
基于卷积神经网络的单图像去雾模型硬件重构加速方法
2022-11-08 12:43王官军简春莲向强
计算机应用 2022年10期
王官军,简春莲,向强*
(1.西南民族大学 电子信息学院,成都 610041;2.成都动力视讯科技股份有限公司,成都 610046)
0 引言
由于空气中存在大量的悬浮颗粒物对光线产生散射等原因,造成摄取图像的质量严重下降,直接影响后期的智能应用[1];此外,虽然云计算和5G 的发展能为移动终端提供算力支持,但对于实时性要求较高的智能应用如无人驾驶,云计算存在未知风险。因此,进一步研究图像、视频去雾算法以及去雾算法加速是必要和具有实际意义的。
近几年来,去雾算法得到了快速的发展,特别是基于卷积神经网络(Convolutional Neural Network,CNN)的去雾算法(模型)。该类算法较暗通道先验[2]、Retinex 等传统去雾算法鲁棒性更高,透射率图等估计更准确。目前,CNN 去雾算法主要有两种方式[1,3]:使用CNN 生成大气散射模型的某些参数,然后再根据大气散射模型恢复出无雾图像[4-7];使用CNN直接根据模糊图像生成无雾图像[8-12]。其中,2016 年Cai等[6]利用CNN 首次提出名为DehazeNet 去雾网络,用于估计有雾图像的透射率;其使用全局大气光值和分块估计的方式,使得单张640×480 图像在CPU 上推理耗时为5.09 s[8]。针对耗时较长的问题,余春艳等[7]提出改进方法并使用CUDA(Compute Unified Device Architecture)加速,最终去雾耗时为0.048 9 s;然而,对透射率和大气光分别估计会累积误差并可能相互放大。于是,2017 年Li等[8]首次提出一种名为AOD-Net 的端到端的轻量级去雾网络,即直接从有雾图像恢复出清晰图像,单张640×480 去雾时间为0.65 s。为了进一步缩小AOD-Net 的去雾时间,2020 年Qian等[9]提出一种计算效率更高的模型,称为FAOD-Net,去雾耗时降低为0.34 s。此外,Zhang等[10]提出一种适用于任意尺寸的单图像去雾模型,称为FAMED-Net,其包含三个不同尺度的解码器和融合模块,用于直接学习去雾后的图像。Chen等[11]采用生成对抗网络,构造出名为GCANet 的单图像去雾网络模型。
此外,对于暗通道先验[2]、Retinex 等传统去雾算法的硬件加速部署,已有广泛研究[13-17]。张春雷等[13]基于FPGA(Field Programmable Gate Array),对改进暗通道先验算法进行硬件加速,能够实现1080P@60 frame/s 视频去雾。陆斌等[16]在暗通道先验的基础上,引入硬件处理架构来优化透射率和大气光值的计算方式,可显著地提高处理速度,实现1080P@69 frame/s 的视频去雾。齐乐等[17]基于高级综合(High-Level Synthesis,HLS)工具和C 语言,实现对暗通道先验快速的硬件部署,可实现1080P@45 frame/s 的视频去雾。
综上,虽然有对暗通道先验、Retinex 等传统去雾算法硬件加速部署的研究,以及有大量CNN 单图像去雾算法模型的研究成果,但是对CNN 单图像去雾算法模型的硬件重构,输出具有高性能扩展总线接口(Advanced eXtensible Interface 4,AXI4)的硬件IP核,并用作视频去雾,尚缺乏研究。针对该问题,本文基于Zynq 片上系统(System-on-Chip,SoC)提出一种去雾模型硬件重构加速的方法。首先,基于TFLite 原理[18-19]提出“量化-反量化”算法,在保证去雾效果的前提下,确定了两类代表去雾模型(AOD-Net[8]和DehazeNet[6])最低可量化为5 bit;其次,基于视频直接存储器访问(Video Direct Memory Access,VDMA)[20]视频流存储器架构和软硬件协同、流水线等技术以及HLS[21-22]工具,对量化后的AOD-Net 去雾模型硬件重构,并生成具有AXI4 标准总线接口的硬件IP核,且在Zynq7035 硬件平台上搭建测试环境。实验结果表明,所提方法能够实现单图像去雾到1080P@60 frame/s 视频去雾的拓展。此外,这种生成带有标准总线接口的硬件IP 核也便于跨平台移植和部署,从而可以扩大这类去雾算法模型的应用范围,也能为其他模型的硬件部署提供数据和方法参考。
1 AOD-Net去雾模型
AOD-Net[8]是首个通过轻量级CNN 直接生成清晰图像,可以与Faster R-CNN(Faster Region proposal CNN)连接,以提高对模糊图像的检测性能。AOD-Net 由两个模块组成,如图1(a)所示:一个是K(x)估算模块,用于从输入图像I(x)中估计K(x);一个是去雾图像生成模块,K(x)作为其输入自适应参数来估计J(x)。其数学表达如式(1)所示:
K(x)估算模块是AOD-Net 的关键组成部分,负责估算深度和雾的浓度。如图1(b)所示,K(x)共有5 个卷积层,并通过融合不同大小的卷积核形成多尺度特征。
虽然AOD-Net 去雾模型较为简单,但是它包含了CNN 去雾模型的基本结构,如图1(b)中的3×3、5×5 等多尺度特征的提取、不同特征的融合、多通道2D 卷积以及卷积边界的填充等基本结构。
2 本文方法
本文去雾模型硬件重构加速方法主要包含两个方面的内容:模型量化和模型重构。首先,基于TFLite 原理[18-19]提出“量化-反量化”算法。该算法能去掉多余乘积项,并确定可量化的最低bit数,从而将模型参数直接部署到可编程逻辑(Programmable Logic,PL)资源中,并实现仅整型和移位运算。其次,针对去雾模型的结构特点和视频流去雾的初衷,提出一种模型硬件重构方法。
2.1 量化-反量化算法
TFLite 模型量化原理[18-19],是谷歌在2017 年提出的一种模型压缩算法。该算法的核心是用量化模型代替全精度模型,允许仅使用整数和移位运算进行推理。其浮点数和整型之间的换算如式(2)~(3)所示:
其中:r是浮点数;q是量化后的整数;S是尺度因子,表示实数和整数之间的比例关系;Z是零点,表示实数中0 经过量化之后对应的整数值。S和Z的计算公式如式(4)~(5)所示:
其中:rmin和rmax分别是r的最小值和最大值,是根据不同量化对象进行统计而得出的值。如果已确定量化比特数以及统计出该计算对象的实数范围,那么就可以利用式(4)~(5)计算出S和Z,进而利用式(3)计算出其量化结果。
此外,TFLite 模型量化对卷积运算(矩阵乘法)也有量化方法。假设R1和R2是浮点实数上两个N×N的矩阵,R3是R1、R2相乘后的矩阵,则R3可表示为(假设R1为输入特征图,R2为模型参数,R3为输出特征图):
假设S1、Z1是R1矩阵对应的尺度因子和零点,S2、Z2、S3、Z3同理,则将式(2)代入式(6),移项变型可得式(7):
由式(7)可知,除S1S2/S3∈(0,1)以外,其他都是定点整数运算。为了实现仅整型和移位运算,令M=S1S2/S3=2-nM0。其中,n是非负整数,M0∈[0.5,1)是一个定点实数,则可以通过M0的位移操作来近似逼近M,从而整个矩阵相乘的过程仅是定点整数和移位运算[18]。此外,为了简化计算,本文把输入和输出特征图的像素值范围都约束为[0,255],即可认为Z1=Z3=0,则式(7)可简化为:
然而,由于Z2的存在,式(8)中存在多余的乘积项,不利于硬件加速。因此,本文采用平移策略来改进TFLite 算法,提出“量化-反量化”算法。例如,对预训练后AOD-Net 卷积第 3 层进行统计,得出rmin=-0.031 663 906,rmax=0.086 845 72。若量化为无符 号7 bit,可知qmin=0,qmax=127,则可以通过式(4)~(5)计算出Z=33,S=0.000 933 146 617 543 979,再使用式(3)即可实现量化。随后,平移其零点(Z=33)到绝对零点,以降低后续处理复杂度,具体如图2 所示。
可见,平移之后的范围就从(0,127)映射为(-33,94)。此外,为了保证平移后不出现数据溢出,在保存权重参数时会添加一个符号位,即量化为7 bit 时会占用8 bit,最高位为符号位,具体如算法1 所示。需要注意的是,算法1 是在PC上进行运算,不是在硬件部署后的推理阶段。
算法1 量化-反量化算法。
输入 预训练后的单精度权重参数。
输出 量化和平移后的权重参数,反量化后的权重参数。
1)对已训练好的模型,统计各层rmin、rmax并确定量化比特数,从而确定qmin、qmax;
2)使用式(4)~(5)计算各层S、Z;
3)使用式(3)进行量化并平移相对零点到绝对零点,再保存所有权重参数到文件,用于硬件部署;
4)使用式(2)进行反量化并储存成文件,用来模拟量化对去雾效果的影响,进而确定最低的量化比特数。
2.2 模型硬件重构方法
正如前文所述,基于CNN 的去雾模型主要包括卷积和填充(padding)、多尺度特征提取和融合等结构。通过引用HLS 视频库和流水线等技术,实现去雾模型的快速重构,并输出可综合的硬件IP核,从而实现视频去雾。
2.2.1 卷积层和卷积边界处理
无论是单通道还是多通道的2D 卷积,都可以转化为多级嵌套的for 循环,然后使用“unroll”等指令解循环。为了实现像素流处理,引用HLS 视频库[21-22]的两个综合数据结构:行缓存(hls::LineBuffer)和窗口缓存(hls::Window),并用该数据结构实现2D 卷积的流水处理,具体如图3 所示。图3 中定义了一个3×3 的窗口缓存区和两行的行缓冲区。在特定的循环周期,存储器将从行缓冲区中读取出数据并存储在窗口缓冲区的最右列。其中,虚线框内的像素存储在窗口缓冲区中,实线框内的像素存储在行缓冲区中。
此外,对于卷积边界采用不处理的方式。在深度学习库中,为了使得输入和输出特征图有相同的高宽,各卷积层设有不同的填充大小;然而,这种结构对于硬件实现不太友好。因此,采用忽略边界填充以降低硬件实现的时空复杂度,对于不能参与卷积运算的边界像素点,直接输出零或者原像素。
2.2.2 流水线和存储架构设计
相较于OpenCV 的存储器帧缓存,基于视频流架构可实现高性能和低功耗。通常,视频是按扫描线从左上角像素到右下角像素的顺序处理,即“Z”字形扫描。这种可预测的视频处理顺序允许FPGA,在无需消耗大量存储器件的条件下,构建高效的数据存储架构,从而有效地处理视频数据。因此,本文采用基于VDMA[20]的视频流存储器架构,将外部采集的视频帧(摄像头或视频文件)经过流化处理后,缓存在外部存储器DDR3中,并配置VDMA 为3 帧动态同步锁相模式(Dynamic Genlock Master),以防止图像割裂,如图4(a)所示。
其次,多分支和流水线同步设计能够满足绝大部分的模型,从而实现快速重构模型。如图1(b)所示,中间数据之间存在多重依赖关系,同时存在旁路分支;此外,由于HLS 视频库不支持随机访问,对于读取超过一次的数据必须使用hls::Duplicate()。如图4(b)所示,Conv1 的输出X1 同时作为Conv2 和Conv3 的输入。由于Conv2 运算存在延迟,所以需要预留X1 到Conv3 足够的缓冲空间。例如,假设每行有800 个像素点,则可以使用约束指令:#pragma HLS STREAM variable=X1 depth=8000 dim=1,缓存10 行。
2.2.3 流接口实现
为了实现流水化和生成标准总线接口,IP 核端口需要通过指令约束成流式接口,即AXI4-Stream 协议,并添加AXI4-Lite 从接口动态配置图片帧的高宽。其顶层函数定义为:
此外,Vivado HLS 视频处理函数库,使用hls::mat 数据类型,用于模型化视频像素流处理。因此,在可综合的函数内部,需要使用函数hls::AXIvideo2Mat 和hls::Mat2 AXIvideo 进行数据格式转换,如图5 所示。
3 实验与结果分析
本章包含3 个实验:
1)AOD-Net[8]和DehazeNet[6]的量化-反量化实验;
2)硬件重构量化后的AOD-Net 模型,并输出IP 核的实验;
3)搭建软硬件系统,测试IP 核的实验。
实验运行的操作系统为64 位Windows7,系统配置为Intel Core i5-4460 四核处理器,显卡为NVIDIA GTX1660S,内存配置为16 GB。Xilinx 套件为2018.3 版本,包括Vivado、HLS 和SDK 三部分。
3.1 量化-反量化实验
实验选取DehazeNet[6]和AOD-Net[8]两类代表去雾 模型[1,3]。基于文中所提量化-反量化算法,确定可量化的最低比特数。该实验均在Visual Studio Code 1.52.1 中采用Python 3.7 版本进行编写,均基于PyTorch 1.7.1 的深度框架。首先,本文参考文献[6]中的方法,生成约25 万张16×16的图像块,作为已知透射率的人造DehazeNet 的训练数据集;其次,AOD-Net 完全按照文献[8]中的方法和数据进行还原,训练并生成单精度的模型数据;最后,用于评估的数据集由50 张图片构成,真实图片和人工合成图片各占50%,用以获取去雾的平均效果。
3.1.1 主观视觉评价
图6 罗列了部分雾图在AOD-Net 和DehazeNet 去雾模型中,不同量化比特数下的去雾结果。
实验结果表明,当模型参数量化为5 bit 及以上时,与单精度的去雾效果没有明显的区别;当量化低于5 bit时,去雾效果图存在色偏、图像失真,且两个模型在4 bit 和3 bit 都存在图像亮度的大幅波动;当量化低于3 bit时,两个模型都存在图像失真且丢失大量图像细节。究其原因,主要是因为较低的量化比特数限制了数值可表示的范围,使得与原浮点参数的分布存在较大差异,从而影响推断结果[23]。
3.1.2 客观指标评价
为了客观评价去雾效果,本文选取均方误差(Mean Squared Error,MSE)、峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)、结构相似性(Structural SIMilarity,SSIM)、图像均值等共计6 个评价指标,定量研究不同量化比特数对去雾效果的影响。实验结果采用对评估数据集取平均的方法,统计数据如表1 所示。值得注意的是,所有指标都与单精度(float32)去雾效果图进行对比。
如表1 所示,当量化在5 bit 及以上时,各数据指标变化幅度都较小;当量化低于5 bit时,数据波动明显,也侧面印证了主观视觉的判断。综上,本文将采用5 bit 对AOD-Net 模型先进行量化,然后再硬件重构输出硬件IP 核;但即便如此,当模型参数从32 bit 量化为5 bit时,也可为模型参数节省84.4%的存储空间。
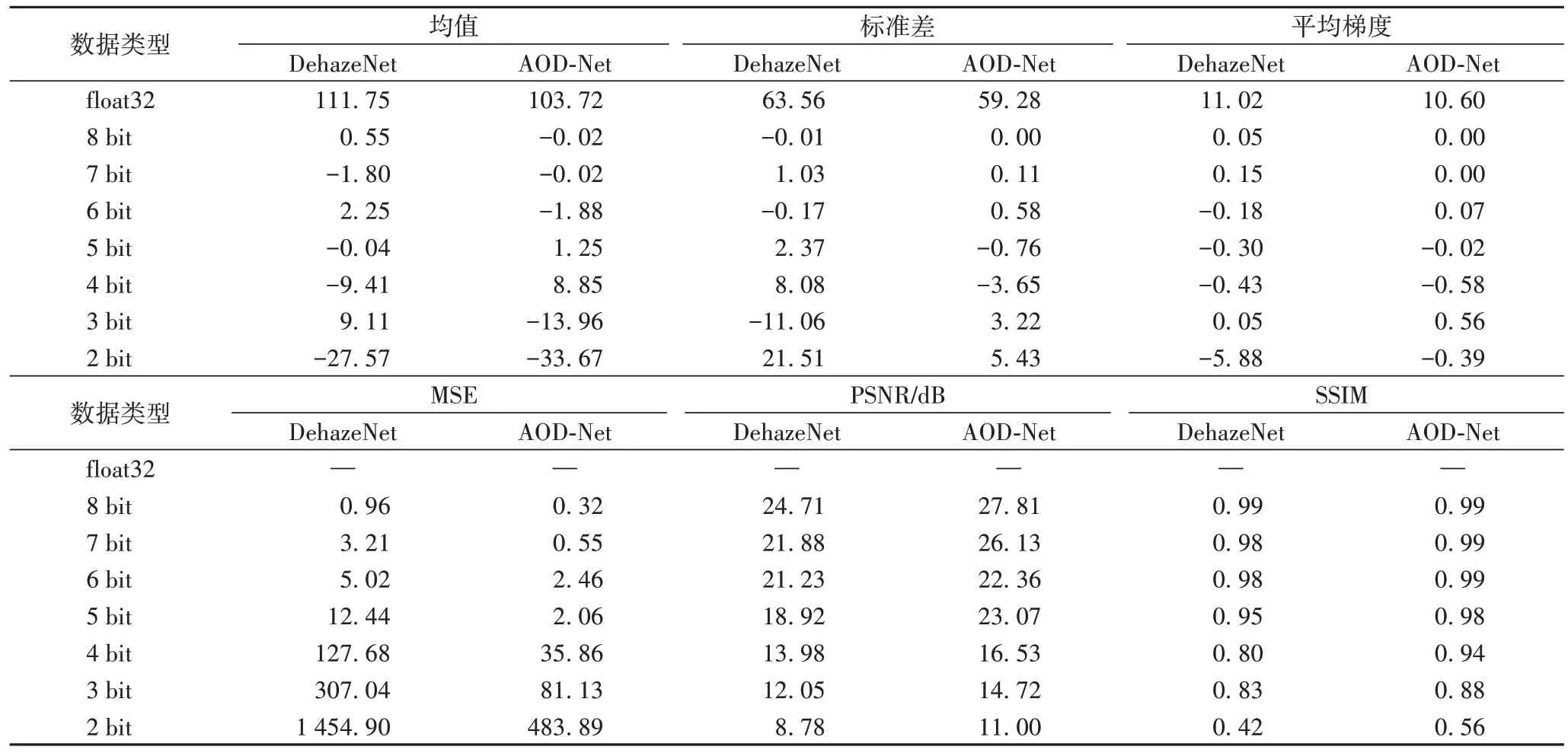
表1 不同量化的去雾效果客观评价结果Tab.1 Objective evaluation results of defogging effect after different quantifications
3.2 输出已量化AOD-Net的IP核及测试
该实验的目的是通过Xilinx HLS[21-22]工具,按照本文所提方法,重构量化后的AOD-Net 去雾模型,并使用Zynq7035硬件平台验证该IP 核。特别地,相较于使用Verilog 来重构去雾模型,使用HLS 具有更大的灵活性。通过使用C++语言和相关TCL(Tool Command Language)约束指令,可以非常方便地尝试不同的实现并且不用过多关注底层硬件,从而提高重构效率。
3.2.1 IP核综合与实现的实验
本文实验在HLS 工具中选择Zynq7035 作为目标SoC 处理器,设置初始时钟为6 ns 作为约束条件,设置一个时钟处理一个像素,即II=1(Iteration Interval,II);进行综合与实现,生成IP 核的硬件资源耗用如表2 所示。
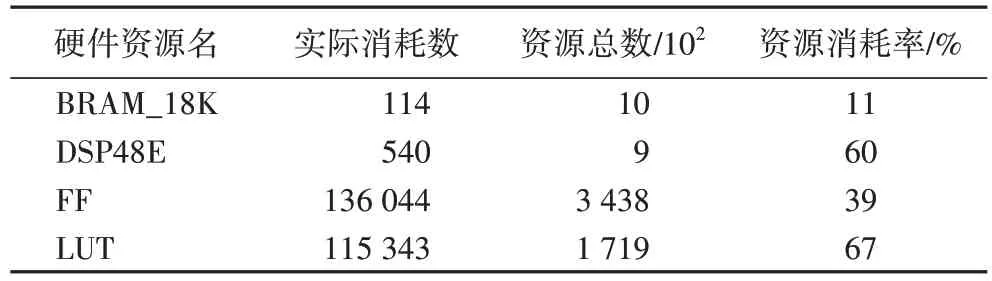
表2 综合后IP核的预估资源耗用Tab.2 Estimated resource consumption of IP core after synthesis
实验结果表明,硬件IP 核能够实现最小时钟周期为5.5 ns,对应最高像素时钟频率约182 Mpixel/s,能够实现1080P@60 frame/s 视频去雾,能够实现如暗通道先验等[13,16-17]传统算法的同等加速效果。
3.2.2 IP核的测试及对比实验
为了验证本文所提的硬件重构加速方法,以及与其他CNN 单图像去雾模型的去雾耗时对比,本文在Vivado 中按照图4 结构搭建软硬件测试系统,结果如图7 所示。
在该系统中,配置“ZYNQ7 Processing System”,勾选SD(Secure Digital memory card)和UART(Universal Asynchronous Receiver/Transmitter)外设部分,并配置PL 部分的时钟频率为150 MHz。其中,SD 存储模块用于保存待去雾图像和硬件IP去雾后的效果图,UART 用作控制去雾推理的启停。对图7进行综合与实现,资源耗用的数据如表3 所示。
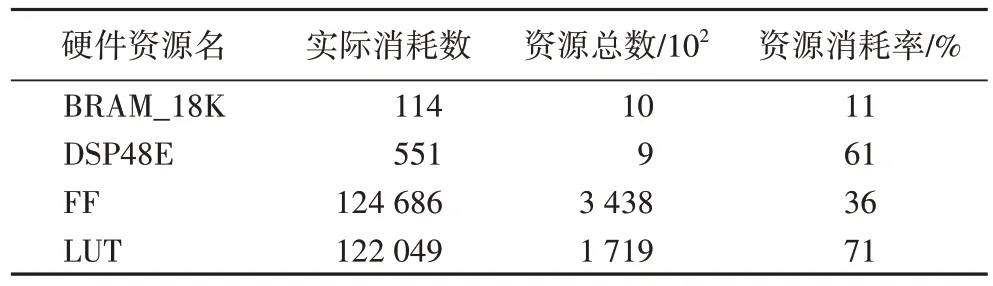
表3 硬件测试系统综合后的资源耗用Tab.3 Resource consumption of hardware test system after synthesis
此外,系统最小像素时钟周期为6.7 ns,片上功耗约为2.25 W,能够保证部署在能量受限的终端上。接着,在SDK软件开发平台中,利用Cortex-A9 完成VDMA、DDR 的地址映射、读写通道使能等配置,并调用时间函数XTime_GetTime()统计单帧图像去雾时间,部分去雾效果见图8。
实验结果表明,除外边界的三圈像素以外,基于硬件IP核和基于PyTorch 单精度的去雾效果,在主观评价上没有明显的差别。至于外边界的三圈像素异常的原因,主要是因为在重构模型时不处理2D 卷积边界(即没有进行填充)所造成的。
此外,通过对20 张640×480 雾图去雾耗时取平均的方式,测得硬件IP 核去雾耗时的平均时间,具体如表4 所示。其中:文献[7]模型和本文模型的实际值精确到小数后4位,其他模型原始数据来自各文献,均只精确到小数后2 位。
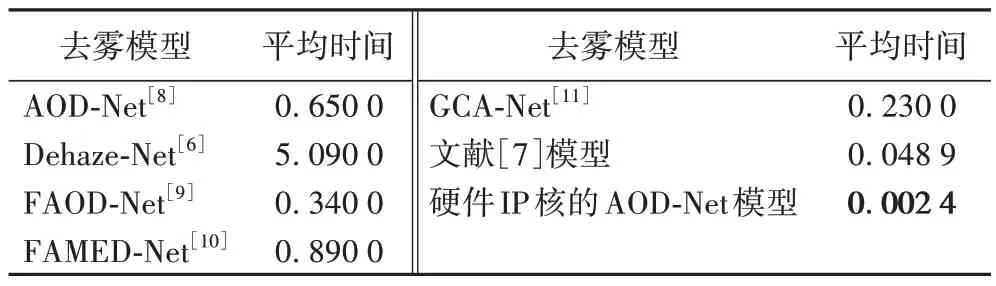
表4 不同去雾模型处理640×480雾图的平均时间 单位:sTab.4 Average time taken by various methods to process single image with resolution of 640 pixel×480 pixel unit:s
从表4 可知,相较于其他去雾模型,本文硬件IP 核的AOD-Net 模型对单帧640×480 图像去雾的平均推理时间有显著的数量级差异,约为AOD-Net 去雾时间的1/271,FAOD-Net的1/142。此外,文献[24]对改进AOD-Net 的FPGA 实现,在128×128 的雾图上的去雾平均时间为36 ms;而本文硬件IP核的AOD-Net 模型处理较大尺寸640×480 的雾图的时间仅为2.4 ms,表明本文模型有更好的加速效果。
4 结语
为了实现CNN 单图像去雾到视频去雾,并能够部署在能量受限的移动/嵌入式端,本文提出一种可快速硬件重构去雾模型的方法。首先,通过改进TFLite 量化提出了“量化-反量化”算法,在保证去雾效果的前提下,实现两类代表去雾模型(AOD-Net 和DehazeNet)最低为5 bit 的量化;其次,采用VDMA 视频流存储架构、高级综合HLS 工具以及流水线等技术,对已量化的AOD-Net 模型快速地重构,输出具有标准AXI4 接口的硬件IP 核。实验结果表明,该IP 核能够实现单图像去雾到1080P@60 frame/s 视频去雾的拓展,单帧640×480 的去雾耗时为2.4 ms,而片上功耗仅为2.25 W。这种生成带有标准总线接口的硬件IP 核也便于跨平台移植和部署,从而可以扩大这类去雾模型的应用范围。此外,正如文中所述,较低比特数量化会改变原有权重参数的分布,从而导致异常的推理结果。因此,接下来将研究低量化比特的硬件加速,或者进一步探究硬件友好的去雾模型。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
中国生殖健康(2020年7期)2020-12-10
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
天津诗人(2017年2期)2017-11-29
