[22]和OTT 中的词向量矩阵[30]连接在一起,送入到softmax分类器实现图文情感分析.
4)晚期融合模型LFIT[22,30].取OIG 情感得分与OTT 情感得分之和的平均值作为图文情感分析的情感得分.
5)CCR[13].一种用于图文情感分析的跨模态一致性回归模型.
6)DMAF[15].提出了2 种独立的单模态注意力机制,得到分别基于图像和文本2 种模态的情感预测模型,并与一种多模态注意模型通过晚期融合结合,构建了一个深度多模态注意力融合模型.
7)AMGN[16].采用视觉语义注意力机制提取视觉特征,并采用门控LSTM 融合图文特征,构建了一种基于注意力的多模态门控模型.
8)SCC[17].采用一种类别词典处理文本的语义特征,通过内类依赖LSTM 获取跨模态非线性相关性,构建了一种基于深度匹配和层次网络的交叉模态语义内容关联模型.
由于当前所有文献的数据集样本量各不相同,故这些实验结果都无法直接对比.为保证对比的公平性,所提模型将分别在本文数据集和最新文献[17]的数据集上进行实验分析.其中,在本文数据集上,我们对前7 种模型[13,15-16,22,30]进行了复现并与之对比.进一步地,为展示所提模型的优越性,在最新文献[17]的数据集上,与文献[17]模型SCC 进行了对比.
为验证本文所提图文特征压缩和公共情感特征融合的有效性与合理性,需要去除核心模块图文特征压缩(FE)和公共情感特征融合(PE)并忽略词向量矩阵微调(WR),进行消融实验.具体的方案有:
1)MF.用一般卷积层代替图文特征压缩模块,用连接融合代替公共情感特征融合模块,不采用词向量微调的基本模型.
2)MF+FE.在基本模型上加上图文特征压缩模块,用连接融合代替公共情感特征融合模块的模型.
3)MF+FE+PE.在基本模型上加上图文特征压缩模块和公共情感特征融合模块的模型.
4)MF+FE+PE+WR(本文).在基本模型上加上图文特征压缩模块、公共情感特征融合模块,并对词向量进行微调,是本文提出的模型.
为消除不同数据预处理方式对模型性能的影响,保证实验分析的有效性和可靠性,所有模型的输入数据都采用本文的预处理方法处理.
3.3 参数设置
在整个实验中,将原始图像处理成224×224的RGB 图像作为模型的图像输入,用于提取图像低级特征的卷积层分别是2 个卷积核大小为(3,3)的卷积层、1 个卷积核大小为(5,5)的卷积层、1 个卷积核大小为(3,3)且膨胀率(dilation rate)为(2,2)的空洞卷积层(dilated convolutional layer)[31],卷积核数量都为3,文本的输入序列长度k=50,采用Word2Vec[30]技术将文本中每个单词训练成128 维的词向量.文本特征提取部分的激活函数采用tanh 函数,图像特征提取部分的激活函数采用relu函数.在训练过程中,优化器使用Adam[32],损失函数采用交叉熵.为防止过拟合,在2 个加权融合之后采用最大池化(max-pooling)处理.为提高结果的可靠性,采用5 折交叉验证法(5-fold cross-validation)[33]用于训练和测试,其中对每一折而言,将20%的样本作为测试集,剩下样本中的10%作为验证集、90%作为训练集.其他训练参数设置如表2 所示.
此外,本实验采用正确率(accuracy)、查准率(precision)、查全率(recall)和F1(F1-score)这4 个指标作为评价指标.
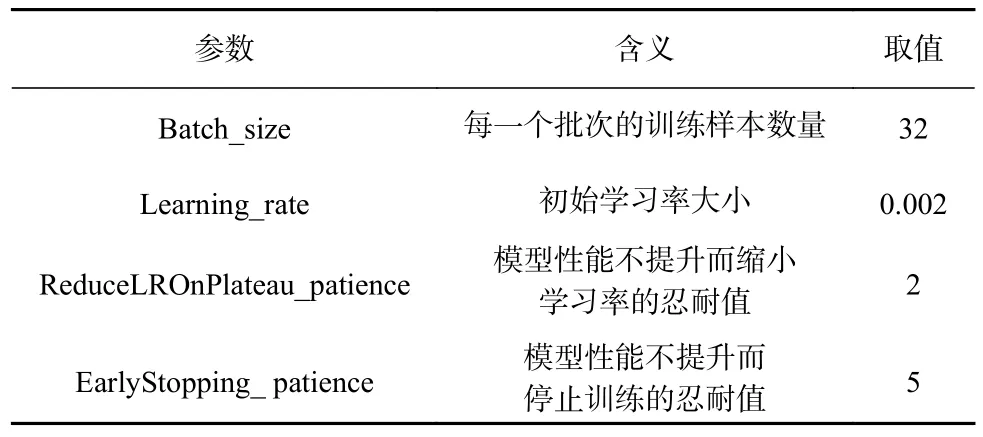
Table 2 Experimental Training Parameter Setting表 2 实验训练参数设置
3.4 实验结果与分析
根据3.3 节所述的参数设置,将本文模型与所有对比模型在最新文献[17]的数据集上进行对比分析,并在Twitter,Flickr,Getty Images 上与3.2 节所述的前7 种模型进行对比分析与消融实验,还结合了具体样例进行分析.
3.4.1 对比实验
在Twitter 数据集上的实验结果如表3 所示.可见与7 种对比模型相比,本文模型在该数据集上的表现更为优越.因为OIG,OTT 只分别利用了图像数据和文本数据,所以性能较差.而OTT 效果比OIG 好很多,这大概是因为该数据集的标签是基于文本的弱标签.EFIT,LFIT 虽然融合了图文信息,但对模型性能的提升效果并不理想,证明了简单的早期融合和晚期融合方式并不能有效融合图文信息.在3 个最新图文情感分析模型中,AMGN 在Twitter 数据集上的表现最好,而本文模型在4 个指标上都超越了AMGN.原因是在本文模型的公共情感融合模块是将图文特征映射到相同的情感空间中,相比AMGN 将图像特征映射到文本特征空间的方式,消除特征异构性的效果更佳.此外,本文提取融合图文公共情感特征的方式能更精确地提取图像和文本中的有用情感信息以进行更有效的情感分析.
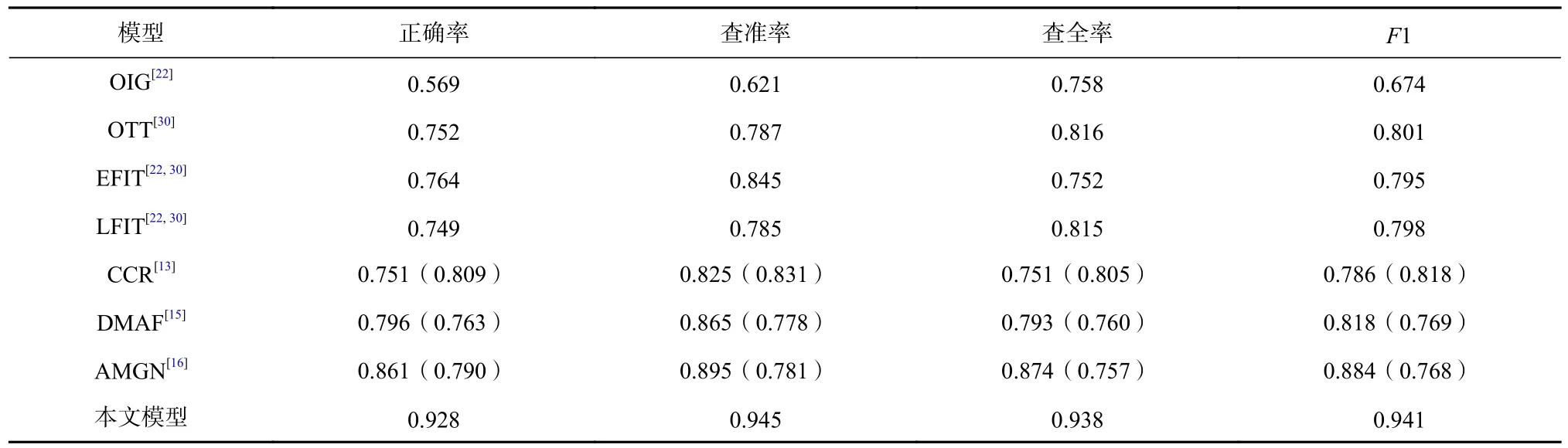
Table 3 Comparative Experimental Results on Twitter Dataset表 3 Twitter 数据集上的对比实验结果
在Flickr 数据集上的实验结果如表4 所示.CCR的正确率略高于DMAF,这大概是Flickr 数据集中积极情感样本数更多,情感表达更显著的原因.相比CCR,DMAF,AMGN 这3 种最新模型,本文模型在正确率、查准率和F1 这3 个指标上取得了更优的效果.但在查全率上本文模型并未得到最高分数,原因是Flickr 数据集的积极样本数更多,而在本文模型中提取的公共情感特征更加均衡,能同时有效地学习积极情感和消极情感.
由于CCR 采用与其他模型不同的损失函数,最佳收敛时的损失值与其他模型相差较大,于是通过前10 次迭代的归一化损失值收敛曲线来进一步分析模型在Flickr 上的收敛情况,如图3 所示.本文模型相比其他模型能更快地收敛到最优值,说明本文模型能够更快、更准确地学习到图文中的情感信息.此外,CCR 的收敛速度仅次于本文模型,证明CCR 中的跨模一致性损失能够加快模型收敛速度.
在Getty Images 数据集上的实验结果,如表5 所示.表5 表明,本文模型在该数据集上的表现比在Twitter 和Flickr 两个数据集上更好,这是因为Getty Images 数据集中的样本更加正式,样本间的情感关联性更强.在该数据集上,本文模型依然具有更优的性能,这是因为经过图文特征压缩模块压缩后,图文特征能包含更大比重的情感信息,再经由公共情感特征融合模块,可以更精准地学习情感分布.而AMGN 的性能低于DMAF,说明在该数据集上,运用多种融合方式对提取情感信息更加有效,同时证明相比AMGN,DMAF,本文模型的鲁棒性更好.此外,EFIT 在该数据集上的表现不如LFIT,说明若不消除图文特征间的异构性,在数据情感关联性更强的情况下,早期融合不如晚期融合有效.

Table 4 Comparative Experimental Results on Flickr Dataset表 4 Flickr 数据集上的对比实验结果
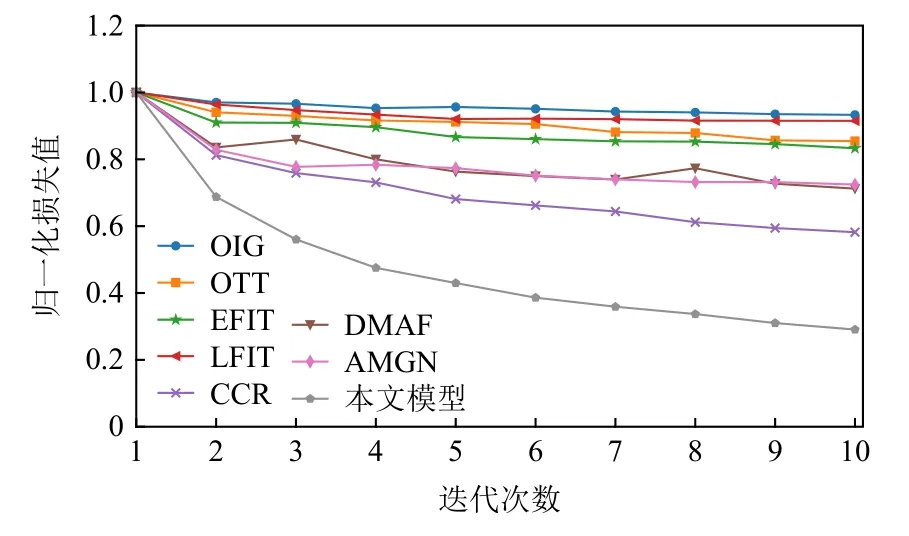
Fig.3 Convergence curve of normalized loss value图 3 归一化损失值收敛曲线
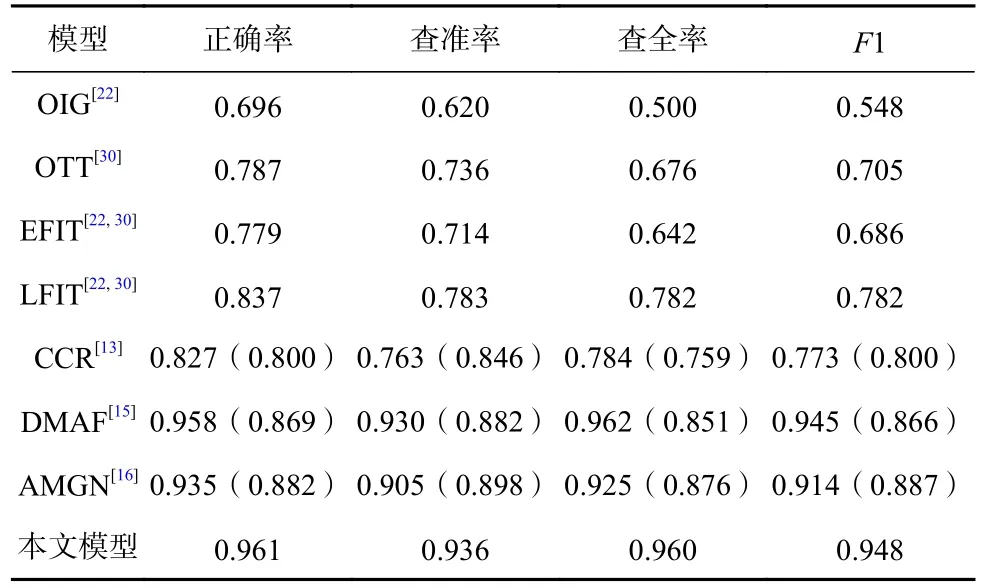
Table 5 Comparative Experimental Results on Getty Images Dataset表 5 Getty Images 数据集上的对比实验结果
为进一步验证模型在Getty Images 上的稳定性,在图4 中展示了模型在该数据集上5 折验证的正确率.可以发现,DMAF 和本文模型在每折上都展现了更高的正确率且变化更小、更加稳定,证明本文模型能够更加稳定有效地进行情感分析.
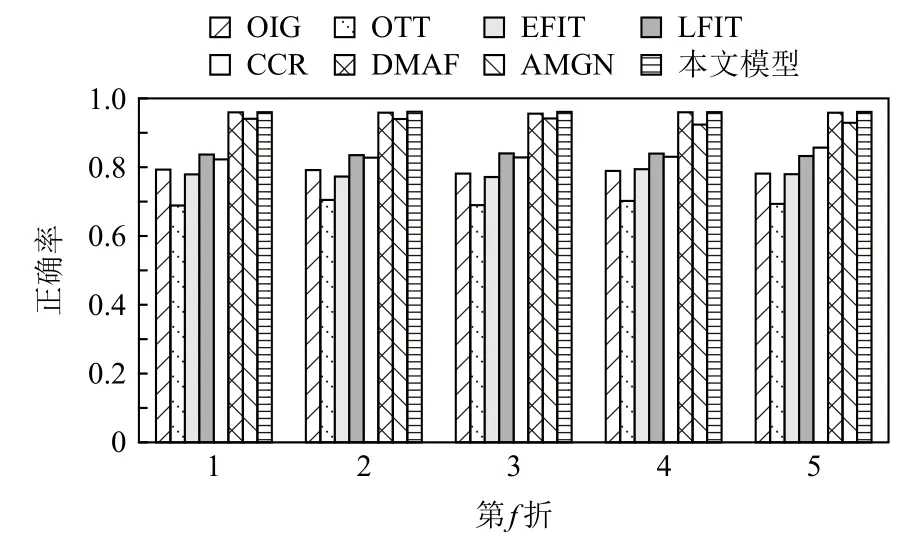
Fig.4 Accuracy of 5 folds on Getty Images图 4 Getty Images 上5 折的正确率
在这3 个数据集上,本文提出的模型都有较好的表现,证明其在图文情感分析任务上是有效的.而对比模型的结果与原文献的结果都存在差别,主要是因为数据集的样本和数据预处理方式与原文献有所不同.
为验证所提模型的轻巧性,在3 个数据集上采用相同的超参数,通过数据集各自的文本得到的Word-2Vec 词典对所提模型与对比模型分别训练,并进行参数比较,如图5 所示.
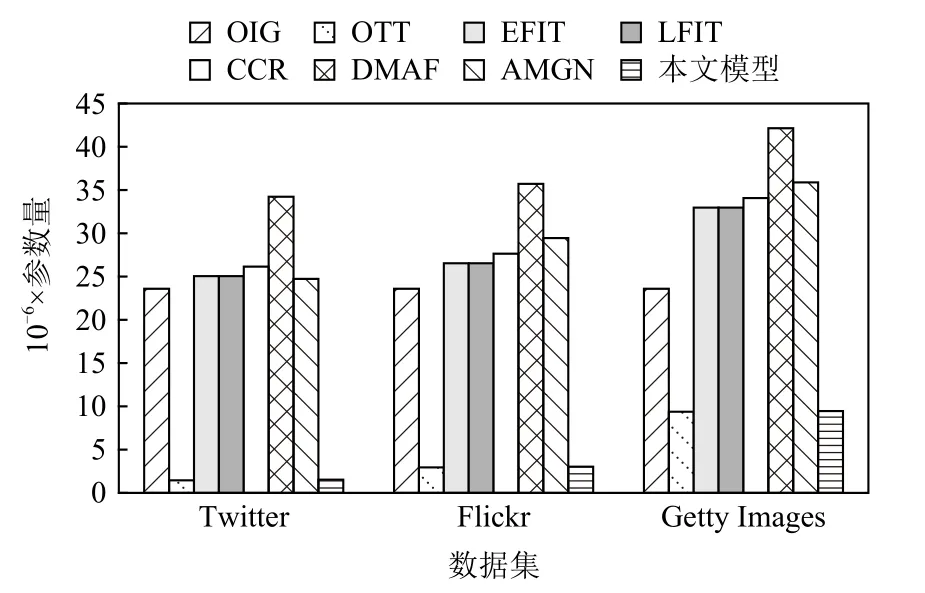
Fig.5 Comparison of model parameters图 5 模型参数量对比
由图5 可知,DMAF 的参数量最多,OTT 参数量最少;本文提出的模型参数量仅多于OTT 且远少于DMAF 和AMGN,原因是本文模型中的图文特征压缩模块通过压缩图文特征降低了特征维度,减小了后续处理的资源消耗.图5 的结果表明,本文模型有更小的参数量,更易部署应用.值得一提的是,所有模型在3 个数据集上的参数量都不同,这主要是由于3 个数据集的样本量不同,在通过Word2Vec 进行词嵌入时,参数随着数据集的样本量增大而增加.
为进一步验证所提模型的优越性,本文还在文献[17]的Flickr,Getty Images 数据集上(为与本文数据集区分,此处分别命名为Flickr2,Getty Images2)与文献[17]进行了对比,实验结果如表6 所示.可以看出,本文模型在Flickr2,Getty Images2 上的所有评价指标都超越了SCC,表明本文模型比SCC 更能有效地提取情感信息.

Table 6 Comparative Experimental Results on the Datasets of Ref [17]表 6 文献[17]数据集上的对比实验结果
3.4.2 消融实验
为评估设计模块的合理性和有效性,在Twitter,Flickr,Getty Images 这3 个数据集上进行消融实验.如表7 所示,在3 个数据集上本文模型的性能都更优越.具体来看,在Twitter,Getty Images 这2 个数据集上,MF 的性能较低,且加入FE 后性能提升较大,这是因为FE 能够进一步提取压缩图文特征,帮助模型更稳定有效地学习图文情感信息.PE 可以提取公共情感特征,去除冗余信息,提升模型在Twitter,Flickr上的性能.而在Getty Images 上,加入PE 后并没有提高正确率,这是因为Getty Images 中样本间的情感关联性更高,PE 在提取公共情感特征时损失了部分情感信息.此外,在加入WR 后,模型在3 个数据集上的表现都有不同的提升,说明经过微调的词向量矩阵更契合模型,有助于模型提取特征.从总体上看,加入FE,PE 能够提高模型在图文情感分析上的表现,证明本文设计的图文特征压缩模块和公共情感特征融合模块是合理有效的.

Table 7 Ablation Results on the 3 Datasets表 7 3 个数据集上的消融实验结果
3.4.3 样例分析
3.4.1节和3.4.2节所述的实验从宏观上验证了本文模型的优良性能.为更具体地比较不同模型在不同样本上的表现,从Twitter 中挑选出3 个积极样本和3 个消极样本,其中“积极”标注为“1”,“消极”标注为“0”;进一步地,为更直观地比较预测的情感极性分布与样本真实分布,将“1”和“0”分别编码为“[0,1]”和“[1,0]”.为方便叙述分析,将样本编号为1~6.样本细节和各模型的预测结果如表8 所示.
结合模型在样本1 和样本3 的表现可以发现,对于“积极”的情感较为强烈的样本,所有模型都能够准确地判断.在样本2 上,文本的情感表现不如样本1 和样本3 明显,此时获取文本的情感信息更加困难,因此只利用文本信息预测情感极性的OTT 更易出错.尽管样本2 的图像中包含丰富的情感信息,但是EFIT,LFIT,CCR 仍预测错误,说明这3 种模型更依赖文本信息,不能有效结合图像中的情感信息.此外,DMAF,AMGN 和本文模型都正确地判断了3 个积极样本的情感极性,其中本文模型预测的情感分布更加接近真实分布,在样本2 文本情感不明显的情况下依然有较好的表现,这表明本文模型的鲁棒性更为优越.

Table 8 Details and Performance of 6 Samples of Twitter on Different Models表 8 Twitter 的6 个样本在不同模型上的细节和性能
在样本4 上,可以发现DMAF 不能正确判断其情感极性,这是因为该样本中图像的消极情感表现不明显,DMAF 无法准确提取情感信息.另外,在3 个消极样本上,CCR,AMGN 预测的概率分布都较接近真实分布,是因为这2 种模型对消极情感信息敏感.而本文模型的预测结果比CCR,AMGN 更接近真实分布,说明本文模型更有效地提取了消极情感信息.值得一提的是,在样本5 和样本6 上本文预测的样本分布并非就是[1,0],而是因为概率分布极为接近真实分布,经过四舍五入后的近似值.
综合模型在这6 个样本上的表现可以看出,OIG只能较为准确地预测积极情感,原因是在缺乏文本信息的指导下,OIG 无法准确提取图像中的情感信息;此外,数据集含有更多的积极样本也可能使模型更偏向学习积极情感.虽然DMAF 能较为准确地判断情感极性,但与真实分布差别较大,这是因为DMAF 提取了较多的冗余信息.对比DMAF,AMGN,本文模型能更准确地预测这6 个样本的情感极性,且在不同样本上的表现变化较小,证明本文模型能够更准确有效地联合利用图文中的情感信息,有更强的稳定性.
4 结束语
现有图文情感分析模型不能同时保证高性能与低参数量,使得模型难以用于实际部署.针对这个问题,本文提出了一种基于公共情感特征压缩与融合的轻量级图文情感分析模型.首先设计了图文特征压缩模块,通过卷积层与全连接层压缩图文特征,降低了特征维度;然后提出一种基于门控机制的公共特征融合模块,通过将图文特征映射到相同的情感空间来消除特征异构性,并融合图文公共情感特征以减少冗余信息.结合这2 种模块,提高了模型性能,减少了参数量,使得模型更易部署应用.在3 个基线数据集上的实验证明本文所提模型是有效的.
虽然本文模型在多个数据集上都有着更优越的表现,然而实验中还是暴露了2 个问题:1)为了减少参数量,在处理过程中舍弃了许多特征信息,导致在样本量较小的情况下,模型无法有效地学习情感分布;2)在模态信息处理上,本文是以图像辅助文本,对文本长度和规范的要求更高,在文本有混合语言、长度过短或者有单词错误缺失问题的数据集上,本文模型难以取得满意的结果.在未来的工作中,我们将尝试通过探索新的特征提取方法保证在不同大小的数据集上都能准确地提取情感信息.此外,我们还希望能够引入社交关系等其他信息,进行更有效的情感分析.
作者贡献声明:甘臣权和付祥负责论文撰写和修改;冯庆东负责数据集搜集与整理;祝清意负责设计论文框架并指导实验分析.
猜你喜欢
文萃报·周二版(2022年3期)2022-01-20 19:00:40
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
数学物理学报(2017年5期)2017-11-23 07:51:31
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
河南科技(2014年23期)2014-02-27 14:19:15
海外英语(2013年9期)2013-12-11 09:03:36
海外英语(2013年10期)2013-12-10 03:46:22
