
深度在线多目标跟踪算法综述
2022-12-19 03:00:04刘文强裘杭萍赵昕昕
计算机与生活 2022年12期
刘文强,裘杭萍,李 航,杨 利,李 阳,苗 壮,李 一,赵昕昕
陆军工程大学 指挥控制工程学院,南京 210007
多目标跟踪(multiple object tracking,MOT)是机器视觉领域的一个重要研究课题,其目的是稳定跟踪视频序列中的多个感兴趣的目标,生成目标的运动轨迹。按照运动轨迹的生成是否依赖后续帧的信息,多目标跟踪任务可以分为离线跟踪与在线跟踪两种不同的模式[1]。离线跟踪使用一段视频中全部的检测结果共同推理每一帧中目标的运动轨迹,可以视为全局优化问题,而在线跟踪根据当前的检测结果与历史轨迹按时间顺序逐步生成新的轨迹。由于在线多目标跟踪可以实时处理输入的视频序列,在现实场景中应用广泛。在自动驾驶领域[2],汽车需要从运动画面中快速定位行人、车辆、交通标志等目标,然后预测目标在场景中的运动轨迹,为车辆正常运行提供基本的数据支撑;在视频监控系统中[3-4],基于行为识别的上层应用也常常依赖在线多目标跟踪技术,如入侵检测、遗留物检测、人体跌倒检测、突发事件检测等技术都需要其提供感兴趣目标的运动轨迹;特别在军事领域[5],在线多目标跟踪是制导武器系统和无人作战平台的关键技术,是保障武器快速精准命中目标和执行侦查等作战任务的基本条件。
早期的在线多目标跟踪算法关注复杂的关联优化方法,这些方法精度有限。随着深度学习的快速发展,基于深度学习的在线多目标跟踪算法逐渐成为主流,其基本框架如图1 所示,包括检测器和关联器两部分,分别用于目标检测以及表观特征提取、目标特征预测和数据关联。其中,目标检测产供目标的基本信息,包括位置、大小以及形态等;表观特征提取模块为目标提取表观特征,用于确定目标的身份;目标特征预测模块建模之前帧中目标的空间位置或表观特征随时间的变化,预测目标在后续帧中的空间位置或表观特征;数据关联模块根据前三个模块的输出连接不同帧中的检测框形成最终的轨迹。
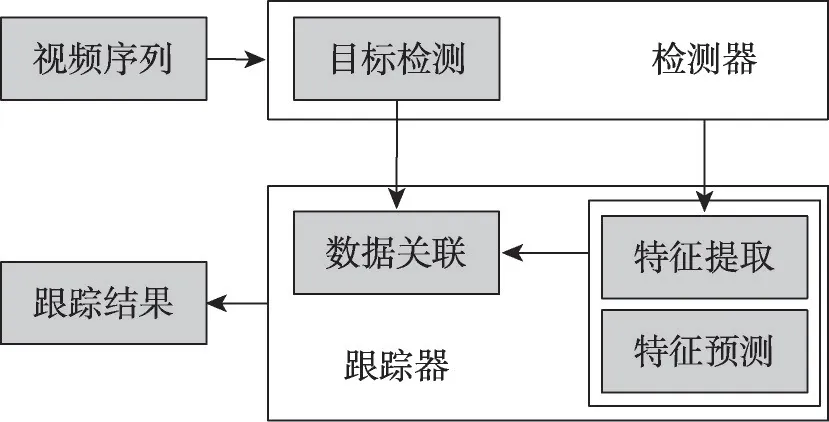
图1 深度在线多目标跟踪算法主要步骤流程图Fig.1 Flow chart of main steps of deep online multi-object tracking algorithm
与传统方法相比,深度在线多目标跟踪算法性能更加良好,但依旧存在以下几方面问题:
(1)遮挡和小目标问题。跟踪过程中部分被遮挡目标的表观特征损失严重,并且场景中的小目标由于其本身占据的像素点较少导致特征不足。以上问题对目标的检测与匹配均有显著影响,从而降低了跟踪算法最终的性能。由Bytetrack算法[6]在MOT17验证集上的跟踪结果(图2)可以看出,跟踪过程中遗漏的目标大部分都集中于可视度(未被遮挡面积与目标框总面积的比值)较低的目标和小目标当中。

图2 遗漏目标散点图Fig.2 Scatter diagram of missing target
(2)目标特征不一致问题。在跟踪时,目标的特征处于动态变化中,当前后特征变化过大时,就会产生特征不一致的问题。例如:序列帧中同一目标的尺度不对齐,随雨、雪、雾、强烈光照变化导致跟踪主体特征的变化,镜头抖动导致运动规律不一致。
虽然基于深度学习的在线多目标跟踪算法相比传统算法已经有了较大突破,但较为全面地介绍基于深度学习的在线多目标跟踪算法的相关综述较少。例如,文献[7-8]主要介绍基于传统检测方法和特征提取方法的多目标跟踪算法,与现有基于深度学习的在线多目标跟踪算法具有较大差异;文献[9-10]主要关注多目标跟踪算法中的数据关联技术;近期,文献[11-14]讨论了基于深度学习的在线多目标跟踪算法。当前,一般的分类方法将基于深度学习的在线多目标跟踪算法分为基于检测跟踪和联合检测跟踪两种框架,它们的区别在于是否存在与目标检测网络融合的跟踪模块。本文在此基础上进一步将深度多目标跟踪算法分为了如图3所示的六个子类。为了便于表达,后文图表中分别用DBE(detection-basedembedding)、DBP(detection-based-prediction)、DBA(detection-based-association)、JDE(joint-detectionembedding)、JDP(joint-detection-prediction)和JDA(joint-detection-association)表示基于特征重提取的表观特征提取、基于时序性建模的特征预测、基于匹配的数据关联、基于特征复用的表观特征提取、基于帧间特征融合的特征预测以及基于特征查询的数据关联,子类根据多目标跟踪的功能模块进行分类:
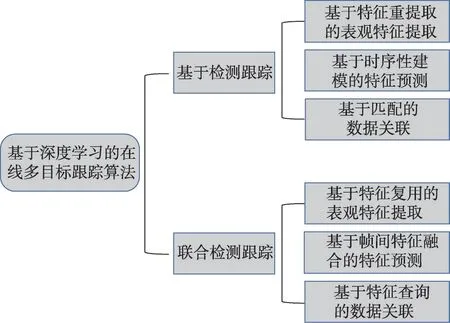
图3 深度在线多目标跟踪算法分类Fig.3 Classification of deep online multi-object tracking algorithm
(1)表观特征提取模块。提取当前图像中所有目标的表观特征向量。如图4所示,DBE的特征提取独立于检测阶段的图像处理过程,其输入是一组检测到的目标区域的切片,通过重识别网络提取切片的表观特征作为目标的表观特征向量。JDE通过一体式网络推理全图信息,然后抽取目标在特征图上的对应像素点作为目标的表观特征向量,并同时输出目标的检测框。图中的行人图片均来自MOT17数据集。
(2)目标特征预测模块。根据目标之前的空间位置和表观特征预测其后续的空间位置和表观特征。如图4,DBP采用独立于检测器的模块预测目标特征,其输入通常为目标在历史中的几何特征(位置、长宽等)的编码向量和表观特征向量,通过时序模型预测特征向量的变化。JDP 的特征预测与检测阶段的图像处理过程共同进行,通过在检测网络中加入前帧信息或多帧检测完成。
(3)数据关联模块。根据对目标特征的预测结果和当前帧的检测结果和提取的目标表观特征向量(为方便叙述,后文分别称为轨迹特征和检测特征)更新轨迹。如图4所示,DBA的深度关联模型使用检测模型的输出作为输入,直接预测当前的分配矩阵,然后通过分配矩阵识别目标身份。JDA 的数据关联与目标检测同时进行,使用单一神经网络处理输入图像直接推理输出目标的轨迹。

图4 不同框架的在线多目标跟踪对比Fig.4 Comparison of different online multi-object tracking pipelines
为了清楚地展示各类算法的异同,表1总结了每类算法的典型机制以及优缺点。
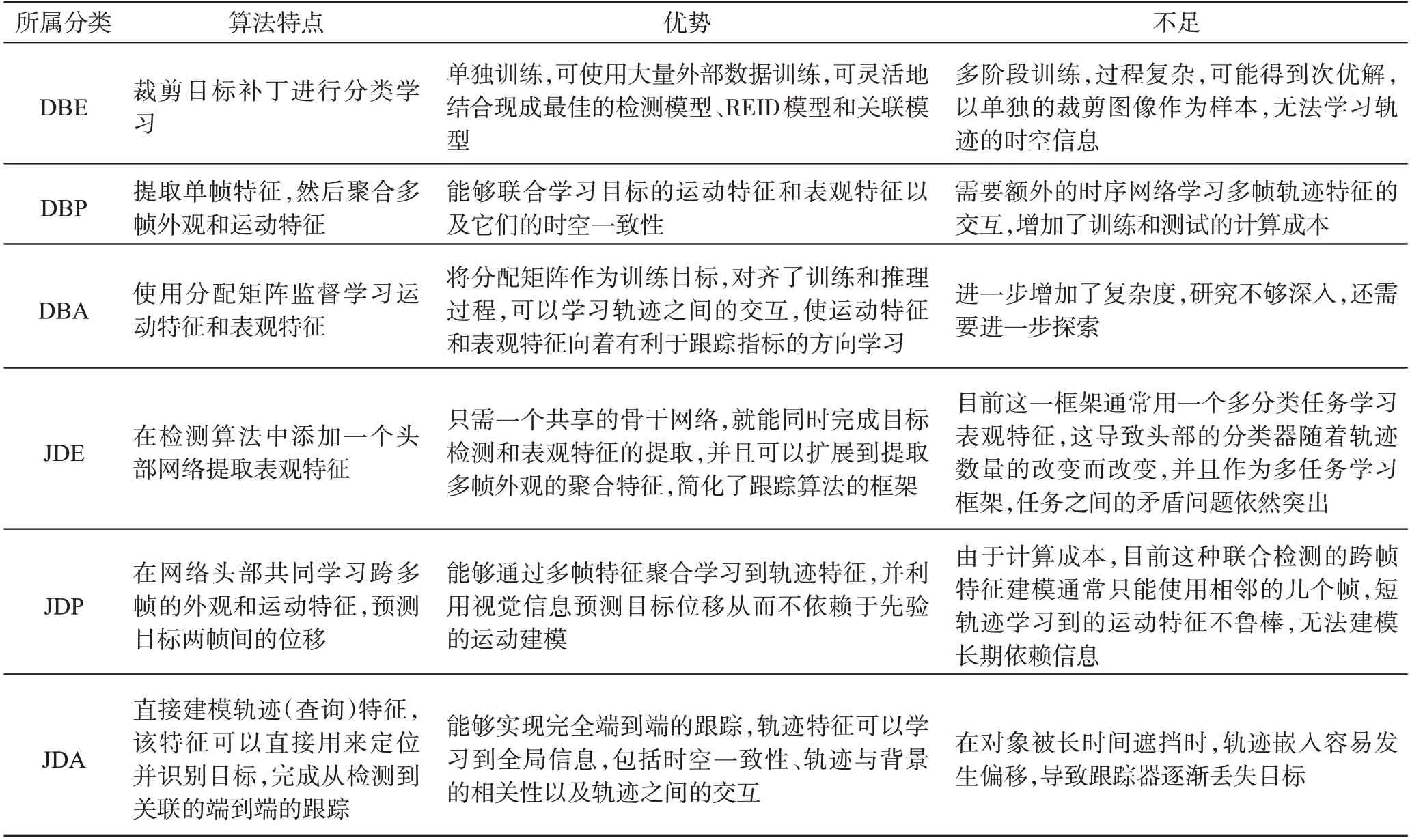
表1 不同类型的在线多目标跟踪算法特点总结Table 1 Summary of characteristics of different types of online multi-object tracking algorithms
本文的贡献主要如下:
(1)全面调查了基于深度学习的在线多目标跟踪方法,重点是从单摄像机视频中提取的2D视频,包括以往综述中未涉及的近期主要工作。
(2)分析整理了深度在线多目标跟踪的两类框架和三个重要模块,分别描述了深度学习模型在这些模块中使用的方法以及优缺点。
(3)收集了不同算法在MOT17和MOT20测试集的结果,对数据进行了分析比较,然后讨论了未来的发展方向。
1 基于深度学习的在线多目标跟踪算法
1.1 基于检测的在线多目标跟踪算法
在线多目标跟踪领域引入深度学习算法后,首先出现了基于深度目标检测器的多目标跟踪算法。这些算法[15-17]在多目标跟踪流程的检测部分加入性能较高的深度学习目标检测器,例如区域卷积神经网络(region-CNN,R-CNN)[18-19]、SSD(single shot multibox detector)[20]和YOLO(you only look once)[21-24],提升在线多目标跟踪算法的性能。典型的SORT(simple online and realtime tracking)算法[15]就基于传统的匈牙利关联算法,使用Faster R-CNN 目标检测网络替换原有的聚合通道检测(aggregate channel feature,ACF),实现了跟踪准确度和速度的大幅提升。后续的研究[6]也表明了检测精度与在线多目标跟踪性能存在高度的正相关。以良好的目标检测结果为前置输入,分别改进目标特征预测模块、表观特征提取模块和数据关联模块的算法都属于基于检测的多目标跟踪算法。下面根据这三个模块分别进行论述。
1.1.1 基于特征重提取的表观特征提取
目标的表观特征被广泛用于多目标跟踪进行关联,相比于一些只使用简单的运动建模的基线跟踪器[6,15,25],目标的表观特征较为稳定,可以更加鲁棒地连接长时间遮挡的目标。例如,DeepSORT[26]在SORT算法的基础上使用在大规模ReID数据集上预训练的ResNet网络[27]提取目标的表观特征,然后将表观特征相似性度量融入到关联代价中进行关联,大幅减少了跟踪过程中目标身份切换的问题。
在基于检测的跟踪范式中,目标的表观特征通过一个额外的网络进行学习,网络的输入为裁剪并对齐的检测图像,如图5 所示。其中ResNet-50[27]、Wide Residual Network[28]以及GoogLeNet[29]均被广泛采用[26,30-39]。通常,这些算法将不同帧间的相同对象视为单独的类,并使用交叉熵损失进行ID分类[30-31,34-35],也有一些算法将来自同一对象的检测视为正样本,来自不同对象的检测视为负样本,然后采用三元组损失(triplet loss)[32,37]或者基于Softmax的对比损失[40]来学习批样本中的区别嵌入。与交叉熵损失相比,三元组损失可以更好地区分不同ID 之间的细微差异,特别是对于颜色和姿态相似的物体。与每次只取三个样本的Triplet loss不同,对比损失比较了批中所有负对的关系,拉近正样本间的相似性。三元组损失由于需要挑选合适的样本对而训练较慢。这种使用裁剪样本重新提取特征的方法有几个优点:首先,这种算法非常灵活,可以替换、组合最优秀的检测模型、外观模型和关联模型;其次,它可以使用大量的外部数据进行训练,与完全标注的视频数据相比,大规模裁剪的图像数据集更容易收集;最后,这些算法会将裁剪的检测图像缩放到统一的尺寸,因此可以缓解目标尺度变化带来的特征不一致问题。同时,这类算法的缺点也很明显:首先,使用一个额外的表观模型单独训练,无法进行全局优化,容易得到次优解;其次,视频中的目标切片可能存在大量背景和重叠目标影响正常分类学习;再次,只学习图像样本的表观特征,无法得到跟踪轨迹的时间信息;最后,推理时需要裁剪所有检测图像再调用外观模型提取特征,比较耗时。

图5 提取检测目标切片的表观特征Fig.5 Extract appearance features of detection object patch
1.1.2 基于时序性建模的特征预测
使用聚合的轨迹表观特征进行数据关联是一个合理的做法。不同于直接比对两个相邻帧目标的表观特征,关联模型通常会使用指数移动平均(exponential moving average,EMA)[41]将轨迹的特征进行聚合,防止遮挡和离群的特征点影响匹配。不同于表观特征关注目标的体貌及姿态,运动特征可以建模目标空间位置和边框尺寸随时间的变化,从而衡量两个检测框是否匹配,对遮挡目标更加有效。
在基于检测的框架中,为了更好地模拟时间线索,许多工作也建模了轨迹的视觉表观特征和运动特征的时空特性。如图6所示,使用一个特征聚合网络建模轨迹的特征,并预测当前时刻的运动以及表观特征。例如,Babaee 等[42]使用长短时记忆网络(long short-term memory network,LSTM)[43]建模目标的运动特征,预测当前帧的目标框;Girbau 等[44]使用一个额外的循环神经网络(recurrent neural network,RNN)循环估计目标的运动,采用RNN来估计模拟物体轨迹的高斯混合模型,有效减少了目标身份切换(ID switch,IDs)的发生。Han等[45]提出一个运动感知跟踪器(motion-aware tracker,MAT),在运动预测时,先使用卡尔曼滤波对目标位置进行预测,然后使用增强相关系数最大化(enhanced correlation coefficient maximization,ECC)模型[46]对齐场景的旋转和平移,并基于运动预测进行插值。ArTIST[47]提出了一个运动代理网络,该网络建立在一个循环的自动编码器神经网络上,学习用历史轨迹线索预测所有目标下一帧边界框的概率分布,单纯依靠运动建模达到了良好的跟踪性能。不同于只建模目标的运动特征,Babaee 等[48]使用特征聚合网络联合推断一对轨迹的视觉外观和时空特性,从而获得更加稳健的特征,提升在目标长期遮挡时的关联效果,特征聚合网络由两个RNN组成。Fang等[49]设计了一个循环自回归网络(recurrent autoregressive network,RAN)迭代优化目标的表观特征和运动特征,然后选择良好的特征构建代价矩阵。由于加入了目标长时间的表观特征建模,因此这一模型对遮挡较为鲁棒,但也会占用较大内存。Wang 等[50]设计了一个基于RNN 的循环跟踪单元(recurrent tracking unit,RTU)建模轨迹外观相似度、运动一致性、检测缺失状态以及检测置信度的长期线索,以此对不同的轨迹进行评分得到最佳轨迹表示,可作为插件接入其他算法中提升跟踪性能。Wang 等[51]使用多头注意来聚合个体检测的特征,并结合三重态损失和交叉熵损失来学习融合目标轨迹的表观特征。Dai等[52]将平均表观特征和时空特征连接起来,然后采用图卷积神经网络(graph convolutional networks,GCN)[53]聚合特征获得长期表观特征。同样,这种额外的特征聚合和预测网络也可以方便地与许多现有跟踪器集成,并且这些算法可以自然地整合来自外观和运动的信息,因此其外观和运动特征可以使用一个统一的模型学习,相比单帧的表观特征,聚合特征和运动特征更加丰富稳定且包含时间信息。然而,额外的时序建模也带来了巨大的计算成本,降低了跟踪速度。
1.1.3 基于匹配的深度数据关联
在线多目标跟踪的数据关联一般被视为二分图匹配问题,通过轨迹特征和检测特征的相似度构建代价矩阵,然后求解分配矩阵。这个问题的解存在两个约束条件:第一,一个检测最多匹配一条轨迹,一条轨迹最多匹配一个检测;第二,分配矩阵使总代价最小,即匹配上的目标之间的总相似度最高。匈牙利算法是求解该问题的一个高效的组合优化方法,已被大量应用于在线多目标跟踪算法中。
一些研究人员也使用深度学习模型解决数据关联问题[54],如图7所示,通常将两帧的目标特征et-1和et两两拼接,利用相关性建模推断两者匹配概率,得到匹配矩阵。例如,DeepMOT[55]提出了一个深度匈牙利网络,使用两次双向循环网络(bidirectional RNN,BRNN)[56]传递代价矩阵中的全局信息,其损失函数根据两个可以微分的评价指标进行设计,使网络输出的分配矩阵更加有利于指标的提升,但是作为一个初步的尝试,模型的复杂度较高。Jiang 等[57]使用二分图结构表示代价矩阵。其中,图的节点由轨迹和检测的特征向量构成,边权值则为代价矩阵的对应元素。然后通过图神经网络融合特征节点间的信息,更新边的权值,从而将匹配问题转化为对边的二分类。相比只利用代价矩阵进行关联的方法,这种关联方式更加充分地利用了目标特征的原始信息。在消融实验中证明这是有效的。Shan 等[58]进一步融合目标在前几帧的位置和表观特征以获取更好的全局时空信息,缓解目标特征随时间变化的问题。Weng等[59]采用图神经网络分多层更新特征节点与边权值,并在每一层中都学习一个分配矩阵,融合所有分配矩阵共同关联,取得了更加良好的关联性能。文献[60]进一步考虑了同一帧中的相邻目标在特征聚合时的干扰,提升了模型对目标遮挡的适应性。Li等[61]认为目标的运动特征和表观特征具有不同的模式,不能简单耦合,于是使用两种不同的图更新策略分别更新目标的表观特征与运动特征,也取得了良好的跟踪效果。近期,Chu等[62]修改Transformer结构使其能够推理图模型。该模型对目标特征进行编解码得到优化后的分配矩阵,能够有效提升对遮挡目标的跟踪效果,在MOTChallenge中名列前茅。

图7 预测帧间目标的匹配得分Fig.7 Predict matching scores for inter-frame objects
利用匹配网络生成轨迹对的匹配得分具有两个好处:首先,它直接将分配矩阵作为优化目标,对齐了训练和推理的过程,使运动特征和表观特征向着有利于跟踪指标的方向学习;其次,拼接同一帧中检测的特征向量,可以学习轨迹之间的判别关系和时间顺序。但是目前基于匹配的深度数据关联的研究依然处于起步阶段,在实际应用中还存在一些问题,例如关联速度较慢,计算成本巨大,不利于实际部署。
可以发现,基于检测跟踪算法的每个模块都可以单独优化,随着各模块性能的提升,算法能达到较高的跟踪精度。例如近期提出的ByteTrack[6]和MAAtrack[63]算法,分别对数据关联等模块进行改进,均达到了SOTA。这类算法的缺点是模块间的耦合度不高,多个模块独立的训练方式可能使模型参数收敛至各自模块的最优,而不是多目标跟踪的全局最优。并且一些模型通过堆叠多个模块、使用更多的深度学习技巧来提高跟踪的效果,导致DBT 框架越发复杂,跟踪实时性达不到在线要求,难以实际部署。
1.2 联合检测的在线多目标跟踪算法
从深度神经网络的结构来看,跟踪器中的目标特征预测、表观特征提取和数据关联模块都可以与目标检测网络相融合,从而降低整体算法的复杂度,同时缓解了手工连接各模块带来的局部优化问题。从结果上看,这类算法推理速度通常更快,并且能够达到与基于检测跟踪算法相当的性能,因此在近两年发展较快。下面根据这三个模块分别进行论述。
1.2.1 基于特征复用的深度表观特征提取
从结构上看,深度目标检测网络包括一个图像特征提取骨干网和一个检测头,目标重识别网络也包括一个图像特征提取骨干网和一个分类头。因此可以让两个网络共享特征提取骨干网,然后在不同的头网络进行检测和表观特征提取,形成一个多任务学习的框架,达到减小模型、提升运行速度的目的。
现有的工作通常遵循最先进的检测算法框架。例如,JDE利用了DarkNet-5的YOLOv3框架[64],添加一个与检测分支并行的ReID 分支,在该分支输出的特征图上抽取正锚框中心点的特征向量作为目标的表观特征向量,如图8 所示。由于共享骨干网,模型结构更加紧凑。然而,正如FairMOT[65]中提到的,预测的anchors 中心可能不落在目标区域,因此锚框机制并不适合训练表观特征,一些作品采用了无锚框架。例如,研究人员[65-67]在CenterNet[68]上构建跟踪算法,在主干架构中使用了深层聚合(deep layer aggregation,DLA)[69],在目标中心点提取特征向量学习表观特征。
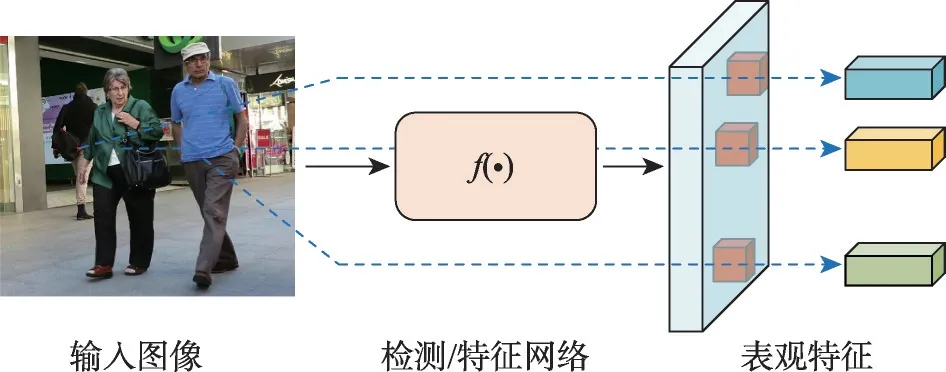
图8 同时进行检测和表观特征提取Fig.8 Simultaneous detection and apparent feature extraction
联合学习检测和Re-ID 的主要挑战之一来自于这两个任务的冲突。检测任务的目的是从背景中识别对象类别,如行人和车辆,而Re-ID 嵌入的目的是区分不同的对象,而不是类别。针对这一问题,一些工作解耦了不同任务的特征图。例如,文献[65,70]使用一个单独的Re-ID 头来学习除原始检测分支之外的表观特征。RetinaTrack[71]设计了特定任务的后特征金字塔网络层进行分类、边界框回归,并同时生成表观特征向量。CSTrack[72]、CSTrackv2[73]通过通道互注意力机制学习检测和重识别之间的相关和差异信息,然后使用多尺度注意力模块提取表观特征。RelationTrack[74]将检测和ReID 与所提出的全局上下文解耦相结合,并使用具有可变形注意力的引导Transformer编码器来提取Re-ID特征。SimpleTrack[66]基于FairMOT模型使用与检测不同的特征融合分支提取表观特征。这些模块设计都增加了特征图在头部网络的建模,丰富了各自任务头与原始特征图的差异,使算法的检测性能和识别性能都有所提升。同样,在单帧图像中提取的表观特征无法获取时间信息,为此,一些研究者使用了多帧特征提取的方式。例如,GSDT(joint object detection and multi-object tracking with graph neural networks)[75]基于FairMOT算法,利用图卷积模型建模轨迹特征与当前特征图的局部相关性,使提取的表观特征包含历史信息,提高了对目标遮挡和变形的适应性。CorrTracker[76]同时学习时空和尺度信息,采用自监督的方式学习目标之间的相似性,限制同一目标的特征距离以增加判别度。这种自监督需要执行M×N次孪生操作,训练更加费时,但跟踪准确度得到明显提升。OUTrack[77]设计了一个基于对关联线索的强弱监督的无监督Re-ID框架。
不同于利用目标切片的特征重提取方法,基于特征复用的表观特征提取方法不依赖于预先训练过的检测器,也不需要额外的计算和存储去裁剪检测框,提高了效率;并且在多帧特征提取方式中不仅可以学习目标间的关系,还能够建模目标与背景之间的联系。但是由于需要同时学好检测和重识别,导致其需要一个庞大的训练数据提高泛化能力,此外,时间一致性在该框架中还没有得到很好的利用。
1.2.2 基于帧间特征融合的特征预测
为了跨多帧学习轨迹的外观和运动特征,建模时间特性并预测轨迹走向,一些研究者以联合检测跟踪的形式用多帧网络或头部聚合网络学习时空特征图进行跟踪。
具体来说,Tubetk[78]以3D-ResNet[27]作为骨干,结合GIOU(generalized intersection over union)[79]、焦点损失[80]和二分类交叉熵损失训练生成短轨迹管道。DMM-Net[81]使用三维卷积预测目标的多帧运动、类别以及可见性,来学习给定多帧的时空嵌入来生成管道。如图9 所示,CenterTrack[82]遵循CenterNet[68]无锚检测框架,在输入端拼接一对顺序帧和前一帧的热图,输出端预测目标中心位置、大小、偏移以及帧间的目标位移,可以同时实现二维和三维多目标跟踪。PermaTrack[83]使用卷积门控递归单元(convolution gated recurrent unit,ConvGRU)编码目标特征的时空演化,捕捉物体的持久性概念以处理被遮挡的目标。Wan等[84]采用基于时间的编码-解码器架构进行多帧预测,同时估计多通道轨迹图,包括存在图、外观图和运动图。TraDeS[85]还使用基于成本体积的关联和可变形卷积[86],聚合多帧信息联合学习目标的二维、三维偏移量和掩膜估计。

图9 多帧检测并预测图中目标的特征变化Fig.9 Detect objects in multi-frame images and predict the altered features
除了使用多帧网络预测轨迹的特征,还有一些工作在头部网络中连接多帧的特征映射来进行预测。例如,Chained-Tracker[87]采用成对的特征在Faster RCNN[7]中进行边界框回归和ID 验证。TransCenter[88]也将Transformer 嵌入到MOT 中,在基于可变形Transformer的编码器和解码器的两个查询学习网络中处理密集的像素级多尺度检测和跟踪查询,获得检测和预测位移。此外,一些研究者基于两步检测器,在第二步中使用跟踪框指导检测,同时传递身份信息进行跟踪[89-91],其中FFT(multiple object tracking by flowing and fusing)[91]还利用光流网络细化运动。
在这一框架中,运动特征可以更加深入地与视觉特征联合。然而,虽然三维神经网络可以学习时间一致性,但也增加了训练和测试的计算成本,导致目前通常只能考虑几个帧的聚合,以至于学习到的时间运动特征不够鲁棒,无法模拟物体的不同运动。而在头部聚合多帧特征的方向虽然大大降低了计算成本,但它可能缺乏用于检测和关联的低像素级关联特征。
1.2.3 基于特征查询的数据关联
受单目标跟踪(single object tracking,SOT)方法的启发,目标位置可以通过轨迹特征和当前特征图之间的相关性来细化。部分研究者将单目标跟踪算法融入到多目标算法中[92],利用单目标算法强大的特征提取和定位能力,可以实现较高精度的端到端跟踪。例如,DASOT(unified framework integrating data association and single object tracking)[93]将数据关联和SOT 集成在一个统一的框架中,基于截断的ResNet-50与特征金字塔网络(feature pyramid networks,FPN)[94]估计时间关联的密集相关特征图。SOTMOT(improving multiple object tracking with single object tracking)[95]建立在DLA-34[69]的一个变体上,为每个对象解决前一帧的岭回归系数,并使用学习到的系数来预测下一帧的标签。因此,可以在局部区域学习鉴别特征。其缺点是随着场景中目标数量的增加,为每个目标分配一个单目标跟踪器将会造成效率问题。近期,随着Transformer[96]的进展,一些研究人员也在多目标跟踪中利用Transformer模型中的查询向量机制,如图10所示,以查询向量学习轨迹的特征在帧间定位并识别目标,隐式地完成数据关联,从而简化复杂、多步骤的架构。
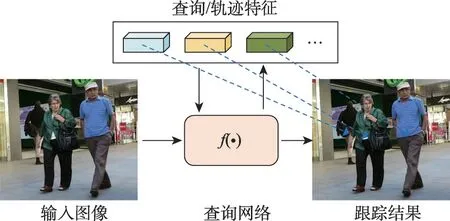
图10 使用逐帧更新的查询特征检测并识别目标Fig.10 Detect and identify objects by query features updated from frame by frame
Meinhardt等[97]最先将Transformer引入多目标跟踪,他们将DETR(end-to-end object detection with transformers)检测器[98]在时间方向上迭代,第一帧使用随机初始化的空查询在图片中检测目标,并输出目标对应的查询,在后续帧中,前一帧的对象查询与随机初始化的空查询一起输入解码器,其中对象查询负责检测轨迹在当前帧的位置并传递身份,隐式地完成数据关联,而空查询负责检测新出现的目标。得益于Transformer 对特征关系的强大建模能力,能够达到不错的跟踪精度。然而,直接混合使用空查询与对象查询容易在轨迹附近将背景识别为目标,并且由于目标的轨迹查询逐帧更新,在轨迹交互过程中查询特征差异性将减小,容易导致目标的身份标识发生互换。为了解决这两个问题,Zeng等[99]提出一个查询交互模块(query interaction module,QIM),该模块去除了在每一帧中都加入新的空查询的设置,而是利用查询交互模块迭代更新所有的查询向量,让单个查询始终跟踪同一目标。这一策略增强了查询向量的历史信息建模能力,显著提升了算法的身份保持能力。TransTrack[100]将目标的查询向量分为了检测对象查询和跟踪对象查询,在原有DETR检测器的解码器外并行添加一个结构相同的跟踪解码分支,两类查询由不同的分支解码得到检测框与跟踪框,然后两类框使用交并比距离度量执行贪婪关联。这一跟踪过程较为简洁高效,取得了良好的跟踪准确度,但由于跟踪查询携带的身份信息不足而导致模型在跟踪时的身份保持能力有所下降。无锚跟踪方式同样也被引入到这一跟踪框架中,TransCenter[88]与CenterTrack框架类似,使用中心点热图跟踪目标。它将跟踪查询扩展成了密集的多尺度跟踪查询,能更好地跟踪到小尺寸的目标。值得注意的是,TransCenter中的查询由编码的输出经查询学习网络(query learning networks,QLN)自适应地学习,由此可以学习到密集的多尺度查询而不用手动设置最大查询数。
以相关性构建的关联算法具有以下优点:首先,利用单目标跟踪的算法可以在其领域中借鉴最先进的方法,当目标被部分遮挡并且未被检测,这种追踪器仍然能够持续跟踪物体,利用Transformer 的算法采用成对的注意力,可以融合全局信息,实现完全端到端的跟踪,并提升跟踪性能。但是,这类算法计算复杂度偏高,不利于部署,并且当长时间遮挡发生时,漂移成为主要问题,跟踪器可能会逐渐失去目标。
联合检测跟踪算法将不同模块与检测网络融合共同优化,期望算法各模块之间能够更加协同地工作,并简化复杂的多步骤形式,从而提升多目标跟踪的速度,在近几年受到广泛关注。目前,这类算法面临的问题是:(1)不同模块共同学习时可能存在不兼容问题;(2)联合训练各模块的数据集不足。
2 数据集介绍及评价指标
2.1 数据集介绍
本节整理了近几年公开的多目标跟踪数据集,总结如表2所示。

表2 多目标跟踪数据集Table 2 Multi-object tracking datasets
2.2 评价指标
多目标跟踪较为复杂,仅使用单一标准无法全面评估其整体跟踪效果,因此当前采用多种指标共同评价多目标跟踪算法的性能。下面简要介绍部分重要的评价指标。
单独考虑视频的检测结果,被正确检测到的目标为正样本,记作TP;未检测到的真实目标为漏检,记作FN;错误的检测为虚警,记作FP。加入对目标身份的考虑,对于一对完整的真实轨迹和预测轨迹,正确预测的轨迹段记作TPA,未预测到的真实轨迹记作FNA,其余的预测轨迹段被记作FTA。跟踪过程中目标身份标识切换的总数记作IDs。此外,FPS指标用于衡量多目标跟踪算法的实时性。给定全序列帧的所有TP、FN、FP、TPA、FNA、FTA、IDs、FPS,多目标跟踪的评价指标如下:
最大跟踪轨迹数量(MT):至少80%被正确匹配的真实轨迹的数量。
最大丢失轨迹数量(ML):低于20%被正确匹配的真实轨迹的数量。

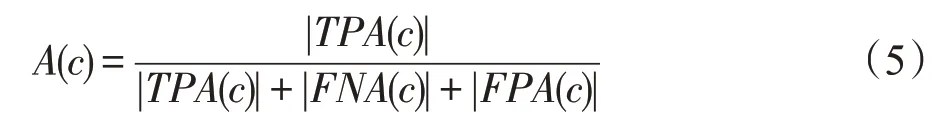
其中,GT是所有真实值的数量,IDTP、IDFP、IDFN分别是在轨迹级别上二分匹配得到的目标身份正正例、假正例及假负例,α为定位阈值,C为某一正样本轨迹TP。上述指标中,多目标跟踪准确度(MOTA)、目标标识精度(IDF1)和高阶度量(HOTA)综合了多种错误,共同作为评价多目标跟踪算法的重要指标。
3 实验分析
为了对当前在线多目标跟踪算法进行分析比较,本章整理了部分在MOTChallenge 挑战赛中的结果。由于检测结果对跟踪整体性能影响较大,报告的结果分为了使用公共检测的算法和使用私有检测的算法。MOT17 数据集包含MOT16 数据集所有内容,应用广泛,MOT20数据集拥有更加复杂的场景和密集的人群,更具挑战性,因此选取MOT17和MOT20两个数据集分析结果,结果如表3和表4所示。表格中展示了算法使用的数据集、MOTA、HOTA、IDF1、FP、FN、IDs以及FPS指标。其中“↑”表示越大越好,“↓”表示越小越好,CH 表示训练时额外使用的数据集CrowdHuman;CP表示额外数据集Cityperson;2D 表示CrowdHuman、ILSVRC15 两个额外数据集;5D1 表示5 个额外数据集(CrowdHuman、Caltech Pedestrian、CityPersons、CUHK-SYS、PRW);5D2 将5D1中的CrowdHuman替换成ETH数据集。
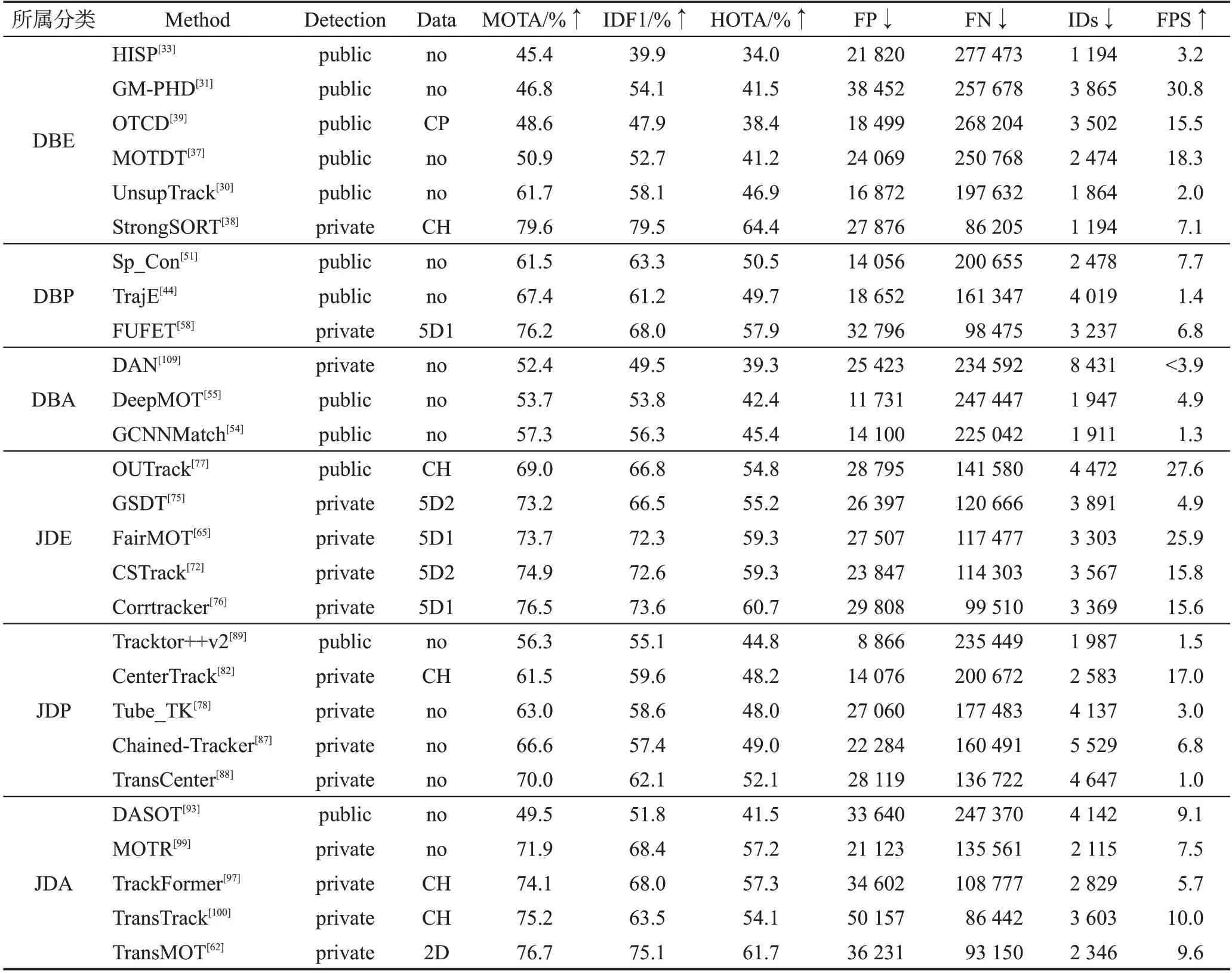
表3 不同算法在MOT17测试集上的实验结果Table 3 Experimental results of different algorithms on MOT17 dataset
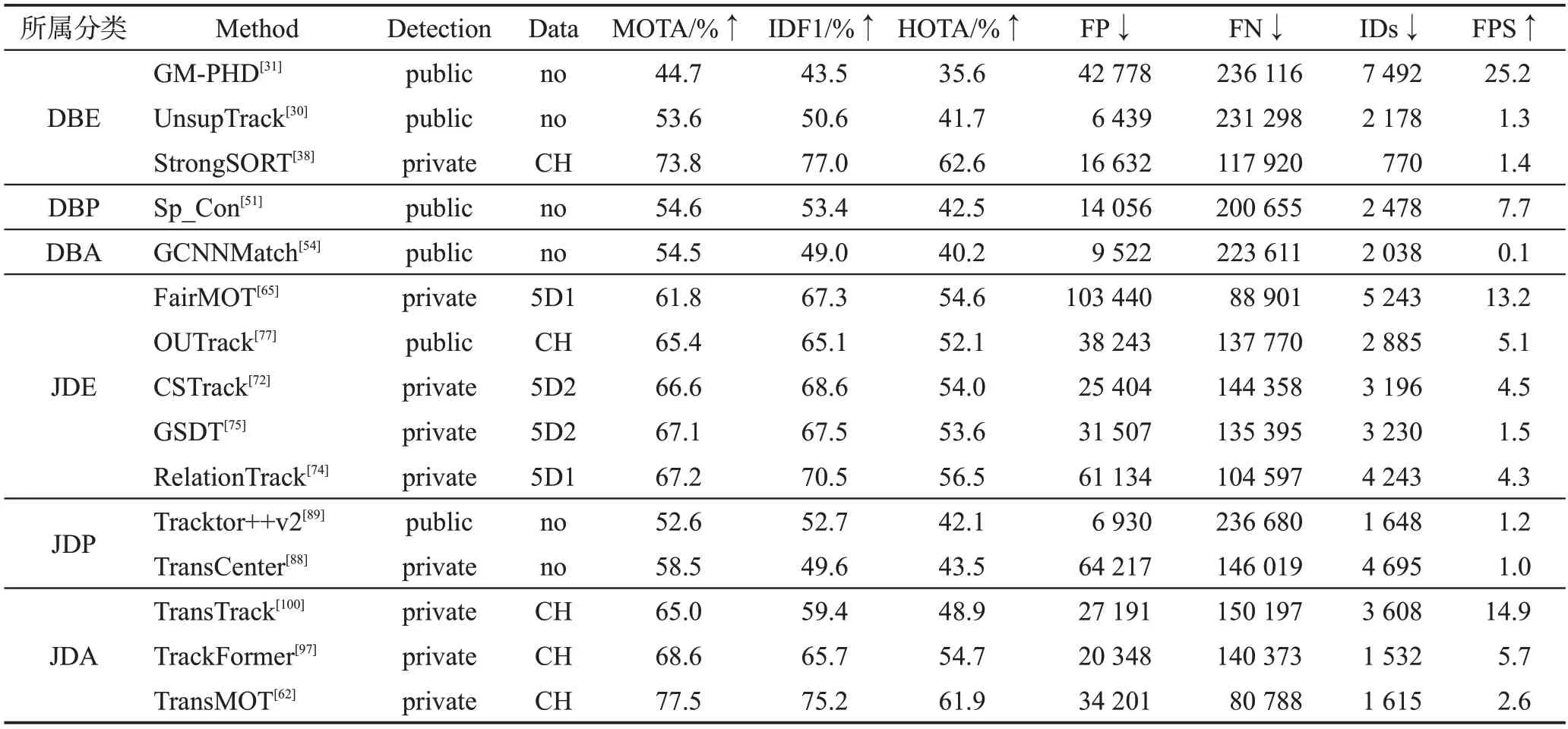
表4 不同算法在MOT20测试集上的实验结果Table 4 Experimental results of different algorithms on MOT20 dataset
根据算法在MOT17和MOT20测试集上的性能,可以发现:
(1)对于这两个数据集,基于私有检测的算法大多明显优于基于公共检测的算法,验证了检测精度对多目标跟踪性能具有显著影响。
(2)使用额外数据集训练的模型通常比不使用额外数据集训练的模型的MOTA 得分更高,表明多样性的数据对模型具有较大影响。
(3)对于绝大部分算法,跟踪结果的漏检数量远高于虚警和身份标识切换数量,因此漏检测是造成MOTA 指标下降的主要原因。漏检大部分来自被遮挡的目标和小目标,因此如何充分利用序列图像信息找回这些目标依然需要更深入的研究。
(4)对目标外观进行显示建模的算法IDF1 得分通常名列前茅,这说明鲁棒的表观特征可以降低数据关联时发生的错误。
(5)部分采用图卷积模型的多目标跟踪算法排名靠前,特别是人群密集的跟踪场景,因为图卷积模型可以有效建模不同目标及背景之间的特征交互,自适应地融合不同特征得到亲和度矩阵,优于手工融合的效果。
4 未来研究展望
(1)数据集的制备。当前主流多目标跟踪数据集中目标的运动模式较为简单,跟踪场景单一,数据多样性不足,跟踪主题大多集中在街道行人与车辆。在行为模式更加复杂、环境干扰较为严重、跟踪目标类别多样或外观较相似等因素下构建数据集是未来可继续研究的方向。此外,由于自然场景中遮挡目标无法成像,导致模型对遮挡目标的建模陷入困境,因此构建虚拟数据集也是未来可研究的方向。
(2)跟踪各模块性能的提升与协同。根据本文分析,跟踪各模块性能的提升都能够对整体的跟踪性能带来有效收益,因此,改进各部分结构或寻找新的框架使模型性能突破现有壁垒、建模数据长期信息是未来重要的研究方向。此外,算法各模块间的协同也是重要的研究方向之一。
(3)数据关联算法研究。当前多目标跟踪在目标检测与特征提取方面都已经广泛应用深度学习,而作为多目标跟踪核心的数据关联算法用深度学习指导依然处于初步阶段,未来需要投入更多的研究。
(4)应用部署。根据本文分析,目前多目标跟踪大多算法无法落地于实际应用,针对这一问题,应当考虑提高当前模型的泛化能力,研究轻量化网络结构以及模型加速方法。
5 结束语
本文对近年来的深度在线多目标跟踪算法进行了调查总结,分析了基于检测跟踪和联合检测跟踪两个不同框架中目标特征预测、表观特征提取和数据关联三个重要模块的优化方法和各自的优缺点,并介绍了多目标跟踪相关的数据集和评估方法。目前,多目标跟踪技术在实际应用中依然存在一些问题,如场景迁移和模型轻量化部署,但其发展必将为现实世界带来更多便利。
猜你喜欢
河北果树(2021年4期)2021-12-02 01:14:50
上海公路(2019年3期)2019-11-25 07:39:28
当代陕西(2019年15期)2019-09-02 01:52:00
福建基础教育研究(2019年10期)2019-05-28 08:27:04
电子制作(2018年19期)2018-11-14 02:37:08
学苑创造·A版(2018年11期)2018-02-01 06:29:20
自动化学报(2017年11期)2017-04-04 02:52:58
读者(2017年5期)2017-02-15 18:04:18
噪声与振动控制(2015年4期)2015-01-01 07:08:21
遗传(2014年3期)2014-02-28 20:58:52
