
基于主成分—马尔可夫链模型的高职院校就业的预测研究
2022-09-21 07:55黄敏菁练佳熠宋伟奇
电脑知识与技术 2022年24期
黄敏菁,练佳熠,宋伟奇
(柳州城市职业学院,广西柳州 545036)
1 概述
2020 年,在新冠肺炎疫情的影响下,国内经济增长速度放缓,就业市场面临严峻的挑战。虽然2021年GDP增长带来了新的就业机会,在一定程度上缓解就业压力,但据教育部公示数据2021年高校毕业生高达909万人,创历史新高。另一方面,国外经济形势持续下滑,留学生回流,导致2021年就业形势也不容乐观。2021年习近平总书记对职业教育工作做出指示,职业教育前途广阔、大有可为。作为高职院校,本就是以就业为导向,为各个岗位输送人才。因此,对毕业生就业情况进行研究,探究影响就业因素并且对就业率进行建模和预测,为高职院校招生就业指导提供参考依据显得尤为重要。
对于高职院校就业率问题,有许多学者进行了研究,针对就业率的预测提出了一些可行的方法。第一种是采用专家系统,通过领域内一些专家对职业院校学生就业特点进行分析,建立职业院校就业率预测的知识专家库,对未来某时刻职业院校学生的就业率进行估计和预测,但这种方法工作过程复杂,对专家库的依赖性高,有很强的主观性[1]。第二种是时间序列进行预测,将就业率看成一个灰色系统,不需要了解影响系统的因素就可以对就业率的变化进行预测,但就业率并非持续增长而是会有波动,单一的灰色系统只可对增长趋势的模型进行预测,且只单一预测出就业率,无法理解具体的影响因素对高校就业指导的作用不大。第三种是利用主成分分析法等模型选出影响就业率的主要因素,将影响因子作为输入,就业率作为输出进行预测[2]。第四种是神经网络,神经网络能够根据输入影响因子,预测出较为精确的数据,但神经网络往往需要大量数据训练才能达到效果,样本量较少会影响神经网络输出的稳定性。
基于现实情况,往往不能提供大量的就业率数据,所以选用第三种方法,运用主成分分析的方法对就业率进行预测。但就业率影响因素很多,且存在一定的随机性和非线性,为了增加模型预测的准确性,利用马尔可夫链模型适用于随机波动大的特点,本文将两种模型对高职就业率进行预测。利用主成分分析建模找出影响就业率的主要因子并进行消除共线性、降维等处理,提高就业率数据预测的效率。在主成分回归模型预测就业率的基础上利用马尔可夫链对预测数据进行修正,建立主成分-马尔可夫链预测模型,提高预测数据的准确率。
2 模型构建
2.1 主成分回归分析模型
主成分回归模型是利用了降维的思想,将在线性回归模型中存在精确相关关系或高度相关关系的一组解释变量,在只损失少量信息的前提下,通过正交旋转变换为一组线性不相关的变量,正交变换后的这组变量就叫作主成分。由此可知,每一个主成分都是由原始变量的线性组合,并且各个主成分之间互不相关。因此通过主成分分析,除了可以降低研究因素的维度,在研究复杂多因素问题时还可以不用考虑变量之间是否相互独立的问题,并且可以通过构造主成分的线性组合探究各个因素间的内部关系。用主成分分析后构造出的主成分作为新的自变量代替原有的因素做回归分析,可提高模型的计算效率,增加模型的可解释性。
主成分回归分析模型构造理论如下:
首先进行主成分构造。设选出可能影响某事物变化的因素有p 个,分别用X1,X2,…,Xp表示,这p 个因素构成p 维的随机向量X=(X1,X2,…,Xp)',其中随机向量X的均值为μ,协方差矩阵为Σ。可对向量X进行线性变换,得到新的p维随机向量Y,即满足下式:
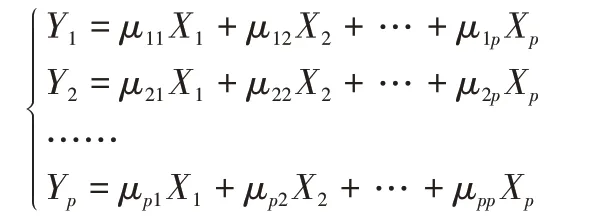
若要进行的线性变换正好为正交变换,即各Yi之间相互独立且变换后的Yi=μ'iX方差尽可能大。并且线性变换要满足以下条件:
(1)μ'iμi=1,即=1(i=1,2,…,p)。
(2)Yi与Yj不相关(i≠j;i,j=1,2,…,p),即cov(Yi,Yj)=μ'iΣμj=0,i≠j。
至此,经过正交线性变换后的p维因素可称为p个主成分,并且消除各因素间的共线性,实现互不相关。若要实现降维,选出理想的主成分就要保留变换后方差最大的主成分,而舍弃方差较小的主成分。即在满足正交线性变换条件(1)的情况下,Y1是所有X1,X2,…,Xp线性组合中的方差最大者;Y2是与Y1不相关的X1,X2,…,Xp的所有线性组合中方差最大者;……;Yp是与Y1,Y2,…,Yp-1都不相关的X1,X2,…,Xp的所有线性组合中方差最大者。可选出前q个主成分作为回归模型的自变量,实现降维的要求[3]。
其次,将选出的q个主成分作为自变量,建立回归模型,进行回归分析。可根据投入模型的主成分个数选择一元回归或多元回归分析,并且可根据因变量和自变量的变化趋势选择线性回归或者非线性回归分析。
2.2 马尔可夫链模型
马尔可夫链是根据现有的状态转移规律,预测未来可能出现的状态模型。在事情发展的过程中,若每次状态的转移都只和前一时刻的状态相关,与过去的状态无关,具有这样属性的随机过程称为马尔可夫链。原理如下:
设{Xn}={Xn|n=0,1,…}的状态空间是I,并且用i,j,l,i0,i1,…等表示I中的状态。如果对任何正整数n 和I中的i,j,l,i0,i1,…,in-1随机序列{Xn}满足:
P(Xn+1=j|Xn=i,Xn-1=in-1,…,X0=i0)=P(Xn+1=j|Xn=i)=P(X1=j|X0=i)
则称{Xn}为时齐的马尔可夫链,简称“马氏链”。这时称Pij=P(X1=j|X0=i),i,j∈I为马氏链{Xn}的转移概率,称矩阵P=(pij)=为马氏链{Xn}的一步转移矩阵,简称为转移矩阵。且转移矩阵P的各行之和等于1,即:
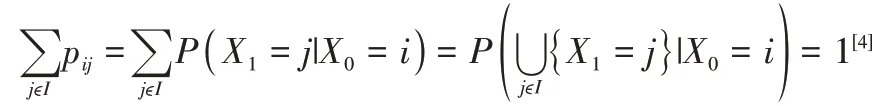
若从随机序列{Xn}中状态i经过一步转移达到状态j的频数为fij,i,j∈I,即有转移概率pij=。将转移矩阵的第j列之和除以各行各列综合所得的值称为边际概率,记为p·j,即满足:
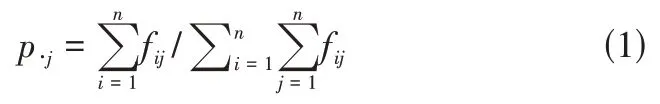
χ2统计量满足:
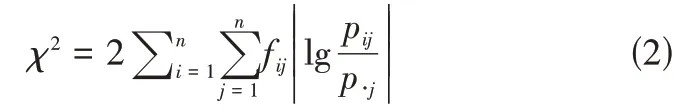
并且服从自由度为(n-1)2的χ2分布。若给定置信度为α,如χ2>,则拒绝零假设,认为序列{Xn}具有马尔可夫性(即马氏性),反之,则这个序列不能作为马尔可夫链处理[5]。
2.3 主成分—马尔可夫链模型
对于主成分回归模型的预测结果,得到的残差具有随机性。可经检验具有马氏性后,运用马尔可夫链模型对残差结果进行修正。设残差序列为e=(e1,e2,e3,…),其中ei=为预测值,yi为实际值。将残差序列划分为k个状态区间,设第i个状态区间为Ei,i∈(0,k]。后计算残差序列的一步转移矩阵Pk×k=。当残差的预测值落在区间Ei时,记[Eil,Eiu]为区间的范围,取区间的均值=(Eiu-Eil)/2 作为该区间的中残差的预测值。并且修正后的预测值为:
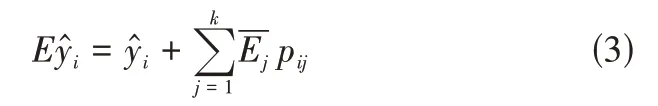
3 模型实证
3.1 数据来源
本文数据来源于选取某高校2015~2020 年共6 年,6 个系部,36个专业的就业率数据。由于高职毕业生的就业范围多是服务本地产业,所以选取的影响因素需要多是从区域范围选取。现从区域经济、区域社会情况和高校三个方面选取影响就业率的相关因素。由于区域经济和社会情况数据获得具有一定的滞后性,所以区域经济选取2014~2019年区域生产总值、各个产业总值及占比、固定投资增速、相关产业固定投资增速作为模型影响因子。区域社会因素选取2014~2019年从业人员单位数、就业人数,相关行业单位数、相关行业从业人员数作为模型影响因子。高校因素方面选取2015~2020年教职工数量、招生人数作为模型影响因子[7]。
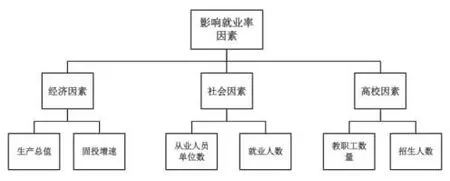
图1 影响就业率因素
3.2 数据处理
本文采用主成分回归分析模型,根据上述选择的影响就业率因素,共有15 个影响因子输入模型。由于各个因子的量纲不同,如果直接使用原始数据会使得量级较大的字段放大对整体的影响,例如生产总值都是亿万级别的数据,若直接投入模型会直接影响主成分的权值。因此,需要对输入模型的数据利用式(3)Z-score标准化处理。

其中,X为原始数据,μ为各输入字段对应的均值,σ为个输入字段对应的标准差,Z为标准化处理后的数据。标准化后的数据输入主成分回归模型默认各个因子之间权重相等,不用考虑因子之间的差异和相互影响。
3.3 主成分-马尔可夫链模型
第一步,将标准化后的输入数据分为两部分,取近两年的作为测试集,其他数据作为训练集。
第二步,输入主成分模型做降维处理。利用Python进行主成分分析。15个影响因子,由于部分因子存在相关性的原因,经运算共有5个特征根。其中有三个成分的累计贡献率较大,可作为主成分。表1 为提取主成分的总方差解释表。可得前三个成分的累计方差百分比已经达到93.67%,方差贡献率高,表示前三个因素所包含的信息量已经占了93.67%,可选前三个作为主成分。分别求出三个主成分的成分矩阵和各因子的特征值。得到由各因子组成的主成分表达式:
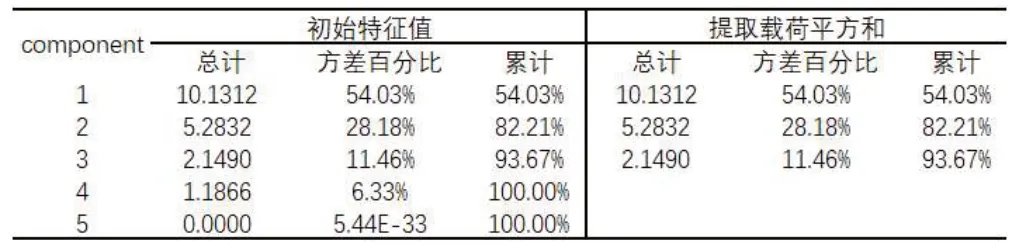
表1 主成分方差总解释表

由以上表达式可见,第一个主成分受经济因素影响比较大,第二个和第三个主成分受相关行业社会因素影响比较大。
第三步,将原数据经过式(2) 的计算得到降维后训练集。现在用Y对训练集前三个主成分做回归分析,得到主成分回归方程。并且计算决定系数,发现模型的拟合效果较好,但个别的样本点预测结果仍有较大误差。
第四步,检验主成分回归后的残差序列{Ye}是否具有马尔可夫性。由上述步骤可计算得到残差Ye的区间范围[-0.0682,0.0772],并且残差值围绕0上下波动,偏离超过5%以上的较少。因此根据实际情况,可将马尔可夫链的状态区间划分为5个区间,得到马尔可夫状态集为:E1=[-0.07,-0.04),E2=[-0.04,-0.01),E3=[-0.01,0.02),E4=[0.02,0.05),E5=[0.05,0.08]。计算残差落在各个区间的转移频数,并计算转移概率,得到一步转移矩阵为:
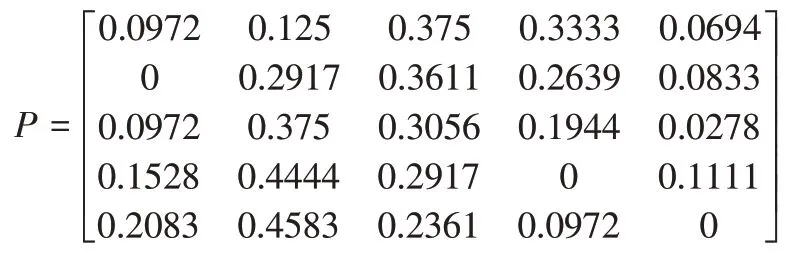
并且经过式(2)计算χ2统计量为44.057,在置信度α为0.05且自由度为16 的情况下=26.296<44.057。故可以判断残差序列{Ye}具有马氏性,可对就业率预测值的残差使用马尔可夫修正。
第五步,对主成分回归的预测结果进行修正。利用式(3)对预测的就业率数据进行马尔可夫修正。以某专业2019~2020年就业率预测为例,得到的结果如表2:

表2 某专业就业率主成分—马尔可夫链模型预测结果比对表
可由表2知,单一的主成分回归模型在对某专业预测的平均绝对误差为4.275%,对全部专业就业率预测的平均绝对误差为2.467%;经过马尔可夫修正后的某专业就业率预测的平均绝对误差为2.82%,对全部专业就业率预测的平均绝对误差为1.333%。由此可知,马尔可夫修正主成分回归模型大大提高了预测的准确率,使得修正值更接近实际值[8]。
4 结论及建议
4.1 结论
本文以某高校2015~2020 年各专业就业情况为例,结合主成分回归模型和主成分——马尔可夫链模型,将区域经济情况、行业情况和高校情况作为输入指标,对就业率进行预测。针对两种预测模型的比较,经过马尔可夫链修正后的主成分回归模型预测就业率的精度更高,能有效减小预测数据与实际数据之间的差距,可为学校对未来招生就业政策的制定提供可靠的依据。并且由主成分回归模型可得知影响高职就业率的主要因素是经济因素和行业情况。
4.2 建议
高职院校的就业率受各方面因素影响,除了学校方面需要努力外,总体来说,受区域经济和行业发展情况影响更大。在此情形下,学校若想提高就业率还得回归职业教育的初心,以就业为导向,把握行业发展的脉搏。专业的设置应该符合现在社会的发展和需要,对于专业的设置不能一成不变。并且学校的人才培养方向要根据区域发展的需要,为区域企业输送人才,同时也为学生创业提供孵化条件,扶植区域企业的发展,达到互利共赢。
同时,在教学过程中的专业技术应该与时俱进,加强产教融合、校企合作,深入企业了解行业的前沿技术和发展动向,教学内容应该及时根据市场岗位所需技能的主要方向而调整。以此提升学生的质量和在就业市场上的竞争力。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
数学理论与应用(2016年3期)2016-05-17
核科学与工程(2015年3期)2015-09-26
哈尔滨师范大学自然科学学报(2015年1期)2015-04-19
河南科技(2015年8期)2015-03-11
新闻前哨(2014年11期)2014-12-25
职业技术教育(2014年9期)2014-07-08
教育与职业(2014年34期)2014-04-17
