
YOLOv3融合图像超分辨率重建的鲁棒人脸检测
2022-10-18 01:03赵军艳降爱莲
计算机工程与应用 2022年19期
赵军艳,降爱莲,强 彦
太原理工大学 信息与计算机学院,山西 晋中 030600
人脸检测技术在计算机视觉领域具有重要的理论研究意义和广泛的应用价值。从门禁识别、人脸支付到情感分析、人机交互以及视频监控与追踪,不断扩展的各种市场应用需求的推动下,人脸检测技术取得了巨大进步。然而在动态场景和复杂背景下,由于拍摄角度不同、背景噪声干扰、图像模糊,人脸尺度、姿势、表情多变以及光照条件等因素的影响,准确地检测出人脸的存在并确定人脸位置的人脸检测技术仍然存在许多困难和挑战,比如漏检、误检以及检测速度慢等问题。现实场景中,由于小人脸目标像素少、特征不明显,与大目标相比,其召回率低,所以如何提高检测的精度和模型的鲁棒性成为一个至关重要的问题[1]。
基于卷积神经网络的目标检测方法主要分为两大类[2]:第一类是两步(two-stage)目标检测算法,其检测过程分为候选区域和特征提取、区域分类和位置调整两个阶段,典型的算法有R-CNN[3]及其变体Fast R-CNN[4]和Faster R-CNN[5]、SPPNet[6]、R-FCN[7]以及Mask R-CNN[8];第二类是单步检测算法,直接通过回归得到目标的概率和位置坐标,经典的算法有YOLO(you only look once)[9]、SSD(single shot multiBox setector)[10]、YOLOv2[11]和YOLOv3[12]。前者拥有更高的检测准确度,但其检测速度较慢,后者在保持性能的同时大大提高了检测速度。
人脸是一种特殊的目标,为了获得更好的检测效果,研究者们对目标检测算法进行改进和优化,提出许多优秀的人脸检测算法。CMS-RCN[13]基于Faster RCNN进行改进,融入人体上下文信息来提高人脸的检测性能。MTCNN(mutil-task convolutional neural network)[14]采用3个单独的网络模块级联的方式,网络中加入了关键点位置的检测,有利于人脸检测。Wan等[15]将Faster R-CNN 与困难负样本优化结合,取得了不错的检测结果。Hu等[16]提出的多模板人脸检测算法使用大尺度人脸的局部上下文信息,对检测小尺度的人脸非常有帮助。Zhang 等[17]提出S3FD,基于SSD 的框架进行改进,对于不同尺度的人脸均具有良好的性能,尤其是小尺度人脸。以上这些方法在可控条件场景下都取得了很好的检测效果,但是当复杂场景中人脸信息不足、尺寸较小的情况下,这些人脸检测方法的精度相对较低。
YOLOv3是目前较优秀的目标检测算法,其网络中的多尺度融合可以很好地检测小目标,且实时性强,被广泛应用在各种场景。为了提高小人脸的检测精度,本文基于YOLOv3进行改进,采用Darknet53作为主干网络,在网络中融合图像超分辨率重建技术,使小目标拥有更丰富的纹理信息,提高视觉感受的真实性。文中所提算法SR-YOLOv3保证检测速度的同时提高了检测精度,以及小目标的检测能力。
1 相关技术
1.1 YOLOv3算法
YOLO是较新的单步目标检测算法,可以在一次扫描中同时预测整个图像的边界框和类别,不需要使用RPN(region proposal network),直接通过网络来产生目标的位置和类别信息,相比较两步目标检测算法,其具有更快的检测速度。
YOLOv3 在YOLOv2 的基础上进行改进,并使用基于残差神经网络改进的Darknet-53 网络进行特征提取,改善了YOLO 系列在检测小目标上的缺陷。Darknet53 网络有52 个卷积层和一个全连接层,可以输出13×13,26×26,52×52 这3 种尺度的特征。然后YOLOv3 的检测网络对Darknet53 的输出进行回归,预测出多个预测框,并使用非极大值抑制算法,去除IOU 较大的和置信度较低的预测框,保留置信度较高的预测框为目标检测框。YOLOv3 首先将输入的图像整体缩放为416×416,并将图像划分成大小为S×S的网格,如果某个目标的中心落在某个网格中,则该网格负责预测该目标。
YOLOv3 的网络结构如图1 所示,卷积信息第一列表示卷积核的个数,第二列表示卷积核的大小,“/”后面的数字表示卷积的步长,默认为1。网络中没有使用池化来进行下采样,而是采用步长为2的卷积,共进行了5次下采样,经过5 个残差模块后,得到的特征图大小为416→208→104→52→26→13。up sampling 为上采样层,使用内插值方法来放大图像,将上采样后的大特征图与小特征图进行concatenate张量拼接,使网络能够拥有既包含丰富的高层抽象特征又包含精确的位置信息特征的融合特征层[18]。
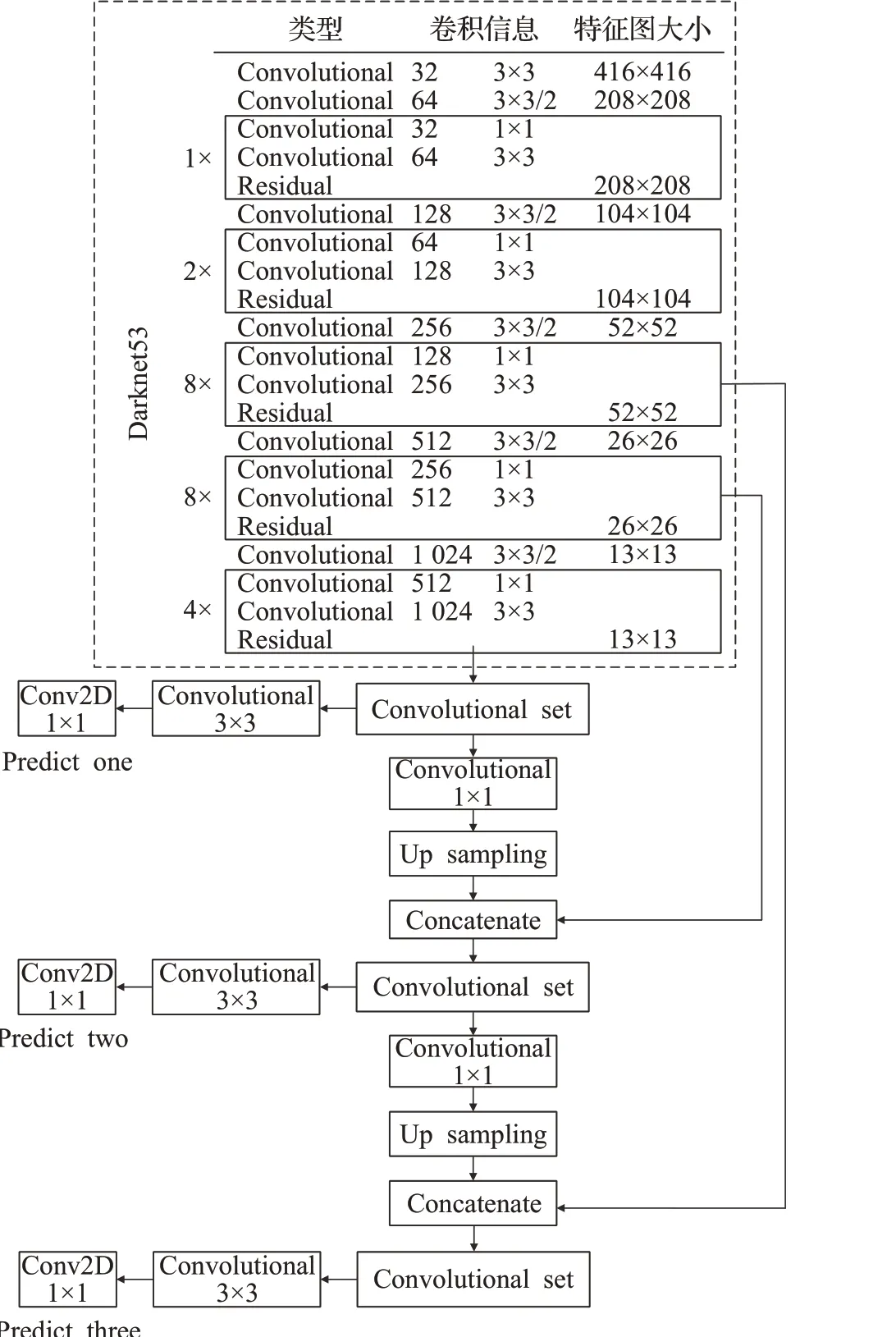
图1 YOLOv3网络结构Fig.1 Network architecture of YOLOv3
网络中有5个残差块,每个残差块由多个残差单元(res-unit)组成,通过输入与两个DBL(darknetconv2DbatchNorm-leak ReLU)单元的累加进行残差操作,add层将相同维度的张量进行相加,确保网络结构在很深的情况下也能收敛,如图2(a)所示。其中DBL单元包含卷积、批归一化和leaky ReLU激活函数,如图2(b)所示。
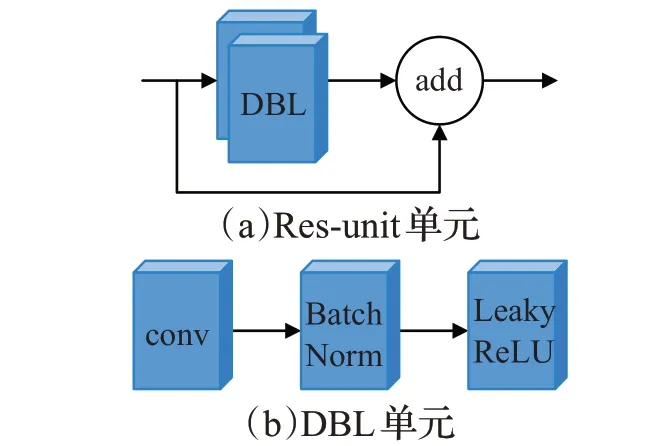
图2 残差块结构Fig.2 Residual block structure
1.2 图像超分辨率重建技术
在现实应用场景中,由于图像环境和拍摄技术的限制,一些图像会出现模糊、低质量等问题,这种情况则为低分辨率图像,这类图像在感兴趣区域RoI 的表现很差。为此,提出一种特定的算法来丰富低分辨率图像的细节信息,提高图像的表述能力,即图像超分辨率重建技术。
当前应用广泛的是基于深度学习的超分辨率重建技术,其中基于生成对抗网络的(GAN)[19]的SRGAN[20]网络生成的超分辨率图像具有较好的视觉效果,是一种应用广泛、效果优秀的图像超分辨率重建技术,SRGAN本质仍是GAN,目的是为了训练出一个生成函数,输入低分辨率图像,便可以生成相应的超分辨率图像。SRGAN 在SRResNet 的基础上,采用感知损失(perceptual loss)和对抗损失(adversatial loss)使得生成的图片与目标图片更接近。
SRGAN 网络是由一个生成器和一个判别器组成,其网络模型如图3 所示[20]。生成网络(generator network)的核心是多个残差块,每个残差块包含两个3×3的卷积层,卷积层后是批归一化层,PReLU 作为激活函数。判别网络采用类似VGG19 的网络结构,但没有进行最大池化。判别网络(discriminator network)包含8个卷积层,随着网络的加深,特征数量不断增加,特征尺寸不断减小,LeakyReLU 作为激活函数,网络最后采用两个全卷积层和sigmoid激活函数来获得学习到的真实样本的概率,用来判断该图像是来自真实样本的高分辨率图像还是伪造样本的超分辨率图像。
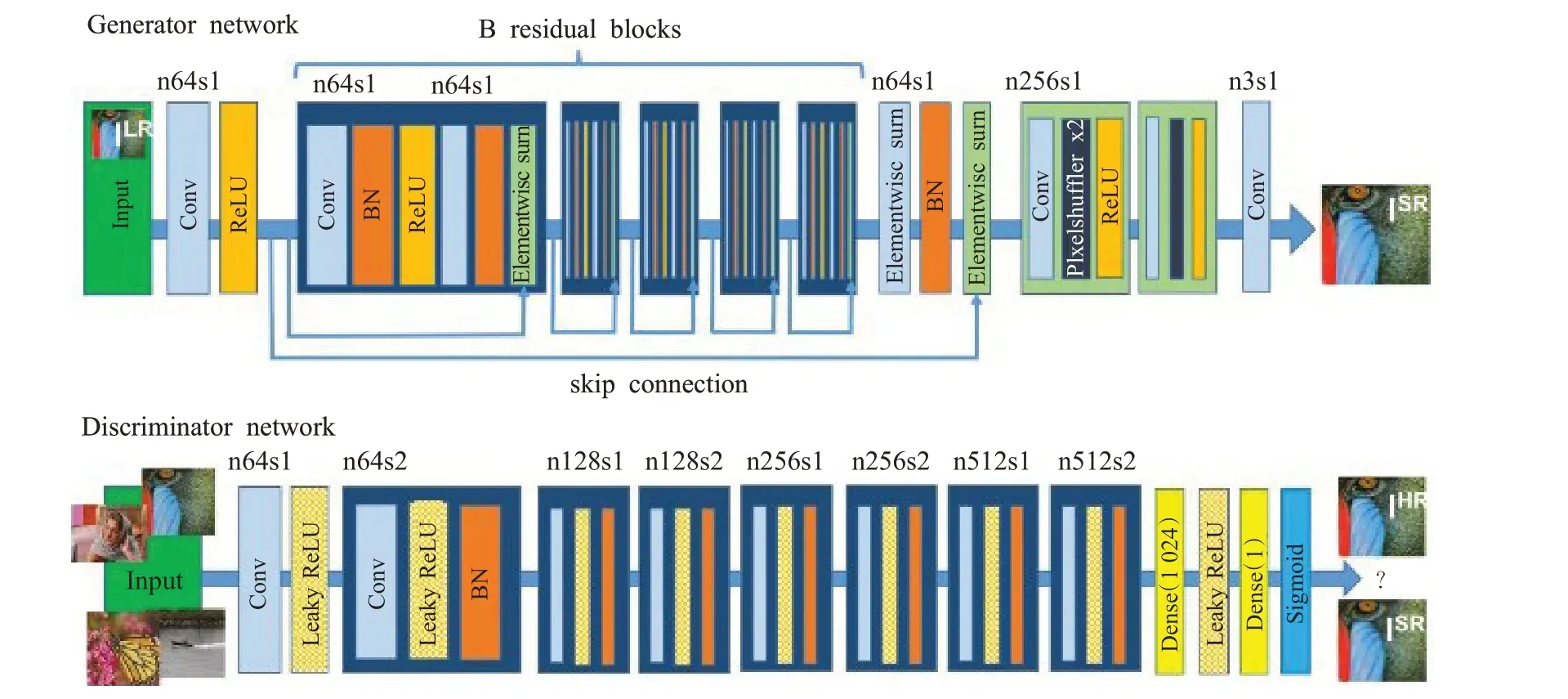
图3 SRGAN 网络模型Fig.3 SRGAN network model
2 提出的方法
本文主要研究小人脸检测问题,YOLOv3网络中所使用的先验框和网络结构不适用本文的研究对象。所以,本文中首先对所选用的样本使用K-means++算法进行聚类分析,得到适合本文研究对象的先验框,然后在网络中融合图像超分辨率技术,使修改后的网络在小目标上有很好的检测效果。
2.1 数据集目标框的聚类分析
YOLOv3 算法沿用了YOLOv2 的先验框(anchor box)思想。anchor box是一组宽高固定的初始候选框,数量由人工设定,其设定会影响到网络的的准确度和速度。原YOLOv3 网络在COCO 数据集上进行训练,有9种大小的anchor box,表示3种边框大小和3种长宽比。网络在训练阶段,需要计算真实框与哪个anchor box的IoU(intersection over union)最大,然后标记该box的置信度为1。在计算损失时,这个anchor box 对应的预测有回归、置信度和分类3 种误差,大于某个阈值但不是最优的锚框对应的预测值则没有置信度和分类损失,小于阈值的则有置信度。在测试阶段,则根据置信度与阈值的关系判断预测的边框是否有效,这时anchor box的作用就是还原预测边框在输入图像中的大小。所以,如果直接将原来的9 个anchor box 应用到人脸数据集上显然是存在不足的,检测样本中存在很多10×10~40×40的小人脸目标,很容易出现小人脸漏检的情况。
本文使用K-means++对数据集WIDERFACE 中人脸真实框的宽高进行聚类分析,生成适合该数据集的9个宽高组合的anchor box。K-means++采用欧氏距离,候选框越大,产生的误差越大,所以YOLOv3 采用候选框与真实框的交并比IoU 来消除候选框所带来的误差。这里使用平均IoU 来分析聚类结果,聚类的平均IoU目标函数f可以表示为:
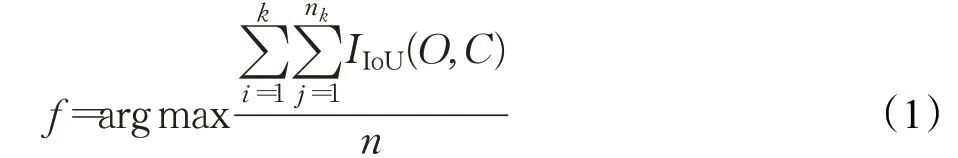
公式(1)中,O表示样本,n表示样本总个数;C表示聚类中心,k表示簇的个数;nk表示第k个簇中样本的个数,i表示样本的序号,j表示聚类中心的序号。IIoU(O,C)表示边界框与聚类中心框面积的交并比。
聚类得到的anchor box 能使网络有更快的收敛速度,保证网络的检测精度。具体特征图及其先验框尺寸的分配如表1所示。

表1 训练集的anchor boxes结果Table 1 Results of anchor boxes of training set
2.2 SR-YOLOv3网络模型
本文为解决小尺度人脸检测问题,设计了一个两级人脸检测器,在YOLOv3 网络框架的基础上,融合图像超分辨重建模块SRGAN 网络,整体构成一个小人脸检测模型SR-YOLOv3,网络结构如图4 所示。这个网络前半部分为DarkNet53,可以检测出大部分高清人脸样本;对于待确定样本,通过其坐标信息,将区域信息输入到SRGAN 中进行超分辨率重建并再次进行人脸检测,最后将两级人脸检测器的输出整合输出。
Darknet53 网络有3 个不同尺度的输出,在图4 中,y3 感受野小,可以检测出图像的小人脸,所以在y3 后增加SRGAN 网络。文中使用Faster-RCNN 中anchor box 与真实框的匹配方法,默认pos_iou_thr 为0.7,neg_iou_thr 为0.4,min_pos_iou 为0.4。若由y3 输出的目标满足IoU〉pos_iou_thr,则判定其为正样本,若IoU〈neg_iou_thr,判定其为负样本,若min_pos_iou〈IoU〈pos_iou_thr,判定其为待确定样本。对于待确定样本,将其输入二级检测器SRGAN 中,由生成器生成高分辨率样本,判别器用来判定是否是合格的重建样本并判断其中其否包含人脸,若满足,则保留其位置信息。最后采用非极大值抑制算法(non-maximum suppression),设定阈值为0.45,计算所有预测框的交并比IoU,确定目标最终位置。
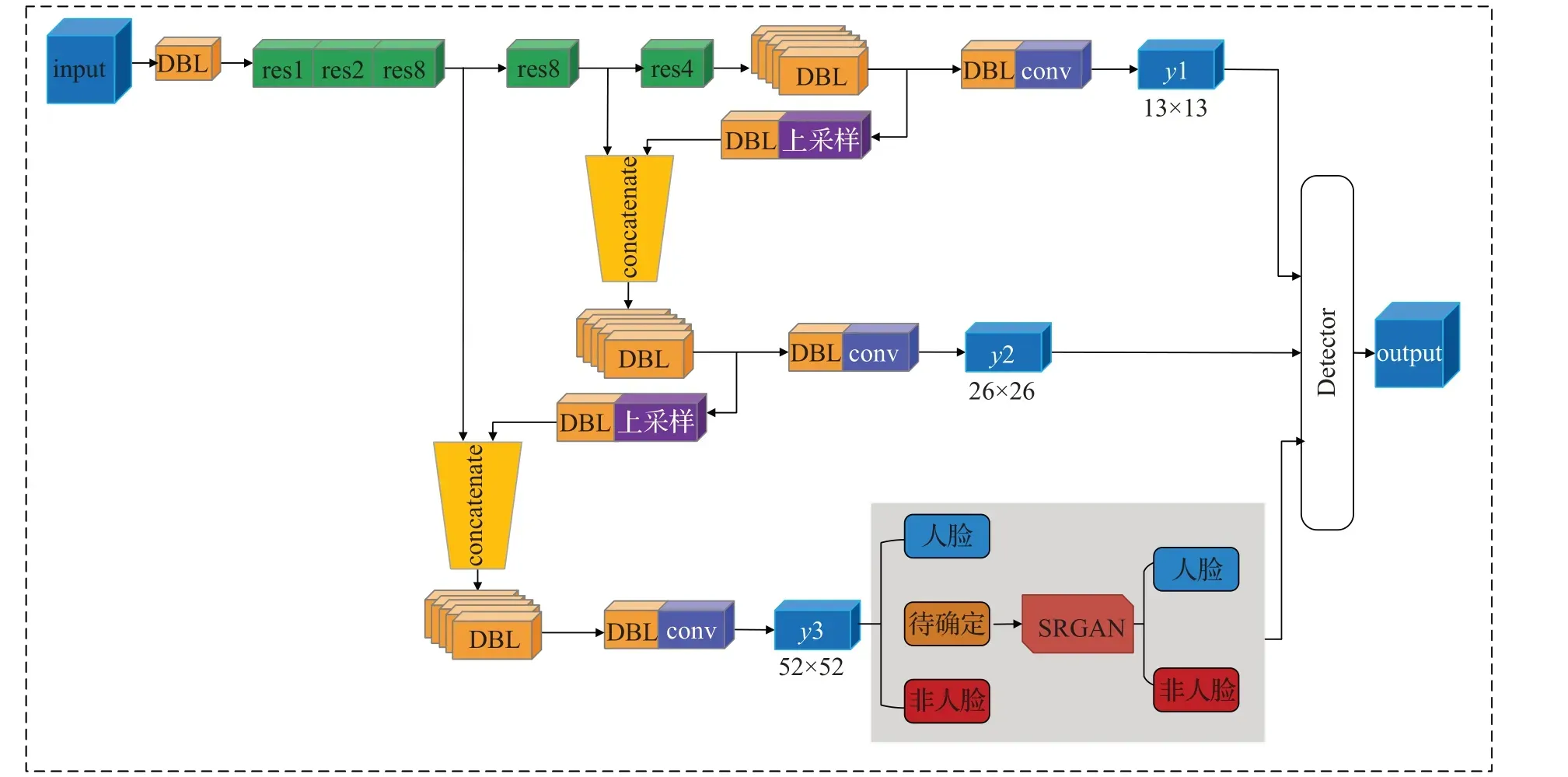
图4 本文算法网络结构Fig.4 Proposed algorithm network architecture
2.3 网络损失函数
网络的损失函数包括坐标损失Lbbox、置信度损失Lobj和分类损失Lclass三部分。损失函数L为:

使用均方差损失函数计算坐标损失,交叉熵损失函数计算置信度损失和分类损失:

3 实验与结果分析
3.1 数据集及实验环境
实验使用的是一个人脸检测的基准数据集WIDERFACE[21],其中包含32 203张图片及393 703张已标注的人脸,这些人脸在尺度、姿势和遮挡方面都具有很大的变化,图片中人脸数据偏多,平均每张图片有12.2 个人脸,密集小人脸非常多。数据集包含三部分:训练集train、验证集val、测试集test,分别占样本数的40%、10%、50%。本文着重对小人脸进行检测,难度会有所加大,所以在这种检测困难的情况下验证集和测试集分为easy、medium、hard难度等级,其中hard子集中有许多小尺度人脸,大部分为10~50 pixel,适合验证所提方法的有效性。
本文的实验环境配置如表2所示。

表2 实验环境配置Table 2 Experimental environment configuration
3.2 SR-YOLOv3模型的训练与测试
3.2.1 训练模型
在模型训练之前,先设置网络的训练参数。目标类别为1,anchor box 为(5,6),(8,9),(10,13),(15,19),(21,27),(30,38),(44,56),(76,100),(178,236)。训练的batch size 为64,动量为0.9,衰减率为0.000 5。最大迭代次数为60 000 次。开始训练时,设置学习率为0.001,用来稳定整个网络,迭代10 000次后调整为0.01,迭代30 000次后,调整为0.001,迭代40 000次后调整为0.000 1,使损失函数进一步收敛。
改进后的网络SR-YOLOv3训练过程中准确度收敛曲线如图5所示,平均损失函数的收敛曲线如图6所示,大约经过50 000 次迭代后,平均损失函数值稳定在1.3附近。
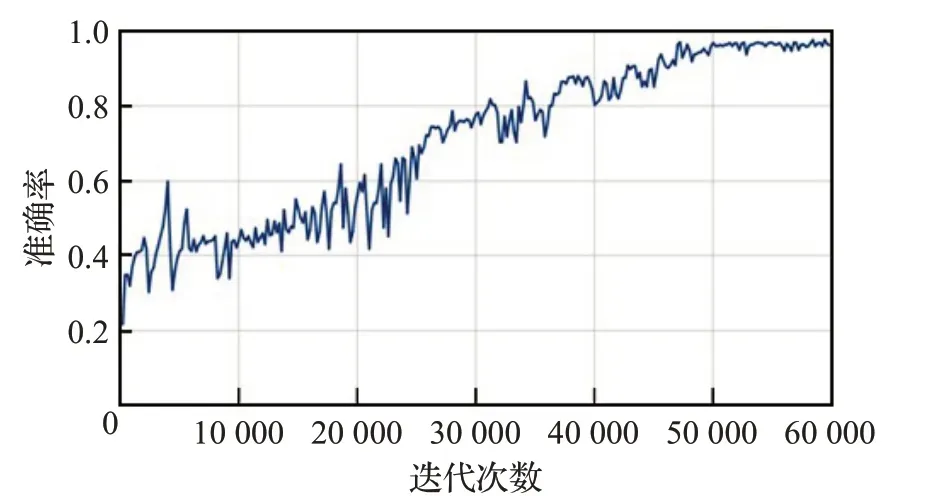
图5 准确率曲线Fig.5 Accuracy curve
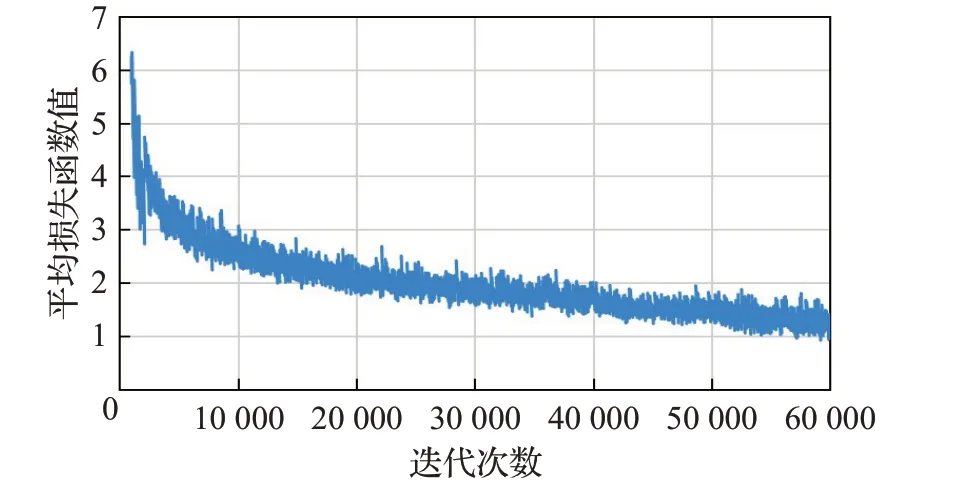
图6 平均损失函数曲线Fig.6 Average loss function curve
3.2.2 测试模型
改进后的算法在WIDERFACE 数据集上的检测效果如图7所示,可以看出该方法在各种复杂场景下具有较好的鲁棒性和较高的准确度。图(a)可以检测出那些暗光下的人脸,图(b)即使在高密度人群中,也可以很好地检测出大量小人脸,图(c)本身分辨率较低,视觉效果差,但从检测结果中可以看出,仍有许多人脸被检测出来,图(d)可以看出该方法在遮挡人脸上也有很好的检测效果。

图7 在WIDERFACE测试集上的检测结果Fig.7 Detection results on WIDERFACE test set
3.3 实验结果分析
在人脸检测的效果评价中,有一些相关参数:TP(true positives)表示检测到人脸,实际图片中也存在人脸;TN(true negatives)表示没有检测到人脸,实际图片也不存在人脸;FP(false positives)表示检测到人脸,但是实际图片中不存在人脸;FN(false negatives)表示没有检测到人脸,但实际图片中存在人脸。本文的模型评价指标包括:召回率R、精确度P和F1 分数。召回率用来评价检测出的人脸占样本标价总人脸的比例;精确率用来评价检测出的正确人脸占检测出的总人脸的比例;当两者相近时,参考F1 分数,F1 分数越大则认为算法越好。
各指标的具体算法如下所示。
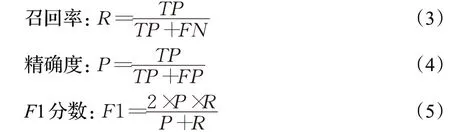
将所训练的模型在验证子集上进行验证,由公式(3)、(4)和公式(5)得到召回率R=0.84,精确度P=0.85,F1=0.845。从F1 分数上看,所提出的算法性能较好。
3.3.1 模型性能分析
在Darknet53网络中融合SRGAN后,首先需要验证融合后网络的合理性和有效性。从测试子集中挑选1 000张图片进行网络模型测试对比,由表3中可知,融合超分重建技术后的网络相较于原YOLOv3,速度有所降低,这是由于融入新网络时增加了网络深度,但是相较于使用Resnet101作为骨干网络的HR网络模型,运行时间减少了许多。改进后的网络在平均检测精度上有了明显的提升,比原YOLOv3提高了1.9个百分点。

表3 不同模型的性能对比Table 3 Performance comparison using different models
3.3.2 相关算法精确度比较
为了说明本文算法的有效性,选取了一些优秀的人脸检测算法在WIDERFACE 数据集上测试并进行结果分析。如表4所示,本文算法在easy、medium、hard验证子集上的平均精度均值(mean average precision,mAP)分别为94.3%、93.5%、86.2%。相较于MTCNN 算法分别提高了9.2、11.5、23.3 个百分点,相较于CMS-RCNN算法分别提高了4.1、6.1、21.9个百分点,相较于HR算法分别提高了1.8、2.5、4.3个百分点。相较于S3FD算法分别提高了0.6、1.0、0.3个百分点。
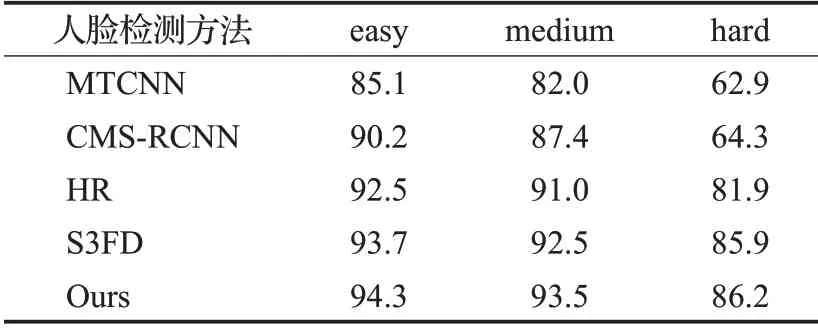
表4 不同人脸检测算法对比(mAP)Table 4 Comparison of mAP using different face detection algorithms单位:%
本文提出的SR-YOLOv3在YOLOv3网络上进行改进,引入图像超分辨率重建技术对小尺度模糊人脸进行二次检测,加深网络来使人脸特征更容易被检测到,捕捉小目标信息,使网络在处理复杂的人脸和非人脸的分类检测时,能够能加精准。通过在WIDERFACE数据集上的对比实验,验证了本文所用方法具有更高的检测精度和更好的鲁棒性,尤其是在hard子集下有更为突出的性能。
4 结束语
针对实际应用中人脸尺度多变带来的检测问题,本文提出一种适用于复杂场景中的小人脸检测算法。本文的主要思想是将SRGAN 的图像超分辨率重建技术融入到目标检测算法YOLOv3 的网络结构中,YOLOv3 检测速度快,但是相较于SSD 等其他一阶检测算法,其检测精度有所下降,所以利用SRGAN 来弥补其检测精度,进而提高小尺度人脸的检测精度。与其他人脸检测算法在相同的环境下,使用相同的数据集进行对比实验,结果证实了所提出方法的可行性及优越性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
奥秘(2021年5期)2021-06-15
河南科技(2021年35期)2021-04-25
上海师范大学学报·自然科学版(2019年5期)2019-12-13
小雪花·初中高分作文(2017年9期)2018-05-21
米娜·女性大世界(2016年8期)2016-08-17
CHIP新电脑(2016年3期)2016-03-10
奇闻怪事(2014年5期)2014-05-13
