
基于ACNN和Bi-LSTM的微表情识别
2022-11-22 11:18朱文球李永胜黄史记阳昊彤
湖南工业大学学报 2022年6期
朱文球,李永胜,黄史记,阳昊彤
(湖南工业大学 计算机学院,湖南 株洲 412007)
0 引言
相对于普通表情,微表情是一种持续时间短并且动作幅度小的表情变化。微表情是人们在试图掩盖内在情绪时产生的一种自发性表情,是一种既无法伪造也无法抑制的表情[1-4]。1966年,Haggard 等发现了一种快速且不易被人眼所察觉的面部表情,并首次提出了微表情的概念[2]。起初这种微小且短暂的面部变化并没有引起其他同行研究人员的注意。直至1969年,P.Ekman 等[5]在研究抑郁症患者的一段录像时,发现处于微笑表情表现的病人会出现短暂的痛苦表情,该患者用微笑等积极性表情来掩饰内心的焦虑[3]。和宏表情不同的是,微表情的持续时间仅为1/25~1/5 s,因此仅凭人眼对微表情进行识别并不能满足精确辨别的需要,因而使用现代人工智能手段识别微表情是非常有必要的。
T.Pfister 等[6]利用三维正交平面局部二值(local binary patterns from three orthogonal planes,LBPTOP)算法,将特征提取方式由XY方向扩展到XY、XT和YT组成的3 个正交平面上,即将以往的静态特征提取拓展到随时间信息变化的动态特征提取。Peng M.等[7]提出了一种深度学习的自动抠图(ATNet)方法,即利用ResNet10 从顶点帧中提取出微表情空间信息,再利用长短期记忆网络(long short-term memory,LSTM)从相邻帧中提取出微表情时间信息,并且在特征融合后进行识别。Liu J.等[8]提出了利用原始灰度图训练空间注意力模型SAIN_GRAY,但是该模型并没有考虑图像间的序列相关性。Quang N.V.等[9]利用胶囊网络(CapsuleNet)进行了微表情识别,其首先提取出微表情的顶点帧,接着把顶点帧输入胶囊网络中提取空间信息,最后分类输出,这种方式可以比较有效地提取出空间信息,但是忽略了微表情的时间相关性。
1 相关工作
1.1 面部表情编码系统
面部表情编码系统(facial action coding system,FACS)是P.Ekman 等[5]在1976年提出的。微表情有两种分类标准:基于情绪的分类和基于面部动作编码系统的分类[10]。FACS 依据解剖学按区域将人脸划分为44 个运动单元(action unit,AU),每个动作单元表示一个特定的面部局部动作,如动作单元1表示眉毛内侧上扬(inner brow raiser),而动作单元5 表示拉动上嘴唇向上运动(upper lip raiser)等。人脸面部有42 块肌肉,丰富的表情变化是由多种肌肉共同作用的结果。有些面部肌肉可以受意识控制,被称为“随意肌”;还有一些面部肌肉不受意识控制,被称为“不随意肌”。微表情的产生通常是由一个或多个运动单元(AU)共同作用的结果,如代表高兴的微表情是由AU16 和AU12 共同作用的结果,其中AU16 表示下嘴唇向下拉动,AU12 表示嘴角上扬。FACS 是微表情识别的重要依据,是对眉毛、脸颊与嘴角等面部关键点特征的运动记录。
1.2 带有注意力机制的卷积神经网络
为了解决微表情识别中的持续时间短、动作强度低等缺点,本文采用基于带有注意力机制的卷积神经网络(convolution neural network with attention mechanism,ACNN)的改进算法。ACNN 是在卷积神经网络的基础上添加了注意力网络,使得ACNN模型在微表情识别中不仅可以提取整个面部的特征,还可以专注于表情的局部细节变化,从而提取出更细微的面部特征。课题组基于ACNN 算法,并对其进行了改进,即增加了局部注意力网络、全局注意力网络,以及双向长短期记忆网络(bi-directional long short-term memory,Bi-LSTM),以适用微表情视频序列的识别。CNN 具有提取出微表情抽象特征的能力,带有局部注意力网络的ACNN 用于提取微表情变化中关键局部单元的运动信息,而带有全局注意力网络的ACNN 可以提取全局的变化信息。本文中将局部ACNN 和全局ACNN 相结合,期望改进后的ACNN 模型具有既关注全局又兼顾细节的能力。
1.3 双向长短期记忆网络
普通的卷积神经网络以及全连接层都有一个共同的特点,即在处理具有连续性的序列时都不能“记忆”时序间的相关信息。循环神经网络(recurrent neural network,RNN)[11]新增了一个可以保存状态信息的隐藏层,这个隐藏层包括了序列输入的某些历史信息,并随着输入序列的增加不断自我更新。然而普通循环神经网络最大的缺点,是随着训练规模与层数的增大很容易产生长期依赖问题(long-term dependencies problem),即在对较长序列学习时容易产生梯度消失和梯度爆炸等问题。为了解决循环神经网络的上述问题,20世纪90年代初,Hochreiter 等提出了长短期记忆网络(LSTM)[12]。LSTM 中每一个单元块包括输入门(input gate)、遗忘门(forget gate)和输出门(output gate)。其中,输入门用来决定当前时刻的输入数据有多少可以保存到本状态单元;遗忘门用来表示上一时刻的状态单元有多少可以保存到本状态单元;输出门控制当前状态单元有多少可以用来输出。双向长短期记忆网络(Bi-LSTM)在单向LSTM 中增加反向传播层,使得LSTM 模型不仅可以利用历史序列信息还可以利用未来的信息。Bi-LSTM 相对于LSTM 可以更好地提取出微表情中的特征信息与序列信息。
2 本文方法介绍
2.1 方法概述
本文提出了一种基于带有注意力机制的卷积神经网络(ACNN)和双向长短期记忆网络(Bi-LSTM)相结合的神经网络结构。为了实现对微表情较小幅度的动作进行精准地捕捉,本文对传统的ACNN 框架进行了改进。改进后的ACNN 框架会对面部多个微表情区域块提取出不同的特征信息,同时除了微表情区域块的特征提取,也增加了对全局信息的处理。改进后的模型架构如图1所示。
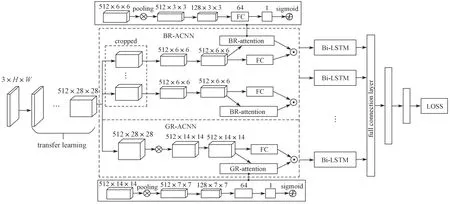
图1 基于ACNN 和Bi-LSTM 的微表情识别模型Fig.1 Micro-expression recognition model based on ACNN and Bi-LSTM.
改进后的模型中,网络首先将预处理后的微表情特征向量通过带有预训练权重的VGG16[13]模型进行迁移学习,并从中提取出基本面部特征,再将每一帧提取出的面部特征分别经过局部识别块注意力卷积神经网络(block recognition based convolution neural network with attention mechanism,BR-ACNN) 与全局注意力卷积神经网络(global recognition based convolution neural network with attention mechanism,GR-ACNN)提取出整体与局部信息;接着,把提取出的整体与局部信息进行融合,并通过Bi-LSTM 提取出序列的相关信息,最后通过3 层全连接层进行分类输出。
对于全局和局部特征的提取,本文引入了两种不同的ACNN,即局部识别块注意力卷积神经网络(BR-ACNN)和全局注意力卷积神经网络(GRACNN)。如图1所示,BR-ACNN 为图中虚线框内上半部分,GR-ACNN 为图中虚线框内下半部分。
2.2 局部识别块注意力卷积神经网络
由于微表情面部变化的幅度较小,很难被有效识别,故本实验采用面部关键区域块注意力的识别方法,即在要识别的面部特征中增加微表情关键代表性区域的识别,以及对应的注意力网络。详细实验方法描述如下。
1)确定微表情识别点。首先,使用Dlib[14]方法提取出68 个面部关键点(如图2a);其次在68 个面部关键点的基础上经过转换,成为24 个微表情识别点,识别点位置覆盖脸颊、嘴巴、鼻子、眼睛、眉毛等处。转换过程如下,首先从68 个面部关键点中选取16 个覆盖嘴巴、鼻子、眼睛、眉毛的识别点,68 个面部关键点(如图2a)中的提取序号为:19、22、23、26、39、37、44、46、28、30、49、51、53、55、59、57。最终生成的微表情识别点(如图2b)序号为:1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16。其次,对于眼睛、眉毛以及脸颊部分,由于没有直接的关键点覆盖,本文通过关键点的中点坐标进行生成。左眼、左眉毛与左脸颊部分从68 个面部关键点(如图2a)中选取(20,38)、(41,42)、(18,59)点对的中点坐标作为微表情识别点;右眼、右眉毛与右脸颊部分从68 个面部关键点中选取(25,45)、(47,48)、(27,57)点对的中点坐标作为微表情识别点。最终生成的识别点(如图2b)序号为17、19、18、20、21、22。最后,对于左右嘴角部分,本文从68 个面部关键点(如图2a)中选取49、55 两个关键点,然后分别根据这两个点的坐标选择两个嘴角的相对偏移点,最终得到识别点的坐标。最终生成的左右嘴角识别点(如图2b)序号为:23、24。式(1)(2)分别是左右嘴角识别点的计算方式。
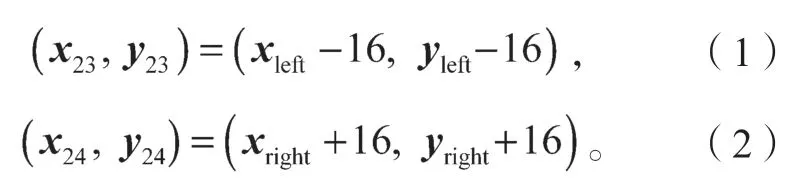
式中:xleft、yleft为序号为49 关键点的横、纵轴坐标;
xright、yright为序号为55 关键点的横、纵轴坐标;
x23、y23分别为序号为23 识别点的横、纵轴坐标;
x24、y24分别为序号为24 识别点的横、纵轴坐标。
最终得到了24 个微表情识别点(图2b),重新选取的24 个微表情识别点在实验中将会生成以识别点为中心的24 个6×6 的识别块。为了提高模型的鲁棒性、增大识别块的感受野,识别块将会作用在经过VGG16 迁移学习处理后的512×28×28 特征向量上,从而得到24 个识别块,每个识别块大小为512×6×6。
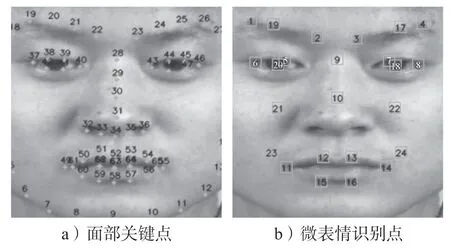
图2 面部关键点及其处理后的微表情识别点位置图Fig.2 Location map of facial key points with their processed micro-expression recognition points
2)注意力机制算法。带有注意力机制的局部识别块卷积神经网络(BR-ACNN)如图1虚线框内上半部分所示。在BR-ACNN 中,经过裁剪后得到的24 个局部识别块分别经过一个全连接层和一个输出为权重标量的普通注意力网络,最后得到24 个带权特征向量。
在注意力网络中(图1虚线框上半部分),假设ci表示第i个识别块的特征向量,则可利用式(3)计算第i个识别块的注意力权重,利用式(4)计算第i个识别块提取后且未加权的特征,利用式(5)计算第i个识别块带有注意力权重的特征向量。这样,经过计算后,便可得到所有识别块的带权特征向量。
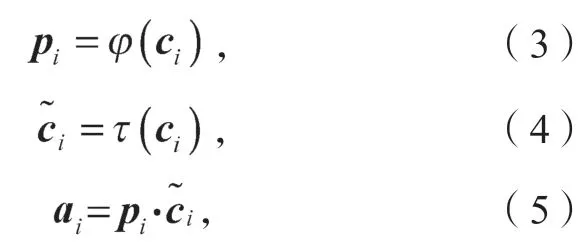
式(3)~(5)中:pi为第i个识别块的注意力权重;
ci为第i个识别块的特征向量;
φ(·)为注意力网络中的操作;
τ(·)为对输入特征向量的特征学习;
ai为第i个识别块带有注意力权重的特征向量。
2.3 全局注意力卷积神经网络
BR-ACNN 具有学习人脸面部特征细微变化的能力,然而完成微表情动作有时涉及面部各个部位的相互配合。在特征识别中融合全局特征,有望提高微表情的识别效果,所以不仅需要提取面部区块的特征,还需要提取全局的特征。
全局注意力卷积神经网络(GR-ACNN)的详细结构如图1虚线框内下半部分所示,其输入特征向量大小为512×28×28。首先,本文将输入的全局特征向量通过VGG16 网络的conv4_2 层到conv5_2 层,得到输出大小为512×14×14 的特征向量;其次,将大小为512×14×14 的特征向量,分别经过一个全连接层和一个输出为权重标量的注意力网络;最后,输出带权重的全局特征向量。
2.4 双向长短期记忆网络
RC-ACNN 和RG-ACNN 可以提取出微表情某一帧局部和整体的信息,然而微表情视频帧之间在连续时间内是动态变化的,因此还需要提取微表情时间上的变化信息。长短期记忆网络(LSTM)是一种为了克服传统循环神经网络(RNN)中的长期依赖问题而设计出来的新结构。而Bi-LSTM 是在LSTM 的基础上增加反向层,使得新的网络结构不仅能够利用已经输入的历史信息能力,还具有捕获未来的可用信息的能力。
双向循环神经网络的结构如图3所示,图中w为学习权重。
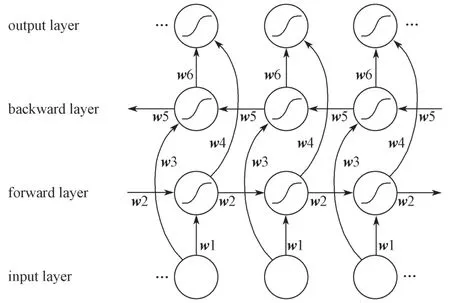
图3 双向循环神经网络结构图Fig.3 Structure diagram of bidirectional recurrent neural network
如图3所示,双向长短期记忆网络(Bi-LSTM)结构把双向循环神经网络每个节点换成LSTM 单元。定义Bi-LSTM 网络模型输入特征序列为,前项传播中隐藏层变量序列为,反向传播中隐藏层变量序列为,定义Bi-LSTM 模型输出序列为,可得出以下公式:
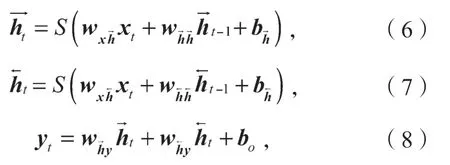
式(6)~(8)中:S(·)为激活函数;
w为Bi-LSTM 的权重;
b为偏置项。
对每个部分使用LSTM 单元进行计算,LSTM单元的网络结构如图4所示。
LSTM 的输入是经过BR-ACNN 和GR-ACNN 模型从帧序列中提取并进行拼接操作后的空间特征值,本文采用单层双向的LSTM 结构,其中包含一个256个节点的隐藏层。为了增加模型网络节点的鲁棒性,减少神经元之间复杂的共适应关系,在双向LSTM隐藏层和全连接层之间增加了Dropout 层,以一定概率随机屏蔽神经元。
3 实验
3.1 数据集的选择与预处理
实验选用中国科学院心理研究所傅小兰团队所建立的CSAME II 数据集[15]。CSAME II 微表情数据集采用200 帧/s 的高速摄像头,每帧大小为280×340 像素。CSAME II 微表情数据集有255 个样本,数据集中参与者的平均年龄为22 岁,被采集者总数为24 个。该数据集包括被采集者每个样本对应的微表情标签,并分别带有起始帧、顶点帧和结束帧视频序列。标签包括压抑、厌恶、高兴、惊讶、害怕、伤心及其他分类(repression,disgust,happiness,surprise,fear,sadness,others)。本文将CSAME II 数据集划分为消极、积极、惊讶3 类,划分结果如表1所示。
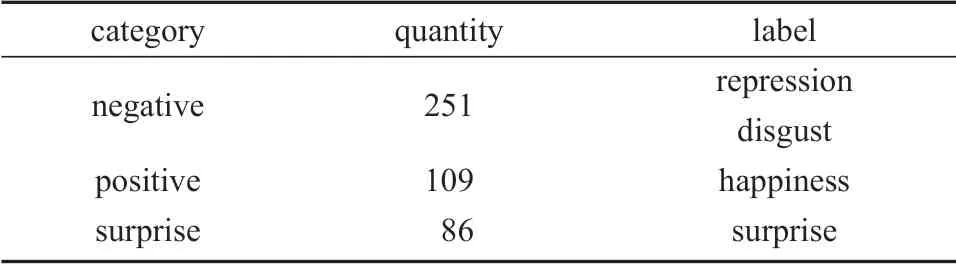
表1 数据集划分情况Table 1 Data set division
本研究首先通过时域插值模型(temporal interpolation model,TIM)[16]将微表情数据集处理成固定10 帧的输入序列,并通过双线性插值[17]将视频帧归一化为224×224 像素。接下来使用Dlib[18]裁剪对齐,并提取出68 个面部关键点,在对面部关键点进行实验分析后,本文选取其中的24 个微表情面部运动识别点,并由24 个识别点生成24 个大小为6×6 的识别块。最后,把经过预处理的视频帧和每一帧的识别块放入模型训练。
3.2 实验评估标准
由于微表情数据集的数量较少,为了保证实验的准确性,本文选用5 折交叉验证,即把训练集分为5等份,每次训练选取其中1 份作为验证集,其余4 份作为测试集,依次类推,循环5 次,直至所有数据都做过训练集和验证集。
本文采用了未加权F1值UF1(unweightedF1-score),未加权平均召回率UAR(unweighted average recall),以及准确率Acc(accuracy)的评价指标。未加权F1值的计算如式(9)所示,未加权平均召回率的计算如式(10)所示,准确率的计算如式(11)所示。
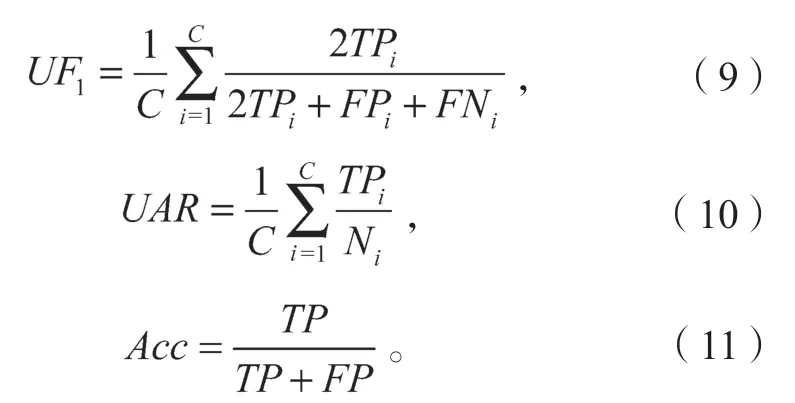
式(9)~(11)中:TPi、FPi、FNi分别为第i个类别中真正例、假正例、假负例的数量;
C为类别数;
Ni为第i个样本的数量;
TP为所有种类中真正例的数量;
FP为所有种类中假正例的数量。
3.3 实验结果
训练使用Adam 优化器,学习率为0.000 16,迭代次数epoch 设置为100,训练batch_size 设置为16。因为微表情是小数据集,容易过拟合,为了提高模型的鲁棒性与泛化能力,本文对模型参数取正则化的L2 范数,并在损失函数中加上λ倍的L2参数范数,经过多次实验,结果表明λ设置为0.01 时模型效果最好。图5为5 折交叉验证的平均损失曲线,图6为5 折交叉验证的平均准确率曲线,横坐标为迭代的epoch 次数,纵坐标为准确率。
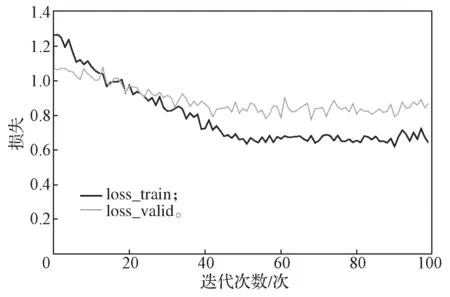
图5 5 折交叉验证的损失曲线Fig.5 5-fold cross-validation loss curves
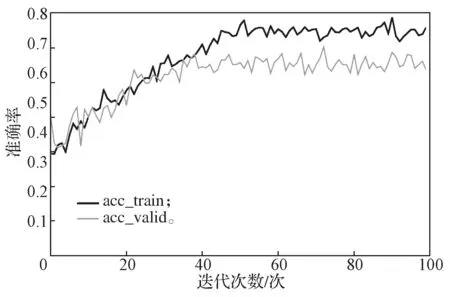
图6 5 折交叉验证的准确率曲线Fig.6 5-fold cross-validation accuracy curves
5 折交叉验证结果的具体准确率数据如表2所示。

表2 验证训练的准确率数据Table 2 Training accuracy results %
表2所示实验结果显示,5 折交叉验证的平均准确率为69.04%,UF1为0.638 2,UAR为0.675 0。最终的混淆矩阵如图7所示,预测结果在“消极”附近分布比较多,并且准确率较高,这主要是由数据集分布的不平衡性导致的。因为CASME II 数据集在采集中“积极”的微表情比较难触发,所以数据集标签为“消极”的数目远大于标签为“积极”的数目,这才导致数据集分布不平衡,从而影响训练精度。
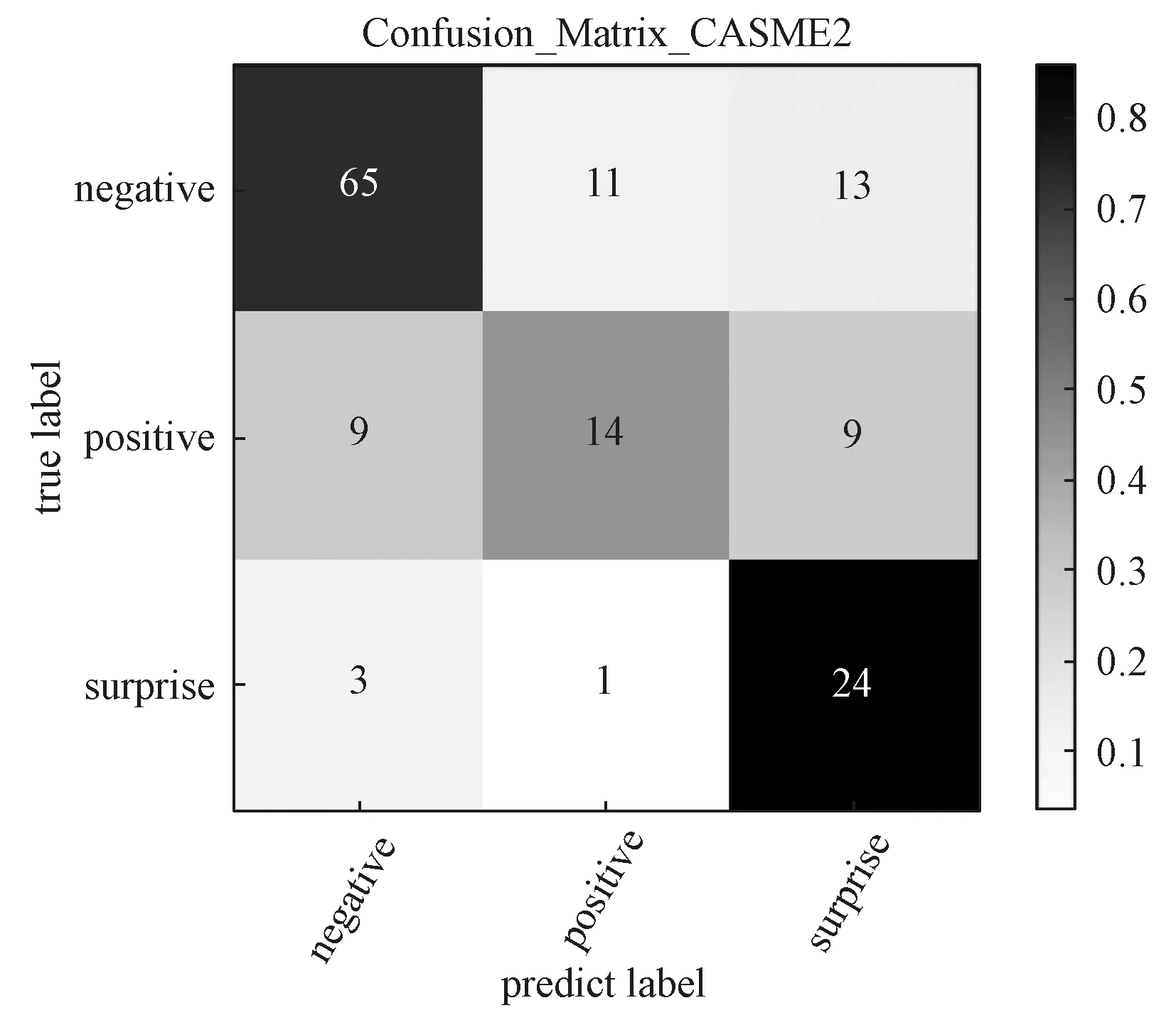
图7 混淆矩阵图Fig.7 Confusion matrix diagram
3.4 数据分析
不同算法的识别效果对比如表3所示。
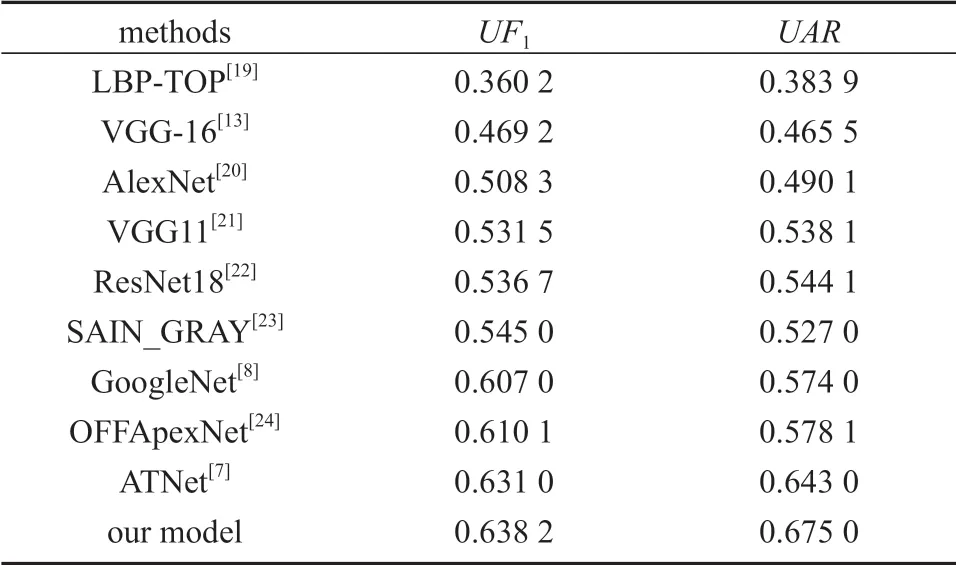
表3 不同算法识别效果对比Table 3 Comparison of recognition effects of different algorithms
表3中的数据表明,本文改进的算法模型相对于以往的识别算法,其精度有了相对的提高。其中相对OFFApexNet 模型,改进算法的UF1提高了0.028 1,UAR提高了0.096 9;相对ATNet 模型,改进算法的UF1提高了0.007 2,UAR提高了0.032 0。这主要是因为:OFFApexNet 模型依靠起始帧和顶点帧的光流变化进行微表情识别,但忽略了其他连续帧中有用的微表情信息。ATNet 模型利用ResNet 网络从顶点帧中提取出微表情的空间信息,利用LSTM 从相邻帧中提取出微表情的时间信息,并在特征融合后进行识别。ATNet 模型虽然考虑到连续帧中空间与时间信息,但是在空间特征提取中并没有兼顾微表情面部不同部位关注度的差异性。
4 结语
微表情具有持续时间短、动作幅度小等特点,因此微表情数据集较小,容易产生过拟合,针对这一问题,本文在ACNN 框架的基础上进行了改进,提出了局部注意力网络和双向长短期记忆网络结合的识别方式。首先,将预处理后的微表情视频帧通过VGG16 提取出特征集合;然后,将提取出的特征集合分别通过局部识别块注意力卷积神经网络(BRACNN)和全局注意力卷积神经网络(GR-ACNN)提取出局部与全局特征;接下来,通过双向长短期记忆网络(Bi-LSTM)提取出每一帧的序列信息;最后,通过3 层全连接层进行分类。实验结果表明,基于识别块注意力网络与双向长短期记忆网络的识别方式,可以从动作幅度小的视频帧里有效地提取出有用信息,并在实验中表现出较高的准确率。但是微表情数据集数量较少,持续时间普遍较短、强度较低,这仍然是导致实验识别率较低的主要原因,这一点在混淆矩阵中尤为明显。
在以后的研究中,对于数据集数量较少的问题,还需要进一步完善数据集,以促进微表情识别的发展;对于微表情强度低的问题,在数据预处理部分下一步,可以通过对视频起始和峰值帧之间的视频帧做线性时域插值以强化峰值帧的作用。此外,微表情识别点的选取可以依据以后的实验再优化,识别点的选取应该尽量具有代表性。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
今日农业(2021年8期)2021-11-28
建材发展导向(2021年11期)2021-07-28
数学大世界(2019年7期)2019-05-28
金桥(2018年4期)2018-09-26
中华建设(2017年1期)2017-06-07
新高考·高一物理(2015年5期)2015-08-18
中国卫生(2014年2期)2014-11-12
