
检测脑电癫痫的多头自注意力机制神经网络
2023-02-18 07:16:54江永全
计算机与生活 2023年2期
仝 航,杨 燕,江永全
西南交通大学 计算机与人工智能学院,成都611756
癫痫是第四大最常见的神经疾病,具有慢性、复发性、非感染性等特点,全世界有超过5 000 万的癫痫患者,其中25%的患者没有得到有效的手术或药物控制。由于癫痫发作的时间不可预测,癫痫对患者的生活质量造成了很大的影响。大脑活动异常即大脑神经细胞突然过度放电导致癫痫发作,致使患者出现不正常的行为或感觉,有时甚至失去意识,进而导致其他健康问题,甚至死亡。
脑电图(electroencephalogram,EEG)是一种记录大脑活动的有效工具,已被广泛用于分析和诊断癫痫、阿尔茨海默症、注意力缺陷多动障碍等疾病。作为监测、检测和诊断癫痫发作的常用方法之一,脑电图通过放置在大脑不同位置的多个电极来测量脑电活动,记录的信号通常包含多个通道。根据以往的工作,脑电图信号的采集通常是将电极置于头皮表面或短期植入颅内,分别称为头皮脑电图和颅内脑电图。虽然颅内脑电图记录提供了更好的信噪比,更好地定位于致痫区域,但是,颅内电极的覆盖范围有限,可能会漏过覆盖范围以外的痫样放电,对手术者要求较高。头皮脑电图是一个非侵入性的无创技术,对于每天的患者监测和发作警报生成,头皮脑电图记录具有更高的适用性和易用性,因此,目前对癫痫发作检测的研究大多倾向于利用头皮脑电图。
在癫痫发作检测任务中,需要对脑电图信号进行彻底的分析,以判断癫痫是否发作,这是一项依赖大量临床经验且耗时的工作。由于癫痫发作的频率相对较低,面对长期的脑电图记录,人类专家或专业医生通过视觉阅读多通道脑电图信号识别癫痫发作的特征模式耗时严重且效率低下。脑电图癫痫发作的自动检测深受神经信息学研究者和医学界的关注,因此,迫切需要基于计算机的癫痫自动检测技术,这也是节省时间和精力的关键方法。
近年来,癫痫发作自动检测方面存在着大量的研究。一般来说,癫痫检测过程分为特征提取和分类两个阶段。特征提取至关重要,因为提取的脑电特征模式将影响着分类器的性能。基于人工特征和机器学习分类器的技术研究很多。常见的人工特征提取方法有时频分析[1]、非线性动力学[2]、累积能量增量[3]、统计特征[4]等。这些人工特征提取的设计方法虽然各不相同,但通常涉及大量的专家知识,以便从数据中获得可解释的表示。常见的机器学习分类器有决策树、贝叶斯网络、高斯混合模型、传统神经网络和支持向量机等。然而,特征提取依赖于有限的和预先细化的手工工程操作集。此外,不同患者的癫痫发作特征不同且可能随着时间的推移而有所改变,提取这些特征所需的计算时间取决于过程的复杂性,因此,自动从脑电数据中提取和学习特征信息是非常有必要的。
随着深度学习在图像分类、自然语言处理、时间序列预测等领域的广泛应用和深入推广,越来越多的深度学习模型被提出。尤其是深度学习算法拥有可以从自然信号中学习高级表示的能力[5],因此,它在医学领域和信号处理领域取得了较为突出的结果。在脑电图癫痫检测中,像卷积神经网络(convolutional neural network,CNN)和堆叠自编码器(stacked autoencoder,SAE)等深度学习模型可以直接从脑电数据中学习特征表示,进而代替手工设计的特征提取方法,已被证明提取的特征更健壮,可以实现更好的性能检测[6-7]。因此,本文将基于深度学习的癫痫发作检测作为研究的主要任务。
EEG 信号本质上是多维度、高度动态、非线性的时间序列数据,BiLSTM(bi-directional long short-term memory)网络在提取不同状态下大脑活动的时间特征方面比CNN 有设计上的优势,如在情绪识别[8]、运动想象分类[9]和睡眠分期[10]等方面。但由于信息在深层神经网络结构中经过许多层后会衰减,当长短时记忆网络(long short-term memory,LSTM)面对超长序列时,反向传播也会导致梯度消失问题,会削弱模型的可靠性。而CNN 可以从输入序列中提取位移不变的局部模式作为分类模型的特征,尤其是学习多元时间序列数据的特征,例如,用于动作或活动识别[11],可捕获医疗保健数据的多元时间序列的隐藏模式[12],提取周期信息进行多元时间序列预测[13]。
由于深度学习算法需要大量的脑电图记录数据,缺乏开放的含标记的脑电图数据是一个限制因素。公开的波士顿儿童医院收集的头皮脑电图数据库CHB-MIT 是一个包含连续长期头皮脑电图记录的开放数据库,且由专家对癫痫发作期做了标记,可用于癫痫检测。在实践中,不平衡的数据问题可能会破坏深度学习方法的有效性,因为癫痫发作事件的数量是有限的。另外,因为癫痫发作的脑电图特征在不同患者之间可能存在显著差异,虽然大部分针对特定患者的分类器可以具有良好的性能,却不能对其他新患者起作用。由于癫痫发作和癫痫不发作活动因患者不同而具有特异性,跨多患者非特异性分类器的研究更有实际意义。文献[14]提出了一种基于堆叠稀疏去噪自编码器(stacked sparse denoising autoencoder,SSDA)的脑电通道选择方法,考虑了多种信息共同确定关键信道特征。由于不相关的通道被过滤掉,这些方法显著地减轻了噪声影响。虽然他们的选择策略取得了很好的效果,但实际上,不相关的通道会因设备不同、患者不同而有所改变。大多研究是利用领域知识从多通道脑电信号中选择特定的通道进行分析,而对多通道癫痫脑电信号的数据驱动分析还没有深入研究。此外,由于癫痫发作与一系列的脑电图信号有关,而不是与某一时刻的值有关,大多数方法将每个时间戳随机反馈给分类器,忽略了脑电数据之间的动态相关性,这导致无法更好地识别时间信号模式,因此时间分析对于癫痫发作的检测是关键且有必要的。
为了解决上述挑战,本文提出了一种广义的癫痫预测方法,此方法将特征提取和分类阶段结合到一个单独的自动化框架中,能够直接处理原始脑电图数据。本文的主要贡献包括三方面:
(1)利用滑动窗口将CHB-MIT 多通道脑电信号分割成固定时间长度的片段,确保癫痫发作和非发作数据的平衡,以便进一步研究和分析。
(2)提出了CABLNet(convolutional attention bidirectional long short-term memory network)深度学习网络模型,使用CNN 提取脑电时间序列数据的时间短期模式和多通道之间的局部依赖关系,利用多头自注意力机制捕获特征表示的时间动态相关性,使用双向LSTM 充分利用上下文向量前后时刻信息,可在不依赖任何医学专家知识的情况下,从多通道脑电信号中准确检测癫痫发作。
(3)在CHB-MIT 有噪声脑电数据上的实验结果表明,本文提出的模型在捕获癫痫发作模式上具有很好的鲁棒性和稳定性,能较好地克服不同患者癫痫发作的变化,用于跨多患者癫痫检测。
1 相关工作
癫痫自动检获的研究已经进行了几十年,提出的许多方法都取得了良好的性能。这些方法可以分为两类:基于特征的方法和深度学习方法。
大多数基于特征的方法将专家手工制作的特征与分类器相结合,比较注重从背景模式中提取手工制作的特征,常见的特征包括时域方法[15]、频域方法[16]、时频域方法[17]和非线性方法[18]。分类器常使用传统的机器学习方法,更注重研究开发患者特异性癫痫检测方法。例如,文献[19]提取了频谱、空间、时间三类特征,提出了一种混合数据采样和增强技术的算法,这种学习框架可以缓解类别不平衡问题,在鲁棒性和泛化方面具有强大能力,对CHB-MIT 数据集进行患者特异性实验,检出准确率达97%,每小时误检率为0.08,可以有效地用于自动癫痫发作检测问题。文献[17]提出了一种基于离散小波变换(discrete wavelet transform,DWT)的新型计算效率特征Sigmoid熵的癫痫自动检测模型。根据每个子带的小波系数估计出Sigmoid 熵,并使用非线性支持向量机分类器进行交叉验证,在UBonn 和CHB-MIT 两个数据集的灵敏度分别达到100.00%和94.21%。文献[20]认为将部分定向相干性(partial directed coherence,PDC)分析作为特征提取机制应用于癫痫发作检测的头皮脑电图记录,可以反映癫痫发作前后大脑活动的生理变化。于是,利用PDC 分析方法提取脑电通道相关信息流的方向和强度等特征,将特征输入到支持向量机分类器,用于区分癫痫间期和发作期。这些方法试图通过整合图像特征和信号相关特征来捕捉脑电信号的非平稳行为,虽然在特征提取方面有所不同,但通常需要大量的领域知识。
然而,在许多领域,通过深度学习方法提取的特征比手工制作的特征更健壮。随着深度学习技术的兴起,许多深度学习方法被开发出来用于癫痫检测。卷积神经网络引起了人们对癫痫发作检测的极大兴趣,文献[21]利用短时傅里叶变换(short time Fourier transform,STFT)提取脑电信号的时域和频域信息,使用由3 个block 组成的CNN 架构(每个block包括一个归一化层、一个卷积层和一个最大池化层)进行特征提取和分类。在CHB-MIT 数据集上,平均癫痫检测灵敏度达81.2%,误检率为每小时0.16。文献[22]并不对脑电信号进行特征提取,而是直接使用金字塔型一维深度卷积神经网络对单通道脑电信号进行癫痫检测,实验结果表明,CNN 比人工工程技术的学习效果好。
另外,循环神经网络也被用于从头皮脑电图记录中自动检测癫痫发作。文献[23]提出了一种基于头皮脑电图的特殊癫痫发作检测的深度循环结构(deep recurrent neural network,DRNN)和一种癫痫脑电信号映射方法,使所提出的深度结构能够同时分别学习原始脑电信号的时间特征和空间特征。文献[24]提取Hurst 和自回归滑动平均(auto-regressive moving average,ARMA)特征,为脑电信号建立一个20 维的通道特征,标准化处理之后送入LSTM,实验结果表明,双层LSTM 方法比之前使用的支持向量机分类器获得了更高的精度。文献[25]对原始脑电信号进行局部均值分解,使用最大值、最小值、中位数、均值、标准差、方差、均值绝对偏差、均方根、偏度、峰度10 个统计参数作为特征,将这些特征送入到双向LSTM。在CHB-MIT 头皮脑电图数据库中,平均灵敏度为93.61%,平均特异度为91.85%,该模型考虑了当前分析时刻前后的信息,并共同确定了决策结果。文献[26]首先在脑电通道中引入注意机制,不同的权重会自动分配给大脑不同区域的信号通道,之后采用BiLSTM 提取脑电图信号的前向和后向的时间特征,使用时间分布全连接层是在每个时间步上进一步提取特征,平均池化操作后提取每个样本的全局特征,大量的实验结果表明,提出的新方法的性能更加稳定。这些研究都取得了良好的成果,深度学习技术在脑电分析中仍有很大的潜力。
手工提取特征需要大量的领域知识,只选择部分脑电通道会丢失部分有用信息。虽然脑电图信号通常是动态的和非线性的,但在足够小的时间段内,信号可以被认为是平稳的。不同的大脑区域可能对癫痫有不同的影响,不同脑区癫痫的脑电图数据特征不同,不同的通道之间可能存在着局部依赖性。脑电图信号在一个时间点的特征与过去时间点的数据和未来时间点的数据有着不同程度的关联。而在自然语言处理领域,自注意力机制往往用于捕获上下文关系。例如,文献[27]提出了一种具有自注意力机制和多通道特性的BiLSTM 模型,结合多种特征向量和BiLSTM 模型的隐式输出,利用自注意力机制对不同的词给出不同的情感权重,能有效提高情感极性词的重要性,充分挖掘文本中的情感信息。文献[28]提出了一种基于多尺度局部上下文特征和自注意力机制的中文命名实体识别模型。通过融合不同核大小的卷积神经网络(CNN)提取多尺度局部上下文特征,改进了原有的双向长短期记忆和条件随机场模型(bidirectional long short-term memory and conditional random field,BiLSTM-CRF),利用多头自注意机制打破了BiLSTM-CRF 在捕获远程依赖关系方面的局限性,进一步提高了模型的性能。
基于上述观点,本文提出了基于多头自注意力机制神经网络的癫痫脑电检测方法。该方法不提取手工特征,直接处理原始脑电信号,提取信号的时间短期模式和多通道之间的局部依赖关系,引入多头自注意力机制进一步捕获短期时间模式之间的上下文联系。在本文构造的数据集上进行跨多患者实验,与其他方法进行对比,结果表明,提出的新方法的性能有了很大提升,具有高稳定性。
2 CABLNet模型
本章主要介绍所提出的CABLNet(即卷积-多头自注意力机制-双向长短时记忆网络)模型,模型结构如图1 所示。该模型包括卷积层、多头自注意力层、双向长短时记忆层和融合输出层。本文将脑电信号切割为长为4 s 的样本(详见3.2 节),对切割得到的全部数据进行标准化,每个样本可以表示为一组时间序列信号X={x1,x2,…,xn}∈RT×n,其中,xi∈RT,n表示脑电信号通道数,T表示每个样本记录的时间数。
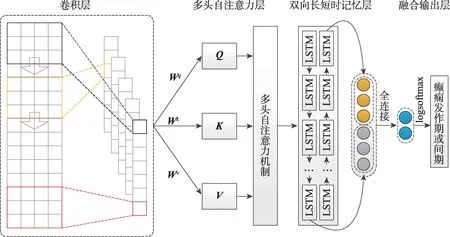
图1 模型架构图Fig.1 Model architecture diagram
2.1 卷积层
CABLNet 网络模型的第一层是一个没有池化层的卷积层,其目的是为了提取脑电信号的短期时间模式和各个脑电通道间的局部依赖关系。同时,对时间步进行位移不变的压缩,防止超长时间序列导致的梯度消失问题,方便后续双向长短时记忆层捕获信息。卷积层由多个滤波器组成,滤波器高度为h,滤波器宽度为n(宽度设置与脑电信号通道数相同),步长为s。第k个滤波器扫过脑电时间序列信号X得到输出,计算过程如式(1)所示。

其中,*表示卷积操作,hk表示此滤波器对应的输出向量,bk表示偏置项,函数f是非线性激活函数,这里使用ReLU,如式(2)所示。

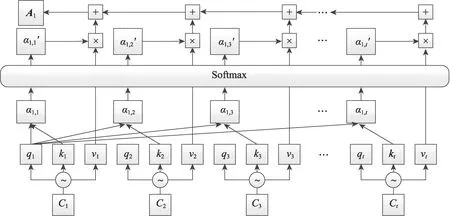
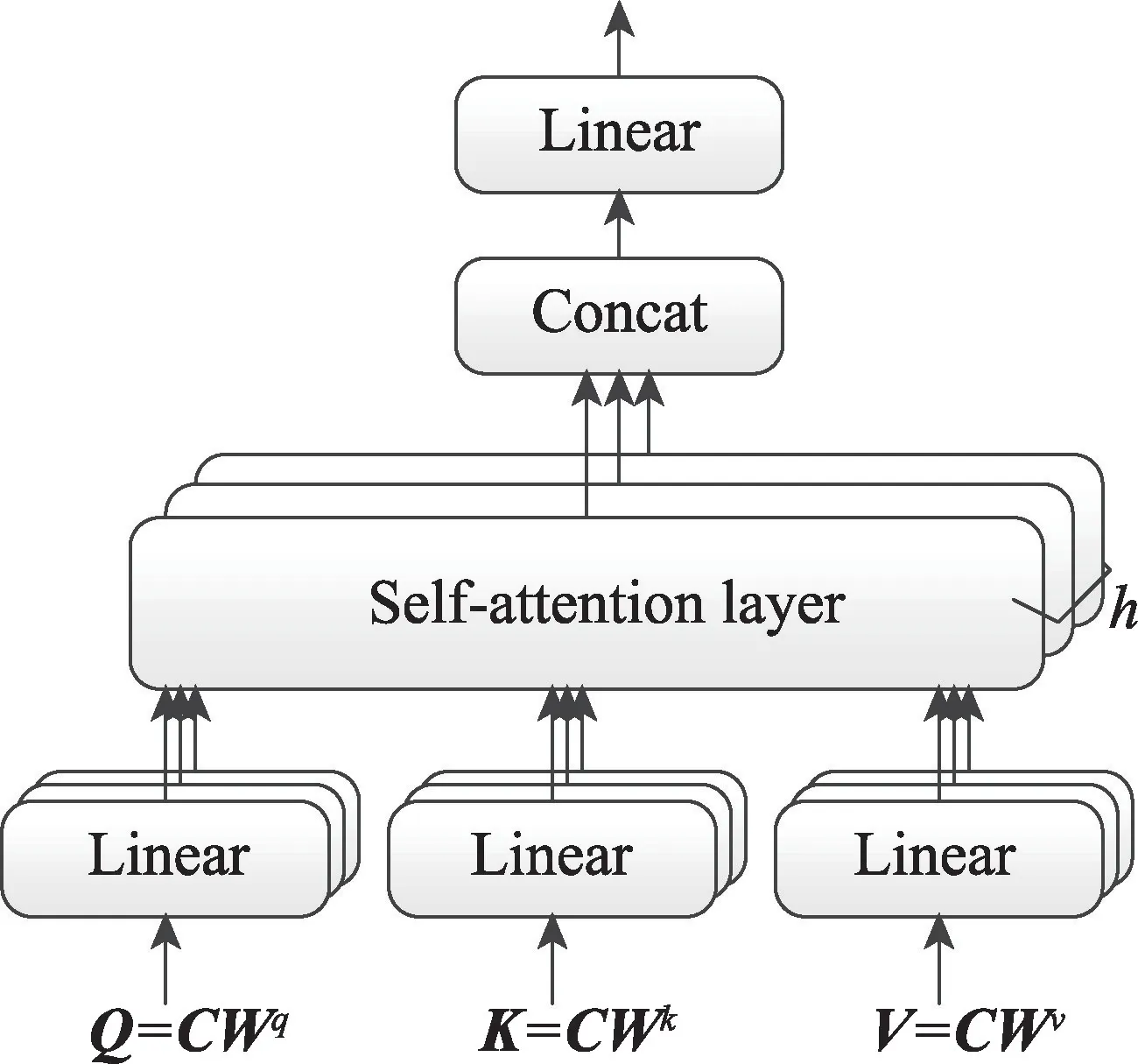
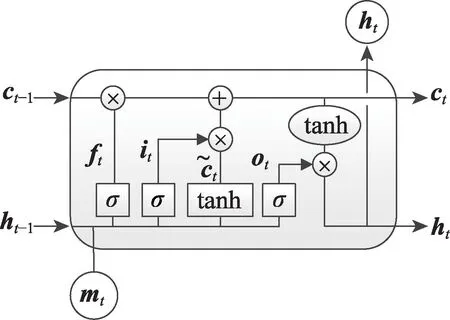
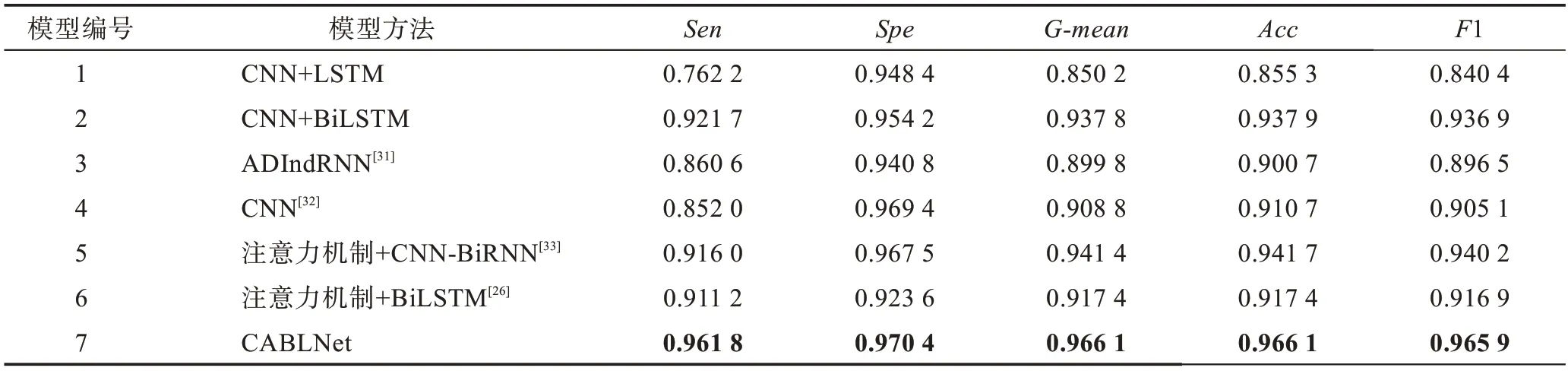
另外,为了减少神经网络训练中的内部协变量偏移,降低过拟合的风险,同时增加收敛速度,本文在卷积之后以及使用非线性激活函数之前加入批处理归一化(batch normalization,BN)操作。在非线性激活函数之后,增加dropout操作,用于减少神经元之间复杂的协同适应,迫使每个神经元学习更加鲁棒的特征,避免过拟合。最终得到特征表示C∈Rt×m,其中m是滤波器的个数,t(t 自注意力机制是注意力机制的一个特例,已经成功应用于自然语言处理(natural language processing,NLP)和问答系统(question answering system,QA)等多个领域。自注意力机制可以用于捕获输入输出之间的全局依赖关系和序列本身的长距离依赖。针对本文,卷积得到的特征表示在时间维度上具有位移不变性,不同时间步的特征向量之间依然存在着长距离依赖关系和时间动态相关性。采用多头自注意力机制[29]可以在不同表示子空间学习到相关的信息,进一步提高全局上下文特征的提取能力。 自注意力机制主要采用缩放点积注意力,注意力模块的输入由查询(queries)、键(keys)、值(values)矩阵三部分组成,输出是基于查询和键的相似度与值的加权和。缩放点积注意力计算公式如下: 其中,Q、K、V分别表示查询、键、值矩阵,dk表示键的维数。自注意力机制是一种与单个序列的不同位置相关的注意力机制,用于计算序列的表示。本文使用d表示自注意力机制的输出维度,用Wq,Wk,Wv∈Rm×d表示可训练的参数矩阵,则根据如下计算过程可得到上下文表示: 图2 自注意力机制的计算过程Fig.2 Computational process of self-attention mechanism 与CNN 中的过滤器类似,一次自注意力关注不足以学习多个特征的权值。为了让模型从不同的表示子空间学习信息,通过多个平行头重复多次Attention运算,每个头处理不同的信息,这样可以处理特征表示的不同部分,提取出更丰富的时间序列长距离依赖关系。多头自注意力机制的模型图如图3 所示,其中,h表示头数。用Qi、Ki、Vi表示第i个子空间的查询、键、值矩阵,则第i头的自注意力结果表示如式(5)所示,将各个头的自注意力结果拼接,使用矩阵Wdr进行多空间融合,最终得到多头自注意力的最终结果,具体如式(6)所示。 图3 多头自注意力机制模型图Fig.3 Model of multi-head self-attention mechanism 最后,使用层规范化(layer normalization)得到最终的上下文表示矩阵M∈Rt×d。多头自注意力机制为不同时间步的特征向量分配不同的权重,即大的权重分配给少数关键特征向量,小的权重分配给大多数不相关的特征向量,从而有效地解决了各时间步特征向量的平等贡献问题,捕获了各时间步特征向量的长距离依赖关系和时间动态相关性。 循环神经网络(recurrent neural network,RNN)比人工神经网络(artificial neural network,ANN)更适合于具有短期依赖性的序列学习问题。然而,RNN并不能有效地处理长期依赖的问题,因为长期的训练过程可能因训练权重突然变化导致网络不稳定(即梯度爆炸)。 长短时记忆网络[30]是一种特殊的递归神经网络,它使用记忆单元(memory cell)的概念来处理长期依赖关系,克服了传统RNN 模型的梯度消失和爆炸问题,可以有选择地保存上下文信息。如图4 所示,用mt表示第t时间步的输入向量,用b表示偏置项,用ft、it、ot分别表示遗忘门、输入门、输出门的激活值向量,用ct、表示细胞状态和候选值向量,用ht表示输出向量,用W表示权重矩阵。在时间步t更新LSTM 记忆单元的计算操作如下: 图4 LSTM 网络结构图Fig.4 LSTM network structure diagram 其中,函数σ表示Sigmoid 非线性激活函数,⊙表示元素的乘积。 然而,LSTM 只考虑过去的信息,只能按顺序处理来自过去的信息,忽略了未来的信息。针对脑电癫痫检测问题,需要有效地使用上下文信息,因此,采用双向长短时记忆网络(Bi-LSTM)。将上下文表示矩阵送入Bi-LSTM,分别由前向LSTM 和后向LSTM 通过计算前向隐藏序列和后向隐藏序列得到两个单独的隐藏状态,然后将这两个隐藏状态拼接起来形成最终提取到的上下文特征: ht+1∈R2h_d,h_d表示隐状态的特征维度。 含有长距离依赖关系的上下文表示,经过双向长短时记忆网络的信息提取,得到最终的上下文特征表示,将其输入到全连接层进行融合,经logsoftmax函数计算得到最后的分类结果,如式(13)所示。其中,Wp、bp分别表示权重矩阵和偏置项。 本文使用灵敏度(Sen)、特异性(Spe)、G-均值(G-mean)、准确率(Acc)、F1-score(F1)作为模型分类的评价指标[25-26]。如果用TP 表示预测类别和真实类别都为癫痫发作期的样本数,FN 表示预测类别为癫痫间期而真实类别为癫痫发作期的样本数,FP表示预测类别为癫痫发作期而真实类别为癫痫间期的样本数,TN 表示预测类别和真实类别都为癫痫间期的样本数,那么所用评价指标公式表示如下: 用Pre表示精确率,其公式如式(18)所示,则可根据Pre和Sen得到F1,如式(19)所示。 本文使用波士顿儿童医院收集的头皮脑电图数据库(CHB-MIT),此数据库包含连续长期头皮脑电图记录。该数据库共包含23 名患者24 个病例记录(每个文件包含9 至42 个连续的.edf 格式的脑电数据文件),其中第1 个和第21 个病例记录来自同一名患者。这些记录采用国际10-20 EEG 电极位置和命名系统,所有信号采样频率为256 Hz,16 位分辨率。大多数病例记录的脑电图信号是23 通道的,为便于统一研究,本文只保留这23 个通道:FP1-F7、F7-T7、T7-P7、P7-O1、FP1-F3、F3-C3、C3-P3、P3-O1、FP2-F4、F4-C4、C4-P4、P4-O2、FP2-F8、F8-T8、T8-P8、P8-O2、FZCZ、CZ-PZ、P7-T7、T7-FT9、FT9-FT10、FT10-T8、T8-P8。通道数小于23 的记录将被舍弃。 因为每个病例记录文件所包含的每条记录长度都不同,大部分记录没有发作,而发作的记录也可能是多次发作,为保证样本数据维度统一,需对数据做预处理工作。为便于理解数据预处理过程,图5 展示了对只含有癫痫间期的记录和同时含癫痫发作期的记录的处理过程,上方的记录只含有癫痫间期的记录,下方的记录表示含癫痫发作期的记录,灰色部分表示癫痫发作期,阴影部分表示癫痫发作间期,小矩形表示4 s 的无重叠滑动窗口,将截取的长为4 s 的癫痫发作期数据、癫痫发作间期数据分别看作正、负样本,对包含发作期的记录进行两次发作期采样(第一次从发作开始,第二次从发作后3 s 开始),每段发作最后不足4 s 的部分将被舍弃,可得到5 236 条正样本。每个不含发作期的记录从第10 min 开始采样12个无重叠的负样本,为保证样本数据的平衡性,从采样得到的负样本中随机选择5 236 条。按照60%∶20%∶20%的比例分别将正负样本数据集划分,最终得到训练集数据6 284 条、验证集数据2 094 条、测试集数据2 094 条。 图5 脑电数据预处理过程图Fig.5 Preprocessing process chart of EEG data 本文的实验环境为:Ubuntu 16.04 操作系统,cudnn7,编程语言采用的是Python 3.6.8,深度学习框架为Pytorch(其版本为1.1)。另外使用了CUDA 9 用于GPU 加 速,GPU 为TIAN X,内 存16 GB,显 存12 GB。 本实验在模型训练过程中训练200 个轮次(Epoch),数据批处理大小设置为20。使用负对数似然损失函数NLLLoss 作为损失函数,使用Adam 优化器进行优化,学习率为0.000 1。根据以上参数设置,按照3.2 节的预处理方法,对数据进行分割,每个EEG 片段的大小为(1 024,23),可表示成通道数为1的张量(1,1 024,23),则卷积层输入一个批次的张量大小为(20,1,1 024,23),卷积核尺寸设置为(26,23),卷积产生的通道数为26,步长设置为4,dropout为0.5,最终卷积层输出张量大小为(20,26,250,1)。可训练矩阵Wq、Wk、Wv的大小都为(26,64),多头自注意力层的输入Q、K、V的张量大小都为(250,20,64)。双向长短时记忆层的隐藏状态数为12,前后两个方向最后时间步的隐藏状态拼接后的上下文特征矩阵大小为(20,24)。最终经过融合输出层得到输出矩阵大小(20,2)。 在本节中,通过在CHB-MIT 有噪声的头皮脑电图数据集上进行跨多患者实验来评估CABLNet模型的性能,并针对不同病例的测试集进行分析,对比几种不同方法的敏感性、特异性、G-均值、准确率、F1-score。 子空间数量(即头数)意味着多头自注意力层的多个子表示层的学习能力,头数过少会导致提取的特征数量不足,头数过多会导致过度表示,并不能从中提取更多有用的信息,反而增加了模型的复杂度。因此,就多头注意力机制的头数对实现性能的影响进行对比实验。实验结果如图6 所示,分析可得,8 头对应的G-均值、准确率、F1-score 均取得较高值,因此,本文将注意力子空间数量的最优值设置为8。 图6 不同头数的实验结果对比Fig.6 Comparison of experimental results with different number of heads 使用8 头注意力机制,模型在大约175 个轮次之后趋于收敛。如图7 所示,(a)图展示了在训练集和验证集上准确率随轮次的变化情况,(b)图展示了训练损失和验证损失随轮次的变化情况。 图7 准确率和损失值随轮次的变化情况Fig.7 Variation of accuracy and loss with epoch 虽然是针对同一脑电数据集CHB-MIT,但不同的文献对数据切割所得到的样本时长(1~30 s)不尽相同。为了使实验结果具有可对比性,本文对比了两个基线实验CNN+LSTM 和CNN+BiLSTM,同时复现了文献[26]、文献[31]、文献[32]、文献[33]所提出的方法,在本文预处理得到的数据集上进行了对比实验,实验结果如表1 所示。 表1 中,模型7 是本文提出的模型,模型1、模型2是两个基线模型,隐藏状态数为12,卷积层的相关设置以及其他实验参数和本文模型相同。模型3、模型4、模型5 和模型6 是对比实验模型,它们的相关参数设置与对应原文献一致。 表1 不同模型在CHB-MIT 数据集上的实验结果对比Table 1 Comparison of experimental results of different models on CHB-MIT dataset 与模型1 相比,除特异性外,模型2 在灵敏度、G-均值、准确率、F1-score 上有了大幅度提升,由此可见,双向LSTM 比单方向的LSTM 具有更好的性能,对癫痫检测问题融合前后信息至关重要。与模型2相比,本文提出的模型在各个评价指标上均有所提高,捕获短期时间模式特征间的相关性有利于更好地进行特征提取。对比模型3、模型4、模型5 和模型6,灵敏度方面,模型5 最高,可达到91.60%,而本文提出的模型为96.18%,高出其4.58 个百分点;特异性方面,模型4 和模型5 比较高,分别为96.94%和96.75%,而本文模型为97.04%,与这些模型不相上下;G-均值方面,模型3、模型4 和模型6 较低,模型5 较高,为94.14%,本文模型为96.61%,高出其2.47 个百分点;准确率和F1-score 方面,模型3、模型4 和模型6 较低,模型5 最高,分别为94.17%和94.02%,本文模型为96.61%和96.59%,均高出其2 个百分点。整体看来,本文提出的模型在各项指标上均比对比的算法高,具有良好的性能。 癫痫发作和癫痫不发作活动因患者不同而具有特异性,为了比较训练的模型在不同的病例上的表现能力,将原来的测试集数据按病例划分为24 个测试集,实验结果如表2 所示。本文提出的CABLNet模型,病例chb07、chb11、chb21 的准确率最高,为100.00%,病例chb14、chb24 的准确率较低,分别为84.78%、86.44%,灵敏度分别为73.68%、82.93%。病例ch13的特异性最差,为75.00%,敏感性为100.00%。经过对比,模型4 在病例chb01、chb10、chb22、chb23上准确率最高,模型5 在病例chb3、chb18、chb20 上准确率最高,而在其他病例上,本文提出的模型准确率均最高。模型3 准确率低于85.00%的病例分别为chb08、chb13、chb14、chb16 和chb24,模型4 准确率低于85.00%的病例分别为chb12、chb14、chb20、chb21和chb24,模型5 准确率低于85.00%的病例分别为chb12、chb14 和chb24,模型6 准确率低于85.00%的病例分别为chb5、chb14 和chb24,而本文提出的模型仅在病例chb14 上低于85.00%。更进一步,模型3 在13 个病例上准确率低于90.00%,模型4 在9 个病例上准确率低于90.00%,模型5 在4 个病例上准确率低于90.00%,模型6 在7 个病例上准确率低于90.00%,而本文提出的模型准确率低于90.00%的病例仅有2个。实验结果表明,CABLNet 模型具有较好的鲁棒性,能有效检测不同患者的癫痫发作情况。 表2 不同模型在不同病例数据上的表现Table 2 Performance of different models on different case data 本文提出了一种基于多头自注意力机制神经网络的癫痫脑电检测方法,该模型主要由卷积层、多头自注意力层、双向长短时记忆层构成,因此,命名为CABLNet(C 代表卷积,A 代表注意力机制,BL 代表双向LSTM)模型。首先,对多位患者的数据进行采样,确保得到不同类别均衡的样本数据。其次,将原始脑电时序数据送入到卷积层,提取短期时间模式和通道之间的关系,将特征表示送入多头自注意力机制捕获短期时间模式的时间动态相关性,进而得到上下文表示,利用双向LSTM 充分提取前后两个方向的信息。最后,进行融合分类。实验结果表明,该方法在捕获癫痫发作模式上具有鲁棒性和稳定性,提高了泛化性能,能够有效地实现对多通道脑电信号的跨多患者癫痫检测。该工作可以减轻临床医生的工作量,对辅助诊断有重要意义。 在未来的研究工作中,一方面,扩大癫痫数据的规模,使用更多患者的EEG 数据,继续优化模型,提升算法性能;另一方面,结合实际情况,考虑EEG 记录过程中部分电极脱落的情况,针对通道缺失问题做进一步研究。2.2 多头自注意力层
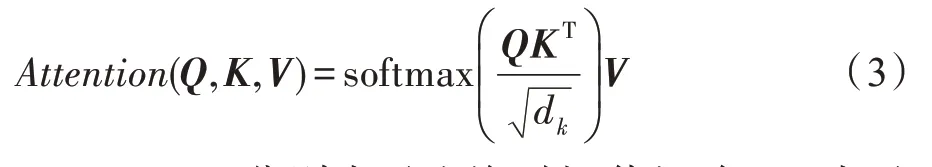


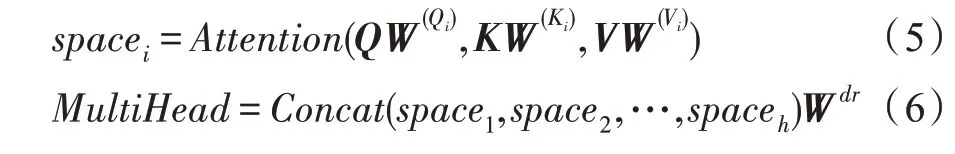
2.3 双向长短时记忆层
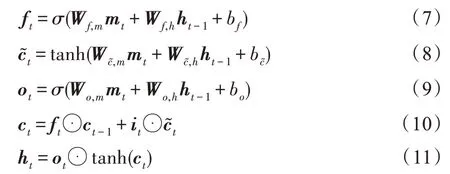

2.4 融合输出层
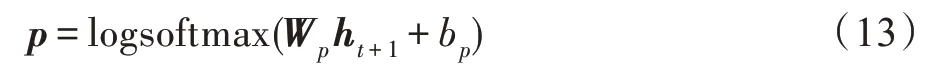
3 实验与结果
3.1 评价指标
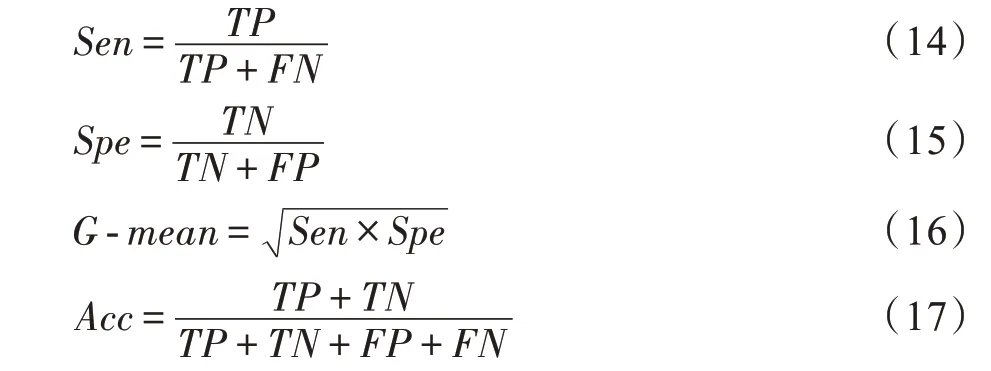

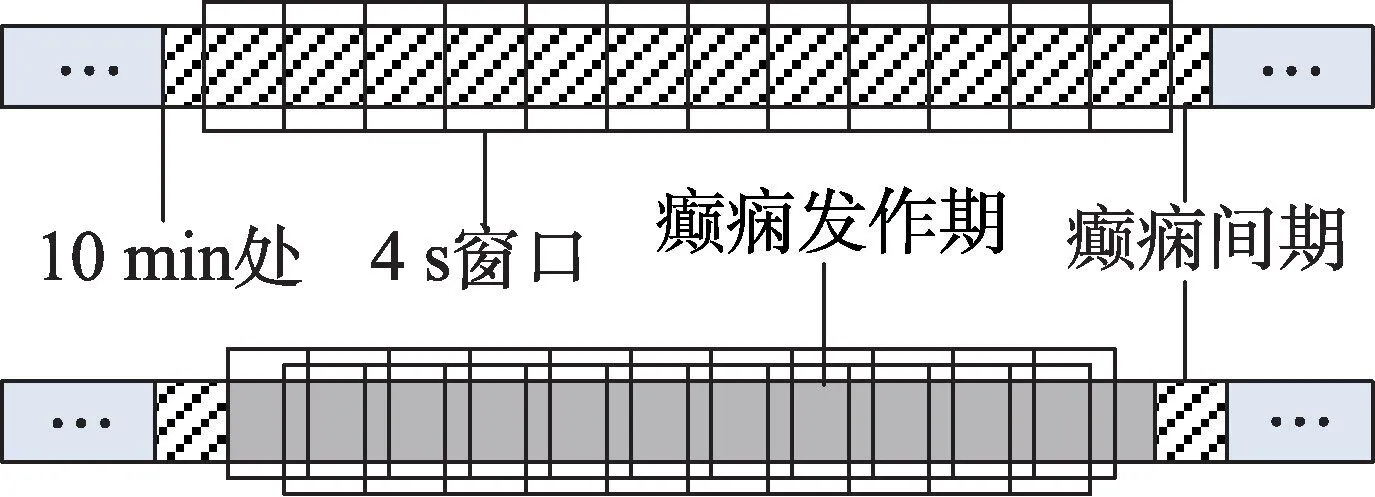
3.2 实验数据及预处理
3.3 实验环境
3.4 实验参数
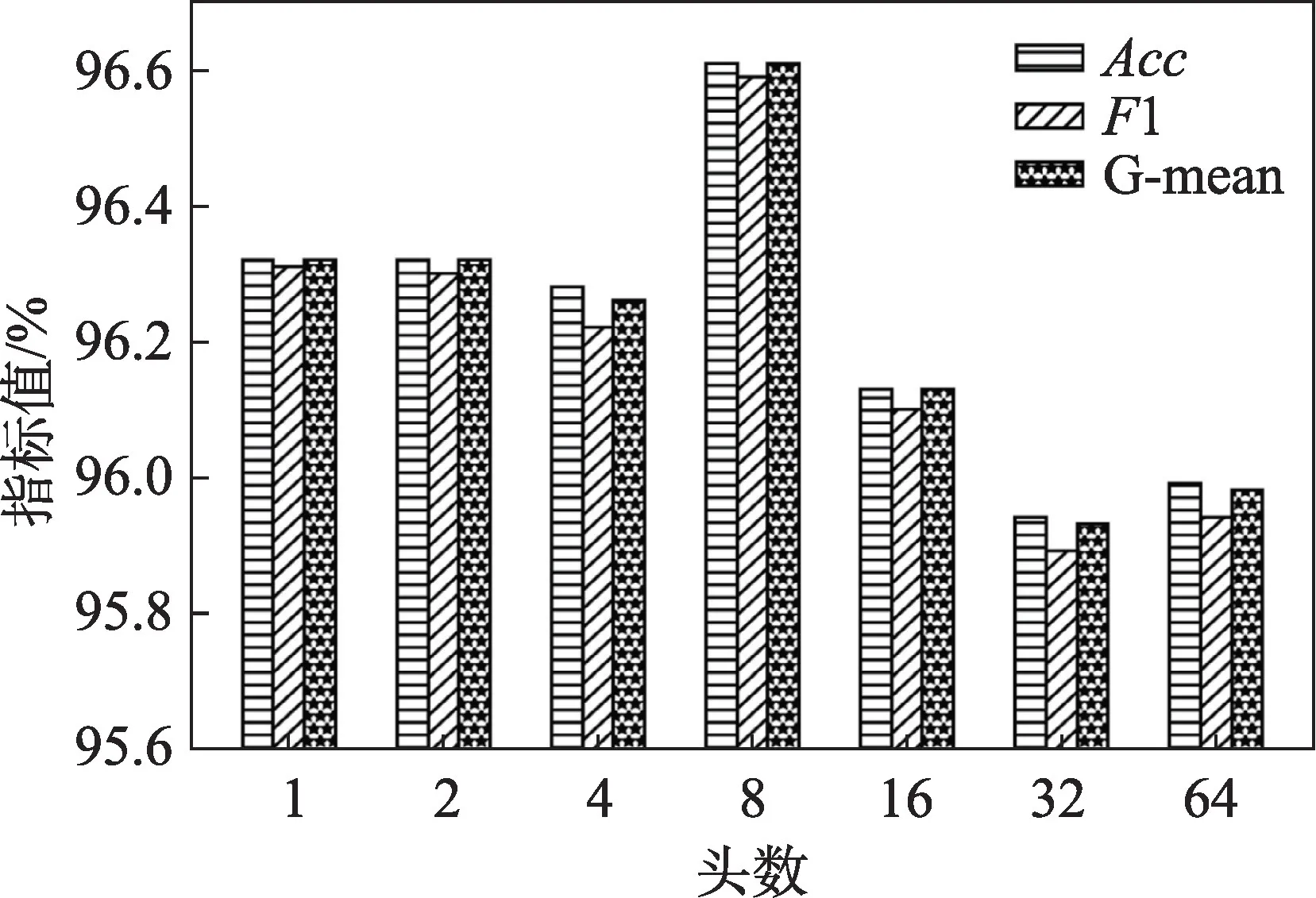
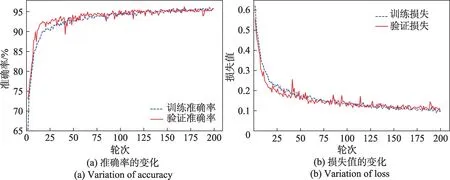
3.5 实验结果分析

4 结束语
猜你喜欢
中国民间疗法(2021年5期)2021-06-09 09:21:04
饮食科学(2017年5期)2017-05-20 17:11:53
现代电生理学杂志(2016年3期)2016-07-10 12:10:32
现代电生理学杂志(2016年4期)2016-07-10 12:02:17
现代电生理学杂志(2016年1期)2016-07-10 10:20:58
现代电生理学杂志(2016年1期)2016-07-10 10:20:58
川北医学院学报(2015年5期)2015-12-05 08:22:33
现代电生理学杂志(2015年1期)2015-07-18 11:02:17
现代电生理学杂志(2015年1期)2015-07-18 11:02:16
中国当代医药(2015年7期)2015-03-01 02:01:13
