
基于深度学习的脑卒中预测模型的改进*
2022-10-14 13:51宋其江宋佳音
科技创新与生产力 2022年9期
刘 洋,宋其江,宋佳音
(东北林业大学机电工程学院,黑龙江 哈尔滨 150040)
脑卒中是在临床表现上高复发率和高致残率的一类疾病,中国卒中协会发布的研究报告显示,脑卒中已经成为威胁我国国民生命安全的第一大疾病。脑卒中疾病发病快,致死致残率高,一旦发病,对心脑血管损伤严重。对于脑卒中这类疾病,预防大于治疗,如果能够对脑卒中进行及早预防及干预,将会有重要意义[1]。卒中可能随时发生,医学专家知道哪些人最容易发生脑卒中,但是医生不能同时监控所有病人。机器学习模型可以实时跟踪数千名患者,让医生有机会跟上需求。本文通过对已有的神经网络进行参数的改良,提高原有模型的准确率,增加表现模型性能的曲线进而构建一个更加贴切的模型来预测脑卒中的风险。
1 对象与特征
数据集的数据来源是5 111 个身份不同,家庭情况不同的人(数据集及原模型作者是来自索马里的fedesoriano)。他们身体的各项指标和生活习惯也有所不同,5 000 多条数据足以满足训练和验证模型的需要。在他们的身体数据中,被普遍认为和脑卒中有关系,被记录成为特征的如下:ID,性别,年龄,高血压,心脏病,婚姻状况,工作类型,居住地,平均血糖水平,身体质量指数,是否吸烟[2]。研究证明,全球范围内,性别在脑卒中负担比例上没有显著差异,但在低收入和中等收入国家,男性行为风险集群的人口归因分数(PAF)大于女性。随着年龄的增长[3],身体机能也有所下降,卒中的风险也会随之升高,尤其50 岁之后,卒中患病率显著增加。研究表明,BMI 是可归因DALY 最重要的五个风险因素之一,占比23.5%,卒中患者BMI 的DALY 增加比例高达46%,位居第一;高血压是最重要的卒中影响因素[4],它与出血性卒中的相关性更强;心脏病包括房颤、冠心病、瓣膜病和心肌梗死等心脏相关病症,可令缺血性卒中风险增加3.49倍。平均血糖水平是为了更好地显示患者患糖尿病的情况,是正常还是糖尿病前期,还是已经有糖尿病,比简单地分为是否有糖尿病更加具体。很多研究证实,糖尿病是仅次于高血压的重要卒中风险因素,且与缺血性卒中的关系更为密切。在居住地的划分上,所有的研究对象被划分成两种,城市和农村,城市和农村的生活环境有不小的差异,这有可能对卒中造成影响[5]。
2 数据预处理
本文使用的数据库涉及到患者一些身体数据,比起姓名,用ID 来区分不同的人更为合理[6]。为了使数据库的数据能够输入神经网络,本文对数据库中的数据进行了一些预处理。
第一步是数据清理,数据清理可以通过填补空缺值,删除或者解决数据的不一致性来达到清理数据的目的[7]。例如将文中的ID 列删除是为了减少不必要的工作量,因为ID 列仅仅是为了区分不同的健康数据,对于模型数据的训练并没有其他的意义。本研究对缺失数据的处理是用其他数据的平均值来进行填充,这也是最为普遍的一种方法[8]。
第二步是数据规范,数据采集的信息是多样化的,为了其能在神经网络中得到更好的处理,需要将数据的格式统一。在本文中将性别、婚姻状况、住宅类型和吸烟状况的相关信息由字符串形式改为数字形式,便于更好地输入神经网络。将平均血糖水平、年龄、身体质量指数等一些出现连续数值的指标按照一定的医学标准分为几类,再分别对应成‘0’‘1’‘2’这样的数字用来区分不同的身体状况。其中,平均血糖指标“avg_glucose_level”根据美国糖尿病协会给出的标准分为不同的类型。小于或等于100 的值被认为是正常的,大于100 和小于125 的值被认为是糖尿病前期,大于125 的值被认为是糖尿病。
3 神经网络模拟与参数的改变
神经网络模拟是机器学习算法的一种,通过模拟高度复杂、非线性、自适应和并行的人脑系统功能,构成彼此相互连接的神经系统,用来进行复杂的计算和建模。人工神经网络的网络结构是由隐层和隐节点的个数决定的,在对原有的神经网络进行改进的同时也要考虑到网络结构的复杂度和模型的训练效率[9]。如果结构过于简单,学习收敛速度快,不一定达到预想的精度,如果过于复杂,预测原有的神经网络输入层有64 个神经元,由relu 函数激活,由统一的内核初始化,前三个隐藏层的个数分别是32、16、10,所用的激活函数都是Relu 函数,最后的输出层则只有一个神经元,输出层的激活函数是Sigmoid 函数,使用Adam 优化器以0.001 的学习率学习,以5 批大小对该模型进行30 个历元的训练。
神经网络参数改进前后的模型准确率和损失情况见图1。训练成功后,该模型报告的损失值为37.3%,准确率为83.7%。如第103 页图2 所示,本研究对参数进行了相应的调整,增加了神经网络的层数和每层神经元的个数,训练的批次变成了epochs=200,batch_size=15,同时也兼顾了网络结构的复杂度和训练效率,成功提高了模型的准确率。
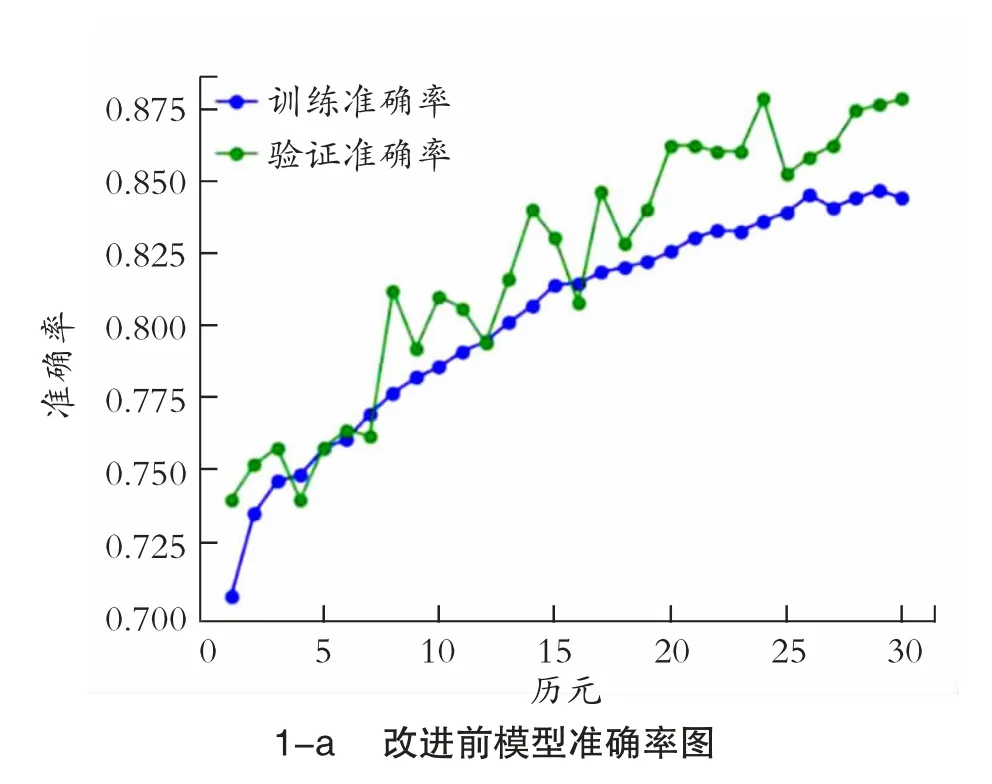
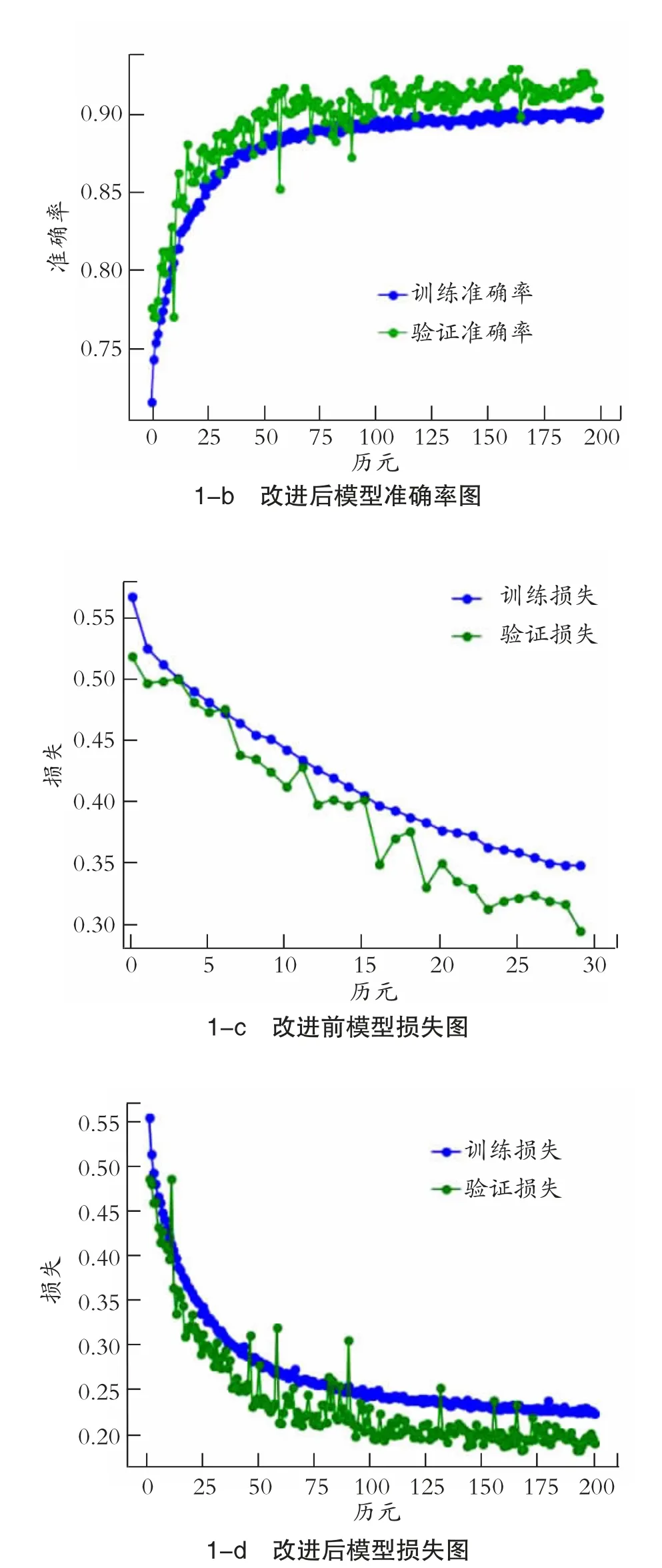
图1 模型改进前后对比图
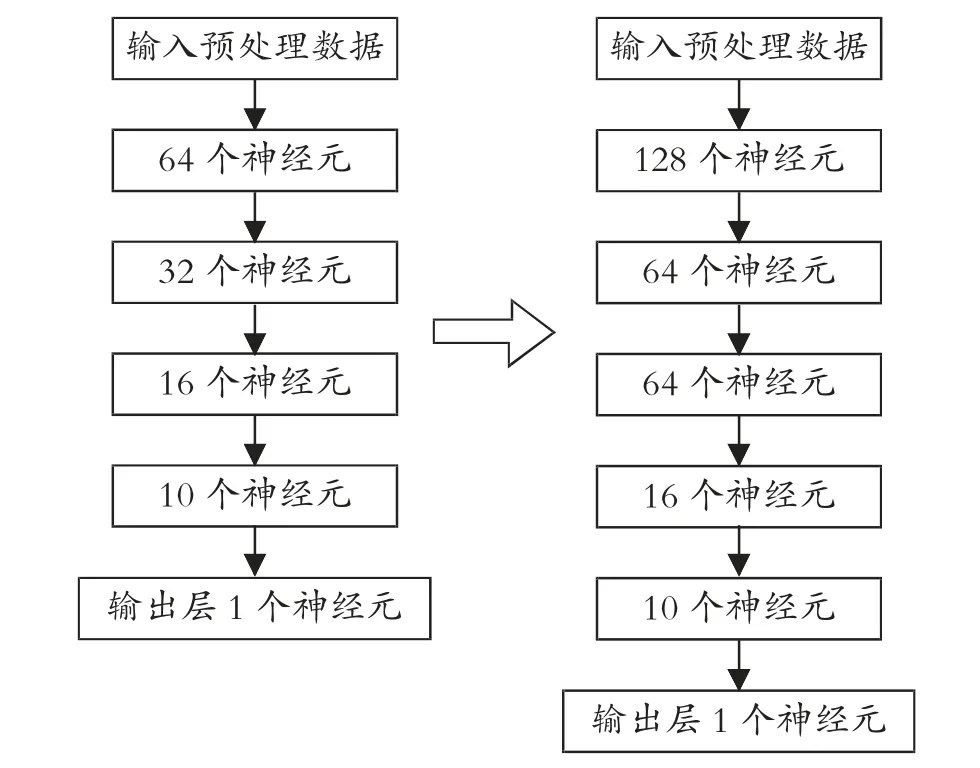
图2 对神经网络参数的改进
准确率是评价一个模型性能的重要指标,是对模型预测准确度的评判标准,即分类模型判断正确的结果占所有观测率的比值,其计算公式为
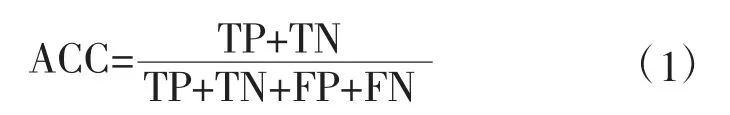
式中:TP 表示正类判断为正类;FP表示负类判断为正类;FN表示正类判断为负类;TN 表示负类判断为负类。
4 增加的ROC 曲线
为了更好地评估模型,本研究增加了ROC 曲线,用图像来更加直观地描述模型的性能。1960 年开始,ROC 曲线开始被应用于医疗领域。ROC曲线是一种比较模型效果坐标图的可视化工具,用来展示灵敏度和特异度之间的相互关系[10]。灵敏度(TPR)是对真实正例覆盖率的测量,指的是观察为正例的结果中,模型判断为正例的比率,公式为
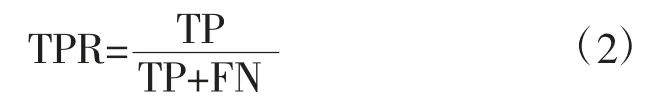
特异度也叫真阴性率(TNR),是对真实负例的预测覆盖面的度量,指观测值为负例的结果中,模型判断为负例的占比,公式为
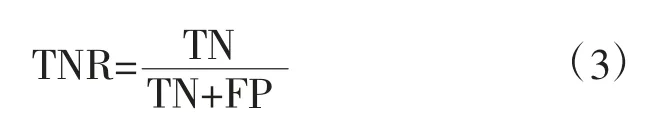
ROC 曲线以灵敏度为纵坐标,特异度为横坐标,通过设定出不同的临界值,得出每个点对应的坐标,最后绘制曲线,通过曲线下面积值(AUC),用来评价模型的准确率AUC 的值越大,证明模型的效果越好。ROC 分析最早在信号检测中出现,作用是选择出最优的信号侦测模型。由于ROC 分析不受成本和收益的影响,所以评估的效果也更加中立。AUC 曲线有两种极端情况,一种是所有样本都正确,AUC=1;另一种是分类几乎没有发挥作用,等价于随机分类,AUC=5,但是实际情况可能是RUC 曲线的值大于0.5 小于1。
此外ROC 曲线能够很好地体现自适应合成抽样对模型的效果,如图3 所示,自适应合成抽样是原有的模型中作者为了处理不平衡类采用的一种方法。这个方法通过插值法创建不平衡类的更多样本来生成合成数据,调整网络参数对ROC 曲线的影响并不大,但是对于体现自适应合成抽样的作用却有很好的效果。
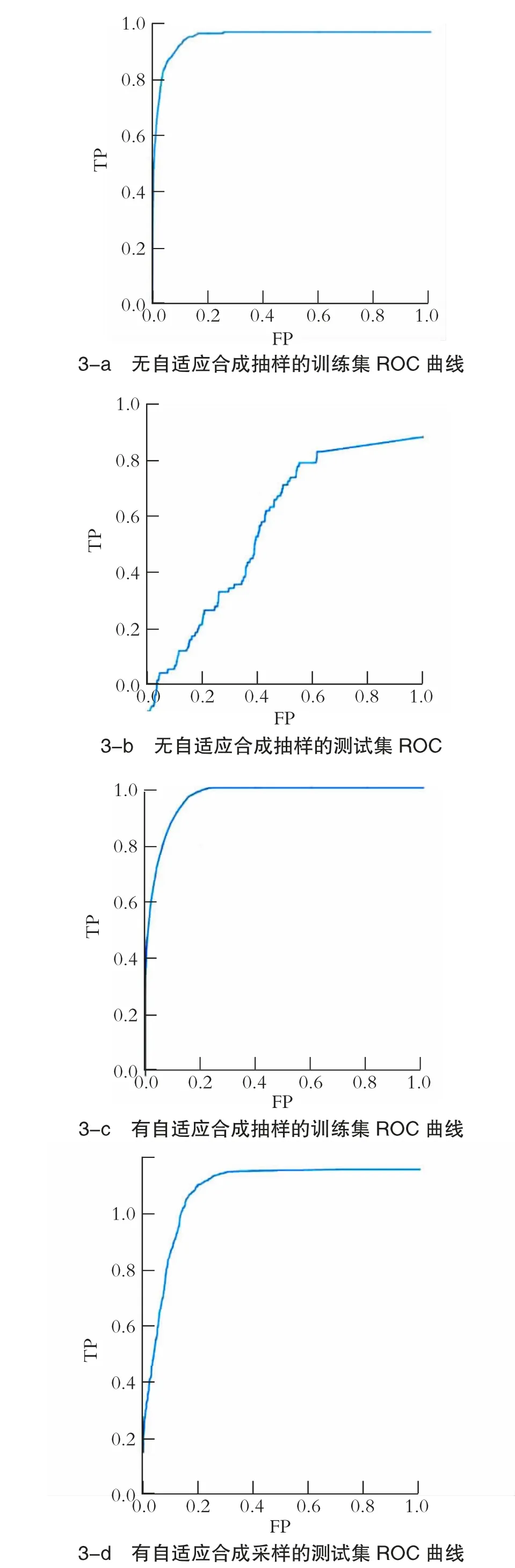
图3 ROC 曲线对自适应合成抽样的体现
5 结论
对于脑卒中这种突发类且伤害大的疾病,现阶段还没有理想的治疗方法,所以是预防大于治疗,有效的预测模型能够更好地保障大众的健康,也让医学知识与深度学习的结合更好地造福大众。已经对脑卒中做预测模型的研究不在少数,本文找到一个已有的神经网络模型,通过调节参数使得模型准确率更高,通过添加AUC 曲线评估模型,使得模型能够更好地预测脑卒中数据。
猜你喜欢
出版人(2022年8期)2022-08-23
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
软件(2017年6期)2017-09-23
Coco薇(2015年10期)2015-10-19
