
面向行人重识别的通道与空间双重注意力网络
2022-12-13 13:53:06曾涛薛峰杨添
计算机工程 2022年12期
曾涛,薛峰,杨添
(合肥工业大学计算机与信息学院,合肥 230601)
0 概述
随着智能安防和视频监控领域的需求与日俱增,行人重识别(Re-Identification,ReID)受到了越来越多研究人员的关注[1-2]。行人重识别可以看成一个图片检索任务,利用计算机视觉技术判断给定的图片或视频序列中是否存在特定行人,即给定一张待识别的行人图片,在其它摄像头拍摄到的视频中检索出与待识别行人具有相同身份的行人图片。在现实场景中,视角变化、行人姿态变化、物体遮挡、图像低分辨率等不利因素[3]导致行人重识别算法难以提取充分、有效的行人特征,造成行人重识别精度较低。因此,如何提取判别性强的行人特征是行人重识别研究的重点。
在深度学习技术普及之前,与大部分图像分类识别一样,行人重识别主要通过手工设计图像特征来实现,计算过程繁琐,识别效果较差,难以满足复杂环境变化下行人重识别任务的要求。近年来,基于深度学习的行人识别技术取得了较大的进展和突破,其识别准确率较基于人工特征的方法有了大幅提高,成为行人重识别领域的主流方法[4]。按照行人特征表达方式的不同,可以将基于深度学习的行人重识别方法概括为基于全局特征、基于局部特征和基于注意力机制3 种方法。
基于全局特征的行人重识别将整张行人图像表示成一个不包含任何空间信息的特征向量,并对图像进行相似性度量。文献[5]提出一个身份判别性编码方法,将行人重识别问题看成分类问题,即将同一个行人的图片看成同一类的图片,在训练过程中利用行人的ID 标签计算分类损失。文献[6]使用三元组损失来训练深度模型,通过拉近同一类样本之间的距离,拉开不同类样本之间的距离,从而获得判别性强的行人特征。文献[7]提出一个融合分类损失和验证损失的孪生网络,在模型训练过程中学习行人特征表示和相似度度量。然而,基于全局特征的方法忽略了图像局部细节信息,在物体遮挡、行人图片未对齐、视角变化等复杂场景下,辨别能力较差。
基于局部特征的行人重识别则先将整张图像表示成若干局部特征的集合,再进行度量学习,这类方法可通过图像切片、分割、人体骨架关键点检测等方式实现。文献[8]提出一种基于分块卷积基线方法提取局部特征,使用分块修正池化方法对齐分块信息,并针对每个分块信息分别采用分类损失进行训练。文献[9]提出一种水平金字塔匹配方法,通过在水平方向提取多个尺度的局部特征并分别进行训练,从而增强行人局部特征的鲁棒性和判别能力。文献[10]提出一种以人体区域划分的多阶段特征提取和融合方法,从而对齐不同图像中人体区域特征。但这类方法通常仅考虑粗粒度的局部特征,缺乏对行人全局特征的统筹考虑,因此难以获得辨别力强的行人特征。
基于注意力机制的行人重识别方法是近年来行人重识别领域出现的新方法。文献[11]提出一个端到端的比较性注意力网络,以长短时记忆网络为基础设计了注意力机制,并加入时空信息模拟人类的感知过程来比较行人之间的显著性区域,判断两幅照片是否属于同一个行人。文献[12]通过将注意力机制融入孪生网络中,发现具有相同身份的行人图像中的一致性注意力区域,在跨视角的匹配中有较强的鲁棒性。文献[13]提出一个轻量级的注意力网络,能够联合学习行人图片中的硬区域注意力和软像素注意力,优化未对准图像中的行人识别。文献[14]提出一种批丢弃块网络,通过在一个批次中随机丢弃所有输入特征图的相同区域,加强局部区域的注意力特征学习,从而获得更加鲁棒和判别性高的行人特征。文献[15]提出一个类激活图增强模型,通过在主干模型后面连接一系列有序分支进行扩展,并通过引入一个重叠激活惩罚的新损失函数,使当前分支更多地关注那些被先前分支较少激活的图像区域,从而获得多种辨别力的细粒度行人特征。然而,目前这些基于注意力机制的方法主要考虑行人局部区域的注意力特征,缺乏对行人图片不同区域细粒度注意力特征的关注,特征粒度不够精细,特征表达的辨别能力有待进一步增强。
本文提出一种通道与空间双重注意力网络(Channel and Spatial Dual-Attention Network,CSDA-Net),通过改进设计一种混合池通道注意力模块(Hybrid Pooling Channel Attention Module,HPCAM),在通道维度上获得更加具有判别性的特征,并在HPCAM模块之后设计一种新型像素级细粒度的全像素空间注意力模块(Full Pixel Spatial Attention Module,FPSAM),从而在空间维度上增强行人特征的判别能力。
1 通道和空间双重注意力网络
1.1 网络结构
受文献[16]中bagTricks 模型的启发,本文设计了一种通道和空间双重注意力网络CSDA-Net,其结构如图1 所示。可以看到,CSDA-Net 网络在骨干网络的第1 个、第2 个、第3 个残差块后引入HPCAM 模块,在骨干网络的第4 个残差块后引入FPSAM 模块。相比于批归一化(Batch Normalization,BN)模块,实例批归一化(Instance Batch Normalization,IBN)模块[17]对一个批次里的每一个样本均进行正则化处理,而不是对整个批次样本进行正则化处理。研究表明IBN 泛化能力较强[18],更加适合处理在复杂环境下拍摄的行人图片。因此,CSDA-Net 骨干网络采用ResNet50-IBN 网络。

图1 CSDA-Net 结构Fig.1 Structure of CSDA-Net
1.2 混合池通道注意模块
通道注意力机制可以在引入少量参数的情况下,在通道维度上抑制无用信息的干扰及增强显著性特征的表达,从而提高行人重识别的准确度和精度。为了在通道维度上获得更加具有判别性的行人特征,本文在传统通道注意力网络机构上进行改进,设计了混合池通道注意力模块HPCAM,其结构如图2 所示。本文的HPCAM模块在通道域注意力(Squeeze and Excitation SE)模块[19]的全局均值池化(Global Average Pooling,GAP)单分支结构设计的基础上,加入全局最大池化(Global Max Pooling,GMP)分支结构,即通过全局均值池化操作混合全局最大池化操作,进一步挖掘通道维度上的显著性特征,从而提取到更加具有判别性的特征。

图2 HPCAM 模块Fig.2 HPCAM module
如图2 所示,HPCAM 模块的输入是一个三维向量XCA∈RC×H×W,其中W、H、C分别表示特征图的宽度、高度和通道个数。HPCAM 模块旨在学习得到一个在通道维度上的权重偏好向量Ac∈RC×1×1,用于捕获特征在通道维度上的显著性信息。HPCAM 模块的输出计算过程如式(1)所示:

由式(1)可以看出,当权重偏好向量Ac为0时,式(1)变成恒等映射,能有效避免随着深度网络层数的加深而出现梯度消失和网络退化的情况,有助于深度模型的训练学习,挖掘出在通道维度上的行人显著性特征。其中权重偏好向量Ac是通过GAP 分支和GMP 分支共同学习得到,其表达式如式(2)所示:

在GAP 分支中,Aca的计算式如式(3)所示:

其中:σ(·)表示Sigmoid 函数;δ(·)表示ReLU 激活函数;Wa1表示GAP 分支中第1 个全连接层中权重向量,其特征维度为(C/r)×1×1,其中r表示降维比例因子,本文中r取16;Wa2表示第2 个全连接层中权重向量,其特征维度为C×1×1;GAP(·)表示全局均值池化操作。
在GMP 分支中,Acm的计算式如式(4)所示:

其中:Wm1表示GMP 分支中第1 个全连接层的权重向量;Wm2表示第2 个全连接层的权重向量;GMP(·)表示全局最大池化操作。
1.3 全像素空间注意力模块
为进一步在空间维度上增强行人特征的判别能力,本文在HPCAM 模块之后加入了全像素空间注意力模块FPSAM,其结构组成如图3 所示。FPSAM模块学习到的是一个和输入特征图维度一致的全像素细粒度的注意力权重向量,能够在HPCAM 模块获得粗粒度的注意力特征基础上,进一步获得更加具有判别性的行人特征,提高行人重识别的准确率和精度。

图3 FPSAM 模块Fig.3 FPSAM module
FPSAM 模块的输入是一个三维向量XPA∈RC×H×W,其中W、H、C分别表示特征图的宽度、高度和通道个数。FPSAM 模块旨在学习得到一个和输入维度相同的权重向量As∈RC×H×W。FPSAM模块的输出为输入向量XPA和权重偏好向量As的乘积,其计算式如式(5)所示:

其中:权重向量As是基于通道注意力权重向量Apc∈RC×1×1和空间注意力权重向量Aps∈R1×H×W计算所得,向量Apc和向量Aps的学习过程如图3 所示,其中,通道注意力权重向量Apc的学习过程如图3 中左虚线框所示。Apc的计算式如式(6)所示:

其中:Wpa1表示第1 个全连接层中的权重向量;Wpa2表示第2 个全连接层中的权重向量。
空间注意力权重向量Aps的学习过程如图3 中右虚线框所示。具体而言,首先在通道维度上求均值,然后通过一个卷积核为3×3、步长为2 的卷积层,最后通过一个双线性插值层还原得到特征图Aps。基于向量Apc和向量Aps即可得到像素注意力权重向量As。具体而言,向量Apc和向量Aps首先进行逐元素相乘,然后再经过一个卷积核为1×1、步长为1 的卷积层,最后经过Sigmoid 激活函数进行归一化处理。向量As的计算式如式(7)所示:

其中:Conv(·)表示卷积操作。因为Apc和Aps是通过2 个不同的分支独立学习得到的,两者直接相乘得到的权重向量存在信息冗余,所以加入1×1 的卷积层后可以修正权重向量,得到更加具有判别性的特征。
1.4 损失函数
为了使模型能更加有效地提取出辨别性强的行人特征,本文采用交叉熵损失函数、三元组损失函数和中心损失函数进行联合训练。交叉熵损失结合三元组损失和中心损失进行联合训练可以获取更加有效的行人特征,这也是行人重识别研究领域常用的方式。
1.4.1 交叉熵损失函数
设进行分类识别的特征为f,交叉熵损失函数的计算式如式(8)所示:

其中:N为训练集中类别总数;Wi表示全连接层中第i个类别的权重向量;y是输入图像的真实标签,当y≠i时,qi=0,当y=i时,qi=1。为防止模型对训练集中行人图片过拟合,提高模型的泛化能力,本文采用了带标签平滑的交叉熵损失函数qi,其表达式为:

其中:ε是标签平滑参数,其通过抑制真实标签在计算损失时的权重,从而抑制模型在数据集上过拟合,提高模型泛化能力。在本文中,ε设置为0.1。
1.4.2 三元组损失函数
本文采用的难样本三元组损失函数是三元组损失函数的一个改进版本。难样本三元组损失函数可以表示为式(10)所示:

其中:P表示一个批次数据中行人ID 个数;K表示每个行人挑选出图片的个数表示批次中一张ID为i的行人图片(anchor)的特征表示与其ID 相同的正样本特征表示ID不同的负样本特征;α为预设的超参阈值,用来调整正负样本对之间的距离,本文中,α设置为0.6;[·]+表示max(·,0)函数。
1.4.3 中心损失函数
中心损失函数通过为每个类别学习得到一个特征中心点,并在训练过程中不断拉近深度特征和其对应的特征中心之间的距离,从而使类内特征更加紧凑,学习得到更加鲁棒的判别性特征。中心损失函数的表达式如式(11)所示:

其中:fi表示第i个样本经过深度网络后提取得到的特征;yi表示第i个样本的标签;cyi表示第yi个类别对应的高维特征中心;B表示批次大小。
1.4.4 本文损失函数
综上所述,本文使用3 种损失函数进行联合训练,最终的损失函数表达式如式(12)所示:

其中:β表示中心损失对应的权重系数,在本文中,β默认设置为0.000 5。
2 实验结果与分析
2.1 数据集介绍
为证明本文网络的有效性,本文在行人重识别领域公开的3 个大型数据集Market1501[20]、DukeMTMC-ReID[21]和CUHK03[22]上进行了实验,数据集的属性信息如表1 所示。
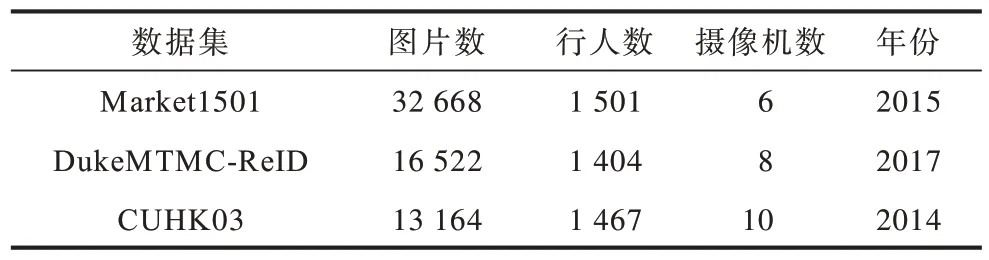
表1 数据集属性信息Table 1 Attribute information of dataset
2.2 实验参数与评价指标
本文使用Pytorch 深度学习框架,并采用2 块GeForce GTX 1080ti 显卡进行GPU加速。在训练迭代过程中,每次随机挑选16个行人,每个行人挑选4张图片来构成一个批次,且图片大小统一调整为384×192像素。在训练过程中,学习率采用预热策略,即在前10个epoch学习率由3.5×10-5线性增加到3.5×10-4,然后在第50个、第140 个和第240 个epoch 时学习率进行系数为0.1 的指数衰减,训练总次数为400 个epoch。训练过程中采用Adam 优化器算法对模型参数进行优化,并使用权重衰减因子为5×10-4的L2正则化。测试时,使用BN 层之后的特征作为行人检索特征,并采用余弦距离度量方式计算特征之间的距离。
本文使用累积匹配特性曲线(Cumulative Match Characteristic Curve,CMC)中的Rank-1 准确率和平均精度均值(mean Average Precision,mAP)作为评估模型性能的指标。
2.3 与相关网络的比较
为证明本文网络性能,本文与近几年行人重识别领域中一些具有代表性的网络进行比较,如基于全局特征的IDE[5]、TriNet[6]、SVDNet[23]、bagTricks[16],基于局部特征的PCB[8]、PCB+RPP[8]、HPM[9]、MGN[24],以及基于注意力机制的HA-CNN[13]、CASN[11]、CAMA[15]、BDB[14]。为简化实验和直观地分析网络本身的有效性,本文所有实验均采用单帧查询模式,且未使用re-ranking[25]技术。实验结果如表2 和表3 所示,其中“—”表示原文献中未列出该实验结果。

表2 不同网络在Market1501 和DukeMTMC-ReID 数据集下的结果对比Table 2 Comparison of results of different networks under Market1501 and DukeMTMC-ReID datasets %

表3 不同网络在CUHK03 数据集下的结果对比Table 3 Comparison of results of different networks under CUHK03 dataset %
由表2 可知,本文CSDA-Net网络在Market1501 数据集上的Rank-1 和mAP 分别为96.0%和90.4%,两者同时达到了对比网络中的最高精度。相比于同样基于注意力机制的CAMA[15]和BDB[14],本文CSDA-Net 网络在Rank-1 上分别提升了1.3 和0.7 个百分点,在mAP上分别提升了5.9 和3.7 个百分点。CAMA 和BDB 网络由于仅考虑的是局部区域粗粒度的注意力特征,缺乏对行人像素级细粒度注意力特征的统筹考虑,因此获取的行人判别性特征不够准确。相比于使用全局 特征的bagTricks[16]和使用局部特征的MGN[24]网络,本文的CSDA-Net 在Rank-1 上分别提升了1.5和0.3 个百分点,在mAP 上分别提升了4.5 和3.5 个百分点。未使用注意力机制的bagTricks 和MGN 网络提取得到的是一个全局的特征,缺乏对判别性特征的关注,故而较难获得辨别力强的行人特征。上述实验结果验证了本文CSDA-Net 网络的有效性。
由表2 可知,本文CSDA-Net 网络在DukeMTMCReID数据集上的Rank-1和mAP分别为91.3%和82.1%,两者同时达到了对比网络中的最高精度。相比于同样基于注意力机制的CAMA[15]和BDB[14]网络,本文CSDANet 网络在Rank-1 上分别提升了5.5 和2.3 个百分点,在mAP 上分别提升了9.2 和6.1 个百分点。相比于使用全局特征的bagTricks[16]网络,本文CSDA-Net 网络在Rank-1 和mAP 分别提高了4.9 和5.7 个百分点。相比于使用局部特征的MGN[24]网络,本文CSDA-Net 网络在Rank-1 方面提高了2.6 个百分点,在mAP 上提高了3.7 个百分点。在DukeMTMC-ReID 数据集上的实验结果同样证明了本文CSDA-Net 网络的有效性。
不同网络在CUHK03 数据集上的对比结果如表3 所示,可以看到,本文CSDA-Net 网络的性能显著优于其他网络。因为该数据集中行人边界框由手工标记方式和检测器检测两种方式获得,所以分成两种情况进行验证。在使用手工标注方式获得的行人边界框下,本文CSDA-Net 网络达到了81.1%的Rank-1 精度和82.9%的mAP,两者同时达到了对比网络中最好的性能。相比于同样基于注意力机制的CAMA[15]和BDB[14]网络,本文CSDA-Net网络在Rank-1上分别提升了12.8 和6.2 个百分点,在mAP 上分别提升了14.6 和1.7 个百分点。在使用检测器检测的方式下,本文CSDA-Net 网络达到了78.3%的Rank-1和80.0%的mAP,性能同样优于其他的网络,相比于同样基于注意力机制的CAMA[15]和BDB[14]网络,本文CSDA-Net 网络在Rank-1 上分别提升了11.7 和4.8 个百分点,在mAP 上分别提升了15.8 和3.6 个百分点。在CUHK03 数据集上的实验结果进一步验证了本文CSDA-Net 网络的有效性。
由表2、表3 可以看出,本文CSDA-Net 网络在DukeMTMC-ReID 和CUHK03 数据集上性能提升幅度明显高于在Market1501 数据集上的性能提升幅度,这是由于Market1501 数据集中的行人图片较为规整,且较少出现物体遮挡、视图变化、行人未对齐等不利情况,而DukeMTMC-ReID 和CUHK03 数据集具有较大挑战性,更符合真实场景下行人图片的特点,即图片来自于多个互不重叠的摄像头,普遍存在行人姿态变化、物体遮挡、行人未对齐等不利情况。实验结果论证了本文CSDA-Net 网络能够有效应对上述不利情况,具有更好的鲁棒性,更适合真实场景下的行人重识别任务。
2.4 消融实验
为展现本文网络中2 个主要创新改进模块(HPCAM 模块和FPSAM 模块)对算法性能提升的贡献,本文以Market1501 数据集为例,设计了一系列消融实验。本文以未加入注意力模块作为基线(Baseline)模型,实验结果如表4 所示。

表4 不同模块组合在Market1501 数据集下的实验结果Table 4 Experimental results of different module combinations on Market1501 dataset %
由表4 实验结果可以看出,单独融入HPCAM 模块或FPSAM 模块均对模型效果有所提升,将HPCAM 模块和FPSAM 模块同时融入Baseline 模型(即本文方法),Rank-1 和mAP 得到了进一步提升。上述实验表明,HPCAM 和FPSAM 两个注意力模块在“粒度”上具有互补作用,通过深度网络联合学习粗粒度和细粒度注意力特征,可以获得更具鲁棒性的行人特征,从而提高行人重识别的准确率和精度。
2.5 算法可视化结果分析
为进一步验证本文网络的先进性,本文随机检索了Market1501 查询集中的3 个行人,检索结果排名前10 的图片如图4 所示。其中,Query 是待查询图像,1~10 是按照相识度从大到小排列的10 张检索结果正确的图像,分别表示为Rank-1~Rank-10。

图4 本文网络在Market1501 数据集下排名前10 的行人检索结果展示Fig.4 Display of the top 10 pedestrian search results of network in this paper under the Market1501 dataset
从图4 第1 个检索示例中可以看出,当摄像机视角变化(Rank-1,Rank-4,Rank-8)和行人姿态变化(Rank-1,Rank-2,Rank-3)时,均可以被检索出来。从图4 第2 个检索示例中可以看出,即使是与待检索图像不对齐的行人图像(Rank-1,Rank-8)也可以被检索出来。从图4 第3 个检索示例中可以看出,即使是被自行车遮挡的行人图像(Rank-7)也可以被正确地检索出来。在图像低分辨率情况下,如第1 个检索示例中的Rank-8 和第3 个检索示例中的Rank-6 所示,也能被检索出来。上述实验结果验证了本文网络的有效性和鲁棒性,可以有效应对真实场景下的行人重识别问题。
3 结束语
针对在复杂环境下行人判别性特征难以获取的问题,本文提出一种面向行人重识别的通道与空间双重注意力网络CSDA-Net。通过在深度模型中分阶段融入HPCAM 模块和FPSAM 模块,获得不同粒度的注意力特征,并通过深度网络互补训练学习,有效挖掘行人判别性特征,提高行人重识别的准确率和精度。在CUHK03、DukeMTMC-ReID 和Market1501 公开数据集上的实验结果表明,本文网络能有效提高行人重识别性能。下一步将从实际应用的角度出发,在跨模态的情况下把不同模态的特征数据统一映射到一个共享的特征表征空间中,并同时约束该共享特征空间中的类内一致性和类间辨别性,使用深度模型训练得到与模态无关的行人判别性特征,提高行人重识别模型的泛化能力,从而提取具有鲁棒性和判别性的行人特征。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
意林(2021年5期)2021-04-18 12:21:17
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
扬子江(2019年1期)2019-03-08 02:52:34
传媒评论(2017年3期)2017-06-13 09:18:10
小天使·一年级语数英综合(2017年6期)2017-06-07 23:51:16
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
专利代理(2016年1期)2016-05-17 06:14:36
上海理工大学学报(2012年2期)2012-03-20 13:54:30
质量与标准化(2010年5期)2010-05-03 04:15:40
