
基于SimAM-YOLOv4的自动驾驶目标检测算法
2022-11-24 02:29刘丽伟侯德彪侯阿临郑贺伟
长春工业大学学报 2022年3期
刘丽伟,侯德彪,侯阿临,梁 超,郑贺伟
(长春工业大学 计算机科学与工程学院, 吉林 长春 130102)
0 引 言
近年来,随着智能交通和人工智能技术的高速发展,自动驾驶技术成为汽车领域的研究热点[1]。然而,自动驾驶场景下的道路环境复杂。一方面,车辆行驶过程中光线和相对角度等因素变化,导致目标的特征发生改变,从而产生目标检测漏检和误检的现象。另一方面,行人姿态改变以及车辆局部遮挡,容易产生目标检测的漏检和误检[2]。因此,在复杂的道路场景中,如何准确、快速地检测出车辆与行人是自动驾驶技术的重点研究内容。
目前主流的目标检测算法主要分两类,传统的目标检测算法以及基于深度学习的目标检测算法[3]。其中传统的目标检测算法主要通过矩形的滑动窗口去搜索图片内的目标,而后利用SURF[4]、HOG[5]等手工特征输入支持向量机、Adaboost等分类器中进行识别。然而在自动驾驶场景中,环境复杂多变,目标形态各异,手工特征往往达不到理想的检测效果,并且传统的目标检测技术检测效率低、精度差、鲁棒性不足,不能达到实际要求。
基于深度学习[6]的目标检测算法自动学习检测目标的高级语义特征,避免了手工特征泛化能力差的问题,具有较高的检测精度和较快的检测速度,已成为自动驾驶目标检测的主流算法。目前,基于深度学习的目标检测算法大概可以分为单阶段和二阶段。其中,二阶段目标检测算法以R-CNN[7]系列为代表,此类算法首先通过提取候选框获取感兴趣部分,并缩放到固定大小,再通过大规模的卷积神经网络提取图片的特征信息,最后再进行目标分类与回归。此算法虽然可以获得较高的精确度,但是其所有的候选框皆需送入大规模的卷积神经网络中,耗费时间过长,导致无法达到自动驾驶的实时性要求。单阶段目标检测算法以SSD[8]、YOLO网络[9-11]等为代表,相较于二阶段目标检测算法,此类算法无须预先设置候选框获取目标信息,便可直接输出目标的位置信息与类别,大大提高了检测效率。Du S等[12]通过在YOLOv4网络基础上加入难挖掘模块(hard negative mining),抑制了复杂背景的干扰,提高了车辆检测精度。Tan L等[13]利用空洞卷积、ULSAM超轻量子空间注意力机制改进YOLOv4网络,提高了特征提取与目标检测性能。
尽管当前的检测算法提升了检测效率,但是常以牺牲检测精度为代价。因此,如何在不降低检测效率的前提下,提高检测精度成为亟待解决的问题。卷积神经网络较深层的特征语义信息更为丰富,但对于检测密集的对象并不有效[14]。在自动驾驶场景下,目标遮挡是行人检测中经常遇到的难题。注意力机制常被用来改善复杂交通环境下的目标检测,突出人脸或车辆等目标特征[15-16]。
文中提出一种改进的YOLOv4算法实现自动驾驶场景下的目标检测。首先,将轻量型注意力模块SimAM[17]引入主干网络,在不增加参数量的前提下加速权值的计算,使得精练的特征更加聚焦目标主体。然后,采用一种新的激活函数ACON-C[18]加速分类过程,进一步提高检测精度,使得网络在保证实时性的前提下,达到较高检测精度。
1 YOLOv4网络
YOLO网络是单阶段目标检测网络代表之一,其直接将检测任务转换成回归问题来进行快速检测,而在训练过程与预测过程利用全图信息,相比较区域候选网络拥有更快的检测速度与更高的检测精度,可以实现端到端的预测。
2020年,Bochkovskiy A等[19]提出了YOLOv4网络,其网络结构如图1所示。
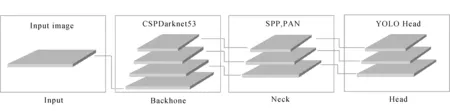
图1 YOLOv4网络结构
与YOLOv3网络相比,YOLOv4在数据输入端采用了Mosaic数据增强,丰富了检测物体的背景,同时也采用了K-means聚类算法对数据集中的目标框进行维度聚类分析。在主干网络部分,采用CSPDarknet53网络作为骨干网络,借鉴CSPNet[20]思想,在YOLOv3的特征网络Darknet基础上形成,降低了计算量,提升计算速度,激活函数采用Mish,使网络得到更好的检测精度和泛化能力。在neck部分,YOLOv4不再使用特征金字塔(FPN),而是改用空间金字塔池化层(SPP)[21]和路径聚合网络(PANet)[22],使用多个尺寸的窗口,扩大了网络的感受野,增强提取特征的能力,同时实现了深层特征与浅层特征的融合,保证了特征的完整性与多样性。在Head部分,YOLOv4网络沿用YOLOv3的检测头,进行大小为3×3和1×1的两次卷积操作完成检测。YOLOv4的网络结构增加了对小目标的检测能力,检测速度也优于YOLOv3等其他系列,更能胜任复杂的自动驾驶场景中的目标检测任务。
2 SimAM-YOLOv4检测算法
2.1 SimAM注意力模块
SimAM模块是由Yang L等[17]提出的一种无参数的注意力模块,从神经科学理论出发,为挖掘重要神经元,构建一种能量函数。
SimAM算法首先评估每个神经元的重要性,在神经科学中,信息丰富的神经元通常表现出与周围神经元不同的放电模式,而且,激活神经元通常会抑制周围的神经元,即空域抑制,所以具有空域抑制效应的神经元应该被赋予更高的重要性。通过度量神经元之间的线性可分性去寻找重要神经元,因此定义如下能量函数:
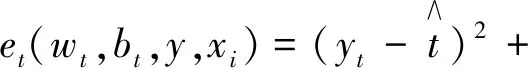

(1)
其中,
最小化上述公式等价于训练统一通道内神经元t与其他神经元之间的线性可分性。采用二值标签,并添加正则项,最终能量函数定义为
et(wt,bt,y,xi)=
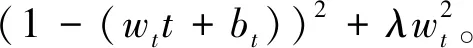
(2)
理论上,每个通道有M=H×W个能量函数。上述公式具有如下解析解:
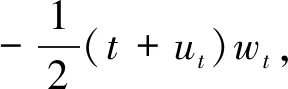
(3)
其中,
因此,最小能量可以通过下式得到
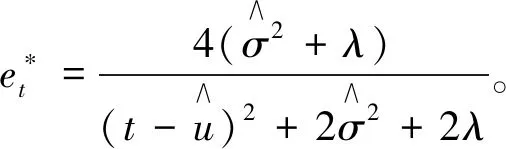
(4)
2.2 ACON-C激活函数
ACON-C激活函数是由Ma N等[18]提出的一种简单有效的激活函数,其函数表达式为
fACON-C(x)=Sβ(ptx,p2x)=
(p1-p2)x·σ[β(p1-p2)x]+
p2x,
(5)
式中:Sβ----平滑最大值函数的微分形式;
β----平滑因子;
σ----Sigmoid函数,该激活函数采用双自变量函数,带有一个额外的超参数β,作用是在功能上使用超参数缩放,通过新增加p1与p2两个超参数,改善可学习的上界与下界。
2.3 SimAM-YOLOv4算法
YOLOv4算法具有较高的实时性检测能力得益于其全卷积神经网络结构和较小的卷积核尺寸,以及回归边界框的算法结构设计,为实现在不增加网络深度的前提下提升网络的检测精度,SimAM-YOLOv4算法仅对YOLOv4主干网络中的残差结构进行改进,通过对传递特征的筛选,使得残差融合时保留更加有效的特征,降低特征损失,有利于后续的定位与分类。
对目标检测任务而言,主干网络对于不同的目标所关注的特征是不同的,如果在训练开始时就以同样的关注度对待每一张特征图,会加快网络的收敛速度。同时,在保证实时性的前提下,由于不引入额外的参数能够保持模型的大小,并且获得了良好的mAP提升,因此选用无参数注意力模块是一个较好的选择。CSPDarknet53主干网络存在大量的残差模块连接,因此在残差模块中嵌入注意力模块时需要对其模块结构进行一定的调整。CSPDarknet53中原始的残差模块如图2所示。
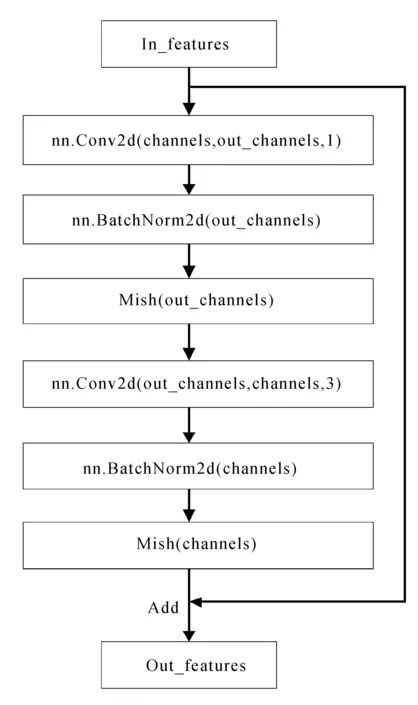
图2 CSPDarknet53中原始残差模块
该模块将特征图输入到两个由二维卷积、标准化和Mish激活函数所组成的卷积块中,再通过跳跃连接,将输入的特征图与处理后的特征图相加得到最终的输出特征图。
改进的CSPDarknet53中残差模块如图3所示。
利用ACON-C激活函数替换原有的Mish激活函数,改善网络可学习的上下限,再通过将SimAM注意力模块嵌入到两个卷积块之后,度量神经元之间的线性可分性,寻找重要的神经元,最后利用跳跃连接,实现原始特征图的重要信息进行筛选。
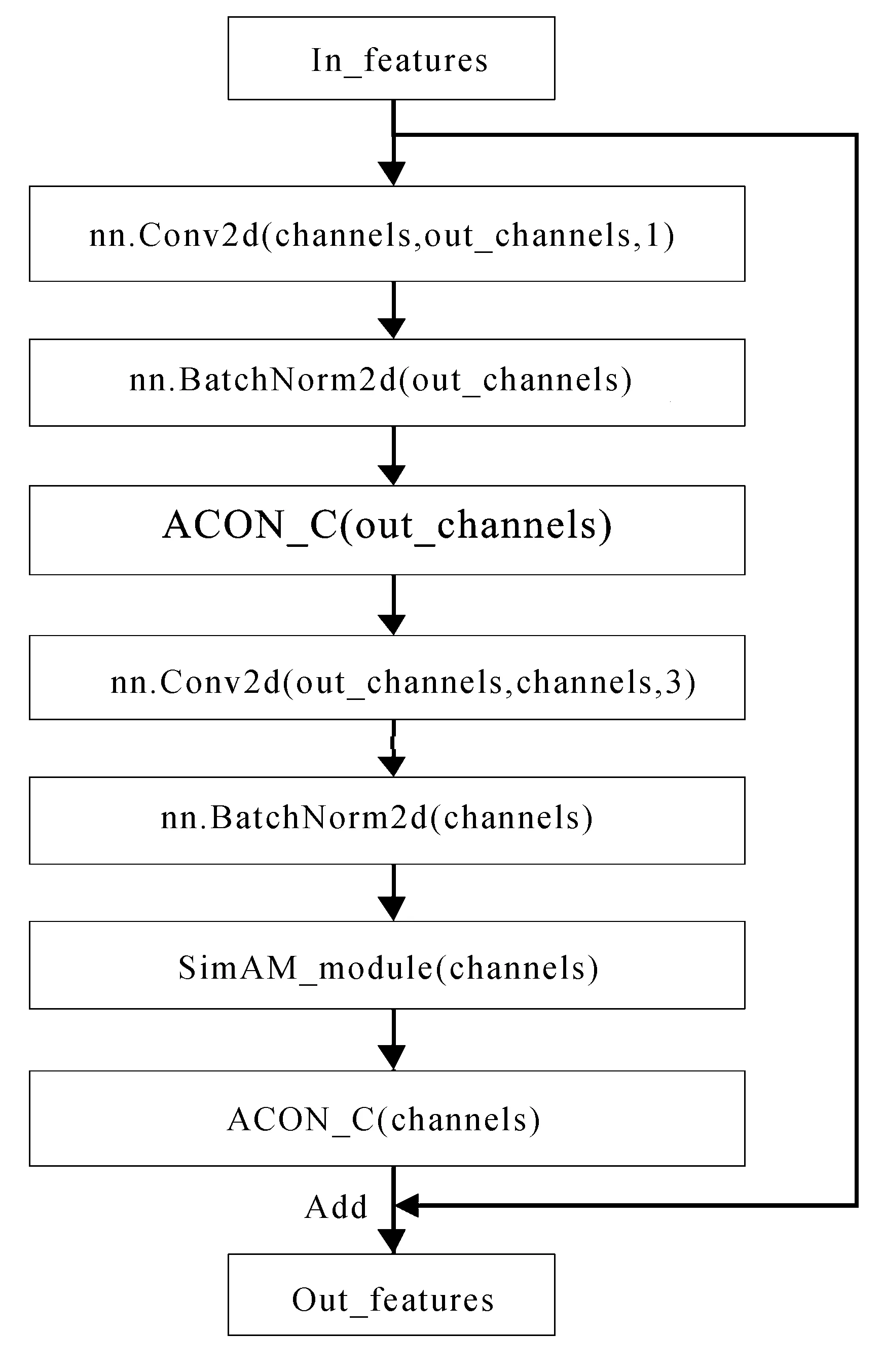
图3 改进的CSPDarknet53中残差模块
3 实验与分析
3.1 实验数据和实验平台
实验数据集选用当前国际上最大的自动驾驶场景下的计算机视觉评测数据集KITTI,数据集共7 481张图片,分8个类别:汽车、箱式汽车、货车、行人、坐着的人、骑车的人、电车和杂项。在实验中考虑到实际场景的复杂性,将数据集的类别进行调整,汽车、箱式汽车与货车合并为汽车;将行人与坐着的人合并为人;骑车的人不作调整;删除最后两个类别。最终得到样本数:汽车33 261个、行人4 709个、骑车的人1 627个。
实验环境配置为:Intel i5处理器,64 G内存,NVIDIA GeForce RTX 3090显卡,Windows10操作系统,Python版本3.8。
3.2 评价指标
在实际自动驾驶场景下,目标检测的速度与精度极其重要。如果模型检测速度过慢,达不到实时性,致使汽车系统来不及对突发事件做出反应,亦或是检测的精度不准确,不能够准确判断目标的类别与位置,导致汽车在驾驶过程中无法做出正确识别,最终导致车祸发生。
根据上述问题,本实验检测的精度评价指标选用mAP值(mean Average Precision)来衡量,mAP值表示所有类别的平均精度值(Average Precision, AP)的平均值,而AP值是由精确率(Precision)和召回率(Recall)形成的PR曲线和横纵坐标组成的面积计算得到,其计算为
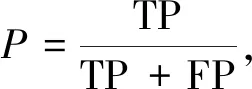
(6)
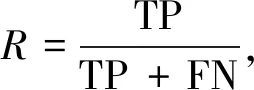
(7)
式中:TP----正类样本预测为正类样本的数量;
FP----负类样本预测为正类样本的数量;
FN----正类样本预测为负类样本的数量。
选用FPS(frames per second)去衡量算法的检测速度,即每秒处理的图片数量或者处理每张图片所需要时间。
3.3 模型训练
实验采用迁移学习,将原始YOLOv4网络的预训练模型的参数加载到SimAM-YOLOv4网络中进行训练,总共迭代500次,前100次迭代采用冻结主干网络参数训练,防止训练初期权值被破坏,加快训练速度,此时批量大小设定为8,学习率设定为0.001,剩余400次迭代,将所有参数解冻全部参与训练,批量大小设定为4,学习率设定为0.000 1。在训练过程中输入图片的分辨率大小设定为608*608,优化策略采用余弦退火的Adam优化算法,设定参数T_max为5,参数eta_min为0.000 01。
3.4 实验结果与分析
为了验证各个方法改进的有效性,分别采用原始YOLOv4网络、添加SE-Attention注意力模块的YOLOv4网络、添加CBAM注意力模块的YOLOv4网络、添加SimAM注意力模块的YOLOv4网络以及同时添加SimAM注意力模块和激活函数的SimAM-YOLOv4网络进行实验对比,网络模型性能对比见表1。
通过表1可以看到,原始YOLOv4在没有改进的条件下,mAP值为85.85%,加入CBAM注意力模块的YOLOv4,其mAP值为89.95%,mAP提升4.1%,为20 帧/s,牺牲25 帧/s,加入SE注意力模块的YOLOv4,其mAP值为90.08%,mAP提升4.23%,为34 帧/s,牺牲11 帧/s,加入SimAM注意力模块,mAP提升4.01%,为40 帧/s,牺牲5 帧/s,可以看出,SimAM模块仅牺牲了较低的速度,获得了与其他注意力模块相近的mAP提升。
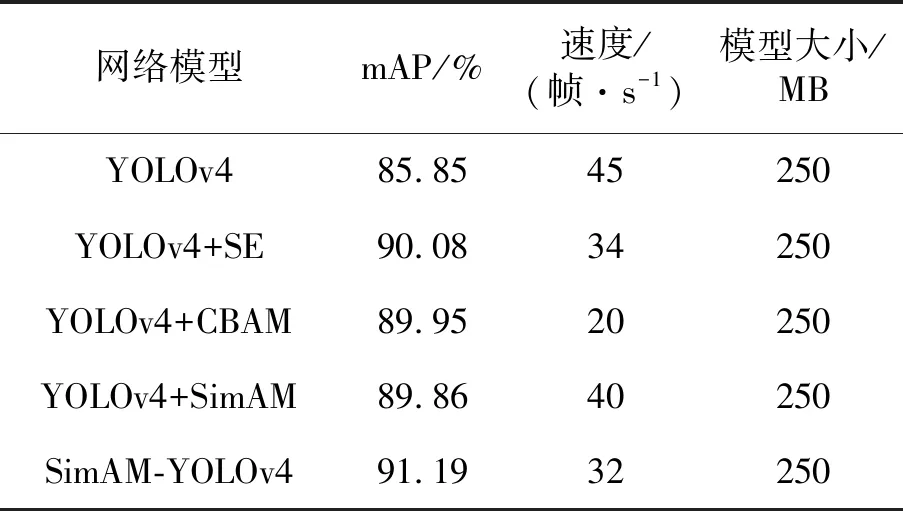
表1 不同模型性能对比
在SimAM注意力模块的基础上加入ACON-C激活函数,修正了特征向量,使得后续检测可以充分利用特征,mAP相比原始YOLOv4提高5.34%,与只加SimAM注意力模块模型结果提高1.33%。虽然都有检测速度的损失,但能够满足实时性的要求。同时不同模型针对不同类别的检测性能进行对比,实验结果对比见表2。
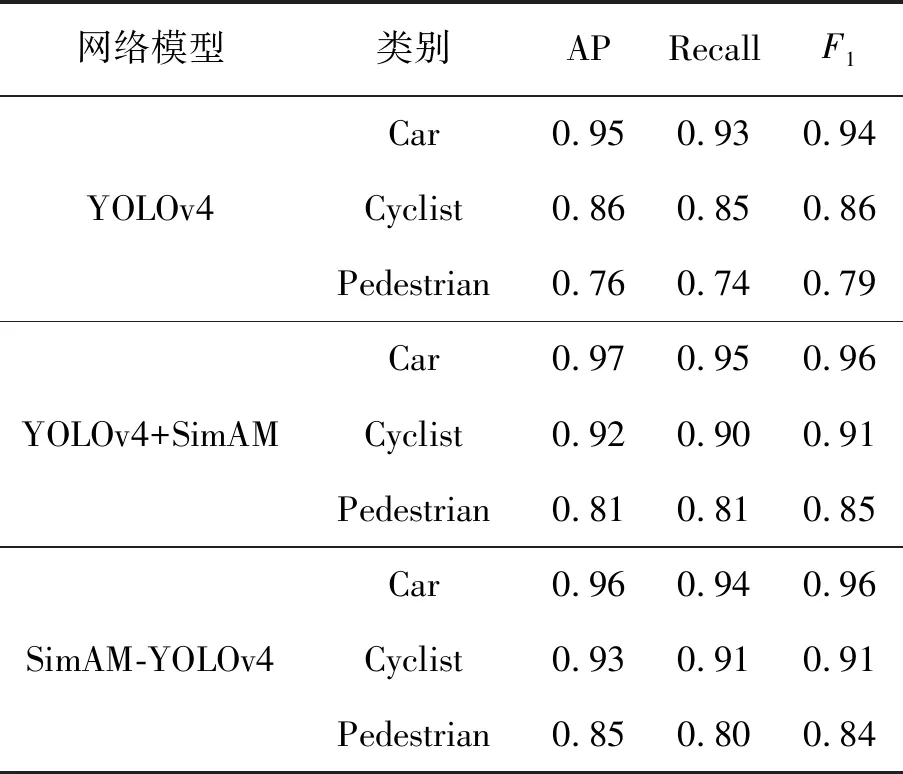
表2 不同类别的对比结果
通过表2可以看出,原始YOLOv4对大目标Car检测精度很高,而对小目标Cyclist、Pedestrian检测精度明显达不到要求。通过嵌入SimAM注意力模块,Car类AP提升2%,Cyclist类AP提升6%,Pedestrian类AP提升5%。SimAM-YOLOv4相较于只引入注意力机制,Car、Cyclist类指标基本不变,但Pedestrian类AP提升4%。由此可以看出,SimAM-YOLOv4有效地解决了原始YOLOv4对小目标检测精度不足的问题。
为了更加直观地感受上述不同算法之间的差异,文中选取了一组检测结果进行对比分析,检测效果如图4所示。

(a) 原始YOLOv4模型

(b) OLOv4+SimAM

(c) SimAM-YOLOv4模型
从实验效果可以看出,原始YOLOv4对检测出的对象具有较高的置信度,但由于遮挡存在漏检问题,相较而言,引入SimAM注意力模块有效地解决了漏检问题,但存在某些目标置信度较低的问题,而SimAM-YOLOv4既解决了漏检问题,也解决了遮挡导致目标置信度较低的问题。
综上所述,SimAM-YOLOv4对YOLOv4的改进与优化具备合理性与有效性,在自动驾驶场景下的目标检测任务中提升了原算法的检测性能。
4 结 语
提出一种基于改进YOLOv4的自动驾驶场景目标检测任务的算法,针对原始YOLOv4对于小目标检测精度低的问题,SimAM-YOLOv4使用SimAM无参注意力模块结合ACON-C激活函数改进主干网络中的残差结构,引导网络对所提取出的特征图进行充分的修正,更好地筛选出有利于后续检测的特征。在KITTI数据集上的mAP达到91.19%,较原始模型提升5.34%,检测速度达到32 帧/s。在满足实际自动驾驶对目标检测实时性需求的前提下,以较低的推理耗时换取了较大的检测精度提升。同时模型大小为250 MB,与原模型大小几乎相同,可以更好地应用在自动驾驶场景中。下一步工作将从网络结构轻量化的角度优化模型,继续研究注意力模块及激活函数机理,进一步提高检测精度与速度。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化·八年级物理人教版(2019年12期)2019-05-21
电子制作(2018年11期)2018-08-04
现代装饰(2018年5期)2018-05-26
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
测绘科学与工程(2016年5期)2016-04-17
电源技术(2015年5期)2015-08-22
中国生化药物杂志(2015年4期)2015-07-07
弹箭与制导学报(2015年1期)2015-03-11
