
余弦定理在新闻分类中的应用
2022-09-21 07:55卜磊
电脑知识与技术 2022年24期
卜磊
(南京国图信息产业有限公司,江苏南京 210003)
1 概述
新闻分类或者说对于任何文本的分类,都是将待分类的文本与被定义的某类文本做相似度计算。如果相似度很高,那么该文本就属于此类。然而计算机本质上是看不懂新闻的,它只是可以做快速的计算。余弦定理和新闻分类看似也毫无关联,可实际上却有着紧密的联系。本文将阐述如何运用余弦定理让计算机计算出文本的类别。此方法能够快速准确地分类新闻,相比于依靠人工进行文本的编辑分类,将大大提高工作效率。
2 关键词的提取
2.1 分词处理
文章是依靠词语来表达的,同类型的文章所包含的关键词必定是类似的。反之,不同类型的文章所包含的关键词则不太一样。例如财经类新闻,出现频率很高的关键词有:股票、利息、债券、基金、银行、GDP、物价、上涨、同比、环比。而另一些关键词,如明星、电影、档期、喜剧、观众、票房、演员、角色等,几乎不会出现在财经类新闻之中。所以首先需要对文章进行分词处理,从而进一步提取出能够代表此类文章的关键词。
中文分词技术[1]是自然语言处理领域的关键技术,人可以很容易地识别一句话中的词语,但怎样让计算机也能识别呢?所用到的基本方法为分词算法。分词的算法[2]基本可以分成三个大类:基于字符串匹配的分词算法、基于语义理解的分词算法和基于统计的分词算法。按照是否需要和词语的词性相结合,又可以细分为只做分词的方法和分词与词性标注相结合的方法。本文使用Ansj对文本进行分词处理,并且采用单纯只做分词的方法。Ansj 是一个基于N-Gram+CRF+HMM 的中文分词算法,底层是由JAVA 语言实现,属于统计的分词算法,分词速度能够达到每秒200 万字左右。Ansj 目前所具备的功能有:中文分词、词性识别、关键词提取、用户自定义词典、停用词典、自动摘要、关键词标记等功能。可以在自然语言处理等多个方面使用,适用于对分词准确度要求很高的项目。Ansj会对语句进行原子切分和全切分,并且这两个操作是同时进行的。原子是指短句中不可再分割的最小语素单位。例如,一个汉字就是一个原子。全切分的意思是把语句中的所有词都找出来,只要是字典中有的就找出来。例如,“今天天气真晴朗”这就话中所包含的词有:今天、天气、真、晴朗。一个文本可能拥有成百上千个词语,哪些词语能够代表此文章呢?答案是“关键词”。
2.2 提取关键词
正如上文所说,股票、基金、银行、物价等词汇能够代表财经类新闻;明星、电影、票房、档期等词汇能够代表娱乐新闻。这些能够代表新闻类别的词语,称为关键词。假设人们和计算机一样,不理解词语的含义,如何通过统计学的概念来判断某个词语是否为关键词呢。首先想到的是,如果有个词在一篇文章中出现的次数很多,那么这个词相对来说是重要的。可是如果这个词也在其他类别的文章中大量出现,那么这个词就不是关键词,因为其不具有代表性。例如“天气”“周一”“时间”“高兴”等,诸如此类的词在任何文章中都可能出现,所以它们不具备成为关键词的条件。准确地提取出具有象征意义的关键词,对文章的分类有着至关重要的作用。
TF-IDF(Term Frequency-Inverse Document Frequency),即词频-逆文件频率[3]。用于评估某个字或词语对于一个文本库中的其中一份文件的重要程度[4]。字词的重要性和它在文件中出现的次数成正比,但同时与它在语料库中出现的频率成反比。简而言之,一个词语在某篇文章中出现的次数越多,且在所有文本库中出现的次数越少,就越能代表这篇文章。需要注意的是,一篇文章中出现最多的词为“的”“是”“在”这一类最常用的词,以及标点符号。它们叫作“停用词”(stop words),对结果的准确性会产生很大影响,所以在做分词时必须过滤掉。TF-IDF被公认为是信息检索中最重要的发明,在搜索、文本分类和其他相关领域有着广泛的应用。
词频计算公式:

逆文档频率计算公式:
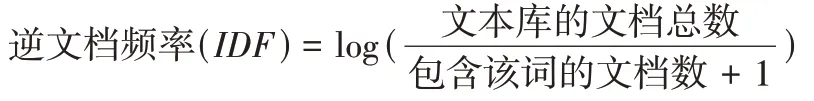
TF-IDF计算公式:
TF-IDF=词频(TF)×逆文档频率(IDF)
本文将新闻分成社会、财经、军事、历史文化、科技、汽车、房产、体育、娱乐、健康十个类别。通过网络爬虫技术爬取相应类别文本各100 篇,建立共1000 篇文章的文本库。通过上述TF-IDF算法计算出每个文本包含词语的TF-IDF值,然后将同类别文本的关键词进行统计,最终得出TF-IDF值最高的100个词,即此类文本的关键词。经过实验验证,此方法获得的类别关键词准确且全面,为下一步相似度的计算奠定了基础。
3 利用余弦定理计算相似度
3.1 获得文本的特征向量
上文中已经获得了能够代表某类新闻的关键词,即此类新闻TF-IDF排名前100的词。例如财经类新闻,100个关键词为【经济,消费,理财,股票,基金,...】。将财经类新闻的特征向量[5-6](Feature Vector)定义为【1,1,1,1,1,...,1,1】。同理可以提取出待分类文章的关键词,然后将此关键词与类别关键词做比对。如果出现在类别关键词集合中,则相应位置特征向量的值为1,否则为0。可能得到的结果是【1,0,0,1,...,1,1】,这样就形成了两个100维的向量。当文本从文字变成了数字之后,就可以通过数学基本定理(余弦定理),来计算两个向量之间的关系,即两个文本的相识度。
3.2 计算向量的距离
余弦相似性指的是通过测量两个向量夹角的余弦值来度量它们之间的相似性[7]。从两个向量之间角度的余弦值可以确定两个向量的距离,即向量所指的方向[8-9]。余弦相似度的值等于1 时,夹角为0 度,表示两个向量具有相同的方向;余弦相似度的值等于0时,夹角为90度;余弦相似度的值等于-1时,夹角为180 度,这时两个向量方向完全相反。在文本分类中,每个词项被赋予不同的维度,而一个维度由一个向量表示,其各个维度上的值对应于该词项在文档中出现的频率。余弦相似度因此可以给出两篇文档在其主题方面的相似性。
假设A向量为【x1,y1】,B向量为【x2,y2】,那么它们的余弦相似度计算形式为:
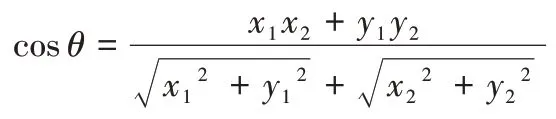
余弦相似度的计算方法对n维向量也是成立的。假定A和B 是两个n 维向量,A 是【A1,A2,...,An】,B 是【B1,B2,...,Bn】,则A与B的夹角余弦值等于:
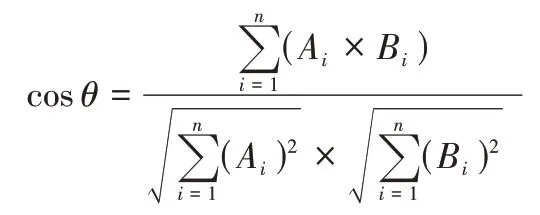
余弦值越接近于1,就表明夹角越接近0度,也就是两个向量越相似,从而得出待分类文本关键词和类别关键词用词越接近。余弦定理就这样通过新闻的特征向量和新闻分类联系在了一起。
4 结束语
本文首先通过网络爬虫技术爬取不同类别的新闻文本,建立文本库。然后通过TF-IDF算法统计得出不同类别新闻的关键词。将待分类文本关键词和类别关键词生成特征向量,通过余弦定理计算出文本的相似度,从而得出新闻的类型。实践证明此方法高效准确,为新闻文本的自动分类提供了一种行之有效的方法。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
中学生数理化(高中版.高二数学)(2020年11期)2020-12-14
中学生数理化(高中版.高考数学)(2020年10期)2020-10-27
河北理科教学研究(2020年1期)2020-07-24
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
智富时代(2017年4期)2017-04-27
智富时代(2017年4期)2017-04-27
中学数学杂志(高中版)(2016年6期)2017-03-01
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
