
基于倒金字塔深度学习网络的三维医学图像分割
2022-12-13 13:53:14张相芬刘艳袁非牛
计算机工程 2022年12期
张相芬,刘艳,袁非牛
(上海师范大学信息与机电工程学院,上海 201400)
0 概述
医学图像分割能够最大程度地为医生提供患者的信息,对疾病的诊断和治疗手段的选择具有重要意义。人脑图像分割是根据强度同质性等特征将脑组织分割成白质(WM)、灰质(GM)和脑脊液(CSF)。受脑组织复杂特征的限制,脑组织的分割面临极大的挑战。
现有的脑组织分割方法主要分为基于传统算法的分割方法和基于深度学习的分割方法[1]。基于传统算法的脑组织分割方法包括基于区域增长、边缘、聚类和阈值的分割方法。其中,SOMASUNDARAM等[2]根据不同脑组织的强度信息自动选取种子点,并进行多种子点的区域生长,最终得到分割结果。LI等[3]使用K-means 聚类方法实现对脑组织的分割,方法简单且分割速率较快。SALMAN等[4]提出一种结合K-means、聚类、分水岭变换等多种传统分割算法的边缘检测分割网络,分阶段地完成图像分割。但传统分割方法易受噪声影响,导致分割精度降低。基于深度学习的分割方法[5]多借助端到端的网络,这种网络不易受噪声影响,能更好地学习图像特征,因此广泛应用在医学图像分割任务中。例如,RONNEBERGER等[6]提出U-Net 网络,该网络能够提取单层二维图像的上下文信息,但不能获得医学图像的三维空间信息。CICEK等[7]设计3D U-Net 网络模型,将3D 的卷积、池化、反卷积等操作引入到U-Net 中,从而获取医学图像的3D 空间信息,但仅依靠单一模态提供的信息,存在局限性问题。此外,受上采样、下采样操作的影响,深度学习网络不能准确表达输出特征,进一步影响分割精度。LONG等[8]提出MSCD-UNet 网络,采用多分支池化信息提取器缓解最大池化方法存在的信息丢失问题,使得分割精度得到一定程度的提升,但是其网络结构过于复杂,导致参数量增加、分割效率降低。
针对以上问题,本文提出基于深度学习的医学图像分割网络MCRAIP-Net。以3D U-Net作为基础网络,为充分融合多模态特征信息,构建多模态编码器模块(Multi-modality Encoder Module,MEM)和双通道交叉重构注意力(Dual-channel Cross Reconstruction Attention,DCRA)模块,此外,设计倒金字塔解码器(IPD)模块,以融合多模态图像的特征,解决解码器最后一层输出特征表达不准确的问题。
1 相关理论
1.1 3D U-Net 网络
3D U-Net[7]是一个具有对称编码器和解码器的神经网络。3D U-Net 中编码器和解码器通过跳跃连接将同等分辨率的特征相连接,以提供较高的分辨率特征。此外,3D U-Net 结构设计中将3D 医学图像数据作为输入并使用3D 卷积、3D 最大池化和3D 反卷积来实现特征提取和特征恢复。这种方式可以捕获图像的3D 空间特征以提高分割精度。SUN等[9]基于3D U-Net 提出一种改进的具有体积特征重新校准层的3D U-Net,称为SW-3D-Unet,以充分利用切片间的空间上下文特征。HUANG等[10]提出的3D RU-Net,从编码器的区域特征中切出多级感兴趣区域(Region of Interest,ROI),从而扩大了3D RU-Net适用的体积大小和有效感知领域。
上述自动分割方法在医学图像分割方面具有较优的性能,但多数忽略了单一模态数据信息的局限性。因此,本文引入注意力机制,设计多模态交叉重构的倒金字塔分割网络,以3D U-Net 为基础,在输入层引入双通道交叉注意力机制和多模态融合策略,从而提高图像的分割精度。
1.2 注意力机制
在人们感知中,从不同感官获得的信息会被注意力机制加权[11]。这种注意力机制允许人们选择性地关注重要信息。受此启发,Google DeepMind 团队在执行图像分类任务时提出注意力机制,从而掀起了注意力机制研究的热潮。例如,SENet[12]通过显式建模通道之间的连接关系,以自适应地重新校准通道特征响应。残差注意力网络[13]是通过堆叠注意力模块构建的,这些注意力模块生成注意力感知特征。SENet 和残差注意力网络分别是采用通道注意力模块和空间注意力模块的代表。CBAM[14]是一种轻量级的通用模块,同时采用空间和通道注意力来提高深度神经网络的性能。除了通道注意力和空间注意力之外,一些研究人员还使用其他注意力机制。例如,为了提取相关的空间图像特征,SUN等[15]提出一种用于左心室分割的新堆栈注意U-Net。
多种方法利用注意力机制进行医学图像分割。YANG等[16]提出用于舌下小静脉分割的协同注意网络,它可以自动学习静脉目标结构。KAUL等[17]提出将注意力整合到全卷积网络中的FocusNet,通过卷积编码器生成的特征图实现医学图像分割。受这些注意力机制的启发,本文设计双通道交叉注意力模块以获得更多相关特征,并将这一思想与多模态融合机制相结合以关注更多的大脑细节信息。
1.3 多模态融合
在医学图像分析中,由于多模态(如T1、T1-IR、T2-FLAIR 等)数据可以为医学研究提供互补信息,因此多模态的融合信息被广泛用于脑组织分割[18]和病变分割[19]。根据医学图像分割的深度学习网络[20],基于多模态的图像分割网络分为层级融合网络、决策级融合网络和输入级融合网络。在层级融合网络中,将每个模态的图像作为输入来训练个体增强网络,这些学习到的个体特征表示在网络层中进行融合。层级融合网络可以有效地集成和充分利用多模态图像[21]。在决策级融合网络[22]中,以每个模态图像作为单个分割网络的单一输入,将各自的分割结果相结合得到最终的分割结果。输入级融合网络[23]通常在通道维度上将多模态图像叠加得到融合特征,用于训练分割网络。
本文考虑到输入级融合网络可以最大限度地保留原始图像信息并学习图像内在特征,采用输入级融合网络来充分利用多模态图像的特征表示。为了更加关注重要信息,本文在输入级融合网络中添加了双通道交叉注意力机制,既能够融合多模态特征又能关注到其中的大脑细节信息。
2 本文算法
本文引入注意力机制,提出一种新颖的多模态交叉重构倒金字塔网络MCRAIP-Net,实现医学脑图像的分割,该网络主要包含多模态交叉重构编码结构和倒金字塔解码器结构两个部分。
2.1 多模态交叉重构编码器
由于不同模态的MRI 图像能够表征不同的信息,因此有效地融合多模态信息对于实现高质量的分割具有重要意义。本文使用并行前馈编码器结构提取不同模态的特征,并在每个分辨率上进行融合,该融合过程主要分为两个步骤:1)在多模态编码器模块中进行初步融合;2)将初步融合的特征送入双通道交叉重构注意力模块中进一步融合。
在初步融合过程中,本文将T1、T1-IR 和T2-FLAIR三个模态的MRI 数据作为输入,采用最大池化对每个模态的数据独立地进行下采样,从而有效捕获3D 图像的上下文信息。将同一分辨率级的特征按像素级相加,这样的设计不仅能够提高网络的表达能力,还可以减少参数量。多模态编码器模块结构如图1 所示。假设第l层的三个模态特征在初步融合后得到的特征为Featurel_1 和Featurel_2,其中l∈1、2、3,至此,完成多模态的初步融合。

图1 多模态编码器模块结构Fig.1 Structure of multi-modality encoder module
第二步融合是对初步融合的特征进行交叉重构融合。双通道交叉重构注意力模块结构如图2所示。
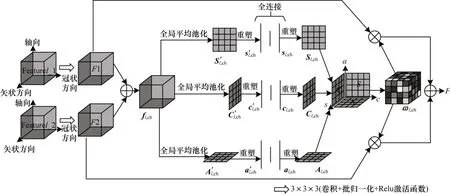
图2 双通道交叉重构注意力模块结构Fig.2 Structure of dual-channel cross reconstruction attention module
DCRA 模块的输入是第一步的融合特征Featurel_1 和Featurel_2。两个融合特征的大小均为I×J×K,其中,I、J、K分别表示特征图的长、宽、高。首先,分别对两个输入进行一次卷积,其目的是充分融合每个输入中包含的两个模态信息,在卷积之后得到特征F1、F2;然后,将特征F1、F2 按像素级相加得到特征fl,ch;最后,使用全局平均池化对特征fl,ch沿轴向、冠状和矢状方向进行空间信息压缩,以获得空间统计信息,其中ch 表示第ch 个通道,ch ∈[1,Ch]。的计算过程如式(1)~式(3)所示:



其中:ωl,ch(i,j,k)表示空间像素(i,j,k)的权重值。
每个像素通道的加权张量是使用所有模态的空间信息产生的,这样能够增强网络对图像特征信息的表达。本文将特征F1和F2 分别与重构的三维权重相乘并按像素级相加,得到重构注意的特征,该特征能更好地表达多模态的三维特征信息。
2.2 倒金字塔解码器
本文提出一种基于3D U-Net的MCRAIP-Net网络,其网络结构如图3 所示,在图中每个特征上都标记了通道数量。

图3 多模态交叉重构的倒金字塔网络结构Fig.3 Structure of inverted pyramid network with multi-modality cross reconstruction
为了对当前分辨率下的特征向量进行重构加权,本文对编码器每一个分辨率级的特征都使用了双通道交叉重构注意力模块,以捕获更有效的特征,将双通道交叉重构注意力模块的输出特征跳转连接到同一分辨率级的解码器中,降低下采样时信息丢失对分割精度的影响。在深度神经网络中,通常仅对网络最后一层的输出特征进行分类,该特征经过多次连续的下采样和上采样后得到,在一定程度上存在表达不准确的问题。为解决该问题,本文采用倒金字塔解码器(如图3 中虚线框所示),将解码器中每一层的特征都参与到最后的分类任务中。具体做法是:将低分辨率特征通过双线性插值的方法恢复到输入图像大小,再将这些特征进行拼接并通过3×3×3 的卷积来实现融合,对融合特征进行1×1×1 卷积,最后采用Sigmoid 函数对卷积结果进行判决,最终完成分割任务。
3 实验细节与评价指标
3.1 实验细节
本文实验均在Tensorflow 开源框架下实现,训练和测试的平台 是Intel®Xeon®处理器,两块NVIDIA GeForce GT1080ti显卡(显 存8 GB)的windows(64 位)系统。网络权重更新迭代次数设为5 000 次,网络模型的初始学习率为0.001,权重每更新1 000 次学习率下降1/2。
本文为了更好地评价所提的网络模型,在两个主流的医学脑图像数据集MRBrainS13 和IBSR18 上进行实验。MRBrainS13 数据集是对不同程度白质病变的糖尿病患者采集获得的,该训练数据集有5 个研究对象(2 个男性、3 个女性),对每个成像受试者进行扫描,获取多模态的MRI 大脑数据,数据包括T1、T1-IR 和T2-FLAIR 三种模态,每种模态数据的大小为240×240×240。在实验中,本文将数据的80%作为训练集,10%作为验证集,10%作为测试集。所有的图像都经过了偏差矫正,其目标分割图像由医学专家手工分割获得。IBSR18 数据集包含18 个T1 MRI 数据,大小均为256×256×128,MRI扫描图像和医学专家手工分割结果由马萨诸塞州综合医院的形态测量分析中心提供。
3.2 评价指标
为了评价本文算法的有效性和可靠性,本文使用最常用的三个评价指标来评估网络对脑组织(WM、GM和CSF)的分割性能。这三个指标分别是Dice系数(Dice Coefficient,DC)、绝对体积差(Absolute Volume Difference,AVD)和豪斯多夫距离(Hausdorff Distance,HD),其表达式如式(5)所示:

其中:P表示预测模型的分割图像;G表示人工分割的真实图像;VP表示预测分割结果的体积;VG表示真实分割图像的体积。h(P,G)和h(G,P)的表达式分别如式(6)和式(7)所示:

Dice 系数越大表示分割越准确,HD 和AVD 值越小表示分割性能越好。
4 实验
4.1 消融实验
本文基于MRBrainS13 数据集进行实验,以验证所提各模块的有效性,实验结果如表1 所示。

表1 在MRBrainS13 数据集上的消融实验结果Table 1 Results of ablation experiments on the MRBrainS13 dataset
将未嵌入MEM 模块、DCRA 模块和IPD 模块的3D U-Net 作为基础网络。在逐步将MEM、DCRA 和IPD模块添加到3D U-Net 之后,网络的分割性能也相应得到提高。在3D U-Net 中加入MEM 模块后(网络模块表示为3D U-Net+MEM),在9 个评价指标中,除了CSF的AVD 指标以外,相比3D U-Net 其他8 项指标都有所提升,尤其是WM 和GM 的Dice 指标,分别提升了2.03和2.39 个百分点。在3D U-Net+MEM 框架基础上加入DCRA 模块后(网络模块表示为3D U-Net+MEM+DCRA),相比3D U-Net+MEM 又有6 个指标得到提升,其中,WM 和GM 的Dice 指标分别从90.89%和87.83%提高到91.57%和88.44%,说明本文构造的双通道交叉重构注意力模块能够有效提取不同模态的特征,从而提高网络的分割性能。
为验证IPD 模块的有效性,本文算法基于3D U-Net+MEM+DCRA+IPD 框架做了第四组实验。从表1 可以看出,3D U-Net+MEM+DCRA+IPD 框架取得了最优的分割结果。因此,本文提出的算法具有更好的特征提取和分割性能,所提的分割网络模型在分割精度上较3D U-Net 有明显的提升,但是其参数量比3D U-Net 网络增加了将近一倍,因此其运行效率低于3D U-Net 网络。
加入不同模块后模型所需的参数量以及对每个32×32×32 三维图像的运行时间对比如表2 所示。从表2 可以看出,虽然MCRAIP-Net 所需参数量和运行时间较3D U-Net 更多,但表1 数据已表明MCRAIPNet 的分割精度最高。

表2 不同模型的参数量和运行时间对比Table 2 Parameters quantity and running time comparison among different models
本文消融实验结果如图4 所示,本文给出三个分割实例的实验结果对比,分别为例1、例2、例3。Ground-Truth 代表真实分割图像,从图中方框标记的脑组织细节信息可以看出,与真实分割结果对比,本文提出的算法对细节特征的分割更加准确,进一步验证本文所提的MEM 模块、DCRA 模块以及IPD 模块的有效性。

图4 消融实验的分割结果Fig.4 Segmentation results of ablation experiment
实验结果表明,本文提出的MCRAIP-Net 可以有效地对多模态数据进行训练,并且获得更优的分割结果。
4.2 在MRBrainS13 数据集上的实验结果
本文将MCRAIP-Net 算法与四种目前最先进的医学脑图像分割算法进行对比,包括3D U-Net[7]、HyperDense-Net[24]、MMAN[25]和SW-3D-Unet[9]。实验统计数据如表3 所示。从表3 可以看出,在除了CSF 的Dice 系数和AVD 以及CSF 的AVD 三个指标之外,本文提出的MCRAIP-Net 算法的6 个指标均优于其他算法,本文提出的深度网络模型的分割效果总体优于其他算法。以GM 的分割为例,本文算法得到的Dice 系数比SW-3D-Unet 提高2.39 个百分点。从表3 可以看出,本文算法的分割性能相比于3D U-Net 和HyperDense-Net 均有较大的提升,以WM为例,相较于3D U-Net 的Dice 系数平均提升了2.81 个百分点,相较于HyperDense-Net 的Dice 系数平均提升2.21 个百分点。因此,本文算法能更准确地完成脑部图像分割任务。

表3 在MRBrainS13 数据集上不同算法的分割结果Table 3 Segmentation results among different algorithms on MRBrainS13 dataset
在MRBrainS13 数据集上不同算法的实验结果对比如图5 所示。

图5 在MRBrainS13 数据集上不同算法的实验结果对比Fig.5 Experimental results comparison among different algorithms on MRBrainS13 dataset
从图5 可以看出,相较于其他四种算法,本文算法分割图像的整体形态与真实标签最接近,对脑组织分割也更准确,特别是在图中方框标记的区域。本文算法在测试集上的多模态分割示例如图6 所示。本文算法分割出的脑组织边界十分清晰,也证明了本文算法在脑组织分割任务中具有较好的分割性能。

图6 在测试集上本文算法的多模态分割示例Fig.6 An example of multi-modality segmentation of the proposed algorithm on test dataset
4.3 在IBSR18 数据集上的对比实验
为验证本文提出的网络架构也适用于分割单模态数据,本文在IBSR18 数据集上进行对比实验,将本文所提算法与U-Net[6]、Residual U-Net[26]、Inception U-Net[27]、SegNet[28]和MhURI[29]的分割结果进行对比。不同算法的图像分割评价指标如表4 所示。以Dice 系数为例,从表4 可以看出,本文算法的Dice 系数分割指标总体高于其他对比算法。实验结果表明,本文算法在只有单模态情况下也能取得较好的分割结果。

表4 在IBSR18 数据集上不同算法的分割结果Table 4 Segmentation results comparison among different algorithms on IBSR18 dataset
5 结束语
本文提出一种新颖的深度学习网络,用于实现人脑磁共振图像的分割。将T1、T1-IR 和T2-FLAIR三种模态的数据作为输入,通过多模态交叉重构编码器对各模态数据进行下采样实现特征提取,并对同一分辨率级的特征进行两级融合,其中在双通道交叉重构注意力模块中不仅充分融合了三模态的特征,还对特征进行重构加权和细化。基于解码器各分辨率级的特征,利用倒金字塔解码器实现脑组织的分割,有效提升图像的分割精度。实验结果表明,本文算法不仅具有较优的细节特征提取能力,而且能有效融合不同模态的信息。后续将引入边缘检测注意力模块来定位待分割组织的边界,并利用正则化方法进行深度监督,进一步提升网络模型的分割精度和训练效率。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
摄影世界(2022年1期)2022-01-21 10:50:14
知识经济·中国直销(2018年12期)2018-12-29 12:22:14
商周刊(2017年6期)2017-08-22 03:42:36
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
山东大学法律评论(2016年0期)2016-08-16 03:24:12
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
计算物理(2014年2期)2014-03-11 17:01:39
