
关联规则在特定行业审计数据分析中的应用
2023-03-23 02:39续婧范杰
科技资讯 2023年3期
续婧 范杰
(1.中国中钢集团有限公司审计部 北京 100080;2.首都医科大学附属北京中医医院 北京 100010)
随着综合国力的不断强大,我国的各行业发展不断扩大[1-2]。例如:为了便于国民使用医疗保险,定点零售药店和定点医疗服务机构的数量持续增加[3-5]。这给国民带来方便的同时,也导致审计变得越来越困难。违规使用保险的现象层出不穷,违反审计的手段多样且隐蔽,仅利用传统的审核方式来加强资金的监控难以满足当今各行业对审计的需求[6-7]。
针对上述问题,如何快速有效地对特定行业的审计数据进行分析,从而发现违反审计的行为是非常重要的。关联规则可以快速分析变量之间的依赖或关联关系,因此常被用于分析审计数据中的异常行为数据[8-9]。例如:可以发现异常参保人通常同时购买那种中药品,进一步结合购药金额、数量等信息分析是否存在医保欺诈行为[10]。该文对关联规则在特定行业审计数据分析中的应用进行研究,并以分析医保欺诈审计数据为例进行了实验。实验结果表明,该方法通过数据分析数据中的关联规则能够快速识别医保欺诈行为。
1 医保数据预处理
该文筛选在定点零售药店和定点医疗机构都有过医保刷卡记录的参保人作为研究群体,总人数共计47 028 人,其中异常购药参保人数为1 037 人,正常购药参保人数为45 991人。购药异常参保人判断依据具体如表1 所示。数据包含参保人1 年以内分别在定点零售药店和定点医疗机构的购药交易记录数据和交易明细数据。实验中训练数据集占总样本数据的75%,测试数据集占总样本数据的25%。该文主要分析异常参保人的购药序列中的药品关联情况,判断异常情况下通常同时购买什么药品。因此,只保留参保人的购药记录序列,其中时间以月为分界点,分界点内药品按照金额大小排序。

表1 异常数据筛选标准
2 关联规则挖掘
2.1 相关概念
项是数据库中的最小单位,通常用符号i表示。设I={i1,i2,…,in}是项的集合,其中ij(j∈[1,n])表示第j种药品。设购药记录数据库为D,其中每个元素有若干项组成,通常表示为E。E是I的子集,表示为E⊇I。给定一个项集A,如果A⊇E,则元素E包含A。对于任意两个项集A⊇I和B⊇I,关联规则表示为A⇒B,其中A∩B=ϕ。ms表示最小支持度,mc表示最小置信度。
定义1 项集的支持度sup(A)。在数据集D中,对于任意项集A,它的支持度为A在D中出现的概率,即sup(A)=P(A)。
定义2 关联规则的支持度sup(A⇒B)。对于任意两个项集A⊇I和B⊇I,关联规则A⇒B的支持度sup(A⇒B)表示为A∪B在D中的出现概率,即
定义3 关联规则的置信度conf(A⇒B)。对于任意两个项集A⊇I和B⊇I,关联规则A⇒B的置信度conf(A⇒B)表示为在包含A的元素中包含B的概率P(B|A),即
定义4 最小支持度阈值ms。最小支持度由用户设定,取值范围为[0,1],它表示关联规则或项集的最低重要性/有用性。
定义5 最小置信度阈值mc。最小支持度由用户设定,取值范围为[0,1],它表示关联规则的最低可靠性/确定性。
定义6 频繁项集。给定一个项集A,如果sup(A)=P(A)≥ms,则A为频繁项集。
定义7 强关联规则。对于关联规则A⇒B,如果A∪B是频繁项集(P(A∪B)≥ms),且cconf(A⇒B)≥mc,则A⇒B是强关联规则。
2.2 关联规则挖掘基本步骤
关联规则挖掘的基本步骤主要分为两个部分:第一,从数据集中挖掘所有的频繁项集,该文通过FPgrowth 算法[11]挖掘参保人购药记录中的频繁项集;第二,从第一步中得到的频繁项集中挖掘强关联规则。相较于挖掘关联规则,挖掘频繁项集的工作较为繁琐,且工作量大,因此该文重点介绍如何挖掘频繁项集。
3 医保审计数据分析建模
该文采用关联规则挖掘技术对参保人的购药记录中的关联药品进行分析,发现异常参保人通常同时购买什么药品,通过药品购买频率和购买数量判定是否存在代刷医保卡,代替购买药物等医保欺诈行为。图1是基于关联规则挖掘技术的医保审计数据分析建模示意图。

图1 审计建模流程图
3.1 FP-growth算法
FP-growth 算法的核心思想是构建FP-tree 树节点,以减少所需项集的数量。假设I={i1,i2,…,in}是数据库D中所有项的集合,Eset={E1,E2,…,Ed}是数据库D中所有元素的集合。每个元素包含I中的若干项。
假设参保人的购药序列为i5、i2、i1、i3、i5、i2、i4、i2、i3、i5、i4、i2、i5、i3、i6、i1、i2、i4、i6、i5、i3、i5、i4、i2、…。将序列以月为分界点划分为元素,得到元素集合列表,如表2 所示。通过扫描数据库D,计算每个项的支持度,即包含项的元素个数与总元素个数之比。
表2中的内容表示一个参保人的购药序列的元素划分,假设D中有m个参保人,则经过元素划分完成后得到12×m个元素。设最小支持度阈值为0.2,支持度小于0.2 的项视为可忽略项,将其从元素中删除,剩余项按照支持度大小降序排列,假设对表2 重新排序后的结果如表3 所示,从表3 可以看出,元素E7中的项i7由于支持度小于最小支持度阈值而被去除,而sup(i2)>sup(i5)>sup(i3)>sup(i1)>sup(i4)>sup(i6)。
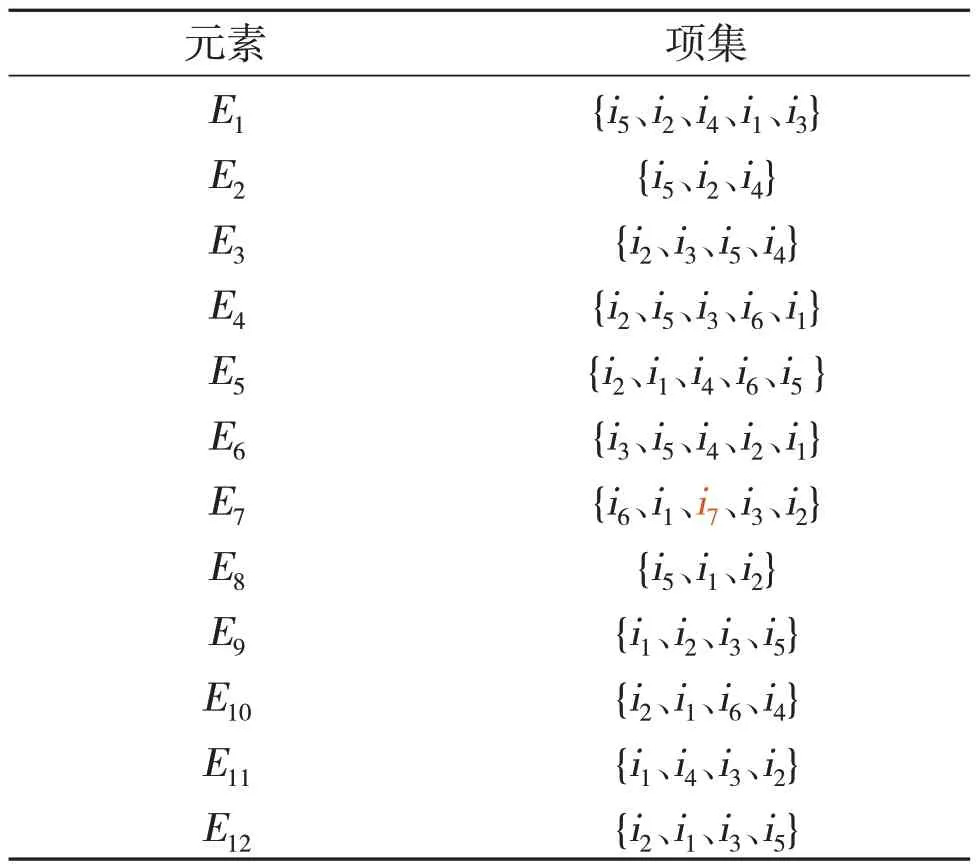
表2 元素划分表
假设表3 是小型数据库,计算每个项的支持度如图2 中左边表格所示,依据表3 中项的排列顺序将12个元素中的项依次加入FP-tree 中,得到如图2所示的FP-tree树状图。
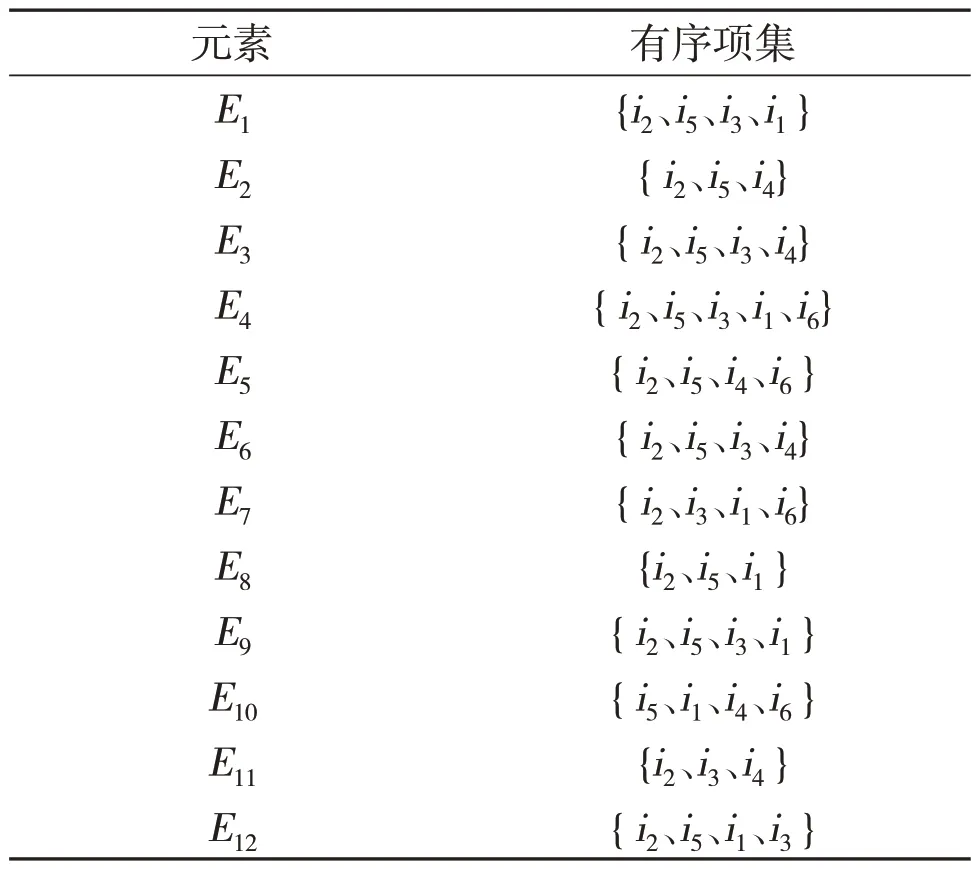
表3 元素包含有序项划分表

图2 构建FP-tree
3.2 实验分析
图3展示了在异常参保人购药记录中常购买的前15种药品。其中,前4种药物购买率高达60%以上,除第三种药物是糖尿病人为控制血糖可能需要长期服用以外,剩余3种药物均为非长期服用类药物,因此正常情况下的购买频率较低。显然这是一种异常现象。图4是图3中频繁项中存在的强关联规则,其中group1表示“头孢可肟分散片”和“盐酸二甲双胍片”组合,group2 表示“布洛芬缓释胶囊”和“格列齐特片(II)”组合,group3 表示“布洛芬缓释胶囊”和“莲花清瘟颗粒”组合,group4 表示“头孢可肟分散片”和“牛黄解毒片”组合。这4组规则是有效的,并且是强规则,说明具有异常购药行为的参保人所购的药品是存在一定关联的。

图3 药品购买频率
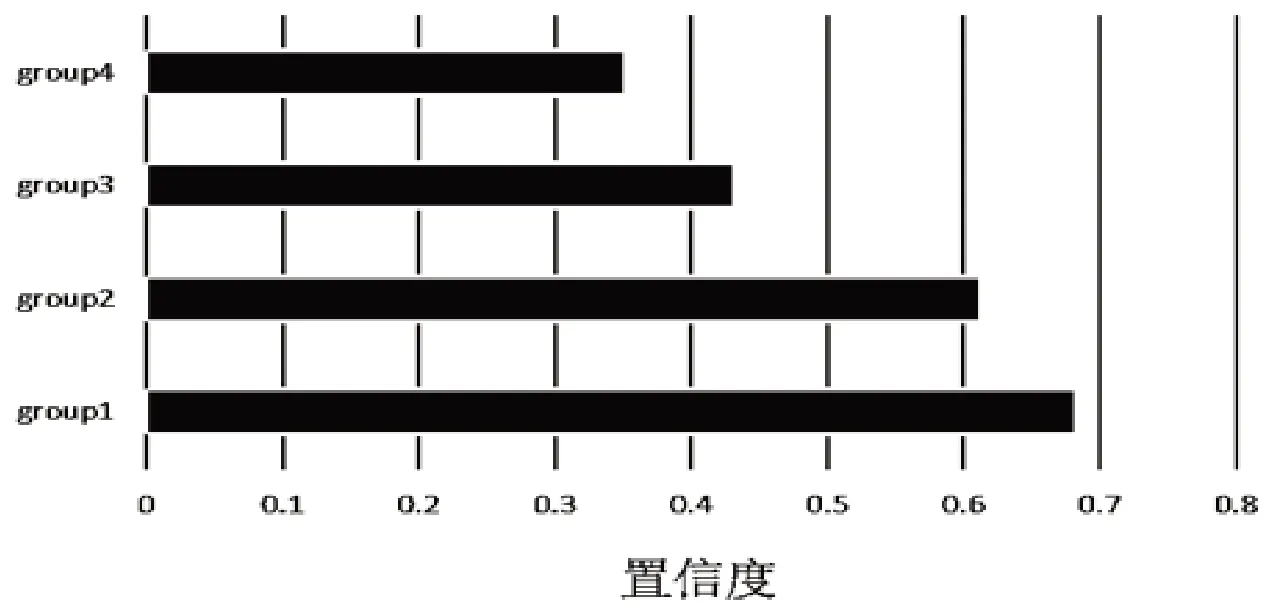
图4 药品中的强关联规则
4 结语
该文基于关联规则挖掘技术对对医保审计数据进行分析。首先,对参保人的购药记录数据进行预处理,得到以月为单位的参保人的购药项集;其次,通过关联规则挖掘建立医保审计数据集分析模型,通过模型可以得到具有异常行为的参保人购药记录中的不合理现象和组合。
猜你喜欢
中学生数理化(高中版.高考数学)(2022年4期)2022-05-25
今日农业(2021年21期)2021-11-26
新世纪智能(教师)(2021年2期)2021-11-05
教育周报·教育论坛(2021年21期)2021-04-14
天津科技大学学报(2018年4期)2018-08-22
中国防伪报道(2017年4期)2017-01-27
——基于计划行为理论框架下的研究
药学研究(2014年7期)2014-03-08
中国卫生政策研究(2014年1期)2014-02-03
中国全科医学(2013年16期)2013-04-19
网络安全与数据管理(2010年1期)2010-05-18
