
分层特征融合网络航拍图像超分辨率重建
2022-10-18 01:48杨夏宁王帮海李佐龙
计算机工程与应用 2022年19期
杨夏宁,王帮海,李佐龙
广东工业大学 计算机学院,广州 510006
近年来,得益于卷积神经网络的发展,图像超分辨率重建的效果得到了显著提高,使其在人脸超分[1]、安防监控[2]、航拍遥感[3]和医疗卫生[4]等领域得到了广泛的应用。在硬件方面提高图像超分辨率的效果通常有三种途径:减小像素传感器的尺寸、增加感光芯片尺寸和提高相机的焦距[5]。但受限于成本,人们无法在所有场景中都使用高昂的拍摄设备,故而以算法作为辅助手段的低成本方法成为了研究的热点。
图像超分辨重建算法可分为基于传统插值[6]、基于重构[7]和基于学习三种。相比基于插值和重构的方法,基于深度学习的图像超分辨率重建在效果上更优越。图像超分辨率技术在数学上属于高度欠定问题[8],即从低分辨率图像(low-resolution,LR)到高分辨率图像(high-resolution,HR)重建过程中由于图像特征信息的缺失,映射解空间并不唯一。并且放大因子越大,重建所欠缺的信息就越多,最终得到重建的效果也越差。为此许多深度学习的方法都致力于通过构建更深层或更宽的结构来提升网络的容量来承载LR图像与HR图像之间复杂的映射关系。
2014 年,Dong 等人[9-10]首次在其提出的神经网络SRCNN(super resolution convolutional neural network)中,将深度学习方法应用到了图像超分辨率重建领域中,并在后续工作中改进SRCNN上采样方式,进一步提出了FSRCNN(accelerating the super-resolution convolutional neural network)[11]。2015年,Kim等人[12]受到残差网络的启发,首次将残差网络[13](residual network,ResNet)应用于图像超分辨率重建网络中,提出VDSR(very deep convolution networks for super-resolution)模型,成功将SRCNN的3层网络结构,跨越式的增加到20 层,自此基于深度学习的超分辨率重建工作开始朝着构建更深层网络的方向发展。2016年,Kim等人[14]提出了深层卷积神经网络DRCN(deeply-recursive convolutional network)。该模型借鉴了递归神经网络RNN[15](recurrent neural network regularization)结构,将非线性映射层拓展为16个递归层,同样达到了加大网络深度的目的。2017 年,Tai 等人[16]提出的DRRN(deep recursive residual network)在DRCN全局残差学习的基础上引入局部残差学习,网络权重在递归的局部残差中共享。得益于递归和残差思想的结合,DRRN 最终将网络模型提高到了52 层。不同于VDSR 着重于增加网络深度,2017年,Tong等人[17]提出的SRDenseNet模型将DenseNet[18](dense convolutional network)中密集残差连接结构应用到了图像超分辨率重建网络中。实验结果表明,SRDenseNet 的密集连接结构加强了局部特征的传播,在不同深度的网络层中起到了信息互补的作用,从而提高了边缘和纹理的重建效果。2017年,Lim等人[19]提出的EDSR(enhanced deep super-resolution network)网络模型简化了SRDenseNet 的残差模块,指出ResNet 网络中的残差结构在图像超分辨率重建领域的局限性,并使用去除批归一化层(batch normalization layer)的残差结构作为非线性映射层的堆叠模块。去除批归一化层减少了模型的参数,从而让EDSR成功构建更深层的网络结构,提高网络的整体性能。
由SRCNN到EDSR表明越深的网络和更密集的残差结构能够有效的提高超分辨率重建的最终效果。但深层神经网络训练难度较大,需要耗费巨大的计算资源,同时在深层卷积过程中难以避免地会造成图像信息的损失。一味的堆叠网络的深度已经无法有较大的突破。如何在有限的资源里充分发挥网络的效能成为图像超分辨率任务的新挑战。
针对以上问题,本文提出一种分层特征融合的图像超分辨率重建网络。该网络使用分层结构完成通道特征的融合,以此来补偿卷积过程中图像信息的损失。网络将逐层递增特征通道的数量,以保留更多分辨率信息,而且特征通道数的增加也为上一层提供了更多的整合信息。为加强图像低频信息在网络中的传递,本文算法在基础残差块中使用密集连接结构,组成密集连接残差块。此外,在基础残差结构中引入不降维轻量级注意力模块,以提高模型对图像高频信息的敏感度。与现有的方法对比,尤其是在较为复杂的环境中,本文算法在重建效果上具备一定的优势,证明了算法有效性。
1 相关工作
1.1 U-Net算法
Ronnerberger等人[20]在2015年提出U-Net全连接神经网络并应用于医学图像分割。受限于医学图像数据样本较少的问题,U-Net 采取了一种对称式的U 形结构以充分提取有限图像样本中的特征信息。整个网络结构主要分为下采样收缩过程和上采样扩充两个过程。下采样操作共有四次,每一次都会通过增加卷积核数目来将图像的特征通道数加倍。卷积之后使用全局平均池化(global average pooling,GAP)缩小特征图尺寸,以减小网络训练的难度。如此逐层地通过卷积操作来递增特征通道数量不仅减轻了训练全卷积网络的负担,也能够充分提取到图像信息的有利部分。
上采样通过反卷积[21](deconvolution)来实现。在特征图上采样扩张的过程中,卷积核的数目会逐层减半,同时使用反卷积将特征图尺寸逐层复原。U形网络中,同层收缩和扩张路径的特征信息会通过跳跃连接融合在一起后,再通过卷积层进行特征提取。U形结构中收缩路径提取的定位信息会与扩张路径中提取的高级特征信息进行结合,一定程度上为网络提供了注意力。此外,在下采样过程中丢失的图像信息也可以通过对称的网络结构得到相应的补偿,减少连续卷积中图像信息的损失。
1.2 通道注意力机制
2017 年,Hu 等人[22]首次在SENet(squeeze-andexcitation network)中提出通道注意力学习机制开始,通道注意力机制就被应用于各种网络模型中。2018年,Zhang等人[23]提出的RCAN网络在残差模块中插入通道注意力模块,虽然增加了一部分计算量,但是相比较于VDSR 和EDSR 等没有使用注意力模块的深层网络,RCAN 获得了更好的重建效果。如图1 为RCAN 插入局部残差结构中的通道注意力模块的基本结构。
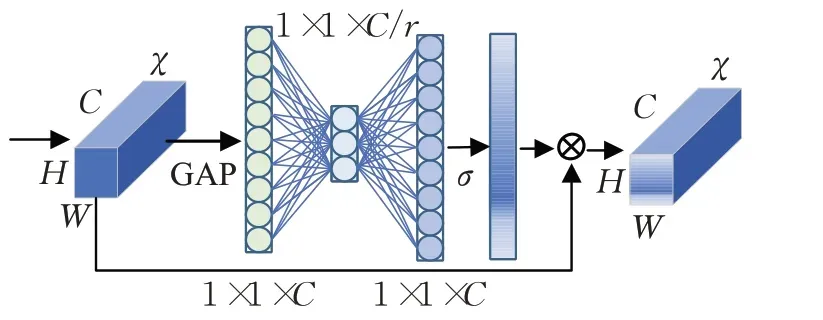
图1 通道注意力模块Fig.1 Channel attention module
假设输入形状为H×W×C的特征图χ=[x1,…,xc,…,xC]。挤压的过程首先使用全局平均池化(GAP)将全局空间信息转换为通道描述符z,z是形状为1×1×C的特征图,表征输入特征通道的统计量,即该通道共享感受野的范围。z的第c个元素zc为:

f(·) 和δ(·) 分别表示sigmoid 函数和ReLU 激活函数,WD、WU为卷积层的权重设置。两个全连接层间的瓶颈结构用于降低整个模型的复杂度,最终得到通道统计量s。该统计量与初始输入特征图进行加权后完成对输入特征图通道xc微调:

SE 注意力模块对通道的依赖性进行建模,通过加权的方法对特征进行逐通道调整,使得网络可以通过学习全局信息来有选择性的加强或抑制网络的学习过程,从而达到网络侧重学习对重建有益信息的目的。
2 本文方法
本文借鉴了U-Net的对称式分层特征融合结构,整体的网络结构展示如图2 所示。主要分为特征图通道扩张(channels expansion)、特征图通道融合(channels fusion)和上采样重建(reconstruction)3个模块。向下路径为特征图通道数扩张的过程,特征通道数的增加能保留更多的分辨率信息。网络右侧向上的路径为特征提取和融合的过程,同一层的特征通过跳跃连接进行拼接后将输入到密集残差块中进行特征提取,最终由上采样重建得到高分辨率图像。
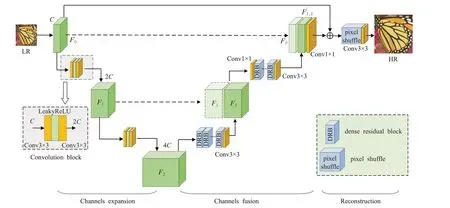
图2 分层特征融合网络框架图Fig.2 Architecture of hierarchical feature fusion network(HFFN)
2.1 整体分层特征融合结构
U-Net 设计之初用于医学图像分割,每层的下采样操作除了增加特征通道数量之外,还会缩小特征图的大小,以减小网络训练的难度。为最大程度的避免分辨率的损失,特征图的大小在图像超分辨率任务中应保持不变。本文算法改进U-Net网络的下采样操作,保持特征图通道扩张路径中特征图大小不变,而只增加特征图通道数量。同时为了减小网络训练的难度,特征图通道扩张操作只进行两次,每一次扩张路径的卷积模块(convolution block,CB)会将特征图的通道数增至上一层的2倍,两次卷积模块操作最终将通道数增加至初始的4倍。
网络首先输入RGB三通道LR图像,初始卷积使用64个大小为3×3的卷积核将LR图像转换为特征通道数为64的粗特征图F0,并在两次向下卷积模块中将特征图通道数量分别增至F1(128层)和F2(256层):

其中,fCB表示卷积模块操作,经过两次fCB后得到特征图F2。
F2送入特征图通道融合阶段,在堆叠的密集残差块(dense residual block,DRB)中进行特征提取。密集残差块的输出经过一次3×3卷积操作将256层特征图融合为128层特征图F′2:

密集残差模块(DRB)结构由多个基础残差块构成,激活函数使用LeakyReLU,具体结构在下节说明。
2.2 密集残差模块DRB
残差学习方法自VDSR 开始就被广泛应用到图像超分辨率重建网络中。为了能够更好地发挥出残差学习的性能,大部分的工作如VDSR和EDSR都是尽可能多的堆叠残差模块。但二者都仅有一段连接全局残差的跳跃连接,特征信息在输入残差块后需要经过漫长的路径输出到网络的末端,连续的卷积层无可避免的造成图像信息的损失,最终影响到图像重建的效果。本文在U 形结构特征图通道融合路径中使用密集连接的残差结构可以有效减少图像特征损失。
残差特征增强框架(residual feature aggregation framework,RFA)是由Liu 等人[24]于2020 年提出的残差块密集连接方案,用以加强局部残差信息的传递。如图3展示了该结构的大体框架。每4 个基础残差注意力模块(residual attention block,RAB)组成一个密集残差块(DRB)结构。前3 个残差注意力块的特征信息会直接输入到DRB 模块的尾部,并且与最后一个残差注意力块的输出拼接,最后通过1×1卷积进行特征融合。相比于简单堆叠的残差结构,局部残差信息在每一个密集残差块中是直接相连的,使其在密集残差块中几乎是无损失的进行传递。密集残差结构的使用除了能够保证网络训练的稳定性,减缓梯度消失和梯度爆炸问题之外,还保证了图像中较为平滑的低频信息在网络结构中能够得到有效的传递,从而使整个网络更注重于图像高频信息的学习,有利于提高最终重建的效果。

图3 密集残差块Fig.3 Dense residual block(DRB)
2.3 ECA模块
图像中的低频信息比较平滑,而高频信息则更多的表征着图像的边缘、语义和其他的细节。但无论是图像的低频信息还是高频信息,在特征通道中都是被同等对待的。不同于文本信息,图像中信息量庞大。一味的堆叠残差块不仅需要耗费巨大的计算资源,而且对最终重建效果的提升也非常有限,无法有效的提高网络的表征能力。为了让深层网络更注重于高频信息的学习,本文在残差结构中插入注意力机制,以增加各通道之间的差异性,增强跨通道的判别性学习能力。
对于图像超分辨率重建任务而言,通道注意力模块的轻量化同样非常重要。为了减轻SENet 中注意力模块的参数量,2020 年由Wang 等人[25]提出的不降维轻量级通道注意力模块ECA(efficient channel attention)改进了SE 通道注意力模块中的全连接层的降维操作,指出降维会损害注意力模块的性能。ECA 改用自适应调整大小的一维卷积核,在提升效果的同时也降低了参数总量。
ECA模块通过对比SE模块的两个变体:SE-Var2和SE-Var3。指出SE-Var2独立计算单通道权重,虽然参数量很少但得到的效果不佳。相反的,SE-Var3 通过单个全连接层(fully connected layer),将跨通道注意力效能提到了最高,但是参数量却非常大。SE-Var2 的参数量为C,参数矩阵为:
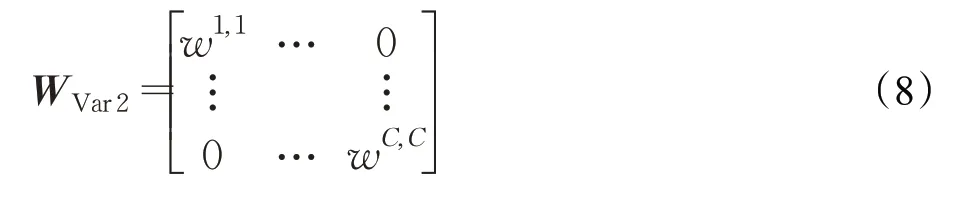
SE-Var3参数量为C×C,参数矩阵为:
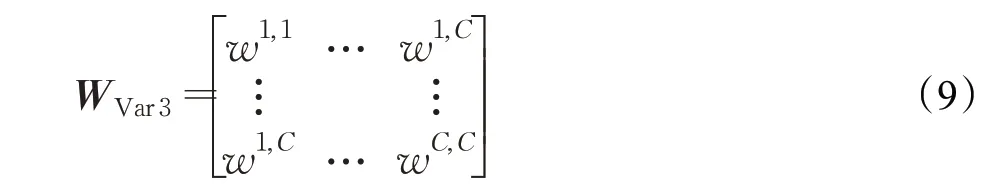
其中,wi,j表示单通道之间的权重参数,WVar3考虑了所有通道之间关系,故而参数量也最大。
RCAN 中使用的通道注意力模块主要由全局平均池化层、全连接层和Sigmoid 函数组成。其结构如图1所示。为了避免出现SE-Var3庞大的参数量,第一个全连接层会降低特征矩阵的维度以减小模型的复杂度,但维度的缩减同时也会损害注意力机制的部分性能。ECA模型就此对降维操作进行了改进:使用自适应调整大小的一维卷积核k代替了SE 模块中的全连接层,只加强相邻通道之间的跨通道信息交流。该结构如图4所示。
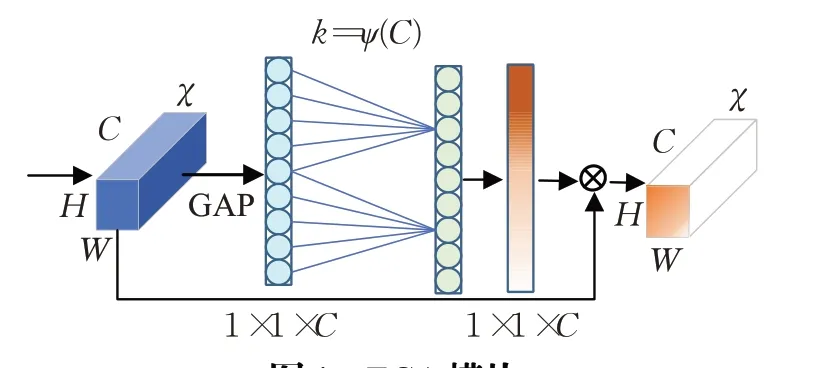
图4 ECA模块Fig.4 Efficient channel attention module
自适应一维卷积的特征矩阵参数量为k×C,特征矩阵表示为:

得益于注意力模块的轻量化,本文算法在每个基础残差模块中都插入ECA 注意力机制,具体插入位置如图3所示。
2.4 亚像素卷积
亚像素卷积层上采样方法由Shi 等人[26]于2016 年在ESPCN(efficient sub-pixel convolutional neural network)网络中提出,其原理如图5 所示。亚像素卷积层会将特征图单个像素的所有通道重新排列,组成高分辨率空间的单个像素区域。首先,LR 图像经过多个卷积特征提取层得到形状为H×W×r2的特征图,并以此作为亚像素卷积层的输入,r为图像的放大因子。该层会将单像素的r2个通道重新排列成为一个r×r区域,对应着HR图像的一个像素点区域,最终得到形状为rH×rW×1的HR图像。
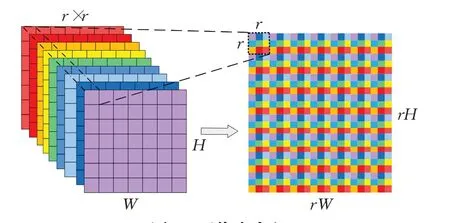
图5 亚像素卷积Fig.5 Sub-pixel convolution
不同于插值法简单的利用图像相邻像素来计算待插像素的值,也不像反卷积上采样中存在大量的补零操作,亚像素卷积并没有涉及到卷积操作,而是一种基于反抽样思想的方法,因而相比于其他上采样方法更高效、快速。加之亚像素卷积是基于学习的上采样方法,有效地避免了过多人工因素的引入,同时也能够减轻了生成图像锯齿状失真等问题。
3 实验与分析
对模型进行验证的实验环境为:Ubuntu18.04LTS操作系统,采用Pytorch1.7深度学习框架,cuda11.1加速学习。实验的硬件设备配置为Intel®Core™i7-10700K@3.8 GHz 处 理 器,16 GB 运 行 内 存,NVIDIA Geforce RTX3080(10 GB)显卡。
3.1 实验数据集准备
本文选用由Xia 等人[27]提出的公开航拍图像数据集,该数据集提供了800×800到4 000×4 000不同分辨率下的大部分航拍场景图,主要包含汽车停车场、飞机场、居民区、运动场、港口、高架桥、农田、高速跑道等。本文实验选取114张涵盖大部分场景的高分辨率图片,将其中100张切割成分辨率为480×480的小图,共计8 234张图片作为网络的训练数据,余下14 张图片作为验证和测试集。相对应的,作为测试集的14 张图片也涵盖了绝大部分航拍场景。
ESRGAN(enhanced super-resolution generative adversarial network)[28]网络通过对比使用DIV2K 数据集、Flickr2K 和OST 数据集训练得到的模型,证明了大规模、内容丰富的图像数据可以有效地提升的网络的训练效果。因此在数据选择时应尽可能的涵盖多个场景,并且在原数据的基础上,采用随机水平翻转、垂直翻转和水平垂直翻转的方式扩增数据集以提升网络训练的效果。
本文实验将输入RGB 三通道的图像数据进行训练。为了得到配对的低分辨率图像,使用MATLAB 对裁切后的高分辨率图像进行双三次插值(Bicubic)下采样。分别得到不同尺度因子(×2、×3、×4)的低分辨率图像,与裁切后的HR图像制作成配对的数据集。
3.2 结构参数
分层特征融合网络的参数设置如图表1 所示。网络训练参数设置如下:训练共计8 234对480×480图像,输入网络后会在480×480分辨率中随机的切出96×96的子图像,每16 对子图像作为一批,共计训练30 万个周期。训练使用Adam优化器,β1=0.9,β2=0.99。初始学习率为10-4,迭代20 万个周期后学习率减半。损失函数为L1损失函数。
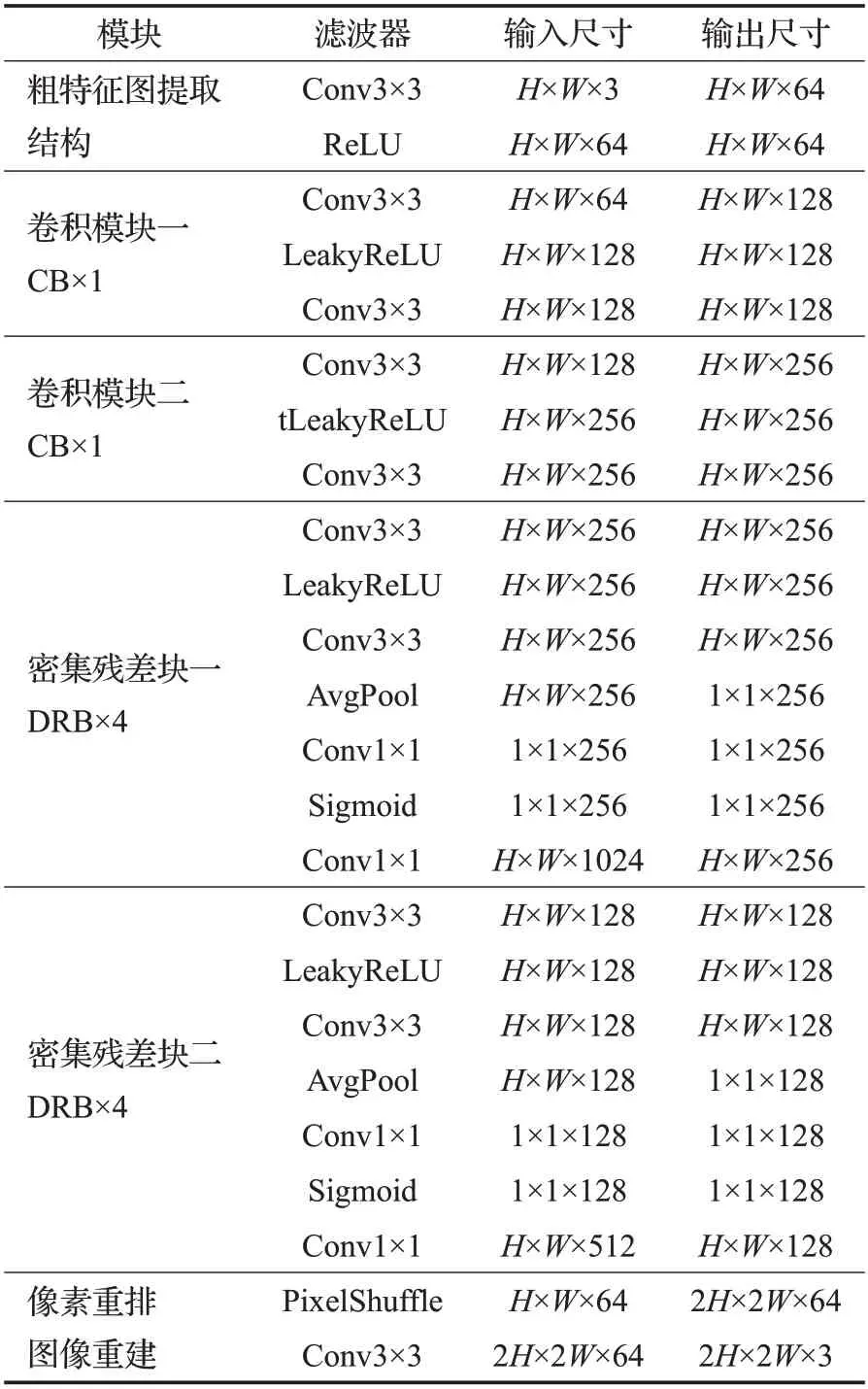
表1 分层特征融合网络的参数设置Table 1 Parameters setting of hierarchical feature fusion networks
3.3 图像重建效果比较
使用峰值信噪比(PSNR)和结构相似性(SSIM)作为主要的评价指标,并且与双三次插值法(Bicubic)、SRCNN、SRResNet、EDSR 网络做对比实验。各个模型输入的初始特征图通道数均为64,在选用的航拍图像当中分别进行训练,迭代次数为30万,其他参数保持原设置不变。实验主要测试算法在不同的航拍环境(飞机场、居民区、海面、高架桥、机场跑道、运动场)中重建的效果。表2 展示不同算法在14 张不同场景测试图片下的平均PSNR/SSIM值。通过对比可以发现在绝大部分场景下,本文方法都优于比较算法。14张测试场景图平均PSNR 值与SRResNet、EDSR 和SRCNN 进行比较,分别高0.18 dB、0.14 dB和2.88 dB。

表2 不同图像超分辨率重建算法在14种航拍场景中的平均表现Table 2 Average performance of different image super-resolution reconstruction algorithms on 14 aerial images
为了测试本文算法在更具体的场景中图像重建效果,现分别在飞机场、居民区、海面、高架桥、机场跑道和运动场六个常见的航拍场景中选择一定数量的测试图片。并分别计算不同算法的平均PSNR/SSIM 值,结果展示如表3所示。可以发现在较为简单的场景(如飞机场和跑道上)EDSR和本文算法在效果上接近。但是在较为复杂的环境(如密集的居民区和港口区域)本文算法有更为明显的优势,尤其是放大因子较大时,相比较于EDSR 重建的效果更好。放大因子为4 倍的情况下,居民区图像重建效果较EDSR高出0.16 dB,港口区域高出0.28 dB。
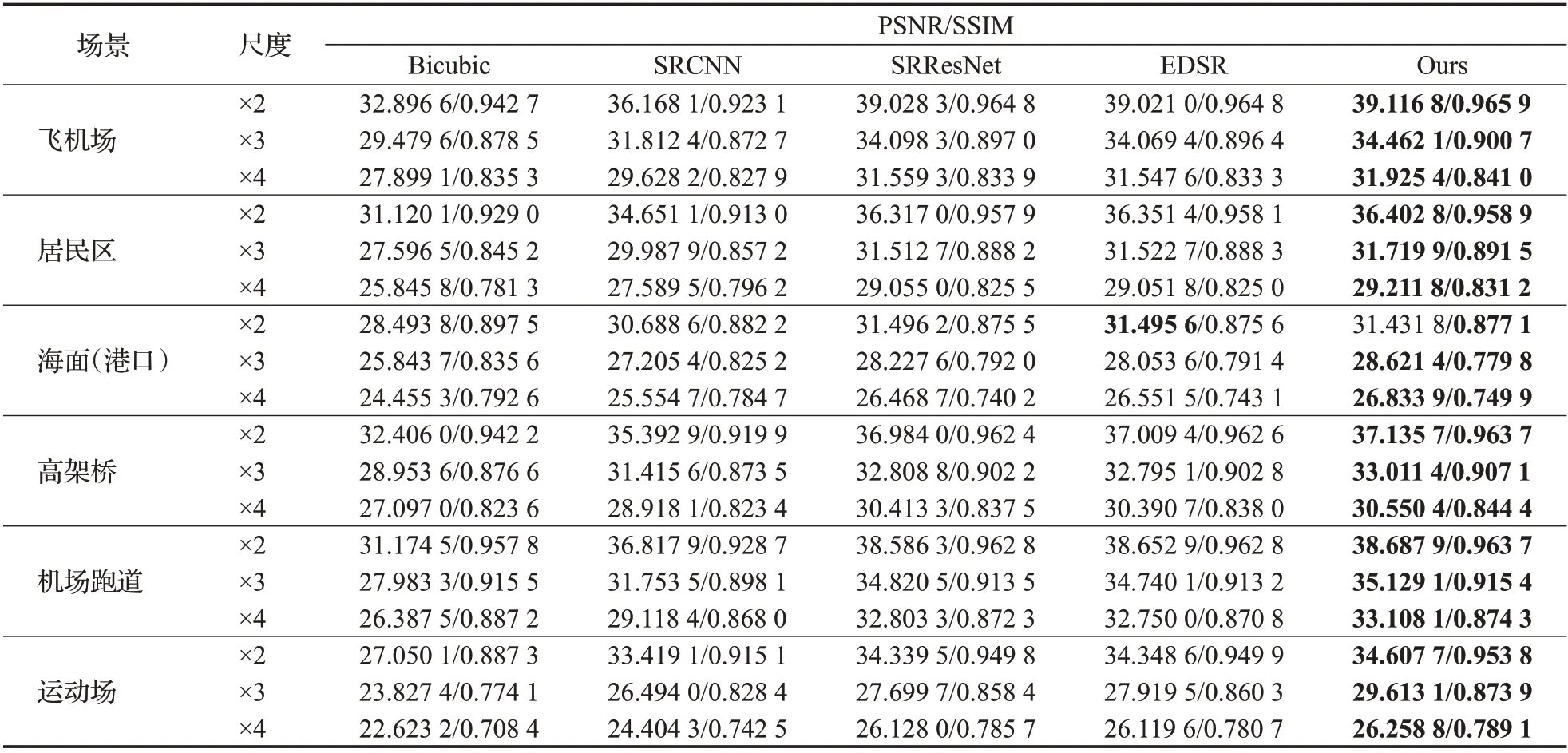
表3 不同图像超分辨率重建算法在不同航拍图像重建中的表现Table 3 Performance of different image super-resolution reconstruction algorithms in different aerial images reconstruction
为了能够更直观地对比各个算法在不同放大因子下重建的效果,现在不同场景中抽取一张测试图片,使用各个算法进行图像超分辨重建。如图6为5个算法在飞机场和运动场中放大2 倍的图像超分辨率重建的最终效果。如图7和图8分别展示了在放大因子为3倍和4倍的情况下,机场跑道、港口、居民区和高架桥上图像重建的主观效果。对比可知在复杂的高架桥环境下,本文算法重建得到的车辆图像边缘更为清晰。

图6 不同航拍场景下×2重建对比Fig.6 Comparison of ×2 image reconstruction in different aerial scenes

图7 不同航拍场景下×3重建对比Fig.7 Comparison of ×3 image reconstruction in different aerial scenes

图8 不同航拍场景下×4重建对比图Fig.8 Comparison of ×4 image reconstruction in different aerial scenes
4 结束语
本文针对图像超分辨率重建在复杂航拍环境中图像特征损失严重,特征利用率不高的问题,结合U-Net分层特征融合的思想,采用更为密集的残差连接块和轻量级特征注意力机制,构建分层特征融合网络。本文算法降低了特征信息在残差块中的损失,加强了局部残差的传递;同时分层结构能够更好保留重建图像的边缘细节信息,减缓深层网络带来的梯度消失和梯度爆炸问题。为了验证算法的有效性,本文实验部分在公开的航拍图像中制作模型训练所需要的数据集,并分别在SRCNN、SRResNet 和EDSR 模型中进行训练。对比实验结果可知,无论是在主观视觉感受,还是在客观评价指标PSNR/SSIM上,本文算法都有更好的表现,有效重建了复杂航拍环境中图像的纹理边缘,成功拓展了航拍图像在其他高级视觉任务中的应用。下一步的工作将对算法进行适应性改进,使模型在不同的环境中有更好的鲁棒性,并降低模型的复杂度,提高网络训练的效率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
心理学报(2022年9期)2022-09-06
计算机仿真(2022年7期)2022-08-22
成都信息工程大学学报(2022年2期)2022-06-14
计算技术与自动化(2022年1期)2022-04-15
心理学报(2022年4期)2022-04-12
北京大学学报(自然科学版)(2022年1期)2022-02-21
时代邮刊·下半月(2020年9期)2020-09-23
上海师范大学学报·自然科学版(2019年5期)2019-12-13
金桥(2018年6期)2018-09-22
