
近邻系数协同强化人脸图像子空间聚类法
2022-10-24 04:59许毅强夏靖波简彩仁翁谦
福州大学学报(自然科学版) 2022年5期
许毅强,夏靖波,简彩仁,翁谦
(1.厦门大学嘉庚学院,福建 漳州 363105; 2.福州大学计算机与大数据学院,福建 福州 350108)
0 引言
子空间聚类是最流行的数据分析技术之一,引起计算机视觉[1-2]、 图像分析[3-5]和基因表达数据识别[6-7]等多个领域研究人员的兴趣.假设高维数据是从低维子空间的并集中近似提取出来的,子空间聚类的目的是寻找一组子空间来拟合给定的数据集,并基于所识别的子空间进行聚类.子空间聚类方法通过将高维数据点表示为其线性相关的低维子空间的组合以降低数据集的高维性.特别是,基于自表示理论的子空间聚类方法取得了显著的效果,在各种无监督机器学习领域取得突出成就.
子空间聚类方法作为高维数据聚类的一种解决方案,人们提出了各种子空间聚类方法.目前大多数子空间聚类方法都执行两个步骤: 首先,通过施加各种约束来构造相似矩阵确定给定数据点之间有意义的关系; 第二,将谱聚类应用于构造以确定最终数据点成员关系的相似矩阵.大多数高性能线性子空间聚类方法是基于自表示理论的,这意味着每个样本点可以表示为其他样本点的线性组合,使用几个相同子空间的向量基,这个线性组合会突出显示样本点之间的冗余.典型的线性子空间聚类方法是稀疏子空间聚类(SSC)[8]、 低秩表示子空间聚类(LRR)[9]和最小二乘回归子空间聚类(LSR)[10].SSC方法使用L1范数来寻找最稀疏的表示,LRR方法利用核范数寻求最低秩表示,而LSR方法利用F-范数寻求良好聚集性的表示.这3种方法都是比较成功的,随后针对特定应用,研究人员开发了一些改进模型.然而,由于SSC方法为每个数据点单独找到了最稀疏的表示,其无法捕获全局数据结构; 由于核范数极小化计算量大,LRR方法受到限制.此外,如果数据点不足,基于SSC方法和LRR方法的聚类性能会显著下降.LSR方法因为其聚集性能优越,并且模型具有解析解,因此得到了许多学者的青睐.核截断回归表示子空间聚类(KTRR)[11]利用核方法寻找能刻画非线性的表示.缩放单纯形表示子空间聚类(SSR)[12]利用缩放和非负约束求解更有区分能力的表示.
尽管这些方法在一定程度上提高了高维数据无监督的学习能力,但是这些方法仍存在一些不足.例如,近邻样本更有可能属于同一类别,因此对所有的样本点一视同仁存在不合理.考虑近邻样本的表示系数将有利于寻找更加合理的表示.基于这一发现,利用近邻样本的表示系数协同强化求解表示系数提出改进LSR的一种方法.
1 最小二乘回归子空间聚类法

利用最小二乘回归模型求解表示系数,其数学模型如下:
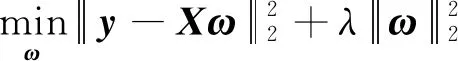
(1)
其中:λ>0是正则参数.那么,不难得到其解析解:
ω=(XTX+λI)-1XTy
(2)
这里,I是单位矩阵.
利用公式(2)对每个样本分别求解表示系数ω=(ω1,ω2,…,ωn-1)T,利用ω构造表示系数矩阵Zn×n=(zi)n×n如下:

(3)
2 近邻系数协同强化子空间聚类法
直观上,近邻样本更有可能属于同一类别,因此在同一度量空间中,相同类别的表示系数应该很接近.本节针对最小二乘回归子空间聚类法在求解表示系数时,对每个样本同等对待的不足,利用近邻系数协同强化的思想提出一种改进方法: 近邻系数协同强化子空间聚类法.
2.1 研究动机

因此测试样本P的表示系数(4.06, 4.45)与五角星类最为接近,根据表示系数相近,将P归为五角星类.依据这一发现,当利用表示理论求解表示系数时,往往以数据集X作为基,此时,同类别的样本得到的表示系数也应该很接近.
2.2 目标函数


(4)
其中:p是y的近邻样本数量.子空间聚类的目标是将相同类别的样本聚集,而近邻样本更可能属于同一类.因此,在相同度量空间下,近邻样本的表示系数应该很接近,于是旨在求解使公式(4)最小的表示系数.
将公式(1)和公式(4)合并得到近邻系数协同强化子空间聚类法的数学模型如下:

(5)
其中:γ≥0是正则参数用来平衡样本重构项和近邻系数协同强化项,当γ=0时退化为最小二乘回归模型.
2.3 模型求解
显然,公式(5)是一个可微的凸优化问题,可以求解其解析解.利用矩阵的迹tr(·)将公式(5)重写为:
(6)
展开为:
L(ω)=tr(yTy)-2tr(ωTXTy)+tr(ωTXTXω)+λtr(ωTω)+
(7)
关于ω求导得:
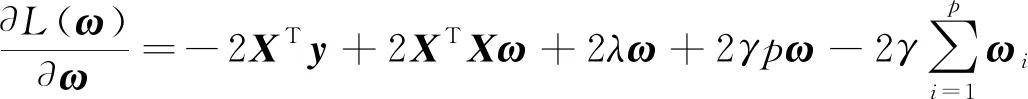
(8)
令其为0,得解析解为:
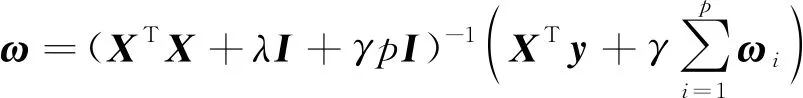
(9)
2.4 算法流程
由于现实中的数据集往往是非线性的,因此基于欧式距离的相似度度量不够准确.借鉴文献[14]的思想,选出p个近邻样本.利用最小二乘回归的表示系数,即公式(2)定义相似度为:
d=|ω|
(10)
其中: |ω|为表示系数ω的绝对值;di=|ωi|=sim(xi,y)表示样本xi与样本y的相似度,越大的di=|ωi|说明xi在重构y时的作用越大,也意味着xi与y的相似度越高.将d按照降序排列,选出前p个作为y的近邻样本.利用公式(9)和公式(3)得到相似矩阵:
最后用标准化分割方法对W进行分割完成聚类.
综上所述,近邻系数协同强化子空间聚类法(nearest neighbor coefficient cooperative reinforcement subspace clustering method,2N2CR)流程如下:

算法1 近邻系数协同强化子空间聚类法(2N2CR)Input: 数据集A, 参数λ, γ, 近邻数量p, 类别数量Kfor i in 1∶n Step1: 将A分为第i个样本y=ai和X=A-i, 利用公式(2)求解表示系数得到相似度向量d, 并按照降序排列, 选出前p个作为y的近邻样本; Step2: 对X、 y和p个近邻样本, 利用公式(9)求解表示系数ωi; end Step3: 利用公式(3)组合表示系数得到表示系数矩阵, 并构造相似矩阵W; Step4: 利用标准化分割方法对W进行分割完成聚类; Output: 聚类结果, 即K个类簇.
3 实验分析
本节通过对比实验和参数讨论等研究2N2CR方法的性能.
3.1 实验设置
选用6个标准的人脸图像数据集为研究对象,如表1所示.2N2CR方法作为LSR方法的一种改进,KTRR和SSR也是LSR的扩展模型.为了突出2N2CR方法的性能,选用LSR、 KTRR和SSR为对比方法,KMEANS作为一种经典的传统方法也作为一种对比方法.

表1 数据集描述
为了便于实验操作,在对比实验中固定各种方法的参数,其中,统一的正则参数λ设为0.01,2N2CR方法的近邻数量p设为5,γ设为0.3.鉴于所有方法的聚类结果都有随机性,采用Matlab固定随机种子的方法以避免随机性.选用研究聚类方法常用的聚类准确率(AC)[15]作为聚类性能评价指标.
3.2 对比实验与参数讨论
表2给出了所有对比方法的聚类准确率.从表2的实验结果可以看出,除pixraw10P数据集外,子空间聚类方法,即2N2CR等方法的聚类准确率明显优于KMEANS聚类方法,这表明传统的基于欧式距离度量的聚类方法难以适应高维样本的聚类.这一结果表明子空间聚类方法更适合高维数据的聚类.2N2CR方法的聚类准确率优于LSR及其扩展方法.所以,2N2CR方法利用近邻系数协同强化求解的表示系数能很好地反映样本相似度,从而提高聚类准确率.因此, 2N2CR方法是对LSR方法的一种有效改进.

表2 聚类准确率对比
2N2CR方法有3个参数,正则参数λ和γ,以及近邻数量p,本节研究参数对2N2CR方法的影响.图2为固定参数λ=0.01和γ=0.3的情形下,参数p对2N2CR方法的聚类准确率的影响.图3给出了固定参数p=5的情形下,参数λ和γ对2N2CR方法的聚类准确率的影响.从图2的实验结果不难发现,当近邻数量p=7时,2N2CR方法在6个数据集上都取得了最高的聚类准确率,这一结果为选择近邻数量提供了指导,增强了2N2CR方法的实用性.
从图3的实验结果可以看出,λ和γ对2N2CR方法的聚类准确率有明显的影响,当固定λ=0.01时,在γ>0的情况下,γ变化时,2N2CR方法的聚类准确率变化不大,这表明γ对聚类准确率的影响较小.但是当固定γ(比如取γ=0.5),λ变化时,2N2CR方法的聚类准确率变化比较明显,从图中可以发现当λ为0.01或0.1时,2N2CR方法可以取到较好的聚类准确率.
综合图2~3的实验结果,选择正则参数λ为0.1或0.01,γ为0.3或0.5,近邻数量p为7时,2N2CR方法将取得比较理想的聚类准确率.
4 结语
针对最小二乘回归子空间聚类法没有考虑近邻样本对求解表示系数的影响这一不足,提出近邻系数协同强化子空间聚类法.在6个人脸图像数据集上的实验表明2N2CR方法是LSR方法的一种有效改进.2N2CR方法的关键在于求解每个样本表示系数,因此更适合小样本数据的聚类研究.尽管2N2CR方法可以取得较好的聚类准确率,但是与LSR方法对比,2N2CR方法不仅要对每个样本寻找近邻样本,还要对每个样本求解表示系数,因此运行效率较低.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
新高考·高二数学(2022年3期)2022-04-29
新高考·高二数学(2022年3期)2022-04-29
计算机应用与软件(2021年7期)2021-07-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
健康体检与管理(2021年10期)2021-01-03
中学生数理化(高中版.高一使用)(2018年6期)2018-07-09
