
一个实体关系与事件抽取的通用模型
2023-02-20 09:38杨红菊靳新宇
计算机工程 2023年2期
杨红菊,靳新宇
(1.山西大学 计算机与信息技术学院,太原 030006;2.山西大学 计算智能与中文信息处理教育部重点实验室,太原 030006)
0 概述
信息提取的目的是从非结构化自然语言文本中提取结构化知识。对于给定的自然语言句子,信息提取的子任务事件抽取根据预先设定的事件类型及其所包含的事件信息点,预测句子中的事件信息。事件类型和事件中所包含的关系信息定义了事件抽取的范围(事件类型:地震;事件论元:地点、事件、伤亡人数)。实体关系抽取的目的是根据给定自然语言语句设置的预定义SPO 三模板,提取与模板相匹配的所有语句信息。SPO 三模板定义关系P、相应的主体S和对象O。例如事件类型:“音乐专辑”;实体关系:“所属专辑”“主体类型”“歌曲”。
研究人员对事件抽取和实体关系抽取方面的工作进行大量研究,但未同时解决两个任务均存在的共性问题。因此,本文提出一种两阶段的实体关系抽取和事件抽取的通用模型。受预训练语言模型的启发,采用RoBERTa 表示作为编码器,获得共享的特征表示。将多标签分类任务用于抽取实体关系或事件类型,利用多个二进制分类器确定论元的范围,以解决汉语中的角色重叠、词触发不匹配、词边界问题。
1 相关工作
1.1 问题描述
由于中文存在特定的语言问题[1],因此中文信息抽取是一项比较困难的任务。汉语在词与词之间没有定界符,分词通常是文本数据进一步处理的必要步骤,导致触发词不匹配[2]。基于词分类的方法通常会受到这种影响。例如,一个句子中有“打死”两个字会触发两个不同的事件:由“打”触发“攻击”事件和由“死”触发“死亡”事件。为避免该问题的出现,本文将事件抽取和实体关系抽取作为基于单个字符的分类任务。
事件抽取和实体关系抽取的例句如表1所示。两个例子分别来自千言数据集中信息抽取任务的事件抽取任务数据集DuEE[3]和关系抽取数据集DuIE[4]。

表1 事件抽取和实体关系抽取例句 Table 1 Examples of event extraction and entity relationship extraction
从表1 可以看出,实体关系抽取任务和事件抽取任务的数据存在三个相似特点:1)在事件抽取任务中单个实例允许包含多个事件,例1 提到两个事件,其中一个事件类型为“人生-结婚”,另一个是“人生-生子”,在实体关系抽取中,单个实例也允许包括多个关系及其主客体,例如,例2 提到的三个关系“所属专辑”“歌手”和“母亲”;2)在事件抽取中允许不同的事件论元共享相同的论元角色,例如,例1 中“余文乐”和“王棠云”共同承担了角色“结婚双方”,在实体关系抽取中,例2 的“叶惠美”和“周杰伦”都属于“人物”类别;3)事件抽取一个论元可以扮演不同的角色,“王棠云”在第一个事件中扮演角色“结婚双方”,在例1 中第二个事件中扮演角色“产子者”,在实体关系抽取中,关系是有方向性的,例如“周杰伦”可能既扮演现实角色“父亲”,又扮演角色“儿子”。
1.2 研究现状
事件抽取和实体关系抽取最初都是基于模板匹配来完成的,模板通过手工或自动获取的方法获得,抽取时通过各种模板匹配算法找出符合模板约束条件的信息。RILOFF等[5]使用事件内容描述和上下文语义信息开发自动匹配事件抽取系统。KIM等[6]开发一个可以从文本中提取基于事件信息的语言模板系统,缩短了构建知识库的时间。YU等[7]对相关领域的语料库进行研究,并结合领域专家编写的文本关系规则,对文本进行实体关系抽取。基于模板匹配的方法在领域事件抽取任务中取得较优的效果,但其系统的可移植性差,模板的构建所需劳动量和专业指导量较大。
机器学习在自然语言处理中的应用已取得一定成果。将事件抽取和实体关系抽取任务作为分类任务,已成为当前研究热点。其中,神经网络和深度学习已成为事件抽取和实体关系抽取的关键方式。ZENG等[8]将卷积神经网 络(Convolutional Neural Network,CNN)应用于实体关系抽取。CHEN等[9]提出一种基于动态多池化卷积神经网络的事件抽取模型,以捕获语句中包含的多个事件信息。SOCHER等[10]使用循环神经网络方法分析语句,考虑语句的语法结构并完成实体关系提取任务。FENG等[11]提出使用双向长短期记忆(Bidirectional Long-Short Term,BiLSTM)网络和卷积神经网络进行事件抽取,在多种语言上取得有效成果。NGUYEN等[12]将双向递归神经网络的协同框架应用到事件抽取任务中。KATIYAR等[13]在实体关系提取任务中将递归神经网络与注意力机制相结合。LIU等[14]针对句子中含有多个事件的问题,将语法信息引入到框架中来增强信息流,将语言模型和图卷积神经网络相结合,实现联合抽取事件触发词和事件论元信息。武国亮等[15]提出一种基于加强命名实体识别任务反馈的我国应急抽取方法FB-Latiice-BiLSTM-CRF。唐朝等[16]提出一种融合残差网络和双向门控循环单元的混合模型来完成关系抽取任务。
预训练模型基于迁移学习的思想,通过训练大型数据集生成模型,根据下游任务,小型数据集对预训练模型进行微调,能有效提升模型性能,加快模型训练的收敛速度。预训练模型可以学习到文本深层语义信息,解决了相同词语在不同上下文中具有不同特征的问题,因此,被应用于事件抽取和实体关系抽取任务中,并取得较好的效果。YANG等[17]将事件抽取分为两个阶段,使用预训练模型BERT 分别对触发词和事件论元进行抽取,根据事件角色的重要性重新加权损失函数。ZHAO等[18]提出一个多样化的问答机制和答案集成策略,以改进现有基于机器阅读理解的实体关系框架。DU等[19]将事件抽取任务转化为阅读理解任务,使用两个基于预训练模型BERT 的问答模型,分别抽取触发词和事件论元。ZHONG等[20]提出一种简单pipeline 方法,采用两个相互独立的预训练模型进行实体识别和关系识别,在多个数据集上具有较优的性能。LIU等[21]通过逻辑回归模型抽取触发词,根据触发事件类型,利用问题模板进行无监督问题生成,最后使用基于预训练模型BERT 的问答模型进行事件论元抽取。XU等[22]定义事件关系三元组来明确表示事件触发词、论元和论元角色之间的关系,并提出一种新的中文事件联合抽取框架,该框架基于预训练语言模型BERT的共享特征表示来联合预测事件触发词和事件论元。王炳乾等[23]提出一种端到端的多标签指针网络事件抽取方法,并将事件检测任务融入到事件角色识别任务中,达到同时抽取事件角色及事件类型的目的。SUI等[24]将预训练模型BERT 与非自回归解码器相结合,将联合实体和关系抽取任务表述为集合预测问题,并提出一个基于集合的损失函数。
2 本文模型
本文将事件抽取和实体关系抽取均看作一个两阶段的任务,包括类型抽取器和论元抽取器。类型抽取器是抽取事件抽取任务中的事件类型和实体关系抽取任务中的关系类型,论元抽取器是抽取事件抽取任务中每个事件所包含的事件论元和实体关系抽取任务中与关系相对应的主体和客体。本文模型结构如图1 所示,由一个类型抽取器和一个论元抽取器组成,两者都依赖于RoBERTa 的特征表示。

图1 本文模型架构Fig.1 Framework of the proposed model
2.1 类型抽取器
传统的序列标注模型需要预测每个字符触发的事件或实体关系。然而,本文模型预测整个句子中所包含的所有事件类型或实体关系类型,并将其作为一个多标签分类任务,其标签是事件类型或实体关系类型。
本文采用RoBERTa 提取文本的语义特征,输入部分将每个句子分割为单个字符。为进一步提取文本特征,本文对RoBERTa 输出的特征矩阵进行卷积操作(如图1 中左半部分所示)。
令Wi∈Rk表示RoBERTa 输出的特征矩阵句子中第i个字的k维向量,长度n为句子,其特征矩阵的表示如式(1)所示:

其中:⊕表示连接符。令ω∈Rh×k表示卷积核,h×k表示窗口大小,因此通过卷积操作的特征c表示为:

其中:b∈R 表示偏执变量;f表示非线性激活函数ReLU。在卷积操作后,特征矩阵W1:n转化成特征图c,表示如式(3)所示:

采用最大池化的方式将特征图c变为=max{c}。本文使用三个不同大小的卷积内核来提取文本信息。
2.2 论元抽取器
论元抽取器的输入与类型抽取器的输入相同,但是,论元抽取器需要知道句子中所包含的事件类型或实体关系类型。首先,在数据集中通过预训练模型进行微调,以获取文本序列的语义表示。将获取的词表示向量输入到BiLSTM 模型中,以进一步整合文本语义信息。
本文给定输入序列X={x1,x2,…,xn},通过RoBERTa模型后可得W={w1,w2,…,wn},其中wi表示第i个词的上下文嵌入,n表示序列最长长度,W表示BiLSTM 的输入。t时刻的隐藏状态是ht=[;],其中表示t时刻前向LSTM 的信息,表示t时刻反向LSTM 的信息。最后由BiLSTM 编码后的句子可表示为R={h1,h2,…,hn}。
与类型抽取器相比,论元抽取器更复杂,因为其存在论元对事件类型或实体关系类型的依赖性、论元是长名词短语以及论元角色重叠问题。为解决论元抽取器中的后两个问题,本文在RoBERTa 上增加多组二值分类器。每组分类器为一个论元角色提供服务,以确定扮演分类器的所有论元范围,且每个范围都由一个头位置指针和一个尾位置指针确定。一个参数可以扮演多个角色,一个字符可以属于不同的参数。本文使用和分别表示句子字符中每个论元角色的开始和结束的概率值,如式(4)和式(5)所示:

其中:下标s 表示头位置;下标e 表示尾位置;Wrs和分别表示用于检测论元角色r的开始和结束的二元分类器的权重;R(t)表示经过BiLSTM 编码后的句子表示。
2.3 损失函数
在论元抽取器中,由于论元角色之间的频率存在很大差距,本文使用文献[11]在ACE2005 数据集上的加权方法,根据论元角色的重要性对损失函数重新加权,并使用角色频率(Role Frequency,RF)和逆类型频率(Inverse Type Frequency,ITF)来衡量论元角色的重要性。角色频率定义为角色r出现在类型v(事件类型或关系类型)中的频率。逆类型频率定义为包含角色r的类型v的对数比例的倒数。RF和ITF 的表示如式(6)和式(7)所示:

其中:表示在类型v中角色r的计数;V表示类型的集合。
本文将RF-ITF作为RF和ITF的乘积:RRF-IITF(r,v)=RRF(r,v)×IITF(r)。I(r,v)是通过RF-ITF 衡量角色r在类型v中的重要性,如式(8)所示:

本文给出类型v的输入,主要检测所有论元开始和结束的二进制分类器的损失函数Ls和Le,如式(9)和式(10)所示:

其中:H表示交叉熵损失函数;R表示论元角色集合;S表示输入句子;|S|表示S中的字符数。最后,本文将Ls和Le的平均值作为论元抽取器的损失函数L。
3 实验
3.1 实验数据
本文使用千言数据集上信息抽取任务中提供的事件抽取数据集DuEE 和关系抽取数据集DuIE。
DuEE 由现实世界热门话题和新闻构建,包含19 640 个事件,这些事件被分为65 种不同的预定义事件类型,41 520 个事件论元被映射到121 个唯一的预定义论元角色。该数据集分为12 000 条训练集、1 500 条验证集和3 500 条测试集。
DuIE 是从百度百科、百度贴吧、百度信息等网络信息流中获取,涵盖现实世界信息需求的主要领域,包括实体描述、娱乐新闻、用户生成文章等。该数据集包含超过43 000条三元组数据、21 000个中文句子及48个预定义的关系类型。该数据集分为17 000 条训练集、21 000 条验证集和21 000 条测试集。
3.2 评价指标
在评测方法上,本文事件抽取部分采用字级别匹配F1 值作为评价指标。F1 值的计算如式(11)所示:

其中:P表示预测论元得分总和与预测论元数量的比值;R表示预测论元得分总和与所有人工标注论元数量的比值。
实体关系抽取部分采用式(11)中的F1 值作为评价指标。但不同的是:P表示测试集所有句子中预测正确的SPO 个数与测试集所有句子中预测出SPO 个数的比值;R表示测试集所有句子中预测正确的SPO 个数与测试集所有句子中人工标注的SPO 个数的比值。
3.3 实验参数
本文模型使用PyTorch 框架进行深度学习来实现,通过反向传播和随机梯度下降训练网络。Python 语言用于完成网络构建、训练和测试。
本文使用的预训练模型是中文版的RoBERTa-Large[25],共有24层,隐藏层维数为1 024,采用16 头模型,共330×106个参数。在TITAN Xp GPU 上利用RoBERTa 进行预训练,epoch 为10,最大序列长度为256,优化算法为Adam,学习速率为2e-5,训练的batch_size 为8,BiLSTM 的隐藏单元大小为256。
3.4 实验过程
本文对主体模型进行调整,如去掉BiLSTM 层(ours_without_BiLSTM)、去掉在损失函数上的加权(ours_without_newloss),并分别对调整后的模型进行实验。在实体关系抽取任务的结果中,三元组是包含方向性的,该方向性是由简单的规则所决定。为证明该模型的有效性,本文将其与以下传统模型进行比较:
1)DuEE_baseline 模型:采用基于ERNIE 的序列标注方案,分为一个基于序列标注的触发词抽取模型和一个基于序列标注的论元抽取模型。
2)DuIE_baseline模型:使 用ERNIE 作为编码层,对字级别Token 进行编码,解码层是一个全连接层,以ERNIE 字向量作为输入,输出一个多层label实现实体关系的抽取。
3)BERT-CRF 模型:经典的序列标注模型,事件抽取包括触发词抽取和论元抽取,在实体关系抽取中抽取主体、客体以及实体关系。BERT 模型用于在预训练语料库上抽取的文本特征,并将其输入到CRF层。
4)RoBERTa-CRF 模型:其实验过程与BERT-CRF模型相同,将其中的BERT 模型替换为RoBERTa模型。
以上序列标注模型的标签均为实体关系/事件类型和其相对应的实体关系/事件论元角色的组合,每个Token 根据其在实体span 中的位置(包括B、I、O三种),为其标注三类标签。
3.5 结果分析
表2 和表3 所示为不同模型在DuEE 和DuIE 测试集上的对比结果。从表2 可以看出,本文模型相较于DuEE_baseline 和DuIE_baseline 有较大的优势,并具有较高的召回率。在事件抽取任务中损失函数的调整和BiLSTM 层的加入,进一步改进了模型的抽取效果。

表2 在DuEE 测试集上不同模型的实验结果对比 Table 2 Experimental results comparison among different models on DuEE testset %
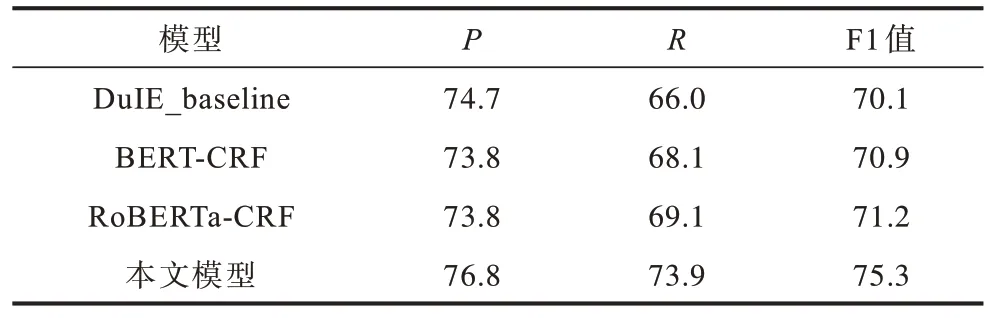
表3 在DuIE 测试集上不同模型的实验结果对比 Table 3 Experimental results comparison among different models on DuIE testset %
相比传统基于CRF 的序列标注模型,本文所提论元抽取器的优势是能够有效地处理两个任务中角色重叠的问题。本文将DuEE 验证集中论元角色重叠的110 条样本作为验证集Dev2,将DuIE 验证集中论元角色重叠的6 162 条样本作为验证集Dev3,并在这两个数据集上进行对比实验,结果如表4 所示。本文模型在处理两个任务中角色重叠问题上具有较优的效果。

表4 在Dev2 和Dev3 验证集上不同模型的实验结果对比 Table 4 Experimental results comparison among different models on Dev2 and Dev3 validation sets %
表5所示为在两个任务中经典的RoBERTa-CRF模型和本文模型的抽取结果对比。例1 和例2 为事件抽取样例,例3 为实体关系抽取样例。在处理类似例1 中存在角色重叠问题的样本时,RoBERTa-CRF模型会丢失事件类型“人生-死亡”;在处理类似例2的样本时,RoBERTa-CRF 模型会丢失事件角色“交易物”“红帽公司”;在处理类似例3 的样本时,RoBERTa-CRF 模型会丢失关系类型“歌手”及其相应的论元。本文所提的模型在处理类似样本时具有较优的抽取效果。

表5 不同模型的抽取结果对比Table 5 Extraction results comparison among different models
4 结束语
针对实体关系抽取任务和事件抽取任务的共有特性,本文设计一个实体关系抽取与事件抽取两阶段的通用模型。以预训练模型RoBERTa 作为文本的编码器,将多标签分类任务用于抽取实体关系或事件类型,以解决汉语中角色重叠和数据标签不平衡,以及词触发不匹配和词边界的问题。在千言数据集上的实验结果验证本文模型的有效性,实验结果表明,本文模型的F1 值分别为83.1%和75.3%。后续将利用多种特征融合的方法从文本中抽取结构化信息,以提高事件抽取和关系抽取任务的抽取效率。
猜你喜欢
导航定位学报(2022年4期)2022-08-15
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
数学物理学报(2020年2期)2020-06-02
中国外汇(2019年18期)2019-11-25
渭南师范学院学报(2017年22期)2017-11-22
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
海外华文教育(2016年3期)2017-01-20
光学精密工程(2016年6期)2016-11-07
