
基于深度学习的伪装目标检测综述
2022-12-19 03:00史彩娟任弼娟王子雯闫巾玮
计算机与生活 2022年12期
史彩娟,任弼娟,王子雯,闫巾玮,石 泽
1.华北理工大学 人工智能学院,河北 唐山 063210
2.河北省工业智能感知重点实验室,河北 唐山 063210
伪装是自然界中广泛存在的一种生物现象,它可以帮助自然界中的生物利用自身结构和生理特征来融入周围环境,从而躲避捕食者。除了自然界的生物伪装,还存在人工伪装,如军事中的迷彩伪装士兵以及艺术中的人体彩绘等。为了识别这些完美嵌入周围环境中的伪装生物和人工伪装目标,研究者们提出了许多伪装目标检测(camouflaged object detection,COD)方法。然而,与其他任务(普通目标检测[1-3]、显著性目标检测(salient object detection,SOD)[4-6])相比,伪装目标在纹理、颜色、形状等与背景高度相似,且其边界与周围环境的视觉辨识度极低,这导致检测伪装目标更具挑战性。图1 展示了多种类型的伪装目标,其中(1)~(4)为自然伪装,(5)和(6)为人工伪装。具体来说,(1)为陆地类伪装生物,(2)为水生类伪装生物,(3)为飞行类伪装生物,(4)为爬行类伪装生物,(5)为伪装士兵,(6)为人体彩绘伪装目标。

图1 从4个COD数据集中选取的多种类型伪装目标Fig.1 Various types of camouflaged objects selected from 4 COD datasets
伪装目标检测最早可以追溯到1998年[7],Tankus等人提出的非边缘感兴趣区域机制对自然环境和作战场景中的人工伪装目标进行检测。自此以后,研究者们利用人类识别目标时的直接视觉特征,如颜色、纹理、光流等来描述伪装目标,提出了多种基于传统特征提取的伪装目标检测方法[8-13]。但是,传统方法在面对前景和背景对比度极低的伪装场景时,通常存在手工提取特征耗时、迁移性较差、检测性能较低等问题。
近年,为了解决传统方法存在的问题,研究者们将深度学习引入到伪装目标检测领域并提出了多种基于深度学习的伪装目标检测模型。基于深度学习的伪装目标检测方法以强大的特征提取能力和自主学习能力对伪装目标信息进行建模,能够提升伪装目标检测的精度,同时还能增强伪装目标检测模型的泛化性。然而现有的伪装目标检测工作大多从模型结构出发,旨在改善伪装目标检测和分割的性能,而关于伪装目标检测的发展现状及发展前景分析较少。虽然Bi 等人[14]对伪装目标检测方法进行了梳理,但主要是对传统的基于手工特征提取的方法进行了分类梳理,对近年来基于深度学习的伪装目标检测方法概述不全面且缺乏归类分析。
因此,本文将对基于深度学习的伪装目标检测算法进行归纳总结。首先从五个角度对现有基于深度学习的COD 算法进行了详细分析;其次介绍了伪装目标检测中常用的数据集和评估准则;然后对基于深度学习的检测方法进行了性能比较;接着列举了伪装目标检测的应用领域;最后分析了伪装目标检测方法面临的挑战以及未来研究方向,为后续提出新的伪装目标检测模型提供一定的技术思路和改进方向。
1 基于深度学习的伪装目标检测模型
近年,基于深度学习的伪装目标检测成为当前目标检测领域的一个研究热点,越来越多基于深度学习的伪装目标检测算法不断被提出,检测精度、时效性等均得到不断提升。
现有的大部分基于深度学习的伪装目标检测方法首先采用卷积神经网络(convolutional neural network,CNN),如VGG(visual geometry group)[15]、ResNet(residual neural network)[16]、Res2Net[17]等提取特征,然后采用由粗到细、多任务学习、置信感知学习、多源信息融合、Transformer 等不同策略来进一步增强特征,进而提升伪装目标检测性能。
因此,本文从由粗到细策略、多任务学习策略、置信感知学习策略、多源信息融合策略和Transformer策略五个角度对现有基于深度学习的伪装目标检测方法进行深入分析。图2 给出了现有基于深度学习的伪装目标检测方法导图,列出了现有基于五种不同策略的23种伪装目标检测方法以及它们的主干网络情况。下面对基于这五种策略的伪装目标检测方法进行详细的分析。

图2 基于深度学习的伪装目标检测方法导图Fig.2 Map of camouflaged object detection methods based on deep learning
1.1 基于由粗到细策略的伪装目标检测
由粗到细策略是一种结合全局预测和局部细化的体系结构,这种结构可以将复杂目标进行解耦,先对整体区域进行粗糙预测,再通过多种手段细化预测。根据细化手段的不同,现有的基于由粗到细策略的伪装目标检测方法又可以分为三类:利用特征融合细化的伪装目标检测方法、利用分心挖掘细化的伪装目标检测方法和利用边缘线索细化的伪装目标检测方法。
1.1.1 利用特征融合细化的伪装目标检测方法
利用特征融合进行细化是指在初始提取特征后,采用密集连接、X 形连接或者以注意力引导等方式融合特征进行细化,实现特征增强。Fan 等人[18]使用搜索注意力和部分解码器组件(partial decoder component,PDC)[19]对粗糙区域进行细化,PDC 的结构如图3(a)所示。但是,这种密集连接的特征融合方式可能会导致计算冗余。因此,Wang 等人[20]提出D2CNet,在PDC的基础上引入整体注意、残差注意机制来增强特征,并采用优化后的U-Net[21]结构融合对等层的局部信息进行细化。但是该模型在产生最终预测时直接引入第三层特征而未作任何处理,可能会引入误导信息。Zhuge 等人[22]针对多层特征利用不足的问题,提出CubeNet 模型,通过构建一种X 形连接(见图3(b))以多入多出的结构进行特征融合,充分考虑到每一层初始特征,但同时层层传递特征可能会积累冗余信息。
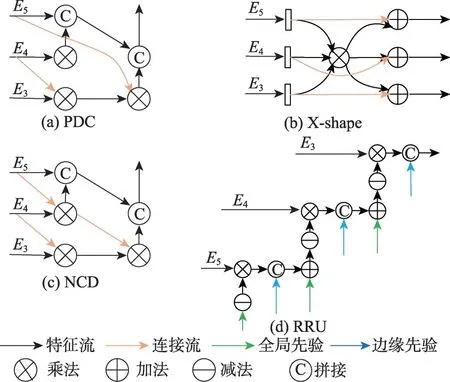
图3 不同特征融合策略的示意图Fig.3 Different feature fusion strategies
除了这三种构建不同连接通路进行特征融合的方式外,Sun 等人[23]利用注意力引导进行特征融合。他们设计了C²F-Net(context-aware cross-level fusion network)模型,利用多尺度通道注意力引导来聚合跨层次特征,同时关注全局和局部信息,从而提升多尺度目标检测性能。但是,该方法在粗糙预测和细化阶段都仅使用融合策略,这可能会使图像中难以被检测到的困难像素始终不被关注到。
利用特征融合进行细化的伪装目标检测方法优点在于能够在不增加额外线索的前提下充分利用多层特征中的有用信息。但是由于伪装目标与背景极为相似的部分区域仅通过特征融合策略难以被关注,使得模型的细化范围存在一定局限性。
1.1.2 利用分心挖掘细化的伪装目标检测方法
分心挖掘是指发现预测中前景或背景中的异质干扰,并移除这些干扰以获得目标对象更纯粹的特征表示。Mei等人[24]提出PFNet(positioning and focus network)模型,将更高层预测图和取反后的预测图分别与当前层特征相乘并输入到上下文探索块中以发现假阳性和假阴性预测,接着分别使用逐元素减法和减法来抑制这两种干扰,由于使用简单的加减法,使得模型有着较快的推理速度,但是直接将当前特征与预测先验直接相乘可能会导致特征混淆的问题。Fan等人[25]提出的SINetV2模型使用组反向注意力很好地解决了上述问题,它是将候选特征沿通道进行分组后,在每组之间周期性地插入预测先验,以明确隔离二者的方式来缓解特征混淆和先验中积累的不准确预测的问题。除此之外,SINetV2对PDC进行改进,设计了一种新的特征融合方式NCD(neighbor connection decoder)对相邻层特征进行融合,如图3(c)所示。NCD 少而有效的连接方式不仅减少了计算冗余,并且特征只在相邻层之间传递,进一步缓解了不同尺度特征的不一致性。基于分心挖掘策略的COD方法优势在于模型通过简单的加减法运算来消除错误预测的干扰,使得该策略下模型的参数量较少,运行速度也较快,但是细化前需要增强对有用特征信息的提取。
1.1.3 利用边缘线索细化的伪装目标检测方法
前两种类型的细化方法仅在上下文特征内进行增强,然而要获取伪装目标的精细化结构,边缘线索是最直接的补充方式。因此,Qin等人[26]提出BASNet(boundary-aware segmentation network)模型,学习粗略预测图和GT之间的残差来对粗糙预测进行细化,并设计了一种结合二进制交叉熵损失[27]、结构相似性损失[28]和IoU损失[29]的混合损失来隐式地引导网络更加关注目标边界信息,因此BASNet能够在不显式提取边界的情况下获取精细的伪装目标边界。不同于BASNet隐式关注边缘的方法,Ji等人[30]提出ERRNet对低层特征相互加权以显式监督的方式获取边缘先验,并通过RRU(reversible re-calibration unit)单元(如图3(d))与其他先验知识(语义先验、邻居先验、全局先验)融合达到细化的目的,但是由于先验知识过多,可能使有价值的线索被淹没。ERRNet的优势在于融合过程中使用了简单的级联和加减法运算,使得模型达到了现有算法中最快的推理速度。Jia 等人[31]从设计边缘标签的角度提出了SegMaR,利用文献[32]设计的固定注释和经高斯运算扩展后的边缘注释以合并和相交的方式生成一种包含边缘线索的判别掩码,以此作为监督来关注伪装相关的边缘信息。另外还设计了一种目标放大和多阶段训练的方式进行迭代细化,但是迭代优化终止条件缺乏理论依据,且多阶段训练方式导致训练复杂且耗时。
利用边缘线索进行细化的方式通常能获取比较精细的边缘轮廓,但由于伪装目标的边缘比较模糊(如图1),导致使用边缘监督学习到的特征响应包含噪声,尤其是复杂场景下,因此用何种方式引入边缘信息是该方法需要解决的一个重要问题。
1.2 基于多任务学习策略的伪装目标检测
多任务学习策略通过引入常见的分类、定位等任务或者其他检测任务来辅助二值分割主任务以提升伪装目标的检测性能,通过多种任务的协同工作,以挖掘更加丰富的伪装目标信息。根据任务的不同,基于多任务学习策略的伪装目标检测方法主要分为:基于分类+分割的伪装目标检测方法、基于定位/排序+分割的伪装目标检测方法、基于仿生攻击+分割的伪装目标检测方法、基于纹理检测+分割的伪装目标检测方法和基于边缘检测+分割任务的伪装目标检测。
1.2.1 基于定位/排序+分割的伪装目标检测方法
基于定位/排序+分割的伪装目标检测方法是指在分割之前找到伪装目标所在位置,符合人类观察伪装目标的步骤。Lv等人[32]提出使用LSR(localization,segmentation and ranking)来定位目标并区分不同图像中伪装目标的伪装级别。针对定位任务,采用固定注释作为监督标签来检测明显区别于背景的伪装目标判别区域;分割任务将反向判别区域映射作为输入来分割伪装目标的整个范围;针对排序任务,构建排序数据集用以将分割结果的每个像素按区分难易度进行排序。LSR 是首次对伪装程度进行探索的算法,它能在分割伪装目标的同时,为观察伪装目标的难易程度提供一定指引。
1.2.2 基于分类+分割的伪装目标检测方法
基于分类+分割的伪装目标检测方法是指在分割之前对图像中的像素进行分类以检测是否有伪装目标的存在。Le 等人[33]提出的ANet(Anabranch network)引入分类流,采用三个全连接层和Softmax分类层输出分类概率,并与分割流预测的伪装映射相乘达到分割伪装目标的目的。ANet是使用分类和分割任务的早期尝试,它使用分类任务让模型聚焦于包含伪装目标的区域,为后续分割任务排除了非伪装和背景的干扰。但由于伪装图像中一些非伪装的显著目标极具迷惑性,分类流可能会产生错误判断导致分割失败。
1.2.3 基于仿生攻击+分割的伪装目标检测方法
仿生攻击是通过制造与原始图像差异较大的图像来改变场景视点以检测伪装目标。Yan 等人[34]提出MirrorNet,通过引入分割翻转图像的仿生攻击流来增强分割原始图像的主流,并将仿生攻击流的预测翻转后与主流预测进行融合得到最终的伪装目标预测。MirrorNet利用翻转图像作为补充进行分割的过程本质上是促使模型更加关注伪装目标的纹理和形状特征,能在一定程度上增强模型的抗干扰能力。但是,图像翻转并不会改变低辨识度的纹理或者边缘,因此,仅使用翻转图像作为补充得到的性能增益十分有限。
1.2.4 基于纹理检测+分割的伪装目标检测方法
上述利用计算机视觉中的分类、定位等来辅助分割的方法并未考虑到伪装特征中纹理的重要性。如图4 所示,伪装目标通常表现出边缘模糊性,然而纹理特征具有的旋转不变性以及抗噪能力强等特点,使得一些伪装目标检测方法通过引入纹理感知任务来补充深度上下文信息。现有基于纹理检测+分割任务的主要不同点在于探索纹理信息的方式不同,有的从纹理信息的表示出发,设计独特的纹理标签;有的则关注获取纹理信息的方法,如矩阵方法、卷积方法等来探索提取纹理特征的有效性。

图4 具有边缘模糊性和纹理欺骗性的伪装目标Fig.4 Camouflaged objects with edge fuzziness and texture deception
Ren 等人[35]提出了TANet,通过计算每个位置特征响应的协方差矩阵,以此来提取深度特征的纹理信息,同时设计亲和力损失帮助分离伪装目标与背景之间的纹理。但是由于很大一部分伪装目标在纹理上与背景相似度仍然比较高(见图4),而TANet的重点关注仅在纹理信息上,因此它所能获得的检测性能有限,而且使用卷积特征图的协方差矩阵表征的纹理特征图会损失位置信息。Zhu等人[36]则从纹理信息的表示出发,构建了一种包含局部纹理、局部显著性区域以及边缘的纹理标签,并提出TINet(textureaware interactive guidance network)融合纹理信息与深度信息并以层间监督的方式生成纹理预测。但该模型使用的纹理标签并未充分体现像素与周围空间邻域的灰度分布,而且由于伪装图像中强烈的背景干扰,TINet并不能挖掘到充足的纹理信息。Ji等人[37]提出的DGNet(deep gradient network)引入梯度信息很好地改善了TINet 中存在的问题。DGNet 构建了对象级的梯度映射(见图5[38])来监督纹理分支,相较于TINet中的纹理标签,梯度标签能表示更加丰富的纹理信息。同时,梯度值越高的地方意味着图像能量的急剧变化,这也对应着图像的边缘部分,因此DGNet 同时关注了纹理和边缘信息,从而取得了良好检测性能。但是引入梯度信息也存在一定问题,由于图像梯度对邻域像素值变化敏感,而图像内的噪声,尤其是伪装图像中非边缘区域及非伪装的显著区域同样具有较高的梯度,这些噪声在一定程度上对模型产生干扰。

图5 DGNet中使用的四种监督标签Fig.5 Four types of supervision labels widely used in DGNet
由于伪装目标的特殊性,基于纹理检测来补充分割任务的方法通常能取得较好的检测效果,但是由于一部分伪装目标存在纹理欺骗性(如图4),而这种情况下仅靠纹理特征来检测伪装目标是不够的。因此在关注纹理信息的同时,也要考虑到局部显著信息或者边缘的重要性。
1.2.5 基于边缘检测+分割任务的伪装目标检测
与利用边缘线索进行细化或者让边缘作为一小部分因素参与到模型中的方法不同,基于边缘检测+分割的任务是将边缘检测作为与分割并行的一大任务,通过明确建模边缘并推理两个任务的互补信息来检测伪装目标。Zhai等人[38]引入图卷积提出了MGL(mutual graph learning)来捕获区域和边缘,并使用边缘压缩图推理模块显式合并边缘信息以增强区域信息。MGL的有效性来源于使用类型化函数明确推理两个任务的互补信息以捕获语义信息和空间信息,但是每次提取的信息种类繁多,很难保证每次提取的信息都是有效的,而且基于图推理的模型复杂度较高,使得模型运行速度较慢,R-MGL(MGL中性能最好的一种变体)的运行速度只有9.9 frame/s,是现有方法中运行最慢的方法。
以上基于多任务学习策略的方法能充分利用不同任务的特殊性以及和主任务之间的互补性来辅助伪装目标检测。但在实现的过程中,通常会忽略不同任务之间的固有差异造成的负面影响,导致伪装目标检测的学习缺乏针对性,影响检测性能。
1.3 基于置信感知学习策略的伪装目标检测
置信感知学习旨在估计代表数据质量的不确定性(任意不确定性)或对真实模型的感知不确定性(认知不确定性)[39]。在完全监督模型中,置信感知学习被用来测量预测与真实标签的高阶不一致性,并且它已被证实能够有效提升深层神经网络的鲁棒性[40-41]。在伪装目标检测任务中,一些工作引入置信感知学习策略,明确建模网络预测的置信度来促进模型学习图像中的困难样本,以此提升模型的鲁棒性。现有基于置信感知学习策略的伪装目标检测方法的主要不同在于对模型不确定性的表示和建模过程。研究者们对于完全标注伪装目标的困难带来的不确定性、模型预测和真实标签之间的不一致性、不可区分的纹理或边缘的不确定性等分别采用对抗训练策略、动态监督策略、正则化约束策略等进行伪装目标检测。
Li 等人[42]对完全标注伪装目标时产生的不确定性,提出了JCSOD(joint salient object and camouflaged object detection)模型,使用全卷积判别器来估计预测结果的置信度,并采用对抗训练策略对置信度估计显式建模。但是,由于JCSOD同时进行显著性目标检测,导致模型参数量巨大,比DGNet高出196.96 MB。Liu等人[43]提出的CANet模型,使用UNet结构对预测和真实标签之间的不确定性进行建模,利用预测图和真实标签的L1距离以动态监督的方式生成置信度图。它的优势在于能够引导网络重点学习预测不确定的区域,提升网络的鲁棒性能。但是,关注不确定性学习得到的特征通常响应于伪装目标的稀疏边缘,导致该模型在特征学习过程中容易引入噪声。与前面显式生成置信度图的方式不同,Pang等人[44]对不可区分纹理和复杂背景干扰带来的不确定性进行建模,提出的Zoom-Net 在目标检测损失中加入正则化约束,增加对模糊预测的惩罚,来迫使模型关注不确定像素,这种方式以简单的计算降低模糊背景带来的干扰。除此之外,Zoom-Net 还致力于缓解多尺度目标的检测,但是它用多尺度图像训练模型大大增加了内存占用量和模型运算量。
以上几个模型对不确定性采用不同策略进行建模来提升伪装目标的检测性能,这种基于置信感知学习的方法为模型难以关注硬像素提供了很好的解决思路,能够增强模型的鲁棒性能,同时还能以估计置信度图的方式为模型预测提供一定的可解释性。但是这种从不确定性模型中学习到的特征通常响应于伪装目标的稀疏边缘或者难以区分区域,从而容易引入噪声,降低模型的检测能力。
1.4 基于多源信息融合策略的伪装目标检测
前面所有模型仅采用RGB信息进行伪装目标检测,为了获得更加丰富的伪装目标信息,一些研究者采用多源信息,如深度信息、频域信息等来补充RGB信息,从而提升伪装目标检测性能。
由于深度图能够提供丰富的空间信息,Zhang等人[45]首次利用现有的单目估计方法生成相应的伪装深度图,并提出基于RGB-D 置信感知学习的双分支框架DCNet(depth contribution exploration network)。由于引入了包含丰富空间信息的深度线索,DCNet整体取得了不错的性能。但它存在两个问题:一是提取的深度信息不够准确,低质量深度图导致模型性能降低;二是RGB数据和深度数据结合时,DCNet没有充分考虑两种模态信息之间的互补性和差异性。
频域处理有着简单高效且参数设置少的特点,因此,有研究者利用频域信息来增强伪装特征。Zhong 等人[46]使用离线离散余弦变换和在线可学习增强的方式让模型在频域中学习更多统计信息,同时使用特征对齐的方式对两种线索进行融合,另外构建了高阶关系模块借助频域信息来促使模型区分伪装和非伪装的细微差异。得益于频域信息的引入以及对所有频带系数的增强,该模型可以提取判别性信息提升伪装目标检测性能。
由于多源信息的引入,使得伪装目标检测性能优于仅采用RGB 信息的检测性能。但是,多源信息之间的表示、转化、对齐以及融合等加大了伪装目标检测模型的复杂度,甚至在多源信息处理不当的情况下降低模型检测准确度。因此在结合多源信息时,需要充分考虑多源信息之间的差异性影响。
1.5 基于Transformer的伪装目标检测
近年,研究发现CNN 在特征提取过程中会损失结构信息,而且CNN 的实际感受野远小于理论感受野[47],因此基于CNN 的伪装目标检测模型通常不能充分地捕获全局上下文信息。2017年,Vaswani等人针对自然语言处理提出的Transformer[48]能够利用自注意力捕获长距离依赖关系,更好地捕获全局信息。近年Transformer也被广泛应用到了视觉领域[49-50],多种Transformer模型被提出,如用于分类的ViT(vision transformer)[51]和PVT(pyramid vision transformer)[52],用于目标检测和分割的SETR(segmentation transformer)[53]、DETR(detection transformer)[54]和Swin Transformer[55]等。由于Transformer 在计算机视觉领域中的巨大潜力,研究者们也将其引入到了伪装目标检测任务中。
Mao 等人[56]提出T2Net 模型,利用Swin Transformer作为主干网提取丰富的全局伪装特征,并利用一种基于残差注意力和密集金字塔池化的深度监督结构来缓解Swin Transformer 不直接提供空间监督的问题。得益于Transformer强大的全局信息捕获能力,T2Net的检测精度优于现有基于CNN的伪装目标检测方法。但是T2Net 在将Transformer 引入到COD任务中时,主要缓解了Transformer 对空间信息建模效果较差的问题,并未充分考虑到提取局部特征能力的欠缺。不同于T2Net 直接使用Transformer 的主干网来提取特征的方法,Yang 等人[57]提出的UGTR(uncertainty-guided transformer reasoning)将CNN 和Transformer结合起来,利用概率表示模型学习Transformer框架下伪装目标的不确定性,使得模型能更多关注不确定区域。但它仅对不确定性建模,使得模型的不确定响应区域总是分布在弱边界和不可区分的纹理区域,学习过程中不可避免地会引入噪声。
基于Transformer 的COD 模型可表征的特征空间比CNN 更加丰富,并且它在建模过程中不会丢失细粒度信息,因此Transformer 是比较适合类似COD这种迫切需要丰富全局上下文信息的任务。但是基于Transformer 的COD 模型也存在固有缺陷:一是模型预训练耗时耗数据,这是由全局自注意机制具有二次的时间和空间复杂度导致的;二是Transformer特征存在局部信息欠缺以及过度光滑的问题;三是在训练过程中,基于Transformer的模型对学习率、权重衰减等参数比较敏感。由于Transformer固有的利弊,基于Transformer 进行伪装目标检测还存在很大的研究空间。
1.6 不同类型伪装目标检测方法比较
表1 给出了以上五种基于不同策略机制的伪装目标检测的典型方法以及它们的优缺点。
通过以上分析及表1可以看出,现有基于深度学习不同策略的伪装目标检测方法各有优劣。目前对于基于由粗到细策略和多任务学习策略的伪装目标检测方法研究较多,但这两种方法固有的缺陷使得研究者们逐步引入后三种学习策略。Transformer策略虽然能够捕获更加丰富的全局上下文,但是它不能有效应对伪装目标的尺度变化,而且训练需要巨大的算力和时间,不能满足实时性需求。多源信息融合策略能引入其他信息来补充RGB 信息,多种信息的有效结合能够有效提升伪装目标的检测性能。置信感知学习策略作为一种有效提升网络鲁棒性的手段,可以与其他策略结合起来,共同提高伪装目标检测的性能。
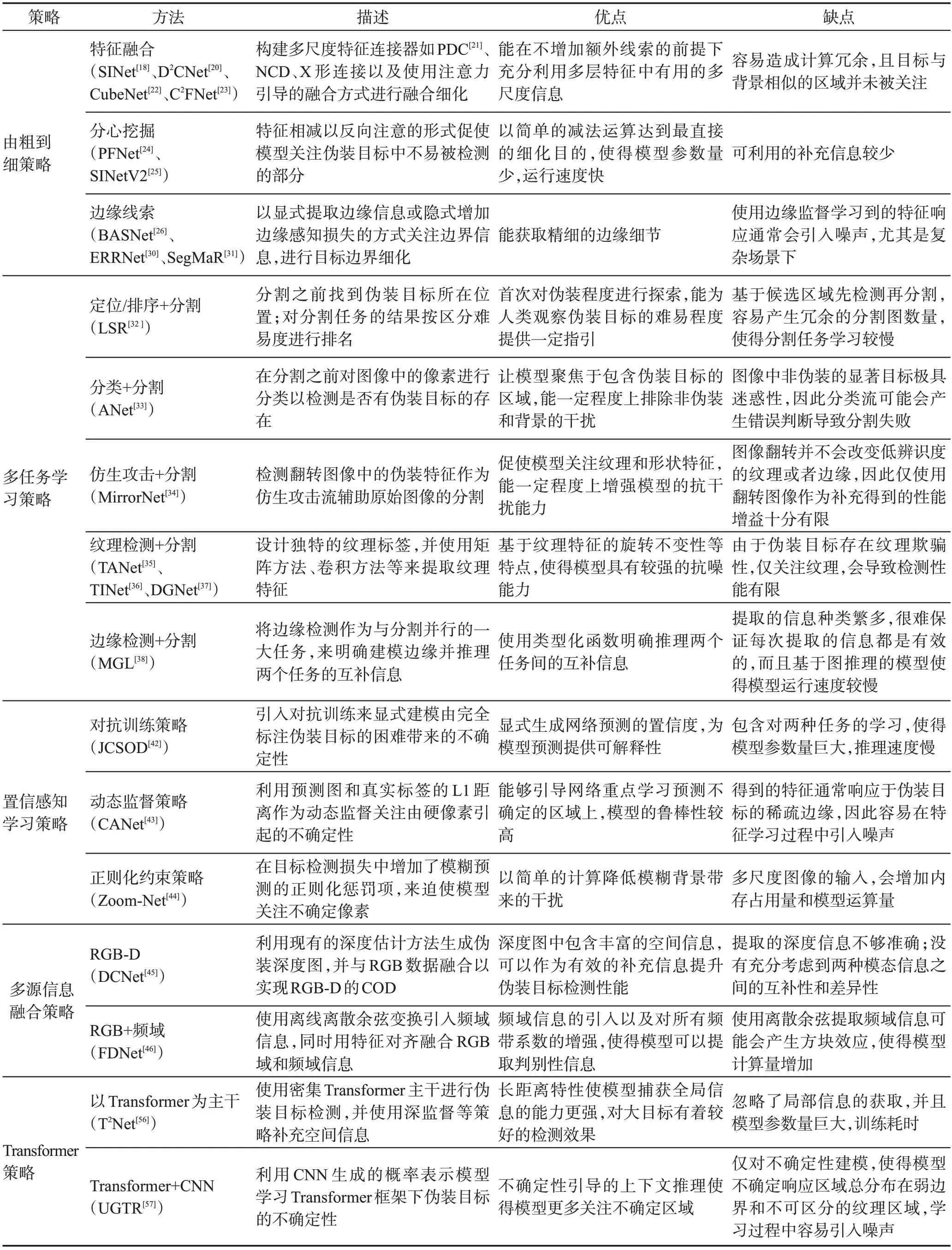
表1 不同类型伪装目标检测方法分析比较Table 1 Analysis and comparison of different types of camouflaged object detection methods
2 数据集和评估指标
本部分介绍了伪装目标检测常用的数据集和评估指标。
2.1 数据集
由于检测难度和伪装目标的特殊性,伪装目标检测任务在最近几年才开始得到广泛关注,因此COD公开数据集仅有四个,具体信息如表2所示。

表2 四个伪装目标检测数据集的主要信息Table 2 Main information of four camouflaged object detection datasets
CHAMELEON[19]数据集:是一个未经同行评议的公开数据集,仅包含76张从网上以关键字“伪装的动物”收集汇总的图像,它主要关注自然界的生物伪装,即复杂背景中的伪装动物。该数据集通常用于验证伪装目标检测模型的可用性。
CAMO[34]数据集:该数据集包含一个伪装图像数据集CAMO 和另一个非伪装图像数据集MS-COCO两个子集。CAMO 和MS-COCO 各包括1 250 张图像,其中1 000张用于训练,剩余250张用于测试。常用于伪装任务的CAMO 数据集包括自然伪装(伪装动物)和人工伪装(人体彩绘及军事中的迷彩伪装),具有较大的识别难度,可用于验证伪装模型的有效性。
COD10K[19]数据集:该数据集是目前规模最大的伪装目标数据集,共包含了5个超类和69个子类,共计10 000 张伪装图像(6 000 张用于训练,4 000 张用于测试)。该数据集的伪装目标类别包含有自然伪装中的陆地、海洋、飞行、两栖生物,目标维度包括大、中、小三个维度,可以进行模型训练和验证,目标标注包括类别、包围盒、对象级/实例级以及抠图级的注释。该数据集极大地促进了伪装目标检测的发展。
NC4K[33]数据集:是目前最大的伪装目标测试集,它包含从互联网上下载的4 121张伪装图像,其中伪装目标类别大部分为自然伪装,也包含少量人工伪装。
2.2 评估指标
伪装目标检测通常被定义为二值图像分割任务,为了全面评估伪装模型的精度和泛化能力,广泛使用S度量、E度量、F度量和平均绝对误差M来测试每个模型的生成预测图。接下来将详细介绍这几种评价指标。
S度量(Sα)[58]:用来评估预测图和真值图之间的结构相似性,它包括两个参数So和Sr,其中So计算目标感知,Sr获取区域观测特征。S度量Sα可以被描述为:

其中,α和o是权重。
E度量(Eϕ)[59]:通过比较预测图和真值图之间的差异来评估伪装目标检测结果的整体和局部精度。E度量Eϕ定义为:

其中,ϕ是增强一致性矩阵,W和H分别代表输入的宽度和高度,C和G分别表示预测图和真值图。
F度量(Fβ)[60]:用来计算精确率P和召回率R的关系,能够计算出P和R之间的平均谐波测量值,并将其数值显示出来。F度量Fβ定义为:

平均绝对误差MAE(M)[61]:用来计算每个像素的平均绝对误差,其定义式为:

其中,M值越小表示模型性能越好。
3 基于深度学习的伪装目标检测方法性能比较
本章对现有的基于深度学习的伪装目标检测方法进行了性能比较,包括定量比较、视觉比较和模型效率分析,从比较结果能够更为直观地看出不同方法之间的性能差异。
3.1 定量比较
本节对上述基于深度学习的不同伪装目标检测方法进行了定量比较,采用S度量(Sα)、E度量的平均值(Eϕ)、F度量的平均值(Fβ)以及平均绝对误差MAE(M)作为评估准则,在数据集CHAMELEON、CAMO、COD10K、NC4K 上分别进行了实验,实验结果见表3。表中“1”“2”“3”“4”“5”分别代表“由粗到细策略”“多任务学习策略”“置信感知学习策略”“多源信息融合策略”和“Transformer策略”。

表3 基于深度学习的伪装目标检测方法的定量比较Table 3 Quantitative comparison of camouflaged target detection methods based on deep learning
从表3可以看出:
(1)从整体表现来看,T2Net 在CAMO-Test、COD10K-Test 和NC4K 三个数据集的四个指标上均达到了最佳性能,在CHAMELEON 数据集上达到了第二的性能。T2Net是基于Transformer的模型,它利用自注意捕获长距离依赖关系的优势适合伪装目标检测这种需要全面上下文信息的任务,而T2Net在四个伪装数据集上的突出性能表明了Transformer应用在伪装目标检测任务的巨大潜力。性能排名第二的是Zoom-Net,它是基于置信感知学习策略的方法,能更加关注不确定像素的检测,另外该模型的性能优越性还受益于放大缩小策略对多尺度信息的获取。性能排名第三和第四的是DCNet和FDNet(frequency domain network),这两种是基于多源信息融合策略的方法,由于额外深度信息或频域信息作为补充,这两种算法表现出了较高的检测精度。基于CNN且不引入其他源信息的算法中,DGNet达到了与Zoom-Net相抗衡的性能,尤其在CAMO数据集上。除了整体性能最好的以上五种方法外,BASNet在CHAMELEON数据集上达到了最佳性能,这得益于它使用的U-Net结构以及混合损失,但它在伪装类型更加全面而且数据量更大的另外三个数据集上并未达到突出的检测性能。
(2)从不同策略的表现来看,表现最好的是基于Transformer策略和多源信息融合策略的伪装目标检测方法,基于多任务学习策略和置信感知学习策略的方法在基于CNN且不引入多源信息的方法中表现最好,其次基于由粗到细策略中的SINetV2也表现出了较好的性能。不同策略均具有很高的研究价值,因此应当权衡不同策略的优劣设计性能更加优越的伪装目标检测模型。
3.2 视觉比较
本节给出了13 种伪装目标检测算法在7 种不同类型伪装目标下的视觉检测结果,如图6 所示,其中从左至右依次为:(1)大目标;(2)小目标;(3)多且小的目标;(4)遮挡目标;(5)重影目标;(6)边缘细节丰富的目标;(7)人工伪装中的人体彩绘目标和军事伪装目标。对于其他并未提供开放的源代码或者结果预测图的伪装目标检测方法在此没有比较。

图6 基于深度学习的伪装目标检测方法的视觉比较Fig.6 Visual comparison of deep learning-based camouflaged object detection methods
由图6可以看出:
(1)从整体检测效果来看,这些算法中基于Transformer 的T2Net,基于置信感知学习策略的Zoom-Net以及基于多任务学习的DGNet在多种挑战场景下表现出了较好的检测效果,尤其是对大目标(1)、多目标(3)和遮挡目标(4)的检测要优于其他算法,检测的目标区域更加完整,轮廓也比较清晰。基于多任务学习的LSR在遮挡目标和重影目标中表现出了较好的检测效果,它利用定位和排序任务对伪装目标的检测起到了促进作用。基于置信感知学习策略的JCSOD能比较完整地检测大目标并获取丰富的边缘细节,这是由于JCSOD联合SOD数据并利用置信感知学习帮助模型排除非伪装中显著性区域的干扰。基于由粗到细策略的SINetV2 检测出了较为丰富的目标信息,尤其是在复杂场景下((4)(6)(7))的效果较好,这得益于邻居连接的特征融合方式和组反向注意力的目标细化手段。值得注意的是,BASNet 检测的目标虽然不够完整,但是它检测出的目标边界和轮廓都很精细,这主要归功于其设计的混合损失函数和类U-Net结构的解码器进行的细化。
(2)从不同目标的检测效果来看,这些伪装目标检测方法对简单场景下的普通伪装目标具有较好的检测性能,但是对挑战场景下的伪装目标的检测性能较差。如图6所示,这些方法对小目标、遮挡目标、人工伪装目标中的检测效果不佳。对于小目标,不能准确定位目标位置;对于遮挡目标,不能完整分离出目标信息;对于人工伪装目标,检测出来过多的无关信息。
通过定量分析和视觉分析可以看出,现有伪装目标检测算法能够取得较好的检测精度,对伪装这种极具挑战性的目标表现出了较好的分割结果。但是由于伪装目标的特殊性,现有算法的分割结果仍然存在边缘模糊、定位不准确等缺陷。
3.3 模型效率分析
本文在NVIDIA GeForce RTX 2080 上测试了13种COD方法(SINet[18]、C2F-Net[23]、PFNet[24]、SINetV2[25]、BASNet[26]、ERRNet[30]、SegMaR[31]、LSR[32]、DGNet[37]、MGL[38]、JCSOD[42]、Zoom-Net[44]、UGTR[57])的模型参数量、乘法和累加运算(multiply-accumulate operations,MACs)以及运行速度,结果如图7 所示。其中(a)是参数量和COD10K数据集上Sα的散点图,点越大,代表参数量越大。

图7 现有COD方法的效率分析Fig.7 Efficiency analysis of existing COD methods
从图中可以看出,在精度和参数之间平衡较好的模型是Zoom-Net、DGNet 和UGTR。ERRNet 的运行速度为57.8 frame/s,是比较方法中运行速度最快的模型。DGNet 的参数量和MACs 分别为21.02 MB和2.76 GB,是所有方法中参数量和MACs 最少的模型,这是由于DGNet是出于轻量化设计的模型,它使用了轻量化的主干网以及张量分解和重组的融合方式。同时,JCSOD的参数量最高,为217.98 MB,这是由于JCSOD联合了SOD任务。
4 伪装目标检测的应用
基于深度学习的伪装目标检测作为计算机视觉领域中的新兴任务,不仅可以进一步补充完善目标检测技术,还有助于推动医学、工业、军事、农业、艺术等多个现实领域的智能化发展。下面对伪装目标检测在不同领域的应用进行介绍。
(1)医学领域。医学成像在早期诊断中起着重要作用,然而早期病变区域与周围组织有着高度的同质性,如图8 所示的息肉图像和肺部感染图像(图像来源于文献[62-63]),它们的边界模糊,并且与周围组织相似度极高,可以被视为一种伪装目标。因此伪装目标检测可以应用于医学图像分析,进行息肉分割和肺部感染分割。

图8 COD在医学领域的应用Fig.8 Applications of COD in medicine
(2)工业领域。在工业生产过程,需要对质量低劣的产品(如木材、纺织品、瓷砖等)进行筛选和剔除。然而如图9 所示(图像来源于文献[64]),这些零件的缺陷通常在纹理等方面与其他部分对比度很低,而且边界模糊,可以看作一种伪装。因此,伪装目标检测可以用于手工艺品或机械零件等物体表面的缺陷检测。

图9 COD在工业领域的应用Fig.9 Applications of COD in industry
(3)农业领域。农业中的害虫通常在颜色纹理等都与农作物极为相似,因此伪装目标检测可做害虫检测为整个环境中的蝗灾密度监测提供统计数据。除此之外,果实早熟阶段,为了监控产量,也需要对果实进行检测,而果实早期常与绿叶极为相似,可视作伪装目标对其进行检测。图10展示了蝗虫检测和番茄检测(图像来源于文献[65-66])。

图10 COD在农业领域的应用Fig.10 Applications of COD in agriculture
(4)军事领域。军事中的迷彩伪装是人工伪装的主要组成部分,迷彩伪装是在作战环境中完美嵌入周围环境中的人员、武器、装备等。在作战环境中,需要识别出隐藏的士兵和军事设备,在确保他们安全的同时,提升我方军队的作战能力。因此,伪装目标检测在军事领域中有着很大的应用潜力。图11展示了迷彩伪装士兵(图像来源于CAMO[33])。

图11 迷彩伪装士兵检测Fig.11 Camouflage soldier detection
(5)艺术领域。图像的风格迁移可以将自然风景图像与伪装的目标嵌在一起,如图12所示(图像来源于文献[67]),这可以为伪装目标检测提供更多的训练数据。

图12 动物嵌入在风景图像中Fig.12 Some animals embedded into landscape images
(6)其他领域。伪装目标检测还可以用于透明物体的检测、搜索引擎的完善、探测或保护野生动物以及在野外或者自然灾害中进行搜索救援活动等。
5 总结及展望
5.1 伪装目标检测存在的挑战
本文从由粗到细、多任务学习、置信感知学习、多源信息融合以及Transformer五种策略角度对现有的基于深度学习的伪装目标检测方法进行了归纳总结,分析探讨了不同模型的优劣,给出了不同方法的定量分析、视觉比较和效率分析。尽管伪装目标检测得到了越来越多的研究,性能不断提升,但由于伪装目标本身极具挑战性,现有基于深度学习的伪装目标检测算法仍然存在着很多不足和挑战。主要包括:
(1)复杂场景下检测效果差。现有伪装目标检测算法基本能实现简单场景下的伪装目标检测,然而,现实中的伪装目标通常处于背景杂乱、大面积遮挡、背景过于突出等复杂场景下,导致伪装目标的边界混淆和形状的非连续性。因此,针对复杂场景下的遮挡目标、人工伪装目标等的伪装目标检测仍具有很大的挑战性。
(2)多尺度目标检测性能不佳。面对实际场景下的多种尺度伪装目标,现有的伪装目标检测方法通常不能完整检测出大目标,无法准确定位小目标位置(将目标错误定位为背景比较突出的背景区域)等,导致对大目标以及多且小的伪装目标检测效果较差。
(3)实时性不足。目前仅有DGNet[37]是以轻量级的模型参数达到了较高的检测精度,它在模型设计中使用更为轻量的主干网EfficientNet进行初始特征提取,同时在特征融合过程中使用张量分解和重组的方式减少模型参数量。现有的一部分COD模型在设计中会考虑参数和精度的平衡,如SINet[18]使用非对称卷积代替大核卷积来降低参数;PFNet[24]、SINetV2[25]和ERRNet[30]使用简单的加减法进行分心挖掘也能减少一定参数量和运算量。但是这些方法都没重点考虑轻量化设计,致使方法的参数量和运算量依然很高,依然需要巨大的算力和时间,不能满足实际应用的实时性需求。
(4)有限条件下的伪装目标检测研究较少。相比普通目标或显著性目标,由于伪装目标背景复杂及边界辨识度极低等挑战,使得检测伪装目标具有更大的难度,因此现有算法都以完全监督的方式从带有对象及标签的图片中提取特征,试图达到较为理想的检测效果。然而,就目前为止,基于完全监督的算法实现的检测效果仍然非常有限(见图6),另外由于现有少样本学习、弱监督学习、无监督学习、自监督学习等性能还比较有限,导致适合实际场景的现实应用需求下有限条件的伪装目标检测研究较少。
(5)多模态伪装目标检测研究较少。目前伪装目标检测仅限于多源信息,如基于RGB-D的DCNet[45]、基于频域的FDNet[46]和基于VCOD 的SLT-Net[68]等,而基于图像、文本、音频、视频等多种模态的多模态伪装目标检测研究还非常有限。
5.2 未来研究方向
针对上述伪装目标检测中存在的不足和挑战,下面分析列举了基于深度学习的伪装目标检测的未来研究方向。
(1)复杂背景下的多尺度伪装目标检测方法研究。最大化模拟人类视觉识别伪装目标的理念,设计具有针对性的模型去推理和判断复杂背景下的伪装目标;充分捕获伪装目标的全局、局部信息和局部显著性信息,提升多尺度伪装目标检测性能。
(2)轻量化伪装目标检测方法研究。充分利用现有的轻量化模型思想,如深度可分离卷积、小卷积代替大卷积、压缩编码、权值量化、权值共享、迁移学习/知识蒸馏、计算加速等,设计更加精细的能满足实时性应用需求伪装目标检测模型,以在军事作战环境、搜索救援活动等对实时性要求非常高的场景中进行应用。
(3)有限条件下的伪装目标检测方法研究。在算法研究方面,利用少量注释数据进行少样本训练以避免昂贵的注释成本;使用聚类、降维、自编码器等方式对无标签的伪装数据进行无监督学习,以实现对伪装目标进行分类等任务;使用样本增强技术、对比任务等进行自监督学习来学习伪装数据本身的特征;引入自学习、生成式方法及协同学习等方式进行半监督学习以利用未标注数据提升模型学习性能。在实际应用角度方面,可以根据不同领域的数据特点及应用需求,进行特定任务的数据收集并设计相应的学习方式。
(4)多模态伪装目标检测方法研究。单一的图像模态对伪装目标检测的性能还很有限,利用多源信息融合、多视图学习、协同学习等方法将文本、图像、音频、视频等多种模态相结合,利用多模态来提升伪装目标的检测性能。
6 结束语
本文从由粗到细、多任务学习、置信感知学习、多源信息融合以及Transformer五种策略角度对现有的基于深度学习的伪装目标检测方法进行了分类综述,比较了各类方法的优缺点,在四个公共伪装目标数据集上对现有的基于深度学习的伪装目标检测模型进行了定量分析、视觉分析和效率分析,评估了不同模型的性能。此外,列举了伪装目标检测的应用领域,讨论了现有伪装目标检测模型存在的不足和挑战,并探讨了伪装目标检测的未来研究方向。
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
软件(2020年3期)2020-04-20
家庭影院技术(2019年8期)2019-08-27
当代陕西(2019年10期)2019-06-03
摄影之友(影像视觉)(2018年12期)2019-01-28
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
燕山大学学报(2015年4期)2015-12-25
中国塑料(2015年4期)2015-10-14
