
集成层级图注意力网络检测非均衡虚假评论
2023-02-18 07:16:52张月琴窦英通张泽华
计算机与生活 2023年2期
赵 敏,张月琴,窦英通,张泽华+
1.太原理工大学 信息与计算机学院,太原030024
2.Department of Computer Science,University of Illinois at Chicago,Chicago 60607,USA
随着智能推荐系统、机器在线问答等数据挖掘技术与应用的深入发展,用户网络评论已成为互联网大数据不可忽视的组成部分。但在巨大经济利益的推动下,虚假评论和网络水军(paid posters)已成为当前的一大顽疾。针对产品或服务的欺诈评论会误导用户的消费决策,从而降低用户消费体验,影响商家信誉,给商家造成经济损失[1]。因此,检测并及时过滤虚假评论已成数据挖掘应用的痛点问题。
虽然当前互联网中的虚假评论数量逐年递增,但总体仍呈现出类别不均衡[1]。基于传统机器学习的欺诈评论识别方法从类别分布不均衡的数据中学习的模型会偏向多数类,因此在识别少数不实评论时难免产生有偏差的分类结果。针对这一现实存在的问题,Yuan 等人提出两阶段检测方法TM-DRD(deceptive review detection algorithm based on target product identification and calculation of metapath feature weight)[2],首先利用核密度估计分析欺诈者的评分模式得到频繁受攻击的商品集合,将识别范围缩小到目标商品的评论后数据类别倾斜程度降低,再采用元路径特征权重计算得到最终的识别结果。周黎宇从算法改进入手,提出了基于支持向量取样的非均衡数据分类方法,并依此构建了虚假评论检测模型[3]。ISRD(spam review detection with imbalanced data distributions)方法结合降采样与集成学习,在多个平衡数据集上训练不同的决策树分类器,最后通过多数投票算法(majority vote)检测欺诈评论[4]。这些方法在一定程度上提升了不均衡虚假评论检测的性能,但大多基于传统的统计方法改进,高代价的特征工程会限制其灵活性。
图神经网络[5]是一类专门处理网络结构数据的深度学习模型,可以聚合邻居信息为中心节点学习高维非线性的向量表示,应用于下游的分类、聚类等任务。近年来,有些欺诈检测方法基于GNN(graph neural networks)相关模型构建,Zhang 等人从地下论坛抽取有效的关系构建异构用户网络,结合图卷积神经网络(graph convolutional neural networks,GCN)[6]和注意力机制(attention mechanism)[7]提出player2vec方法检测非法利益链上的关键用户[8]。Wang 等人提出基于双层结构GCN 的FdGars 方法对手机应用商店的评论进行欺诈检测[9]。不同于传统机器学习方法的多步处理过程,GNN-based 方法以端到端的方式检测欺诈,但这类方法同样受到类别不均衡的影响,在浅层神经网络的反向传播过程中,多数类主导着用于更新模型权重的梯度,这使得类别失衡的数据训练得到的神经网络偏向多数类,与更关注少数异常的欺诈检测任务相违背[10]。
为了避免大量的特征工程,降低类别倾斜的影响,本文结合集成学习框架提出了一种面向非均衡类数据的集成层级图注意力网络虚假评论检测方法(ensemble hierarchical graph attention network,En-HGAN),其总体识别过程如图1。本文主要工作内容如下:
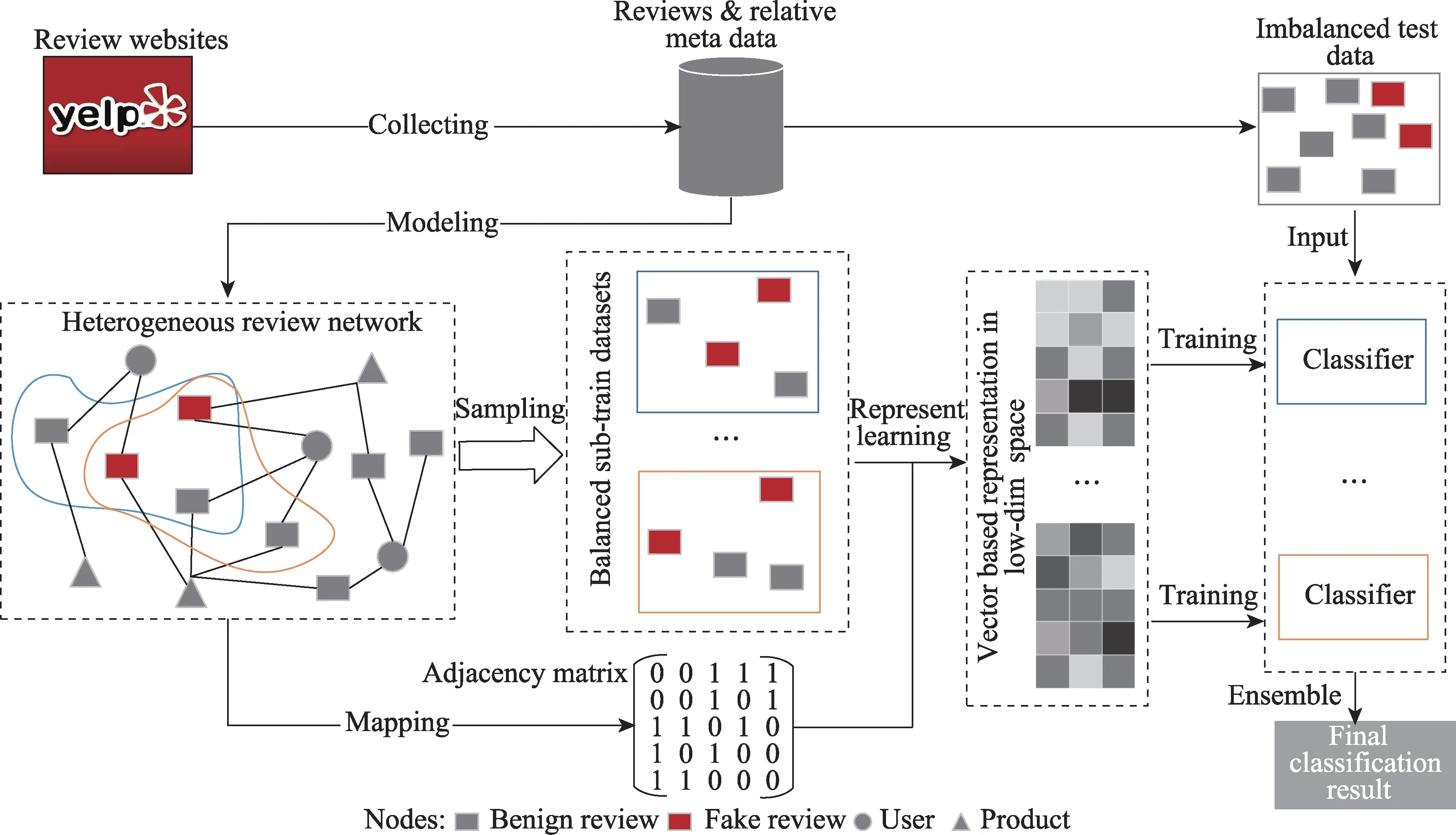
图1 En-HGAN 识别欺诈评论的总体过程Fig.1 Overall process of detecting fake reviews using En-HGAN
(1)为了充分学习评论网络中各种形式异构的信息,En-HGAN 采用双层注意力计算为混合领域的评论生成更加细致的向量表征。
(2)利用随机欠采样(random under sampling,RUS)对原始倾斜数据做预处理,再融合Bagging 框架集成多个“好而不同”的HGAN 子模型来缓解类别不均衡问题。
(3)通过选择数据倾斜分布时适用的评价指标,进而可反映En-HGAN 方法真实的欺诈检测效果。
1 相关工作
传统机器学习检测虚假评论的方法可分为有监督、半监督和无监督三类,大多依赖于反映不实评论与可信评价间差异的欺诈特征,如针对文本的有词袋(bag of word,BoW)、心理语言学(linguistic inquiry and word count,LIWC)、评论长度、发布日期、评分等文本属性及元数据;关注评论行为的包括最大评论内容相似度(maximum content similarity)、最大评论数量(maximum number of reviews)、极端评分(extreme rating behavior)等统计信息[11]。
监督方法通常把检测不实评论当作二分类任务,从评论文本及元数据中抽取欺诈特征,利用有标记数据来训练机器学习分类算法。Shojaee 等人采用反映写作风格的词汇和句法特征(lexical and syntactic features),通过支持向量机和朴素贝叶斯算法在酒店评论语料库上实施了欺诈检测任务[12]。由于标记数据难以准确构建,不依赖类别标签的无监督方法为检测不实评论提供了新思路。任亚峰等人充分研究了欺诈者的心理状态,认为虚假评论在语言结构和情感极性上必然与真实评论存在较大差异,从评论文本中抽取相关特征后,通过聚类算法检测虚假评论[13]。半监督方法大都通过协同训练(co-training)、正例-无标记学习(PU-learning)等半监督学习框架,利用少量有标记数据以及大量无标记数据来训练机器学习分类器,达到检测目的。例如先用全监督的分类算法在少量标记数据上选择最优的混合欺诈特征,再利用半监督的协同训练、三元训练(tri-training)和协同随机森林(co-forest)算法以及大量无标记数据提升识别虚假评论的性能[14]。但是随着评论数据规模的不断增加,大量费时费力的特征抽取、特征选择工作无法避免,同时这些“精心设计”的统计模型容易受到攻击且面临领域迁移的问题。
随着欺诈与反欺诈检测的博弈过程,欺诈者会有规避检测的进阶行为,导致根据专家经验设计的欺诈特征失效。鉴于评论系统中实体间关系难以改变和隐藏,基于网络的虚假评论检测方法出现。基于概率图模型的URSM(unified review spamming model)方法将评论建模为隐变量,并以无监督的方式对其欺诈程度进行排序[15]。NetSpam 方法将评论网络建模为异构信息网络,并利用元路径特征权重计算对评论进行分类[16]。
2 层级图注意力网络虚假评论检测方法HGAN
HGAN(hierarchical graph attention network)是实施在异构信息网络上,利用节点嵌入来检测欺诈评论的GNN-based 方法,下面介绍相关定义。
2.1 相关概念
定义1异构信息网络(heterogeneous information network,HIN)[17]可以表示为无向图G=(V,E,X),其中代表a类型节点,Xa是a类型节点的初始特征矩阵,网络中共有A种不同类型的节点,Eb代表b类型的边,网络中共有B种不同类型的边,且A+B>2;当A=B=1 时,异构网络G演变成同构网络g。
定义2(异构信息网络节点表征学习[17])给定一个异构信息网络G=(V,E,X),节点表征学习的目标是训练一个函数f:Va→Rd,将目标节点映射到d维向量空间,其中d≪|Va|。
定义3图神经网络(GNN)[5]遵循层间信息传递机制,能够同时学习网络结构与节点属性信息为节点生成向量表示,总层数可用L表示,l层接收并聚合l-1 层的信息,1 ≤l≤L,通过堆叠多层GNN,目标节点最终可以接收来自较远邻居的信息。图神经网络模型的一般框架可以表示成为,其中是中心节点v在l层的向量表示,Nv是节点v的one-hop 邻接节点集合,l层的聚合函数AGG(l)(∙)可将邻居信息映射为向量,⊕代表邻居信息与节点v属性的结合操作。
2.2 异构评论网络的构建
根据评论系统中天然存在的关系构建异构评论网络G=(V,E,X),其中V={VU,VR,VP},E={Epost,Ebelongs-to},X={XU,XR,XP},VU、XU分别代表用户(User,U)节点及其特征矩阵,VR、XR分别代表评论(Review,R)节点及其特征矩阵,VP、XP分别代表商品(Product,P)节点及其特征矩阵,Epost代表用户与评论间的发表关系,Ebelongs-to代表评论与商品间的属于关系。图2(a)给出构建一个异构评论网络的例子,虚假评论检测可以视为其中的节点二分类问题,利用网络表征学习把评论节点VR映射到输出向量空间Rd,接着训练分类器C:Rd→{0,1}检测评论节点的可信性,1 代表不实,0 代表可信。
2.3 异构评论网络中关系的选择
异构评论网络包含丰富各异的关系信息,要从中选出对欺诈检测有意义的,能反映虚假评论间相似性的关系。
Xu 等人的研究表明群组欺诈评论,即有组织的水军团体有目的地攻击某些特定商品,以群组的方式发布虚假评论的行为,是现在非法操纵评论的主要形式,其危害性远大于单个欺诈用户[18]。群组虚假评论在发表者、商品、评分和发表时间上紧密关联[19]。
基于上述研究,形成图上的迹(trail),即图上两个互异节点间不经过重复边的一条路径,选择评论节点间的三种复合关系,如图2(b)所示。
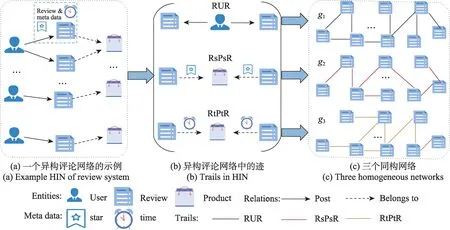
图2 通过评论间的关系映射异构评论网络到同构网络Fig.2 Mapping HIN to homogeneous networks via several trails
2.4 HGAN 的整体结构
如图3,层级图注意力网络HGAN 检测方法整体由三部分组成:首先是基于图注意力网络(graph attention network,GAT)[20]的GAT-layer,其中包含节点级别的注意力计算;接着是语义融合层(semanticfusion-layer),其中包含关系级别的注意力计算;最后是输出分类结果的线性层(linear-layer)。
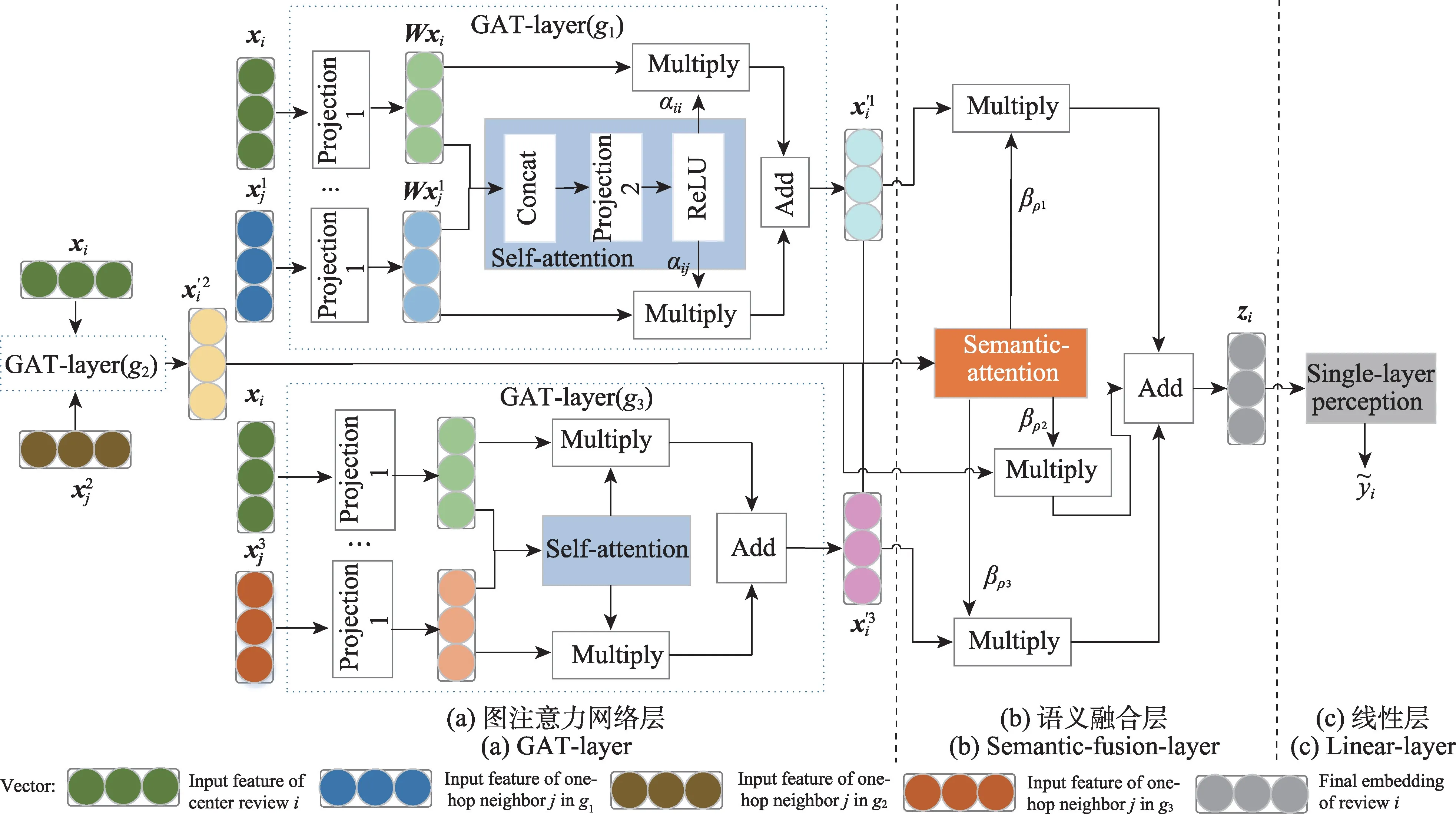
图3 HGAN 的整体框架Fig.3 Overview framework of HGAN
(1)处理同构评论网络的GAT-layer 评论数据通常涉及多个领域,由不同用户撰写,特征呈现多样性[21]。GAT-layer在信息聚合阶段采用自注意力(self-attention)机制,依赖网络结构与节点特征为中心评论的邻居学习不同的相对重要性,一定程度上提高整体分类性能。
三个平行的单层GAT-layer分别学习评论在三个同构网络下的向量表征,下面以g1为例介绍关系RUR 下评论表示的学习过程,其他两种关系下的节点表征学习可由此类推。


式(2)用Softmax 函数计算评论i、j间归一化的注意力系数,保证i所有邻居的注意力系数之和为1,Ni是i的一阶邻居集合。相比GCN[6]不考虑相邻评论之间互相影响程度的差异,通过计算节点连接度deg(∙)为邻居分配的对称性权重αij这样非对称的相邻评论间重要性更具现实意义。
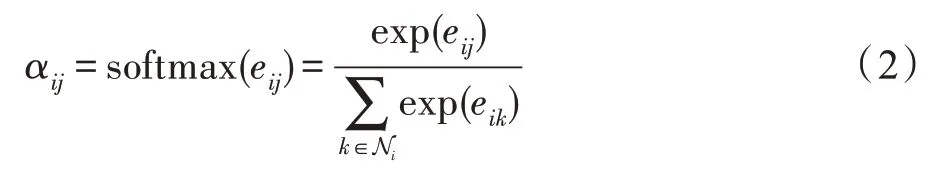
式(3)结合评论i与其邻居信息生成向量表示。结合操作⊕选择加和,邻居信息聚合操作选择邻居特征与其对应注意力系数的线性组合,σ是激活函数。
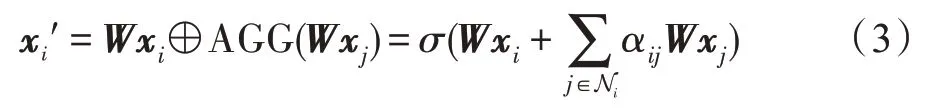
为增强自注意力学习过程的稳定性,采用式(4)的多头注意力(multi-head attention)机制,即实施自注意力机制P次,把得到的评论向量连接。其中是第p个注意力机制计算得到的邻居权重,这样评论的输出表征的维数是Pd2。
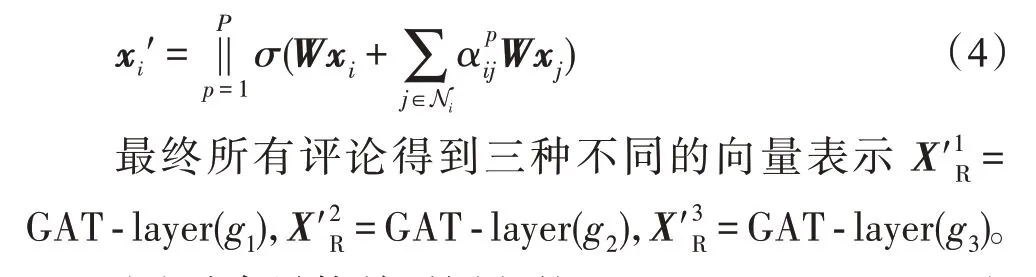
(2)融合异构关系语义的semantic-fusion-layer这一部分融合不同关系下的评论向量表示,学习更全面统一的评论表征。semantic-fusion-layer 的输入是评论表征集合,输出评论表征,l是向量维数,⊕是融合操作。不同关系下的表征对评论分类任务的贡献各异,在融合时采用注意力机制自动计算各个关系的权重,具体如下。
式(5)计算关系ρk的注意力权重。首先对ρk下的评论表征实施非线性变换,M是可训练的权重矩阵,b是偏置;接着用语义级别的注意力权重向量q与非线性变换后的评论表征做点积,最后取均值作为,是对特定关系下所有评论表征重要性的平均。
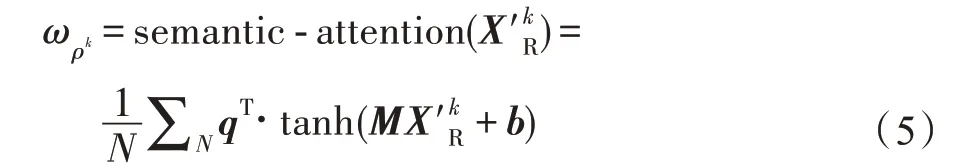
式(6)利用Softmax 函数计算关系ρk归一化后的注意力权重,表示关系ρk下评论表示的重要性。
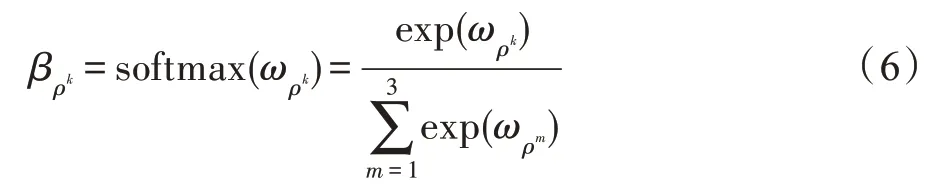
式(7)输出融合评论表征ZR,融合操作⊕选定为特定关系的注意力权重与相应评论表征的线性组合。

(3)输出分类结果的linear-layer
式(8)将融合全部语义的评论表征ZR输入到单层的神经网络分类器中,输出评论的类别,W1和b1分别代表权重矩阵与偏置。

因此,可最小化式(9)的二分类交叉熵损失来指导模型的训练,其中yR代表评论的真实标签,代表HGAN 方法计算的分类结果。
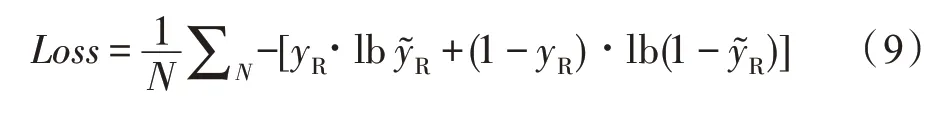
3 非均衡虚假评论检测方法En-HGAN
传统机器学习方法和深度学习模型多广泛使用数据预处理来解决非均衡监督学习问题,这类方法不需对模型做修改,主要通过在训练数据集上实施随机过采样、随机欠采样或其他动态采样方法减轻训练集的倾斜程度[22]。
利用随机降采样对训练集做预平衡,可以简单地解决HGAN 方法面临的评论数据类别倾斜问题,但单一的欠采样处理会丢失一些对评论分类任务有意义的负例样本信息,因此融合Bagging[23]集成框架提出En-HGAN 方法,尽量减少欠采样带来的信息损失,En-HGAN 集成模型的整体学习过程如图4。
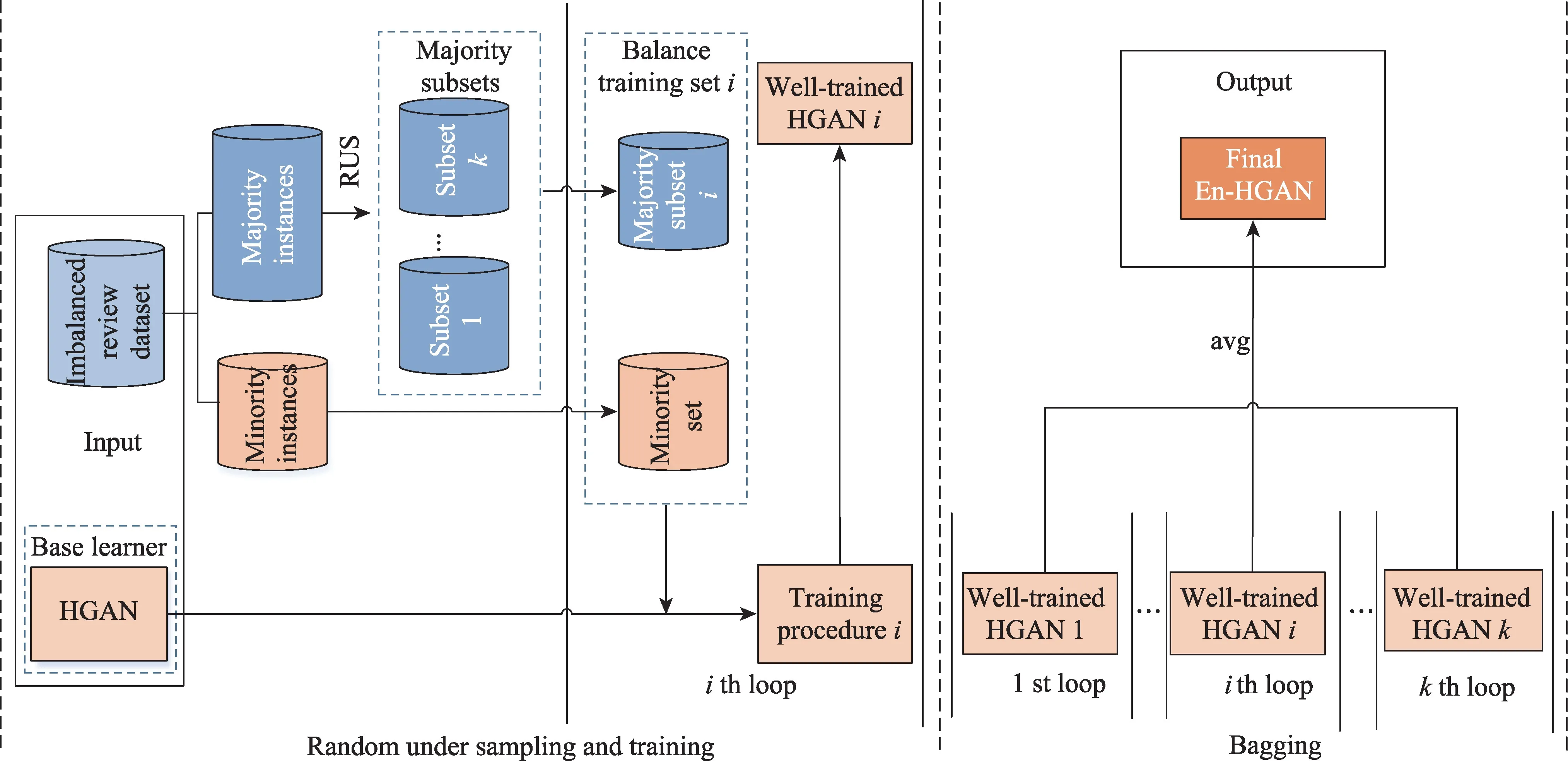
图4 En-HGAN 的学习过程Fig.4 Learning procedure of En-HGAN

利用集成模型En-HGAN 判断评论是否欺诈节点时,输入用于测试的评论样本集Dtest;首先利用集合ε={HGAN1,HGAN2,…,HGANk} 中所有训练好的基础检测模型为Dtest中的测试评论样本生成二分类结果;之后将基础检测模型HGANi对测试评论实例j∈Dtest给出的分类结果记作cij,对集合ε中所有基础学习器的分类结果取算数平均值作为评论j最终的集成检测结果,即En-HGAN(j)=。
由于不同的训练子集存在差异,且基学习器HGAN 作为一种神经网络模型,其学习结果容易受到样本扰动的影响,在一定程度上可以保证集成学习结果的多样性。
在En-HGAN 检测方法中,基学习器的个数k等于均衡训练子集的数量,依照Lee[24]提出的式(10)选取k值,该式通过提供足够多的训练子集,尽可能利用所有实例的信息。
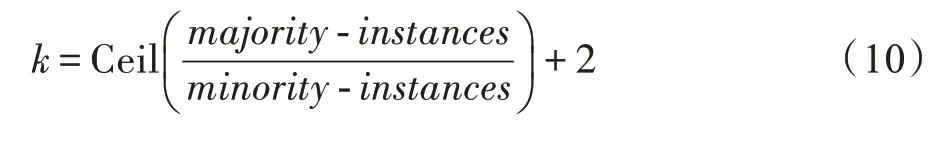
4 实验与结果
在内存为640 GB DDR2 的浪潮异构机群GPU:12X 32 GB Tesla V100s 实验环境下,分别测试基学习器HGAN 与集成方法En-HGAN 的虚假评论识别效果并且对参数设置进行讨论,又与其他基线方法进行对比。
4.1 实验数据与评价指标
在数据类别分布非均衡的情况下,本文利用En-HGAN 欺诈检测方法在YelpChi[25]评论数据集上实施虚假评论识别任务,在Amazon[26]评论数据集上实施欺诈用户检测任务,二者都可归结为异构网络上的节点二分类问题。
YelpChi 数据来自Rayana 等人[25]从商业点评网站Yelp.com 上采集的经网站自身过滤算法标记的用户评论数据,涵盖了酒店与饭店两个领域,预处理后YelpChi数据集的统计信息如表1。

表1 YelpChi数据集的统计信息Table 1 Statistics of YelpChi dataset
Amazon 数据包含乐器类产品的用户评论,来自Mcauley 等人[26]从电子商务网站Amazon.com 上爬取并公开的无标记用户评论数据,预处理后Amazon 欺诈用户数据集的统计信息如表2。

表2 Amazon 数据集的统计信息Table 2 Statistics of Amazon dataset
为了利用En-HGAN 方法在Amazon 数据上对欺诈用户进行识别,与Zhang 等人[27]的做法相似,将获得有用投票(helpful votes)超过80%的用户标记为良性实体,将有用投票低于20%的用户标记为不可信实体;Amazon 评论数据集上同构用户网络的构造与Dou 等人[28]的做法类似,基于关系UPU 为针对至少一个相同产品发表过评论的用户建立直接关联,基于关系UsU 为一周时间内至少给出过一次相同评分的用户建立直接关联,基于关系URU 利用TF-IDF(term frequency-inverse document frequency)衡量所有用户的评论文本相似度,并为前5%的用户建立直接关联;最后得到三种不同关系下的Amazon 同构用户网络gUPU、gUsU和gURU。
图5 给出YelpChi 数据下根据评论间关系构造的网络gRUR、gRsPsR、gRtPtR的度分布情况,横轴代表节点连接度,纵轴代表频次,可以看出通过时间戳、评分连接的评论网络比用户连接的评论网络更加稠密。
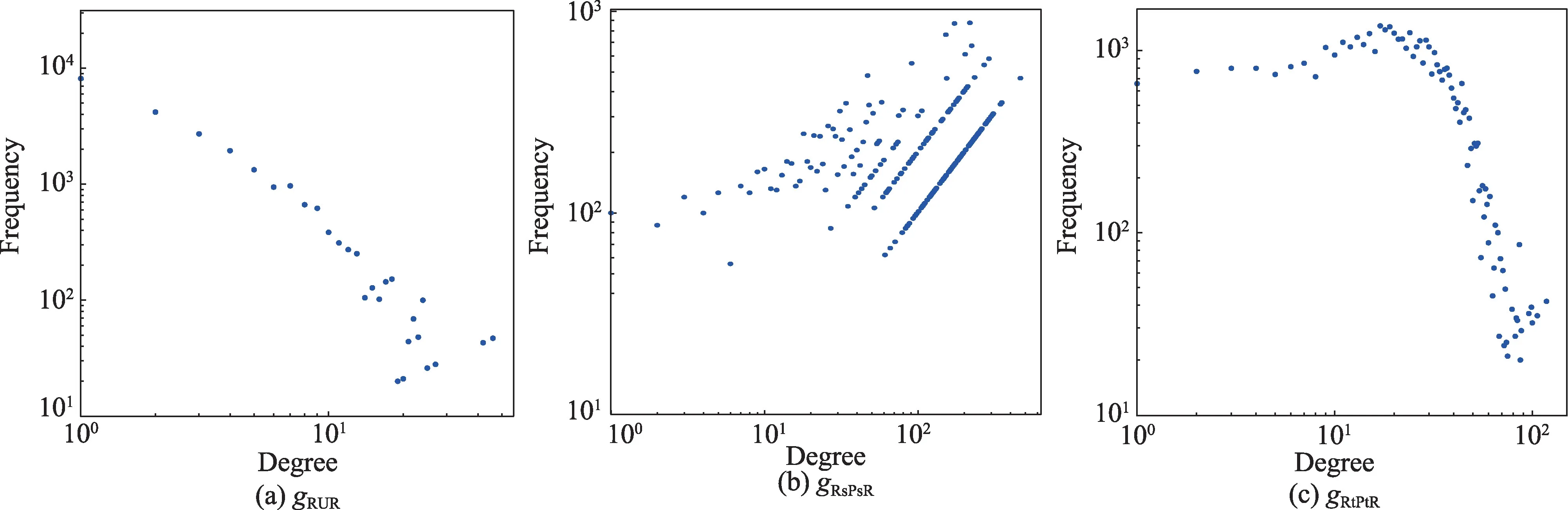
图5 YelpChi评论网络的度分布Fig.5 Degree distribution of YelpChi review networks
图6 给出Amazon 数据下根据用户间关系构造的网络gUPU、gUsU、gURU的度分布情况,不难看出通过评分与评论文本相似度连接的用户网络比通过产品连接的用户网络更稠密。
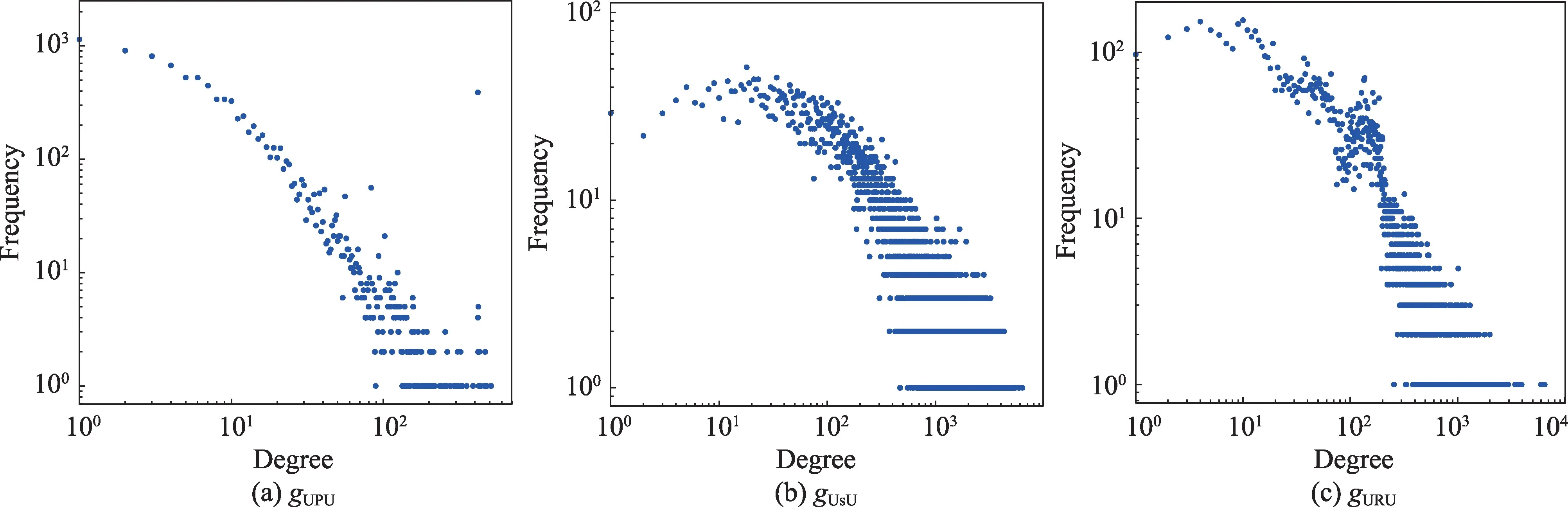
图6 Amazon 用户网络的度分布Fig.6 Degree distribution of Amazon user networks
本文选择F1 值评价模型的整体分类性能,选择ROC-AUC(receiver operating characteristic-area under the curve)值评价模型对欺诈节点的检测能力。
4.2 对比方法
(1)LR,传统的机器学习分类算法,实验中采用Rayana 等人论文中的离散欺诈属性[25]作为YelpChi评论数据初始特征。
(2)Player2Vec[8],该方法使用GCN 对每个关系中的信息进行编码,并使用注意力机制汇总来自不同关系的信息。
(3)FdGars[9],基于GCN 的欺诈检测方法,实验中用该方法分别为多个同构评论(用户)网络生成节点表征,并报告多种关系下最优的检测性能。
(4)HGANnd,HGAN方法的一个变体,去除GAT-layer 中的self-attention 计算模块,在信息聚合时为中心评论的邻居分配相同的权重。
(5)HGANsem,HGAN 方法的另一变体,仅去除语义融合层的注意力权重计算,并为每种关系分配相同的权重。
(6)graphconsis[29],基于空间域的GNN模型graphsage[30]改进,通过解决邻居信息聚合时的不一致问题缓解类别倾斜的影响。
4.3 实验设置
实验中所有GNN-based 模型的可训练参数采用随机方法初始化,并基于交叉熵损失采用Adam 算法进行优化训练。YelpChi评论网络中节点的初始特征XR采用100维的Word2Vec 嵌入表征,Amazon 用户网络中节点的初始输入特征采用Zhang 等人[27]论文里25 维的离散属性。
在HGAN 模型结构的设置上,对每个YelpChi 评论网络(Amazon 用户网络),GAT-layer 均设置为1层,即只考虑距中心评论(用户)1-hop 的邻居,其中多头注意力机制实施次数P设置为8,输出空间维度d2设置为8,即输出特征维数为64,激活函数采用LeakyReLU;semantic-fusion-layer 中学习语义注意力系数的向量q的维数设置为128,最终每个YelpChi 评论(Amazon用户)节点学习到的嵌入表征的维度l是64。
在En-HGAN方法的实验中,根据式(10)与参数实验为YelpChi 数据集将基学习器个数k设置为9,为Amazon 数据集将基学习器数量k设置为12,每个装袋中正负样本的比例为1∶1,为保证学习结果的可信性,独立实验5 次,对评价指标取平均值。
4.4 实验结果
(1)保持测试集中的正样本比例等于原始数据集中的类别不均衡比率(YelpChi 数据中为14.5%,Amazon 数据中为9.5%),En-HGAN 方法以及基线方法在两个数据集上进行欺诈节点检测的F1 值与AUC 值分别如图7、图8 所示。
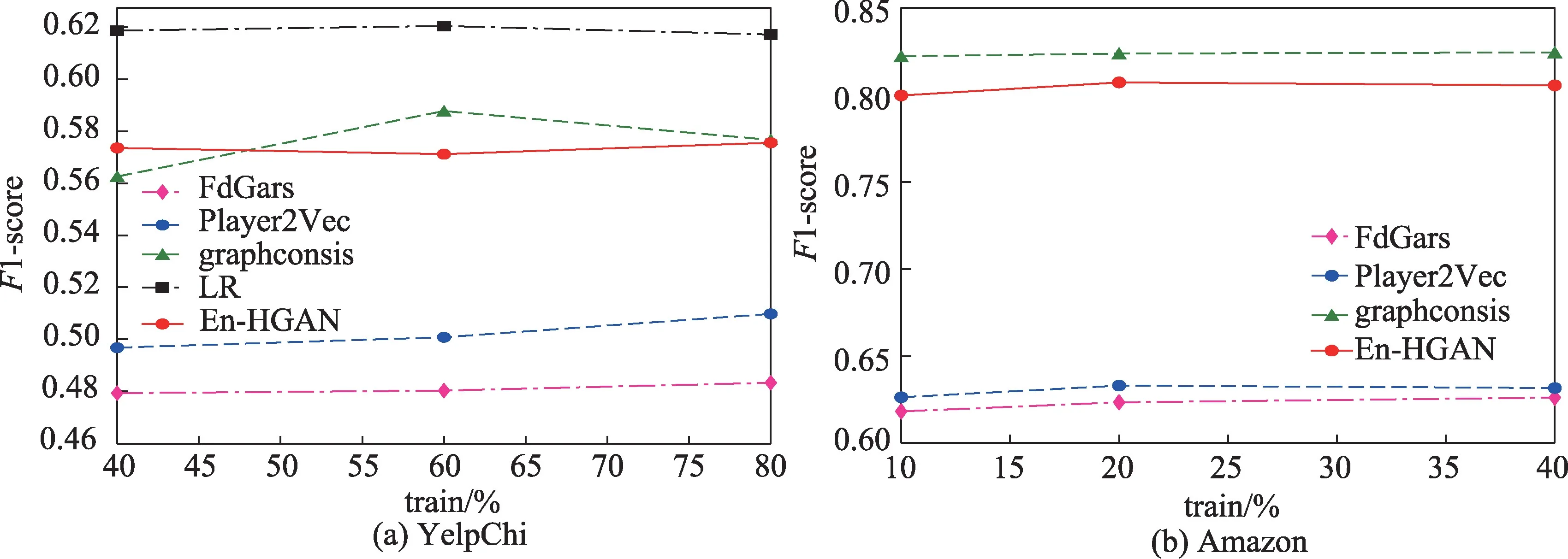
图7 YelpChi与Amazon 数据集上的F1 值结果Fig.7 F1 result on YelpChi and Amazon datasets
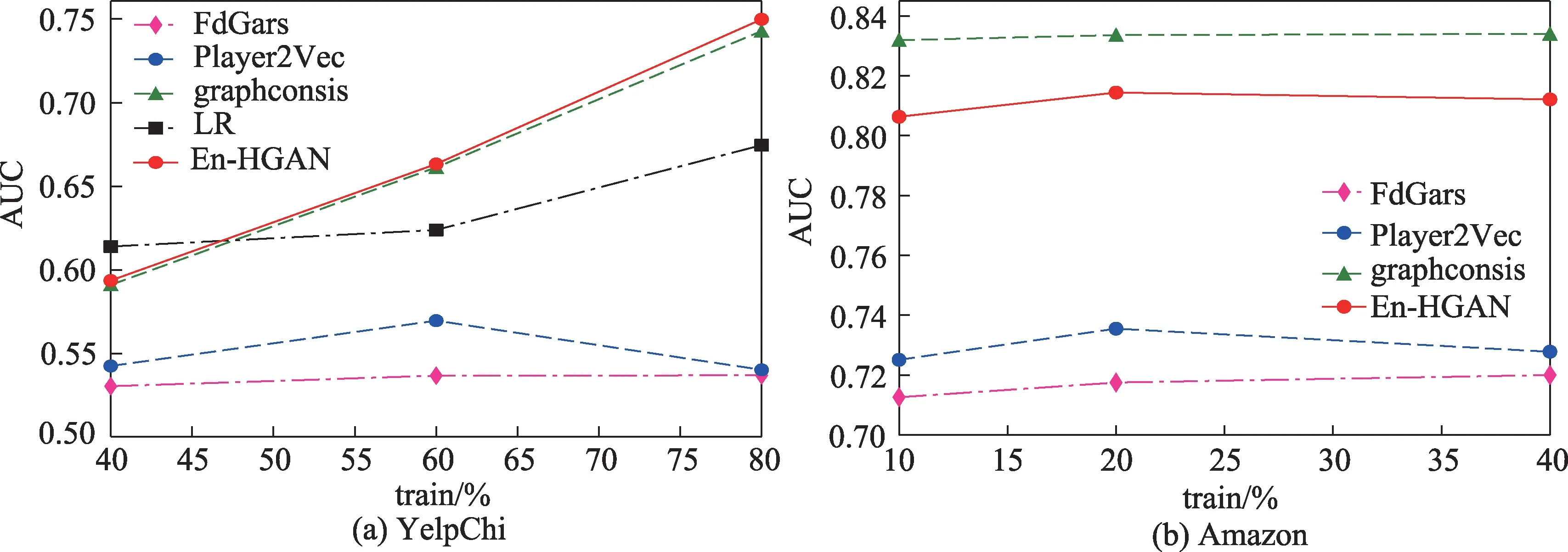
图8 YelpChi与Amazon 数据集上的AUC 值结果Fig.8 AUC result on YelpChi and Amazon datasets
图7(a)中,基于欺诈特征的LR 方法对YelpChi评论的整体分类效果最优,说明根据专家经验设计的特征的有效性。图7 中,集成方法En-HGAN 在YelpChi 数据集上的F1 值基本与先进的graphconsis方法相近,在Amazon 数据集上的F1 值稍低于graphconsis 方法,总体优于其他两个GNN-based 检测方法,这表明在HGAN 模型中引入集成思想解决图结构数据的不均衡分类在一定程度上是有效的;两个数据集上,Player2Vec 在整体分类性能上始终优于FdGars,这表明融合异构语义信息的评论(用户)表征比单一关系下学习到的节点向量表示更具分辨力。
图8(a)中,En-HGAN 方法在YelpChi 数据集上的AUC 值与先进的欺诈检测方法graphconsis 很相近,稍优于传统的LR 方法,且总是优于其他GNNbased 方法;图8(b)中,En-HGAN 方法在Amazon 数据集上的AUC 值相比graphconsis 方法稍低,且总是优于另两个GNN-based 方法。这表明基本的GNNbased 欺诈检测方法确实会受到非均衡数据分布的不良影响,同时也说明集成多个存在差异的HGAN 模型来检测网络中少量的不实评论(欺诈用户)是可行的。
(2)在两个数据集上,基学习器HGAN 与变体方法实验结果的F1 值与AUC值分别如图9、图10所示。
从图9、图10 中不难看出,两个不同数据集上,HGAN 在检测性能上始终优于两个变体方法,这表明双层注意力机制能够从异构的语义关系中学习到表达力更强、对欺诈检测任务更加有效的节点嵌入;HGANsem 的表现总是好于HGANnd 则说明,相比关系级别的注意力计算,在节点级别对邻居信息进行有区别的融合更有益于欺诈节点检测任务。
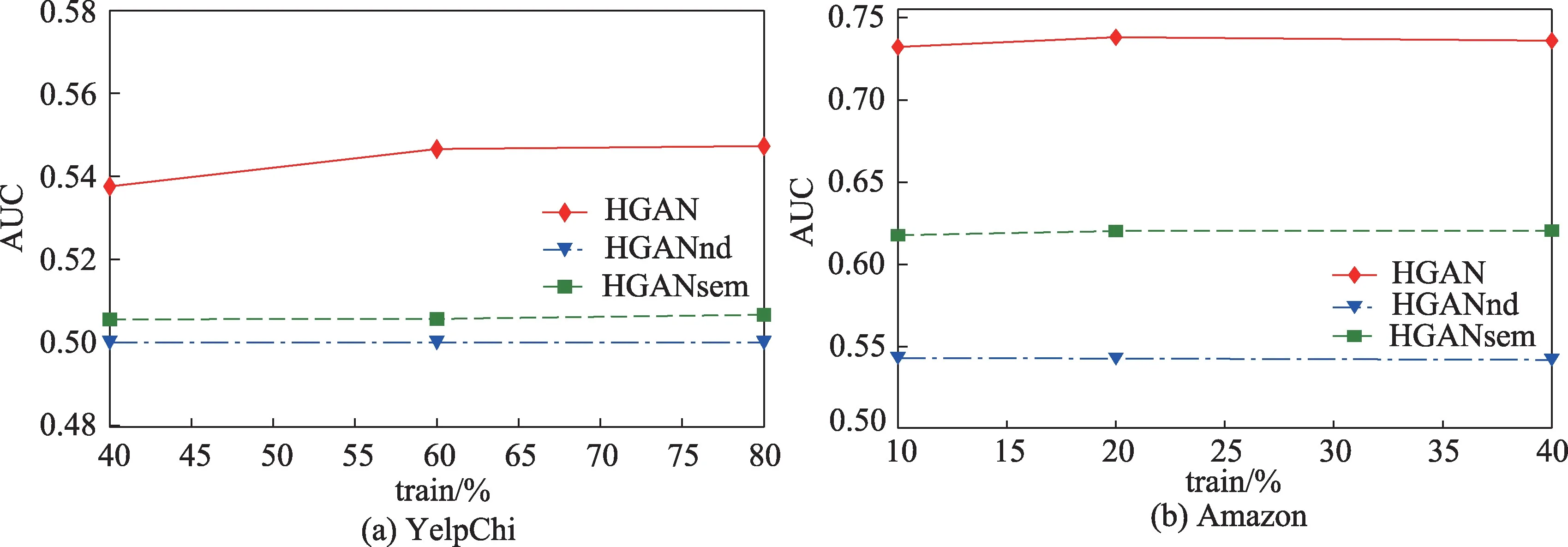
图10 HGAN 与其变体方法在YelpChi与Amazon 数据集上的AUC 值结果Fig.10 AUC result of HGAN and its variant methods on YelpChi and Amazon datasets
4.5 参数讨论
本节基于两个数据集上的实验,分别讨论了一些重要的超参数对基检测方法HGAN 以及集成检测方法En-HGAN 的影响。
(1)图11、图12 和图13 分别给出两个不同数据集的实验结果下网络中节点最终输出向量的维度l,语义融合层的注意力向量q的维数,以及GAT-layer中多头自注意力机制实施次数P这3 个参数对HGAN 识别虚假评论效果的影响。
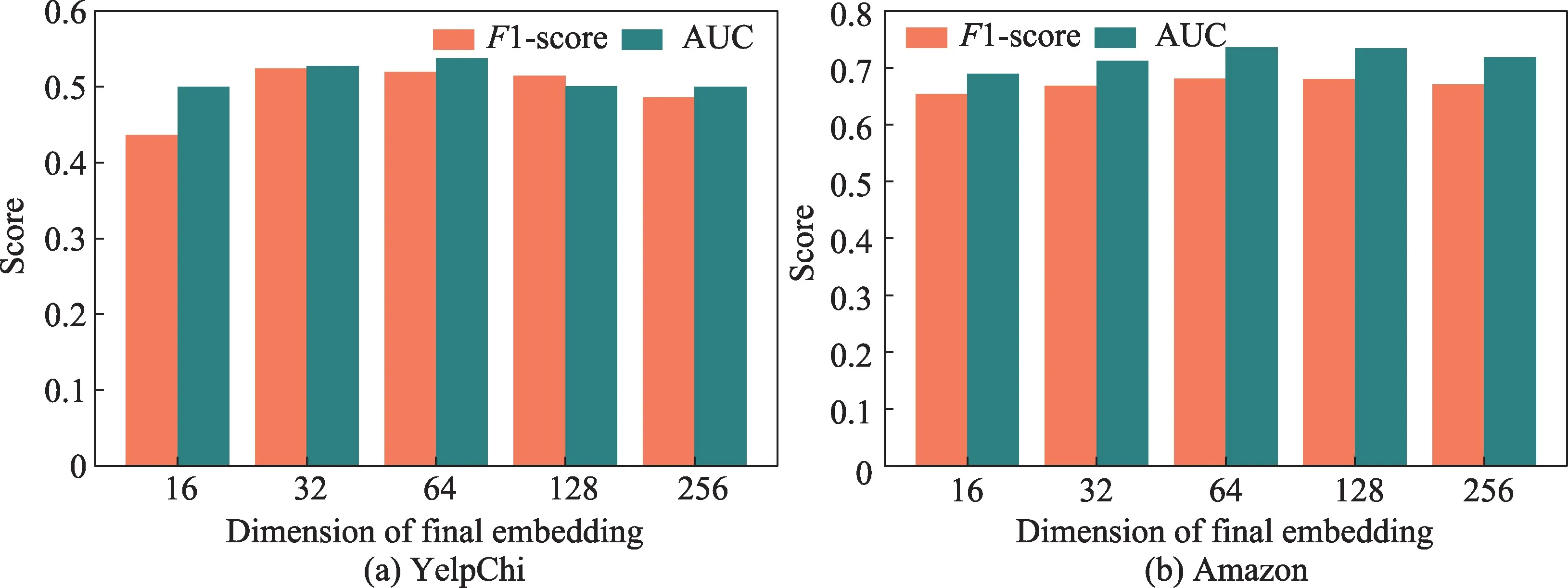
图11 l 对HGAN 方法的影响Fig.11 Effect of l on HGAN
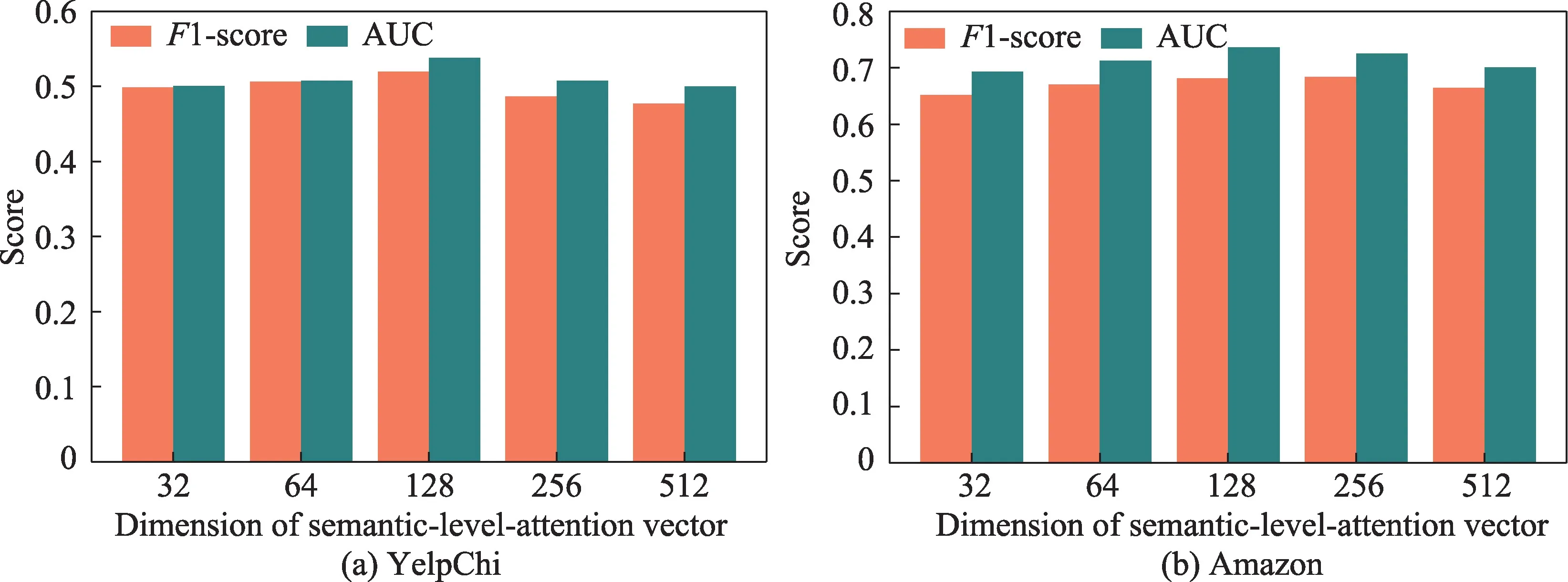
图12 q 对HGAN 方法的影响Fig.12 Effect of q on HGAN
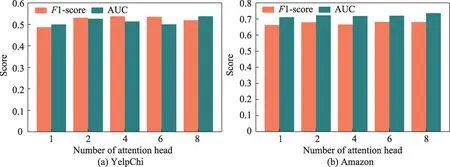
图13 P 对HGAN 方法的影响Fig.13 Effect of P on HGAN
图11(a)中,随着YelpChi 评论最终向量表示维度的增加,HGAN 的检测性能首先随之提升,然后开始缓慢下降;图11(b)中随着Amazon 用户输出表征维度的增加,HGAN 的检测性能也呈现先缓慢提升再下降的趋势,但总体变化并不明显。这表明一个合适的表征维数更有益于HGAN 编码多样的语义,维度过大的节点向量表示可能引入冗余信息。
图12 显示HGAN 对欺诈评论(用户)的检测效果随着语义层次注意力向量维度的增加而提升,并且在q的维数等于128 时达到最优,之后可能因为维度过大导致了过拟合使得模型性能逐渐降低。
图13 的结果显示多头注意力机制中P的值越大,HGAN 的性能会随之轻微波动着增长。
(2)将少数类样本设定为正例(positive),多数类样本设定为负例(negative)。图14 和图15 给出两个数据集的实验下基学习器个数k以及训练子集中正负样本比例(pos∶neg)对En-HGAN 检测性能的影响。
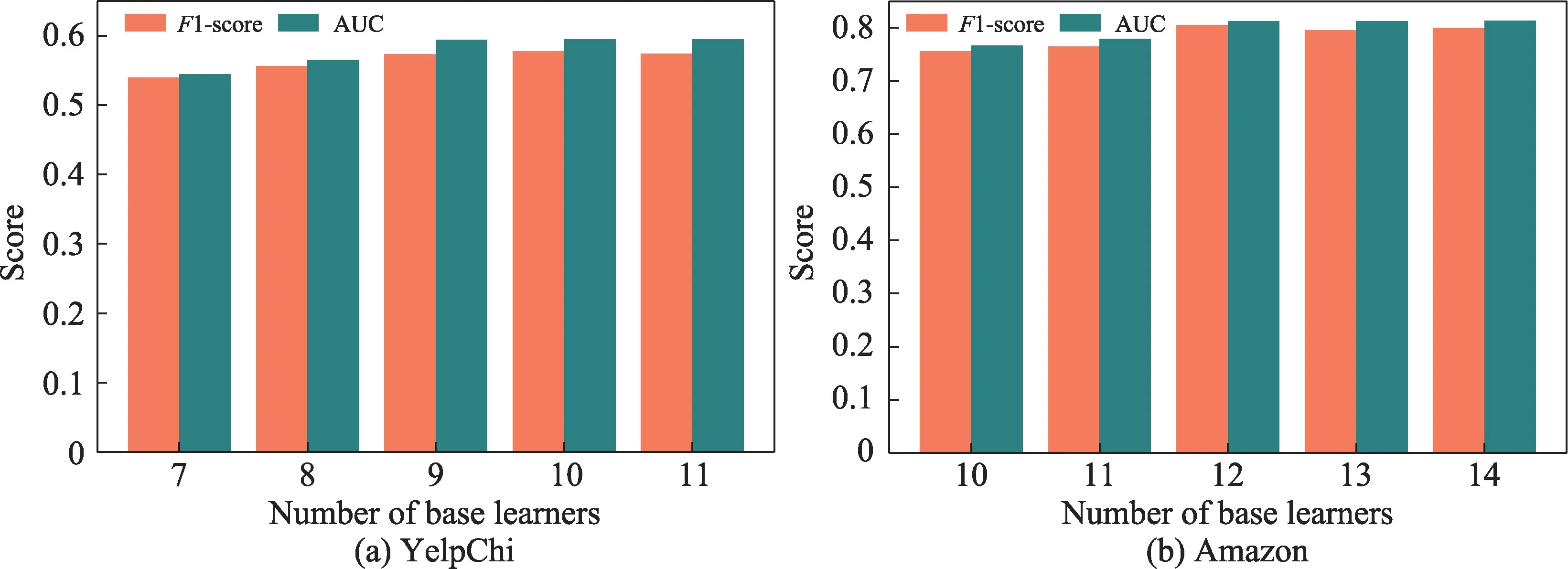
图14 k 对En-HGAN 方法的影响Fig.14 Effect of k on En-HGAN
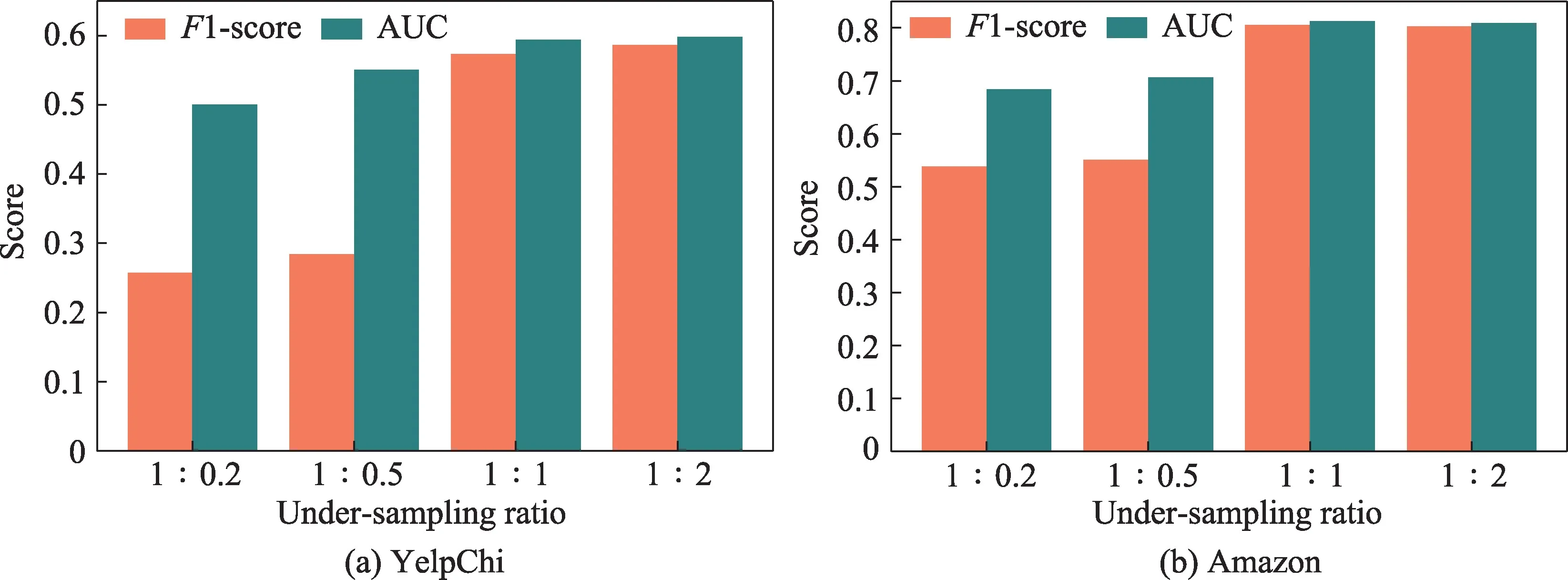
图15 pos∶neg 对En-HGAN 方法的影响Fig.15 Effect of pos∶neg on En-HGAN
图14(a)中,随着子模型个数k不断增大,直到等于9,En-HGAN 对YelpChi 数据集中不实评论的检测效果逐渐优化,但继续增加基学习器数量,模型性能没有进一步提升;图14(b)中,随着基学习器个数的增加,En-HGAN 对Amazon 数据集中欺诈用户的识别效果逐渐提升,并在k等于12 时达到最优,但k的值继续增大后检测性能没有明显变化。
图15 的结果显示训练子集中正例占比变大,En-HGAN 的检测效果却没有更优。pos∶neg 为1∶0.2、1∶0.5时可能由于子训练集中样本量较少和过拟合问题造成方法性能降低。
5 结束语
本文的集成层级图注意力网络En-HGAN 识别方法一方面利用层次化的注意力机制从异构网络中为评论(用户)节点学习语义更加丰富的向量表征,另一方面利用输入样本扰动集成多个差异化的HGAN 模型,实验结果表明传统的数据采样结合集成学习用于图神经网络模型做类别不均衡的节点分类任务是可行的。由于En-HGAN 方法没有进一步考虑数据子集中各类样本的质量,单纯地使用随机欠采样解决不同类实例在数量上的不均衡,未来可以采取更加灵活的动态采样方法构建更优质的均衡子训练集。另外,也可根据问题背景和数据分布等选择其他集成框架,比如Boosting 来挖掘异常特征和均衡检测结果。
猜你喜欢
眼科新进展(2023年9期)2023-08-31 07:18:36
眼科新进展(2022年12期)2022-12-29 06:00:50
新高考·高一数学(2022年3期)2022-04-28 07:02:46
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
中国外汇(2019年10期)2019-08-27 01:58:04
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
公民与法治(2016年24期)2016-05-17 04:21:39
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
