
基于神威·太湖之光的非结构网格计算加速算法
2022-12-13 13:51:46许乐安虹陈俊仕张鹏飞武铮
计算机工程 2022年12期
许乐,安虹,陈俊仕,张鹏飞,武铮
(中国科学技术大学计算机科学与技术学院,合肥 230026)
0 概述
近几十年来,计算流体力学(Computational Fluid Dynamics,CFD)呈现蓬勃发展的态势,在学术界与各学科相互交叉,科研成果日新月异,在工业界与各领域深度结合,成为辅助工程设计的新兴技术。非结构网格是有限元和有限体积等数值方法中最常用的离散网格,在CFD 计算中具有重要意义,需要基于硬件架构精细调优以保证其良好的性能优势。非结构网格计算一般表示为稀疏矩阵运算,其更新时的随机访存加剧了数据存储的离散性。随着网格规模的增加,离散访存的规模也在成倍增加,在带宽受限的计算系统中成为主要性能瓶颈。离散访存的计算特点使得并行化时也会出现多个计算任务同时访问相同元素的写后读冲突和写写冲突问题。
神威·太湖之光计算机系统[1]是世界上第一台峰值性能超过十亿亿次量级的超算系统,使用完全自主研制的申威26010 异构众核处理器[2]。但非结构网格在众核处理器上的计算普遍存在离散访存、数据依赖等问题,并行化难度较高。此外,有依赖关系的算子和对称矩阵的计算进一步提高了在众核处理器上实现高性能非结构网格计算的难度。
为了解决非结构网格计算中有依赖关系算子在众核处理器上的优化问题,本文对大量稀疏网格数据进行分析,从网格本身结构和数据之间的关系出发,提出自适应和无依赖的任务划分策略,使任务划分方法与具体算子不产生绑定关系,从而提高对不同类型算子的普适性。根据主从核架构的特点,本文提出N 阶对角染色算法平衡主从核计算,并在从核计算时摒弃传统的寄存器通信操作,便于扩展到新一代神威平台。此外,考虑到计算访存重叠技术是申威处理器的常见优化策略,本文利用该技术进一步提升计算效率。
1 研究背景
1.1 申威异构众核处理器
神威·太湖之光计算机系统是我国首台完全自主研发的世界第一超算系统,也是我国目前使用最广泛的高性能计算平台之一,为经济和社会发展提供了有力支撑。神威·太湖之光超算系统由高速计算系统和辅助计算系统及配套的互连网络和存储系统组成,配备精准的资源调度系统和丰富的并行编程环境。系统由40 960 块申威26010 处理器构成,内存空间为1 024 TB,访存总带宽为4 473 TB/s,峰值运算速度达到125PFLOPs,比其他同量级超算系统节能60%以上。
申威26010 处理器是我国通过自主核心技术研制的全新异构众核处理器,支持64 位申威指令集。申威处理器由4 个同构核组构成,每个核组内有1 个控制核心(主核)和64 个计算核心(从核),共享统一编址的8 GB 主存,如图1 所示。
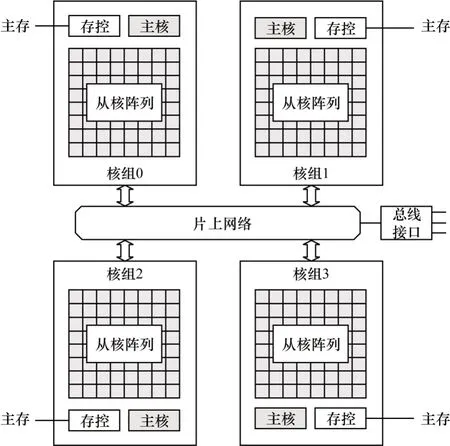
图1 申威26010 处理器架构Fig.1 The architecture of SW26010 processor
在申威26010 处理器中:主核负责任务分发和调度,工作频率为1.45 GHz,L1 Cache 为32 KB,L2 Cache(数据和指令Cache 混合)为256 KB;从核负责稠密计算,工作频率为1.45 GHz,指令Cache 为16 KB。从核采用64 KB 的局部存储(Local Data Memory,LDM)代替硬件Cache,需要用户手动完成数据的换入换出,有利于充分利用片上存储空间,但也给编程带来极大挑战。
申威处理器98%的计算性能来源于从核阵列,因此,挖掘从核架构特性、充分利用从核计算资源十分重要。稀疏矩阵运算的计算强度远低于稠密矩阵,为达到较高的性能,需要更高访存带宽的支持,而申威处理器访存性能不佳,因此,必须充分利用从核访存机制来尽可能降低开销。
从核可以通过gld/gst 指令直接对主存进行访问,但基准测试显示gld/gst 的延迟很高,达到上百节拍数,带宽低于1.5 GB/s,因此,在密集访存时一般不作考虑。在通常情况下,从核使用DMA 操作连续访问主存数据可获得明显的性能提升。DMA 操作带宽如表1 所示。

表1 DMA 操作带宽Table 1 The bandwidth of DMA operation
DMA 操作是指从核LDM 和主存之间的数据传输,它只能由从核线程发起,有单从核模式(PE_MODE)、行模式(ROW_MODE)、广播模式(BCAST_MODE)、广播行模式(BROW_MODE)和行集合模式(RANK_MODE)5 种,一般情况下常用单从核模式。此外,从核还支持跨步DMA,即按照一定跨步间隔连续访问主存。
在每个核组中,64 个从核构成8×8 的从核阵列,从核间的数据交换通过寄存器通信机制(Register Level Communication,RLC)进行,该机制以生产者/消费者模式运行,各从核以1 个向量长度为单位在其行或列上进行数据广播和接收。如图2 所示,源从核首先将256 位对齐的数据加载到寄存器中,然后通过发送缓冲区(Send Buffer)将它们发送到从核通信网格;目的从核通过接收缓冲区(Receive Buffer)从通信网格中获取数据,并将其加载到本地寄存器。
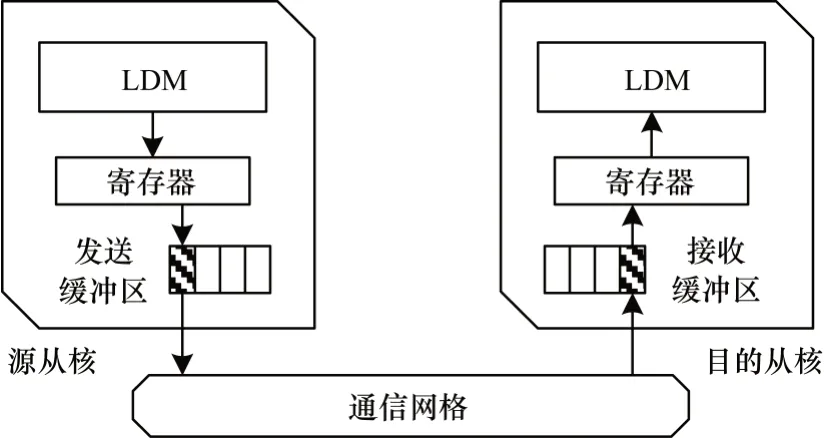
图2 寄存器通信机制原理Fig.2 RLC principle
寄存器的通信延迟通常低至几个周期,如表2所示,这使得从核间的数据可以快速交换,但每个从核只能通过行广播向同一行中的一个或多个从核发送数据,或通过列广播在同一列中发送数据,这给数据的自由传输带来极大限制,不利于开发有复杂依赖关系的从核程序。

表2 寄存器通信延迟Table 2 Register communication latency
1.2 相关研究
近年来,CFD 数值模拟软件作为高性能计算领域中的重要应用,已经广泛部署于众多超算平台上。商业软件因其平台适配性强和稳定性高,曾是非结构网格计算软件的主流,如Fluent[3]、UMS3D[4-5]、FUN3D[6-7]、TAU[8]、CFD++[9]、NSU3D[10]等,但其内部源代码不对外公开,很难精准解决用户需求。相比而言,开源CFD软件可以满足用户不同的开发需求,如OpenFOAM(Open source Field Operation And Manipulation)[11]、Featflow[12]、Gerris[13]、Code_Saturne[14]等,其中,OpenFOAM是目前应用范围最广、可扩展性最强、解算器最全的开源软件包。
CFD 软件中的核心部分是高精度数值求解器,越来越多的研究人员开始使用异构加速方法来改进线性方程组的求解。BOLZ等[15]首次在GPU 上实现了高效的SpMV 算子,此后,基于ELLPACK格式,BELL等[16]设计HYB存储格式实现了SpMV,而VÁZQUEZ等[17]、MONAKOV等[18]和CHOI等[19]分别设计了ELLPACK-R、sliced-ELLPACK 和blocked ELLPACK 存储格式。
基于CSR格式,KOZA等[20]提出了CSMR格式以提高数据重用,GREATHOUSE等[21]和ASHARI等[22]分别提出CSR-adaptive和ACSR格式以解决负载均衡问题。此外,MERRILL等[23]和LIU等[24]还分别提出MCSR和CSR5格式,取得了良好的性能提升。对于分块问题,BULUÇ等[25]、ASHARI等[26]、LIANG等[27]和YAN等[28]分别提出了CSB、BRC、HCC和BCCOO存储格式。
在国产申威处理器上,文献[29]基于CSR 格式提出动静态优化方法,其相比主核实现取得了6 倍的加速效果,文献[30]进一步提出双边多级划分方法,相比主核实现取得了12 倍以上的加速效果。文献[31]基于非结构网格实现了稀疏下三角方程求解器,文献[32]提出基于排序思想的通用众核优化算法以减少非结构网格计算中的随机访存,随后,文献[33]提出两阶段优化方法以克服大规模不规则访存和带宽利用率低的问题。
2 非结构网格计算
OpenFOAM 是一款对连续介质力学问题进行数值计算的开源C++类库,因其模块化和可定制程度高,目前已成为超算平台上主流的CFD 软件。OpenFOAM基于C++语言开发,利用操作符重载、继承和模板等面向对象特性,支持数据预处理、数据后处理和自定义偏微分方程求解,框架内提供网格生成、有限体积法、线性方程组求解、输入输出处理等功能。
如图3 所示,OpenFOAM 中非结构网格一般通过邻接矩阵表示,而非结构网格的稀疏性又使得邻接矩阵为稀疏矩阵。稀疏运算计算强度低,在众核处理器上仍有很大的优化空间,因此,本文基于申威处理器提出非结构网格计算的通用加速框架。
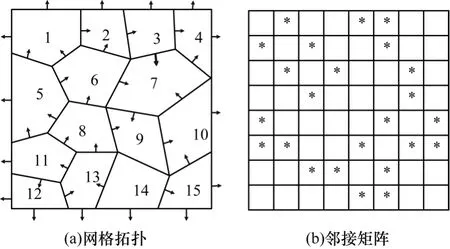
图3 非结构网格及其矩阵表示Fig.3 The unstructured gird and its matrix representation
2.1 基础数据结构
OpenFOAM 中稀疏矩阵按照LDU 格式存储,矩阵上除对角线元素外各非零元素用一个三元组(行号,列号,数值)表示,如图4 所示。
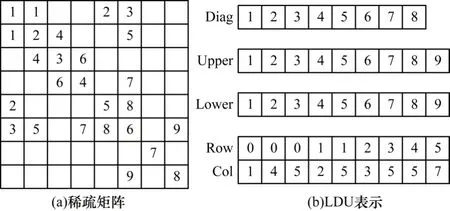
图4 LDU 存储格式Fig.4 LDU storage format
整个稀疏矩阵分为对角部分(Diag)、上三角部分(Upper)和下三角部分(Lower),对角线元素即网格顶点数据,上三角和下三角元素为网格边数据。上三角元素的行索引(Row)对应下三角元素的列索引(Col),而上三角元素的列索引对应下三角元素的行索引,数据可以使用相同的索引数组存储。在从核并行计算时,虽然矩阵上三角每行元素按序排列,但是下三角每行元素并不连续,访问下三角元素时很难满足空间局部性。
2.2 计算特征分析
非结构网格能够适应各种复杂结构的面网格划分,是流体力学仿真软件中最主要的空间离散化解决方案。非结构网格计算存在3 种模式,即顶点状态更新(点更新)、边状态更新(边更新)和通过邻居顶点与邻接边更新顶点状态(边点更新)。
如图5 所示,边更新计算特征为S(e)=f(S(e),S'(v1),S'(v2)),典型计算函数为S(e)+=∑(S'(vi))。
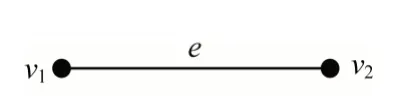
图5 边更新模式Fig.5 The edge update mode
如图6 所示,点更新计算特征为S(v)=f(S(v),S'(e1),S'(e2),S'(e3),S'(e4),S'(e5)),典型计算函数为S(v)+=∑(S'(ei))。
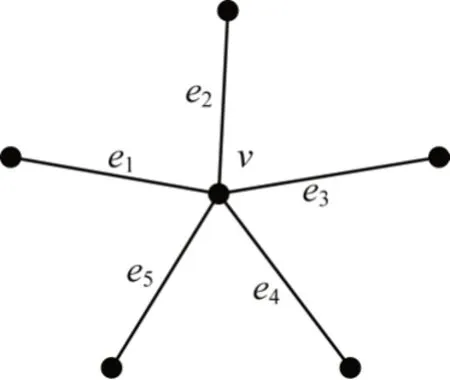
图6 点更新模式Fig.6 The point update mode
如图7 所示,边点更新计算特征为S(v)=f(S(v),S'(e1),S'(e2),S'(e3),S'(e4),S'(e5),S''(v1),S''(v2),S''(v3),S''(v4),S''(v5)),典型计算函数为S(v)+=∑(S'(ei) ·S''(vi))。
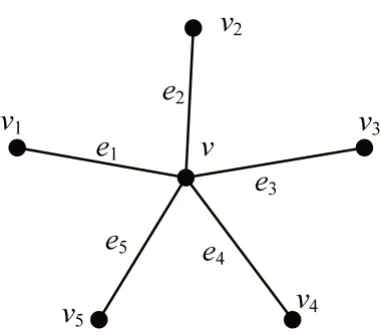
图7 边点更新模式Fig.7 The edge and point update mode
3 种模式的共同特征在于状态信息在顶点与边之间流动。本文将边视为基本单元,顶点视为连接单元,计算过程则为遍历非结构网格的所有边,获取每条边上左右顶点状态,并与边自身状态进行运算,最终用运算结果更新左右顶点状态或边自身状态,如表3 所示。

表3 非结构网格计算模式Table 3 Unstructured grid computing mode
由于数据关系的依赖性和对数据访问的离散性等固有特点,导致非结构网格计算具有局部性差、数据相关、离散访存、并发度低等问题,在众核处理器上进行优化时难度较大,性能偏低。
3 基于申威处理器的众核加速方法
3.1 算法思想
由于非结构网格的稀疏性,导致算法在计算时对元素访问并不连续,无法充分利用访存带宽。此外,非结构网格的离散宽度(稀疏矩阵中非零元素与该行对角线元素之间的距离)较大,造成访存间隔过大,难以满足空间局部性。如图8 所示,1 号边和2 号边的距离较大,遍历时虽然行索引相同,但是列索引相距较远,不满足空间局部性,访存性能较差。因此,本文采用分块划分的思想,将一段时间内的访存数据尽可能集中存储在较快的存储器上,降低从下层存储器读取数据的时间开销。
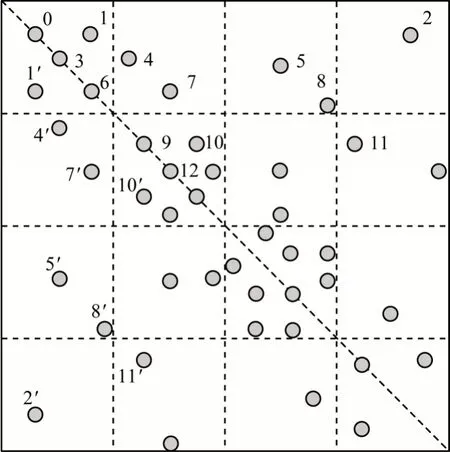
图8 非结构网格的邻接矩阵Fig.8 The adjacent matrix of unstructured grid
此外,非结构网格计算存在大量的对称矩阵,为节省存储空间,一般仅保留上三角矩阵,但是在计算时需要对称更新,因此,在众核处理器上的并行化存在数据相关和输出相关(写冲突)的问题。例如,在图8 中,1 号边和2 号边位于同一行,表示其对相同目标结果进行更新,存在依赖关系,如果计算任务被分配至2 个不同的线程执行,可能会发生写后读冲突。此外,1 号边和6 号边位于同一列,且1′号边和6 号边位于同一行,由于对称更新,则1 号边和1′号边同时更新时如果其他计算任务对6 号边更新,就会发生写写冲突。本文在分析非结构网格的数据特点和计算特征后,提出并行度更高的无依赖任务划分方法,将数据相关和输出相关的计算分配到相同任务队列。
本文提出一种N 阶对角染色算法,非结构网格边线沿对角方向划分为大小相同的方块后,将有依赖关系的方块染上同种颜色,分配到同一任务队列中进行并行计算。然后,染色器不断向外扩展并对其他类对角方块染色。算法根据方块内元素密度决定染色阶数,即向外扩展对角线的次数。该算法支持非结构网格下大多数的算子模型,特别是有依赖关系的算子。算法执行步骤如下:
1)网格预处理及自适应划分。获得当前顶点数和边数,记录边线所连顶点。根据LDM 存储空间等,针对不同网格拓扑自适应确定分块大小(边线所连顶点范围)和染色阶数,保证计算单元负载均衡。
2)分块染色及重排整理。根据分块大小,从对角块向外对网格逐阶染色,按照边随顶点走、一阶一类色的原则,同时建立索引表记录顶点的块内位置与全局位置关系,方便后续计算结果更新。
3)任务调度。同色块分配至同一任务队列,采用动态调度方法管理任务队列以维持从核负载平衡。
4)访存及计算。从核通过DMA 操作完成网格边线重排序,将当前队列内染色块加载至LDM 中并执行计算。同时,为了隐藏DMA 操作时间,从核在进行当前计算时开始下一轮DMA 操作,使得计算与访存重叠。在从核计算过程中,主核同时负责未染色块计算,因为未染色块更为稀疏,局部性更差,更适合通过主核计算,而从核通过DMA 对数据的换入换出往往会带来更高的时间开销,不利于发挥其性能优势。
3.2 算例分析
考虑到计算的常见性和代表性,本文以典型算子稀疏矩阵向量乘(Sparse Matrix Vector Multiplication,SpMV)为例分析众核加速方法。
作为最常见的稀疏运算,双精度SpMV 的计算强度仅为0.080~0.125 FLOPs/Byte,在带宽受限的众核处理器上性能较差。SpMV 算子描述如算法1 所示。
算法1SpMV 算子
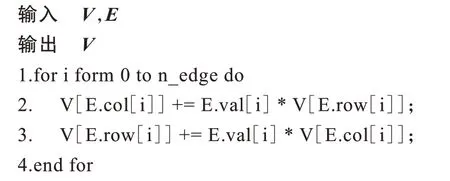
在算法1 中:V为输入/输出向量值,即网格顶点状态;E.row/E.col 和E.val 分别为稀疏矩阵的行/列索引和值,即网格边状态。顶点状态的更新由相连边状态及其连接顶点状态的乘积累加得到。本文所提算法执行过程如下:
1)在算法2 中,设最小并行单位为Δ,即分块最小顶点范围。根据LDM 空间大小、DMA 特性和读取的网格拓扑信息,自适应确定分块因子大小α。
算法2分块因子判决
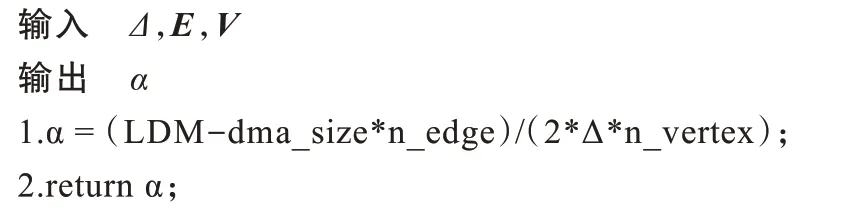
2)在算法3 中,根据分块大小αΔ扫描边线,先将主对角块染色并建立边索引表,例如第一块顶点范围在0~(αΔ-1)内,第二块顶点范围在αΔ~(2αΔ-1)内,同时将顶点全局位置转换为块内位置,建立关系映射表,原因是块内计算时不能使用全局地址。按照同样的方法向二阶及以上阶扩展,皆为双侧次对角块,即包括上三角和对称的下三角两部分。随后,算法4 从对角块中挑选较稠密对角块进行染色,挑选标准由块内节点密度和网格整体密度决定,根据大量测试后得出。未被挑选的非稠密块则分配给主核任务队列,依据主从核的不同特点实现任务分配。三阶对角染色示意图如图9 所示。
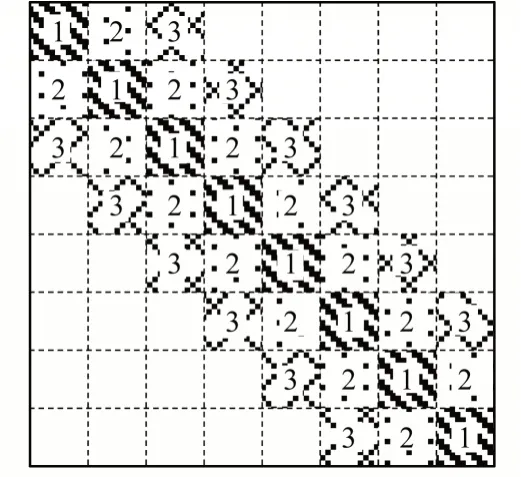
图9 三阶对角染色Fig.9 Third-order diagonal dyeing
算法3分块染色及重排整理

算法4挑选染色对角

3)建立从核任务队列queue,将全部一阶色块分入队列,从核从队列中获取任务并完成计算。类似地,在一阶色块完成计算后,其他同阶色块依次被分配到任务队列,队列内从核运行状态一致,从而避免写后读冲突和写写冲突。
4)在算法5 中,从核通过DMA 获取块内顶点状态和边状态以及索引表并完成更新,在计算时可以预取下一轮数据,从而使得DMA 时间被有效隐藏,如图10 所示。在从核计算的同时,主核负责其他未染色块的计算,从而实现主从核异步并行,进一步提升计算效率。

图10 计算访存异步重叠Fig.10 The asynchronous overlap of computation and memory access
算法5访存及计算

4 实验结果与分析
本次实验基于申威26010 众核处理器,硬件参数如表4 所示,采用swg++编译器编译全部C/C++程序。
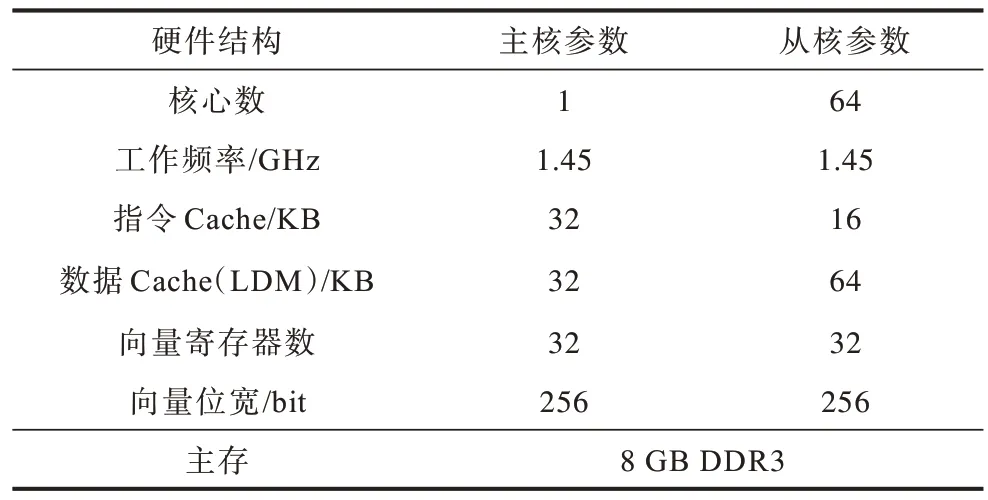
表4 申威26010 处理器硬件参数Table 4 The hardware parameters of SW26010 processor
4.1 不同网格的性能分析
为保证算法性能的可靠性,本文选取典型稀疏算子SpMV 作为标准测试算子,随机输入非结构网格实例进行测试分析。图11 和图12 分别为SpMV算子在不同网格规模下加速算法与主核朴素算法的运行时间及加速比,以验证加速算法的通用性和优化效果。
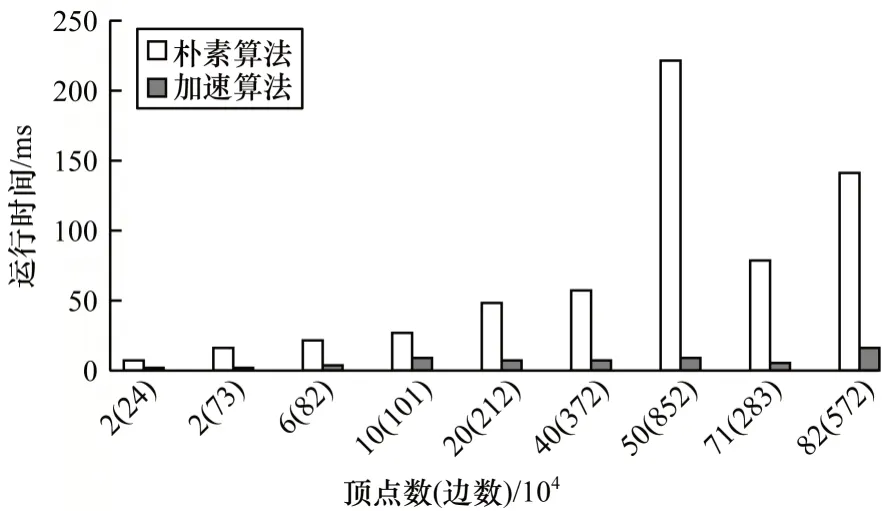
图11 不同网格规模下的优化性能Fig.11 Optimization performance under different grid scales
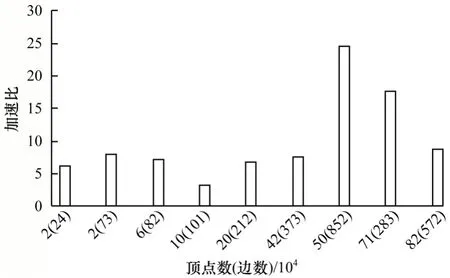
图12 不同网格规模下的加速效果Fig.12 Acceleration effect under different grid scales
从图11 和图12 中可以看出,随着网格规模的增加,加速算法的加速效果基本保持稳定,因为网格划分根据输入网格密度和拓扑自适应调整,染色阶数也根据当前对角线密度自动判决,因此加速算法能在多数网格规模下保持稳定的性能优势,通用性较强。相比于主核上运行的SpMV 算子,组合加速算法获得了平均10 倍左右的加速比,最高加速比可达24 倍。
4.2 不同算子的性能分析
本文设计非结构网格计算在申威众核处理器上的通用加速方法,因此,需要选取多种算子进行综合分析。SpMV 算子的加速比如图12 所示,Integration算子和calcLudsFcc 算子的加速比分别如图13 和图14 所示。
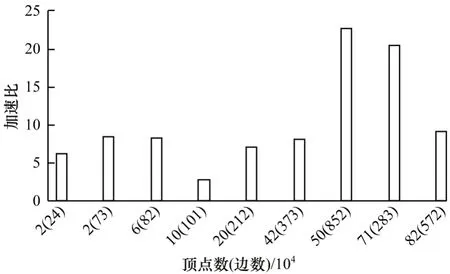
图13 Integration 算子在不同网格规模下的加速效果Fig.13 Acceleration effect of Integration operator under different grid sizes

图14 calcLudsFcc 算子在不同网格规模下的加速效果Fig.14 Acceleration effect of calcLudsFcc operator under different grid sizes
经过对上述2 种算子在不同网格规模下的测试发现,组合加速算法分别获得了10.22 倍和6.82 倍的平均加速比,而且本文算法对不同算子模型的性能表现差异并不明显,在有依赖和无依赖情况下都能取得稳定的性能优势,说明算法在任务划分和数据映射上并没有以牺牲性能为代价,自适应和无依赖任务划分方法取得了良好效果。由于算子在从核的计算和访存是基于染色后的数据块,其加速效果与数据块中的数据分布有关,在数据集中度较高的网格实例中,算子能获得显著的性能提升,可达20 多倍,但在数据非常离散的情况下效果一般。
4.3 不同优化策略的性能分析
为了说明N 阶对角染色算法和自适应任务划分方法的有效性,以SpMV 算子为例,分别采用非N 阶对角染色的分块算法和固定分块大小的任务划分方法进行对比实验,并以主核朴素算法为基准,实验结果如图15 所示。
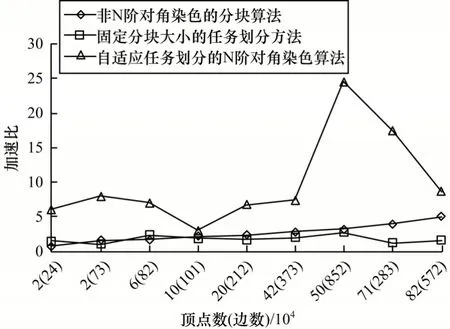
图15 不同优化方法的加速效果Fig.15 Acceleration effect of different optimization methods
N 阶对角染色算法通过分析对角块密度来选择是否染色当前对角块,而普通分块算法缺少对角块信息,易将过于稀疏的对角块交由从核阵列计算。将全部矩阵块映射到从核阵列会造成极大的性能损失,本文通过固定前100 阶对角块由从核计算来模拟非染色的普通分块算法性能。自适应划分方法根据LDM 空间大小、DMA 特性和网格拓扑信息确定分块大小,可以充分利用LDM 空间,而固定分块大小则容易造成对LDM 空间的利用不足。实验结果表明,非N 阶对角染色的分块算法平均加速比为2.64 倍,固定分块大小的任务划分方法平均加速比仅为1.8 倍,难以发挥众核架构的计算能力,甚至有负优化效果出现。采用自适应任务划分的N 阶对角染色算法能有效利用LDM 空间并根据块内密度选择从核或主核来执行计算,平均加速比可达10 倍。
5 结束语
为提升非结构网格计算中有依赖关系算子在众核处理器上的性能,本文针对非结构网格的计算特点,提出一种众核处理器上的通用加速方法,并基于申威26010 处理器架构对其进行精细调优。通过自适应任务划分方法将从核离散访存组织为批量访存,以降低访存开销。采用无依赖划分策略避免计算时的数据冲突,通过N 阶对角染色算法将计算任务分类调度执行,从而有效利用主从核的架构特点。此外,采用计算访存重叠技术进一步提升计算性能。实验结果表明,该方法在不同网格规模和不同算子模型下都取得了良好的加速效果,在有依赖和无依赖情况下均能保持稳定的性能优势,证明了任务划分方法的有效性。但是,本文所提方法对于数据分布极为分散的非结构网格仍存在一定局限性,下一步将结合排序算法对网格数据进行重排整理,提升数据的局部性,增加在从核阵列计算的数据块,从而满足更多稀疏网格数据的众核计算需求。
猜你喜欢
中等数学(2021年9期)2021-11-22 08:06:58
山东农业工程学院学报(2020年12期)2020-03-19 01:58:44
数学年刊A辑(中文版)(2018年4期)2019-01-08 02:00:24
山东科学(2018年6期)2018-12-20 11:08:58
湖州师范学院学报(2016年2期)2016-08-21 13:50:52
山西大同大学学报(自然科学版)(2016年6期)2016-01-30 08:29:19
地理与地理信息科学(2015年4期)2015-10-13 08:29:16
文山学院学报(2012年6期)2012-03-25 13:07:52
中学生数理化·高一版(2009年6期)2009-08-31 02:58:28
岁月(2009年3期)2009-04-10 03:50:12
