
RFID数据清洗技术研究进展
2022-12-19 03:00乐嘉锦
计算机与生活 2022年12期
王 健,乐嘉锦
1.河南财经政法大学 计算机与信息工程学院,郑州 450046
2.东华大学 计算机科学与技术学院,上海 201620
无线射频识别(radio frequency identification,RFID)技术具有非接触识别、穿透力强、识别速度快、自动检测、节省人力等众多优点,已经广泛应用于一些需要采集[1]、监控[2]或追踪[3]信息的领域中,例如仓储物流运输、门禁考勤、固定资产管理、车辆识别、行李安检、医疗信息追踪、军事国防安全等[4]。伴随着广泛应用而来的是对高数据质量的迫切需求。
尽管RFID 具有很多优点,但是在面对水和金属时穿透能力相对较弱,易受无线电信号干扰,这种情况下RFID标签的识别准确率就大大降低,造成数据的不可靠性[5]。另外,RFID 标签的长期停留、多读写器的部署、为提高识别率而采取的多个同一标签的粘贴,在系统采集数据[6]时也会造成数据的冗余。在数据传输过程中,由于网络延迟等因素,收集到的数据还会产生乱序的问题。因此,RFID 数据的不可靠性主要包含数据的漏读、多读/交叉读、冗余、乱序等[7]。如果应用端直接使用RFID原始数据,会造成很多问题。因此,预处理系统一般会对RFID原始数据进行清洗,以提高RFID数据的质量。
在对RFID 原始数据清洗的过程中,存在着很多的挑战。这些挑战一般是由RFID 数据流的特点和应用端的需求带来的[8]。RFID数据是突发产生的,因此造成的挑战之一是其产生和到达速度快。只要RFID 数据在采集设备(读写器)的读写范围内,就会产生数据,造成的挑战之二是数据流的总量是无限的。由于RFID 数据在传输过程中遇到不同的网络状况,造成的挑战之三是数据到达次序不受应用约束。查询等应用一般在内存中完成,且内存容量有限,造成的挑战之四是除非刻意保存,一般每个数据只处理一次。RFID标签一般贴于位置经常变动的物品上,造成的挑战之五是数据时效性强,必须在很短时间内处理。
RFID 数据清洗一度成为最流行的研究热点之一,研究者们从各个方面出发,提出了许多高质量的方法。为了方便广大研究者借鉴和使用相关方法,很有必要对RFID 数据清洗技术进行综述。文中介绍了RFID 数据清洗问题的描述,给出了RFID 数据清洗研究的挑战,整理了典型的数据集和评价标准,梳理了现有的RFID数据清洗技术,并从漏读数据处理[9-10]、多读数据处理[9]、冗余数据处理[9]、乱序数据处理[11]、RFID 系统应用[9-10]等方面对RFID 数据清洗技术的现有工作进行了详细的归纳和总结,最后对RFID数据清洗上可能的研究方向进行了展望。
1 RFID系统与数据清洗问题描述
1.1 RFID系统
RFID 系统通常包含以下几部分:RFID 标签、RFID 读写器、RFID 中间件和后端应用系统[12]。其中,RFID标签由芯片和标签天线或线圈组成,通过电感耦合或电磁反射原理与读写器进行通信。RFID读写器是读取/写入标签信息的设备。天线可以内置在RFID读写器中,也可以通过同轴电缆与RFID读写器天线接口相连。RFID 中间件负责数据清洗[13-14]和复杂事件处理等工作。图1为RFID系统的示意图。
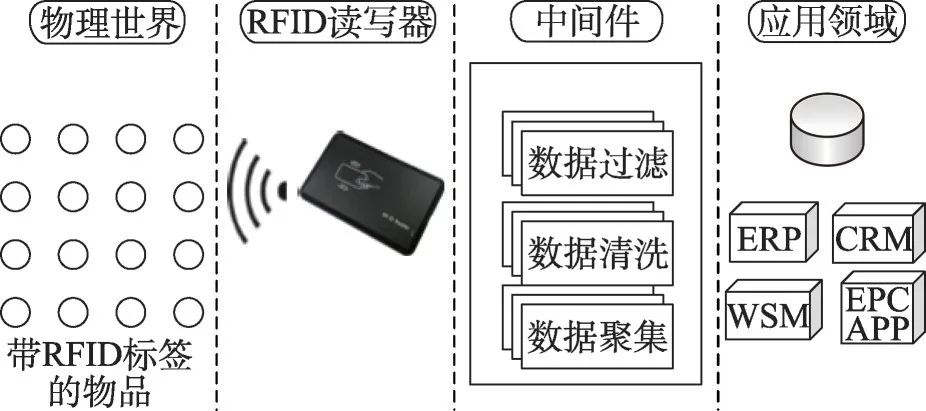
图1 RFID系统Fig.1 RFID system
RFID 标签分为三种类型:无源标签、半无/有源标签和有源标签[15]。其中源的含义是供电电源,这种电源一般具有体积小、使用时间长等特点。
RFID技术的基本原理是:无源标签进入RFID读写器的读写范围内时,接收读写器发出的电磁信号,接着自身产生感应电流,然后凭借感应电流产生的能量将存储于芯片上的信息传递给读写器;若为有源标签,其不需要借助读写器的信号来产生能量,因为其自身带有电源,所以它会主动发出某一频率的电磁波,这样读写器读取电磁波并解码,然后送到中央系统进行后续的数据处理,最后将信息传递给用户或者应用系统[7]。
1.2 RFID数据清洗问题描述
RFID 数据清洗问题主要包括数据的漏读、数据的多读、数据的冗余、数据的乱序等。下面给出相关定义与描述。
定义1(数据的漏读) 也称假阴性读数(false negative readings)[16-18],是指某个或者某些标签实际上已经处于RFID读写器的读取范围内,但是读写器却没有产生相应时间点或者时间段的有关此标签的数据。在RFID数据采集过程中,漏读是一个常见的现象。产生漏读的原因有:(1)当许多标签同时被读写器探测到的时候,无线电波的冲突和信号的干扰经常出现,因此干扰了读写器识别任何一个标签;(2)水、金属或者无线电波的干扰。现有的研究与实验表明,在部署有RFID 设备的应用中,电子标签的识别率通常在60%到70%之间,即超过30%的数据被常规地丢弃掉。图2 给出了一个数据漏读的示意图。在一个货架上放满了带有标签的物品,RFID 读写器读取到了大部分标签的数据,只有个别数据没读到,这就是RFID数据漏读现象。
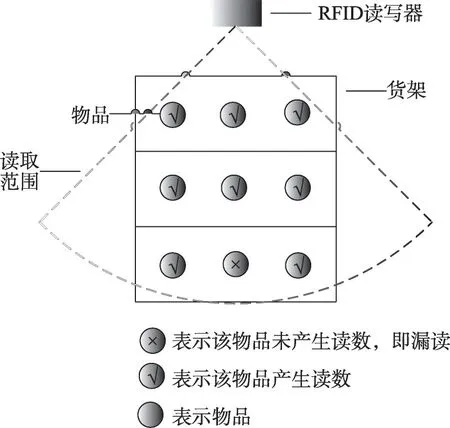
图2 RFID数据的漏读示意图Fig.2 Example of RFID false negative readings
定义2(数据的多读) 也称假阳性读数(false positive readings)、交叉读(cross readings)或噪声(noise)[16-17],是指RFID 读写器不仅读取到了期望的标签,而且也读取到了不期望的标签。这种现象可以归结于以下几种形式:(1)位于RFID 正常读取范围之外的标签被读取到。比如,当在采集一个箱子内的标签数据过程中,读写器可能从邻近的箱子内读到了标签。(2)读写器所处环境中的不确定因素,比如,某读写器产生并传送非其探测范围内的标签中的数据。图3 给出了一个数据多读的示意图。交叉区域内被两个读写器都捕捉到的数据称为多读数据(交叉读数据)。
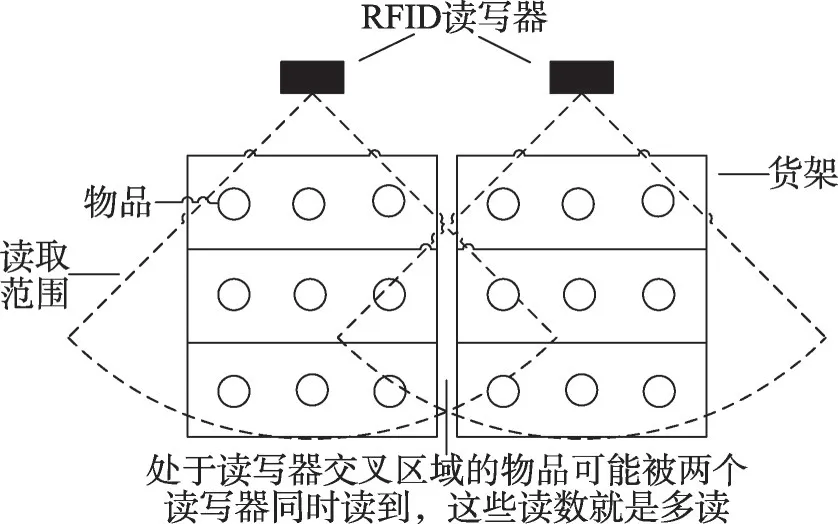
图3 RFID数据的多读示意图Fig.3 Example of RFID false positive readings
定义3(数据的冗余) 英文为duplicated readings[16-17],是由以下几种原因引起的:(1)标签在一个读写器探测范围内停留很长时间,被读写器读取了许多次;(2)在一个大的区域或者长距离的范围内部署了多个RFID读写器,位于读写器重叠区域的标签被读取了多次;(3)为了提高读取精度,许多带有同一标识的标签粘贴于同一物品上,因此产生冗余现象。图4给出一个数据冗余的示意图。该图含义是某个带有RFID标签的数据在不同的n个状态(比如不同位置、不同读写器读写)下产生了多个读数,但是每个状态下有许多冗余,只有每个状态的第一个数据是有效的数据,其他的读数可以丢弃。
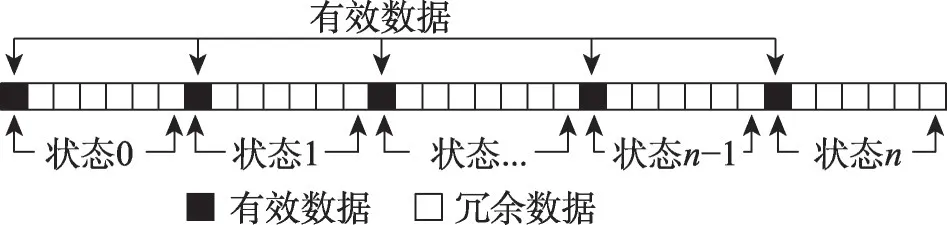
图4 RFID数据的冗余示意图Fig.4 Example of RFID duplicated readings
定义4(数据的乱序) 英文为out-of-order readings[11]。由于不同网络传输中的延迟、拥塞等情况,读写器在工作过程中生成的原本产生时间戳较早但到达时间戳较晚或者原本产生时间戳较晚但到达时间戳较早等非顺序到达。图5 给出了一个数据乱序的示意图。该图含义是在t+1 到t+8 时刻数据1到8 依次产生,然而由于网络延迟等原因经过一定的传输时间,其到达次序就变得与产生次序完全不一样。
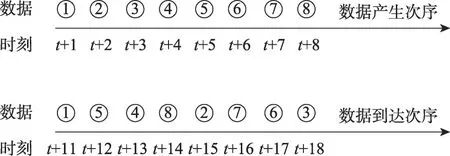
图5 RFID数据的乱序示意图Fig.5 Example of RFID out-of-order readings
定义5(RFID 数据清洗) 是对读写器在工作过程中产生的漏读、多读、冗余读、乱序到达数据进行填补、去伪存真、约减、排序等工作的过程。
2 研究挑战
RFID 数据属于流数据中的一种,其具有流数据的特点[8],这些特点也就形成了若干研究挑战。下面介绍一下比较重要的挑战。
研究挑战1:数据源源不断产生,规模之大难以数计。由于RFID 技术为感知识别,在RFID 读写器开启的情况下,瞬间可以采集多次,比如1 s可以采集1 000次。同时RFID读写器是分布式部署的,这样同时采集多个带有RFID标签的物品,会形成犹如洪水般的数据流,并源源不断地流向应用端。
研究挑战2:数据到达速率极快。RFID 技术感知式采集,采集到的数据通过无线网、有线网、局域网、广电网等不同网络传递到应用端,同时多个网络传输,因此RFID数据流的到达极快。
研究挑战3:数据到达次序不受应用约束。RFID数据来自周围环境,随机发生,你追我赶,多路并发传播,同时也受网络状况的影响,到达的次序与产生时的顺序完全不同。由于不以任何事物的意志为转移,其到达次序也难以预测。
研究挑战4:除非刻意保存,每个数据都只能“看”一次。由于RFID数据规模巨大,受处理机内存大小的限制,该数据无法全部容纳于内存之中。为了快速处理这些数据,只能扫描一遍。在扫描一遍数据情况下,如何完成相关工作时间紧迫。
研究挑战5:数据时效性高,价值转瞬即逝。由于RFID 数据具有独特的时空语义性,带有RFID 标签的物品位置也是在不断变换的,比如带有RFID标签的书籍,可能刚才还在书架上,短时间内就有可能被学生借走,出现在借阅处。如果为了实时监控每一本书籍的情况,就需要不停地处理带有时空信息的RFID数据,距离当前时刻越近的数据越具有应用价值。
3 数据集与评价标准
本章将会介绍典型的RFID 数据集以及RFID 数据清洗的评价标准。
3.1 数据集
高质量与合适场景的数据集对RFID 数据清洗方法的验证与评估非常重要。本节总结了两个广泛使用的RFID数据集。表1给出了相关数据集的基本信息,比如数据集名称、年份、来源、描述、文件数量、网址等。

表1 常见RFID数据集Table 1 Typical RFID datasets
hope/amd 数据集是从2008 年7 月18 日至20 日举行的第七届HOPE(地球上的黑客)会议上收集的RFID跟踪数据。与会者佩戴了RFID徽章,通过该徽章可以在整个会议空间内唯一地识别和跟踪他们。贡献者是Aestetix和Christopher Petro。2008年8月7日上传于CRAWDAD(community resource for archiving wireless data at Dartmouth)网站,该网站是达特茅斯的无线数据存档社区资源。网址为https://crawdad.org/hope/amd/20080807。数据集中有13个文件,总数据量约为25 MB,包含了与会者参会期间的位置信息。
hope/nh_amd 数据集是从2010 年7 月18 日至20日举行的HOPE(地球上的黑客)会议上收集的RFID跟踪数据。目的与hope/amd数据集一致。贡献者是Travis Goodspeed 和Nathaniel Filardo。2010 年7 月18 日上传于CRAWDAD 网站。具体下载地址为https://crawdad.org/hope/nh_amd/20100718。数据集中有33个文件,且每个文件的数据量都接近100 MB,总的数据量约为3.1 GB,同样包含了与会者参会期间的位置信息。
3.2 评价标准
由于本研究方向的评价标准表达形式多样,不能一一列举,这里只给出具有代表性的评价标准。
精确度指的是清洗后的数据Dc与真正数据Dr的交集占真正数据Dr的比重。定义如式(1)所示:

数据压缩率指的是原始数据Draw与数据清洗过后的数据Dc的数据量的差值占真正数据Dr的比重。定义如式(2)所示:

吞吐量指的是处理过的数据量|Draw|与所用处理时间T的比值。定义如式(3)所示:

运行时间是指算法运行稳定时处理数据流所需要的时间。
4 RFID数据清洗
本章主要从漏读数据清洗、多读数据清洗、冗余数据清洗、乱序数据处理、RFID系统应用等方面来总结现有方法的基本思想、优势、局限和适用场景。
4.1 漏读数据清洗
Jeffery等人[19]提出一种称为ESP(extensible receptor stream processing)的数据清洗方法。其在时间滑动窗口中平滑RFID数据,并将多个读写器分组在一个空间粒度中,以纠正漏读数据(亦称假阴性数据或误报)并去除异常值。然而,很难确定不同RFID 数据的最佳窗口大小,尤其是在移动环境[20]中。在这样的环境中,重要的是确保两个应用需求(完整性、标签动态)之间的平衡。完整性:确保所有在读写器范围内的RFID标签都被检测到。标签动态:捕获标签在读写器检测范围内进出的动态。通过设置较大的窗口大小来消除数据的漏读,可以确保数据的完整性,但它们在检测标签跃迁时效率不高,还引入了多读数据(假阳性)。然而,窗口大小设置较小时能够检测到RFID标签的移动,但不能补偿漏读数据。
Jeffery 等人[17]提出一种自适应滑动窗口清洗方法,称为不可靠RFID 数据的统计平滑(statistical smoothing for unreliable RFID data,SMURF)。SMURF把RFID流数据看成统计学中的随机事件,并在系统的整个生命周期内不断地根据流数据的统计学特点自适应调整窗口大小(不会向应用程序公开平滑窗口参数),从一定程度上提高了漏读数据填补的精确度。然而当监控对象在某逻辑区域内的读数完全丢失时,该方法的清洗效果较差。
Massawe 等人[21]采用SMURF[17]中提出的统计方法,给出了一种称为窗口子范围跃迁检测(window subrange transition detection,WSTD)的RFID 数据流自适应清洗方案。其具有更高效的标签迁移检测机制。WSTD能够调整窗口大小,以应对环境变化导致的标签和读写器整体性能波动,同时相对准确地检测迁移时间点。然而,由于使用的窗口较小,它会产生更多的漏读数据。
现有的清洗技术专注于设计在各种条件下都能很好工作的精确方法,但忽视了在可能有数千个读写器和数百万个标签的应用场景的高昂开销。Gonzalez 等人[22]提出了一个清洗框架,该框架采用RFID 数据集和一系列清洗方法以及相关开销,并通过确定廉价方法适用的条件,得出一个清洗计划,进而优化整体清洗开销。该框架所考虑的开销主要包括三方面:一是机器学习中的训练开销;二是存储与运行开销;三是分类错误时所需要的开销。具体的清洗方法主要是基于滑动窗口的平滑过滤填补方法,还可以是用户自定义方法,其中窗口包括静态和动态窗口。文中还介绍了基于决策树和贝叶斯的数据清洗方法,根据不同数据特征进行最优清洗策略,以达到总体开销最小。该方法只解决了漏读现象,如何解决多读、冗余、乱序到达等问题,还有待进一步研究。该方法的优点在于考虑了观测值和估计值,然而这些估计值与观测值的关系是由历史数据集得到的,不能动态更新,因而对动态标签的清洗结果也不十分理想。
Baba等人[23]重点研究了原始室内RFID跟踪[24]数据中的漏读现象。其研究有限制,即室内空间数据,有限制的同时还可以利用时空约束进行数据清洗。其次,利用概率距离感知图模型[25]来识别和填补漏读数据。另外,该方案还可以应用于其他类型的符号化室内跟踪数据的清洗,例如蓝牙跟踪数据。该方法的优点是利用了时空约束信息,应用领域较广,但局限于室内物品产生的数据。
Gu等人[26]通过有效维护和分析监控对象的相关性,提出了RFID漏读数据的填补模型。监测对象之间的时空相关性用于填补漏读数据。突破了大多数RFID数据清洗算法只是根据独立监测对象的历史读数来填补缺失的读数的情况。
在深入分析RFID对象[27]的关键特征之后,Xie等人[28]提出一种用于高效处理不确定RFID 数据的框架,并支持各种查询和跟踪RFID 对象。特别地,提出了一种自适应清洗方法,根据不确定数据的不同速率调整平滑窗口的大小,采用不同的策略处理不确定数据,并根据不确定数据出现位置区分不同类型的数据。还提出一种路径编码方案,通过聚合路径序列、位置和时间间隔来显著压缩海量数据。该方法的优点在于自适应调整窗口大小,融入了时空信息,考虑了群体和单个物体的运动。局限在于规则设置不合理、不完整等都会影响清洗效果。
Baba 等人[29-30]提出一种称为IR-MHMM(indoor RFID multi-variate hidden Markov model)的数据清洗方法。该方法是一种基于学习的数据清洗方法,可以应对RFID源数据中存在噪声(多读、交叉读数)和不完整性(漏读)的问题。与现有方法不同,该方法不需要关于室内空间和RFID 阅读器部署的时空特性的详细先验知识。该方法只需要有关RFID 部署的最少信息(室内拓扑、设备部署),就可以从原始RFID 数据中学习相关知识,并使用它来清洗数据。该方法的优势是不需要关于室内空间和RFID 阅读器部署的时空特性的先验知识,只需要少量RFID部署信息。然而,局限于室内物品产生的数据,局限于马尔可夫模型。
现有RFID 漏读数据填补方法以原始读数为粒度,在此基础上进行窗口平滑操作,其会填补许多冗余数据。在多逻辑区域参与的场景中,填补准确度较差。为了改变上述状况,谷峪等人[31]首次将RFID数据从数据层抽象到逻辑区域层作为处理的粒度,提出3 种基于动态概率路径事件模型的数据填补算法,通过挖掘已知的区域事件的顺序相关性来对后续发生的事件进行判断和填补。该方法的优势在于对漏读数据进行了填补,并考虑了实时性、准确性和维护代价等因素。局限在于未考虑包含相同的区域事件问题;未考虑依次经过多个逻辑区域时,每个逻辑停留时间的相关性。
为了同时解决RFID 数据采集过程中存在的漏读、多读和冗余问题,Jiang等人[32]探索了利用通信信息进行RFID 数据清洗,并使RFID 读写器在早期阶段产生更少的脏数据。首先,设计了一个读者通信协议,以有效地利用读者之间的通信信息。然后,提出了带参数的单元事件序列树。最后,提出了三种新的RFID 数据清洗方法,分别用于减少重复、消除误报和填补缺失数据。该方法有一个假设,即读写器之间可以相互通信,但是实际情况还有所差别,也许在未来是可行的。
在很多RFID 监控应用中,监控物体都是以动态变化的小组为单位进行活动的。谷峪等人[33]通过定义关联度和动态聚簇对各个RFID 监控物体所在的小组进行动态的分析[34],并在此基础上定义了一套关联度维护和数据清洗的模型和算法,通过压缩图模型,提出了基于分裂重组思想的链模型关联度维护策略,提高了维护的时空效率。该方法的不足是:当逻辑上的小组频繁分裂重组时,性能会大大降低。
Xie等人[35]考虑如何有效地识别移动输送机上的标签。考虑到现实环境中的路径丢失和多径效应等情况,研究者首先提出了一个RFID标签识别的概率模型。基于该模型,根据输送机上的固定路径移动,提出了识别移动RFID 标签的有效解决方案。该方法的优势在于考虑概率传播。局限在于事先设定好路径,超出该路径范围,处理效果不确定。
现有的工作主要集中在静态环境中的RFID 数据清洗(例如库存检查)。为了补充现有方法的不足,Zhao 等人[36]提出一种移动环境中目标跟踪RFID数据的清洗方法。首先提出了一个移动环境中目标跟踪的概率模型。同时,设计了一种基于贝叶斯推理的方法,用于使用该模型清洗RFID数据。为了从运动分布中采集数据,设计了一种顺序采样器,该采样器能够以高精度和高效率的方式清洗RFID 数据。该方法的优势是适用于漏读率比较高的移动环境,利用了物品之间的时空关联。局限在于概率计算来自于历史数据。
Fazzinga等人[37]提出了一种离线清洗技术,用于将RFID 跟踪的移动物体产生的读数转换为地图上的位置。它包含一个基于网格的双向过滤方案,其中嵌入了一个用于解决缺失检测(漏读)的采样策略。首先按时间顺序处理读数:在每个时间点t,根据该时刻产生的位置信息与前一时间点t-1 过滤后的位置的可达性进行过滤。然后,对经过第一次滤波后的位置进行重新过滤,并按相反顺序应用相同的方案。随着两个阶段的进行,在每个时间点t逐步评估每个候选位置的概率。该概率集合了过去、未来、实际位置的概率。在第一个过滤阶段的某些步骤中进行采样,智能地减少在下一步被视为候选位置的单元数量,因为它们的数量在连续缺失检测(漏读)的情况下会急剧增加。该方法能做到很高的精确度,但是不能满足实时的应用需求,只能做后续离线分析[38]之用。
现有RFID 数据清洗方法主要针对静态标签,没有考虑动态标签的特性。对于动态标签进出读写器探测范围的时间检测存在延迟,清洗效果并不理想。针对RFID 数据流不准确性和不能及时响应标签跃迁的问题,王妍等人[39]首次在RFID 数据流清洗中引入卡尔曼滤波,提出了一种称为KAL-RFID(Kalman radio frequency identification)的数据清洗方法。该方法通过时间更新和测量更新形成自回归逼近真实值,从而改善了由滑动窗口引发的漏读和多读问题。该方法还可以及时检测标签发生跃迁的时间,避免现有清洗方法在动态标签离开阅读器时易产生的多读现象和对标签发生跃迁的时间响应延迟问题,从而提高了清洗效率。该方法解决了单个读写器的漏读、多读数据的问题,以及动态标签跃迁产生的延迟问题。
表2给出了几种典型的RFID漏读数据清洗方法的对比,包括分类、子类、代表性工作、优势、局限、适用场景等内容。
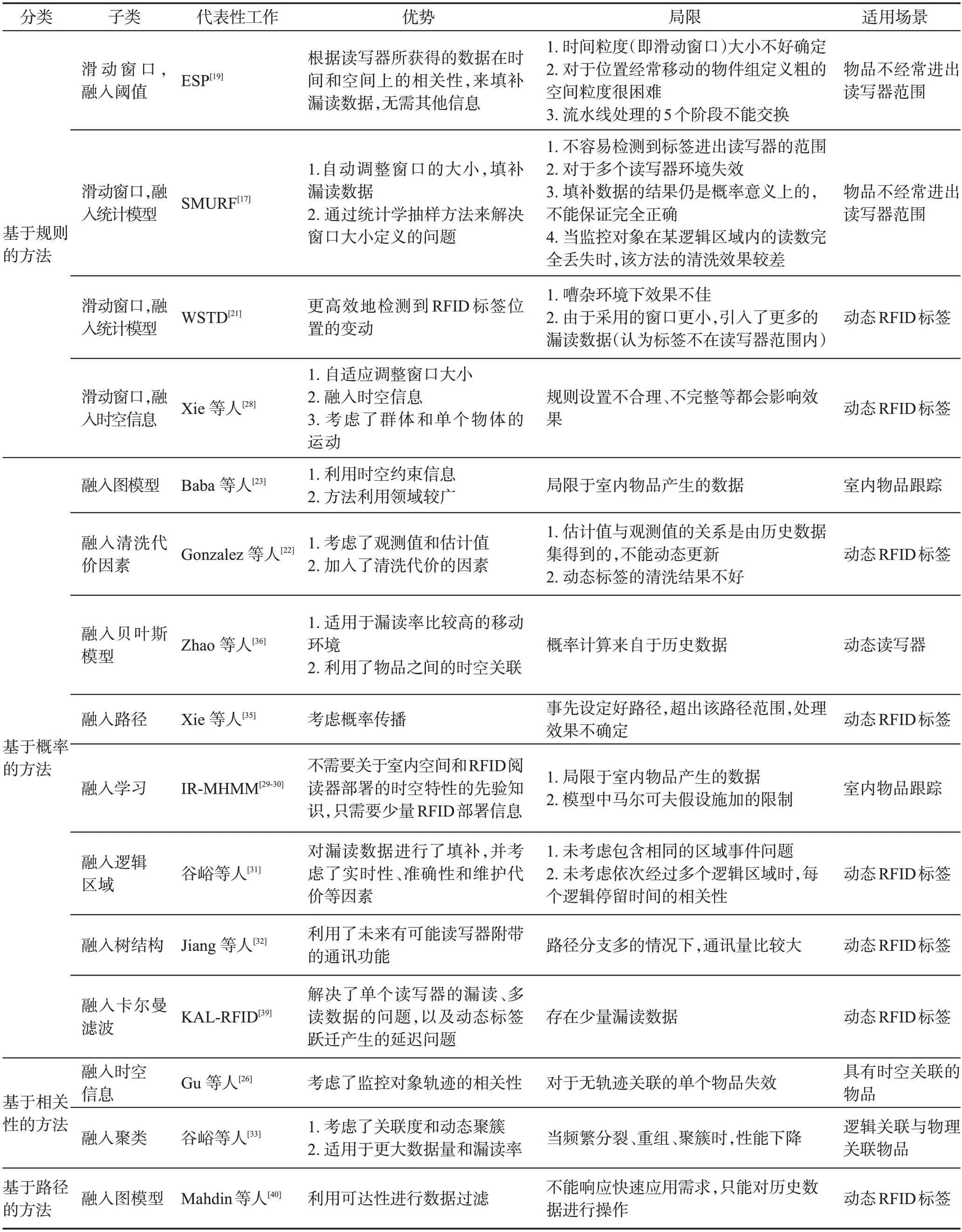
表2 典型RFID漏读数据清洗方法对比Table 2 Comparison of methods of RFID false negative reading cleaning
4.2 多读数据清洗
RFID 数据的多读又称为交叉读,其产生的因素很多,比如环境的干扰、射频技术的限制等。RFID数据的交叉读问题会导致位置信息冲突,进而无法满足RFID 上层应用的需求。为此,Liao 等人[41]提出了一种基于内核密度的概率清洗方法(kernel densitybased probability cleaning method,KLEAP)来消除滑动窗口中的交叉读数。该方法使用基于核的函数估计每个标签的密度。与具有最大密度的微集群相对应的读写器将被视为标记对象在当前窗口中应定位的位置,从其他读写器获得的读数将被视为交叉读数。该方法的优势是能检测到标签的确切位置,局限是滑动窗口大小是固定的。
SMURF方法[19]可以调整窗口大小以减少交叉读数据,但不能消除物理因素产生的交叉读取。
Bai等人[16]使用一种简单的计数方法去除交叉读数,该方法基于交叉读数通常比正常真实读数的发生率低的假设。然而,该方法的有效性与计数阈值直接相关,如果用户没有太多的领域知识,计数阈值很难设置。此外如果交叉读数的数量大于正常的真实读数,该方法可能会产生错误的过滤结果。
潘巍等人[42]提出了利用参考标签思想结合信号强度[43]特征的相对定位技术来解决交叉读仲裁的问题,设计并实现了基于滑动窗口的交叉数据读入检测和仲裁的核心算法。该方法的优势是巧妙地利用了读写器的信号强弱,同时辅以参考标签,利用相对位置推测标签位置。不足之处是其中用到的窗口大小不能自适应调整,还不适用于非规则布局的应用场景。
表3给出了几种典型的RFID多读数据清洗方法的对比,包括分类、子类、代表性工作、优势、局限、适用场景等内容。
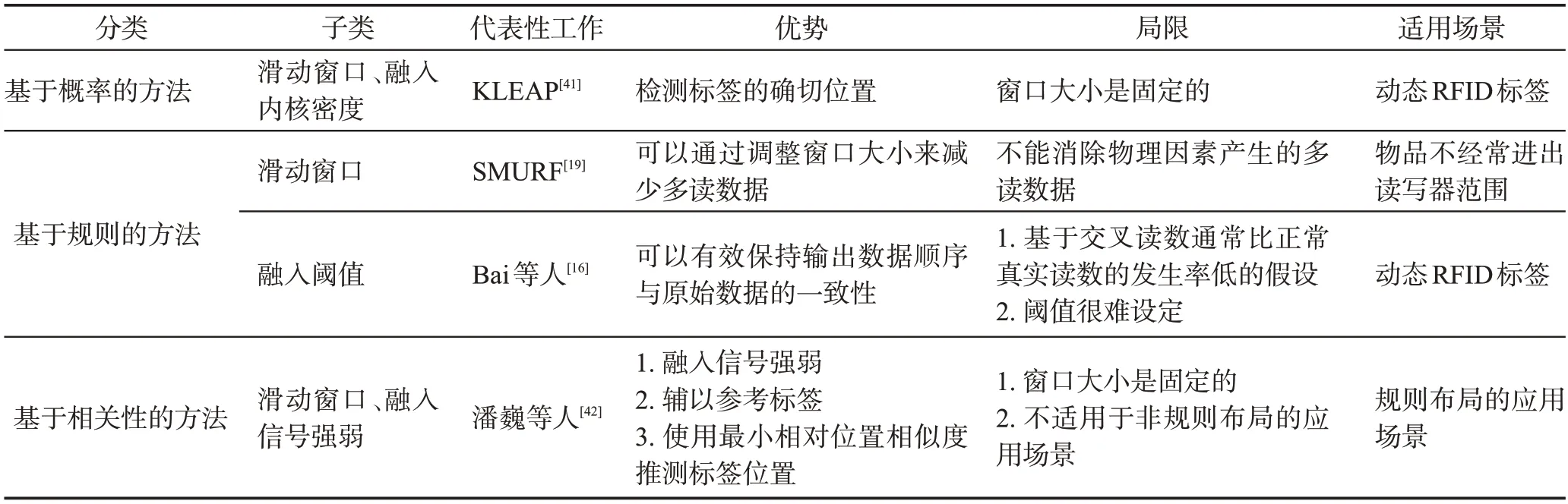
表3 典型RFID多读数据清洗方法对比Table 3 Comparison of methods of RFID false positive reading cleaning
4.3 冗余数据清洗
在RFID 系统中,一个RFID 读写器或部署到同一区域的一些RFID 读写器多次读取RFID 标签,因此RFID 数据流中存在大量重复项。Wang 等人[44]发现现有的基于时间布鲁姆滤波器(time Bloom filter,TBF)的重复消除方法需要多个计数器来存储RFID数据流中元素的检测时间,从而浪费了宝贵的内存资源。为了改变上述情况,其设计了d-左时间布鲁姆滤波器(d-left time Bloom filter,DLTBF),作为d-左计数布鲁姆滤波器的扩展。通过d-left 散列(一种平衡分配机制),DLTBF可以将检测到的元素时间存储到一个计数器中。在此基础上,提出了一种基于DLTBF 的一次性近似消除RFID 数据流中重复项的方法。不过,其在插入数据之前需要计算最小装载桶。此外,它还使用了许多散列函数。
通常,RFID 数据流包含大量重复数据。由于RFID数据是流数据,其产生源源不断,很难用少量内存一次性消除重复的RFID数据。因此,Lee等人[45]提出了基于Bloom滤波器的近似重复消除方法,即时间Bloom 滤波器(TBF)和时间间隔Bloom 滤波器(time interval Bloom filter,TIBF)。在时间Bloom 过滤器中,将Bloom 过滤器中的位数组替换为时间信息数组,因为RFID数据中重复项的定义与检测到的时间有关。此外,为了减少冗余数据,时间间隔Bloom 过滤器使用时间间隔来处理。实验结果表明,所提出的方法可以在一次过程中以较小的误差去除重复的RFID 数据。该方法内存效率不高,因为需要多个时间计数器来存储读取时间。
针对现有方法不能满足处理海量RFID 数据流的实时性要求的问题,Mahdin 等人[40]提出了一种称为CBF(comparison Bloom filter)的数据过滤方法,可以有效地检测和删除RFID 数据流中的重复读数。其优势是将布隆过滤器的数量减少至1个,同时在时间和空间上都有很好的性能。不过其只能过滤一个读写器的冗余数据,且使用了许多哈希函数,滑动窗口在标签运动不规则的情况下效果不好。
Baba 等人[46]研究了室内RFID 跟踪数据的数据清洗。其关注两个相关的任务:消除时间冗余和减少空间歧义。对于前者,设计了一个临时清洗算法来临时聚集原始RFID读数,从而在不丢失信息的情况下压缩数据大小。对于后者,设计了一种空间清洗技术。同时,提出了一个距离感知部署图来捕获RFID读写器部署以及室内拓扑结构所隐含的时空约束。通过利用图中捕捉到的时空约束,设计了一种空间清洗算法来减少RFID 数据中的空间模糊性。本文提出的技术也适用于其他符号定位技术(如蓝牙)获得的室内跟踪数据。其局限在于不容易设定时间和空间粒度的大小。
表4给出了几种典型的RFID冗余数据清洗方法的对比,包括分类、子类、代表性工作、优势、局限、适用场景等内容。
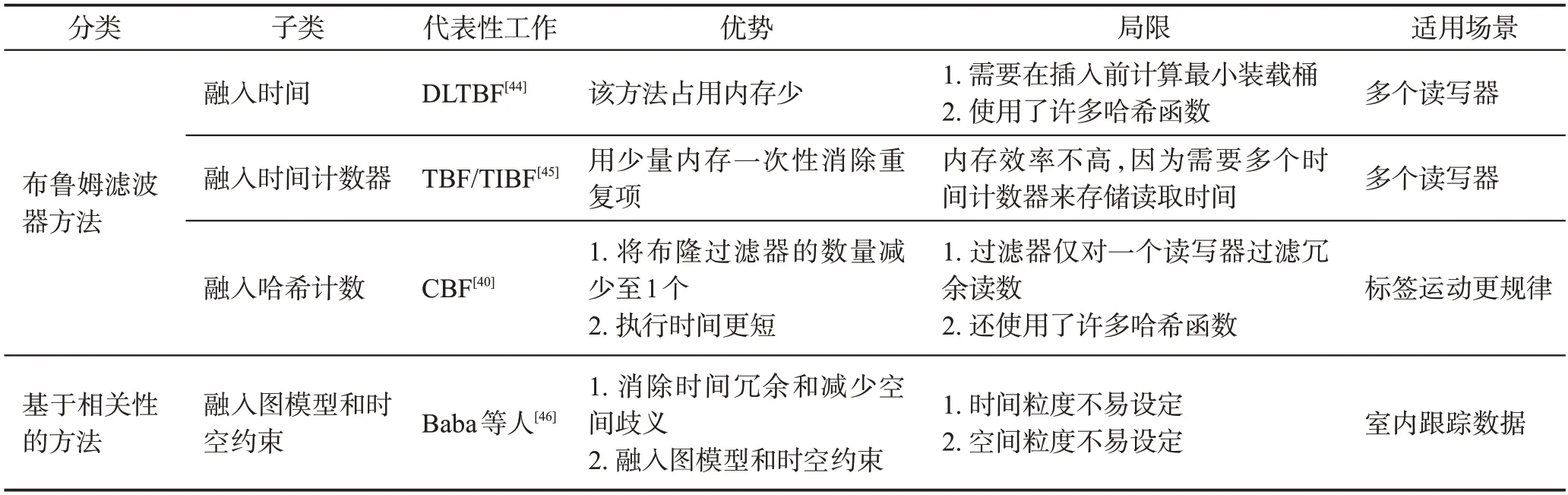
表4 典型RFID冗余数据清洗方法对比Table 4 Comparison of methods of RFID duplicated reading cleaning
4.4 乱序数据处理
现有的方法无法处理存在基于事件的系统(event based system,EBS)时由网络延迟引入的乱序事件到达的情况,而且乱序事件处理可能导致系统故障。为此,Mutschler等人[47]提出了一种基于K时间宽松(K-slack)的低延迟方法。该方法在没有先验知识的情况下实现了对高数据率传感器和事件流的有序事件处理。在不使用本地或全局时钟的情况下,动态调整空闲缓冲区以适应数据流中的乱序。中间件系统透明地重新排列事件输入流,以便事件仍然可以聚合和处理到满足应用程序需求的粒度。在实时定位系统(realtime locating systems,RTLS)上,该系统在乱序事件到达的情况下能够执行准确的低延迟事件检测,并且当系统分布在多个线程和机器上时,具有接近线性的性能。该方法局限在于滑动窗口的大小是固定不变的,不能适应网络延迟的实时变化。
网络延迟、机器故障等因素可能会导致事件在事件流处理引擎中乱序到达。Li 等人[48]解决了在可能包含乱序数据的事件流上查询指定的事件模式的问题。首先,研究者分析了典型的事件流处理技术在面对乱序数据到达时会遇到的问题。然后,研究者为核心流代数操作符(如序列扫描和模式构建)提出了一种新的物理实现策略,包括基于堆栈的数据结构和相关的清除算法。还介绍了序列扫描和构造以及状态清除的优化,以最小化CPU 成本和内存消耗。不过,该方法还存在一定量的误配或者错位事件,同时结果也存在一定的延迟。
乱序处理涉及延迟和生成的连接结果质量之间不可避免的权衡。为了满足流应用程序的不同需求,需要提供用户可配置的结果延迟与结果质量的权衡。现有的乱序处理方法要么不提供这种可配置性,要么只支持用户指定的延迟约束。为此,Ji等人[49]提倡质量驱动的乱序处理思想,并提出了一种基于缓冲区的m路滑动窗口连接(m-way sliding window joins,MSWJ)乱序处理方法。该方法在满足用户指定的结果质量要求的同时,最小化输入排序缓冲区的大小,从而减少结果延迟。该方法的核心是一个分析模型,它建模了输入缓冲区大小与生成结果质量之间的关系。该方法也是通用的,它支持具有任意连接条件的m路滑动窗口连接。优点是允许用户指定结果质量要求,在保证处理结果质量的前提下,尽可能减少延迟时间;缺点是缓存容量的减少和质量的保证,促使实时性要求较高的应用无法使用该方法的处理结果。
现有的事件流处理技术在遇到乱序数据到达时遇到了重大挑战,比如输出阻塞、较长的系统延迟、内存资源溢出和不正确的结果生成。为了解决这些问题,Liu等人[50-51]提出了两种备选解决方案:分别采用激进策略和保守策略来处理乱序事件流上的序列模式查询。在乱序事件很少出现的乐观假设下,激进策略产生最大输出。相反,为了解决乱序事件的意外发生以及由此产生的任何过早错误结果,为激进策略设计了适当的错误补偿方法。保守方法是在乱序数据可能很常见的假设下工作的,因此只有当其正确性得到保证时才会产生输出。提出了一个偏序保证(partial order guarantee,POG)模型,该模型下可以保证这种正确性。对于尖峰工作负载下的健壮性,这两种策略在持久存储支持和用户访问方法上相互补充。不过,该研究还未能实现在两个策略间自动切换。
在乱序数据流上执行连续查询是一项挑战,其中元组不是根据时间戳排序的;因为高准确性和低延迟是两个相互冲突的性能指标。尽管许多应用程序允许以精确的查询结果换取较低的延迟,但它们仍然希望生成的结果满足一定的质量要求。然而,现有的乱序处理方法没有考虑在满足用户指定的查询结果质量要求的同时最小化结果延迟。Ji 等人[52]提出一种基于缓冲区的自适应乱序处理方法AQ-Kslack(approximate query-K-slack),它支持以质量驱动的方式对乱序数据流执行滑动窗口聚合查询。通过采用基于采样的近似查询处理和控制理论领域的技术,该方法在查询运行时动态调整输入缓冲区大小以最小化结果延迟,同时遵守用户指定的查询结果错误阈值。该方法的优点是同时考虑准确性和低延迟,动态调整缓冲区的大小,允许用户指定结果的阈值;缺点是结果既不是最准确的,也不是延迟最短的。
网络延迟和机器故障可能会导致事件乱序到达。此外,现有文献假设事件没有持续时间,但许多实际应用程序中的事件都有持续时间,并且这些事件之间的关系往往很复杂。Zhou等人[53]首先分析了时间语义学的基础知识,接着提出了一个时间语义学模型。还介绍了一种包含时间间隔的混合解决方案,用于处理乱序事件。在未来,该方案还可以考虑其他影响因素,比如缓冲区的大小、乱序比例、乱序事件的平均步长,以便找到平衡点。
现有的事件流处理技术主要提供尽最大努力(best-effort)式的服务来减少平均响应时间,这种方式并不能在确定的时间延迟需求下输出更多的结果。针对监控应用中的确定性服务质量需求,谷峪等人[54]讨论了常见的泊松监控流上的截止期敏感[55]的复杂事件处理最优化资源分配问题。从系统服务角度对事件的到达和复杂事件处理进行了理论分析和建模,提出了复合事件的截止期满足率模型和多事件流处理乱序反馈修正模型,进而给出最优化资源分配模型。通过合理地分配处理资源,保证了在实时限制下产生更多的正确结果,兼顾了复杂事件处理的实时性和正确性。
表5 给出了典型RFID 乱序数据清洗方法的对比,包括分类、优势、局限、适用场景等内容。

表5 典型RFID乱序数据处理方法对比Table 5 Comparison of methods of RFID out-of-order reading cleaning
4.5 应用系统
由于RFID 数据清洗属于数据预处理环节,没有专门的RFID 数据清洗系统,大部分RFID 应用系统是RFID复杂事件处理系统、RFID不确定事件处理系统。下面介绍相关系统并重点介绍与数据预处理相关的应用。
美国加州大学伯克利分校的Gyllstrom 等人[56]开发和设计了原型系统SASE(stream-based and shared event processing),其提供扩展的事件语言、事件查询处理器和操作优化策略等,实现了对数据的收集和清洗、基本事件生成、复合事件处理、事件归档以及对事件的查询。然而,SASE忽略了时间这一关键因素,而在许多RFID应用中,有些事件只有在指定的时间限制内或限制之后才被认为是“有效事件”。同时,SASE还假设所有事件是按照其时间戳排序的,但该假设并不适用于所有的RFID场景,比如乱序的情形。
美国马萨诸塞大学Tran等人[57]以带有RFID标签的对象固定、读写器移动为应用场景设计和实现了RFID概率推演系统,旨在将缺失的、带有噪音的原始数据流清洗成带有较精确位置的事件流。该推演系统适合于仓储管理等这类货物相对固定、读写器随着使用人员移动的应用。
移动和应用程序通常依赖RFID 天线或传感器等设备向其提供有关物理世界的信息。然而,这些设备是不可靠的。它们产生的部分数据可能丢失、重复或错误。目前的技术水平是局部校正误差(例如,温度读数的范围限制)或使用空间/时间相关性(例如,平滑温度读数)。然而错误通常仅在全局设置中才明显,例如,已知存在的对象的读数缺失,或停车场的读数与进入读数不匹配。美国华盛顿大学的Khoussainova 等人[58]设计了名为StreamClean 的系统,该系统使用应用程序定义的全局完整性约束自动纠正输入数据错误。由于通常不可能确定地进行纠正,研究者提出了一种概率方法,其中系统为每个输入元组分配正确的概率。
美国华盛顿大学的Khoussainova等人[59-60]介绍了概率事件抽取器(probabilistic event extractor,PEEX),一个使应用程序能够从RFID 数据中定义和提取有意义的概率高层事件的系统。PEEX 能有效地处理数据中的错误和事件提取的固有模糊性。同时,PEEX提取了所有可能的活动。此外,由于PEEX基于关系数据库管理系统(relational database management system,RDBMS),用户可以方便地查询和管理生成的事件。由于该系统的目标是从错误和不准确的RFID数据中检测事件,传感器和RFID数据清洗领域是该工作的补充。该系统直接对不准确和肮脏的数据进行操作,而不需要用户指定如何清洗数据。
美国华盛顿大学的Ré等人[61]设计和实现了原型系统Lahar。该大学的研究人员给出了一个真实的应用场景,他们在办公楼里的公共场合部署设计和实现了原型系统Lahar。该大学的研究人员给出了一个真实的应用场景,他们在办公楼里的公共场合部署了一些RFID读写器,并且给相关的物品也贴上了电子标签,通过该系统实时监测和跟踪[62]楼内人员的工作和日常生活,必要时给予友善提醒。在数据预处理方面,Lahar 通过粒子滤波技术填补漏读数据并推演标签对象位置的概率分布。在事件处理方面,Lahar系统可以对归档数据和近实时数据执行复杂事件查询。总之,该系统提出了不确定概率事件流之上的复杂事件处理系统,兼顾考虑了数据流上事件的关联性。该系统局限在于只能简单地回答查询,且要求处理的数据是有序的。
Cascadia 系统[63]提供了面向普适RFID 应用的基础结构,管理漏读数据的不确定性、位置信息的不确定性、事件语义的不确定性和事件发生时间的不确定性。在复杂事件建模方面,其构建了概率事件模型。在数据预处理方面,其接收读写器读取的原始数据,并用粒子滤波技术将原始读数清洗成带有位置信息和概率的时间。与文献[57]系统不同,Cascadia系统中读写器的位置是固定的,只能过滤出粗粒度的位置信息。Cascadia系统贡献主要是针对RFID数据的不确定性构建了RFID 概率数据模型并实现了概率事件抽取算法,支持面向RFID移动对象跟踪等复杂应用。
表6给出了几种典型的RFID数据清洗应用系统的对比,包括系统名称、功能描述、贡献、局限、适用场景等内容。

表6 RFID应用系统对比Table 6 Comparison of RFID application systems
5 未来研究方向
RFID 是一种很有前景的技术,其在新兴领域的应用必将给RFID 数据清洗技术带来新的机遇和挑战。为了丰富和完善RFID数据清洗技术,有待从以下五方面做进一步的研究:
(1)构建高质量的RFID 源数据集和RFID 基准测试数据集。现有的用来做实验的RFID 源数据集基本没有公共的数据集,一般都是研究者根据实验情况人工生成的[64],这样的数据缺少权威性和通用性,因此一般没有二次利用价值。如果能够在实际场景中生成一个或者若干高质量的源数据集,对于相关研究方向的广大的科研工作者无疑是一个福音。建议从以下方面保证RFID源数据集的质量:一是RFID数据产生环境尽可能拥有不同等级的噪声、干扰等情况;二是RFID数据在传输过程尽可能包含延迟、拥塞、丢包等情况。同时,广大科研工作者提出的相关RFID数据清洗技术对于源数据的处理也没有统一可用的结果,这样大量相关新技术到底孰优孰劣无从评价,因此构建一个高质量的RFID 基准数据集也是很有必要的。同样,建议从以下方面保证RFID基准测试数据集的质量:一是测试数据应该尽可能少;二是测试基准数据应该覆盖更广泛的业务类型。
(2)如何对加密RFID 数据和具有隐私保护[65]的数据进行数据清洗。安全性[66]是一个倍受使用者关注的问题。例如,一些公司不希望其他竞争对手能通过货物上的RFID 标签追踪到货物的行踪及货物种类。同样,用户在使用贴有RFID标签的与金融信息相关的设备时,不希望与用户帐户相关的信息遭到泄露[67]。为此,科研工作者设计了一些用于RFID标签对可信读写器认证的加密算法,用于标签对读写器实现身份认证,通过认证的读写器才能获取RFID标签中的信息。然而,认证过程耗时,如何设计满足安全性与隐私要求的高性能算法就显得尤为重要。
(3)读取准确率需要提高。数据完整并且正确性是决定RFID 系统性能的重要因素[68],在读写器作用域内,多个标签同时向读写器发送数据或者一个读写器在另一个读写器的作用域内时,信号间发生相互干扰,导致读写器接收到的数据错误,即无法完整识别出标签,或者识别出错误的标签[69]。因此,多目标识别既是RFID的最大优势,也是亟待解决的技术难点。虽然早在2009 年,美国某个知名企业就宣称其单品RFID库存管理系统能提供99%的店面库存可见度,然而在现实操作中,由于算法原因、人员问题和流程问题而引起的误读仍是RFID 技术普及道路上的绊脚石。另外,有媒体报道,在“无人零售店”的体验过程中,也有购买两件同样的商品只能识别出一件,以及因为粘贴太紧密而无法识别金属易拉罐商品的情况出现。
(4)大数据时代,要充分考虑清洗结果的时效性。在大数据时代,数据量大已经不是研究者关注的主要问题,最主要关注的问题应该是数据处理的时效性。如何在非常短的时间内把海量的RFID 数据进行处理,这就是大数据处理面临的最大的挑战。RFID数据的大量应用都是实时或者近实时的应用,如果不能对这些数据进行及时处理,这些RFID数据的价值就消失殆尽,这就是RFID大数据处理最大的挑战。
(5)设计一个没有固定限制的适用范围更广的方法。通常,现有的RFID数据清洗算法大多基于某种情况的假设,比如有的假设标签移动读写器固定[70],有的假设标签固定读写器移动,有的物品间有时空关联,有的假设物品布局规则,有的假设多读写器场景,有的假设数据符合某种分布等,一旦转换场景该方法的性能就大打折扣甚至不可用。因此,在今后的研究中,很有必要设计出一种自学习的算法,系统算法能分析现有情况属于何种场景,从而从库中选择出合适的数据清洗算法,使得性能达到最佳。如果一种数据清洗算法效果不好,可以有选择多种算法的能力,这样的算法也正迎合了人工智能时代的要求。
6 总结
本文旨在回顾RFID 数据清洗技术的研究进展情况,以帮助相关科研人员对该领域的全面了解。本文对RFID数据清洗相关研究进行了全面回顾,给出了RFID系统与RFID数据清洗问题的有关定义与描述,列出了典型的数据集与评价标准,从相关技术的分类、子类、基本思想、优势、局限、适用场景等方面详细比较和总结了现有的RFID数据清洗工作,同时给出了相关应用系统。最后,从RFID原始数据与基准数据集构建、加密与隐私保护数据的清洗策略、数据采集准确率、清洗结果的时效性、场景自学习的全面方法等方面提出了RFID 数据清洗领域五个未来有前景的研究方向。
猜你喜欢
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中国公路(2017年19期)2018-01-23
中国公路(2017年15期)2017-10-16
中国公路(2017年9期)2017-07-25
中国公路(2017年7期)2017-07-24
Coco薇(2015年11期)2015-11-09
少儿科学周刊·少年版(2015年2期)2015-07-07
中国交通信息化(2014年4期)2014-06-05
北京航空航天大学学报(2013年6期)2013-12-19
