
基于嵌入式平台的车前红外行人检测方法研究*
2023-01-31 02:09:54张良李鑫赵晓敏蒋瑞洋张国栋
汽车技术 2023年1期
张良 李鑫 赵晓敏 蒋瑞洋 张国栋
(合肥工业大学,合肥 230009)
主题词:目标检测 红外图像 开源推理加速库 注意力机制 Jetson TX2平台
1 前言
当前,无人驾驶技术发展迅猛,保障行人的安全是无人驾驶领域的重要研究内容。目前,针对可见光图像的深度学习目标检测算法已取得丰硕的成果[1-3],但是可见光技术依赖于良好的光照条件,在夜晚、昏暗隧道或光照过强等场景下,可见光技术应用效果较差,甚至不能应用。红外行人检测技术基于物体自身热辐射和反射成像原理,受光照条件影响小,可以全天候工作,因此在无人驾驶领域具有重要的研究和应用价值[4]。
近年来,随着行人检测技术的日趋成熟和计算机硬件的快速发展,实时行人检测的应用场景逐渐增加,将行人检测模型部署在移动终端已经成为一大趋势。但由于行人检测任务的复杂性,行人检测模型往往有很多参数,计算量大,对于内存、存储容量和计算能力均有限的嵌入式设备来说,很难满足行人检测的实时性要求。因此,平衡行人检测模型的检测速度和准确性,并将其高效地部署到嵌入式设备中,是当前的热门研究方向[5-6]。文献[7]将改进的YOLOv3 模型应用于嵌入式平台,然后进行红外人体检测,平均准确率相较于YOLOv3模型提高3.26%,检测速度达到16帧/s;文献[8]对YOLOv4模型进行剪枝以降低模型复杂度,并部署于嵌入式平台,达到了75.60%的红外行人识别准确率。现有研究虽实现了神经网络在嵌入式平台上的部署,但总体而言,其模型参数量依然较为庞大,识别速度和准确率仍有待提高。
本文提出2 种基于嵌入式平台的车前红外行人检测方法,旨在达到检测速度和平均准确率的良好平衡:使用推理加速库TensorRT 优化轻量化网络YOLOv4-tiny[9],提高推理速度;以YOLOv4-tiny 模型作为算法的基本框架,结合空间金字塔池化(Spatial Pyramid Pooling,SPP)模块、卷积块注意模块(Convolutional Block Attention Module,CBAM)和3 个检测层(3 Layer,3L),提升其平均准确率。最后均部署于Jetson TX2嵌入式平台,验证所提出方法的有效性。
2 方法原理
本文提出2 种车前红外行人检测方法:一是利用TensorRT推理加速原理,对YOLOv4-tiny网络模型进行推理加速,然后进行行人检测;二是使用YOLOv4-tiny+3L+SPP+CBAM(本文称为YOLOv4-tiny-I)网络模型检测行人。
2.1 YOLOv4-tiny网络架构
YOLOv4-tiny 是YOLOv4作者[10]在其开源程序中提供的YOLOv4 的简化版本,降低了模型对硬件的要求,适合部署于移动端或嵌入式端,其网络结构如图1 所示。其骨干网络(CSPDarkNet53_Tiny)包含CBL(Conv+BN+LeakyRelu)模块和跨阶段残差结构(Cross Stage Partial,CSP)模块,CBL模块的构成为卷积层(Conv)、批归一化处理层(Batch Normalization,BN)、激活层(采用LeakyRelu 激活函数);CSP 模块的构成为4 个CBL 层和1 个最大池化(Maxpool)层。骨干网络用来进行特征提取,特征提取网络末端使用2个特征层进行分类与位置回归预测;利用特征金字塔思想[11]对相邻尺度的特征图通过串联操作进行特征融合,输出2 个检测头(Yolo Head)。
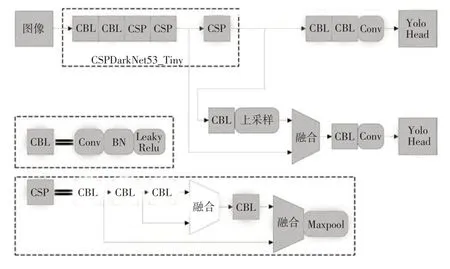
图1 YOLOv4-tiny网络结构
2.2 TensorRT推理加速原理
TensorRT是英伟达(NVIDIA)公司提出的用于推理的加速计算库,其凭借对网络结构的重构、操作的合并和网络量化等优化方法实现高效的推理过程,其优化推理引擎只有前向传播。TensorRT 能将所支持的深度学习网络模型进行解析,并将解析后的网络模型结构与TensorRT自身结构进行一一映射[12],之后便可将深度学习网络模型转移到TensorRT引擎中,以加速模型部署。
深度学习网络往往层数较多,在模型部署推理时,GPU 需启动不同的CUDA 核心对每个层进行运算,CUDA 核心虽有很强的计算能力,但数据的读写和CUDA 核心的启动极为耗时,导致大量GPU 资源浪费。TensorRT 通过对层间的纵向合并(将卷积Conv、偏置Bias 和激活函数ReLU 合并成CBR 层)、横向合并来减少模型层数,以便占用更少的CUDA 核心来完成相同的运算[13]。TensorRT合并具体操作如图2所示。

图2 TensorRT合并策略
2.3 YOLOv4-tiny-I网络结构
YOLOv4-tiny 使用了13×13 和26×26 这2 种不同尺度的特征图来预测检测结果。由于行人形态姿势不固定、行人所处环境复杂多变,会存在目标被部分遮挡和目标较小的情况,此时仅使用2 种尺度特征图进行目标检测易产生对遮挡目标和较小目标的识别率较低的情况。为了更好地检测行人,本文所提出的网络模型YOLOv4-tiny-I 使用19×19、38×38 和76×76 这3 种尺度特征图来预测检测结果,使用3种尺度不仅可提升检测范围,还能提供更丰富的浅层特征信息,进而能更好地将低层的特征和高层的特征融合起来进行多尺度图像预测。YOLOv4-tiny-I网络结构如图3所示。

图3 YOLOv4-tiny-I网络结构
He 等[14]为了解决在一般卷积神经网络结构中输入网络的图片大小必须固定的问题,提出了空间金字塔池化思想,该思想使用多级大小空间窗口对输入特征层进行多尺度池化并融合,从而能够对以任意大小输入的图像产生相同尺度的输出。借鉴He 等人提出的思想,本文使用如图3中所示的空间金字塔池化SPP模块,通过大小分别为5×5、9×9 和13×13 的池化窗口对特征图进行池化,将多尺度特征进行融合,从而丰富语义信息。由于特征图在深层网络中空间信息较少,而SPP模块可以提取物体不同范围的全局特征和局部特征,将这些特征信息融合后便可以丰富深层特征图上的空间信息。骨干网络之后是特征图空间信息较少的位置,在此处增加SPP模块能够使特征图空间信息增多,有助于提高不同尺度红外行人的识别和定位能力。故YOLOv4-tiny-I模型在骨干网络后增加SPP模块。
CBAM由Woo等[15]于2018年提出,该模块由通道注意力模块(Channel Attention Module,CAM)和空间注意力模块(Spatial Attention Module,SAM)构成,如图4 所示。CBAM通过学习的方式,在目标检测网络的特征通道维度及特征空间维度计算原始特征图的注意力权重图,然后将注意力权重图赋予原始特征图,从而使网络重点关注目标区域。在实际红外行人检测识别过程中,行人背景包含大量混淆信息,现有的网络往往无法将其剔除,导致训练后得到的权重信息中掺杂大量的混淆信息,影响检测性能。因此,模型YOLOv4-tiny-I 在增添SPP模块的基础上,引入CBAM模块来关注重点特征并抑制非必要特征。CBAM 的CAM 模块对通道进行重新加权、SAM针对特征图上每个像素进行加权,高阶特征引导低阶特征进行通道注意力获取,低阶特征反向指导高阶特征进行空间注意力筛选,从而使得网络特征图中有目标物体的区域权重提高,进而提高网络检测精度。YOLOv4-tiny-I 模型在3 个检测头之前引入CBAM 模块,可以避免背景像素对检测头的干扰,同时能够使网络具备对不同级别特征图进行信息整合的能力。
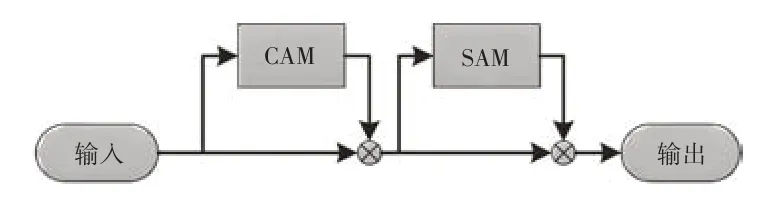
图4 CBAM注意力模块
3 试验验证
为了评估本文提出的2种红外行人检测方法,设计了相关试验进行验证。
3.1 环境配置及训练参数
在本文所有试验中,网络模型均在Google Colab 云服务器进行训练,训练好的模型均部署于NVIDIA 的嵌入式开发板Jetson TX2 上进行测试,TX2 设备如图5 所示。试验基于Darknet框架进行。平台的相关参数如表1所示。
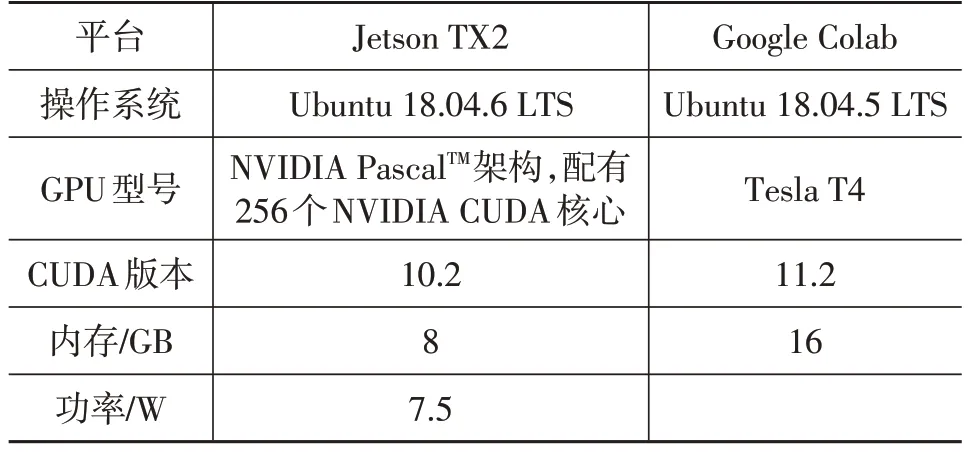
表1 平台参数

图5 Jetson TX2设备
训练网络模型时,采用的训练超参数均保持一致。输入批量大小Batch 设置为64,初始化学习率为0.001,梯度下降动量参数设置为0.9,权重衰减正则项系数设置为0.000 5。
3.2 数据集与锚框
试验采用菲力尔(FLIR)公司于2018年7月发布的公开红外数据集[16]。该数据集采集地点为美国加利福尼亚州圣巴巴拉市的街道和公路上,时间为11 月至次年5 月期间的日间(60%)和夜间(40%),采用红外热像仪进行采集,红外分辨率为640×512。FLIR数据集文件包含3个文件夹train、val、video,类别包含人、汽车、自行车、狗和其他,对train、val 文件夹进行处理筛选出包含行人类别的图片共7 044 张,将其按照5∶1 的比例划分为训练集和测试集。划分后的部分FLIR 数据集如图6所示。

图6 FLIR红外数据集
使用K-means++聚类算法得到各模型的先验框尺寸:YOLOv4-tiny 模型的为(11,19)、(14,32)、(19,51)、(29,74)、(46,122)、(78,196);YOLOv4-tiny-I 模型的为(11,23)、(13,37)、(15,50)、(17,65)、(21,82)、(22,48)、(28,80)、(36,120)、(61,201)。
3.3 评价指标
在车辆前方红外行人的检测中,需要考虑网络的检测准确率与实时性。本文选取平均准确率(mean Average Precision,mAP)和帧率作为红外行人检测的评价指标。mAP 与准确率(Precision)P、召回率(Recall)R有关,相关计算公式为:


式中,T为被正确划分到正样本的数量;F为被错误划分到正样本的数量;N为被错误划分到负样本的数量;M为类别总数,本文仅检测行人,故取M=1;A(k)为第k类的平均准确率。
3.4 试验结果
YOLOv4-tiny 模型在检测时会将输入图片进行尺寸标准化,输入尺寸设置越大,平均准确率越高,但检测速度会下降。为了选择合适的图片输入尺寸,设置了对比试验,如表2 所示。以输入尺寸608×608 为基准,输入尺寸高于该基准时帧率下降较多,对检测实时性不利;输入尺寸低于该基准时平均准确率较低,对精准检测不利。综合检测精度和速度,当输入尺寸设置为608×608时,网络检测精度较高且检测速度也较快。因此选定图像输入尺寸为608×608。

表2 图片输入尺寸对检测性能的影响
为了测试与YOLOv4-tiny 网络结合的每个模块对红外行人检测的影响,设置了对比试验,并将原始FLIR数据集video文件夹下的图片转成视频文件用于评估网络模型。试验结果如表3所示。由表3可以看出:
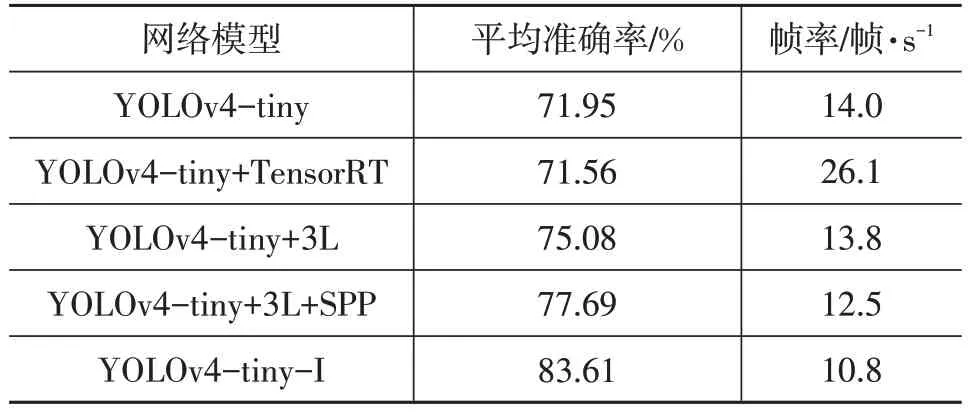
表3 嵌入式模型部署对比结果
a.相较于原始网络YOLOv4-tiny,模型YOLOv4-tiny+TensorRT 的准确率降低了0.54%,这是由于TensorRT 在推理加速时采用了半精度加速推理策略对网络权重进行量化所导致的[17],但模型YOLOv4-tiny+TensorRT 的推理速度提升了86.43%,达到26.1 帧/s,做到了实时检测;
b.模型YOLOv4-tiny+3L增加了1个YOLO 层,该YOLO 层结构不复杂,故帧率相较于YOLOv4-tiny 仅下降1.43%,平均准确率相较于YOLOv4-tiny 增加4.35%,说明增加1个YOLO层能够有效改善模型检测性能;
c.在增加1 个YOLO 层的基础上再增加SPP 模块,帧率小幅下降,平均准确率相较于YOLOv4-tiny+3L增加3.48%,说明SPP 模块有效地丰富了深层特征图上的空间信息,提升了网络检测准确率;
d.本文所提出的YOLOv4-tiny-I模型在YOLOv4-tiny+3L+SPP 模型的基础上又增加了3 个CBAM 模块,所以帧率下降稍多,达到10.8 帧/s,但也能满足车前红外行人检测的需要,平均准确率增幅明显,相较于YOLOv4-tiny+3L+SPP 增加了7.62%,达到了83.61%,说明CBAM 模块能够将特征图中有目标物体的区域权重提高,进而提高网络检测精度。
根据试验结果,本文选取YOLOv4-tiny+TensorRT和YOLOv4-tiny-I 作为车前红外行人检测的2 种方法。为直观展现模型检测效果,选取部分图像进行对比,如图7 所示。从图7a 和图7b 中可以看出:YOLOv4-tiny+TensorRT和YOLOv4-tiny对行人识别效果基本一致,侧面验证了TensorRT 在加速模型检测时模型准确率仅降低0.54%的试验结果的正确性;在场景1中,骑行者所在区域和周围背景区域相似,可以发现YOLOv4-tiny算法在该骑行者的定位上有些偏差(骑行者的脚没有完全在目标检测框内),而YOLOv4-tiny-I 算法中该骑行者完全在目标检测框内;在场景2 中,有被遮挡的行人且行人目标较小,通过比较能够发现,YOLOv4-tiny 未能识别到右侧被遮挡的行人,而YOLOv4-tiny-I能成功识别出被遮挡的行人,验证了在模型YOLOv4-tiny-I中使用的3个YOLO层的有效性;场景3为正常情况下的行人,可以发现3个模型对其均有很好的识别效果。


图7 3种模型的检测效果对比
4 结束语
本文提出2 种基于嵌入式平台的车前红外行人检测方法,YOLOv4-tiny+TensorRT 和YOLOv4-tiny+3L+SPP+CBAM:通过TensorRT 推理加速YOLOv4-tiny模型来提升检测速度;通过修改YOLOv4-tiny模型结构来提升检测精度。第2种方法使用3个YOLO层进行多尺度图像预测,同时引入SPP 模块来加强多尺度特征融合,进一步丰富了深层特征图的表达能力,并引入CBAM模块来关注重点特征,同时抑制非必要特征。试验结果表明:相较于原始网络YOLOv4-tiny,所提出的第1种方法平均准确率降低0.54%,推理速度提升86.43%(达到26.1 帧/s);第2 种方法平均准确率提升16.21%,推理速度降低22.86%(达到10.8帧/s)。2种方法均能满足车前红外行人检测的需要。在实际应用中,若对检测速度要求高,可选用第1种方法,若对检测精度要求高,可选用第2种方法。
猜你喜欢
意林(2021年5期)2021-04-18 12:21:17
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
扬子江(2019年1期)2019-03-08 02:52:34
铁道通信信号(2018年2期)2018-04-18 12:18:23
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
电镀与环保(2016年3期)2017-01-20 08:15:32
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
单片机与嵌入式系统应用(2014年9期)2014-03-11 15:35:13
自动化博览(2014年4期)2014-02-28 22:31:15
