
基于重计算的深度学习加速器容错设计
2023-02-09 01:49王乾龙许达文
合肥工业大学学报(自然科学版) 2023年1期
王乾龙,许达文
(合肥工业大学 电子科学与应用物理学院,安徽 合肥 230601)
深度学习加速器(deep learning accelerator,DLA)作为一种专用于深度学习任务的ASIC设计,因为具有高性能、低功耗的特点,所以在可便携设备中大量部署,广泛应用于人工智能场景中。然而深度学习计算高度密集,每一层都包含复杂的卷积计算任务,给硬件实现带来一些难题。2D计算阵列因为能很好地处理矩阵乘法和卷积计算,所以在DLA中被广泛使用。比如谷歌的深度学习加速器TPU包含了规模为256×256大小的计算阵列,其中每个处理单元(processing element,PE)承担着复杂的卷积计算任务。
随着半导体技术变得越来越复杂,工艺偏差也可能使DLA制造过程中产生很多缺陷,一个严重的影响就是永久性故障的增加。一方面,在本文实验中,PE的错误会导致很多计算结果错误,错误偏差在神经网络任务执行期间不断累积,显著降低分类精度;另一方面,尽管可以在芯片制造后期测试过程中检测出故障,但丢弃每一个带有故障的芯片会显著降低良品率。因此对出现故障的芯片进行修复是维持芯片正常功能、减少生产商损失的重要手段。因为2D计算阵列承担着DLA的几乎全部计算任务,对神经网络任务的执行非常重要,所以本文主要关注对2D计算阵列中故障的修复。
研究人员在解决计算阵列中故障带来的影响时,通常有2种思路。第1种思路是通过硬件方法解决,早期的学者通常会删去故障所在的行或列,从而得到无故障的阵列。这类方法虽然简单,但是会带来严重的性能损失。后来研究人员提出利用冗余PE来替换阵列中的故障PE[1-2],但当故障分布不均匀时,这些方法也很容易失效。还有研究人员[3]采用统一的点乘单元作为冗余处理单元,并在进一步的工作中增加了分组的点乘单元与故障检测功能[4]。虽然故障修复效果较好,但是存储连续周期内所有进入阵列的数据需要额外的存储开销。第2种思路是通过软件方法来解决,一些学者针对故障计算阵列重新训练深度学习模型,虽然可以很好地维持模型的精度[5],但是模型重新训练的过程非常耗时,而且很难用于其他故障配置。总之,仍然缺少DLA的容错计算阵列架构、不能够在原始模型下运行并以较低的资源开销可以同时容忍各种故障配置。
为了解决这些问题,本文提出一种用于容错DLA的重计算结构(recomputing architecture,RCA)。与将同类冗余PE添加到计算阵列内部的工作不同,本文实现了计算阵列外基于冗余的重计算单元(recomputing unit,RCU)。RCU中的每个PE负责计算阵列中单个故障PE的重新计算,通过将故障重新计算所需的部分数据进行延迟,RCU在稍后的周期中将重新计算2D计算阵列中故障PE上的所有输出特征。当2D计算阵列中故障PE的数量不超过RCU大小时,RCA可以完全修复2D计算阵列。即使PE错误率进一步增加,RCA可以通过增加RCU的冗余规模,进一步提高容错能力,也可以选择修复出最大的计算阵列区域,减少性能损失。
1 相关工作
1.1 传统的冗余设计方法
早期的研究人员通常在计算阵列中添加冗余单元来减轻故障对阵列的影响。不同冗余设计方法中冗余的放置如图1所示。图 1a、图1b所示分别为行冗余(row redundancy,RR)和列冗余(column redundancy,CR)[1],它将冗余放置在阵列的一侧,其中的每个PE完成对一列或一行中故障的替换。图1c所示为对角线冗余(diagonal redundancy,DR)[2],它将冗余PE放置在阵列的对角线上,每个PE完成对一行和一列中故障的替换。阵列中的PE出现故障时,都能找到对应的冗余PE来替换,但是当一个区域中故障PE的数目多于其对应的冗余个数时,这些方法往往也无法完全恢复计算阵列。

图1 不同冗余设计方法中冗余的放置
1.2 阵列中故障对精度的影响
为了分析故障对计算阵列的影响,本文将随机位翻转故障注入32×16计算阵列中PE的寄存器中,实现用于故障分析的模拟器,并使用Mnist 数据集运行典型的手写数字分类任务,实验结果如图2所示。从图2可以看出,精度随着PE错误率的增加而大幅下降,表明错误PE的增加对预测准确率有着非常严重的影响。因此,对于关键任务应用程序来说,对计算阵列的保护十分有必要。
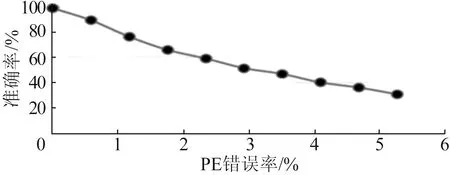
图2 不同PE错误率神经网络模型在DLA上的预测精度
2 用于容错DLA的重计算结构
2.1 RCA整体结构
为了修复2D计算阵列任意位置的故障,本文提出一种重计算结构(RCA),它具有由多个PE构成的重计算单元(RCU),可以一对一地进行2D计算阵列中任意位置故障PE的重新计算,并完成对错误结果的替换。具有RCA的DLA如图3所示。

图3 具有RCA的DLA
2D计算阵列大小为16×16,其中每个PE按给定的输出固定数据流[6]顺序地计算不同的输出特征。同一列的PE共用输入数据,权重则在不同列之间依次向右传递,输出特征的局部计算结果保存在PE本地。对于完成一个输出特征的计算,后一列结果的输出总是比前一列慢一个周期。而RCU需要同时并行地进行多个不同列中故障PE对应的输出特征的计算。因为RCU所需的输入数据储存在片上缓冲区多个地址中,并且增加多个读取端口会带来更多芯片面积开销,所以难以从片上缓冲区中获取RCU所需要的数据。
为了解决这一问题,本文延迟了重新计算,因为权重在计算阵列中依次向右传递,所以将延迟设置为从PE的第1列传输到最后一列所需要的16个周期。在重新计算的过程中,对于权重数据,RCU可以直接从最后一列的PE中进行读取。因为前一列PE总是比后一列PE早一个周期用到相同的权重,在权重向右传递的过程中,其对应的输入数据必须保留以进行接下来的重新计算,所以本文增加输入先入先出队列(first in first out,FIFO)来对输入数据进行存储以达到延迟读取的目的,输入FIFO采用多个深度依次递减的FIFO组成,以对不同PE列的输入数据进行对齐操作,确保RCU能够同时并行进行多个故障PE的计算。因为RCU中的每个PE都可以完成单个故障PE的所有操作,所以当故障PE的数目不超过RCU大小时,RCU总是可以完成映射到故障PE操作的重新计算。此外,RCA还有一个故障PE表来记录2D计算阵列中故障PE的坐标。RCU中的PE可以通过坐标选择对应于某个故障PE的权重和输入特征,从而进行重新计算。同时,这些坐标还可以指示地址生成单元确定写入输出缓冲区的地址,将重新计算的结果替换错误结果。此外RCU输出还有一个寄存器文件,用于存储RCU的计算结果以及将结果写入到输出缓冲区。
2.2 RCA的故障修复过程
本文以带有3个故障PE的16×16规模大小的2D计算阵列的RCA为例,来进一步说明RCA中的故障修复过程,其中RCU包括16个PE,RCA的故障修复过程如图4所示。

图4 RCA的故障修复过程
假设2D计算阵列的PE需要T周期才能产生完整的输出特征。从周期T开始,PE的第1列开始将输出特征写入到输出缓冲区。2D计算阵列将连续占用输出缓冲区16个周期,将16列的输出结果依次写入到输出缓冲区中。在整个过程中,RCU一直都在进行重新计算操作,由于RCU的重新计算只比最后一列慢了一个周期,接下来RCU将继续占用输出缓冲区。具体步骤如下:
(1) 在周期T时,2D计算阵列写入开始。PE的第1列将生成的输出特征写入到输出缓冲区,并开始计算新的输出特征。因为有3个PE出现故障,所以用深色来标记PE的错误计算结果。用于故障PE上的权重继续向右传递,输入特征则存储在输入FIFO中,经过FIFO的延迟之后它们会被读取到RCU中,以便进行重新计算。
(2) 在周期T+15时,2D计算阵列写入结束。RCU根据故障PE表中的故障PE的坐标,分别读取对应3个故障PE的输入特征和权重,并完成3个输出特征的计算。最终计算结果会被写入到输出寄存器中。
(3) 在周期T+16到周期T+18时,因为2D计算阵列中只有3个故障PE,所以需要3个周期才能将重新计算的结果从RCU中的寄存器写入到输出缓冲区。写入地址由AGU根据故障PE表中的坐标确定。并通过掩码的形式只更新错误的计算结果。因为T通常远大于16,所以有足够的时间来将重新计算的结果更新到输出缓冲区而不会发生写冲突。同时,RCU开始重新计算映射到2D计算阵列中的故障PE的最新输出特征,结果保存在PE本地。
(4) 从周期T+19到周期2T-1,RCU占用输出缓冲区结束。2D计算阵列和RCU都在进行新的输出特征计算,并将部分计算结果保存在本地,在计算出新的输出特征之前,输出缓冲区端口将处于空闲状态。
当2D计算阵列中的故障数目增加时,RCU可以通过增加冗余PE的数量以进一步提高RCA的故障修复能力。当故障PE的数量继续增加并超出RCA的容错极限时,本文放弃恢复完整计算阵列的目标,转为修复出一片可用的计算阵列区域。为了尽可能保留计算能力,本文选择从左到右进行故障修复以得到连续可用的计算阵列区域,并丢弃无法修复的故障PE列。在这项工作中,为了保留连续可用的计算阵列,RCA先修复最左侧的故障PE,将其坐标写入故障PE表里,按照之前讲述的故障修复过程就可以修复出一块可用的计算阵列区域。
2.3 RCU结构
RCU可以完成2D计算阵列中故障PE的重新计算,这就要求其能从多个输入和权重中选出对应于故障PE的数据,RCU结构如图5所示。
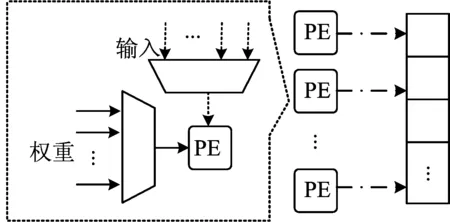
图5 RCU结构
由图5可知,RCU中的每个PE都是相互独立的,分别承担不同故障PE的重新计算任务。每个PE都对输入和权重增加了多路复用器。根据故障PE表里的坐标,故障PE重新计算所需的权重和输入特征将被选出,并在PE中进行重新计算。一段周期后,计算完成的输出特征将被保存在输出寄存器中,并在接下来的时间内写入到输出缓冲区替换错误的计算结果。
3 实 验
3.1 实验设置
(1) RCA配置。本文提出的带有RCA的深度学习加速器在Verilog中实现,并用TSMC 40 nm技术下的Design Compiler编译而成。所使用的权重和输入特征的数据宽度均为8 bit。除此之外,一些单元的配置信息见表1所列。

表1 RCA配置
(2) 故障模型。受到半导体制造工艺的影响,芯片制造过程中由于相同缺陷所导致的故障往往倾向于聚集在一起。因为不同的故障配置对实验结果的影响很大,为了增加实验的可靠性和说服力,所以本文在随机分布模型的基础上,增加了集群分布模型[7]。同时,为了降低故障分布对实验结果的影响,类似于文献[8]中的工作,本文采用PE错误率作为度量,对每个PE错误率随机生成10 000个错误配置,并对实验结果进行平均。
3.2 芯片面积开销比较
具有不同冗余方法的DLA的芯片面积如图6所示。

图6 不同冗余设计策略下的芯片面积
因为2D计算阵列为16×16规模大小,基于RR、CR、DR的传统设计中冗余PE数量相同,但是DR需要增加1倍的多路复用器来实现对一行PE和一列PE中的故障替换,所以需要消耗更多的芯片面积。与传统的冗余设计相比,基于RCA的设计展现出更少的冗余开销。虽然RCU在进行数据选择时也使用了一部分多路复用器,但在冗余PE相同的情况下,所用的多路复用器和寄存器文件的开销要小得多。
3.3 故障修复能力比较
本文用2个主要指标来评估不同冗余设计方法的故障修复能力,类似于文献[3-4]中的工作。其中一个指标是全功能概率,指的是完全修复2D计算阵列中所有故障的概率。因为RCU中一个冗余PE只能修复一个故障PE,所以当故障PE的数目超过RCU的容错能力时,全功能概率迅速降为0。基于不同冗余方法的DLA的全功能概率如图7所示。从图7可以看出,在相同的PE错误率下,RCA的全功能概率仍然要比其他3种冗余设计方法高得多。

图7 基于不同冗余方法的DLA的全功能概率
当冗余设计方法无法对所有故障进行修复时,剩余的计算能力是衡量故障修复策略是否有效的关键。标准化剩余计算能力指的是剩余可用计算阵列占原始阵列大小的百分比。具有不同冗余方法的DLA的标准化剩余计算能力如图8所示。


图8 具有不同冗余方法的DLA的标准化剩余计算能力
从图8可以看出,当故障数目超过16时,RCA在不能修复所有故障的情况下,仍表现出较高的剩余计算能力。这说明了RCA的故障修复更加灵活有效,而其他冗余设计的优化空间则很小。
3.4 可扩展性比较
不同的应用程序对DLA的性能要求不同。为了分析比较不同的冗余设计方法的可扩展性,本文设置了3种阵列规模来进行全功能概率实验,类似于文献[3]中的工作。为了公平比较,实验只对比了冗余数目随阵列规模同等比例扩展的RR和RCA。不同计算阵列大小上RCA和RR的可扩展性如图9所示。从图9可以看出,RCA在计算阵列扩展时,全功能概率几乎没有变化,表明RCA具有良好的可扩展性。相反,RR的全功能概率随着阵列大小的增加明显变差。同时,在计算阵列规模固定时,RCU的扩展可以修复更多的故障,可以预见到RCA的容错能力将与RCU的大小成正比,这一点本文不再赘述。
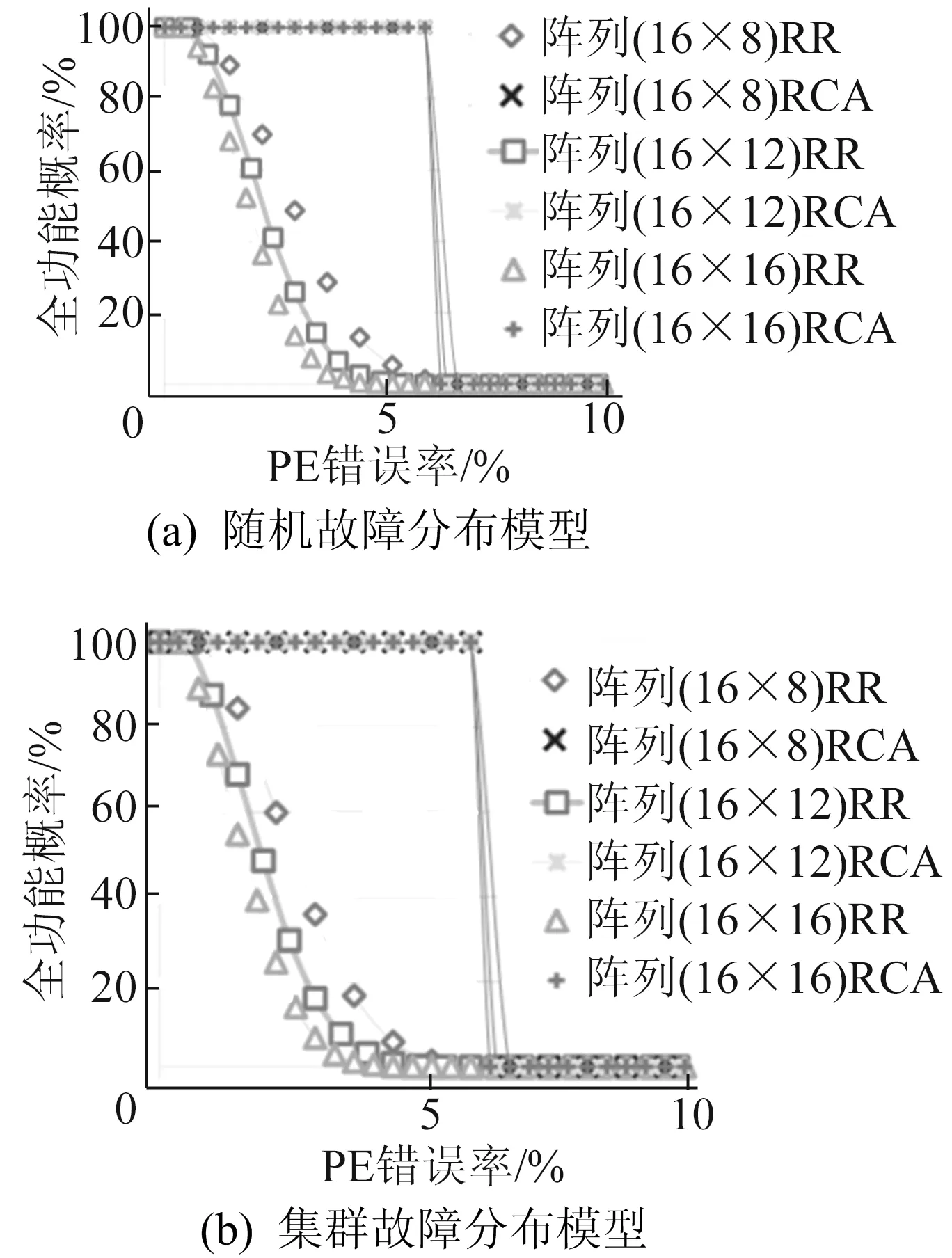
图9 不同计算阵列大小上RCA和RR的可扩展性
4 结 论
关键场景中的AI应用对DLA的可靠性要求很高。基于RR、CR、DR等常规阵列的冗余方法虽然能简单地修复一些故障,但是容易受到故障分配不均的影响,即使冗余资源充足往往也无法修复所有故障。针对这一问题,本文提出了重计算结构(RCA),与传统即时的故障修复策略不同,它有一组冗余PE组成的重计算单元(RCU),能够从阵列边缘获得流经故障PE的数据,利用冗余PE重新进行故障PE的计算,并在存储单元中替换错误的计算结果。当2D计算阵列中故障PE的数量不超过RCU大小时,RCA可以完全修复2D计算阵列。即使PE错误率进一步增加,RCA可以通过增加RCU的冗余规模,进一步提高容错能力,也可以选择修复出最大的计算阵列区域,减少性能损失。实验表明,RCA具有较高的可扩展性和较小的芯片面积开销,并在故障修复能力上大大优于之前的冗余方法。
猜你喜欢
家庭影院技术(2019年11期)2019-12-09
新课程·上旬(2019年1期)2019-03-18
课堂内外·教师版(2018年1期)2018-05-29
沈阳工业大学学报(2018年1期)2018-01-08
教师·中(2017年3期)2017-04-20
试题与研究·教学论坛(2016年27期)2016-08-11
中国工程机械学报(2016年5期)2016-03-07
项目管理技术(2015年3期)2015-04-23
时代人物(2014年10期)2015-01-28
教学研究与管理(2014年4期)2014-05-16
