
注意力感知的群组Next事件推荐策略
2023-02-18 07:17:10廖国琼杨乐川万常选刘德喜刘喜平
计算机与生活 2023年2期
廖国琼,杨乐川,万常选,刘德喜,刘喜平
江西财经大学 信息管理学院,南昌330013
近年来,越来越多的人倾向于在网络上发布或报名事件,再到现实中真实参与。受此影响,如图1所示,豆瓣同城[1]、Meetup[2]等基于事件的社会网络(event-based social networks,EBSN)[3],作为群组线上线下社交的载体,越发受到关注。在这些平台上,人们试图寻找喜欢的事件进行报名。然而每天都有新的事件在发布,且事件从线上发布到截止报名往往不超过一周,而从线下真正举办到结束更是通常在几小时以内。因此,如果用户仅依靠自己搜索,效率是极低的。幸运的是,越来越多的研究表明推荐系统能够明显改善这一问题。

图1 EBSN 结构Fig.1 Structure of EBSN
在早期的研究中,推荐系统面向的对象是EBSN中的单个用户,但不久之后,研究的热点逐渐转向了面向群组的推荐策略。一方面,这是因为EBSN 中本身就有兴趣组(用户依赖兴趣自发组建的线上群组)的存在;另一方面,线下参与事件的主体往往也带有现实的社交关系(如家人、同事、同学等)。正是因为EBSN 中错综复杂的线上线下社交关系,在EBSN 中研究面向群组的推荐方法更有意义。
以往的EBSN 群组推荐策略将问题聚焦在群组偏好的建模上,建模得到的偏好是静态的。而实际上,群组偏好也会随时间的推移而发生改变,真实的群组偏好是动态变化的,这常常受到忽视。随着推荐系统在电子商务、音乐等领域被广泛应用,发展出了基于会话的推荐(session-based recommendation)、顺序推荐(sequential recommendation)等专门针对用户偏好的动态性进行建模,推荐用户下一个可能访问的项目的算法。然而,考虑群组偏好动态的研究尚不多[4-5]。
图2 介绍了EBSN 中的面向群组的下一个事件推荐问题(next event recommendation for group,NER4G),群组的偏好被认为是随着时间而动态变化的。在宏观上,群组访问记录被划分为多个时段,将每个时段记为T,群组的偏好在每个时段会有不同的体现。比如,在3 月份可能更偏向于爬山,到6 月份就更喜欢冲浪。在微观上,每个时段的偏好由当前时段各个群组成员偏好构成,而在每个时段内,不同用户的参与程度很可能是不一致的,从而群组偏好也会跟着动态变化。
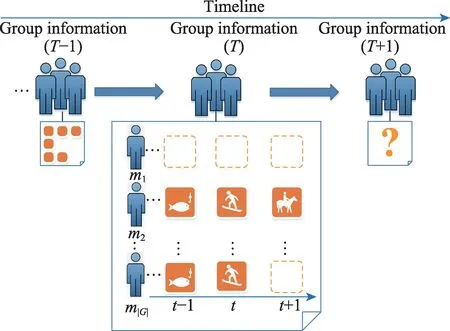
图2 NER4G 的基本模式Fig.2 Basic pattern of NER4G
不同于传统推荐,NER4G 问题面临以下挑战:
(1)数据稀疏性。一方面,用户和事件的交互上具有传统意义上的稀疏性,即大部分用户仅访问了相对较少的事件,大部分事件也仅被少部分用户访问。另一方面,如图2 所示,群组成员的历史记录被以时段划分以后,由于每个群成员在窗口期内访问事件的数量是不一致的,数据的稀疏性会被进一步放大。事实上,在原始数据里像群成员m1一样,在某个时段内无访问记录是非常常见的,而群组规模越大,这种稀疏性就越强。
(2)冷启动。与传统推荐场景中的音乐、商品不同,在EBSN 中,用户不会参与曾经访问过的事件,这是因为EBSN 中的事件都有其生命周期,且生命周期非常短。事实上,事件从线上发布到线下举办常常在数日到数月之间,而线下举办耗时更是往往仅在几个小时之内[3]。事件一旦被用户参与,也就结束了生命周期,这样的事件再推荐给用户没有意义。这意味者只能将在生命周期内的事件推荐给用户,而这些事件都是没有用户历史参与信息的新事件,都存在严重的冷启动[6]问题。
(3)群组动态偏好的建模。最新的研究聚焦在个体用户的动态偏好上[7],而群组偏好在宏观、微观上各有其动态性,比个体用户更为复杂。而群组偏好在宏观、微观上各有其动态性,如何对其进行较为准确而真实的刻画目前还没有统一的定论,是一个新的课题。
尽管直接研究NER4G 领域的文章相对较少,但已有一些研究对上述挑战提出了部分解决思路。为了克服群组交互数据的稀疏性,文献[8]提出一种基于排序学习的群组事件推荐框架,该框架结合时间、地理、地点、内容、直接和间接的社会影响等6 个上下文因素对个体偏好的影响,对群组偏好进行建模,将群组事件推荐任务形式化为一个学习排序问题。文献[9]提出了一种基于注意力的上下文感知群组事件推荐模型,其通过多层神经网络建模上下文对用户、群体和事件的深度非线性影响,并以此缓解新事件冷启动问题。
在群组动态偏好建模上,仅有两篇文章与本文的问题直接相关,其中文献[4]认为当下经典的群组偏好聚合策略如平均、最小痛苦度等在加入多次迭代时,并不能保证群组成员的满意度,于是基于公平的思想提出满意度的概念,动态调整推荐的结果。此方法的整体框架是结果融合,即给群组所有成员都进行推荐,设计排序算法调整推荐结果出现的位置,最后将整合好的结果视为群组推荐。而文献[5]提出了一种群组感知的长短期图表示学习(group-aware long and short graph representation learning,GLSGRL)方法,其将序列视为长期和短期两部分,采用图神经网络来构造群组感知的短期图和长期图用于用户表征,再通过门控机制和受限的用户交互注意力来聚合群组动态偏好。此方法的整体框架是过程融合,即通过聚合群组成员偏好得到一个质心用户,再向这个用户进行推荐。本文的研究更偏向于过程融合,遗憾的是,GLS-GRL 并不能直接应用到EBSN场景中。这是因为无论是长期图还是短期图都依赖于用户与项目的直接交互,而EBSN 中的独特的事件冷启动会使新事件无法进行嵌入导致推荐算法失效。
综上所述,NER4G 在EBSN 中是一个复杂的问题。为解决上述挑战,本文提出一种基于注意力的动态群组推荐(attention-based dynamic group recommendation,ADGR)策略。在宏观上,事件将被看作由各类上下文组成的抽象单元,事件推荐将被视为多标签分类问题,而被分类的标签即为各个上下文。在微观上,本文将结合注意力机制与序列模型,基于不同时期不同群组成员的参与程度,动态地建模群组偏好。
本文的主要贡献如下:
(1)将多标签分类问题引入EBSN 事件推荐领域,提出了一个新颖的事件推荐框架。该框架将事件抽象成上下文的集合,事件推荐转化为多个上下文的分类问题。
(2)提出了一种面向群组的Next 事件推荐策略,其将上下文作为最小单元,结合注意力机制和序列模型,依次构建出事件、成员偏好、群组静态偏好和群组动态偏好的特征表示,从而有效建模出群组偏好的动态特征。
(3)根据爬取的Meetup 真实数据,在事件数最多的三个城市数据集上进行消融实验和对比实验。实验结果表明,本文方法有更优越的性能。
1 相关工作
如前文所言,与本文问题直接相关的研究较少,以下主要从群组推荐、Next 项目推荐、多标签分类三方面来介绍相关的子领域。
1.1 群组推荐
群组推荐是指向一个群体进行推荐,推荐的结果考虑了所有群成员的偏好。其中,如何从群成员偏好获得群组偏好是各个研究的重点和难点。传统的群组偏好聚合策略有均值策略、最小痛苦度、最开心策略等[10],这些方法往往不够灵活,不能随着场景变化动态调整。随着注意力机制[11]的提出,因其能根据数据自适应地学习出权重,被广泛应用在群组聚合方法的研究上。文献[12]首次利用注意力网络从数据中动态学习出群组聚合策略,其还将注意力机制和神经协同过滤框架结合,学习群组与项目、用户与项目的交互,用多任务学习的方法提高模型性能。文献[13]提出了一种基于多注意力的群组推荐模型,其分为两个模块:第一个模块从群组共现、群组描述、外部和内部社交四方面综合建模群组特征表示;第二个模块用神经注意力网络描述群组及其成员的偏好交互,结合群组和项目特征建模群组偏好。
传统应用场景的群组推荐注重群组与项目、组成员与项目之间的交互,而在EBSN 中,由于新事件冷启动问题的存在,如何结合上下文信息进行群组推荐是研究的重点。事实上,已有研究表明[14],将上下文信息考虑进来,能有效缓解数据稀疏性问题,有利于提升群组推荐性能。文献[15]将上下文信息建模成异构信息网络,从中提取额外的内容信息,并将其与评分数据结合,设计了一个捕捉群组凝聚力的推荐模型。
1.2 下一个项目推荐
下一个项目推荐或顺序推荐起源于音乐推荐、兴趣点推荐等领域,目前广泛应用在电子商务领域。其认为用户随着时间的推移产生了大量线性的用户-项目交互数据,而用户的偏好也随之动态地变化,通过建模历史项目之间的顺序依赖关系推荐下一个用户可能感兴趣的项目[16]。
因此,目前主流的顺序推荐算法是依赖于序列模型的,文献[17]结合矩阵分解与马尔可夫链(Markov chain,MC)为每一个用户单独设置个性化转移矩阵,推荐下一个项目。但MC 仅依据最后几个状态来建模,仅在时间跨度较小的数据中效果较好。而递归神经网络(recurrent neural networks,RNN)原则上能够建模更长的语义。文献[18]对RNN 进行了扩展,提出了一种专门用于推荐任务的新型门控循环单元,其能够有效地通过建模项目序列表示用户,从而生成个性化的下一个项目推荐。得益于Transformer 结构在自然语言处理序列任务领域出色的表现,自注意力机制也开始被用于顺序推荐领域。文献[19]试图平衡长期语义与短期语义的建模,以使模型在简单稀疏或复杂稠密的数据集中都能有效发挥作用,其提出了一种基于自注意力的顺序推荐模型,该模型能在每个时间步自适应地为之前的项目分配权重。文献[20]还参考最先进的BERT(bidirectional encoder representations from transformers)序列结构,利用深度双向自注意力对用户行为序列进行建模,取得了较好的效果。
1.3 多标签分类
多标签分类(multi-label classification,MLC)[21]问题是指在分类时,将项目拥有的多个标签同时预测出来。该问题通常由图片分类、文本分类和医疗诊断任务驱动,如在服装图像识别上,一张图片既要给颜色打标签,也要给服装所属的部位打标签。同理,一篇文章可能有多个主题,一个病人可能同时患有多个疾病,要同时识别出来也需要进行多标签分类。在推荐系统中,采用多标签分类能够更精准地定义项目,从而产生质量更高的推荐。如文献[22]针对给文章推荐审稿人问题,考虑审稿人有多个擅长的领域,采用多标签分类作为问题框架,从而更清楚地反映论文与审稿人的语义,产生高效而精准的推荐。
2 问题定义
EBSN 中的信息网络结构如图3 所示。图中包含用户(User)、群组(Group)、事件(Event)、时间(Time)、地点(Venue)和主题(Topic)等实体。实体之间的连线表示关系,其中实线代表直接关系,虚线代表间接关系。线上标注的N和1 代表多对一的关系,N和N代表多对多关系。以用户与事件的关系为例,在EBSN 中,一个用户可以参与多个事件,一个事件也可被多个用户参加。本文研究对象是规模较小但内聚力较高的群组而非EBSN中广义上的兴趣组,因此,群组与事件是间接参与和被参与关系,用虚线表示。
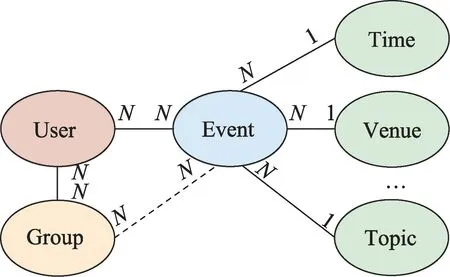
图3 EBSN 中的信息网络结构Fig.3 Information network structure in EBSN


基于上述符号,给出群组g的成员偏好、静态偏好和动态偏好定义。
定义1(群组成员偏好)群组成员m在时间窗T内访问的事件序列可表示为,则成员m在T内的偏好向量可表示为,其中f1表示建模群组成员偏好的聚合函数。
定义2(群组静态偏好)群组g在时间窗T内的静态偏好由其对应时间内群成员的偏好聚合而成,即群组静态偏好,其中f2表示建模群组静态偏好的聚合函数。
定义3(群组动态偏好)群组g的动态偏好由其多个时段的静态偏好聚合而成,即群组动态偏好,其中f3表示群组动态偏好的聚合函数。
根据上述定义,现在可以给出本文研究问题的定义。
定义4(面向群组的Next事件推荐)给定群组g及其所有成员在所有时段的访问记录,目标是计算条件概率P(e∈ET+1|Pg,∀e∈Ec),其中e表示根据Pg预测的群组g下一个时段可能访问的事件,ET+1表示群组在下一个时段真实访问的事件集合,Ec为生命周期在T之后的候选事件集合。
为解决上述问题,本文提出一种基于注意力的动态群组推荐策略(attention-based dynamic group recommendation,ADGR),完成Next事件推荐。
3 基于注意力的动态群组推荐策略
3.1 群组静态偏好建模
要进行动态推荐,首先要建模群组的静态偏好。静态偏好建模的总体架构如图4 所示,由群组g在T时段内的访问记录作为输入,由表示当前时段内群组偏好的特征向量作为输出。建模过程分为4 个阶段:
(1)基于参与度的排序与筛选(图4-①):对原始数据进行过滤,找出核心群成员缓解数据稀疏性。
(2)事件的特征表示(图4-②):用上下文表示用户交互的事件,借助EBSN 中丰富的上下文信息来缓解新事件冷启动问题。
(3)成员偏好的特征表示(图4-③):基于序列模型利用核心群成员在时段T内的历史记录来建模核心群成员的偏好。
(4)群组静态偏好的特征表示(图4-④):利用核心群成员的偏好融合出群组的静态偏好。
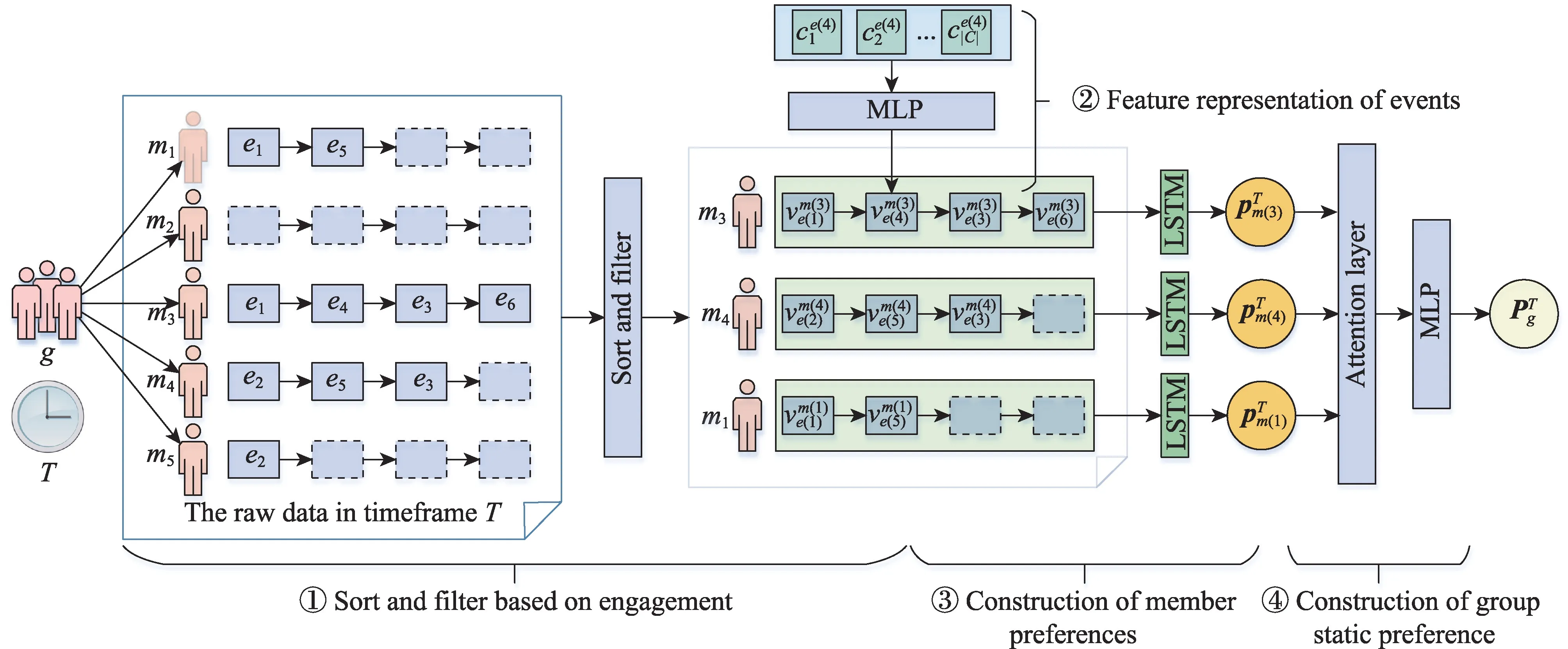
图4 群组静态偏好建模架构Fig.4 Architecture of group static preference modeling
3.1.1 基于参与度的排序与筛选
将群组成员的访问数据按时间片划分后,会加剧数据的稀疏性。为解决这一问题,首先引入参与度(Engagement)的概念,如式(1)所示,群组g中成员m在T时段内的参与度被定义为其在该时段内参与事件的数目。显然,组成员在T时段内参与的事件越多,其在该时段内的参与度越高。

本文认为,群组的静态偏好往往是由在该时段内参与度较高的成员偏好所构成。因此,将成员的原始数据按参与度排序,取参与度最高的前n个用户用于后续偏好建模,具体如式(2)和式(3)所示。
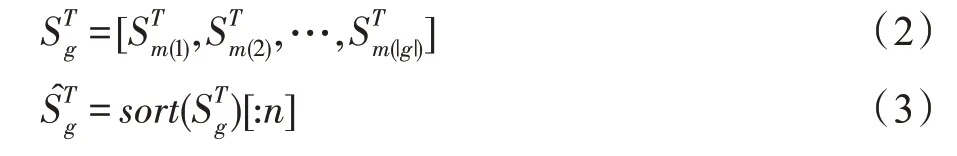
其中,为群组g在T时段内所有成员的历史访问序列,而为将排序并过滤后的对应数据。sort()为按参与度排序函数,符号[:n]表示截取前n个数据。
这样做的好处在于,尽管损失了部分数据,但一方面剔除了如图4 中成员m2这一类无效冗余数据,缓解了稀疏性,另一方面将群组决策建模为少数意见领袖共同决策的过程,符合部分已有研究的先验知识[23-24]。
3.1.2 事件的特征表示
由于事件与各类上下文都是多对一的关系,可以由一组上下文来表示事件[25]。在神经网络中,将数据进行嵌入表示是常用的特征表示方法,因此成员i在时段T内访问的事件j将被表示为向量其可由该事件对应的一组上下文经由MLP(multilayer perceptron)层嵌入后拼接而得。
具体而言,事件中任意一个具体的上下文会被编码为one-hot 向量,输入到神经网络中。经过如式(4)所示的线性变换转码成一个更低维而稠密的向量。拼接各个类别的上下文即得到事件的特征表示。

3.1.3 成员偏好的特征表示
成员的偏好由成员在当前时段内交互过的事件序列构成,因此,将成员m在时段T内的历史记录输入到序列模型里,以得到成员偏好的特征表示,具体如式(5)所示。

其中,lstm(∙)为长短期记忆网络单元,此处为多输入单输出模式。为成员m的偏好,dm为成员偏好的嵌入维度,其大小取决于lstm(∙)中神经元的个数。为成员m交互的第i个事件的特征表示,n为基于参与度过滤后的群组大小。
3.1.4 群组静态偏好的特征表示
群组的静态偏好由成员偏好聚合而得,而聚合方法即为注意力机制,其过程如式(6)、式(7)所示。

在得到成员注意力权重后,接下来就要融合成员偏好。由于已经通过参与度剔除了部分成员,为了使核心成员的信息得到最大利用,使用拼接操作进行聚合。再让融合过后的向量输入到一个MLP层。这样做的好处在于:一方面可以得到更深层的偏好表示;另一方面可以更好地控制群组静态偏好的维度。群组的静态偏好就等于MLP 层的输出,完整过程如式(8)所示。
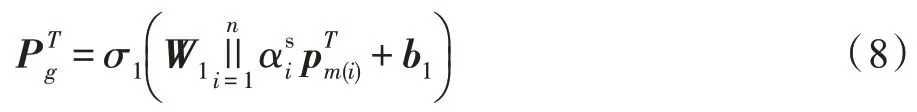
其中,表示群组g在T时段的静态偏好,W1∈分别为将注意力融合后的结果映射到群组静态偏好的权重矩阵和偏置向量,其中ds为静态偏好的嵌入维度,σ1(∙)是MLP 层的激活函数,这里选用“Sigmoid”。
3.2 群组动态偏好建模
群组的动态偏好可看成各个时段的静态偏好经由聚合函数构成,这同样是一个权重分配的过程。本文采用长短期记忆网络和注意力结合的模块对动态偏好进行建模。其过程如图5 所示,群组的静态偏好被输入到序列模型中,注意力模型融合序列模型输出的隐状态,再将其结果输入到MLP 层进行深度表示得到最终的群组动态偏好。
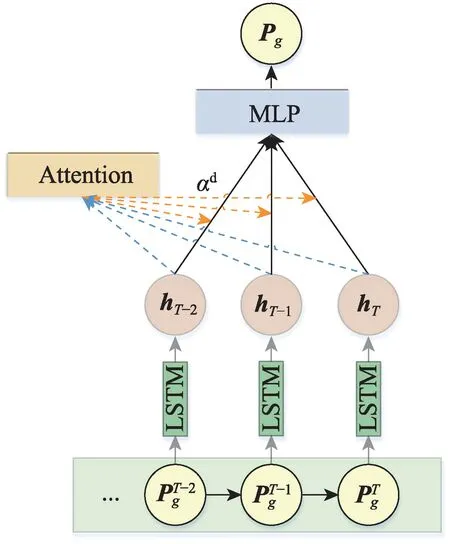
图5 群组动态偏好建模框架Fig.5 Architecture of group dynamic preference modeling
具体而言,群组静态偏好随时间变化也形成了一个序列,将这个静态偏好序列输入到lstm(∙)中,获得每一个时间步的隐状态矩阵h,具体过程如式(9)所示。
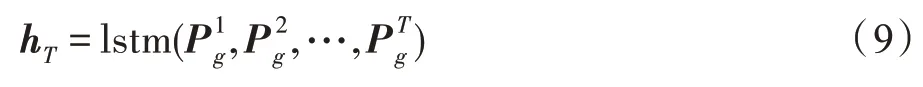
得到隐状态矩阵后,用注意力机制进行融合,其计算过程具体如式(10)、式(11)所示。

如式(12)所示,得到注意力得分后,用拼接的方式进行聚合,并将拼接的结果送入MLP 层,获取更深层的特征表示。MLP 层的输出即可视为群组当前的动态偏好。
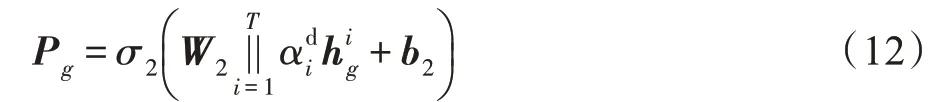
其中,Pg表示群组g动态偏好,和b2∈分别为将注意力融合后的结果映射到群组动态偏好的权重矩阵和偏置向量。其中dd为动态偏好的嵌入维度,σ2(∙) 是MLP层的激活函数,这里选用“Sigmoid”。
3.3 基于多标签分类的推荐
至此,群组动态偏好已经建模,接下来将基于动态偏好完成推荐任务。传统的Next 项目推荐常常被建模为多分类问题,即预测下一个项目属于候选集中各个项目的概率,选择概率最大的前K个项目进行推荐。
然而,由于新事件冷启动问题的存在,候选集中的事件全部都在测试集,这就意味着基于多分类的推荐模型在训练时无法学习到新事件,导致推荐失效。为了解决这一问题,本文率先将多标签分类引入Next事件推荐问题中来。
下面给出基于多标签分类的推荐框架,其如图6所示。ADGR 的输出层为Sigmoid 层(即激活函数为sigmoid(∙)的MLP 层),群组的动态偏好会被转化为每类上下文的概率。之后,将其与候选事件的上下文分布向量进行相似度比较,选择最高的前K个事件作为该群组的推荐结果,从而完成整个推荐任务。
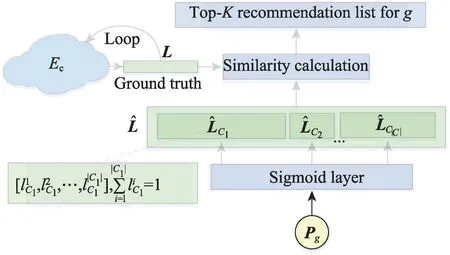
图6 事件推荐框架Fig.6 Framework of events recommendation
因为多分类问题可以转化为多个二分类问题[22],所以损失函数采用二分类交叉熵(binary crossentropy),其计算过程如式(13)~式(15)所示。

得到预测的概率分布向量后,采用余弦相似度进行推荐。为了将事件表示成如一样的概率分布形式,事件的每一个上下文将被进行one-hot 编码并被拼接起来,得到其表示Le,如式(16)所示。

最后,同样采用余弦相似度来衡量推荐哪一个事件。至此,整个群组Next 事件推荐完成,根据定义4,可得式(17)。
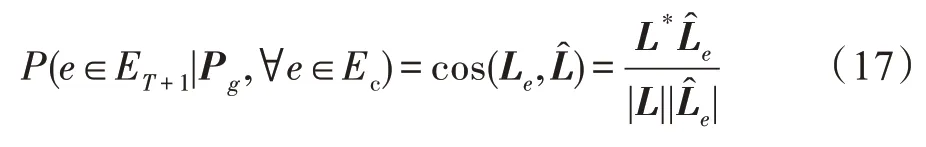
其中,cos(∙)为余弦函数,用于计算相似度。
4 实验及结果分析
4.1 数据集
尽管EBSN 中有显式的兴趣组,但这些群组往往规模比较大,凝聚度不够强。本文认为向规模较小、凝聚度较高的隐式群组进行推荐更有意义。因此,对Meetup 网站上2015 年至2017 年中纽约(NY)、芝加哥(CHI)、圣地亚哥(SD)3 个城市的用户-事件签到数据进行处理,得到群组信息如表1 所示。其中,群组根据用户事件访问记录的余弦相似度生成,群组内的任意两个成员相似度阈值不低于0.3。
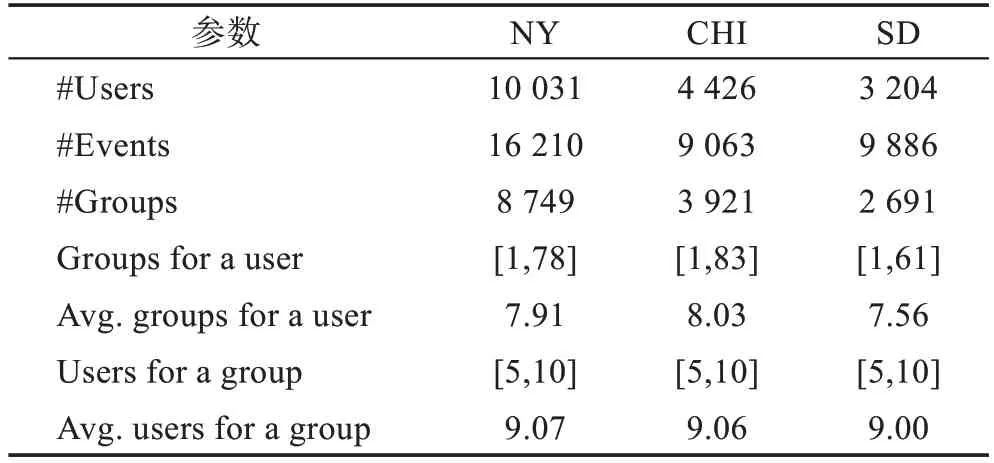
表1 数据集Table 1 Datasets
4.2 评价指标
本文采用精确率(Pre@K)、召回率(Rec@K)、F1值(F1@K)、命中率(HR@K)作为评价指标,其计算过程如式(18)至式(21)所示。
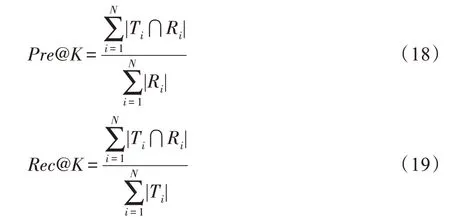
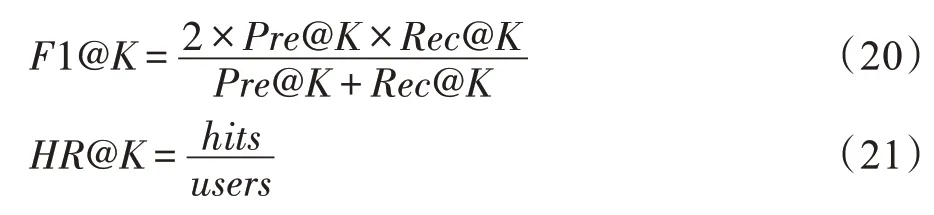
其中,K∈{1,10,20,30,40,50} 为TopK推荐列表的长度。Ti为第i次推荐中用户真实访问的项目集,Ri为第i次推荐中推荐给用户的项目集,N代表推荐的总次数。hits为推荐的项目出现在Ti的用户数目,users为用户总数。
4.3 对比实验
本实验选择下一个项目推荐算法、事件推荐算法、群组推荐算法进行改造,与本文方法及其变种进行对比,具体如下:
(1)PRME+Avg[26],经典的单用户下一个项目推荐方法,考虑了时空上下文与序列关系。采用平均的策略融合组成员偏好。
(2)PRME+UL(upward leveling)[27],群组偏好的融合采用UL 策略,该策略为基于结果融合的群组推荐方法,其同时考虑成员用户对项目评分的平均值、方差以及排名位置三种因素进行偏好融合。
(3)Event2vec+Avg[28],近年来的事件推荐算法,也用到了历史序列信息,采用平均的策略融合组成员偏好。
(4)Event2vec+UL,同样,单用户采用Event2vec获取评分,采用UL 策略融合组成员偏好。
(5)ADGR(attention-based dynamic group recommendation),本文提出的方法。
(6)DGR(dynamic group recommendation),去除ADGR 方法里所有注意力模块得到的模型。
(7)ADGR-,在ADGR 上去除基于参与度排序过滤模块后的模型。
(8)ADGR+,在成员偏好及上下文聚合模块都增加注意力机制而得到的模型。
实验结果如图7 所示。在三个规模不同的数据集上,ADGR 都有较好表现。尤其是在规模更大的纽约数据集上,ADGR 与次优方法DGR 的差距最大,这说明本文方法即使在大数据集上也有较好的表现。Event2vec+Avg 比PRME+Avg 更为出色,Event2vec+UL 同样比PRME+UL 效果好,这是因为Event2vec 建模时不仅考虑了序列信息,还考虑了更多的上下文。而群组聚合策略UL 比简单的平均效果更好,说明偏好融合是组偏好建模的重要部分。无论是对比基于PRME 还是基于Event2vec 的群组推荐方法,ADGR的性能有显著优势。这说明在EBSN 中,仅通过下一个项目推荐和群组推荐的组合策略,仍难以刻画好群组动态偏好。
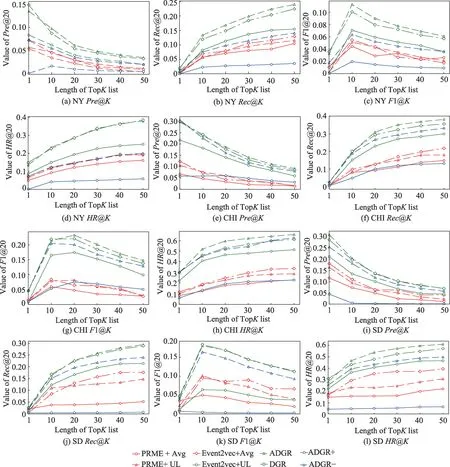
图7 三个数据集上的性能比较Fig.7 Performance comparison on three datasets
对比ADGR、DGR、ADGR-、ADGR+这四个方法可以看到,在大部分评价指标和数据集上,ADGR 优于所有其他变种方法。次优的方法是DGR,尽管去掉了注意力部分,剩余模块依然能较好地发挥作用。再次则为ADGR-,此方法没有做排序和过滤,因此网络更为复杂,同时大部分的网络会因稀疏数据的存在而被误导,整体学习能力较差。表现最差的方法是ADGR+,它在更细粒度的层面上也增加了注意力机制,然而其效果表现很差,这可能是模型复杂从而产生严重的过拟合所导致的。
4.4 参数设置
在本文中上下文嵌入维度dc=16,事件嵌入维度de=80,成员偏好嵌入维度dm=64,单位时段内成员访问的最大事件数等于5,核心成员数n=5,LSTM 里隐藏层的嵌入维度dh=64,群组静态偏好嵌入维度ds=320,群组动态偏好嵌入维度dd=320Lseq。时段数Tcnt和序列长度Lseq将由实验结果确定。
4.4.1 时段数Tcnt
群组下一个事件推荐会将数据集以时段划分,而时段数Tcnt指的是数据集被划分的时段总数,调整Tcnt一方面在于选择合适的参数使模型效果更佳,另一方面在于可以看出数据量的多少对模型性能的影响。图8(a)~(d)展示了实验结果。上述指标是在群组静态偏好序列长度Lseq=3,推荐列表长度K=20情况下三个数据集上的性能对比,划分的依据依赖于时间的分位数。可以看到在SD 和NY 数据集下,各指标在Tcnt从8 变化到24 一直是增长态势,而CHI尽管在一些指标上有所下降但仍相差不大,因此选择Tcnt=24 作为时段数的参数。另一方面,数据集被划分得越细致,单位时段内的数据量就会越少,而在序列长度不变的情况下,数据量少反而指标能够上升,这说明所提出的模型在稀疏数据和短期偏好建模上表现更佳,符合Next事件推荐的需求。
4.4.2 序列长度Lseq
接下来,对群组静态偏好的序列长度Lseq进行测试,同样保持Tcnt=24,K=20 的情况下将Lseq从3 变化到15 进行检验,其结果如图8(e)~(h)所示。
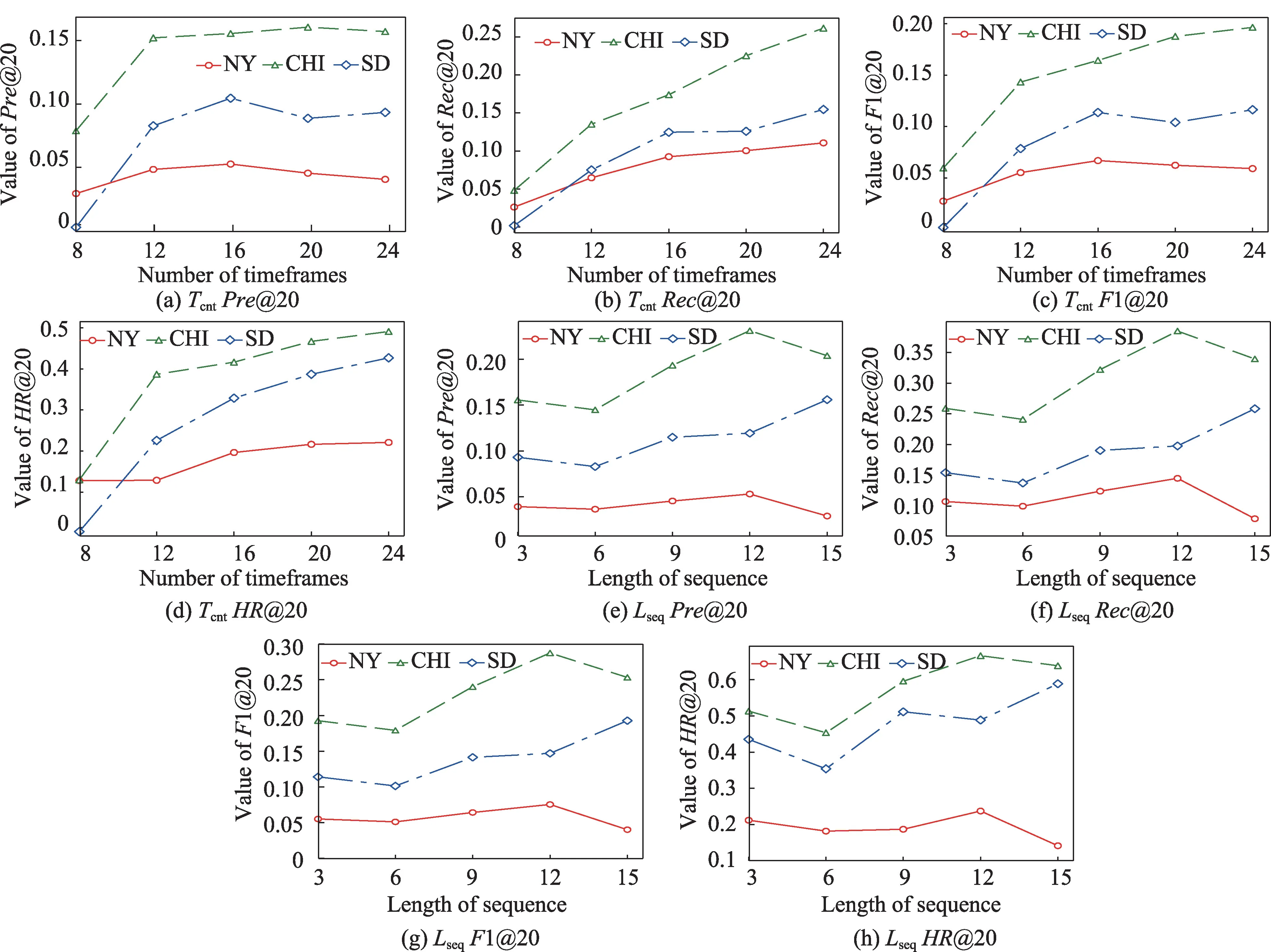
图8 不同Tcnt和Lseq的性能比较Fig.8 Performance comparison with different Tcnt and Lseq
可以看到Lseq=3 并不是最优的,三个数据集来自不同城市,因此它们的数据分布可能是不同的。三个数据集的指标在前期都是呈现先下降后增长的趋 势,在Lseq从12 至15 上 变 化 不 同,CHI 和NY 在Lseq=12 达到峰值而SD 则是在Lseq=15。综合整体考虑,选择Lseq=12 作为最后的参数。
4.5 讨论
从实验结果来看,所提方法取得了较好的效果。然而,如何将其应用于实际场景,如何在一直动态变化的EBSN 中进行增量更新,保证模型的性能,尚不明确,本节将针对这两点进行讨论。
4.5.1 实际应用
在豆瓣同城或Meetup 上,以群组为单位收集组成员数据进行训练,由于Tcnt和Lseq作为超参数可以人工调控,面对不同规模的历史数据可以采用不同的参数进行训练。模型训练完成后通过群组短期内的历史数据在候选事件集中进行预测,其结果向群组所有组成员进行推荐。
4.5.2 增量更新
在EBSN 中,新事件不在历史记录中,而训练好的模型只推荐历史存在的事件,因此直接以事件作为推荐单元不合理。在本文中,事件被视为各类上下文抽象得到的结果,多分类问题将预测事件转换为预测各类上下文。因此,新事件的冷启动转化为各类上下文的冷启动,而部分上下文值域固定,从而减缓冷启动带来的影响。
因此,当新事件的各类上下文仍处于历史值域之中,那么模型就不用更新,新事件也可被推荐。反之,则需要对模型进行更新,由于模型是按时段划分的,模型的更新也可按时段进行更新,从而减少更新频率及提高效率。
5 总结与展望
在EBSN 中面向群组进行下一个事件推荐是一个新颖而复杂的问题。针对稀疏性的问题,基于参与度对成员数据进行了筛选与过滤,选取少数核心成员构成低秩稠密数据。针对新事件冷启动问题,将推荐过程由事件的多分类转换为基于上下文的多标签分类问题,缓解了冷启动。为了建模群组的动态偏好,基于序列模型和注意力机制提出了一种动态群组推荐算法,其将事件看作由各类上下文组成的抽象单元,将短期的成员事件序列构建为成员偏好,通过核心成员的偏好融合出群组静态偏好,最后由静态偏好序列建模出群组动态偏好,从而为群组推荐下一个事件。在Meetup 三个数据集上的实验结果表明,所提方法有较好的表现。
尽管如此,仍然有许多问题可以深入研究。例如,如何更好地衡量成员的参与度,探索参与度与注意力机制结合的可能性,如何在考虑偏好的时序动态性的情形下基于更先进的图方法如超图、图神经网络设计下一个事件推荐算法等。将继续立足于EBSN 这一特殊的推荐场景,探索更多可能的推荐方法和推荐问题。
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:24:00
中国生殖健康(2019年8期)2019-01-07 01:18:20
电子测试(2018年14期)2018-09-26 06:04:10
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:42
机电信息(2015年9期)2015-02-27 15:55:56
电子设计工程(2015年15期)2015-02-27 12:07:33
发明与创新(2015年33期)2015-02-27 10:40:10
西南军医(2015年5期)2015-01-23 01:25:07
上海金属(2013年6期)2013-12-20 07:57:59
江苏卫生事业管理(2013年5期)2013-03-11 17:02:03
