
基于自注意力机制和时空特征的Tor网站流量分析模型
2022-11-08 12:42席荣康蔡满春芦天亮李彦霖
计算机应用 2022年10期
席荣康,蔡满春,芦天亮,李彦霖
(中国人民公安大学 信息网络安全学院,北京 100038)
0 引言
洋葱路由器(The onion router,Tor)匿名通信系统是一种基于链路的低延迟通信系统。与其他匿名通信系统相比,Tor 匿名通信系统因具有更好的安全性、可部署性、可用性、灵活性而被匿名用户广泛运用。由于该系统具有节点发现难、用户定位难、通信关系确认难的特点,常常被不法分子用来作为隐匿网络行为的工具从事网络犯罪活动。Tor 是用户访问暗网的重要工具,而暗网中充斥着信息泄露、人口贩卖、枪支贸易,以及敲诈勒索等反社会活动和言论,严重威胁着个人隐私安全、社会治安,甚至国家安全。Tor 匿名通信系统使用安全传输层(Transport Layer Security,TLS)协议进行数据加密,研究者无法通过分析分组有效负载来识别流量,且该方法由于解析分组负载而触犯隐私。后来有研究者尝试将流量中独特的数据包大小与网页建立匹配关系,从而获取用户访问的页面。但Tor 匿名通信系统不但通过多层跳转、随机转发机制隐藏了通信双方的真实身份,而且通过分割数据包为512 比特固定长度的数据单元消除了许多常用的流量特征。因此,针对Tor 加密流量的监管和识别成为亟待解决的重要问题。
Tor 网站指纹攻击也称为Tor 网站流量分析,攻击者通过监听用户访问页面的流量,分析其行为模式和特征进一步判断用户当前正在访问的页面。目前,Tor 网站指纹攻击在两种应用场景下进行。封闭世界下,攻击者需要准确识别出Tor 网络匿名用户正在访问的已知监控网站种类,检验模型能够对监控网站类别正确分类的多分类能力。在更接近真实互联网环境的开放世界下,攻击者需要在复杂的网络环境下识别出受监控网站,以检验模型的二分类能力。
Hintz[1]最先提出了Web 网站指纹攻击的概念,针对加密代理SafeWeb 证明了指纹攻击的可行性与有效性。后来Liberatore等[2]首次将机器学习算法运用在网站指纹攻击模型中,模型分类准确率达68%。早期网站指纹攻击主要针对安全外壳(Secure SHell,SSH)协议与安全套接字层(Secure Socket Layer,SSL)协议。自2004 年起,Dingledine等[3]介绍了第二代洋葱路由系统Tor,Tor 通信系统便成为了当今最为流行的匿名通信系统。此后,多种机器学习算法相继被应用于Tor 网站指纹攻击中。例如,基于K 指纹的模型K-FP(K-FingerPrinting)[4]采用随机森林算法、基于累积量模型CUMUL(CUMULative sum fingerprinting)[5]采取支持向量机算法。将机器学习算法应用于网站指纹攻击中需要人手动选择特征且选择的依据多为专家经验,算法的固有缺陷导致模型性能难以进一步提高。
神经网络模型由于能够在训练过程中自动提取特征向量,通过大量互联神经元的非线性变换获取抽象特征并进行自适应端到端的分类处理而被广泛运用于网站指纹攻击。Abe等[6]首次尝试将深度学习算法用于指纹攻击,使用堆栈去噪自编码器(Stacked Denoised AutoEncoder,SDAE)对数据进行分类,在封闭世界数据集中达到88%的准确率。后来,研究者一方面通过改进数据分析模型来提高网站指纹攻击的准确率,Rimmer等[7]收集了包含300 万条流量的数据集,并使用卷积神经网络(Convolutional Neural Network,CNN)、SDAE、长短期记忆(Long Short-Term Memory,LSTM)网络对数据集进行分类,封闭世界下能达到96%的准确率。Zhang等[8]提出了多尺寸卷积神经网络和长短期记忆(MultiScale CNN with LSTM,MSCNN-LSTM)网络模型,利用输入数据的时空特征对网络流量进行分类。另一方面,研究者通过改进网络流量的预处理方法以达到更好的实验效果。马陈城等[9]提出将突发流量特征作为指纹攻击特征,在封闭世界下模型分类准确率达到98%。张道维等[10]提出将匿名通信流量映射为RGB 图像,然后使用残差神经网络构造网站分类模型,模型准确率达到97.2%。
除了通过改进模型和数据处理方法提高Tor 网站指纹攻击的准确率,Wang等[11]提出目前网站指纹攻击的局限性,运用数据集更新、网页分割、去噪声等方法来增加指纹攻击的实用性。针对深度学习需要大样本学习、灵活性差等问题,Sirinam等[12]提出三联体指纹攻击的方法,通过小样本训练数据模型,模型分类准确率可达95%且抵抗概念漂移能力和灵活性大幅提高。Attarian等[13]提出自适应的在线指纹识别流处理方法实现网站的动态识别。蔡满春等[14]利用Seq2seq模型自动生成流特征,采用自适应随机森林算法作为分类器,模型在线识别率达98%。
综上所述,针对Tor 网站指纹攻击的研究集中在模型性能改进和模型实用性提高两方面。目前关于Tor 网站流量分析模型的改进虽取得了较大成功但仍存在如下问题:1)通过神经网络的叠加虽提高了模型分类准确率,但模型处理数据量大幅增加,模型训练效率较低;2)利用深度神经网络进行多次信息提取存在信息丢失的隐患;3)模型尺寸单一,结构不灵活,无法充分提取数据多维度、多视野特征进行分类。
本文提出一种基于自注意力机制和时空特征的Tor 网站流量分析模型SA-HST(Self-Attention and Hierarchical SpatioTemporal features):首次引用注意力机制用于Tor 网站流量分析,为输入数据分配注意力权重以选取重要特征;采用多通道并联网络结构取代深度神经网络以提取数据多视野细粒度特征;基于CNN、LSTM 提取流量时空特征用于Tor匿名流量分类。SA-HST 在分类准确率、分类效率、鲁棒性等多方面的性能均有较大提高。
1 基于SA-HST的Tor网站流量分析
1.1 Tor网络结构分析
图1 为Tor 网络结构。Tor 网络客户端在与目标节点数据传输过程中基于加权随机路由选择算法选择3 个中继节点传输信息并建立链路。由于对数据进行三次加密,中继节点和目的服务器无法同时获知客户端IP 地址、目的服务器IP 地址以及数据内容,从而保护了用户隐私。
基于该网络结构,攻击者可通过获取Tor 网络入口节点的权限并位于用户客户端到Tor 网络入口节点的链路上对传输数据包进行监听。拥有Tor 网络入口节点权限的攻击者,能够解密Tor 网络数据包的第一层加密信息并获取Tor 协议信息,但无法获取Tor 网络数据包有效载荷信息。因此,攻击者可通过分析数据包时间、方向等统计特征达到网站指纹攻击的目的。
1.2 SA-HST流量分析模型
结合自注意力机制与多核CNN-LSTM,设计了SA-HST流量分析模型。图2 为SA-HST 模型流程,该模型分为三部分:1)数据编码层将预处理后的数据填充或截取为固定长度的序列,对网站标签采用One-Hot 方式编码;2)自注意力机制层为数据序列特征分配不同的权重,提取出重要的数据特征用于分类;3)多核CNN-LSTM 层提取输入数据的时空特征用于分类,进一步提高分类准确率。最后通过调整全连层参数和数据重组实现开放世界和封闭世界下模型的二分类/多分类。
SA-HST 模型主要具有以下特点:1)注意力机制层忽略输入数据的长度,通过固定运算量便可计算输入数据任意两个位置的依赖关系。对于长序列数据的处理既保留了完整的数据信息,又没有降低训练效率。2)SA-HST 模型采取并联网络结构以消耗算力的方式提高训练效率。3)采用多尺寸卷积核卷积神经网络和长短期记忆网络提取数据细粒度、多尺寸、跨时空特征,充分提取数据特征使模型能够在复杂的测试数据中保持性能稳定。本文模型能够在浅层网络结构的基础上,实现分类高准确率、高训练效率和高鲁棒性。
1.2.1 数据编码层
本文在开放世界和封闭世界下的实验都属于有监督学习,即利用已知的训练数据训练模型并通过输入未知数据映射输出,以达到分类或预测的目的。训练数据通常表示为:
其中:Τ为训练数据;X为经过预处理后的网络流量实例;G为网站类标签,开放世界下为二分类标签,封闭世界下为多分类标签。由于无法获取Tor 网络传递的有效载荷信息,X可表示为:
其中:-1 和1 表示数据包传输方向,数据长度则表示该网站流量实例的大小。经过预处理的信息流是长度不一的数据序列,而模型采用批处理的方式加载数据,需要对批数据进行填充和截取操作以保持长度统一。采用数据处理函数处理数据矩阵,若序列长度过长则截断,反之则补零。由于神经网络执行数字运算性质,输入数据通常为范围是[-1,1]的数字序列,经数据编码层处理的数据序列X能直接输入神经网络进行运算。
对于多分类标签,由于同批数据的各网站标签相互独立,采用One-Hot 编码将网站标签编码为神经网络可处理的一维向量:
One-Hot 编码采用N个状态位来对N个网站名称进行编码,网站名称被映射为整数索引值,N个状态位任意时刻只有一位有效。当表示某一网站时该索引值对应数值为1,其他位都是0。标签G3=1,则G表示第4 个网站类标签。
1.2.2 自注意力机制层
注意力机制的思想起初受到人类注意力机制的启发。本质上来说是实现模型算力资源的高效分配[15]。注意力机制第一次应用于图像处理领域,通过对图像关键位置有选择的处理,减少了需要处理的样本量并提高了模型性能。而后,注意力机制思想在机器翻译领域解决了不定长翻译问题。接着在数据预测领域,LSTM[16]将循环神经网络(Recurrent Neural Network,RNN)与注意力机制思想相结合,利用门结构依据重要性选择将信息进行传递或者遗忘,有效地解决梯度爆炸问题,模型得到初步运用。2017 年以自注意力机制为基本单元的Transformer 模型的提出使注意力机制得到真正的成功运用[17]。Google 公司使用Transformer 模型代替Seq2seq 模型,利用自注意力单元代替传统循环神经网络单元,在机器翻译领域取得了重大成功[18]。受到自注意力机制在序列数据中的应用启发,本文将注意力机制运用于Tor 匿名流量分类中,相较于之前流量分类模型,模型性能在多方面有较大提升。
图3 为自注意力机制层模型结构。首先,先设置输入序列X=(1,-1,1,-1,…,1)的初始化权重矩阵,并计算序列X的相关矩阵:
其中:Wv、Wk、Wq分别为输入序列X的值Value、键Key 以及查询Query 初始化权重矩阵;V、K、Q分别为输入序列X的值Value、键Key 以及查询Query 矩阵。然后,利用特征xi的查询向量与各个位置的键Key 内积并归一化得到注意力权重,注意力权重表示特征xi与序列其他位置的依赖关系,权重越大表示该数据特征越重要:
其中:qi为输入序列中特征xi的查询向量;ai为特征xi的注意力权重;Softmax()为归一化指数函数,用于将注意力得分归一化为调节因子,使得内积不至于太大以便于Softmax()函数计算。最后,将注意力权重与对应的值Value 加权求和得到特征xi的注意力得分:
其中:attention()表示注意力得分函数;vj为特征xj对应的Value 向量。
1.2.3 多核CNN-LSTM层
卷积神经网络能够通过卷积核与局部图像的卷积运算提取抽象的数据特征,在图像处理问题上有良好表现。一维卷积神经网络相较于传统的卷积神经网络层具有轻量级的结构且更易捕捉序列的空间特征[19]。序列数据常用的深度学习模型为RNN,RNN 通过记录系统状态量使神经元具有记忆能力。对于第t时间步,计算公式为:
其中:et表示t时刻系统状态向量;Wp、Wg、Wo为转移矩阵;Xt、Lt分别为t时刻输入向量、输出向量;tanh()为双曲正切函数。由式(9)可知,RNN 运算方式为串行运算,上一刻系统状态影响下一刻系统输出,存在下列局限:1)受制于递推机制,RNN 不能实现并行运算,运算效率低;2)RNN 仅能获取序列上下文依赖关系而忽略数据局部依赖关系;3)深度RNN 存在梯度消失和梯度爆炸的隐患。本文选用一维卷积神经网络作为分类工具。卷积核与提取的数据序列进行卷积运算来提取多视野细粒度数据特征,表示形式为:
其中:和分别表示第l层的第j个输入和第l-1 层的第j个输出;⊗表示卷积操作;代表卷积核;为卷积层偏置量;f() 为激励函数。对于自注意力层输出向量C=(c1,c2,…,cn)经卷积操作之后,每个卷积神经网络得到一个特征矩阵M∈R32*(n+1-h)。卷积核扫描步长为1,则每个卷积核经卷积操作后提取的特征序列长度为n+1 -h。32 个卷积核扫描得到特征序列并拼接为二维特征矩阵M。
其次,一维卷积神经网络后接一维最大池化层对数据特征进行降维、去除冗余信息、压缩,简化特征信息以提高计算速度,防止过拟合[20]。设置一维最大池化层核大小为4,步长为1,最大池化的表示形式为:
其中:表示将第l层三个不同大小卷积核的卷积神经网络卷积、最大池化操作后进行融合的特征;concat()为融合函数用于将矩阵融合。特征矩阵N∈R32*[(n+1-h)/4]经融合层进行矩阵拼接后得到融合矩阵K∈R96*[(n+1-h)/4]。
相较于传统的单尺寸卷积神经网络,本文所提出的并联多尺寸卷积核卷积神经网络结构具有以下改进:1)使用不同尺寸的卷积核对应不同的序列长度窗口,进而提取不同粒度的空间特征。卷积核h=5 的卷积神经网络能够增大卷积层感受野[21],卷积核h=3 的卷积神经网络能够实现细粒度的特征获取。2)改变传统神经网络串行叠加的思路,采用并联结构并行提取数据序列的多粒度特征。没有减少运算量导致特征提取不充分,通过消耗计算机内存与算力资源实现网络并行运算,运行效率约为串联网络的3 倍。此外,网络并联有效避免了同种特征经过多次卷积、池化操作后的信息丢失问题。3)特征融合。由于三组不同卷积核大小的卷积神经网络卷积操作获取的特征是相互独立的,各组之间没有信息交互,因此降低了模型的信息提取能力。如图4 所示,通过融合层将特征矩阵进行简单拼接获得融合特征使信息可以在不同组流转[22]。
融合层处理完毕之后,串联接入LSTM 网络来提取数据的时序特征。LSTM 网络利用门结构控制信息输入解决了循环神经网络长距离依赖难以捕捉的问题,通过挖掘数据包内部前后依赖信息,保证了信息持久化。LSTM 内部含有3 个控制门和1 个记忆单元,用来记忆和存储当前时刻的信息。设置LSTM 网络单元个数为128,则特征矩阵K∈R96*[(n+1-h)/4]经LSTM 网络挖掘数据时序依赖关系和特征一维化之后输出一维矩阵U∈R128并输入全连接层进行分类。全连接层将权重矩阵与输入向量相乘再加上偏置,输出数据属于各个网站的分数,表示形式为:
其中:X为输入向量;WT为权重矩阵;si∈(-∞,+∞)为输入向量属于网站i的分数;z表示全连接层偏置量;mi为利用Softmax()函数将分数归一化后的概率值。
本文两类实验场景即开放世界和封闭世界下的实验都属于有监督学习,通过修改全连接层输出单元个数和数据重组能够让模型同时满足两个场景下的实验需求。
1.3 Tor网站指纹攻击流程
图5 为Tor 网站指纹攻击流程,流程分为训练阶段和攻击阶段。训练阶段主要利用已有的数据集训练数据模型,调整模型参数,保存攻击模型。在真实的互联网环境下,监控网站与非监控网站比例复杂,非监控网站类别多样。首先,为了模拟开放世界网络环境,需要对数据集进行数据重建。将监控网站标签设置为1,非监控网站标签设置为0。按照网站规模、网站构成的不同构建二分类数据集。然后,将构建的二分类数据输入开放世界下基于自注意力机制的跨时空网站流量分析模型SA-HST-OW(SA-HST in Open World)并保存。利用多分类数据集训练并保存封闭世界下基于自注意力机制的跨时空网站流量分析模型SA-HST-CW(SA-HST in Closed World)。
在攻击阶段,攻击者先通过获取Tor 链路入口节点的权限并在客户端到Tor 链路入口节点的链路上监听收集流量数据。然后加载SA-HST-OW 模型并输入网络数据流进行二分类。如果检验到目标网站为非监控网站则输出为非监控网站标签;反之,继续将数据流输入SA-HST-CW 模型输出监控网站类别标签。
2 实验与结果分析
本文模型使用Tensorflow 2.3.0 后端的Keras 2.4.3 库实现。计算机配置为12 核Xeon Platinum 8163 处理器,64 GB内存,运行环境为Windows 10 专业版,显卡为NVIDIA Tesla P100-16 GB,Python 3.7 语言编写。
SA-HST 模型参数如表1 所示,将序列输入数据编码层被填充为固定长度128,设置自注意力层输出单元个数为128,设置卷积层的3 个卷积核大小分别为3、4、5,并将特征融合,将融合特征输入LSTM 层提取时序特征。最后依据二分类,多分类实验场景将全连接层单元数量设置为2 或100。
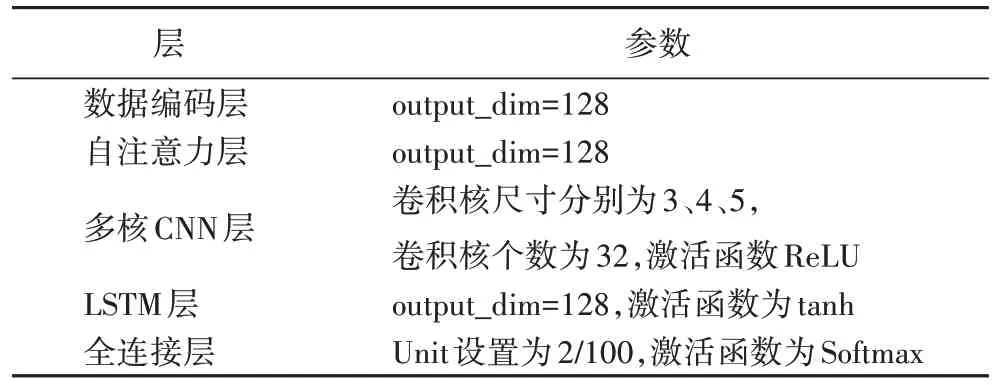
表1 SA-HST模型参数Tab.1 SA-HST model parameters
2.1 数据集
对于深度神经网络来说,用足够的数据集进行训练能够让模型精确地识别输入数据特征,而且让模型对于未知实例具有更好的预测能力。本文采用Rimmer等[7]收集的数据集,该数据集是迄今为止针对Tor 网站指纹攻击收集的最大数据集,包括封闭世界与开放世界数据集。在封闭世界下,收集了Alexa Top1 200 个网站,每一个网站收集了2 500 条流量访问记录。按照访问网站类别将数据集分为CW100、CW200、CW500、CW900 数据集。封闭世界主要检验模型对于已知监控网站的多分类识别能力。在开放世界数据集中,分别对Alexa Top40 万个网站每个网站收集一个访问记录作为非监控网站,对Alexa Top200 个网站,每个网站收集2 000个实例作为监控网站,共80 万条记录用于模型测试。数据集按照训练集:验证集:测试集为8∶1∶1 的比例进行划分。
2.2 评估指标
在封闭世界下,使用准确率Accuracy衡量模型在各类外在条件下的性能表现。在开放世界下,在多个应用场景下对模型进行多角度衡量,因此实验指标包括准确率Accuracy、召回率Recall、精确率Precision及F1 分数F1-Score。具体公式为:
其中:TP(True Positive)为正确分类为监控网站的样本总数;TN(True Negative)为正确分类为非监控网站的样本总数;FP(False Positive)为误分类为监控网站的样本总数;FN(False Negative)为误分类为非监控的网站样本总数。
2.3 实验设置
引入Rimmer等[7]提出的CNN 模型、LSTM 模型进行对比实验。在传统机器学习模型中CUMUL[5]表现突出,将其作为机器学习模型的代表进行对比。为验证注意力机制对于模型性能的影响,在CNN 基础上引入了注意力机制构建结合自注意力机制和卷积神经网络的流量分析模型SA-CNN(Self-Attention and CNN)。
2.3.1 模型分类准确率实验
表2 为5 类模型在CW100 数据集下训练60 轮的实验结果。实验结果表明,CUMUL[5]利用机器学习算法支持向量机作为分类器,分类准确率最低。SA-CNN 在CNN 的基础上引入了注意力机制能够提取重要数据特征用于分类,较CNN模型[7]提高约6.43 个百分点。SA-HST 进一步提取细粒度时空特征分类准确率达到97.14%,相较于CUMUL[5]和深度学习模型CNN[7]分别提高8.74、7.84 个百分点。
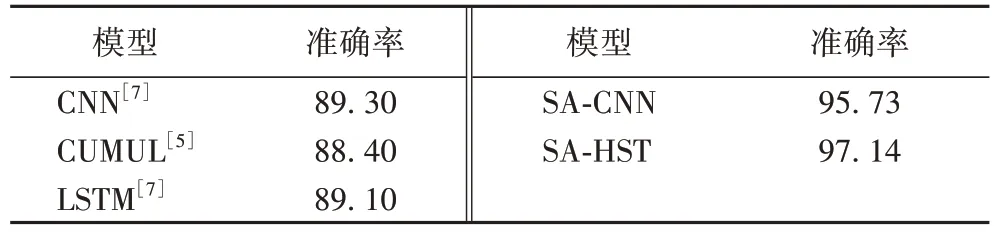
表2 封闭世界下的模型分类准确率对比 单位:%Tab.2 Comparison of model classification accuracy in closed world unit:%
2.3.2 模型训练效率对比实验
从拟合轮次、训练时间、数据拟合度三个角度对模型性能进行验证。图6 为4 类模型在CW100 数据集上不同训练轮次下分类准确率。
表3 为4 类模型在CW100 数据集共250 000 条实例上训练一轮所需时间。

表3 4类模型每轮训练时间对比 单位:sTab.3 Comparison of training time per epoch among four models unit:s
图7 为4 类模型数据集上不同训练轮次下模型数据拟合实验结果。数据集采用CW100,分为训练集、验证集、测试集。训练准确率Train_acc表示模型每一轮训练过程中在训练数据集的分类准确率,验证准确率Val_acc表示模型在验证集上的分类准确率。利用指标误差率abs来表示已训练好的数据模型对未知数据的拟合能力:
引入注意力机制的SA-HST 模型、SA-CNN 模型能够高效提取重要特征用于分类,模型在训练10 轮之后便进入拟合状态,且抵抗概念漂移能力强,对于未知数据拟合效果较好。相较于CNN[7]、LSTM[7]模型利用LSTM 网络基于上下文时序序列提取特征,SA-CNN 模型利用自注意力机制通过固定运算并行提取全局依赖关系,大幅缩短了训练时间。实验结果表明,引入注意力机制能够在轻量级模型结构基础上,快速捕捉数据重要特征。
2.3.3 开放世界下模型性能
开放世界实验设置目的是探究模型能否在互联网中准确识别出监控网站。相较于封闭世界数据集,开放世界数据集网站种类庞多、流量实例多样、环境更加复杂,检验模型二分类性能。采用Rimmer等[7]的open world 数据集来尽量还原网络环境。抽取监控网站50 000 条流量实例(20 个网站),非监控网站50 000 条实例(50 000 个网站),重新构建数据集用于实验。
图8 为4 类模型在开放世界下的性能表现。召回率衡量了模型对监控网站的查全能力。精确率体现了模型对监控网站的查准能力。F1 分数为召回率和精确率的调和平均。准确率体现了模型能将网站正确分类二分类能力。实验结果表明,开放世界下SA-HST 模型各项指标保持稳定的高性能。
图9 为4 类模型在不同网站构成下的性能表现。利用指标网站比率衡量开放世界环境的复杂程度。网站比率表示监控网站与非监控网站的实例数目比。本文采用大小为100 000 的开放世界数据集验证模型在开放世界环境下性能的稳定性。
实验结果表明,当开放世界大小一定时,网络环境趋于复杂,模型的分类准确率会有显著降低,SA-HST 模型能保持相对稳定的高性能。由此也可得出,网站指纹攻击模型需要不断更新网络流量实例才能在互联网环境中保持实时性和实用性,以及时检测网络违法犯罪活动并进一步进行网络管控。
3 结语
本文基于多核卷积神经网络和长短期记忆网络,引入注意力机制实现对Tor 匿名网站的流量分析,通过对比实验验证了SA-HST 模型性能优势。SA-HST 模型在封闭世界下多分类准确率达97%以上,在开放世界下各项指标稳定在96%以上。
将深度学习技术应用于网络指纹攻击中多基于封闭世界和开放世界前提假设,模型在数据集中能够保持良好性能。在实际网站指纹攻击过程中,应考虑到互联网中噪声流量、多标签网页访问场景。除此之外,流量实例流处理取代传统批处理模式能更及时应对瞬息万变互联网环境带来的挑战。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
小哥白尼(趣味科学)(2021年11期)2021-02-28
健康体检与管理(2021年10期)2021-01-03
小天使·一年级语数英综合(2020年10期)2020-12-16
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
