
基于网络聚类与自适应概率的数据库缓冲区替换*
2018-01-08 06:28:11贺红艳李光明张慧萍
沈阳工业大学学报 2018年1期
贺红艳,李光明,张慧萍
(湖北工业大学 工程技术学院,武汉 430068)
基于网络聚类与自适应概率的数据库缓冲区替换*
贺红艳,李光明,张慧萍
(湖北工业大学 工程技术学院,武汉 430068)
针对传统替换方法存在替换不准确、效率低的问题,提出模糊kohonen网络聚类算法与自适应概率相结合的大型数据库缓冲区替换方法.采用Broder理论并基于Jaccard相似性度量对缓冲区重复数据进行消除,建立缓冲区数据检测模型,并采用模糊kohonen网络聚类算法对缓冲区数据进行聚类处理.采用复小波法提取缓冲区的特征,引入自适应概率对大型数据库缓冲区进行替换.结果表明,改进的缓冲区替换方法可有效的实现对大型数据库缓冲区的替换,提高替换效率,增加大型数据库存储的整体性能.
大型数据库;缓冲区;替换方法;改进;特征;网络聚类;自适应概率;数据存储
随着科学技术飞速发展,计算机得到了广泛使用,其中计算机数据存储问题成为计算机正常运行的关键,数据库技术应运而生[1-2].由于存储数据规模的不断增加,以往的小型数据库以无法满足数据存储的需求,从而出现了大型数据库[3-4].缓冲区是计算机最重要的组成部分之一,广泛应用于数据库中,对缓冲区进行替换,可优化I/O序列,减少用户访问次数,优化存储性能,提高使用效率[5-6].如何对大型数据库缓冲区进行替换成为了该领域研究的热点,受到了广大学者的关注.
文献[7]提出基于网络优化的大型数据库缓冲区替换方法,该方法通过一种基于网格边长伸展的参数化方法对大型数据库缓冲区进行优化,求得目标替换数据,实现缓冲区的快速替换;文献[8]提出基于OpenGL Performer的大型数据库缓冲区替换方法,在3DMax中提取出特定缓冲区的替换特征,并使用递归遍历方法减少缓冲区存在的缺陷,实现缓冲区替换,但该方法存在一定的替换误差;文献[9]提出基于支持补偿的大型数据缓冲区替换方法,该方法充分考虑在大型数据库缓冲区进行替换时对缓冲区数据造成的影响,为其进行补充,提高替换效率,但是数据替换响应较慢,不适合快速存取的情况.
针对上述问题,本文提出模糊kohonen网络聚类算法与自适应概率相结合的大型数据库缓冲区替换方法.通过Broder理论并基于Jaccard相似性度量,对缓冲区重复数据进行消除,建立了缓冲区数据检测模型,并以此为基础,采用模糊kohonen网络聚类算法对缓冲区数据进行聚类处理,引入自适应概率实现对大型数据库缓冲区的替换.根据实验结果可知,改进的缓冲区替换方法可有效实现对大型数据库缓冲区的替换,提高了替换效率.
1 重复数据消除及检测模型的建立
1.1 重复数据消除
重复数据消除也叫容量优化技术或者智能压缩,是一种经过自动搜索并检测重复数据,只保留冗余数据唯一一个物理存储的算法.重复数据消除使重复副本被指向单一存储的指针所替换,可达到消除冗余数据(即重复数据),降低数据中心存储及传输压力的目的.将损失的数据量定义为
loss=wOsize
(1)
式中:w为缓冲区数据的共享度;Osize为缓冲区数据的大小.
缓冲区数据的共享度w越高,重复数据消除操作的数据缩减比率越大,相应的缓冲区数据因丢失引起的数据损失量也越大.由于重复数据消除时需要通过消除数据冗余来节省存储空间,因此,为了提高数据可靠性,需要降低数据冗余度和数据可靠性.假设每一个缓冲区数据的副本数目k是一个关于缓冲区数据共享度w的函数,则其数据表达式为
k=min(max(2,a+blog2w),kmaxloss)
(2)
式中:a和b为空间使用率及鲁棒性,通常为常数;kmax为缓冲区最大数据副本数阈值.由式(2)可知,每个缓冲区数据至少维持两个副本,最多不超过kmax个副本,缓冲区数据的副本数和共享度的对数成线性关系.假设有一个安全性函数H产生的缓冲区数据长度为β,存储空间为Θ,则Θ共包含2β个不同的数据特征.Ω为不同缓冲数据块组成的集合,基于哈希算法得到指纹并进行匹配,则缓冲区数据分配函数表示为

(3)
当M⊂Ω,为缓冲区数据块的集合时,则缓冲区数据发生的索引表达式为
L=Pr(h(A)=h(B),∃A,B∈M)
(4)
式中,h(A)和h(B)分别为数据A和B在缓冲区出现的次数.假设缓冲区中有q个不一样的数据块(D1,D2,…,Dq)是依据顺数串存储到缓冲区的,并假设副本分布区数据ej(j=1,2,…,q)与前面存储的数据发生碰撞时,写入新的数据,并重新再磁盘上进行分布,则分布表达式为

(5)
式中,s为缓冲区分布系数.本文使用数据内容而非数据位置来消除缓冲区重复数据,假设有两个数据集合S1、S2,则进行重复数据消除后,缓冲区数据分配函数为
Pr(S)=[minh(S1)+minh(S2)]=
(6)
由式(6)可知,若S1和S2具有很高的相似度,则h(S1),h(S2)里最小元素相同的概率也很高,即对缓冲区重复数据进行消除的效果越好.重复数据消除策略结构图如图1所示.

图1 重复数据消除策略结构Fig.1 Structure of strategy for eliminating repeated data
1.2 数据检测模型的建立
在对缓冲区重复数据消除的基础上,需对缓冲区数据进行检测,建立缓冲区数据检测模型,详细的建模步骤如下:
1) 选取一个正确的缓冲区数据样本为Y={Y1,Y2,…,YN},其中,缓冲区数据样本中含有样本数为N,每个样本向量是一个p维矢量,设定缓冲区数据样本初始值c(1≤c≤N)和数据样本特征距离(即欧式距离).
2) 在设定环境后,初始化检测缓冲区数据中心向量Z=(Z1,Z2,…,Zc),在中心向量集合中每个向量同样是p维矢量.另外初始化检测次数T=0,最大检测次数为Tmax,令隶属度初始加权幂指数为K0(K0>1),设定迭代的终止误差为ε>0.
3) 计算输入时各个缓冲区数据样本属于第i(2≤i≤c)类的隶属度,其计算式为

(7)
式中:τ为均值常数;Yk为缓冲区数据样本总体特征;Zi,Zj分别为缓冲区数据样本i和j的特征.
隶属度rik计算完成后,利用此隶属度计算权值迭代更新检测率,即

(8)
λ=K0-T(K0-1)/Tmax
(9)
当T=Tmax时,λ=1.
4) 调整缓冲区数据样本中心向量,依据前一次的特征量和检测率对缓冲区数据进行检测,检测式为

(10)
通过上述检测可以看出,检测结果主要依赖输入向量和不断检测更新的检测率.假如输入模式里有一个样本属于某一类隶属度的可能性比较大,则这类输入模式向量对缓冲区数据样本中心向量检测的影响就更大,符合实际情况.
5) 在对缓冲区数据进行检测后,采用加权平均的方法建立缓冲区数据检测模型,模型计算式为
(11)
式中:cur_t为检测缓冲区数据所需时间;rec_t为申请检测所需时间;exp_t为预计执行该检测任务所持续的时间;ω,γ均为可调常数.中心向量则需要满足

(12)
当检测次数大于初始设定的最大检测次数Tmax,则会导致检测终止.
2 数据库缓冲区替换方法
在进行大型数据库缓冲区数据检测的基础上,采用模糊kohonen网络聚类算法对缓冲区数据进行聚类处理,再引入自适应概率法对缓冲区进行替换.假设X=(x1,x2,…,xn)为包含n个数据对象的缓冲区数据集,每个缓冲区数据对象具有m个属性,用A1,A2,…,Am表示,数据对象xi可表示成[xi1,xi2,…,xim].通过最小化特定目标成本函数将缓冲区数据集X进行划分,划分式为

(13)
式中:uil为划分缓冲区数据矩阵Un×k的元素,表示缓冲区数据对象i是否属于第l个簇;Qlj为属性j在簇l里的中心数据;d(·)为计算缓冲区数据对象间或数据对象和簇中心间的距离函数;sj为属性j的权重值,权重值满足

(14)
式中,Dj为属性j的簇内距离和.由式(14)可知,对簇内距离之和小的缓冲区数据属性,需要分配一个大的属性权重值;反之,则需分配一个小的属性权重值.特定的目标函数表达式为

(15)
假如缓冲区数据对象i属于簇l,则uil为1,反之为0.采用模糊kohonen网络聚类算法对缓冲区数据进行聚类,计算式表示为
(16)
(17)
式中,G(n)为复小波法提取的缓冲区特征.
综上所述,采用模糊kohonen网络聚类算法对缓冲区数据进行聚类处理,利用复小波法提取缓冲区的特征,并以此为基础引入自适应概率,可实现对大型数据库缓冲区数据的高效替换.
3 实验结果分析
为了验证改进的大型数据库缓冲区替换方法的有效性及可行性,采用实验进行分析.实验的硬件环境为Intel(R)Core(TM)i6-10GHzCPU和4GBitDDR2内存,操作系统为Windows7,并在Flash-DBSim平台上进行操作.采用的参数配置模拟器为一个128Mbit的NAND固态盘,其详细参数如表1所示.

表1 NAND固态盘特性参数Tab.1 Characteristic parameters for NADA solid state disk
在缓冲区容量一定的情况下,将改进方法与基于网络优化的大型数据库缓冲区替换方法、基于支持补偿的大型数据缓冲区替换方法进行命中率方面对比实验分析.参照文献[9]中命中率的计算方法得到不同算法替换大型数据缓冲区的命中率,结果如图2所示.
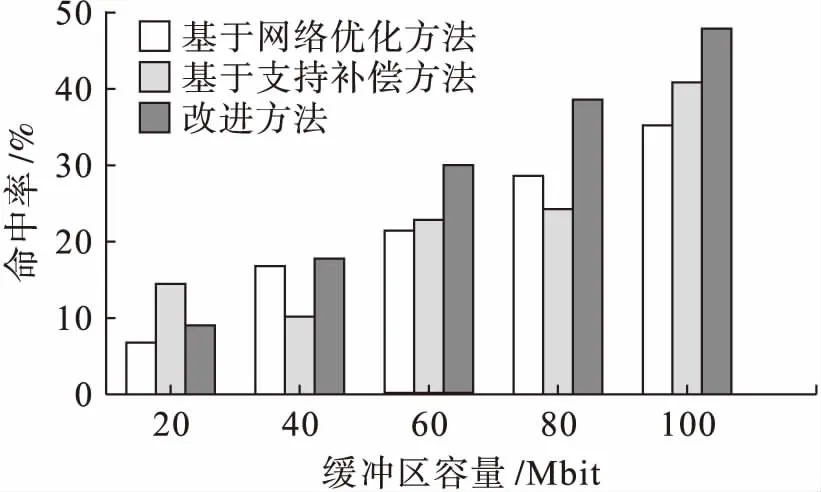
图2 不同算法的命中率比较Fig.2 Comparison in hit rate between different algorithms
由图2可知,采用基于网络优化方法时,其命中率会随着缓冲容量的增加而增加,但其命中率相对较低;采用基于支持补偿方法时,其随着缓冲区容量的增加,命中率会相应出现波动,稳定性较差;采用改进的替换方法时,其命中率随着缓冲区容量的增加而增加,稳定性较好,而且其命中率相比其他两种算法均有所提高.
为了进一步验证改进方法的有效性,在缓冲区容量一定的情况下,将改进方法与基于网络优化的大型数据库缓冲区替换方法、基于支持补偿的大型数据缓冲区替换方法进行运行时间方面的对比实验,结果如图3所示.

图3 不同算法的运行时间对比Fig.3 Comparison in running time between different algorithms
由图3可知,3种方法的运行时间均随缓冲区容量的增加而减少,但采用改进的替换方法时,其平均运行时间约为2 s,且到50 Mbit后算法的运行时间趋于稳定,是3种算法中运行时间最少的、数据处理效率最好的.
4 结 论
针对传统替换方法存在替换不准确、效率低的问题,提出模糊kohonen网络聚类算法与自适应概率相结合的大型数据库缓冲区替换方法.采用Broder理论并基于Jaccard相似性对缓冲区重复数据进行消除,建立缓冲区数据检测模型,并以此为基础,采用模糊kohonen网络聚类算法对缓冲区数据进行聚类处理.采用复小波法提取缓冲区的特征引入自适应概率,实现对大型数据库缓冲区的替换.根据实验结果可知,采用改进的缓冲区替换方法可有效实现对大型数据库缓冲区的替换,提高替换效率,增加大型数据库存储的整体性能.
[1] Xiao J,Ehinger K A,Hays J.Exploring a large collection of scene categories [J].International Journal of Computer Vision,2016,119(1):3-22.
[2] 敖建华.基于闪存的数据库缓冲区替换算法优化研究 [J].电脑知识与技术,2014(20):4631-4633.
(AO Jian-hua.Research on optimization of database buffer replacement algorithm based on flash memory [J].Computer Knowledge and Technology,2014(20):4631-4633.)
[3] Cao C,Weng Y,Zhou S,et al.A 3D facial expression database for visual computing [J].IEEE Transactions on Visualization & Computer Graphics,2014,20(3):413-425.
[4] 徐旭,刘伟.线目标缓冲区生成的矢栅混合算法研究 [J].计算机工程与应用,2014,50(4):152-156.
(XU Xu,LIU Wei.Research on vector-raster mixed algorithm of linear buffer generation [J].Computer Engineering and Applications,2014,50(4):152-156.)
[5] 鹿婷婷,鹿璐.基于分区替换概率的闪存数据库缓冲区自适应替换算法 [J].网络安全技术与应用,2014(11):152-155.
(LU Ting-ting,LU Lu.Based on adaptive probability of flash database partition to replace buffer replacement algorithm [J].Network Security Technology & Application,2014(11):152-155.)
[6] 任艳.微信息大数据粗糙集的近似约简 [J].沈阳工业大学学报,2016,38(3):122-125.
(REN Yan.Approximate reduction of micro-message big data rough set [J].Journal of Shenyang University of Technology,2016,38(3):122-125.)
[7] 孙新轩,吕蓬,李磊.利用最小二乘法检测缓冲区海岸线变化研究 [J].信息工程大学学报,2014,15(1):12-16.
(SUN Xin-xuan,LÜ Peng,LI Lei.Research on detecting buffer shoreline using the least squares method [J].Journal of Information Engineering University,2014,15(1):12-16.)
[8] 杜田田,李芳,武超然.求解有限缓冲区流水线调度问题的混合蝙蝠算法 [J].计算机应用与软件,2015(6):232-235.
(DU Tian-tian,LI Fang,WU Chao-ran.Hybrid bat algorithm for solving permutation flow-shop scheduling problem with limited buffers [J].Computer Applications and Software,2015(6):232-235.)
[9] 林子雨,赖明星,邹权,等.基于替换概率的闪存数据库缓冲区替换算法 [J].计算机学报,2013,36(8):1568-1581.
(LIN Zi-yu,LAI Ming-xing,ZOU Quan,et al.Probability-based buffer replacement algorithm for flash-based databases [J].Chinese Journal of Computers,2013,36(8):1568-1581.)
Databasebufferreplacementbasedonnetworkclusteringandadaptiveprobability
HE Hong-yan, LI Guang-ming, ZHANG Hui-ping
(Engineering and Technology College, Hubei University of Technology, Wuhan 430068, China)
Aiming at the inaccurate replacement and low efficiency existing in the traditional replacement method, a large database buffer replacement method in combination with both fuzzy kohonen network clustering algorithm and adaptive probability was proposed.Through adoptingBroder theory and based on Jaccard similarity measurement, the repeated data in the buffer were eliminated, and the buffer data detection model was established.In addition, the buffer data were clustered with the fuzzykohonen clustering algorithm.The buffer features were extracted with the complex wavelet method, and the adaptive probability was introduced to replace the large database buffer.The results show that the improved buffer replacement method can effectively realize the replacement of large database buffer, increase the replacement efficiency, and enhance the overall performance of large database storage.
large database; buffer; replacement method; improvement; feature; network clustering; adaptive probability; data storage
2016-08-14.
湖北省教育厅科研计划资助项目(2014277);湖北工业大学工程技术学院项目(X201328).
贺红艳(1978-),女,湖北武汉人,讲师,硕士,主要从事计算机应用技术等方面的研究.
* 本文已于2017-10-25 21∶12在中国知网优先数字出版.网络出版地址:http://kns.cnki.net/kcms/detail/21.1189.T.20171025.2112.012.html
10.7688/j.issn.1000-1646.2018.01.12
TP 311
A
1000-1646(2018)01-0065-05
景 勇 英文审校:尹淑英)
猜你喜欢
北京工业职业技术学院学报(2024年1期)2024-01-14 06:35:14
中国生殖健康(2019年11期)2019-01-07 01:27:44
长江丛刊(2018年31期)2018-12-05 06:34:20
电子测试(2017年15期)2017-12-18 07:19:27
NBA特刊(2017年8期)2017-06-05 15:00:13
智能系统学报(2015年4期)2015-12-27 09:38:39
项目管理技术(2015年3期)2015-04-23 08:44:29
梧州学院学报(2015年3期)2015-02-28 17:55:16
电子设计工程(2015年6期)2015-02-27 12:04:53
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
