
泸定Ms6.8地震房屋损失快速评估
2023-05-12 08:59:00赵登科王自法李兆焱周阳高曹珀WANGJianming位栋梁张昕
世界地震工程 2023年2期
赵登科,王自法,,李兆焱,周阳,高曹珀,WANG Jianming,位栋梁,张昕
(1.中国地震局工程力学研究所 中国地震局地震工程与工程振动重点实验室,黑龙江 哈尔滨 150080;2.地震灾害防治应急管理部重点实验室,黑龙江 哈尔滨 150080;3.中震科建(广东)防灾减灾研究院,广东 韶关 512000;4.河南大学 土木建筑学院,河南 开封 475004)
0 引言
地震是地壳快速释放能量过程中引起的地表剧烈振动,通常会引起大量的人员伤亡和经济损失[1],地震发生时大多数损失是由房屋的倒塌与破坏引起的,人员伤亡与商业中断也与房屋的破坏程度有极大的关系。因此利用科学的方法快速准确地评估震后房屋的损失后果以及可能的分布,对于震后指挥、紧急救援、分配救援人员和物资有着重要意义[2]。
目前常用的震后损失评估方法主要有:(a)基于历史震害资料的震害矩阵方法[3-6]。(b)基于性能的易损性分析方法[7-8]。(c)以现场调查为依据的抽样统计方法。(d)基于遥感影像和航片判读的识别法[9-11]。文献[5]详细阐述了上述几种评估方法的流程,并指出后3种方法难以应用于破坏性地震的建筑群体损失快速估计中。建筑物群体快速损失评估目前应用最多的仍为震害矩阵方法[12],该方法的主要是依据震后发布的地震烈度图,承灾体资料以及所建立的房屋震害矩阵,分别计算各烈度区的房屋破坏比例,最终定量给出影响场内房屋的整体损失结果[13]。例如徐国栋等[5]对汶川地震损失估计;李成帅等[14]对芦山地震的损失估计等。
传统的震害矩阵方法虽然能够快速地提供定量的震害损失评估,但是以烈度为基础的评价方法精度有限,而且评估结果仅代表了损失的平均水平,忽略了地震损失中各类不确定性的影响[15]。由于震源参数、传播路径、场地效应和结构反应的多重复杂性,房屋的地震损失有着极大的不确定性[16-17],其对于量化尾部风险尤为重要。PAGER是美国联邦地质调查局开发的全球地震损失快速估计系统[18],对于不同国家或地区,PAGER都定义了归一化的标准差常数ζ(我国为1.895),用以描述总体损失的不确定性[19]。需要说明的是:该方法虽然一定程度上能够刻画整体损失的变异性,但同时意味着,对于不同震源位置和不同震级的地震,PAGER所估计的损失分布形状都是固定的,这显然过于简化和失准,最终导致计算结果及其分布的误差。事实上,由于各类不确定性的相互传递,地震影响场内每个空间位置点的损失都是随机的[20],需要均值、方差和具体的分布形状来共同确定。另外,在城市尺度或者区域层次地震估计损失中,各空间位置点的损失相关关系也是影响地震损失结果概率分布的重要因素[21-23]。因此,震后房屋损失评估是一个涉及多维相关变量的随机过程,仅用均值或者固定的分布形状无法描述房屋地震损失的客观特征,若要得到接近实际的高精度损失结果,必须进行大量的样本计算和模拟分析。
本文基于Copula理论,提出了一种适用于地震巨灾风险分析的相关随机变量模拟方法,能够更准确地刻画地震损失评估过程中的一系列不确定性和损失相关性,并利用所提方法对2022年9月5日泸定6.8级地震的损失进行快速评估,给出了损失估计结果及其概率分布。希望研究方法和结果为震后损失快速评估技术提供参考,也为此次地震的应急管理提供了依据。
1 地质背景
2022年9月5日,四川省甘孜州泸定县发生了6.8级地震,震源深度16 km,震源机制解为走滑型破裂,震中位于北纬29.59°,东经102.08°附近的磨西镇海螺沟公园内。磨西镇整体位于四川西部地区的鲜水河断裂带上[24],鲜水河断裂带是四川境内最长也是地震活动性最强的一条断裂带。记载表明[24]:自1700年以来发生7级以上地震高达9次,平均每百年发生3次大地震,此次地震是鲜水河断裂上40年来发生的最大地震,震中附近活动断层分布如图1所示。鲜水河断裂带西起甘孜东谷北,向东南延伸,经炉霍、道孚和康定,南达石棉,呈北西-南东走向,长约350 km,其位于巴颜喀拉块体与川滇块体的走滑活动边界,与龙门山断裂带和安宁河断裂带交汇构成了川西地区著名的“Y”字形断裂带[25]。2008年汶川地震和2013年芦山地震使得鲜水河断裂附近库仑力明显增加,此次地震释放了康定-石棉段积累的应变能[26]。
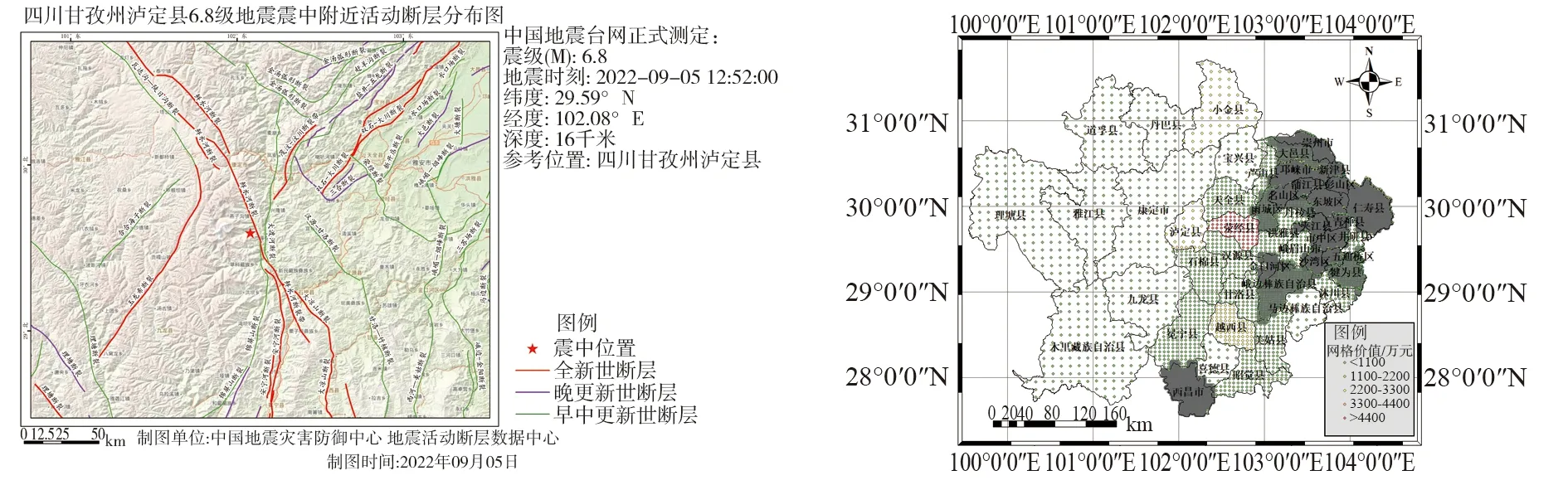
图1 泸定地震震中附近活动断层分布 图2 各单元网格房屋价值的空间分布Fig. 1 Distribution of active faults near the epicenter of the Luding earthquake Fig. 2 Spatial distribution of the building values of each cell grid
2 数据准备
2.1 建筑库存和单元网格划分
全国房屋普查统计数据显示,震中周围县区的建筑类型以砌体结构和框架结构为主,其他结构类型占比极少,为实现损失的快速估算,本文仅考虑砌体和框架结构这2种主要的房建筑类型。在震后损失评估中,通常需要对风险评估区进行地理信息编码[27],例如单元网格化处理,良好的地理信息编码能够在不影响准确度的前提下,快速地确定每个地理位置可能产生的损失大小。该研究通过网格化处理方法,将各县(区)级别的行政区划建筑财产数据转换为多等级非均匀的网格数据。网格尺寸按精度降序分别为:10 km×10 km、5 km×5 km、1 km×1 km、500 m×500 m和250 m×250 m,行政区划的人口密度、GDP以及占地面积等因素越高(大),网格划分精度也就越高。依据转换得到的网格数据,统计得出各单元网格的房屋价值空间分布,如图2所示,发现自西向东各县区网格精度呈阶梯状升高,符合实际情况。
2.2 地震动强度
震后第一时间,研究团队基于泸定地震的震中位置、震级和震源机制解等信息,并参考余言祥等[28]的地震动衰减关系见式(1),对此次地震事件的地震动强度分布情况进行模拟。
lgy=A+BM+Clg(R+DeEM)+ε
(1)
式中:y为地面峰值加速度PGA,M为震级,R为震中距,A、B、C、D和E为回归系数,ε为标准差,回归系数的系数值见表1。

表1 所用衰减模型的回归系数[28]Table 1 Regression coefficients of the ground motion prediction model in use
由于缺少可靠的台站场地信息,因此将台站观测记录按照震源距进行均值化处理,将模拟得到的结果与台站记录均值对比,如图3所示,发现模拟结果与实际观测结果较为接近,说明本文的地震动强度模拟结果是合理的。此外,为了与应急管理部发布的烈度图对比,参考《中国地震烈度表》(GB/T 17742—2020)[29],将本文模拟得到的PGA换算为地震烈度,得到地震烈度分布如图4所示,震中地区的地震烈度达IX度以上,整体灾害空分布大致呈椭圆形,可能受灾范围约18 115 km2。其中:Ⅸ度区面积为168 km2,主要涉及泸定县;Ⅷ度区面积为1 320 km2,主要涉及泸定县及石棉县;Ⅶ度区面积为4 463 km2,主要涉及康定市、泸定县、九龙县、汉源县、石棉县;Ⅵ度区面积为12 164 km2,主要涉及康定市、九龙县、石棉县、冕宁县、甘洛县、汉源县、荥经县和天全县。根据结果可知:本文模拟得到的烈度分布以及各烈度区的面积与应急管理部发布的结果基本一致[30]。

图3 衰减结果对比台站记录 图4 本文计算得到的地震烈度分布Fig. 3 Comparison of ground motion prediction model results with actual station records Fig. 4 Earthquake intensity distribution obtained in this study
2.3 结构易损性
结构易损性描述了地震动与结构破坏之间的关系,相比于震害矩阵,脆弱性曲线,易损性曲线将地震动和结构破坏参数均连续化,因此最为准确[31]。因为缺少大量翔实的震害资料,基于统计方法得到的易损性曲线较少,目前最常见的是基于分析方法的易损性曲线。图5中连续的曲线为文献[32-33]中的模型易损性曲线,散点为汶川地震统计得到的实际破坏数据,可以发现:在地震动强度较高时,无论是框架结构还是砌体结构,分析方法得到的易损性曲线明显高于实际调查结果,这与日本311地震中的发现是一致的[34]。
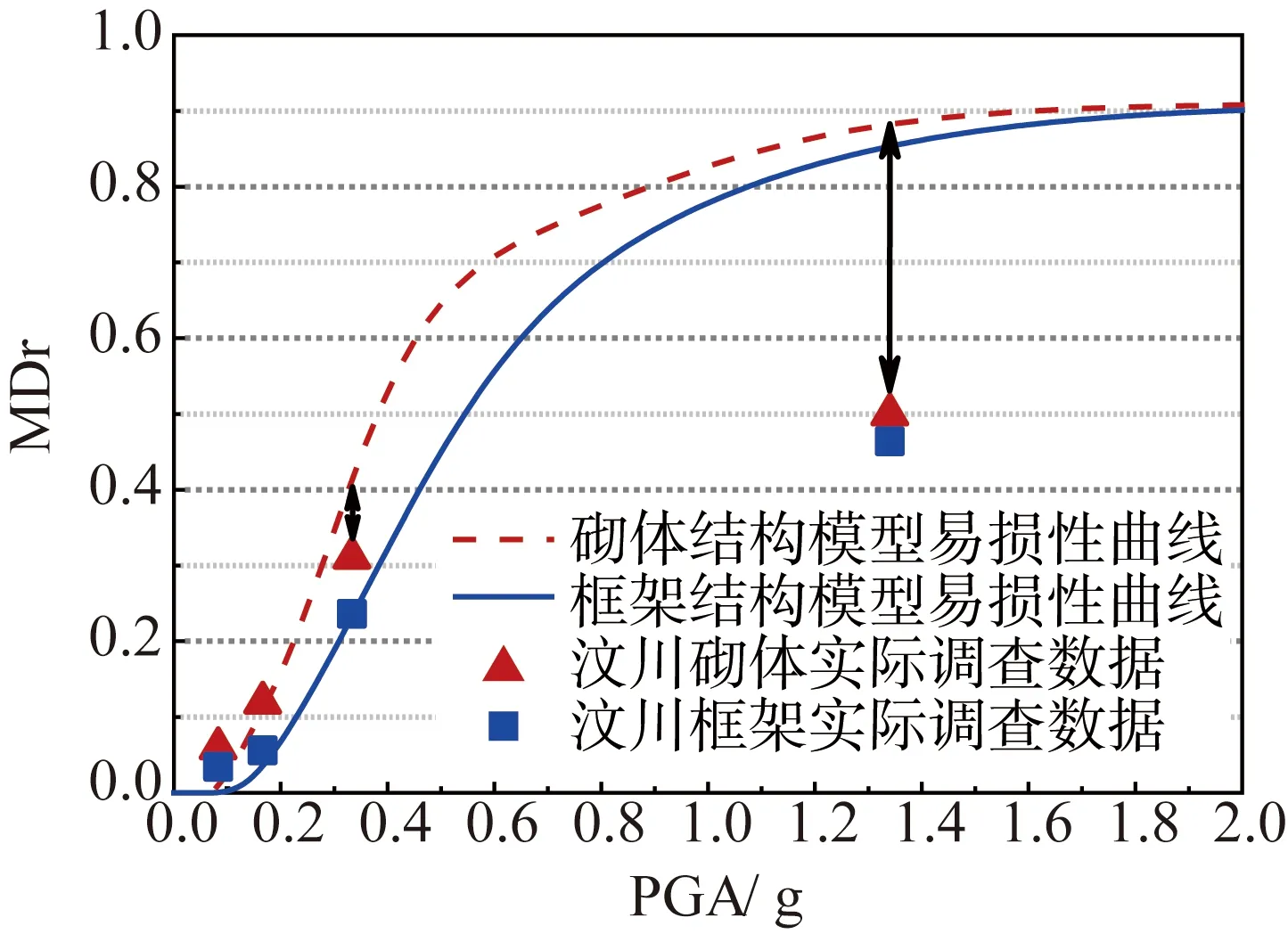
图5 模型易损性曲线与汶川地震实际调查的对比Fig. 5 Comparison of model vulnerability curves with the actual survey in the Wenchuan earthquake
显然,基于分析方法的易损性曲线不能直接应用于地震损失估计中,一个简单有效的修正方法是:针对有限的震害调查点数据,计算各地震动强度下模型损失与实际损失的修正比例系数η,其余地震动强度处的修正系数通过线性内插计算。通过图5中模型易损性与实际调查点的损失比例,得到各地震动强度下的修正系数η以及修正后的易损性曲线,如图6-7所示。可以发现修正后的易损性曲线与实际的调查结果比较接近,能够客观地反映建筑物的抗震能力。需要说明的是:修正后得到的易损性结果符合仝文博等[35]和WESSON等[36]发现的“震害饱和”现象,即随着地震动的增大,结构的损失不会明显上升。

图6 修正后的框架结构易损性曲线 图7 修正后的砌体结构易损性曲线Fig. 6 Corrected vulnerability curve for RC structureFig. 7 Corrected vulnerability curve for masonry structure
3 房屋地震损失的模拟方法
3.1 不确定性与空间相关性
依据所得到的地震动与结构易损性,能够获得每个结构的平均损失程度。但实际震害调查发现:即使是相同地震动水平下,结构损失仍包含着高度的不确定性,因此仅利用平均损失程度无法描述房屋损失的客观规律,需要进一步考虑结构地震损失的分布特征。在以往的研究中,我们针对新西兰和日本大量震害资料,发现相同地震动水平下结构的损失近似服从Beta分布[37]。胡少卿等[38]基于宁蒗地震的实际调查数据,发现我国房屋的地震损失特征也服从Beta分布。由于Beta分布的非线性不可累加特征,在一个区域的损失计算中,无法直接利用Beta分布描述整体损失的不确定,需要首先对空间各单元网格点分别采样确定损失后,再将具体数值累加得到整体损失的分布特征。
当各网格点的损失相互独立时,可以借助蒙特卡洛模拟方法进行随机模拟采样。周阳等[21]基于实际的震害资料,发现各网格点的地震损失是存在相关性的,地震损失的相关性会对损失估计结果产生影响,忽略地震损失空间相关性会高估小震损失或低估大震损失。综上,各网格点的损失就可以看作具有特定相关性结构的多维随机变量X1,X2,… ,Xn,其中:n为空间位置的数量,对于任意的Xi,其边缘分布都为Beta分布。若能够构建出各网格点损失的联合分布,则能够容易地获得到损失样本,但多维随机变量联合分布的构造在相关理论推导和计算中都是极为繁琐的,尤其是当随机变量的数量比较多时,因此需要寻找更好的方法模拟损失。Copula理论提供了一种能够处理随机变量相关性问题的方法,此处引出Copula理论。
3.2 Copula理论
Copula理论基于Sklar定理[39]:假设H是n维随机变量X1,X2,… ,Xn的联合分布函数,与其对应的边际分布分别是F1,F2,… ,Fn,那么就存在一个n元Copula函数C使得对于全部的x1,x2,… ,xn,有:
H(x1,x2,…,xn)=C(F1(x1),F2(x2),…,Fn(xn))=C(u1,u2,…,un)
(2)
若F1,F2,… ,Fn是连续的,则C唯一。因此有以下推理:若C是边缘分布分别为F1,F2,… ,Fn的Copula函数,则式(2)定义的H(x1,x2,… ,xn)是随机变量X1,X2,… ,Xn的联合分布函数。Sklar定理给出了一种利用边际分布对多元联合分布建模的方法,由式(2)可知:多维随机变量X1,X2,… ,Xn的概率密度函数为:
(3)
式(3)说明:一个多维的联合概率密度函数可以拆解为Copula函数与边缘密度概率函数乘积表达的形式,其核心思想是将边缘分布和随机变量间的相关结构分开进行研究,其中随机变量的随机性由各自的边缘分布描述,随机变量之间的耦合特性由Copula函数描述,因此Copula函数能够用于构建具有相关性的随机变量概率模型。
Copula函数总体上可以分为阿基米德型、椭圆型和二次型[40],由于椭圆型高斯Copula函数具有对称性和计算简单的特点,因此在实际中被广泛应用,多维高斯Copula的分布函数如下:
(4)
式(4)中:Φ∑(·)为相关性矩阵满足∑的高斯联合概率分布函数,Φ(·)为标准的高斯分布函数,dx1,dx2,… ,dxn为积分变量。依据Copula理论,式(4)中N元随机数向量u1,u2,… ,un保留了与所研究随机变量相同的相关结构,即同为∑,上述过程很好地解决了随机变量中相关性的问题。
3.3 地震损失采样流程
由概率积分变换可知:对于任意一个已知的连续随机变量X,其累计概率分布函数U=F(x),U都服从[0,1]上的均匀分布:
P(U≤y)=P(F(x)≤y)=P(F-1(F(x))≤F-1(y))
=P(x≤F-1(y))=F(F-1(y))=y
(5)
式中:y∈[0,1]。由式(5)可知:通过Copula函数得到的n维随机数向量U1,U2,… ,UN是服从[0,1]上的均匀分布。由分位数转换的通用性方法可知:只需要以U1,U2,… ,Un为累积分布概率值,对目标边缘分布(我们所用为Beta)求逆累积概率运算,即可得到即既满足特定的相关结构,又满足各自的目标边缘分布的多维随机变量。
随机问题通常需要借助模拟方法采样得到具体的损失结果随机数,本节以蒙特卡洛模拟方法为基础,结合高斯Copula函数,建立一种适用于地震损失的采样方法。在实际应用过程中,问题具体转化为建立符合相关矩阵为R的N元随机变量向量ZBeta,其中:R为房屋地震损失的经验相关矩阵,可以利用地震损失相关性与空间距离的经验公式建立,R∈[0,1]n×n,且满足Rij=Rji,Rii=1,N为地震影响场内的空间位置数量,ZBeta为结构的损失比。采样过程可以分解为以下3个步骤:
1)利用高斯Copula函数生成相关矩阵为R的N元随机向量XGauss1,…,XGaussN,该步可以结合蒙特卡洛抽样高斯分布独立随机数与Cholesky分解的方法实现[41]。
2)计算上步得到的各随机向量XGauss1,…,XGaussN的高斯累积分布函数,将N元随机数向量XGauss转换为服从均匀分布[0,1]的YUniform1,…,YUniformN。
图8展示了所述方法的采样流程,图8(c)中,每个单元网格点的损失边缘分布ZBeta是根据该点的地震动强度与易损性曲线中的损失均值方差共同确定的,且会随着Beta分布控制参数a和b的变化呈现出不同的形状,满足不同地震动强度下结构损失分布形状改变的需要。
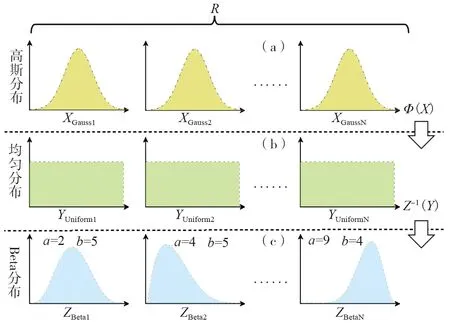
图8 基于Copula理论的地震损失采样流程Fig. 8 Seismic loss sampling process based on Copula theory
当多元变量的维数较低时,可以使用该方法直接抽取样本。然而当维度很高时,尤其是估计破坏性地震的损失时,网格点的数量可以轻易地超过十万级别,即使是对每个网格点进行一次模拟采样,都需要消耗大量的算力,影响震后应急工作的开展。一个较好的方法是:先选择少量位置生成随机样本,然后利用克里金插值方法得到其他位置的采样值,WANG[42]已经证明了克里金插值对于巨灾响应方法的有效性。
4 泸定地震损失估计结果
4.1 采样次数的影响
方法中的损失随机数是基于蒙特卡洛模拟实现的,理论上,只有在足够大的采样规模下才能得到较高的精度。但样本数增加会带来计算量的大幅上升,影响震后应急工作的开展,模拟次数过少,则随机数的分布不均匀,影响模拟结果的可靠性,因此采样次数对结果的影响不可忽略。
本文通过式(6)衡量不同模拟次数下的相对误差ε:
(6)
式中:μk为K次采样后得到的损失均值,ELoss为损失期望基准值,可利用所建立网格数据和易损性曲线得到:
(7)
式(7)中:N为网格数量,M为结构分类数量,计算得到的损失期望(54.29亿元人民币)。针对此次地震,分别进行1~3 000次采样,分析随着抽样次数增加时相对误差ε的变化,以确定合适的采样次数,结果如图9所示。可以发现:当模拟次数达到2 000次时,损失结果趋于基准值,且误差能够控制在0.5%以内,综合考虑计算的精度和速度,认为2 000次模拟结果满足要求。
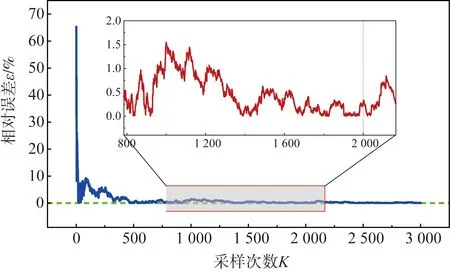
图9 模拟次数对采样精度的影响Fig. 9 Effect of simulation times on sampling accuracy
4.2 泸定地震损失估计结果
基于上述流程,利用多维相关随机变量的抽样方法,对所建立的各网格点损失模拟2 000次得到了泸定地震损失分析结果。图10为框架结构和砌体结构的损失概率分布,可以发现虽然框架结构和砌体结构的损失最大可能在10~20亿元人民币,但是两者在该损失区间的概率值相差较大,差值达到了23.8%。图10给出了砌体结构和框架结构在不同损失区间下的概率差值,在损失小于20亿元人民币的区间内,框架结构发生损失的概率都远大于砌体结构,在损失大于20亿元人民币的各区间内,框架结构发生损失的概率均小于等于砌体结构,意味着砌体结构较大概率会发生更高的损失。两种结构类型损失的均值分别为35.82亿元人民币和18.63亿元人民币,砌体结构的损失均值几乎是框架结构的2倍。原因可归结于两方面:其一,砌体结构抗震能力相比于框架结构较差;其二,地震影响场内,尤其是震中附近(乡镇)的砌体结构房屋占比较大。

图10 不同结构类型的损失分布对比 图11 不同县区地震损失的均值和变异系数Fig. 10 Loss distribution comparison of different structure types Fig. 11 Mean and coefficient of variation of earthquake losses in different counties
依据单元网格,分别计算了各县区的地震损失评估结果,由于受地震影响的县区较多,此处仅展示损失较高的15个县区的房屋损失均值和变异系数,如图11所示。可以看到:泸定县房屋损失最大,其次是石棉县和荥经县,损失均值分别达到了17.81亿元人民币、12.07亿元人民币和6.4亿元人民币。从损失均值来看:损失的估计结果与图4的烈度空间分布具有相似性,符合客观规律,需要说明的是:虽然汉源县的地震烈度比荥经县更高,但图2显示荥经县各单元网格的房屋价值高于汉源县,因此损失估计结果显示荥经县的损失均值(6.4亿元人民币)略高于汉源县(5.3亿元人民币)。此外我们发现:不同县区的损失变异系数存在较大差异,意味着仅用一个恒定的标准差系数无法描述不同空间位置的损失的不确定性特征。图12(a)和图12(b)给出了损失较高的泸定县和石棉县的损失概率分布,图12(c)和图12(d)给出了相同均值下,利用PAGER处理损失不确定性方法得到的结果。对比图12(a)和图12(b)和图12(c)和图12(d)可以发现:两种方法损失分布结果有较大差异,由于不提前设置标准差常数,本文方法给出的损失概率分布较为灵活,能够较好地反映不同县区损失的特征。而PAGER对于不同县区给出的损失分布形状却相对固定,无法反映出不同地区房屋空间分布的差异性。两种方法的对比再次验证了地震损失中相关随机采样方法的重要性。
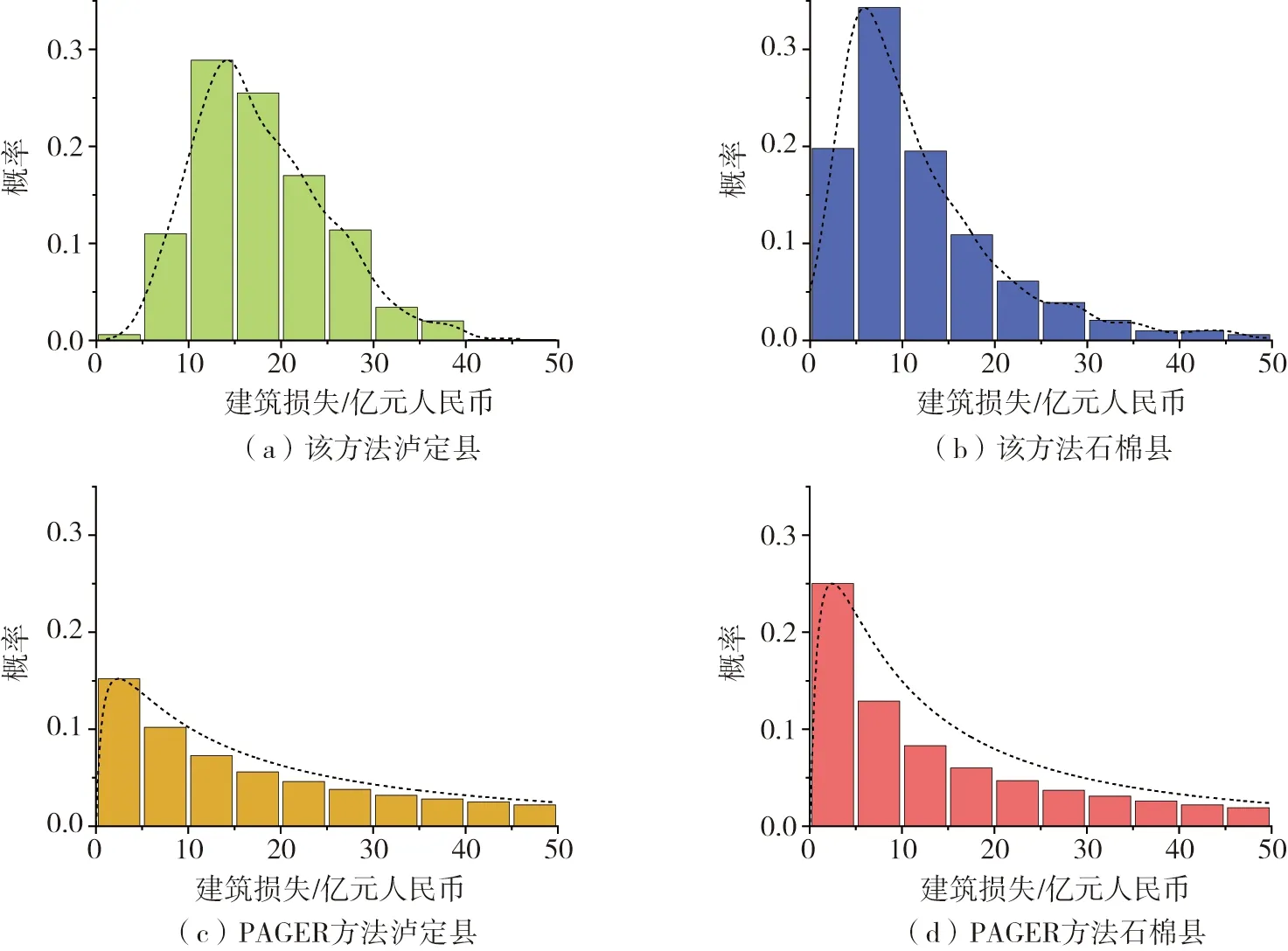
图12 本文方法与PAGER方法计算损失分布的对比Fig. 12 Comparison of earthquake building loss distribution between this study and PAGER
地震影响场内房屋总体损失的分布如图13所示,损失的概率大致呈现出右偏态的长尾分布,损失最大的可能出现在20~30亿元人民币之间,但概率仅为18%。损失在20~50亿元人民币中的各区间的概率均大于15%。虽然分布中的峰值并不明显,但从估计的结果中能够看出:损失超过89.8%的概率处于10~100亿元人民币之间,能够基本确定损失会处于该量级水平,且最有可能为20~50亿元人民币。

图13 泸定地震整体损失概率分布Fig. 13 Building loss probability distribution of Luding earthquake in this study
PAGER在震后发布了此次地震的损失估计结果,如图14所示(单位为百万美元),若按照美元对人民币汇率为7.0计算,则计算结果显示:此次地震损失在7~70亿元人民币和70-700亿元人民币的概率较大,分别为33%和31%,并且有13%的概率超过700亿元人民币。通过图14可以计算出PAGER所估计的损失均值约为10亿美元(70亿元人民币),该值在一定程度上与本文的估计结果较为近似,同时可以发现:PAGER所提供结果的离散型更大,从某种意义上来说缺乏精度。
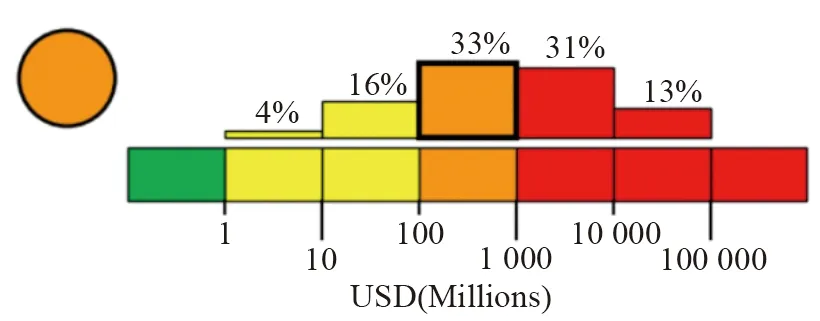
图14 PAGER提供的泸定地震损失概率分布Fig. 14 Loss probability distribution of the Luding earthquake by PAGER
5 结论
针对地震损失中各网格位置点损失的随机性和相关性,本文提出了考虑随机变量相关性的随机变量模拟方法,能够用于未来的地震风险分析和震后损失快速估计中。利用所提方法评估了2022年9月泸定6.8级地震的损失,得到了不同结构类型和不同县区的损失概率分布结果,并与PAGER的估计结果进行了对比,得到了以下结论:
1)提出了一种适用于地震巨灾风险分析的相关随机模拟方法,并在单元网格,克里金插值方法和控制采样次数3个方面进行数据的降维,大幅度地缩减了所需的计算量,能够实现损失结果的快速估算。
2)泸定地震损失估算结果显示,相较于框架结构,砌体结构的损失更高,约是框架结构损失的2倍。此次地震中损失最高的几个县区分别为泸定县、石棉县、荥经县和汉源县,其中前两个县的损失均值超过了10亿元人民币,分别为17.81亿元人民币和12.07亿元人民币。
3)利用PAGER计算损失不确定性的方法,分别得到了泸定县和石棉县的损失概率分布,并与该方法得到的结果对比,发现PAGER对于不同县区给出的损失分布形状相对固定,无法反映不同地区损失特征的差异,验证了所提方法的重要性。
4)估算结果显示,泸定地震造成的房屋损失在10~100亿元人民币量级水平的概率超过89%,并最有可能处于20~50亿元人民币之间。损失的均值为54.45亿元人民币,该结果在一定程度上接近于PAGER的估计结果。
猜你喜欢
建材发展导向(2022年5期)2022-04-18 08:12:06
煤气与热力(2021年11期)2021-12-21 07:15:26
工程与建设(2019年5期)2020-01-19 06:22:48
广州大学学报(自然科学版)(2016年2期)2017-01-15 13:42:53
高中生学习·高三版(2016年1期)2016-05-30 05:45:06
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01 03:46:20
建材与装饰(2015年50期)2015-12-13 09:16:29
江西煤炭科技(2015年2期)2015-11-07 03:10:25
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01 02:54:01
苏州科技大学学报(工程技术版)(2015年3期)2015-02-28 16:21:17
