
基于局部关系卷积的点云分类与分割模型
2022-10-18 01:03高金金李潞洋
计算机工程与应用 2022年19期
高金金,李潞洋
1.山西财经大学 实验中心,太原 030016
2.中北大学 大数据学院,太原 030051
随着三维采集技术的不断发展,物体的三维模型数据更容易被获取。点云是一种常见的三维模型数据,其结构简单,描述的形状信息丰富,因此越来越多地被应用在自动驾驶、虚拟现实、机器人工程等领域。近年来深度学习在计算机视觉和自然语言处理方面取得了巨大成就,然而利用深度学习技术对三维点云数据进行分析还存在着诸多挑战。
卷积神经网络是深度学习研究领域中具有代表性的神经网络之一[1],在图像相关的领域中应用广泛,因为其可以直接输入原始图像进行一系列工作[2-3]。然而点云是无序、稀疏且不均匀的,这使得将二维卷积简单地进行维度扩展后直接应用在点云数据上是困难的。这是因为无法有效地在不同的局部空间定义提取相同特征的卷积核。一些先前的工作[4-10]对点云数据进行了转换加工,将其转换为规整数据结构,例如多个二维图像或三维体素模型,以便于定义适当的卷积算子,但是数据的转换与加工造成了大量的模型形状细节损失。
KD-Net[11]为输入点云构建KD-tree,然后从叶子到根进行分层特征提取。一些近期的工作将点云数据直接作为深度学习网络的输入。PointNet[12]是这类工作的基础,它利用多层感知机(multi-layer perceptron,MLP)逐点进行特征变换,并利用对称函数进行全局特征聚合,克服了点云的无序性。然而PointNet 与KD-Net 没有考虑点云的局部特征。PointNet++[13]在PointNet的基础上增加了逐层下采样与局部区域特征聚合,构建了分层网络模型,借此捕捉到一些局部特征信息。PointNet与PointNet++均是以逐点特征变换为基础,未考虑周边点产生的影响,无法全面捕捉形状信息。显然,点的特征不是孤立存在的,多个点的空间特征可以共同描述有意义的形状。借助局部区域中点之间的相关性可以提高特征转换的有效性,一些基于局部空间卷积的方法对此进行了探索,PointCNN[14]利用局部空间特征变换对局部区域的点进行了排序,A-CNN[15]将邻域点投影在中心点的切平面上以便对局部点进行排序,这类方法为无序的点云提供了一种一致性的排列方法,但并不能彻底解决点云无序的问题。SPLATNet[16]通过稀疏双边卷积层计算虚拟网格节点特征并使用插值计算点云真实点的特征。PointConv[17]利用空间坐标直接拟合产生局部点对应的卷积权重,但是没有参考局部区域的形状特征,这使得卷积核对不同形状的鲁棒性差异较大。RS-CNN[18]在描述局部形状特征时参考了邻域点与中心点之间的多种形状关系,这些方法对于局部区域形状的描述局限于邻域点与中心点之间的形状特征关系,而丢弃了邻域点之间的形状特征依赖,这对于局部形状特征描述是不充分的。这里认为,利用局部区域的形状信息计算邻域点的卷积权重依赖于对形状的精确描述,而邻域点之间的形状依赖也是精确描述形状信息的重要组成部分,应该加以参考。
除此之外,一些基于图卷积网络的方法被提出。PointGCN[19]与RGCNN[20]使用切比雪夫多项式构建图卷积;EdgeConv(DGCNN)[21]依靠了邻域点与中心点之间的向量关系计算局部特征,GAC-Net[22]利用局部中心点与邻域点之间的注意力关系构建图,HAPGN[23]使用门图注意力网络和分层图池化来强化不同表示空间的特征与分层特征。总的来说,图卷积的方法更多关注三维模型表面节点信息而非空间特征,虽然会在分割模型中表现良好,但是分类模型的性能较差。
本文在此基础之上,提出了一种更为全面的点云局部形状描述方法,并定义了一种基于局部关系的点云卷积算子(local relation convolution,LRConv)。该方法通过邻域内某一点与全部邻域点之间的多种低维空间关系对该点的形状特征进行描述,并应用MLP 学习到隐含的高维形状特征,产生对应的卷积权重;卷积权重被用于对本层中局部区域输入特征的抽象;最终将局部区域内全部点的抽象特征聚合为该局部区域的卷积输出特征。由于LRConv 全面参考了局部点之间的低维空间关系,因此学习到的隐式形状特征更加准确,由此生成的空间卷积权重充分反映了局部形状特征,对各种形状变换的感知也更为有效。对该卷积算子进行了一系列的实验,以验证其性能及其各部分的有效性。
本文的主要贡献:
(1)提出了一种新的点云局部区域形状描述方法,基于该方法定义了一种全新的点云空间卷积算子。
(2)基于本文提出的卷积算子,构建了用以点云分类与分割的网络模型。
(3)进行了充分的实验,验证了本文提出的方法在点云分类与分割任务中的有效性、鲁棒性;通过消融实验验证了卷积算子中各部分理论的有效性。
1 局部关系卷积
1.1 点云卷积的一般定义

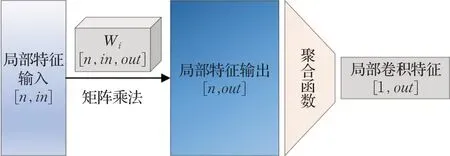
图1 点云卷积的一般定义Fig.1 General definition of convolution on point cloud
在规整的数据结构中,不同的locali之间共享相同的Wi以维持卷积核提取特征的一致性。然而,点云是非规整的,Wi中的每一个元素在不同的locali之间无法做到与xj的一一对应,为了保证卷积核在空间特征提取上的一致性,同一个卷积核对应的Wi在不同locali不应一致,而是应该与该区域的形状特征有关。
为此,探索了点云局部区域的形状关系,并提出一种新的局部区域形状描述方式,称为局部关系(local relation),并以此定义了基于局部关系卷积(LRConv)的全新卷积算子。
1.2 局部关系描述

1.3 局部关系卷积
假定reljk∈Rd,则P:Rd→Rin×out,对于全部n个点(包含xj自身)应用函数P,可以得到一组依赖于全部邻域点形状关系的权重组Wj∈Rn×in×out,如式(6)所示:

点xj的输出特征由局部区内每一个点对xj的卷积特征

在点云深度学习模型中,函数P可以通过MLP逼近,伴随着模型的训练,可以得到有效的映射函数P。注意,函数P应当在reljk之间共享,以保证低阶几何特征向高阶特征映射的一致性。同时,函数P应当在不同的局部区域之间共享,以保证不同区域间卷积核权重产生策略的一致性,进而保证不同局部区域之间特征提取策略的一致性。
通常,特征的维度会伴随着深度学习模型层数的增加而大幅度上涨。在点云深度学习模型较深的卷积层中,往往会出现维度巨大的权重矩阵,例如Wi∈Rn×256×512。考虑到Wi并非直接定义并共享权重,而是通过共享映射函数P产生n个Wj后再由聚合函数生成,在这个过程中,会产生大量无法共享的Wj∈Rn×in×out,这些权重均需要同时被存储于GPU的显存之中,这使得模型的推理与训练变得困难。在此对函数P进行等效改进,可以有效降低显存使用量。
将函数P拆分为两个维度映射函数的组合:

其中“·”为哈达玛积,p:Rd→Rin,T:Rin→Rout。
如图2 展示了LRConv 的张量流,它直观显示了式(12)的张量计算过程:在一个局部区域内,第j个点与第k个点的关系为式(3)中的reljk。映射p的权重在不同的reljk之间共享,以保证产生权重的策略的一致性,第n个点在第l层的特征输入fln经过关系权重Wn变换后,使用函数α聚合该点特征;对局部区域内每一点进行上述操作(可利用向量化并行计算),可以得到每一点的输出特征,并使用A对全部点的特征进行聚合,得到该区域的抽象特征;将聚合后的区域抽象特征输入函数T,变换为维度为out的抽象特征输出。
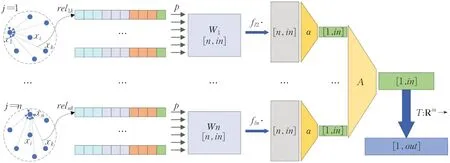
图2 局部关系卷积的实现Fig.2 Implementation of LRConv
关于式(12)中卷积算子的直观理解:在内部对flj进行特征变换、提取与融合的过程中,使用n×in维度的权重替代了大尺度的Wj∈Rn×in×out,同时特征变换的维度一直维持在一个较低的维度in,这使得卷积算子在每一层的内存占用约为式(9)的out-1倍。映射函数T能够将提取到的低维特征向高维特征转换,以维持卷积层的高特征输出维度。在实现过程中,映射函数p与T均由MLP无限逼近,使得式(12)与式(11)等价。
2 网络结构
2.1 分类网络
分类网络侧重于点云模型的整体特征抽象。多层局部特征聚合架构有助于在整体特征中保留更多的局部细节特征。分类网络的整体结构如图3(a)所示,网络的特征抽象部分由3 层LRConv 组成,每一层使用均匀采样方法(如最远点采样)对上一层的输出特征进行均匀采样,并使用空间局部发现(如KNN、球形邻域发现等方法)查找采样点的局部邻域。因此,LRConv的输入分辨率会逐层减少。为了保证更少的点数能够充分容纳整体的特征,每一层的输出通道数逐层增加。在特征抽象部分的最后一层,输出一个分辨率为1,维度为1 024的特征,并将其输入一个三层的全连接网络,全连接网络的每一层使用线性整流函数(rectified linear unit,ReLU)作为激活函数并进行批标准化(batch normalization),最后一层的输出维度为类别数量,并使用Softmax函数激活。
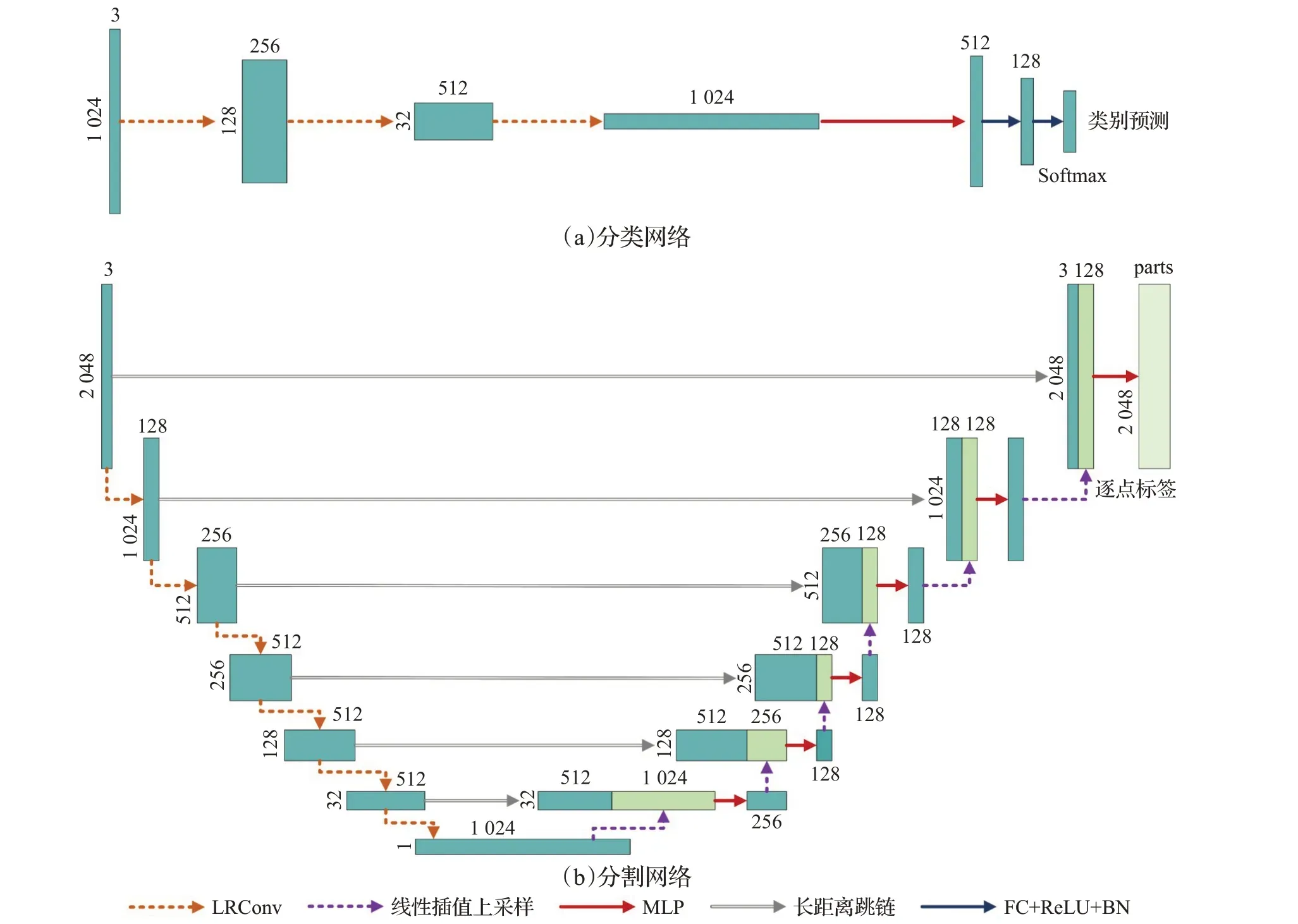
图3 基于LRConv的点云分类与分割网络Fig.3 Point cloud classification and segmentation networks based on LRConv
2.2 分割网络
分割是点云上的一类细粒度任务,网络的输出为点云中每一点的所属部分的标签。分割网络的整体结构如图3(b)所示。特征抽象部分与分类网络相似,分层局部特征聚合并降低点云的分辨率。考虑到更深的网络对分割性能是有益的,分割网络中用以特征抽象的LRConv 增加至6 层。在分割网络的后半部分,特征的分辨率需要逐层恢复,由于在点云的局部区域存在交叉,无法使用常规的特征广播的方式来恢复分辨率。本文采用了空间中4 点按照距离进行线性插值的方法恢复特征的分辨率,并将插值后产生的特征与特征抽象阶段对应的特征进行连接,并输入共享的MLP 产生新的输出特征。网络输出的点云分辨率与输入分辨率相同,并逐点给出对应的标签的概率。
3 实验
进行了一系列实验评估LRConv。分类准确率实验用以评估模型的分类性能,随机丢弃输入点实验用以评估模型的鲁棒性,消融实验用以评估LRConv结构中各部分的有效性。本章实验全部使用PyTorch[24]实现,并在两路NVIDIA TESLA V100 32G GPU上进行数据并行。
3.1 分类任务性能验证
分类准确率是分类网络的最重要指标,准确率直观表现了分类性能。为了方便与最先进的方法进行对比,选用了广泛应用于评估点云分类模型的ModelNet10和ModelNet40数据集。
ModelNet项目[5]提供了一套全面的3D CAD模型。ModelNet10 与ModelNet40 分别为ModelNet 的10 个 类别的子集与40 个类别的子集。ModelNet10 包含了10个类别共4 899 个CAD 三维模型,其中3 991 个模型用于训练,908 个模型用于测试;ModelNet40 包含了40 个类别共12 311个CAD三维模型,其中9 843个模型用于训练,2 468 个模型用于测试。使用的ModelNet 数据的格式为从CAD模型采样至1 024个点的点云模型。
为了增强网络对于模型旋转与抖动的鲁棒性,降低对原始训练集的过拟合,参照文献[12]的方式对训练集模型进行数据增强:按Z轴随机旋转点云并添加高斯噪声对点云进行小幅度随机抖动。
训练细节:实验构建的深度学习网络由三层LRConv构成,每一层采用最远点采样(farthest point sampling,FPS)方法对点云进行均匀下采样,采样点数量分别为512、128与1;邻域选择方法为球形邻域查询,半径分别为0.2、0.5 与0.8。每一层的输出维度分别为64、256、1 024。全连接网络每一层的维度分别为512、128 与类别数量。对称函数的选择均为通常在点云特征聚合中性能最优的最大池化函数。在网络中,所有的线性变换层均加入比例为0.3 的Dropout 以防止过拟合。损失函数为预测标签与真实标签的交叉熵损失,模型优化器为AdamW,初始学习率为0.01,动量为0.9,学习率线性衰减:每20轮训练,学习率降低50%。与先进方法的对比结果如表1所示。
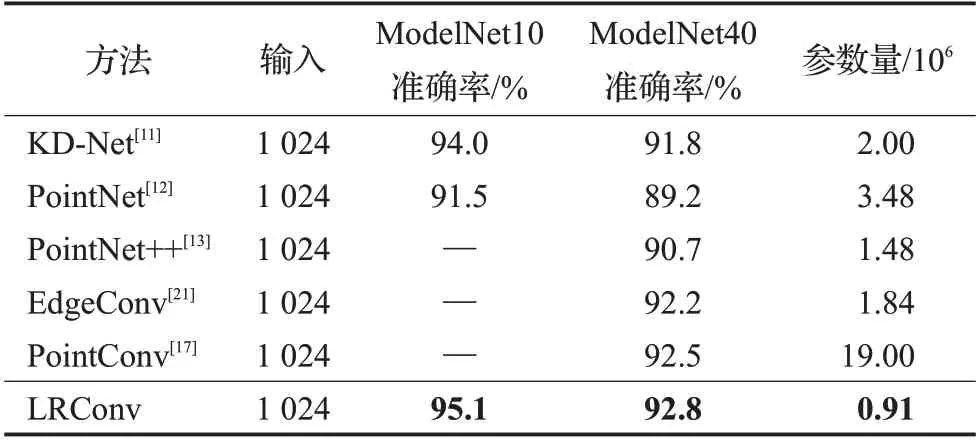
表1 在ModelNet数据集上的模型分类结果Table 1 Model classification results on ModelNet dataset
实验结果表明,提出的LRConv 模型在两个数据集上的分类准确率均优于目前的先进方法。在Model-Net40 上,相比基线方法PointNet++,LRConv 的准确率提升2.1个百分点,相比于动态局部构图方法的EdgeConv也有0.6个百分点的提升,这是由于LRConv有着更强的局部形状描述性能。相比于空间卷积方法PointConv,LRConv也有0.3个百分点的提升,这主要是由于LRConv的计算的卷积权重有着更多的形状约束依赖,能够产生更加有效的卷积核。
同时,为了评估模型的复杂程度,在表1 中提供了LRConv 与对比方法的参数量。LRConv 的参数量明显少于对比实验的其他模型,仅为基线方法PointNet++的61%。这是由于式(12)中LRConv的等价定义大幅度缩减了模型的体积,降低了内存消耗与参数总量,使得模型推理速度提升。由于可训练的参数量的减少,模型的收敛难度也大幅度降低,模型在第150轮训练后已趋近收敛,且在200轮附近完全收敛。网络的收敛曲线如图4所示。
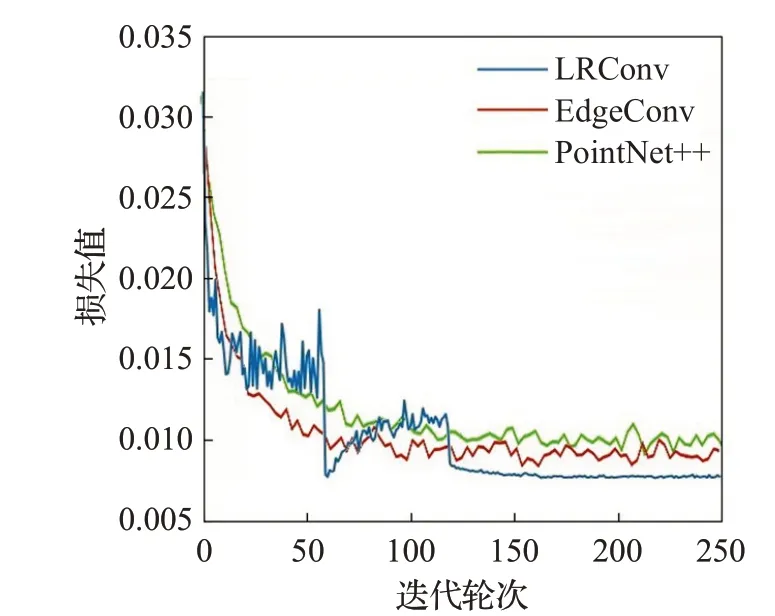
图4 分类模型的收敛曲线Fig.4 Convergence record of classification model
3.2 零件分割性能验证
零件分割任务能够验证深度学习模型处理细粒度问题的性能。ShapeNet 数据集[25]包含16 881 个三维模型,被分为16个类别,由50个类别的零件组成。ShapeNet数据集给出了三维模型中每一个点归属的零件类别标签。实验结果提供了两种指标,分别为类别与实例的平均重叠度(mean intersection over union,mIoU)。与3.1节相同,数据增强参照文献[12]进行。
训练细节:实验构建的零件分割深度学习网络由6个卷积层与5 个反卷积层组成。卷积层为LRConv,每一层的采样数分别为1 024、512、256、128、32 与1,局部查询半径分别为0.1、0.3、0.5、0.6、0.8与1,输出通道数分别为128、256、512、512、512与1 024,在特征分辨率恢复部分,除最后一层外,每个MLP由二层1×1卷积实现,隐藏层通道数为64,输出维度分别为256、128、128、128、128与128;最后一层的MLP由三层1×1卷积实现,通道数分别为128、64与零件类型数量。在网络中,所有的线性变换层均加入比例为0.4 的Dropout 以防止过拟合。损失函数为模型内每一点的类别预测概率与真实标签之间的交叉熵损失的均值,网络的优化器为AdamW,初始学习率为0.01,动量为0.9,学习率线性衰减:每30 轮训练,学习率降低50%。模型经过240轮的训练达到收敛状态,网络的收敛曲线如图5所示。与先进方法的对比结果如表2示。
实验结果表明,由LRConv 构建的点云零件分割深度学习模型优于目前的先进方法,尤其是在更能反映模型泛化能力的类别mIoU 指标中,领先基线方法Point-Net++高达1.5 个百分点,相比空间卷积方法PointConv也有0.6个百分点的领先。在具体类别细分中,LRConv在7 个类别上超越了先前的方法。ShapeNet 数据集上的分割性能实验,主要指标是平均的实例mIoU,具体细分类别上的mIoU 仅作为参考指标。接近于最先进的(state-of-the-art)方法在主要指标上有所提升都是十分艰难的,而少量的平均实例mIoU的提升,未必会使得全部的类别mIoU提升,因此,虽然无法在全部类别完全超越先前的方法,但这依然充分验证了LRConv在点云细粒度任务上特征抽象的有效性。
此外,随机抽取了不同类别的部分模型在图6展示分割的可视化效果,可以看出,LRConv的分割效果非常优秀。

图6 零件分割效果可视化Fig.6 Visualization of part segmentation effect
3.3 鲁棒性实验
对采样至1 024 个点的ModelNet40 模型随机丢弃部分点,降低输入点的数量,验证LRConv 对残缺点云模型的鲁棒性。在随机丢弃点后,残缺模型的输入点数分别为768、512、256、128与32。
与PointNet++和EdgeConv 的对比实验结果如图7所示,整体来说,LRConv的准确率要高于PointNet++与EdgeConv,且曲线下降更为平稳。在随机丢弃75%点后,LRConv依然有着较高的准确率,在随机丢弃80%的输入点后,准确率出现一定幅度的下降,但准确率依然超过85%,随机丢弃的点数超过80%之后,点云模型已无法描述模型的局部细节形状特征,模型形状辨认已经非常困难,准确率低于75%。残缺点实验充分验证了LRConv有着良好的鲁棒性。
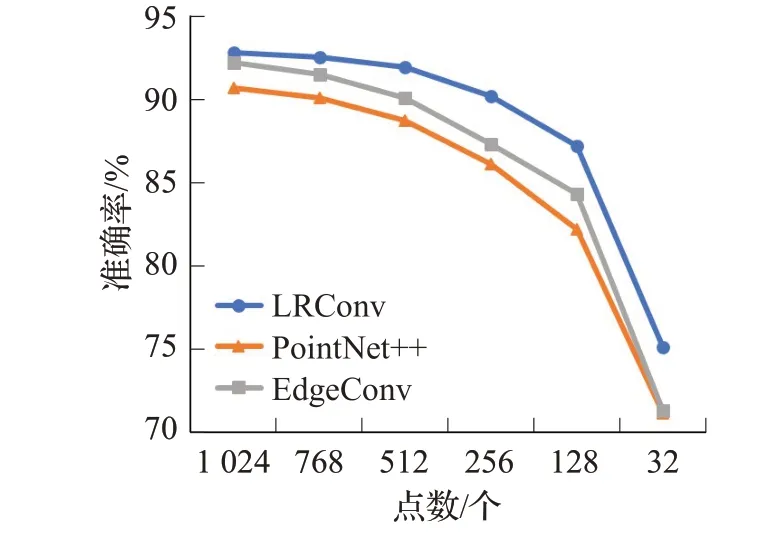
图7 随机丢弃部分点的准确率Fig.7 Accuracy of random dropout partial points
3.4 消融实验
由于目前的深度学习研究还存在着很多不可解释性,消融实验对与理解模型的工作原理十分重要。进行了一系列消融实验,以验证第1 章中提到的LRConv 相关理论的有效性。
3.4.1 关系描述选择
本小节实验选取了点之间不同的关系描述方式对实验结果的影响。这里认为,不同的关系描述方式对形状的关系依赖准确程度有着较大的影响,除第1章中提到reljk之外,还选取了另外的3 种方式进行对比实验,实验结果如表3所示。
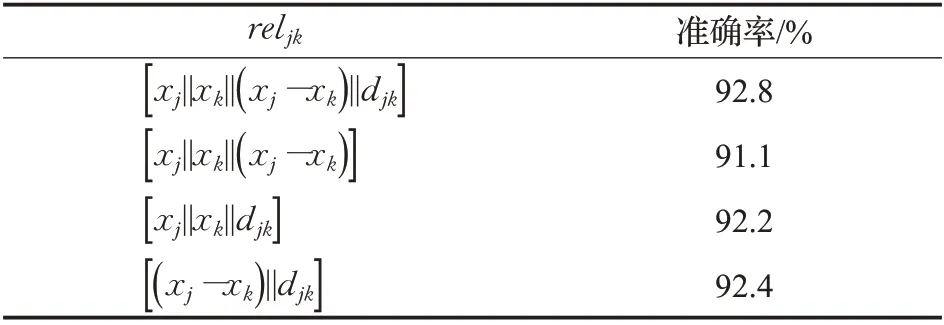
表3 关系描述对准确率的影响Table 3 Influence of relationship description on accuracy
实验结果表明,选择的reljk效果最好,而不同程度的描述缺失对模型的分类性能有着不同程度的不良影响。
3.4.2 非中心点的形状依赖
本小节实验对比了仅使用局部区域的中心点描述邻域点的形状关系,相比LRConv,对比实验设置去掉了非中心点对点xj的形状关系描述。实验的结果如表4所示。

表4 非中心点的影响Table 4 Influence of non-centered points单位:%
实验结果表明,去掉非中心点的形状依赖,模型的分类准确性降低了0.3 个百分点,这验证了非中心点的形状依赖在LRConv中是有效的。
3.4.3 对称聚合函数的选择
本小节对聚合函数A与α,选择了不同的对称函数以验证对称函数选择的影响。实验结果如表5所示。
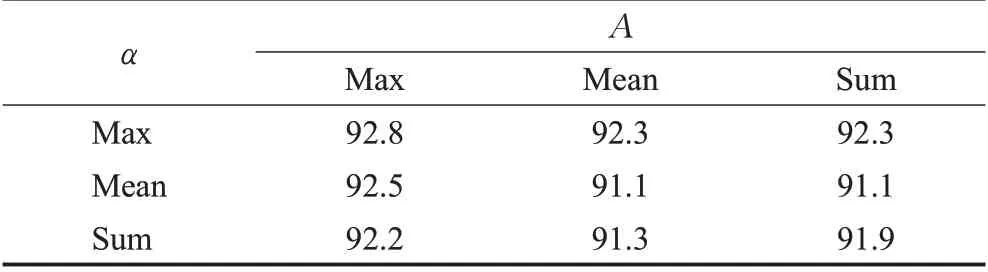
表5 聚合函数的选择Table 5 Selection of aggregate function单位:%
实验结果表明,无论对于A还是α,使用最大池化函数(maxpooling)聚合特征的模型性能都是最优的,通过对比其他的对称函数发现,对于单独的A与α,选择最大池化函数的性能也优于其他对称函数。
4 结论
本文提出了一种有效描述局部区域形状关系的方法,并由此定义了一种全新的用于点云深度学习分析的卷积算子。基于该算子,建立了点云分类与分割网络模型。通过实验表明,提出的局部关系卷积在三维点云模型的分类和分割任务上取得了良好的性能,验证了该算子的有效性。这主要是由于LRConv 有更强的形状关系描述性能,其权重有着更多的形状约束,能够产生更加有效的卷积核。未来,将探索该算子在点云其他任务上的应用,如场景分割、目标检测等。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
农业工程学报(2022年7期)2022-07-09
山花(2022年5期)2022-05-12
计算技术与自动化(2022年1期)2022-04-15
散文诗(2020年1期)2020-07-20
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电子技术与软件工程(2019年8期)2019-07-16
东方艺术·国画(2016年3期)2017-02-08
知识力量·教育理论与教学研究(2013年11期)2013-11-11
