
采用优化特征子集选取和改进SVR的养殖禽舍温度预测算法*
2023-03-04 04:58李继东王强辉
中国农机化学报 2023年2期
李继东,王强辉
(1. 河南林业职业学院,河南洛阳,471000; 2. 河南农业大学,郑州市,450046)
0 引言
中国作为世界上最大的水禽生产消费国家[1],发展具有集约化、无害化、规模化等特点的现代养殖势在必行[2]。温度调控直接影响集约化养殖的成败,如果不能准确掌握禽舍气温环境温度变化趋势,及时进行温度调控,极有可能导致大量禽畜死亡,引发严重经济损失。因此,研究高精度养殖禽舍温度预测算法具有重要现实意义。
监督学习、无监督学习和半监督学习是目前主要的温度预测方法,被广泛应用于海洋环境、水产养殖等领域[3-4],学者们也相继提出了一些研究成果,Xu等[5]将热力机理模型和人工蜂群算法应用于水产养殖水温预测;徐龙琴等[6]采用极限学习机实现对育苗水温的预测分析;Graf等[7]在人工神经网络和小波变换的基础上构建了一种江河水温控模型。这些研究成果大多涉及大规模数据处理,如何最大限度降低数据样本之间冗余度和差异性对预测结果的影响,是值得深入研究的问题。特征提取作为一种高效的数据处理技术,其能够在有效选取高分辨能力特征子集的同时,大幅度降低数据处理维度,提高温度预测精度[8]。特征提取方法可分为单变量度量和多变量度量提取,常见的单变量度量提取方法有Wrapper模型、主成分分析法(PCA)、Filter模型等,这类方法由于基于单变量度量准则,因此选取的特征子集并不是最优[9]。多变量度量提取主要选用最大信息压缩指数、最大信息系数、Pearson系数等作为度量准则,仇利克等[10]融合Pearson系数和信息增益度量,实现特征子集选取;孙广路等[11]基于最大信息系数度量和对称不确定性标准,并采用马尔科夫毯方法算法进行特征子集选取。上述研究实现了特征子集的有效提取,但是还缺乏对特征冗余度与数据多样性的论证分析。完成特征子集选取后,可以利用极端学习机、支持向量机、BP神经网络等进行温度预测分析,Teng等[12]搭建了采用BP神经网络的预测模型;叶林等[13]设计了一种融合RBF神经网络和GA预测算法;王昕等[14]给出了基于PCA、PNN和SVR预测方案。这些方法往往需要大规模数据集作支撑,存在数据样本之间的差异对预测结果有较大影响、训练学习容易陷入局部最优的缺陷。综上所述,提取具有较高辨识度的特征子集以及降低数据差异性对预测结果的影响是提高养殖禽舍温度预测效率和精度的关键。
为此,提出一种基于智能优化特征子集选取和模糊聚类改进SVR的温度预测方法,通过构建最优特征子集选取模型,选取出最大限度保持原始数据辨识能力的特征子集;建立模糊聚类改进SVR预测机制,最大程度的降低样本数据差异性对预测精度的影响。实验仿真结果表明,本文提出的预测方法具有良好的温度预测性能。
1 最优特征子集选取模型
养殖禽舍环境温度受相对湿度、光照强度、TSP(总悬浮颗粒物)等多种因素影响,如果把所有因素作为温度预测输入变量,不仅增加了数据处理复杂度,而且数据之间冗余度会影响预测精度[15],因此提出最优特征子集选取模型,以最大限度选取出保持原始数据辨识能力的特征子集。
1.1 最优特征子集
对于具有N个样本的数据集合D=(x1,x2,…,xN),样本xi由M个特征进行描述,即
xi⟸Fei=(Fi1,Fi2,…,Fij,…,FiM)
(1)
式中:Fij——第j(j=1,…,M)个特征。
设定数据集按照一定规则可以被划分为K个分类C(D)=(C1,C2,…,CK)。
(2)
(3)
式中:Ci——第i个分类;
Ni——Ci内数据个数。
特征提取即在Fei内选取具有m个特征的子集Fei′=(Fi1′,Fi2′,…,Fim′)(1≤m≤M),并且最大限度保持原始数据分类能力。定义特征子集选取向量P=(p1,p2,…,pM)。
pi=0or1
(4)
利用P=(p1,p2,…,pM)对xi进行特征选取

(5)
从式(4)~式(5)可以看出,P仅有m个非0元素,且当pi=1表示第i个特征被提取。当P确定具体表达形式后,其非0元素对应特征组成的集合即为特征子集Fei′,N个Fei′组成特征子集矩阵
(6)
为此,定义最优特征子集选取指标CIP(D),并证明当CIP(D)取最小值时,此时P对应的特征子集即为最优特征子集
(7)
其中,U=[χij]K×K为类间相似矩阵,且为常数矩阵,χij表示分类Ci与Cj之间相似度;RM×K=(PT,PT,…,PT)为特征子集选取矩阵;ΦN×M=(Fe1,Fe2,…,FeN)T为特征矩阵;ψ=(φij)N×K为相关性矩阵,φij∈[0,1]表示xi与Ci的相关程度,采用文献[11]提出的最大信息系数法进行求解。
命题:CIP(D)取最优值时得到的特征子集,特征之间的冗余度最小,而且特征子集最大限度保持原始数据分类能力。
证明:假设Fei所有特征已中心标准化处理,即
为便于描述,令U′=N2U、G=ψT(ΦR)(ΦR)Tψ,对式(7)有

(8)

(9)


(10)

证毕。
特征子集提取过程如下。

1.2 最优特征子集选取模型求解
最优特征子集评价指标CIP(D)求解过程属于NP难题,本文采用灰狼算法(Grey Wolf Optimizer,GWO)[16]进行优化求解。GWO是近期才被提出的一种新型群智能启发式计算技术,其通过模拟狼群进食行为,将种群分为3级层次结构,狼群在不断学习进化中完成捕食行为,进而实现全局优化求解。因其具有参数简单,寻优能力强等特点,越来越受到关注[17](GWO基本原理不再赘述)。设GWO种群规模为O,每头狼的编码Xi等效为特征子集选取向量P,即Xi=(p1,p2,…,pM)。目标函数f(Xi)选取为最优特征子集评价指标
(11)
由于Xi的编码是离散的,如果仍采用GWO连续迭代更新机制,会产生大量不符合要求的解,为此提出离散灰狼算法(DGWO),重新定义种群迭代进化机制。
1) 编码替换。设定Xi(t)与Xj(t)(i,j=1,…,O且i≠j)存在β个不同编码位(1≤β≤M),定义“编码替换”操作α⊗CR[Xi(t),Xj(t)]为Xi(t)随机选取α个不同于Xj(t)的编码位,来替换自身相对应的编码位(0≤α≤β),即
(12)
式中:Tmax——最大迭代次数。
从式(12)可以看出,运算初期,个体选择较多的不同编码位进行替换,以提高收敛效率。
2) 编码突变。定义“编码突变”操作λ⊗CM[Xi(t)]为随选取Xi(t)内λ个编码位进行取反操作(1≤λ≤M),即
Xi(t+1)=Xi(t)+λ⊗CM[Xi(t)]
λ=[(M-1)(cos(tπ/Tmax)-η2(t/Tmax)2+1)]
(13)
图1给出了编码替换、编码突变操作示意图。
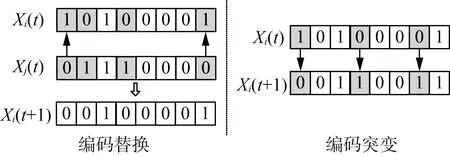
图1 编码替换与编码突变操作示意图
采用DGWO对最优特征子集选取过程中进行优化求解:进化初期,处于第2、3级的狼以头狼为学习对象,执行编码替换操作以提高收敛效率;当种群处于进化停滞状态时,头狼和第2级狼执行编码突变操作,从而扩大搜索空间以提高收敛精度,最终得到最优特征子集选取向量Pbest,其相对应的特征集合即为最优特征子集。图2给出了DGWO优化求解最优特征子集示意图。

图2 DGWO优化求解最优特征子集示意图
2 模糊聚类改进SVR预测
2.1 支持向量回归机(SVR)

(14)
对式(14)引入拉格朗日多项式,有
(15)

(16)

2.2 模糊聚类改进SVR预实现


ωSΦS(x)-vi‖2
(17)

有
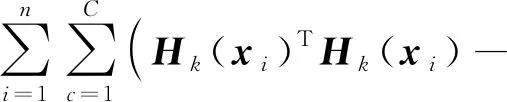
(18)
此时,定义核函数κk(xi,xi)=Hk(xi)THk(xi),当κk(xi,xi)符合Mercer条件时,只需要选取S个核函数,就可以通过式(17)、式(18)实现聚类分析。
对于养殖禽舍温度预测问题,往往事先并不知道数据分类个数,而且式(21)~式(24)迭代计算过程需要消耗大量运算资源,为此采用GWO对聚类函数进行求解,定义GWO狼编码为gi(t)为聚类中心V。
gi(t)=(v1,…,vC)
(19)
3 养殖禽舍温度预测实现
以肉鹅养殖为例,影响养殖禽舍温度TAB的因素有相对湿度(HR)、光照强度(LI)、TSP(TP)、二氧化碳(CO2)、氨气(AM)、硫化物(SU)、空气流动速度(VA)等。利用温度传感器、光照传感器等,每隔1 h进行数据采集,得到数据集合D={(xi,yi)}i=1toN:
xi=(HR,i,LI,i,TP,i,CO2,i,AM,i,SU,i,VA,i),
yi=TAB,i
(20)


图3 肉鹅养殖禽舍温度预测实现示意图
4 试验结果与分析
分别对本文提出的最优特征子集选取、多度量核FCM和养殖禽舍温度预测进行仿真试验。
4.1 最优特征子集选取性能验证
采用典型测试数据Ionosphere(ION)、Arrythmia(Ary)、Madelon、Dexter 4种真实数据对最优特征子集选取性能进行验证,表1给出了4种数据具体参数情况。

表1 仿真具体参数设置Tab. 1 Specific parameter settings of simulation
评价指标设定为数据分类正确率Γ和分类精度Θ。
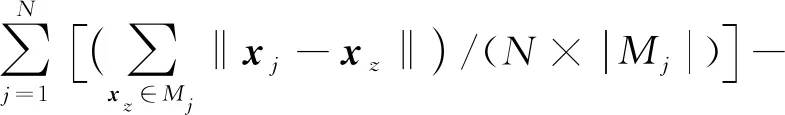
(21)
其中,Mj、Ej分别表示与xj异类样本集合和同类样本集合,|Mj|、|Nj|为集合规模。Θ反映了数据分类精度情况,取值越小分类效果越好。选取KNN(K-Nearest Neighbor)分类器,并采用文献[11]提出的FCBF特征提取算法、文献[19]提出的SPEC特征提取算法和经典的ReliefF特征提取算法进行对比试验,每种算法独立运行30次,取分类正确率、分类精度均值进行对比分析,对比结果如表2所示。

表2 不同特征提取算法对比结果Tab. 2 Comparison results of different feature extraction algorithms
从表2可以看出,对于4种典型测试数据,本文所提特征提取算法无论是在分类正确率上还是在分类精度上,都要优于其他算法,分类正确率提高约6.3%~23.5%,这表明本文所提算法选取出的特征子集具有更好的分类能力,分类正确率几乎都在96%以上。
4.2 多度量核FCM性能验证
采用Adult、Nursery数据集和人工数据集验证多度量核FCM性能,其中,Adult、Nursery数据集的分类个数已知,人工数据集的分类个数对聚类算法未知。选取文献[13]的遗传模糊FCM和文献[20]的核主元熵FCM进行对比实验,每种算法独立运行30次。分别选取聚类正确率均值Λ和式(17)所示的J(U,V)对比值进行对比分析(J(U,V)取对比值),表3给出了对比结果。

表3 不同聚类算法聚类结果对比Tab. 3 Comparison of clustering results of different clustering algorithms
从表3可以看出,对于典型测试数据Adult、Nursery数据集,3种聚类算法的聚类正确率都达到了96%以上。但是,对于人工数据集,由于分类个数未知,导致遗传模糊FCM和核主元熵FCM几乎不能实现数据有效分类,而本文算法表现出了优秀的聚类性能,特别的,对于高维规模数据聚类问题,本文聚类正确率保持在95%左右,实验结果验证了多度量核FCM算法复杂聚类问题良好性能。
4.3 养殖禽舍温度预测
(22)

综上仿真试验结果,本文提出的基于优化特征子集选取和改进SVR的养殖禽舍温度预测算法,采用了最优特征子集选取模型,最大限度了保持了原始数据分类识别能力;利用多度量核FCM对数据样本进行聚类分析,降低了数据差异性对预测精度的影响,使得预测结果更具可信度,研究结果能够为肉鹅等养殖环境温度调控提供支撑。
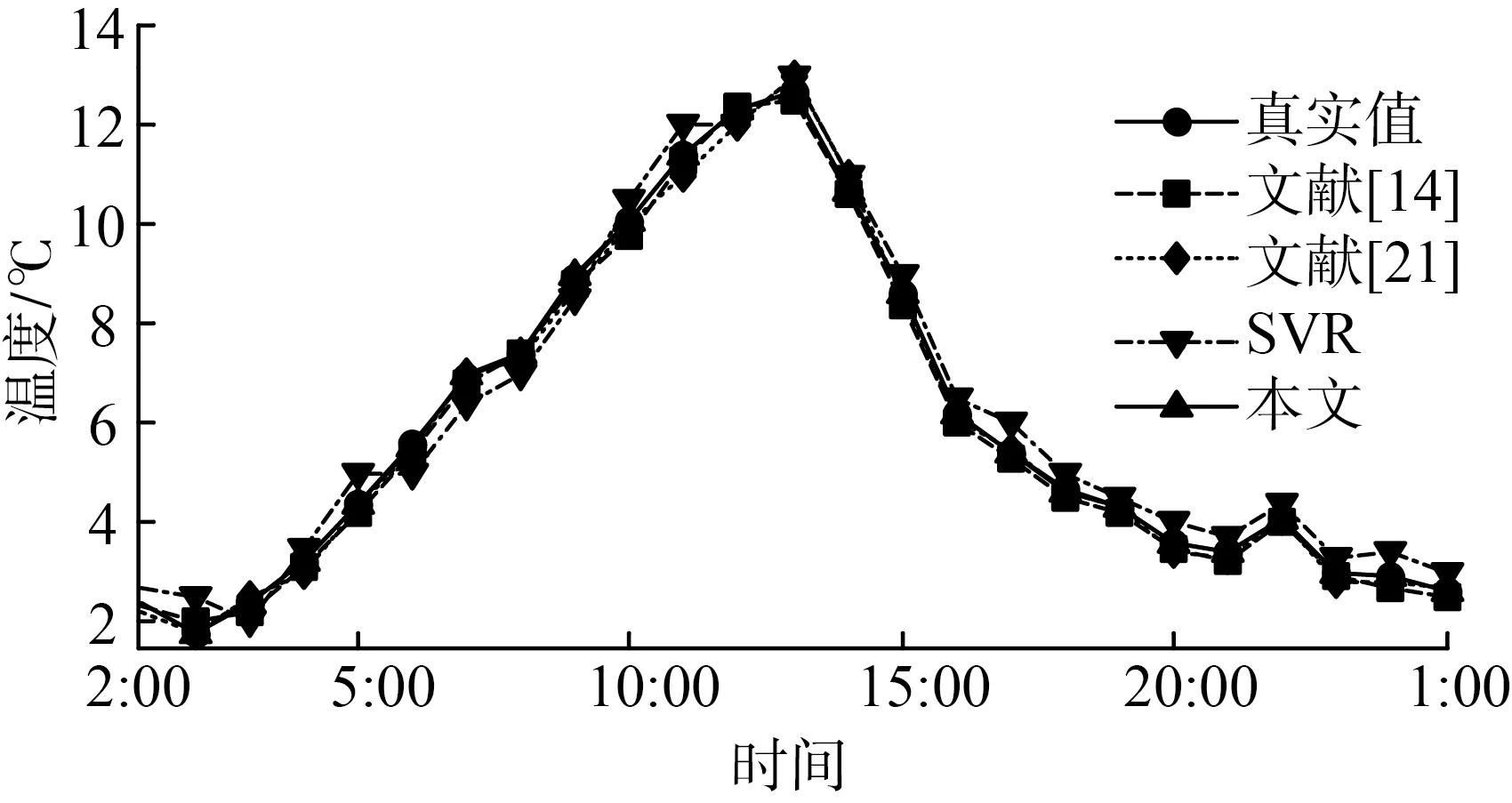
(a) 3月18日温度变化图
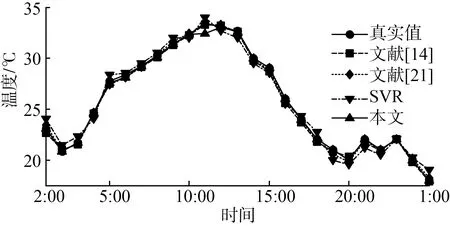
(b) 8月23日温度变化图

表4 不同温度预测算法评价指标Tab. 4 Evaluation indexes of different temperature prediction algorithms
5 结论
提出了一种基于优化特征子集选取和改进SVR的养殖禽舍温度预测算法,该算法融了特征子集提取、多核度量FCM和SVR预测等技术,很大程度地提高了禽畜养殖温度预测的精度和可靠性,聚类正确率可以保持在95%左右,禽舍温度预测均等系数可以达到0.96以上,具有较好的推广应用价值。下一步将重点围绕提高算法预测效率方面进行研究。
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
计算机与数字工程(2021年1期)2021-02-25
阜阳师范大学学报(自然科学版)(2020年3期)2020-08-13
南京大学学报(数学半年刊)(2020年1期)2020-03-19
铁道通信信号(2019年6期)2019-10-08
家禽科学(2018年10期)2018-01-16
雷达学报(2017年6期)2017-03-26
都市丽人(2015年4期)2015-03-20
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
