
书写压力结合DTW-SVM模型对电子签名笔迹的鉴定研究
2022-10-19 02:45杨爽
产业与科技论坛 2022年18期
杨 爽
随着科技的发展,在电子设备上书写电子签名笔迹的现象日益增多,电子签名笔迹的检验鉴定也逐渐出现在司法鉴定领域。近年来法庭科学领域的学者们一直在尝试将人工智能、化学计量学等领域与法庭科学结合,人脸识别、语音识别、指纹识别等技术均得到了发展[1~2],应用其他领域已经成熟的技术已成为了法庭科学领域一种新的趋势。相较于DNA、指纹而言笔迹稳定性较差,原因在于书写过程由手、臂构成书写机制,他们不可能像机器那样精准的复制[3],这就导致笔迹检验人员很难精确地抓住特征变化的范围、幅度,仅依靠主观评断出具鉴定意见,缺少客观的价值评价做支撑,从而致使笔迹检验在法庭证据证明力方面处于争议[4~6]。鉴于电子签名的书写压力曲线较化学领域的光谱图相似,本文通过提取压力峰值走向,进一步采用动态时间规整(DTW)对多次书写压力曲线进行规整,采用SVM探究同一人书写电子签名笔迹压力的稳定性、摹仿电子签名笔迹压力特点和变化规律,利用模式识别方法探究电子签名笔迹的人身识别。
一、理论部分
(一)动态时间规整DTW算法(Dynamic Time Warping)。在时间序列中,两条书写压力曲线的长度大部分是不相等的,利用欧几里得、马氏距离等方法是无法求得有效的两个时间序列之间的相似性的。动态时间规整(Dynamic Time Warping,DTW)是一个典型的优化问题,它用满足一定条件的时间规整函数描述待测模板和目标模板的时间上的关系,求解两模板匹配时累计距离最小所对应的规整函数。
(二)支持向量机(Support Vector Machine,SVM)。支持向量机(Support Vector Machine,SVM)是一种监督学习,根据特有的方式对数据进行分类的广义线性分类器,原本只适用于二分类,后来发展为多分类,其决策边界是对学习样本求解的最大边距超平面。
二、实验部分
(一)实验工具。和冠(Wacom)数位手写板;Microsoft Excel;Matlab2020;联想台式电脑。
(二)样本制作。选取21岁到29岁的30名志愿者为研究对象,在Wacom数位手写板上书写电子签名。由10名书写者书写自己的签名笔迹,并将10名书写人进行编号(W1~W10)每名志愿者均在平稳的心情下在安静的环境书写自己的签名40份,共400份,由20名从事文件检验专业的书写者进行摹仿,每两名志愿者练习摹仿一人签名,练习被摹仿签名的特征稳定后,每名练习摹仿者书写20份签名,共400份,共计400份真实签名,400份伪造签名。
三、结果与讨论
(一)实验可行性分析。书写过程由手、臂构成书写机制,他们不可能像机器那样精准的复制,即使在书写条件相同的情况下同一人多次书写电子签名的压力曲线也不可能完全一致。本文对1名书写者进行10次重复性检验,得出书写者的压力曲线图,通过图1可以看出10次重复性实验结果良好,谱图的峰数、峰位、峰强基本相同,表明可以用书写压力这一特征来达到对书写人的检验鉴定。
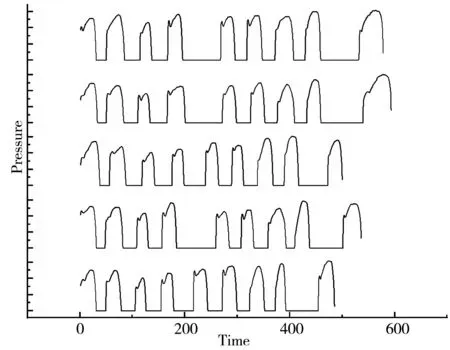
图1 同一人多次书写签名压力曲线图
已有多位学者证明,不同人书写同一签名的压力曲线走向是不同的。
(二)峰值提取及DTW算法应用。由于原始书写压力曲线含有较多的冗余特征信息,曾提到提取压力曲线的峰值走向作为特征效果更好,因此本文首先提取压力的峰值走向,如图2(a)所示为原始压力曲线走向示意图,图2(b)为提取压力峰值后的压力曲线示意图。

图2 (a)书写压力曲线示意图 图2 (b)书写压力曲线峰值走向示意图
由于书写习惯的非绝对稳定性,获得的电子签名之间具有一定的差异,时间维度上的长度也大多不一致,正如图1所示,而模式识别技术的应用需要不同样本之间的特征维度相同,基于算法研究电子签名鉴定的主要问题在于如何解决时间序列长度不一致的电子签名之间的比较,动态时间规整(DTW)算法通常被用来解决该问题,因此本文采取DTW做动态时间规则,将不同时序长度的压力曲线规整为时序长度相同的压力曲线,如图3(a)所示,两条压力曲线在重叠操作的情况下,时序长度是不同的,曲线1的时间维度要多余曲线2的时间维度,在经过动态时间规整(DTW)后,如图3(b)所示,两条曲线根据最优路径映射,已经在时间维度上长度相同,可供后续的模式识别技术。
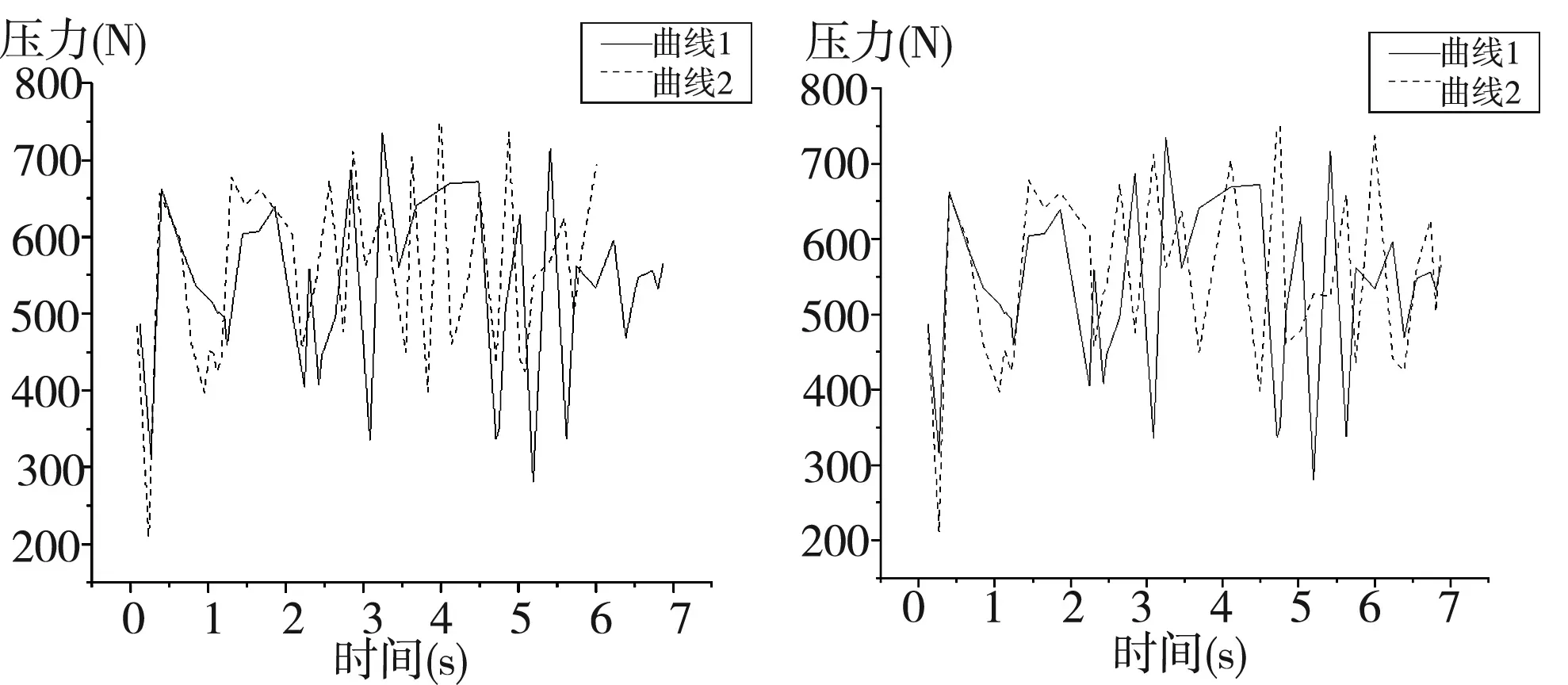
图3 (a)动态时间规整前两条压力曲线 图3 (b)动态时间规整后两条压力曲线
(三)构建SVM模型。本文采用SVM作为数据的分类模型,在实验开始前,通过预实验权衡了4种核函数(线性核函数、多项式核函数、sigmoid核函数以及径向基核函数)下签名样本的分类识别准确率,结果表明径向基核函数(RBF)做为SVM模型的核函数时模型分类识别率最高,因此本文选用RBF作为SVM模型的核函数(回归精准度设置为0.1,惩罚系数C设置为0.1,规范化参数设置为15,RBF伽马值设置为0.1)。
SVM为多维度特征空间上间隔最大的线性分类器,SVM是多维数据空间中构建一个超平面对两类数据进行区分,最终将两类数据的区分划分为一个凸二次规划问题的求解。SVM原本是一种二分类的模型,为了解决多分类的任务,我们将源数据基进行拆分,将多分类任务拆成单独的二分类任务,然后对多个二分类的结果进行集成,以获得最终的多分类结果,常见的拆分数据集方法有一对一法、一对多法。一对多法通常会存在两个诟病,即一个样本可能同时属于多个类以及一个样本可能不属于任何一个类。相反,一对一法可以恰好的解决这种问题,本文的目的是为了多签名笔迹的真伪鉴别,因此本文数据集采用一对一法。
为了验证峰值提取的有效性,本文将采取两种压力曲线预处理方式:一是将原始压力曲线进行动态时间规整(DTW),贴上标签导入SVM模型识别(将此分类模型记为Q1);二是将原始压力曲线进行峰值提取,然后进行动态时间规整(DTW),贴上标签导入SVM模型分类识别(将此分类模型记为Q2)。
实验结果如表1所示,可以看出Q2模型整体的分类识别效果要好于Q1模型,因此峰值提取结合DTW-SVM模型可以做到识别书写人,最高准确率可达到87.2%,鲁棒性较好。
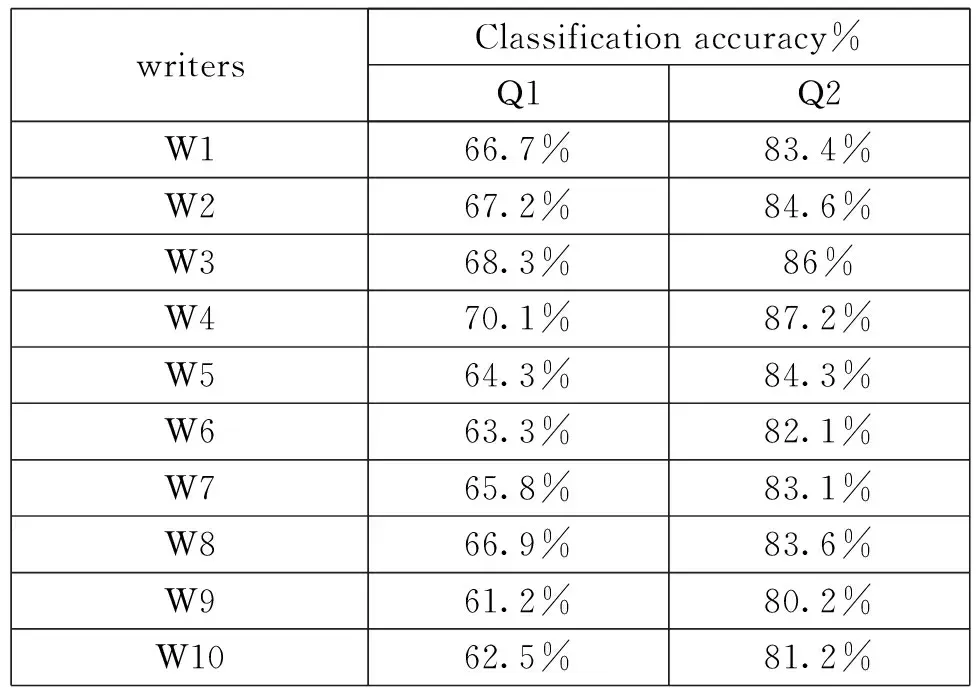
表1 实验结果
四、结语
本文针对电子签名的书写压力动态特征,提出了一种基于DTW-SVM的真伪签名识别模型,经实验表明,原始压力曲线结合DTW-SVM模型的识别效果不好,最高为70.1%,在对压力曲线作出峰值提取后,再利用DTW-SVM进行分类,识别10位书写人的效果较好,最高可达到87.2%,取得的效果较好,可以为笔迹鉴定提供,减少了鉴定人的主观性分析以及可能带来的错误,尽可能的进行客观评价,客服了笔迹鉴定单一依靠主观性的问题,但是考虑到司法鉴定的严谨性,应用计算机到笔迹鉴定领域的技术在不能做到像DNA那样能够几乎完全正确得出结论的前提下,仍需要笔迹鉴定人员作为主体,将计算机作为辅助笔迹鉴定人员的工具,由此才能取得较为正确的鉴定结果。
猜你喜欢
法制博览(2022年18期)2022-11-24
法制博览(2022年22期)2022-11-21
民族文汇(2022年24期)2022-06-09
少儿科技(2021年3期)2021-01-20
法制博览(2020年24期)2020-11-29
中国化工贸易·下旬刊(2019年5期)2019-10-21
中国经济信息(2018年2期)2018-02-02
佛山陶瓷(2016年11期)2016-12-23
大观(2016年9期)2016-11-16
人间(2015年33期)2015-12-08
