
电子病历数据势能模型研究
2023-04-25 16:31:30牟冬梅彭浩华树成等
现代情报 2023年5期
关键词:电子病历
牟冬梅 彭浩 华树成等

关键词: 电子病历; 数据势能; 数据价值; 专病库
DOI:10.3969 / j.issn.1008-0821.2023.05.001
〔中图分类号〕G252.8 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 05-0003-11
电子病历数据是居民在医疗机构历次就诊过程中产生和被记录的, 完整、详细的临床信息资源[1] ,是健康医疗大数据的核心来源。2020 年4 月9 日,《中共中央 国务院关于构建更加完善的要素市场化配置体制机制的意见》将数据与土地、劳动力、资本、技术一同纳入生产要素管理, 强调加快培育数据要素市场, 提升数据资源价值[2] 。电子病历数据作为数据资源的一种, 其特有的多源异构、高维稀疏、真实隐私等特点[3] , 在赋予其更多价值的同时, 也为其附加了更多的使用限制, 而情报学的专业能力恰好能帮助医生应对这些问题, 共同挖掘电子病历数据的潜在价值。一方面, 大数据处理工作并非临床医生的优势所在, 而情报学在电子病历文本处理[4] 、影像处理[5] 、数据挖掘[6] 、知识关联与抽取[7] 等多个研究领域已经取得了一定成果;另一方面, 《“十四五” 全民健康信息化规划》中强调, 要加强健康医疗大数据创新应用和行业治理, 以促进数据合规开放共享应用为主线, 充分释放数据价值[8] , 但电子病历数据的高度隐私性限制了其共享与使用, 二者间的矛盾同样是情报学领域关注的问题[9-10] 。《中国数字经济发展报告(2022年)》提出的“四化框架” 中, 将数字经济划分为数字产业化、产业数字化、数字化治理、数据价值化4 个部分[11] 。情报学专家马费成教授[12] 在《中国数据要素市场发展报告》中指出, 数据价值化强调了价值化的数据在推動数字经济发展中的重要作用, 但是就数据爆炸式增长的体量而言, 数据的价值密度仍相对较低。数据价格既与数据质量有关, 也与数据收集难易有关, 更与特定服务场景有关。健康医疗大数据价值化面临着同样的问题。
本研究基于“势能” 理念和情报学理论与方法, 构建电子病历数据势能蓄积模型和释放模型,试图解决数据要素价值化的难题, 拓展情报学应用场景。
1相关研究
1.1“数据势能”相关研究
物理学中, 势能是指储存于系统内部, 可以释放或转化的能量。2018 年, 情报学领域首次有学者在研究中基于这一概念, 以数据作为研究对象,提出开放的科学数据会在研究机构之间流动, 由数据势能高的机构流向数据势能低的机构[13] 。赵林度[14] 认为, 医疗服务资源数据资源的蓄积会产生数据势能, 势能释放转化的动力, 驱动医疗服务资源的精准配置与调度。2021年, 上海数据中心与普华永道会计师事务所同样提出了“数据势能”估值体系[15] , 用于对公共数据的价值进行评估,评估公式为: 公共数据资产价值=公共数据开发价值*潜在社会价值呈现因子*潜在经济价值呈现因子, 根据该公式对18 个省级公共开放数据资产价值进行了测算, 总价值超过1 000亿元。
1.2电子病历数据的管理与应用
近年来, 医疗机构开始着手建设高效的临床专病数据库与全院统一的临床大数据平台等, 以满足其对医院管理、诊疗决策、科学研究、病历质量控制等方面的数据需求。黄波等[16] 建立了新冠肺炎的专病库及随访系统, 帮助医护团队改进了诊疗、科研、随访的工作流程, 提升工作效率, 满足工作需求。陆军军医大学第一附属医院与上海市肺科医院分别建立了自己医院的肺癌专病库, 立足于自身的数据特点, 对电子病历数据进行抽取、清洗、处理, 并提供影像智能诊断、统计分析、知识图谱等功能, 支撑本院医生进行诊疗与科研工作[17-18] 。郭萱等[19] 建立的iTrial 平台, 在电子病历数据的自动采集、处理与质控等过程中都具有明显优势。唐明伟等[20] 从数据驱动实践的角度出发, 以医学科研领域为例, 构建了电子健康记录实现框架, 为未来情报学在医学科研领域的应用提供了参考。
综上, 已有研究提出了数据具有势能的观点,为本研究提供了良好基础, 但相关研究仍存不足,数据势能的理论探索尚不系统, 数据势能从蓄积到释放的过程没有得到充分揭示。针对电子病历数据质量差、价值密度低等问题, 医院尝试通过建立临床大数据平台或专病数据库的方式解决, 但电子病历数据组织管理与应用实践缺乏理论指导, 大多数医院在临床大数据管理系统的构建过程中仅参考了临床医生的科研需求, 缺乏从数据组织管理与利用角度给予的专业指导。本文面向电子病历数据的组织管理场景, 深入剖析电子病历数据势能的蓄积模式, 释放路径与价值应用场景, 以期指导医学数据组织管理实践, 促进情报学、数据科学与医学学科间的交叉融合。
2电子病历数据势能模型
综合前人的定义, 本文将数据势能定义为: 数据及其衍生的数据产品和服务的潜在效用与价值。
在新的技术环境下, 从数据势能角度, 结合电子病历数据组织管理与分析使用的应用场景, 建立电子病历数据势能蓄积与释放两个模型, 分别刻画从电子病历数据组织管理到分析使用的内在机理。
2.1电子病历数据势能蓄积分析
目前, 医院对电子病历数据的组织管理程度不足, 通常仅以原始形态存储于系统中。临床诊疗过程中需要查找数据时, 需要医生从系统中手工查找、抄录数据, 医院管理场景下, 由信息科抽取、整理数据, 科研过程中, 需要医生自行对数据加工、整合、处理, 为数据赋能, 处理效率较慢, 且处理结果会根据医生自身数据处理能力的不同而呈现差异。因此, 医疗机构开始尝试通过建立临床大数据平台或专病库等方式, 由数据管理人员代替医生进行数据整理, 预先对原始的电子病历数据进行处理, 为医院提供更加充分全面的数据支持。
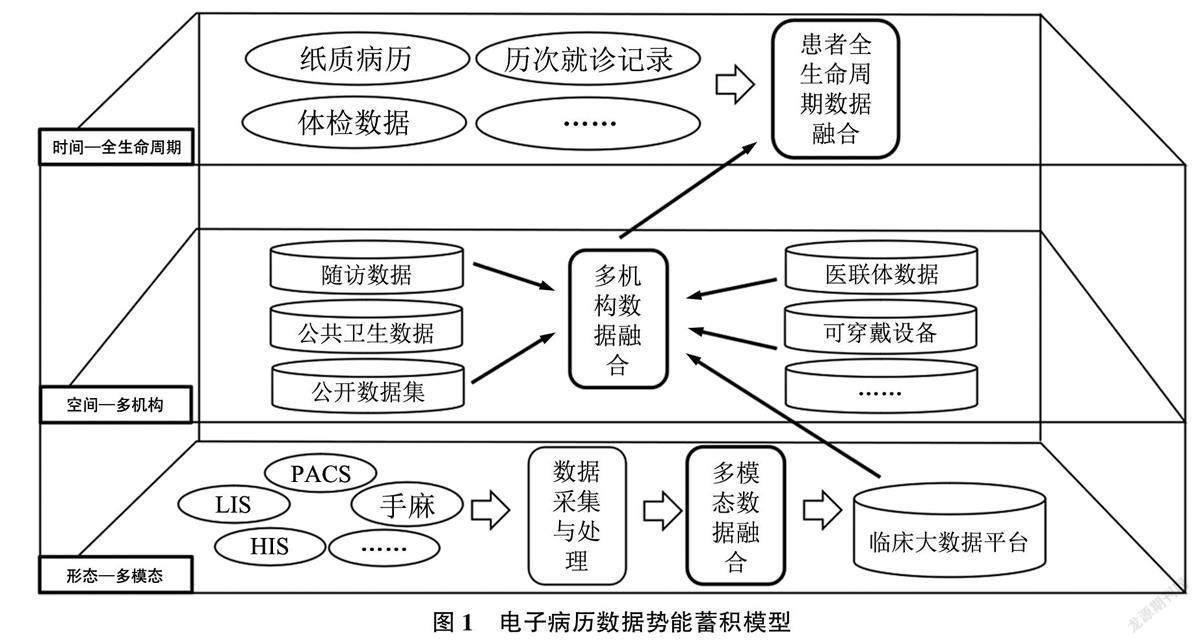
电子病历数据的组织管理通过提升数据质量达到实现数据价值的目的, 为医院提供数据支撑。从数据势能的视角出发, 以电子病历数据为研究对象,认为电子病历数据势能可从以下3个维度进行蓄积: 基于电子病历多模态特点——形态维度, 基于机构间电子病历数据的关联性特点——空间维度,基于电子病历数据时间依赖的特点——时间维度,并构建电子病历数据势能蓄积模型, 如图1 所示。
马费成教授提, 到数据价格与数据质量、数据获取难易度与应用场景有关。价格是价值的外在表现, 其本质是数据在特定场景下所能实现的价值。电子病历数据价值同样受到数据质量、数据获取难易度与应用场景的影响。情报人员对数据的组织管理工作, 从形态维度对电子病历数据进行加工整理, 浓缩数据价值密度, 提升数据品质; 从时间、空间维度获取为医院拓展数据来源、扩大数据数量。既提升了电子病历数据质量, 又代替数据使用者解决数据获取的困难, 赋予数据更多的潜在价值, 蓄积了数据势能。
2.1.1形态维度
电子病历数据在形态维度的蓄积, 是指通过优化数据的原始形态, 提升数据的品质与价值密度。疾病具有复杂性, 作为医学领域的重要生产要素,医生的科研工作与诊疗决策都需要充足的电子病历数据提供支持。数据的价值密度直接影响着数据的使用效率, 电子病历数据继承了大数据价值密度低的特点, 且以多模态的形式分散存储于多个系统,各系统中的数据相互关联, 共同反映了患者的健康状况。传统的临床场景中, 需要医生自行在多个系统中完成对电子病历数据的查询、采集、整合、分析、处理, 极大地消耗着医生的时间与精力。因此, 现代化的数据组织管理工作中, 医院管理者、信息中心与数据公司应以节省医生精力为出发点,围绕医生在使用数据过程中存在的困难, 代替其预先完成数据的整合、清洗、脱敏等初步处理工作,从原始数据中提取关键信息, 排除冗余, 完成数据结构化和多模态数据融合, 提升数据的价值密度,并依据医生的各类数据需求, 合理设置数据的检索点, 存储到临床大数据平台/ 专病库中, 使医生能够快速、便捷地获取高质量数据, 立刻进行分析与使用, 减轻医生在使用数据过程中的负担。
2.1.2空间维度
电子病历数据在空间维度的蓄积, 是指联合其他医疗机构, 对患者疾病从发现确诊到结局(痊愈或死亡)的全过程数据进行搜集整理。受到医疗水平差异、分级诊疗、病情发展状况等因素的影响,患者有时会前后在多个医疗机构进行连续就诊或转院治疗, 在多个医疗机构中产生电子病历数据。治疗结束后, 部分医疗机构还会对患者进行定期随访, 记录患者的病情变化情况。部分患者还会使用可穿戴设备这一新兴的医疗技术, 进行长期、实时的生活习惯与健康参数水平监测。这些数据共同完整地描述了患者在这次就医过程中的病情发展情况, 对医生的复诊、科学研究、医院间转诊等工作具有重要意义。此外, 针对特定疾病的研究, 公开数据集与疾控部门的公共卫生数据也能够作为医院电子病历数据的补充。因此, 如果能够促使多个医疗机构之间建立合作关系, 实现机构间电子病历数据的互联互通, 提升电子病历数据的完整性, 扩充医生可分析利用的数据数量, 既可以使医生在转诊过程中快速掌握患者之前的病情变化与治疗方案,又可以利用数据进行预后预测等课题研究, 同时赋能临床诊疗与科研工作。
2.1.3时间维度
电子病历数据在时间维度的蓄积, 是指按时间顺序尽可能将患者所有的电子病历数据进行搜集整理, 以求获得完整的、记录患者全生命周期健康信息的数据。电子病历数据在时间维度上蓄积越久,它的“势能” 就越大。疾病的产生一方面是由基因或意外所导致的; 另一方面则是由于患者生活行为习惯的长期积累。曾有慢性病专家提出“基因给枪上了膛, 是生活方式扣动了扳机” 的观点[21] ,而患者的生活方式与习惯就隐藏在历次就诊产生的电子病历数据中, 即使就诊科室与疾病不同, 其间仍隐藏着因果性与关联性。将电子病历数据按照时间顺序在时间轴上纵向排列, 就可以从全生命周期的角度直观呈现患者的身体情况变化与病情发展走势, 既包含了患者的疾病史与治疗史, 也隐含着患者长期的生活方式等信息。在临床场景中, 能够帮助医生详细了解病人情况, 辅助诊疗决策; 科研场景中, 能够为病因分析、共病研究等提供数据支撑。
2.2电子病历数据势能释放过程
数据组织与管理使电子病历数据蓄积了势能,但势能只是潜在的价值, 蓄积的势能需要得到释放,才能转化为现实价值。数据使用的过程就是将势能释放, 转化为价值的过程。如图2 所示, 数据使用首先需要从临床大数据平台或专病数据库等数据来源中采集已经过初步组织加工的电子病历数据, 形成研究所需的数据集; 之后根据使用目的不同, 进行后续数据处理工作, 主要包括数据清洗(缺失值、异常值处理、类别平衡等)、数据集成、数据变换(类型变换、标准化、归一化、离散化等)、数据规约(变量合并、特征选择等)4个流程, 并形成新的数据集, 再进行医学统计分析或数据挖掘,得出科研成果或支撑医院管理工作; 也可直接基于临床大数据平台或专病数据库中的电子病历数据,辅助医生进行临床诊疗决策或撰写病例报告。目前, 数据势能释放主要是由医生将数据下载之后自行分析, 但已有机构开始尝试将数据分析、智能诊疗决策、医学知识图谱等功能融入临床大数据平台中, 为医院提供从采集到分析的全过程数据服务。
电子病历数据的价值与其应用的服务场景有关, 电子病历数据的服务场景分为诊疗决策、支撑科研与医院管理3方面, 通过对电子病历数据进行分析使用, 释放数据势能, 最终支撑数据应用于各个场景, 实现电子病历数据价值。在科研场景中,电子病历数据的价值会通过医学统计分析、機器学习等数据分析方法转化为专利、论文、专著等多种形式的科研成果; 在临床场景中, 数据价值可通过辅助诊疗决策等方式, 节约医生工作时间, 优化治疗方案, 节约患者就医费用; 在医院管理场景中,数据价值实现的路径包括优化病房管理、医院感染管理等。
3实证研究
3.1电子病历数据势能蓄积过程模型的案例分析——以J医院肺癌专病数据库构建过程为例
3.1.1案例选择
选择J 医院肺癌专病数据库构建为案例, 分析该专病数据库构建过程中, 电子病历数据势能的蓄积过程。J 医院始建于1949 年, 是集医疗、教学、科研、预防、保健、康复为一体的大型综合三级甲等医院, 以2019年为例,J医院全年的总门诊量高达554万人次[22] , 位居全国医院门诊量前10 位,信息化、智慧化建设程度较高, 曾获得“2020全国智慧医院建设优秀案例” 授牌。
3.1.2蓄积过程分析
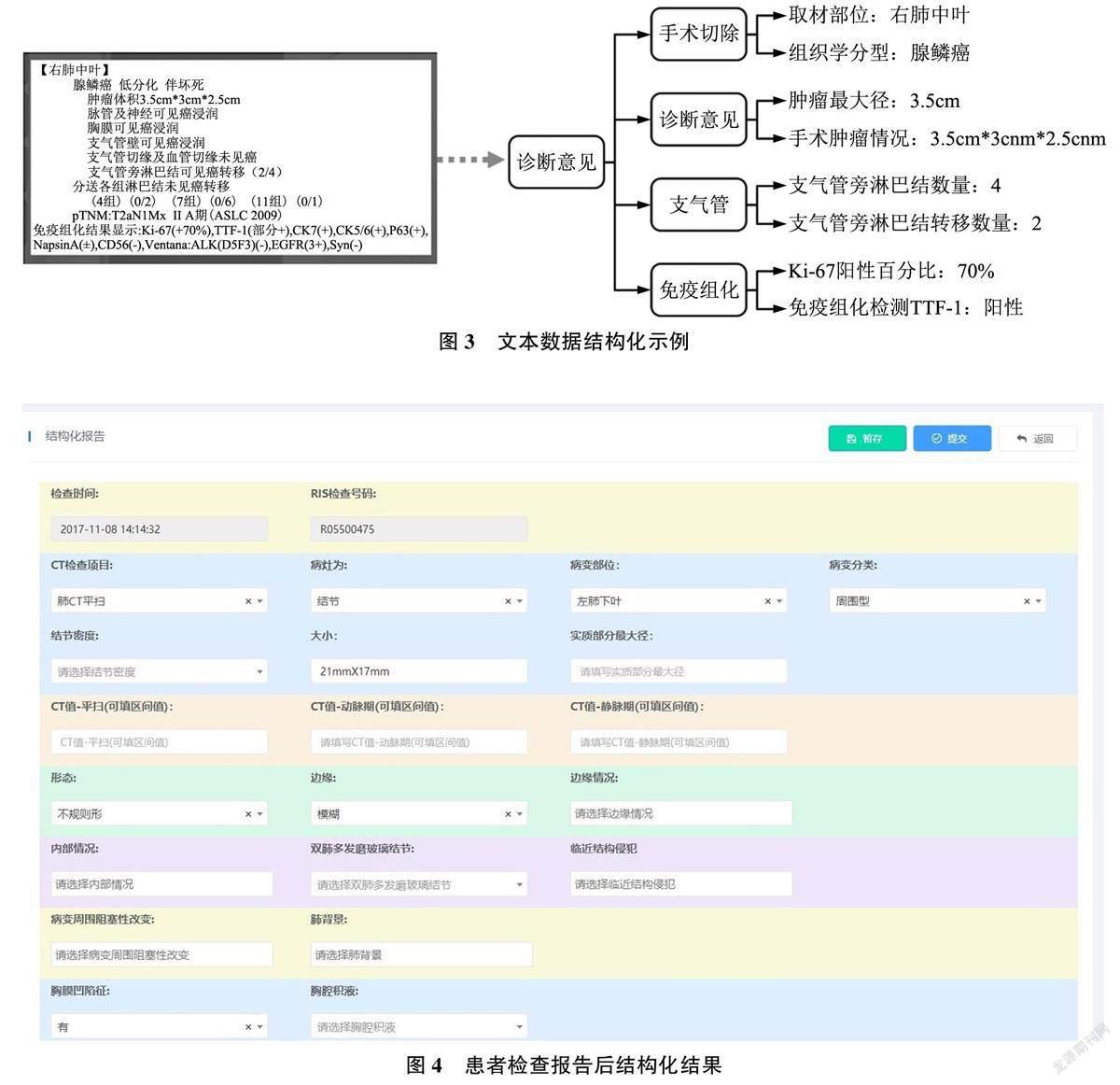
1) 电子病历数据势能在形态维度上的蓄积目标, 是通过多模态数据融合, 完成患者单次就诊过程中全部数据的组织管理。如图3 所示, J 医院基于自然语言数据处理(Natural Language Processing,NLP)技术, 对电子计算机断层扫描( ComputedTomography, CT)等检查结果中的有效文本信息进行了自动抽取, 并支持研究人员对NLP 提取的结果进行线上纠正, 作为NLP 技术的补充。最终,通过多模态数据融合, 对电子病历数据重新梳理,剔除数据中的冗余信息, 以字段的方式结构化地记录肺癌的病灶数量、病变位置、病变分类等重要信息, 录入肺癌专病数据库中, 供医生快速查询使用, 如图4 所示。对于部分纸质病历, 也允许工作人员依据模板进行手工录入。此外, J医院还在处理后的结构化内容与原始电子病历数据之间建立了映射, 允许研究人员对原始的电子病历数据进行回溯查询。简化了医生对电子病历数据提取与处理流程, 加快了醫生的工作速度与效率。
2) 空间维度。2017 年, 吉林省政府发布了《吉林省推进多层次医疗联合体建设实施方案》,指出要完善政府主导的多层次医联体, 实现医联体内信息互联互通, 方便患者就医, 提高医学科研技术水平[23] 。在政府政策的引导下, J 医院已与省内多家医院之间建立了“医联体” 的合作关系, 已能够实现上下级医院之间在转诊时的电子病历数据互通, 为后续实现机构间数据全面互通共享与整合奠定了基础。考虑到公共卫生数据对医生工作的参考价值, 专病库集成了统计年鉴数据, 方便医生查询使用。同时, 专病数据库设计了随访数据、可穿戴设备数据等相关数据的录入接口, 为后续的平台维护工作提供了充分的拓展空间。
3) 时间维度。J 医院基于本院电子病历数据,将患者的历次就诊记录及相关检查结果按时间顺序进行了组织排列, 可以提供患者就诊、治疗、服药、检查等一系列信息的时间节点, 并在时间轴上绘制成图, 如图5所示, 以可视化的形式辅助医生及研究人员掌握患者的病情变化情况。伴随着后续机构间数据互联互通逐步实现, 数据逐步补充, 最终能够形成全生命周期的居民健康数据供医生使用。
3.2电子病历数据势能蓄积释放模型的数据分析——以小细胞肺癌和非小细胞肺癌鉴别诊断为例
基于J 医院肺癌专病数据库数据, 以科研场景为例, 分析电子病历数据的数据势能释放, 验证模型合理性。肺癌作为全球最常见的癌症种类之一,其患者死亡人数占癌症死亡人数的18 0%, 是癌症患者死亡的首要原因[24] 。根据癌细胞病理形态的不同, 肺癌主要可以分为小细胞肺癌(Small CellLung Cancer, SCLC) 与非小细胞肺癌(Non-smallCell Lung Cancer, NSCLC)两种亚型。对于不同的肺癌亚型, 其转移率、发展速度、治疗方式等具有很大差异[25] 。在临床上, 病理学检查是对两者进行鉴别诊断的金标准[26] , 但病理学检查属于有创的操作, 会对患者造成创伤, 所以需要其他的鉴别诊断方式作为辅助手段。有研究证实, 部分肿瘤标志物[27] 、血常规指标[28] 在SCLC 与NSCLC 的诊断中具有参考意义, 因此提出假设, 基于电子病历中的肿瘤标志物与血常规数据, 能够建立SCLC 与NSCLC 的鉴别诊断模型。
3.2.1数据来源与采集
专病库依据ICD-10 编码收录了2012—2018年于J 医院住院的11 377例肺癌患者, 从中提取1 000例肺癌患者数据, 排除无肿瘤标志物检验结果或明确诊断结果的患者数据572 例, 共纳入研究428 例患者数据, 其中小细胞肺癌患者78 例, 非小细胞肺癌患者350 例。部分原始数据如图6 所示, 数据经过组织管理并存入专病库中, 能够快速大量地导出符合医生需求的、经过脱敏等初步处理的数据, 省去了繁琐的查询与抄录过程。
3.2.2数据处理
1) 变量转换。由于原始数据中存在多种数据类型, 不能直接进行分析, 因此需要对数据类型进行转换并统一。对于字符型变量, 如“病理类型——非小细胞肺癌” 字段中包含的“是” 和“否”, 将其转换为“1” 和“0”两种数值型变量。受物理因素、人为因素等影响, J医院肺癌专病库电子病历数据中的部分检查检验结果会粗粒度地用区间范围代替具体数值, 且具体数值与区间范围交替使用, 如“糖链抗原125(CA125)”“游离人绒毛膜促性腺激素(HCG)”等。对于此类数据, 根据变量中两种数据的占比多少, 对两种数据进行相互转换, 以便后续数据分析的顺利进行。
2) 缺失值处理。电子病历数据的缺失情况极为严重, 这是因为患者的病情各异, 不会完整地进行所有的检查、检验项目, 在数据分析前需要对数据进行插补。经正态性检验, 所选变量均不呈正态分布, 依据统计学方法, 应当使用中位数对数据缺失值进行插补。此外, 计算机领域使用随机森林回归算法对缺失值进行预测也有较好的效果。对两种方法建立的模型进行比较, 发现利用随机森林回归算法插补的数据建立出的预测模型性能更好, 因此, 采用该方法处理缺失值。
3) 过采样处理。电子病历数据是高度不平衡的, 因为人群是否患病、疾病种类分布并不均匀。所选数据中SCLC 患者与NSCLC 患者之间分布比例为1∶4,与真实世界中的分布情况一致。在不平衡数据中, 少数类样本被错误分类不会大幅降低全局的分类正确率, 但少数类的分类正确率会下降[29] 。目前, 大多数分类器是根据平衡数据设计的, 不平衡数据会使模型训练不充分, 造成性能下降[30] 。所以通过SMOTE 算法扩充了SCLC 患者数据272例, 使其与NSCLC 数据量达到1∶1,两者共计700例用于模型构建。
之后, 对所有的检验学数据进行标准化处理,消除不同特征的不同计量单位对模型预测结果的影响, 再进行后续实验。
3.2.3数据分析
选取Weka-3.8.4数据挖掘软件作为机器学习预测模型构建的工具软件。该软件全称为怀卡托智能分析环境(Waikato Environment for Knowledge A?nalysis, 简称Weka),是由新西兰怀卡托大学开发的开源软件, 具有交互式的可视化界面和强大的数据分析能力, 是应用较为广泛的数据挖掘软件之一。
1) 特征选择及分析。选取血常规和肿瘤标志物的检验结果, 共37 项特征。由于并非全部特征都会对模型预测结果产生影响, 所以在模型构建之前, 需要对利用算法各特征与分类的关联性进行分析排序, 以选取出特征集合中的最优子集, 降低数据集的特征维度, 简化分类预测模型, 同时提高模型的性能[31]。因此使用了Info Gain Attribute Eval和Symmetrical Uncert Attribute Eval两种算法, 分别基于特征的信息增益和对称不稳定性进行特征选择, 并得到特征相关性排序如图7(a)、图7(b)所示。两种算法对37种特征进行筛选后, 得到了相同的20 个特征, 且特征与分类的相关性排序具有一定相似性。
2) 肺癌鉴别诊断预测模型构建与评价。选取支持向量机、随机森林、C4.5 决策树、Logistic 回归、朴素贝叶斯5 种分类模型, 利用Weka 软件,采用10 折交叉验证方法, 对700 例患者数据的20个特征建立分类预测模型。为验证血常规与肿瘤标志物检验数据联合使用是否能够提升评价效果, 分别以所选取的20 项特征中的血常规数据和肿瘤标志物建立上述5 种模型, 作为对照数据。各模型性能分别如表1、表2 所示。根据计算出的各模型真阳性率(TPR)和假阳性率(FPR), 使用OriginPro8绘图软件绘制的各模型ROC 曲线如图8(a)、图8(b)所示。
将血常规数据与肿瘤标志物数据共同用于建立预测模型, 模型性能如表3 所示, 根据计算出的各模型真阳性率(TPR) 和假阳性率(FPR), 使用OriginPro8 绘图软件绘制的各模型ROC 曲线如图9所示。通过对比各模型的性能数据和ROC 曲线可知, 在5 种分类算法中, 随机森林算法模型的AUC值为0.940, F1 值为0.881 和0.878, 在各个模型中对SCLC 和NSCLC 的分类效果最佳, 其余4 个模型的性能稍差。
3.2.4服务场景
经过对J 医院肺癌专病库中的电子病历数据进行分析, 证实了将血常规检验结果联合肿瘤标志物检验结果对SCLC 与NSCLC 患者进行鉴别诊断的优越性。所构建的机器学习模型效果良好, 可以作为一种辅助手段, 帮助临床工作人员判断肺癌患者的肺癌亚型, 以便其为患者设计进一步的检查与治疗方案, 辅助进行临床诊疗决策。并以科研场景为例, 验证了模型中的势能释放部分在实际应用中的可行性与合理性, 能够顺利释放电子病历数据势能, 实现数据价值。
4结语
目前, 我国电子病历数据的积累呈现出海量高速的特点, 为提升医疗水平、优化医疗环境、实现“智慧医疗” 等提供了充分的外部条件的同时, 也带来了诸多挑战。面对日益复杂的数据环境, 与情报学、计算机科学等数据相关学科交叉融合是最佳方案, 也是必然趋势。电子病历数据经过专业的、智能化的组织管理, 从形态、空间、时间3 个维度逐级蓄积势能, 提升了数据质量, 降低了医生获取数据的难度, 最终能够在多个场景中实现数据价值, 为医学发展起到支撑作用。
本文以情报学视角作为出发点和落脚点, 借用势能的概念建立了电子病历数据势能模型, 强调了对电子病历数据进行科学组织管理的意义, 并运用真实世界的案例数据与电子病历数据验证了理论的有效性与合理性。借此强调了情报学理论在医院数据的管理者于数据势能蓄积中的作用。模型的价值主要体现在: ①从形态、空间、时间3 个维度梳理了电子病历数据现代化管理的途径, 为电子病历数据组织管理实践提供了指导与参考; ②阐明了电子病歷数据在临床诊疗、科学研究、医院管理3 个服务场景下能够发挥的价值及分析使用的一般模式;③将情报学理论融入医院数据管理的场景中, 为情报学与医学交叉融合提供理论基础; ④丰富了数据组织管理的相关理论体系, 为跨学科情报学理论发展提供新思路。
致谢:感谢禾熙公司为本研究提供的原始数据材料。
猜你喜欢
电子技术与软件工程(2017年1期)2017-03-06 23:54:05
医学信息(2016年32期)2017-02-22 15:47:15
法制博览(2016年12期)2016-12-28 13:05:51
电子技术与软件工程(2016年18期)2016-11-14 01:24:53
电脑知识与技术(2016年12期)2016-06-14 01:52:51
医学信息(2015年49期)2016-01-12 15:03:38
中国当代医药(2015年4期)2015-08-03 18:28:34
软件导刊(2015年6期)2015-06-24 12:58:39
医学信息(2015年5期)2015-03-31 15:00:27
医学信息(2015年6期)2015-03-17 14:29:20
