
融合加权异质网络与网络表示学习的学术信息推荐研究
2023-04-25 23:13熊回香唐明月叶佳鑫等
现代情报 2023年5期
熊回香 唐明月 叶佳鑫等


关键词: 异质信息网络; 学术信息推荐; Node2vec; 语义相似度
DOI:10.3969 / j.issn.1008-0821.2023.05.003
〔中图分类号〕G252.6 〔文献标识码〕A 〔文章编号〕1008-0821 (2023) 05-0023-12
随着计算机的发展, 以及Web2 0 时代的到来,互联网络用户逐渐从信息接受者转变为信息制造者和传播者。据CNNIC 发布的第50 次《中国互联网络发展状况统计报告》显示, 截至2022 年6 月,中国网民数量已达10 51 亿, 互联网普及率已达74.4%[1] 。在Web2.0 模式下, 用户可以自由、便捷地分享自己的各种观点, 用户信息产出的门槛变低, 网络信息量因此大幅增长, 导致用户在面对大量信息时无法从中快速准确地获取自身所需信息,对信息的使用效率反而降低[2] 。学术信息亦是如此, 随着学术研究者以及研究成果的不断增多, 学术资源的爆炸式增长给学术研究者帶来了更大的压力, 面对庞大的学术信息资源, 学术研究者难以从中找到与其相关的学术资源。个性化推荐是能够有效处理信息超载问题的方法之一, 学术信息的个性化推荐也逐渐得到了学者的广泛关注。
若要实现准确的学术信息个性化推荐, 首先就需要能够准确地描述学者兴趣特征。目前, 国内外关于学者兴趣特征表示主要包括基于向量[3-5] 、基于主题模型[6-7] 和基于网络结构[8-10] 3 种兴趣特征表示方法。其中, 基于网络结构的兴趣特征表示主要是通过网络中的节点来描述用户的兴趣特征, 如用户—电影网络、学者—关键词网络等, 该类网络包含了非常丰富的结构和语义关系, 而学术信息包含了作者、单位、文献、期刊等多种实体, 基于学术网络结构的学者兴趣表征方法在一定程度上有助于解决信息推荐过程中论文低产量学者的数据“稀疏性” 问题。鉴于此, 本文基于现有的网络表示学习方法, 将文献时间因子与文献语义关系融入学者—文献异质信息网络中进行学术信息推荐研究。
1相关研究
目前, 国内外关于学者兴趣特征挖掘研究主要从基于向量、基于主题模型和基于网络结构3 个方面进行学术用户建模, 从而挖掘学术用户的兴趣特征。基于向量模型的学者兴趣特征表示是用一系列特征词向量来代表学者的兴趣, Guan P 等[11] 使用标题、关键词、摘要和引用等数据, 利用TF-IDF对文献进行建模, 最后利用不同权值的主题词向量进行用户兴趣表示; 耿立校等[12] 使用TF-IDF 技术和Word2vec 技术提取文献特征和用户兴趣中权重较大的前N 个特征词向量, 根据特征词向量和权重来计算文献和用户的匹配度, 从而实现文献推荐。在以主题建模为基础的兴趣挖掘方面, Malho?tra R 等[13] 基于LDA 主题模型, 依据相似作者的兴趣以及作者自身的长期和短期兴趣, 并利用LSA方法计算兴趣的语义相似度, 从而将高相似度的主题推荐给作者, 该研究表明此种类型的融合提高了主题预测的准确性; 尹丽玲等[14] 从资源类型、学科分布、关键词分布和LDA 主题分布4 个特征,整合学术资源兴趣值和质量值作为推荐值, 以实现优质推荐。基于网络结构的兴趣特征表示是通过网络中的节点来描述用户兴趣特征, 网络特征学习已成为网络分析中的重要任务。网络表示学习[15] 旨在从网络中学习一系列低维向量, 如网络节点、边、子图等, 从而在分类、链路预测、信息推荐等下游任务中用于特征表示。Perozzi B 等[16] 首次将深度学习与网络分析相结合并提出了DeepWalk 算法,该算法利用随机游走的方式来对网络进行序列化,以及将Word2vec 引入算法中实现节点特征表示;Node2vec[17] 则是在DeepWalk 算法的基础上对序列采集策略进行优化, 引入有偏参数来引导漫步的下一个节点, 该过程包含广度优先与深度优先两种采样策略, 提高了游走生成路径的质量; Meta?path2Vec[18] 算法是基于元路径来控制随机游走的过程, 在此过程中保留了异质网络中的结构和节点语义关系。在现有研究中, 不少学者利用网络表示学习进行学术信息推荐研究, 如朱祥等[19] 将学科异构知识网络应用于作者—文献的相关性研究中,利用元路径理论和DPRel 相关性算法构建作者—文献相关性矩阵, 最终依据该相关性得到文献推荐列表; Li Y 等[20] 综合考虑论文、地点、作者、术语和用户以及这些实体之间的关系, 在这些元路径上应用随机游动来测量候选论文对目标用户的推荐分数, 提出基于异构网络的论文推荐方法, 依据用户的历史偏好实现有效的论文推荐; 张金柱等[21]则以学者合著网络为基础, 利用LINE 方法进行网络表示学习, 最终通过计算向量相似度来进行科研合作预测。
综上所述, 虽然目前学术界对于学术信息推荐的研究已有较大进展, 但仍存在以下问题亟待解决: 首先, 现有学术信息推荐大多只针对学者静态兴趣, 以学者动态兴趣为基础的学术信息推荐研究较少, 但在现实情况中, 学者的研究兴趣往往具有阶段性的特点, 因为随着时代不断发展, 科学研究需求也会相应发生变化, 学者往往会根据时代背景与研究需求进行一系列研究, 所以捕捉学者动态兴趣特征更有利于提高学术信息的推荐质量, 从而为学者提供更好的信息服务; 其次, 从方法的选择来看, 现有针对学者的学术信息推荐研究主要利用单一的节点类型来构建网络, 无法推荐多粒度的学术信息。基于异质网络的网络表示学习不仅能极大程度地保留图结构数据节点的结构和语义信息, 还能在一定程度上解决数据稀疏问题, 从而提升对少产量作者的推荐效果。然而, 现有应用于学术信息推荐的网络表示学习主要依赖于网络结构信息, 而未考虑节点的外部语义信息。基于此, 本文提出了融合加权异质网络与网络表示学习的学术信息推荐模型, 以实现有效的学术信息推荐。
2基于加权异质信息网络的学术信息推荐模型构建
该模型综合考虑了文献节点的时间特征与语义特征来构建加权异质网络, 其中时间特征体现了学者兴趣的动态性, 而语义特征则利用了文献节点的摘要语义信息帮助建立文献节点关系, 从而可以更好地挖掘潜在的推荐项目。通过该异质网络节点表示学习, 最终完成了包括学者和文献在内的学术信息资源推荐。本文构建的学术信息推荐模型如图1所示, 该模型包含了数据采集与数据预处理、异质网络构建、网络关系加权、节点向量生成以及推荐模块五大模块。首先, 构建了包含学者以及文献的异质信息网络; 其次, 根据文献发表时间计算时间因子加权来反映用户动态兴趣, 同时利用文献摘要文本的相似度来进行文献之间的语义加权; 第三,在该加权异质信息网络上进行节点学习, 得到每个节点的向量表示; 最后, 进行余弦相似度计算得到节点间的相似度, 并以此作为最终推荐值, 从而得到推荐结果。
2.1异质网络构建
本研究定义的异质社交网络包含两种类型的节点: 學者S(Scholar)和文献L(Literature), 实体之间包含两种类型的关系, 即边: SL(学者与文献的关系)、LL(文献与文献之间的关系)。若文献L 由学者S 参与撰写, 则学者S 与文献L 存在SL 关系;若文献L 与文献L 具有较高的相似度, 则文献L与文献L 之间存在LL 关系, 得到如图2 所示的异质网络图。
2.2网络关系加权
近期发表的内容比早期发表的内容更能体现学者目前的研究兴趣, 其对于推荐任务起到了更为重要的作用。所以本文将用户发表时间引入推荐算法中, 通过给近期文献赋予更高的时间权重, 以得到不同时间段的时间权重, 从而更好地表示用户兴趣主题。设共有M 位学者, 学者i(0<i≤M)发表文献数量为Ni, 时间权重函数[22] 如式(1) 所示:
其中, A、B 代表文本的TF-IDF 向量, 设向量长度为n, ai(0<i≤n)与bi(0<i≤n)代表向量A与B 中的元素。
将构建的异质信息网络进行边加权后, 得到了一个包含时间特征与语义特征的加权异质信息网络, 如图3 所示。其中S 代表学者节点, L代表文献节点, 二者的节点集合表示为G, wij代表节点i(i∈G)与节点j(j∈G)之间的边权值。
2.3节点向量生成
节点表示学习的特征质量由采样序列的质量决定, 本文采用文献[17]中的有偏随机游走对异质网络中的节点进行采样, 具体采样过程如下:
τij=eγ(t0 -tn) (1)
其中, τij(0<i≤M, 0<j≤Ni)是从文献发表时间的角度用来衡量文献j 对学者i 兴趣偏好的影响程度参数, γ 为时间衰减因子, t0为学者i 的文献j的发表时间, tn为学者i 最近的研究发表时间。由公式可以看出, 当文献发表时间与最近一次发表时间越近, 时间权重系数越大, 反之越小。
为了将语义信息融入异质图中, 本文将学术文献与学术文献之间的相似性作为异质图中文献节点与文献节点之间的权重值, 主要过程为计算数据集内所有文献摘要的相似度, 为了避免摘要中的通用词汇对语义加权造成影响, 将TF-IDF 的阈值设置为0.1, 若文献与文献之间的TF-IDF 相似度小于0.1, 则表明文献节点之间语义相似度低, 文献和文献之间不存在LL 关系。在文本相似度的度量中, 本文使用TF-IDF 进行文本向量表示, TF-IDF是一种统计方法, 用于评价一个单词在一个语料库中的重要性。单词的重要程度与其出现在文本中的频次成正比, 但也与其在语料文档中出现的次数是反比的关系, 计算方法如式(2) 所示。在得到文本TF-IDF 向量后, 利用余弦值代表文本之间的相似度, 如式(3) 所示。
对网络G中的每一个节点进行采样, 捕捉每个节点的网络结构特征。给定最初始的节点c0(c0∈G), 其中G 的数量为m+z, 设置游走的步长为l,让ci表示随机游走中的第i(0≤i≤m +z)个节点,则在给定的节点ci-1中, 下一节点ci被访问的可能性如式(4) 所示。
对于如何针对所得的节点序列进行学习, 在本研究中, 将概率随机游走得到的序列类比作语料库中的句子, 序列中的节点类比作句子中的单词, 游走序列中节点共现的情况类似于词汇的共现情况。使用基于Skip -gram 模型学习节点的嵌入表示,Skip-gram 是一种嵌入词语的方法, 通过学习到的节点表示, 可以计算每个节点之间的相似性。Skipgram的原理为序列中的中心节点与周围的节点共同出现的概率更大。设中心节点wc在词典中的索引为c, 上下文词wo索引为o, Skip-gram 训练过程中存在两个大小为V ×n 的矩阵, 分别为上下文矩阵与中心词矩阵, 其中V 表示词库大小, n 表示训练出来词向量的维度, 每个词都被表示成作为序列中的中心节点时的向量v 存放在中心词矩阵中与作为上下节点的向量c 存放在上下文矩阵中, 给定中心节点得到上下节点的条件概率, 如式(6) 所示, 其中i 为节点在词典中的索引, vi是它为中心节点时的表示向量, ui为它是上下节点时的表示向量。
最终获得所有节点嵌入表示, 即节点向量表示, 如图5所示。
2.4学术信息推荐
在进行网络表示学习的过程中, 本文将序列中的节点类比作句子中的单词, 在进行推荐值计算的过程中, 同样利用空间向量模型的思想来进行节点相似度计算。向量空间模型(VSM)是Salton G[23]在1970年提出的一种文本代数模型, 在向量空间中以空间相似性来表达语义相似, 最常用的是余弦相似性。在获得所有节点嵌入表示后, 通过计算节点向量之间的余弦相似性来获取学术信息的推荐值, 节点pi和pj的相似度计算如式(7) 所示。
3实证及结果分析
3.1数据采集与预处理
3.1.1数据采集
本文主要使用Python 的工具包Selenium, 并结合CNKI 的导出文献功能来进行数据采集, CNKI自定义的导出文献字段有文献标题、作者、单位、关键词、摘要、发表时间。以华中师范大学的研究学者“熊回香” 为初始学者, 获得该学者在CNKI收录的所有文献信息, 再以其合作学者为查找条件, 获得其合作学者在CNKI 上被收录的文献信息, 以此反复3轮, 最终得到学者1077位, 学术文献1831篇。去除初始数据中重复的文献632篇后, 得到保留文献1199篇, 如表1所示。
3.1.2数据预处理
首先对学位论文、教学相关论文和会议纪要,如“情报学与情报工作发展论坛(2017)隆重召开并凝聚形成《南京共识》” “在‘第七届科学计量学与大学评价国际研讨会 上的致辞”“2021 ‘数据分析与应急情报 系列学术活动纪要” 等文献进行删除, 只保留与学者研究有关的文献, 最终得到实证文献1199篇, 并对其进行编号。然后, 将学者—文献—合作学者的关系统一处理为学者—文献关系, 并将日期保留至年份。同时, 为了方便下一步文献摘要的向量空间模型计算, 在数据预处理阶段也对文献摘要进行分词、去除停用词等操作,本文主要使用Python 工具包Jieba 的精确分词模式进行分词, 最终得到的数据结果如表2所示。
3.2异质网络构建与加权
3.2.1异质网络构建
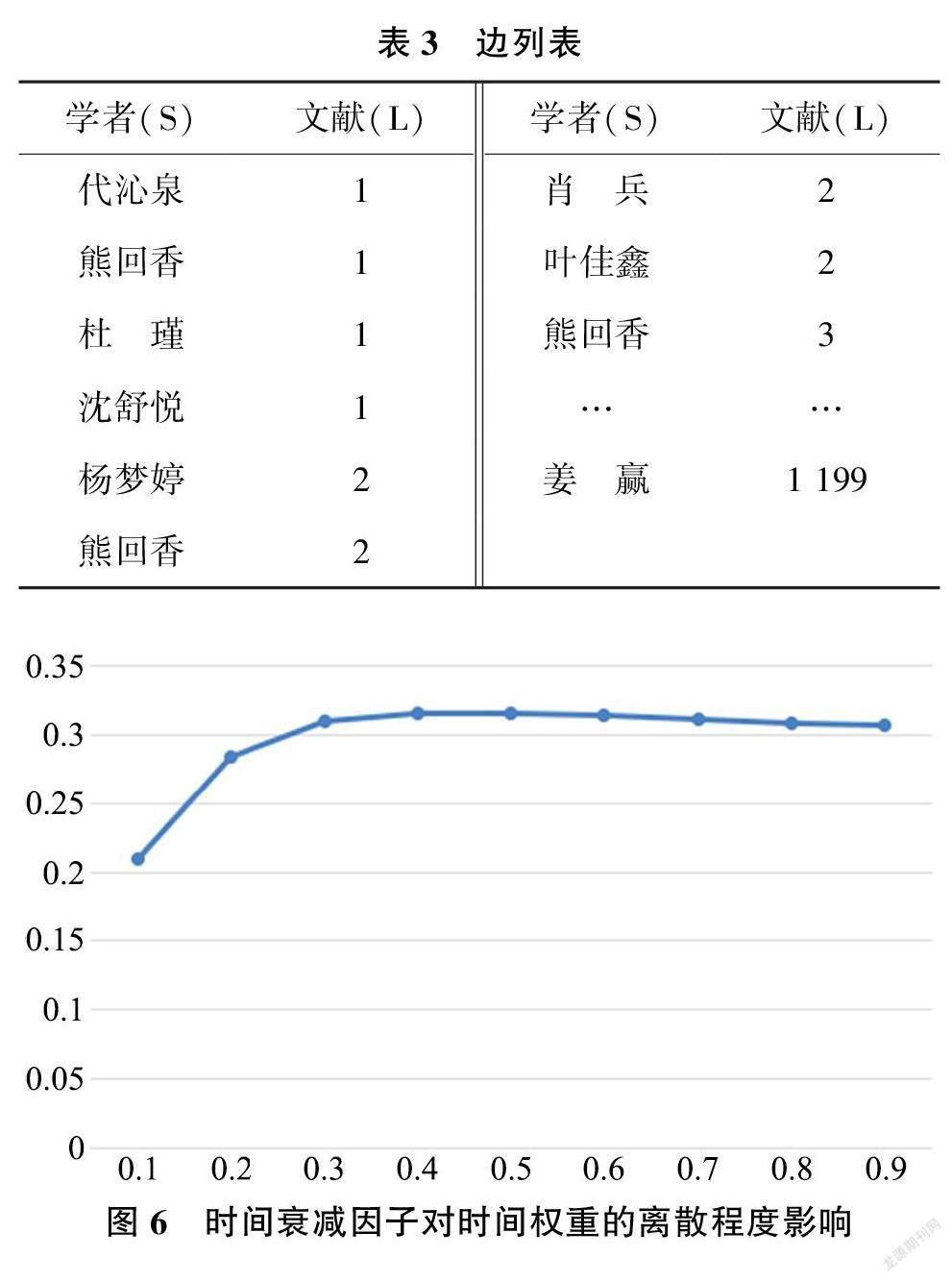
将表2中的学者节点S与文献节点L进行整理, 得到如表3所示的边列表, 该表可作为后续关系加权的初始表格。
3.2.2时间因子加权
式(1) 中的时间衰减因子γ 是计算时间权重时的重要参数, 它是衡量时间差对时间权重的影响程度, 在式中有着重要的作用。根据经验将γ 值设定为{0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1},本文采用数据离散度的指标———方差, 来进行时间因子γ 的分析。以文献发表年份{2011,2012,2013……2021,2022}为例, 得到不同γ 值下的该组数据离散程度, 如图6 所示。当离散程度越大, 随机游走概率越大, 即偏向性越强, 也就代表着游走的节点更能表征学者当前兴趣, 所以最终选择γ =0. 4进行后续实证研究。
利用式(1) 中的时间加权函数, 结合表2 中的学者、文献与发表时间可计算出每位学者—文献的时间权重, 如表4 所示。
3.2.3文献语义关系加权
语义加权主要关注文献摘要与文献摘要之间的语义相似度, 该相似度即代表文献—文献之间的权重。将上一节中进行分词后的摘要作为语料库, 得到每个词的TF-IDF值, 然后抽取出每个文本的TFIDF向量, 再利用式(3) 计算得到每一篇文献与语料库中文献的余弦相似度, 得到最终的文献—文献相似度结果, 如表5 所示。
将学者—文献的时间权重与文献—文献的语义加权添加在异质信息网络中, 得到如下包含边权值的边列表, 如表6 所示, 该表数据作为随机游走的基础数据。
3.3节点向量生成
由于在数据采集阶段, 主要收集了以“熊回香”学者为初始节点的数据, 从学者—文献—学者, 进行了3 輪采集, 最长的节点数为9, 所以本文将随机游走的游走长度设置为10, 即walk_length=10。在进行游走的过程中采用偏深度优先的游走来生成序列, 即q<1、p>max(q,1), 经过参数测试, 令q =0.5、p =1.1。最终, 进行概率随机游走所得到的元路径节点序列如表7 所示。
以第一次游走生成的节点序列为例, [‘李阳,‘1025,‘721, ‘1014, ‘徐健, ‘722,‘1021,‘1139, ‘王贤文,‘1140], 节点序列为学者节点“李阳”, 学术文献节点1025, 再游走到其高相似度文献“应急专家发现路径融合模型探究”, 到“应急知识库系统构建的关键问题与模块划分研究”, …, 概率游走到学者王贤文, 最终到达文献节点“全文引文分析视角下的造假论文学术影响研究”。通过对游走路径1 进行分析可以发现, 第5 个节点是从文献1014 游走到学者徐健, 文献1014 与721 主题上虽然都是应急决策,但是1014 的主题包含知识库系统构建, 从1014 到学者节点“徐建” 产生了一定的偏差。从上述可以发现, 路径长度大于3 之后, 其所反映的关联关系较弱, 所以本文在后续进行节点采样的过程中将这一特点纳入考虑范围。
序列生成之后, 将生成的序列当作句子输入Skip-gram 进行训练集采集与模型训练。为了简化损失函数的计算过程, 本文将采用负采样的方式进行训练集采集。根据上述对游走路径的分析示例,在进行训练采样时将采样窗口确定为3。经过Skipgram训练后, 可得到每一个节点的向量表示, 如表8所示。
3.4学术信息推荐
在本节中, 以“熊回香” 学者为推荐目标进行学术信息推荐, 将推荐目标节点向量作为输入值, 经过式(7) 的向量相似度计算, 可得到目标节点与所有节点之间的相似度, 然后将相似度高的节点根据文献、学者两种类别进行分类, 并从中剔除与目标学者直接相关联的文献以及已合作的学者。在推荐结果展示的过程中, 本文将推荐学者的发表文献关键词与CNKI 中的关注领域作为该名学者的关键词, 即表8 中的关键词字段, 同时以发表文献的关键词作为表9中的关键词字段, 以便进行后续的结果分析。由于学者与文献之间数量的差异, 推荐了学者相似度前8名, 如表9所示; 学术文献相似度前10名, 如表10所示。
3.5推荐结果分析
根据表9的推荐学者与表10推荐的相关论文,可以发现本模型取得了良好的推荐结果。通过检索目标学者单位的官方网站介绍与其所发表文章可知, 目标学者熊回香近期研究主要围绕其课题项目“融合知识图谱和深度学习的在线学术资源挖据与推荐研究” 开展。而从表9 中可以发现, 本模型所推荐的学者许鑫、范涛、王贤文、张宝隆、邓三鸿的关注领域有知识图谱、自然语言处理以及数据挖掘与深度学习领域, 而推荐学者许鑫、王贤文、邓卫华、杨建林、刘友华均在个性化推荐、用户兴趣与用户画像领域有所涉及。从整体上看, 推荐模型所推荐的学者与本文目标学者熊回香的现研究方向相同或相似。从表10 可知, 为目标学者推荐的文献有较强的针对性, 时间维度上价值较高, 目标学者的现研究方向大多与“个性化推荐” 有关,而推荐文献均与信息推荐有着较大的关联。
为了评价模型的有效性, 本文选取准确率(P)、召回率(R)與F 值(F)来评估推荐模型效果, 评价指标公式如式(8) ~式(10)所示。
其中, K 表示推荐列表长度, 将推荐成功的资源数量记作Nrl, 推荐资源中符合推荐兴趣的资源数量记作Nl 。由于本文是基于网络表示学习的推荐改进模型, 故选取基于网络表示学习[21] 的推荐模型进行对比。以CNKI 的作者关注领域代表作者的兴趣特征词, 若目标学者与推荐学者之间的特征词向量相似度大于0.25, 则说明推荐成功。以目标学者近两年发表文献关键词作为作者最新兴趣特征, 若目标学者最新研究与推荐文献之间的相似度大于0.25, 则说明推荐成功。本文从资源列表中随机选取30条推荐资源, 以30条推荐资源中推荐值排名前15条作为推荐列表, 以此来判断推荐效果, 结果如表11 所示。由表11 可知, 本文模型推荐效果优于基于未加权的网络表示学习推荐模型。
综上所述, 本研究提出的推荐方法中推荐学者与目标学者的研究方向高度匹配, 推荐模型推荐的学术文献与目标学者近期研究兴趣相近, 目标学者可以从推荐文献中得到启发, 迅速找到与自己研究方向相近的研究主题。本研究提出的推荐模型输出的结果符合目标学者的科研兴趣需求, 通过推荐潜在的同方向的研究学者和研究文献, 可以为研究者提供更加广阔的视野来开展研究。
4结语
本文提出了一种结合时间与语义加权的异质网络推荐方法, 该方法既考虑了学者的动态兴趣, 又考虑了文献之间的语义关系, 很大程度上缓解了推荐过程中的数据稀疏问题。在构建异质网络的过程中, 针对文献节点, 利用文本向量空间模型与余弦相似度计算得到文献之间的语义相似度, 将该相似度作为异质网络中的边权重, 最终构建了包含语义的异质网络, 从而在此异质网络上进行学术信息推荐。通过采集在线学术平台信息的相关数据, 对本文提出的推荐方法进行实证研究, 验证结果表明了该推荐方法的有效性。该推荐方法的意义在于, 在对学者进行信息推荐的过程中, 首先, 考虑了学者的动态兴趣, 为学者推荐其当前最感兴趣的内容;其次, 利用到文献节点的文本语义信息, 加强了学术—文献异质网络中节点表示的强度和效果, 提高了信息推荐的精准度; 最后, 由于异质网络存在多种节点类型, 在推荐过程中可为学者推荐学者以及文献两类学术信息。但本文仍存在一定的局限性,由于实证研究部分只使用了学者所发表的中文文献, 并未涉及学者所发表的外文文献, 一定程度上降低了推荐的准确度, 未来研究可考虑加入学者已发表的外文文献, 增加异质网络的丰富性, 从而提供更为丰富的推荐内容。
