
Target localization based on cross-view matching between UAV and satellite
2022-10-08 02:56KanRENLeiDINGMinjieWANGuohuaGUQianCHEN
Chinese Journal of Aeronautics 2022年9期
Kan REN, Lei DING, Minjie WAN, Guohua GU, Qian CHEN
Jiangsu Key Laboratory of Spectral Imaging and Intelligent Sense, Nanjing University of Science and Technology, Nanjing 210094, China
KEYWORDS Cross-view image matching;Satellite;Target localization;Template matching;Unmanned Aerial Vehicle(UAV)
Abstract Matching remote sensing images taken by an unmanned aerial vehicle(UAV)with satellite remote sensing images with geolocation information. Thus, the specific geographic location of the target object captured by the UAV is determined. Its main challenge is the considerable differences in the visual content of remote sensing images acquired by satellites and UAVs, such as dramatic changes in viewpoint,unknown orientations,etc.Much of the previous work has focused on image matching of homologous data.To overcome the difficulties caused by the difference between these two data modes and maintain robustness in visual positioning, a quality-aware template matching method based on scale-adaptive deep convolutional features is proposed by deeply mining their common features.The template size feature map and the reference image feature map are first obtained. The two feature maps obtained are used to measure the similarity. Finally, a heat map representing the probability of matching is generated to determine the best match in the reference image. The method is applied to the latest UAV-based geolocation dataset (University-1652 dataset)and the real-scene campus data we collected with UAVs.The experimental results demonstrate the effectiveness and superiority of the method.
1. Introduction
Remote sensing technology has developed rapidly in the last decade or so. At the same time, remote sensing platforms are also growing in a comprehensive manner, such as ground,UAV, and satellite platforms. UAVs and satellites play an essential role in this and are the primary vehicles for acquiring remote sensing images.UAVs have unique characteristics such as mobility and flexibility, stealth, low cost, the richness of information obtained, and comprehensive flight coverage.Information processing,analysis,and recognition technologies based on aerial images from UAVs are widely used in search and rescue,industrial inspection,terrain mapping,precision agriculture,ecological environment monitoring,wildlife monitoring and protection,and other directions. Its related research has also become an important direction of research in the field of image processing, computer vision, and pattern recognition in recent years.Satellite remote sensing images are rich in visual information and play a significant role in the process of target detection, localization, tracking, and surveillance.
Most traditional UAV flight navigation relies on information provided by inertial guidance, GPS, etc.The absence of GPS can lead to unavailable positioning. The accuracy of GPS and the anti-signal interference of GPS often do not meet the needs of modern UAV positioning and navigation. With the development of image sensing hardware and image processing technology, computer vision technologyand artificial intelligence technologyare gradually being introduced into the positioning and navigation of UAVs. More and more UAVs are equipped with image sensor systems combined with artificial intelligence technologies, providing more accurate positioning and navigation information. The potential of image-sensor-based visual localization and navigation is enormous.It can achieve considerable accuracy, reduce the cost of UAV platforms,and replace GPS in case of signal interference unavailability, which is of great practical importance.
The current methods applied to UAV visual localization and navigation are mainly image registration.Specifically,four categories can be described: template matching, feature point matching, image matching based on deep learning, and visual odometer matching. In general, the early visual localization and navigation work of UAVs is mainly intensive or direct matching. The observation of UAV is used as a template for matching in the map. Image matching algorithms such as Sum of Absolute Differences(SAD),Sum of Squared Differences(SSD),and Normalized Cross-Correlation(NCC)are used to compare the similarity of two images or blocks. But their main drawback is a large amount of computation and long computing time.
In 2014, Yol et al.proposed a method to locate UAVs using georeferenced aerial images. They chose to use Mutual Information (MI) to cope with the differences between local and global scene changes.However,their algorithm is complex and computationally inefficient. And the experimental data used are still largely orthophotos, which do not have better robustness for the two types of images with cross-view and significant discrepancies.In 2019,Patelused Normalized Information Distance (NID) obtained from MI to estimate the UAV global pose. However, it lacks rotational invariance between the image to be queried and the reference image.With the rise of artificial intelligence in recent years, deep learning has been applied to various aspects. At the same time, deep learning-based localization research is still in its infancy,mainly because it is challenging to implement an end-to-end localization architecture. In 2017, Amer et al.proposed the concept of deep city signs.They used neural networks to compute characteristics specific to different cities based on their appearance and shape, then compared the features between the query image and the reference image, and finally used the location of the reference image closest to the query image as the UAV location estimation. The shortcoming of this method is mainly that the network needs to be trained on a region-specific dataset before using relocation.In 2018,Nassar et al.combined traditional computer vision with convolutional neural networks. They mainly used feature pointbased matching to determine the location of the UAV.Finally,the query image and the matched map area were further optimized for localization using U-Net for semantic segmentation.The limitations of this method are that the segmentation network is better for segmenting urban areas and requires training on a dataset of flight areas. In 2019, Schleissused a Conditional Generative Adversarial Network(CGAN)based to convert the observed image of the UAV to resemble a geographic map. It was then template-matched to the observed image of the UAV to complete the geolocation task of the UAV. This method uses more cutting-edge techniques, but it assumes the rotation angle and the scale size of the dataset. Thus it lacks model generalization, and it has significant localization errors. In 2020, Zhang et al.combined an edge extraction approach with a deep learning-based matching method to determine the correspondence between two images. The edge-driven matching method is effective for some targets with more apparent contours. But in many cases, the edges extracted from satellite images are intricate. As long as they are disturbed, the extracted edge lines will be incomplete and discontinuous, which will affect the effect of target matching and localization.In 2021,Mughal et al.proposed a complete trainable pipeline to find consistency in neighborhoods by introducing semi-local constraints. A point-to-point matching relationship is established between the template and the prestored map of the target to assist UAV positioning. There are many constraints and convolution operations in this algorithm,and most of the UAV data used in this method are lowpoint front views, which have certain limitations.
In recent years, high-resolution remote sensing image processing techniques have been developed rapidly. Wang et al.proposed a global–local dual-stream architecture based on the Structured Key Area Localization(SKAL)strategy,which has a powerful joint global and local feature representation capability and strong robustness. To address the problem of low detection performance caused by the rapid changes in object scale, rotation, and aspect ratio, Zhao et al.proposed a single-stage detector based on polar coordinates, which effectively improved the accuracy of classification and localization.There has also been some progress in research on matching drone views with satellite views. Zheng et al.applied crossview image retrieval as a classification task to UAV localization and navigation.To reduce the effects of zooming and panning between different views, Zhuang et al.proposed Multi-Scale Block Attention (MSBA) based on local pattern networks. This method improves the efficiency of feature extraction and the accuracy of image retrieval. To compensate for the geometric-spatial correspondence between UAV views and satellite views, Tian et al.proposed an end-to-end cross-view matching method. This method can transform the UAV view image into one closer to the satellite view. It also reduces the burden of network learning during the training process and promotes the convergence of the network. It has the advantage of high matching accuracy on the standard dataset (University-1652).However, the research of algorithms based on matching UAV view with satellite view for localization on real-scene UAV image data is still in the initial stage.
In this paper, we propose a quality-aware template matching method based on scale-adaptive deep convolutional features. Firstly, image pre-processing is performed for the typical interference of UAV images and satellite remote sensing images to eliminate the external influence to obtain the most realistic image information possible. The VGG-16network is trained on the University-1652 dataset and the realscene dataset. The trained VGG-16 network is then used to extract the high-dimensional features of UAV images and satellite remote sensing images, respectively, in which the appropriate feature maps are selected using the scale adaptation method. Finally, the similarity of the two feature maps is calculated. The best matching result is obtained according to the possibility of matching. The area corresponding to the image taken by UAV can be found in the large-scale highresolution satellite image.
The contributions of this paper are as follows:
(1) A quality-aware template matching method based on scale-adaptive deep convolutional feature extraction is proposed to evaluate the similarity between images of different views.By extracting scale-adaptive deep convolutional features,target template images of various sizes can be processed,and the feature extraction process can be simplified. Our proposed method has a large advantage in terms of speed.
(2) The trained model improves the ability to characterize the target object in the real scene as well as the resistance to viewpoint changes, and the performance of the method is not only quantitatively and qualitatively proven on the public dataset(University-1652)but also has some validity and superiority on the real-scene UAV data.
(3) The real-scene UAV dataset is very scarce, and such a dataset is novel and can more effectively and more realistically reflect the in-flight viewpoint condition of UAVs.
2. Method
2.1. Overview
We use the image of the target object captured by the UAV as a template image T ∈Rand the satellite remote sensing image as a reference image S ∈R.The purpose is to find the region corresponding to the template image T in the largescale and high-resolution reference image S,as shown in Fig.1.We use m and n to denote the width and height of the reference image.w and h represent the width and height of the template image. To accomplish this task, we propose a quality-aware template matching method based on scale-adaptive deep convolutional features.The scale-adaptive deep convolutional feature extraction method is described in Section 2.2.Considering the stability of matching localization, deep network feature extraction is combined with the QATM-based image matching method in Section 2.3.
2.2. Deep convolutional feature extraction based on scale adaptation
The VGG network uses repeatedly stacked small convolutional kernels instead of large convolutional kernels. This approach improves the depth of the network and the ability to extract features while ensuring the same field of perception.We use the trained VGG-16network for the template image and the reference image, respectively, to extract the highdimensional features for image matching. The feature extraction method based on Convolutional Neural Network(CNN)is shown in Fig.2,which first requires scaling the input image to a fixed size, e.g., 224 pixel × 224 pixel. Then feature extraction is performed through each layer in the network.
Due to the extremely large amount of pixels in remote sensing images and the fact that most of the feature extraction processes are convolutional operations, remote sensing image processing also keeps increasing the computational and time costs as the depth of the network increases. Moreover, the scale of the target is discontinuous, and scaling its input will lead to the loss of details and affect the matching effect. To solve this problem,we propose a method based on scale adaptive deep convolutional feature extraction.
Different layers in the CNN represent various depth features of the image.We input the template image and the reference image directly to the VGG network without scaling them. Then a suitable target layer is selected according to the size of the template, and feature maps are extracted from the target layer. Each layer in the CNN has a perceptual field,which represents the size of the region mapped on the original image by the pixel points on the feature map output from each layer.The width of the perceptual field for the kth layer is calculated as follows.
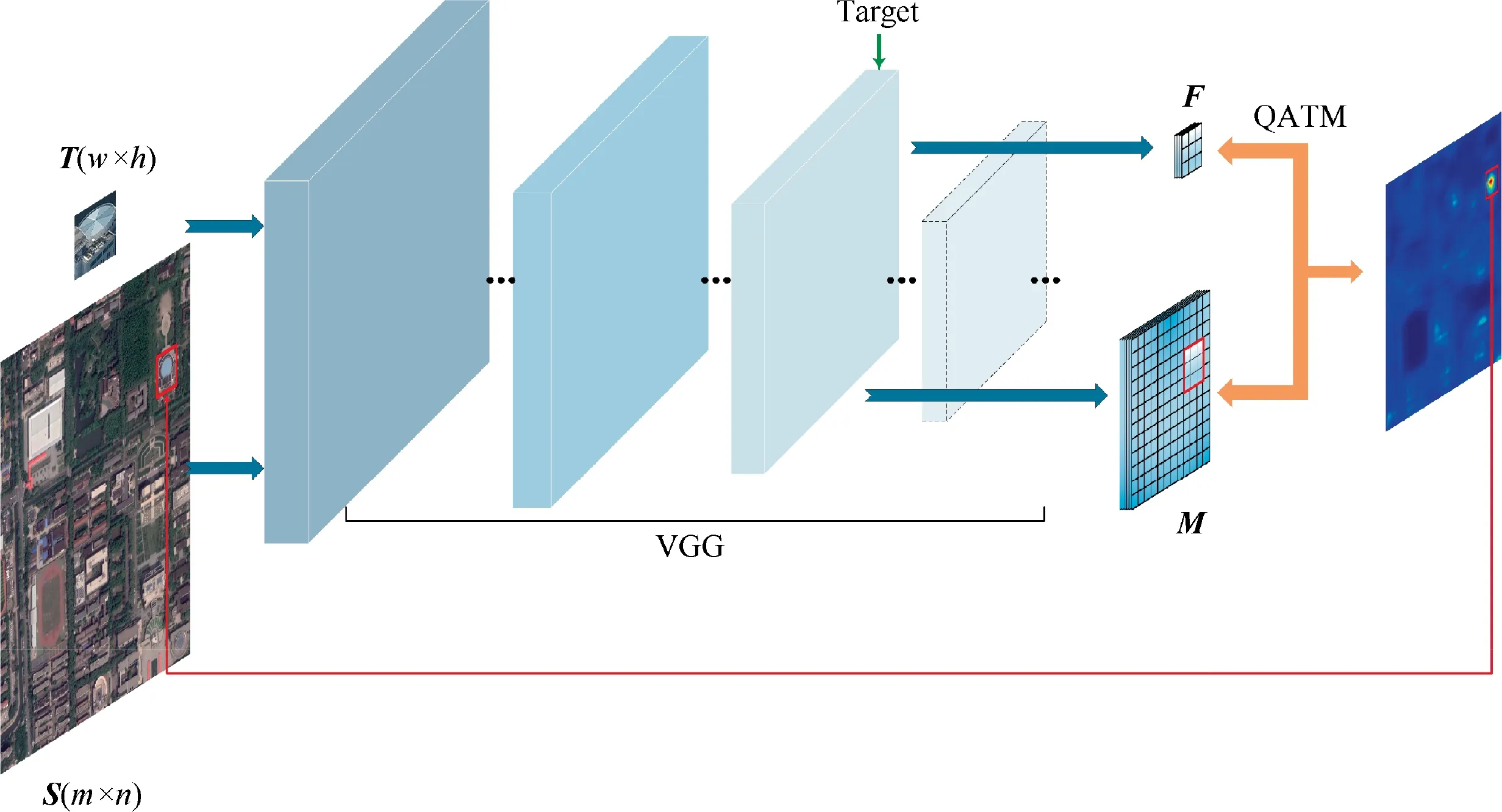
Fig. 1 Overview of feature extraction and template matching.
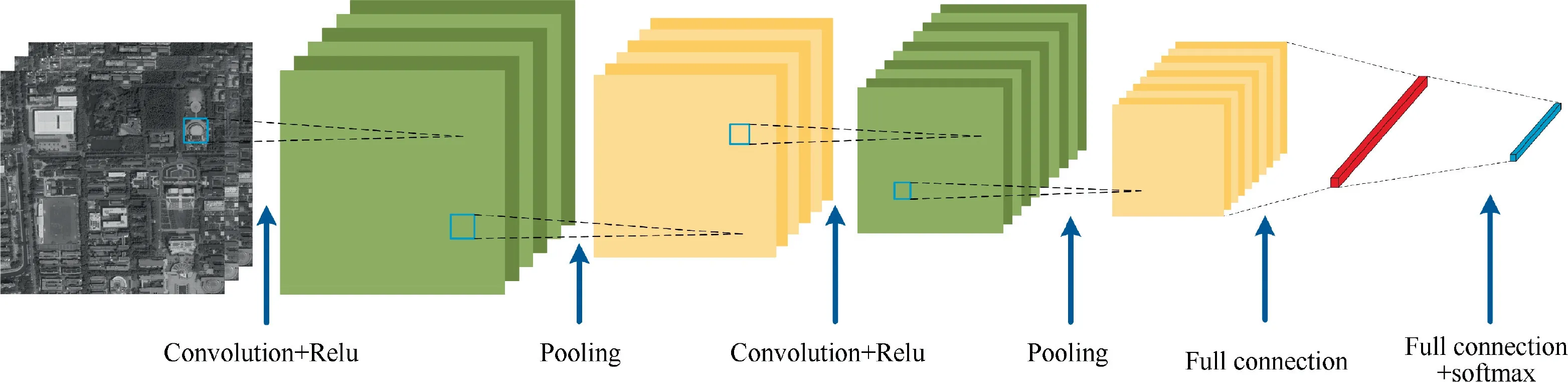
Fig. 2 Convolutional neural network basic structure diagram.
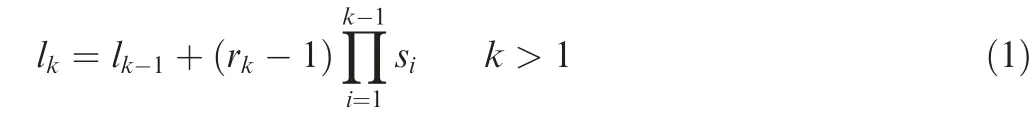
where ldenotes the perceptual field of the(k-1)th layer,rrepresents the filter size of the kth layer, and smeans the step size of the ith layer.When our template size is smaller than the size of the perceptual field of a layer, then that layer will be dealing with a lot of meaningless regions. To a large extent,it will cause a waste of computation.Therefore,the perceptual field of the target layer we choose should be smaller or equal to the size of the template.We choose the kth(k≤k)layer as the target layer for feature selection when l≤min(w,h)is satisfied.For the choice of k, we will discuss it specifically in Section 3.2.1.Then,we input the template image and the reference image into the CNN and extract the template feature map F and the reference image feature map M from the selected target layer.
2.3. Image matching based on quality-aware template matching
Due to the drastic point-of-view changes and directional changes between UAV aerial images and satellite remote sensing images, which leads to large variability in the visual content acquired by both. Some previous template matching algorithms would no longer be applicable.The matching effect of each algorithm will be shown in Section 3.
We first perform scale-adaptive deep convolutional feature extraction on the template T and image S, respectively, to obtain the template feature map F and the image feature map M. Inspired by the literature 33, we use D(b,a) to denote the degree of a good or bad match,where a and b are the image blocks in the template feature map F and the reference image feature map M,respectively.fand fare used to represent the features of image blocks a and b, and ρ is used to denote the cosine similarity between two image blocks. Given the image block b, we use P to describe the matching probability of the template image block a, as shown in Eq. (2).
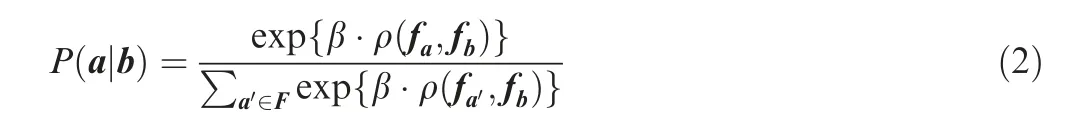
where β is a positive impact factor. a’ is the patch, with the same size as the patch a. By traversing the entire F, this probability P can be interpreted as a soft ranking of the current patch a relative to the remaining patches in the template image in terms of goodness of match,given the search for the patch b.The value of P should be in the range of 0 to 1. A more considerable value of P indicates a better match between the two,which is more similar.Then,D is defined as the product of the probability of b matching in F and a matching in M,as shown in Eq. (3).

Then,according to the correspondence between the feature map and the original image, we can map the feature domain onto the image space. Finally, the value of D is then represented in the form of a heat map using a visualization method so that the degree of good or bad matching at each location can be reflected visually.For this purpose,we can use the best matching region as the matching result and thus complete the task of the target location.
2.4. Model training and optimization
To improve the model network’s ability to represent objects in the real scene and resist perspective changes as much as possible,we can use the pre-training network VGG-16to train the multi-view data of the objects. We blend and classify the acquired real-scene UAV-satellite image pairs with the University-1652 datasetto construct a dataset for model training and optimization. Among them, the target object at each position has a large amount of training data from different views (multi-angle view of the UAV and satellite view).
The UAV multi-view images and satellite view images of the target are scaled to 224 pixel × 224 pixel as the input to the model. A total of 160 epochs were trained. We use some data enhancement strategies during the training process,including random rotation, random cropping, scaling, and color distortion.The loss function is a cross-entropy loss function,and the network is optimized using the Stochastic Gradient Descent (SGD) optimizer with a momentum value of 0.9.The initial learning rate is 0.001, and the learning rate is updated to 0.1 of the current learning rate every 60 epochs.The dropout rate is set to 0.5. The entire model training process is performed on the NVIDIA GPU platform TITAN RTX. In the experimental phase, we use the trained network model to evaluate the similarity between images using a quality-aware template matching method based on scaleadaptive deep convolutional feature extraction.
3. Experiment and analysis
3.1. Experiment setup
In our experiments, we evaluate our method according to the literature.Specifically, 30 videos are selected from the tracking dataset given in.Templates are selected in the first 10 frames of the videos and formed a template-reference image pair with the remaining frames in the videos, respectively.For each pair,we can generate a predicted box in the reference image,which locates the position of the template, as shown in Figs.3(a)and 3(b).Since this tracking dataset contains ground truth data, we perform a quantitative comparison by calculating the value of the Intersection over Union (IoU) of the ground truth box and the predicted box and calculating the Area Under the Curve (AUC).
We also compare our method with previous methods, such as DCIM,A-MNS,SA + NCC,QATM,2ch-2stream,2ch-deep,Siamese,BBS,NCC,SSD,HM.
3.2. Experimental results
3.2.1. Discussion on the choice of target layer
We utilize the trained VGG network for scale-adaptive deep feature extraction.The structure of VGG network is very concise, and the same size of convolution kernel size (3 × 3) and max pooling size (2 × 2) are used throughout the network.We select network layers other than the fully connected and output layers and calculate their perceptual field sizes, as shown in Table 1. The average size of the template image for our validation is 90 pixel × 90 pixel.
First, the features extracted from the template images through each layer of the network are matched with the template features separately, and their AUC performance is analyzed, as shown in Fig. 4(a). By comparison, we find that the conv3_3 layer performs better with an AUC value of 0.67.
Second, for our scale-adaptive feature extraction method,when the size of the perceptual field of the kth layer satisfies less than or equal to the size of the input template image, we take out the feature map of the kth layer (k= k - j) for analysis and verify its effectiveness. When k - j ≤0, let k= 1. As shown in Fig. 4(b), we take the value of j from 0 to 17, and the best performance is achieved when j is 3.And it takes near 3, for example, 2 or 4, and its performance can also be better.
Therefore, we use the (k-3)th layer as the target layer for feature extraction. The adaptive feature extraction method is better than the fixed-layer feature extraction method in terms of overall performance. In addition, based on the average of our selected template image size, it can be determined that k = 12, k= 9. The target layer is namely conv3_3. It is also known from Fig.4(a)that conv3_3 is also the optimal layer in fixed-layer feature extraction.
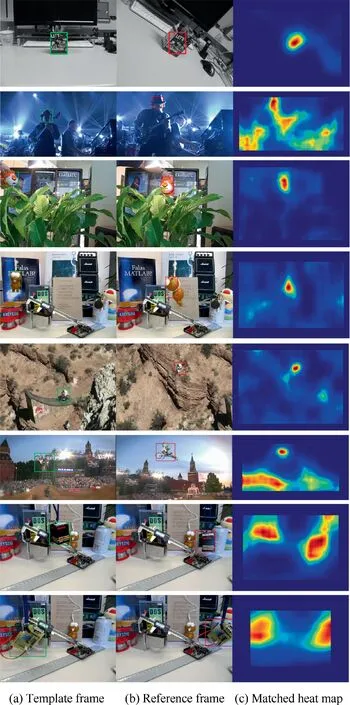
Fig. 3 Detection plots for video frames.
3.2.2. External comparison
We perform some quantitative analyses to demonstrate the effectiveness of the proposed method. First, as shown in Fig. 5(a), through the quantitative analysis of the success curve,it can be seen that the performance of our method is better than the methods in the literature.In the literature,establishing point-to-point correspondence between the template and the reference image for template matching has poor performance for images with large viewpoint transformations. A template matching method with rotational invariance is used in the literature;however,it has poor performance for images in some scenes with changing illumination and motion blur. A convolutional neural network with NCC is applied in the literature.When the transformation between the template and the reference image is complicated,and factors such as occlusion and background transformation are added, the performance of NCC is poor. The purpose of the method in the literatureis relatively clear, using atwo-channel network for matching two image blocks and comparing their similarities.

Table 1 Receptive field size of each layer.
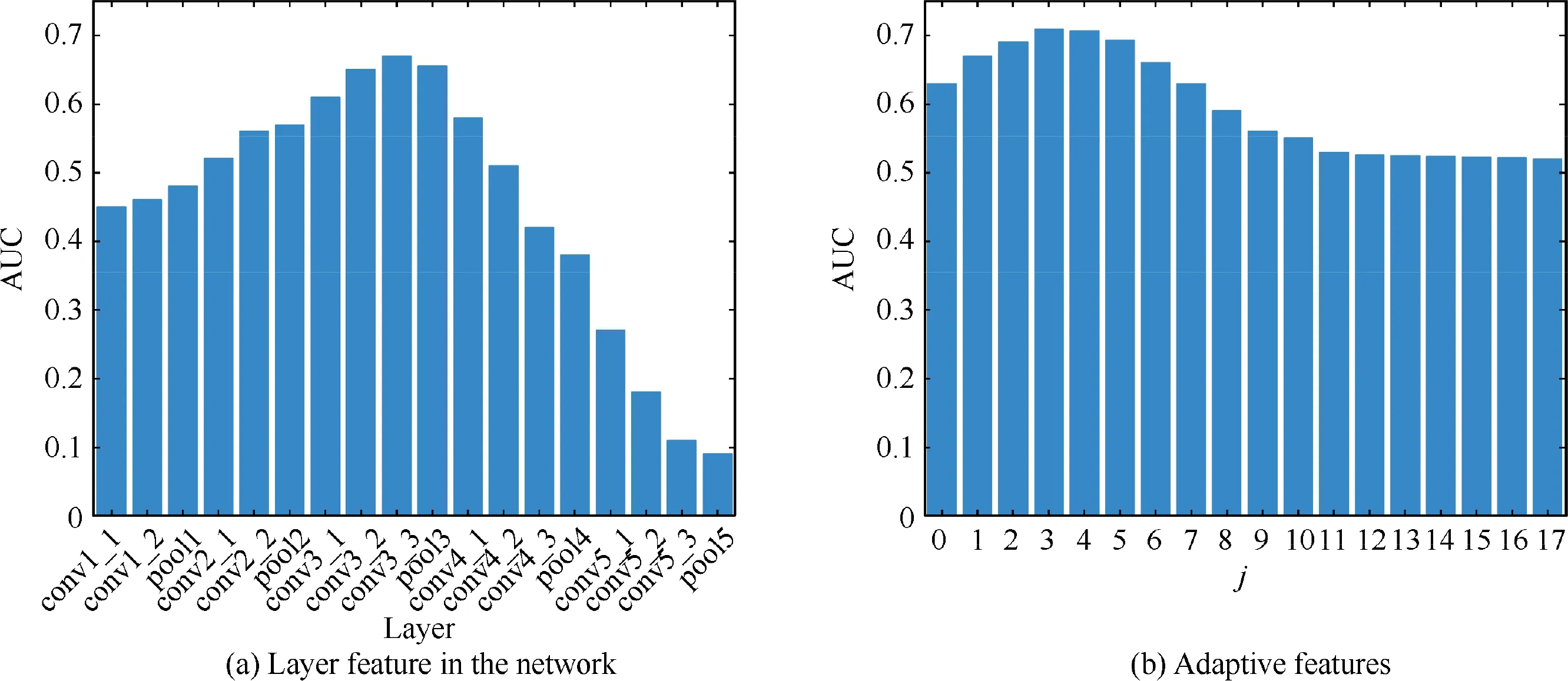
Fig. 4 AUC performance analysis.
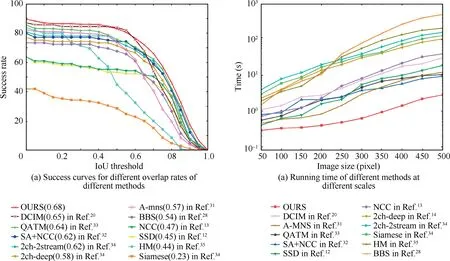
Fig. 5 Performance comparison of different methods.
The matching heat map is generated according to the ranking of matching similarity. As shown in Fig. 3(c), we can also see the quality of the matching results at the moment, where the red color indicates high similarity.

Fig. 6 UAV view and satellite view matching performance test (OURS dataset).
In terms of speed,we analyze and compare the runtime performance of our method with matching algorithms of recent years. We limit the image size to the range of 50 pixel × 50 pixel to 500 pixel × 500 pixel and compare their time differences by running different methods. For the convolutional neural net-based feature extraction methods, the network has many layers, a complex structure, and most of the operations in each layer are convolutional operations. Sliding windows are also used in exhaustive feature extraction, so this type of method generally consumes tens of seconds. In our method,only one feature extraction is performed on the image, avoiding the sliding window operation during exhaustive enumeration. As shown in Fig. 5(b), our method has a greater advantage in large scale images,and it runs significantly faster than BBS(505.3 s), NCC,SSD,QATM,and A-MNS are also in the tens of seconds, and most of the CNN-based methods are in the hundreds of seconds or more.
3.3. Matching localization test and analysis
We use the DJI Phantom 4 Pro to capture UAV images of Nanjing University of Science and Technology with an image size of 1920 pixel × 1080 pixel. We fly the UAV to collect 20 sets of the target object at 150 m-200 m, with a spatial resolution of about 0.5 m-0.8 m,for the validation of the experiment.The corresponding satellite remote sensing image is Google Map over Nanjing University of Science and Technology,with a satellite image size of 2000 pixel × 2000 pixel, covering an area of 1 km × 1 km and a spatial resolution of 0.5 m, as shown in Fig. 6. From left to right are: the template image,the reference image (different colors indicate the matching localization results of different methods), and the matching heat map of OURS, BBS,SA + NCC,QATM,AMNS,and DCIM,respectively.
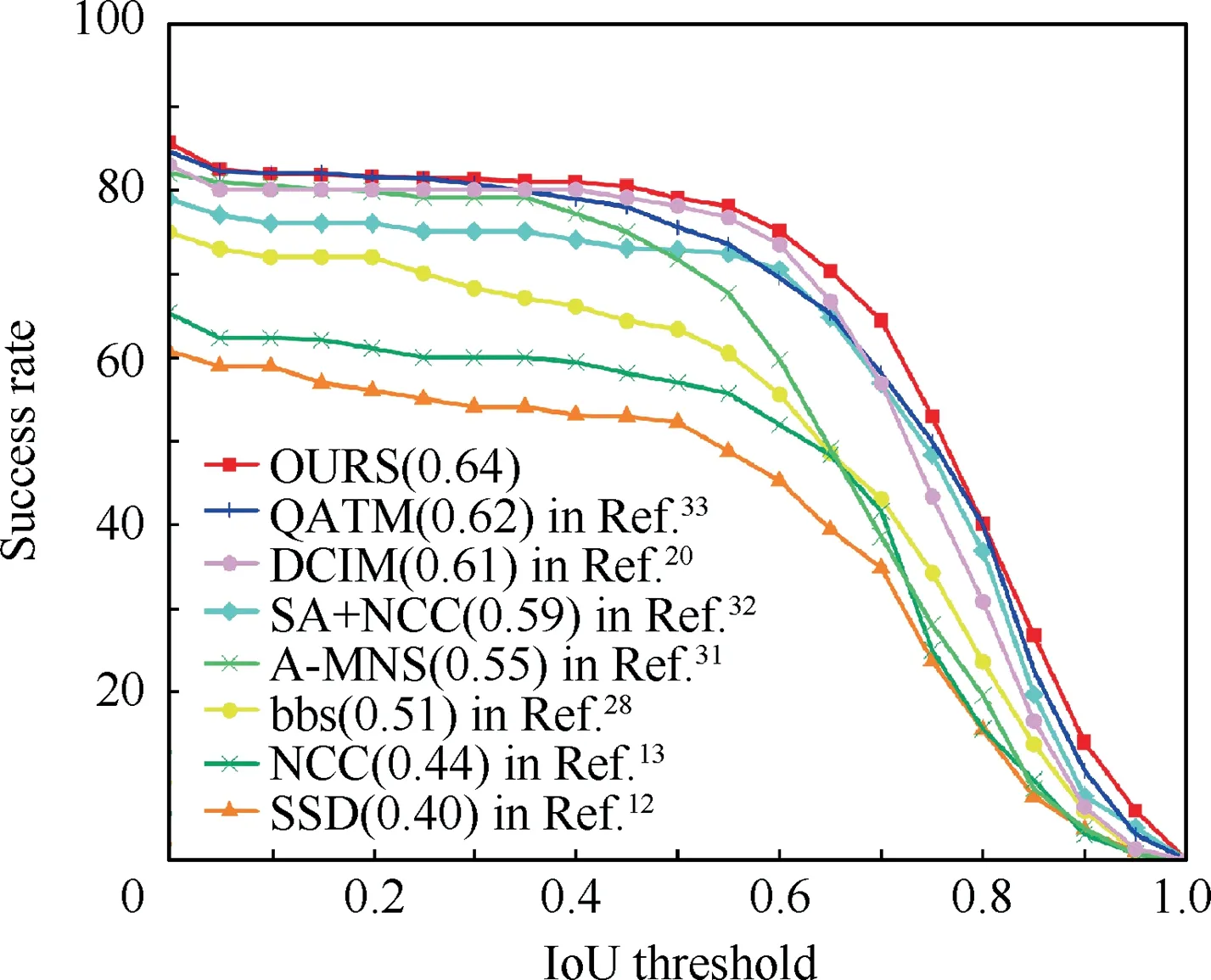
Fig. 7 Quantitative comparison of matching performance.
For large-scale satellite remote sensing images, it is very troublesome to process. First of all, the data information of satellite images is large. Secondly, as a reference image, there is more noise interference, and many traditional template matching algorithms(SSD,NCC,etc.)will result in more computation. They will be exceptionally sensitive to noise when processed. Likewise, we have made a quantitative comparison of this by using the area under the success curve with different overlap rates.As shown in Fig.7,it can be seen from the figure that the AUC value of our method is in the leading position and superior to other methods.
We also select some data from the dataset University-1652 for testing, which is published by Zheng et al.and contains three different views (satellite view, UAV view, and ground view) of 1652 areas. We choose one of the satellite views and UAV views for template matching tests, as shown in Fig. 8.The dataset University-1652 has some limitations in a strict sense. This dataset simulates satellite views and UAV views based on different altitudes.We have tried to select image pairs with large differences in views(the satellite view is vertical,and the UAV view is tilted).In terms of between datasets,the accuracy of our method is slightly reduced compared to the previous tracking dataset, as shown in Table 2. Excluding the poorer matching, the error of localization is within 10 m for a satellite remote sensing image covering an area of 1 km × 1 km.
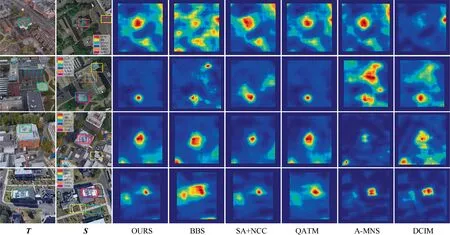
Fig. 8 UAV view and satellite view matching performance test (University-1652).

Table 2 Test performance comparison of tracking dataset and matched localization dataset.
4. Conclusions
The study of UAV image localization without geographic information is of great importance. In this paper, the quality-aware template matching method based on scale adaptive features achieves good results. Experiments on the acquired images verify the feasibility of our method.
The feature maps of suitable template sizes are selected by scale adaptive feature extraction to process templates of various sizes and avoid redundant computation of traversing images. Then quality-aware template matching is performed.The localization of the target in the reference image is determined based on the soft ranking of the matching results.Thus,our method can achieve the task of localizing targets in UAV views in large-scale satellite remote sensing images with geographic information.
Due to the sparsity of real-scene UAV data, we will subsequently expand the scope to test and optimize the UAV view for more regions and scenarios and further improve the stability and accuracy of localization.
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
This study was co-supported by the National Natural Science Foundations of China (Nos. 62175111 and 62001234).
 Chinese Journal of Aeronautics2022年9期
Chinese Journal of Aeronautics2022年9期
- Chinese Journal of Aeronautics的其它文章
- Effect of vortex dynamics and instability characteristics on the induced drag of trailing vortices
- Dynamic modeling and beating phenomenon analysis of space robots with continuum manipulators
- An effective crack position diagnosis method for the hollow shaft rotor system based on the convolutional neural network and deep metric learning
- A homogenization-planning-tracking method to solve cooperative autonomous motion control for heterogeneous carrier dispatch systems
- Static magnetic field analysis of hollow-cup motor model and bow-shaped permanent magnet design
- Adaptive modification of turbofan engine nonlinear model based on LSTM neural networks and hybrid optimization method