
聚类感知的文本多标签分类模型
2022-09-21 12:02赵金榜秦绍伟
云南大学学报(自然科学版) 2022年5期
赵金榜,秦绍伟,武 浩
(云南大学 信息学院,云南 昆明 650500)
人类社会进入信息时代以后,文本数据开始了爆发式的增长,这些文本中包含着大量有价值的信息,但由于文本信息的非结构性,对其组织和有效利用面临着很大的困难.文本分类是指根据文本从给定的标签集合中选取出合适类别标签的过程,对其后续的处理具有很重要的现实意义.对文本的分类有人工分类和自动分类两种方法,人工分类通过人工阅读对文本标注,虽然有高质量的分类结果,但费时费力成本较高;自动分类使用人工智能技术批量快速的对文本进行分类,逐渐成为研究热点.
随着文本自动分类技术在学术界和工业界的广泛研究和使用,众多的方法被应用到文本多标签分类中,包括一对多模型[1-2]、嵌入模型[3]、基于树的模型[4-6]和深度学习模型[7-19]等,其中深度学习由于具有强大的拟合能力,在多标签分类中取得了显著的成果,如卷积神经网络[7]、递归神经网络[8-9]、多重注意力网络[10]、预训练模型[11]等.在深度神经网络的基础上,进一步利用文档和标签的隐含线索可以提升模型的分类性能[12-14],深度神经网络结合降维等方法可以处理大规模数据集[15-16],深度神经网络结合注意力机制在文本分类中表现出了优异的性能[17-19].通过自适应的特征聚集加快模型的分类速度,这些模型对文本分类问题的建模主要集中在文档的词和标签关系之间,缺乏对文档多义性的关注,只获取单一文档特征表示.文本多义性指的是文本中的线索在不同的语境中具有不同的含义,如“苹果”一词既可以指水果也可以指科技公司,在不同的语境下使用同一种特征表示文档里的线索是不合理的.
为此,本文从文档中词语的多义性出发,构建了聚类感知的文本分类(Clustering Perceptual Text Classifier,CPTC)模型.利用注意力机制提取多个文档语义特征,用于建模文档在不同语境下的不同特征,然后将这些不同特征和标签的嵌入交互,充分挖掘文档和标签之间的线索.在4 个数据集上进行实验,结果表明该方法是有效的.
1 相关工作
文本多标签分类由于其重要的现实意义,长时间以来一直是学术界和工业界的研究热点.目前主流的分类方法按照对文档和标签的建模方法可以分为两类,第一类是基于分类器的方法,直接利用文档−标签的关系,将文档的稀疏表示转换为稠密向量,然后通过构建多个分类器进行分类;第二类是基于嵌入的方法,结合标签和文档的特征以挖掘文档和标签的全局关系,将文档和标签做嵌入表示,利用文档标签之间的关联进行分类.
基于分类器的方法:文献[7]最早使用卷积神经网络(Convolutional Neural Network,CNN) 提取文档特征,CNN 通过权值共享减少了参数的数量,训练速度较快,但卷积和池化的操作忽略了文档中词的语序信息.相比于CNN,循环神经网络(Recurrent Neural Network,RNN)被更广泛应用到文本分类任务中,如长短期记忆网络[8](Long shortterm memory,LSTM),基于LSTM 的门控循环网络[9](Gate Recurrent Unit,GRU)等,循环神经网络可以对序列内容建模,优点是捕获了词语在时间维度上的关系,可以带来更好的分类效果,但通常需要训练的参数更多,容易出现梯度消失和梯度爆炸的问题.上述基于分类器的方法只建模了文档到标签的直接映射关系,而忽视了标签自身信息的利用,因此分类的效果仍有提升的空间.
基于嵌入的方法:文献[11]使用卷积神经网络提取文档特征,并将标签做嵌入表示,结合标签信息进行分类,可以处理大规模文本分类任务,但仍然存在对文档和标签的隐含关系利用不充分,分类效果一般的问题;文献[12]将单词和标签嵌入到同一个空间,使用单词和标签的共同嵌入表示文档,建模了词和标签的隐含关系,但是在标签数量较少时不能最大化利用标签的信息,影响分类性能;文献[13]在文本编码器的基础上增加对文档和标签互信息矩阵的分解,实现了对文档和标签的协同表示学习,能有效捕获文档和标签之间的关系,但带来了计算量的增加;文献[14]分别对文档和标签使用嵌入表示,其中标签的嵌入为构成标签的词的嵌入向量的平均,通过相同的词向量建模了文档和标签的关系,但是标签的语义嵌入不能很好地反映标签和文档的共现关系.以上这些嵌入方法利用标签信息做嵌入表示,增强分类效果,但仍然缺乏对文本内不同词多义性的关注,只能获取单一的文本特征表示.
2 聚类感知分类模型
对原始文本和标签的处理是提升文本分类效果的关键.一方面通过构建合理的模型,可以较好地建模文档的特征,如RNN 相比于CNN 可以更好地建模词的时序关系;另一方面是通过对标签进行嵌入表示,更好地利用标签语义信息进行文本分类.本文从文档中词语的多义性出发,建模文档在不同语境下的不同特征表示,具体做法是引入多个簇心向量,使用注意力机制[20]为句子中的每个词分配不同的权重,代表词在不同语境下受到的不同关注程度,从而得到文本在不同语境下的特征.同时将标签做嵌入表示与得到的文本增强特征点乘进行预测,其结构如图1 所示.
图1 中,{w1,w2,···,wn}是一个文档里词的序列,E是词的嵌入向量,H是嵌入向量经过双向GRU 网络输出的词的隐含向量,d是词的隐含向量H通过自注意力模块后得到文档的原始特征,{c1,c2,···,ck}是k个簇心向量,词隐含向量通过Bahdanau 注意力机制在簇心向量的影响下,得到文档在k个簇下的特征 {s1,s2,···,sk},S是这些特征的组合,dc是组合特征S通过自注意力机制得到文档的聚类感知特征.d′是文档原始特征与聚类感知特征融合后的增强特征.{t1,t2,···,tm}是 所有的标签序列,T是标签嵌入的组合,{p1,p2,···,pm}是对标签的预测概率.
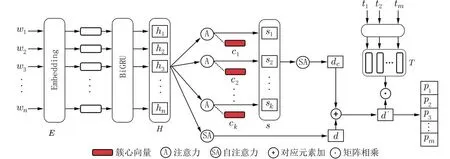
图1 聚类感知模型结构Fig.1 The structure of clustering perceptual mode
2.1 文档原始特征提取本文基于深度学习模型,将词的嵌入向量通过双向GRU 网络和自注意力模块生成文档的特征.词的序列 {w1,w2,···,wn}经过嵌入层获取词的向量表示E,嵌入层使用GloVe[21]进行初始化,其中不在GloVe 词表中的词被表示为随机初始化的向量.将词嵌入表示通过双向GRU 网络得到文档的词的隐含向量H,将H中的多个隐含特征通过自注意力机制加权平均得到文档原始特征表示d.
2.2 文档的聚类感知特征提取为了生成文档在不同语境下的特征,引入簇心向量{c1,c2,···,ck},作为Bahdanau 注意力机制的查询向量,注意力机制的作用是为文档中的每一个词的隐含向量分配权重,加权平均后得到文档的一个特征向量.本文引入多个不同的簇心向量,多次使用注意力机制为文档中的词分配权重,簇心向量作为注意力机制的参数,不同的簇心向量会导致注意力机制每次为文档中相同的词分配的权重是不同的,代表了在不同的语境中对词关注程度的不同.在反向传播中自动更新簇心向量的值,实现语境的自动提取,每个簇心就是一个语境,达到了聚类感知的效果.簇心向量的个数是超参数,人为指定,其向量的初始值采用随机初始化的方式获得.经过注意力机制整合后,文档的特征被重新整合为多个关注不同语境的新特征 {s1,s2,···,sk},其公式如下:
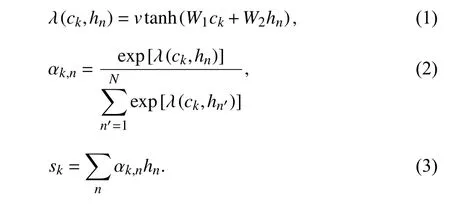
式中,ν、W1、W2是Bahdanau 注意力模型中的权重参数,通过反向传播自动更新,αk,n是文档中词的隐含向量hn在 簇心向量ck上的权重,将文档中词的隐含向量hn和权重 αk,n相乘再求和,得到每个词在簇心上的新特征sk.设定簇心的数量k,可以得到文档在k个语境下的不同特征表示,将这k个不同特征组合在一起得到组合特征S.
2.3 标签嵌入与文档特征交互为了方便和标签的嵌入表示交互,使用自注意力机制将组合特征S转换成文档的语境特征dc,自注意力的实现方式如下:

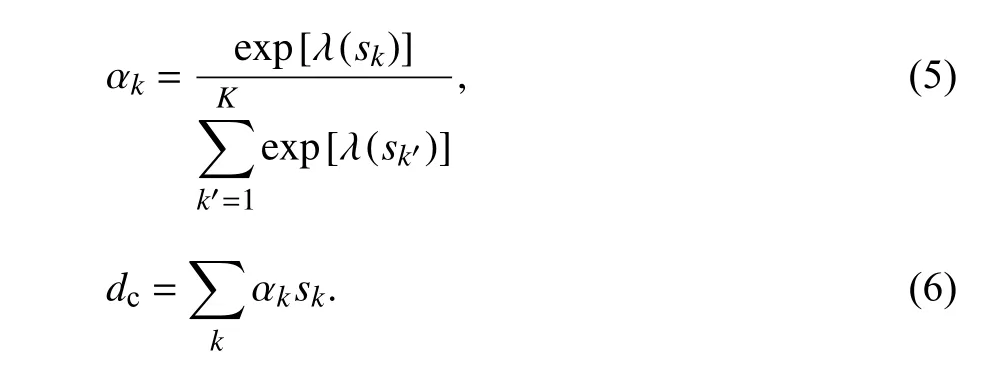
式中,ν、W、b是自注意力的参数,通过反向传播自动更新,αk是特征sk的权重,将公式(3)中求得的组合特征sk和 其对应的权重 αk相乘再求和,得到代表文档在不同语境下的特征dc,同时将文档通过RNN 网络得到的特征H通过同样的自注意力网络得到文档原始特征d,将文档原始特征和文档不同语境下的特征相加,得到文档的最终特征d′,其公式如下:

将所有标签 {t1,t2,···,tm}通过标签嵌入层得到标签的嵌入表示特征T,将文档和标签的特征矩阵点乘得到标签的预测矩阵P,其公式如下:

得到标签的预测矩阵后,获取预测值最高的N个标签,作为模型对标签的预测输出.
2.4 损失函数模型的输出是对每一个标签的预测值,使用二元交叉熵损失(Binary Cross Entropy Loss,BCE Loss)计算损失,其定义如下:
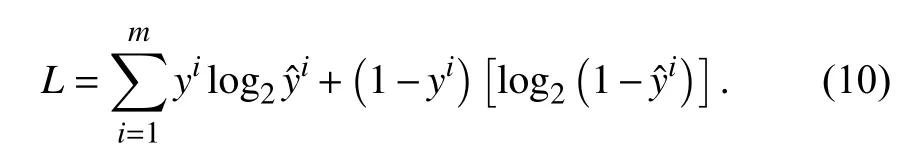
式中,yi是标签的标注值,若标签ti属 于该文档则yi为1,否则为0,是模型对于标签ti是否属于该文档的预测值,得到损失之后,模型优化的目标是最小化该损失值,在反向传播中优化方法使用自适应矩估计(Adaptive moment estimation,Adam)优化器.
3 实验结果与分析
3.1 实验数据集实验中,采用文本多标签分类中常使用的Reuter、PW-20K、CiteULike-t 和Eurlex,其中Reuter 数据集是1987 年路透社新闻的集合,其文档由路透社有限公司的人员按类别进行汇编和索引,它被广泛应用于文本分类的研究领域[22];PW-20K 是从ProgrammableWeb 网站中搜集的,作为全球最大的Web API 在线注册网站,其记录了超过20 000 个开放Web API 和数千个应用程序;CiteULike-t 数据集是Wang 等[23]从CiteULike网站和谷歌学术中收集,其中每一篇学术文章都有摘要、标题和标签,数据集中文档和标签关系非常稀疏,包含许多重复的标签,通过删除低频率标签、识别重复标签来预处理数据集;Eurlex 数据集[24]是欧盟法律的集合,数据集中使用EUROVOC 描述欧洲法律不同方面的主题层次结构.各数据集的参数如表1 所示.

表1 实验数据集参数Tab.1 Parameters of experimental dataset
3.2 参数设置实验中会影响到模型性能的超参数有文档和标签嵌入维度、簇心数量、学习率和文档最大长度,本文采用的设置如表2 所示.

表2 CPTC 模型使用的超参数情况Tab.2 Hyperparametric conditions used by CPTC model
3.3 评价指标文本多标签分类常用的评价指标有精确率(Precision)、召回率(Recall)和归一化折损累积增益(Normalized Discounted Cumulative Gain,NDCG),从不同的维度评估算法性能.
精确率是指模型预测正确的标签数量和模型预测出的所有标签数量的比值,用于评估正样本结果中的预测准确程度,计算方法如下:
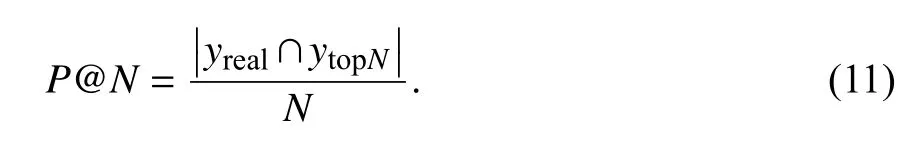
式中,N为推荐序列的长度,yreal是文档对应的真实标签序列,ytopN是模型推荐的前N个标签的集合.
召回率是指模型预测正确的标签数量和真实标签数量的比值,用于评估模型对正确标签的覆盖程度,计算方法如下:
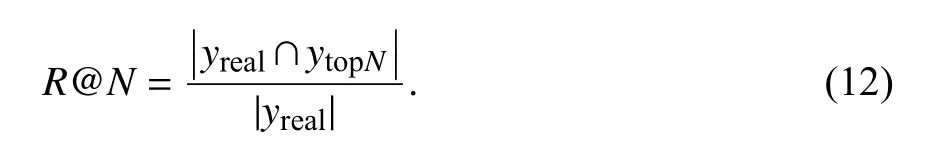
NDCG 除了对准确性的考量,还考虑到标签的先后排名情况,使得排名靠前的标签得分更高,计算方法如下:
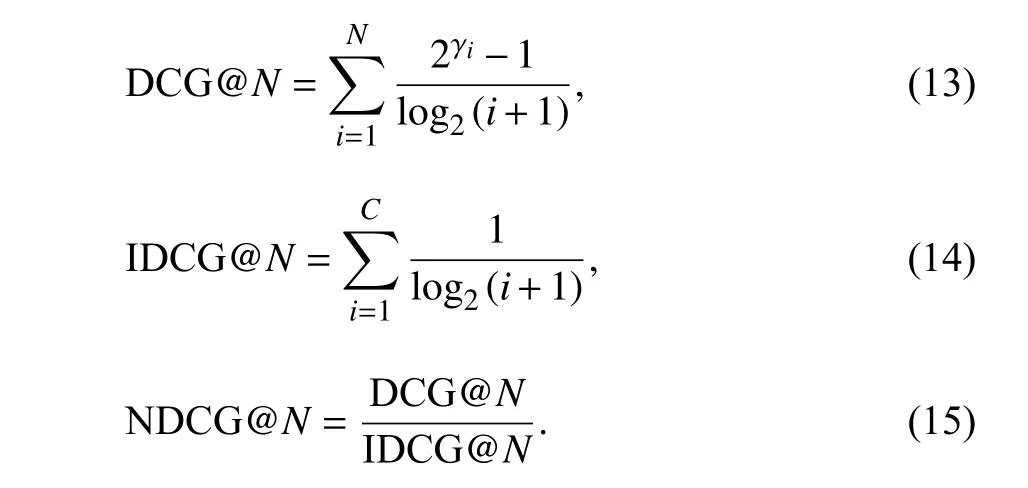
当第i个标签与文档相关时,γi=1,否则 γi=0,C是理想状态下,标签按照相关性从大到小排列的集合.
3.4 对比方法本文使用TagSpace、TextCNN、LEAM、GILE、BGRU-Att 等基线模型对比实验结果,这些基线模型覆盖了多标签分类的不同方法.
TagSpace[11]:使用卷积神经网络提取文档特征,并将标签做嵌入表示,使用文档与标签之间的点积计算进行预测分类,其中卷积窗口大小设置为5,卷积核数量为128.
TextCNN[7]:在预训练的词向量的基础上使用卷积神经网络来学习文档的特征,最后使用一个分类层进行预测,实验中上下文窗口大小为[3,4,5],卷积核数量为128.
LEAM[13]:利用标签嵌入信息结合文本词嵌入增强文本特征表示,并使用全连接层进行分类,使用二元交叉熵损失训练模型.
GILE[14]:将标签使用预训练词向量初始化,与文档特征结合得到交互特征,最后使用一个全连接层进行分类.
BGRU-Att[25]:使用双向GRU 获取文档的向量表示,通过全连接层和sigmoid 激活函数获得预测值,并使用二元交叉熵作为损失函数.
3.5 实验结果对数据集PW-20K,Reuter,Eurlex和CiteULike-t 使用同样的预处理方法清洗之后,使用TagSpace、TextCNN、LEAM、GILE、BGRUAtt 和本文提出的CPTC 模型分别计算精确度、召回率和NDCG,结果如表3~6 所示.
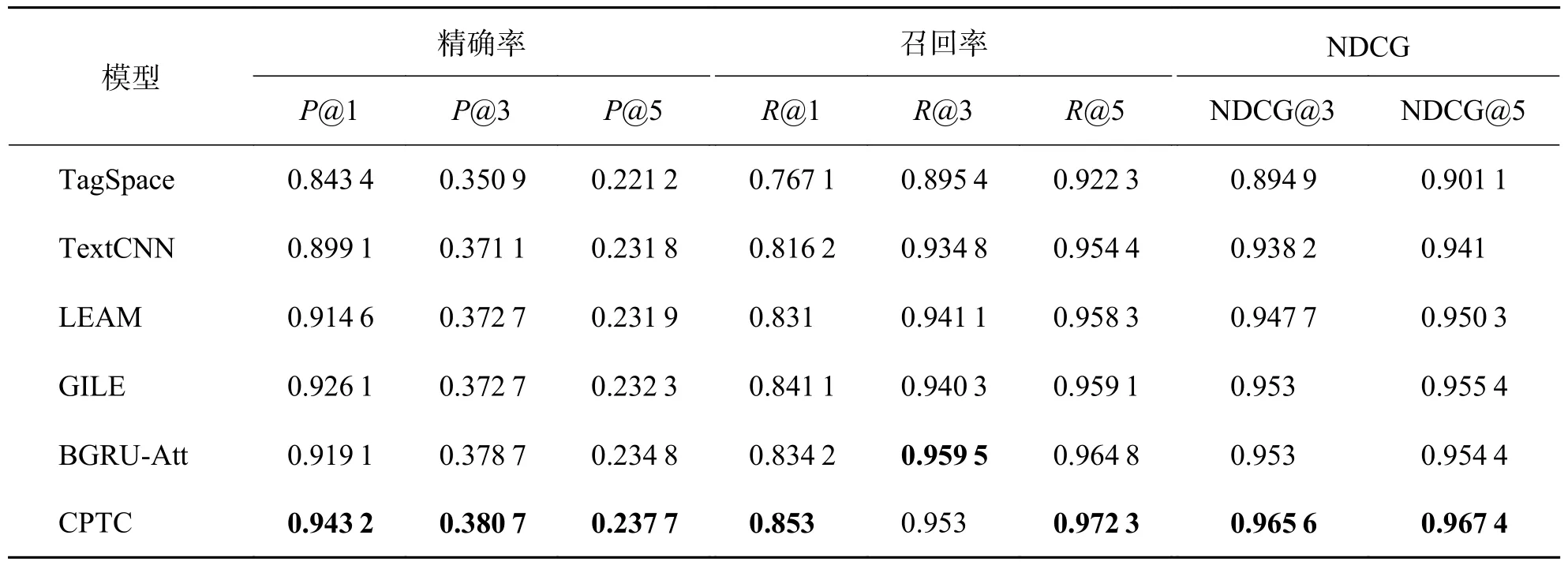
表3 Reuter 数据集下实验结果Tab.3 Experimental results under Reuter dataset
TagSpace 和TextCNN 同样使用CNN 来提取文档的特征、建模文档和标签的关系,TextCNN 使用了多个不同大小的卷积核获取文档特征,因此其分类效果在实验的4 个数据集中都要优于TagSpace.LEAM 和GILE 在深度网络的基础上,将文档和标签嵌入到同一个特征空间,更加充分地建模了文档和标签的关系,因此它们的分类效果优于只利用文档与标签直接关系的TagSpace 和TextCNN.BGRUAtt 采用深度网络与注意力机制结合的方法提取文本特征,一方面BGRU 解决了文档中单词的远距离依赖问题,另一方面注意力机制通过内置神经元的学习为文档中的词分配合适的权重,突出了关键信息的作用.在文本多标签分类中表现尤为出色,在Reuter 数据集中P@1、R@1、NDCG@5 低于GILE 模型,在PW-20K、Eurlex 和CiteULike-t 数据集中全部指标优于其他基线模型,在所有基线模型中表现最好.
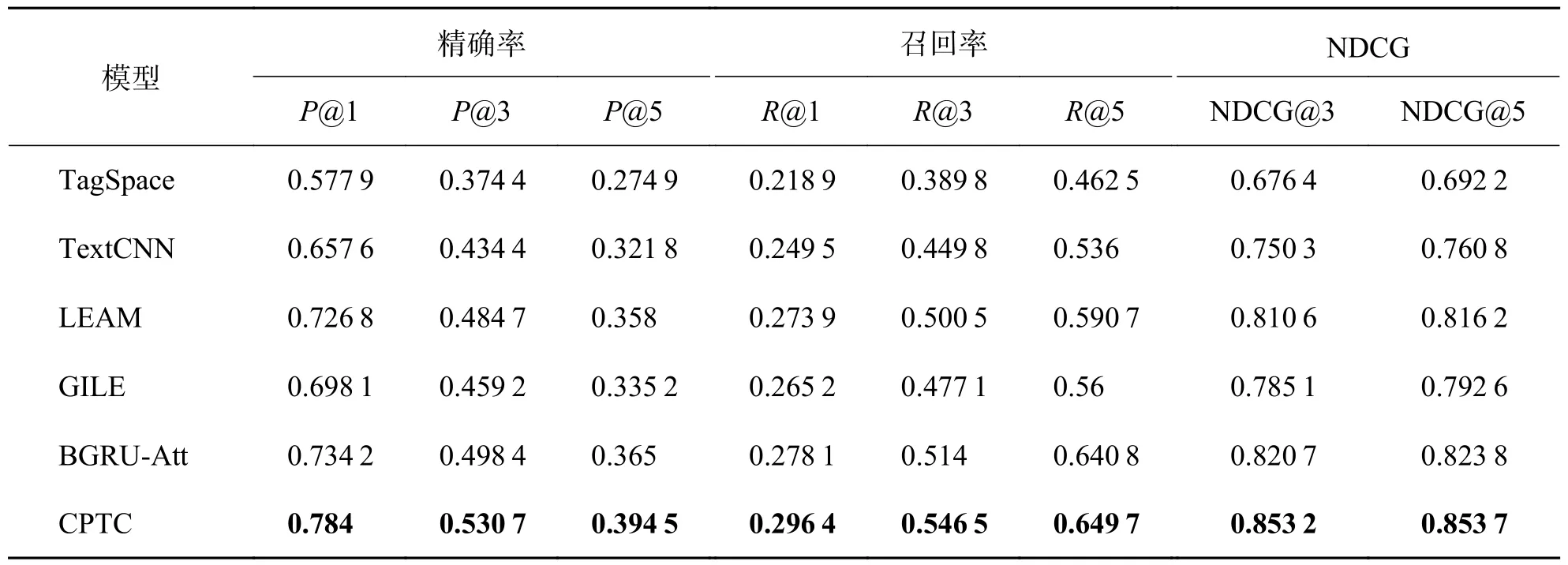
表4 PW-20K 数据集下实验结果Tab.4 Experimental results under PW-20K dataset
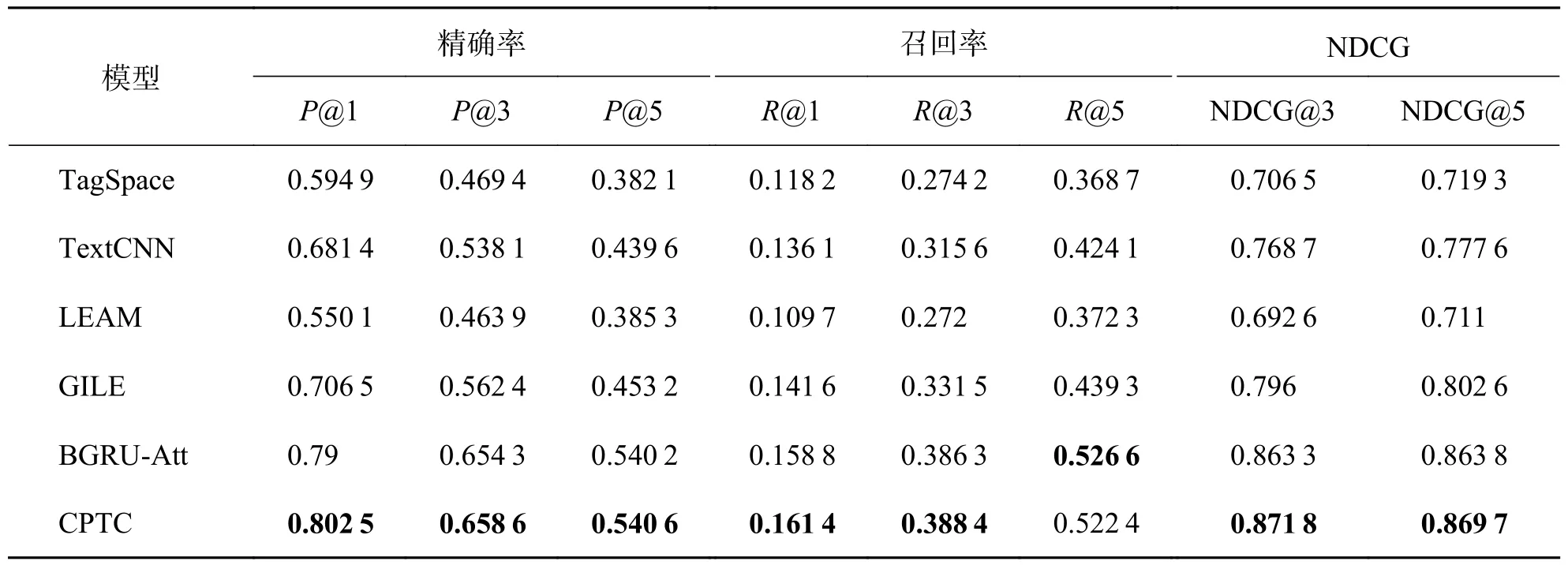
表5 Eurlex 数据集下实验结果Tab.5 Experimental results under Eurlex dataset
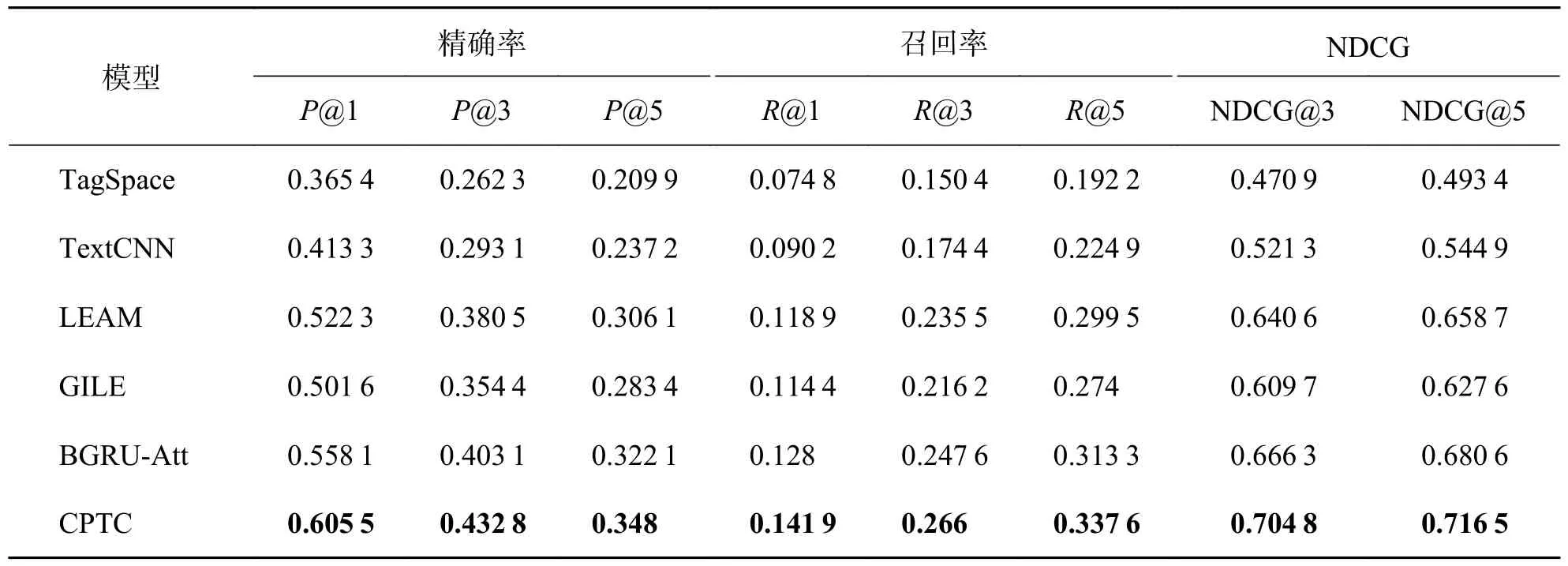
表6 Citeulike-t 数据集下实验结果Tab.6 Experimental results under Citeulike-t dataset
与基线方法相比,本文提出的CPTC 在现有方法的基础上,使用聚类感知的方法建模文档在不同语境下的特征,弥补了现有方法使用单一文档特征无法充分利用文档线索的缺点,充分挖掘了文档和文档之间的隐含关系,因此相较于基线模型效果更好.结果表明CPTC 在所有指标中相较于传统基线模型均有较大提升.其中相较于基线模型中表现最好的BGRU-Att 模型在CiteULike-t 数据集中,P@{1~5}取得了2.59%~4.74%的提升,R@{1~5}取得了1.39%~2.43%的提升,NDCG@{1~5}取得了3.59%~4.74%的提升.
3.6 示例分析为了验证聚类感知建模文档在不同语境下特征的效果,在CiteULike-tt 数据集中使用TagSpace、BGRU-Att 和CPTC 进行示例分析,其中预测正确的标签用粗体标识出来,表7 的第一个示例是使用基因对诺氏疟原虫研究的论文,在前5 项预测中,TagSpace 命中了1 个标签,BGRUAtt 命中了2 个标签,CPTC 命中了全部的4 个标签;表7 的第二个示例是对基因组、转录组和蛋白质组研究的论文,在该示例中,TagSpace 没有命中,BGRU-ATT 命中了1 个标签,CPTC 命中了3 个标签;表7 的第三个示例是对非裔美国大学生的研究,在该示例中TagSpace 没有命中,BGRU-Att 命中了2个标签,CPTC 同样命中了全部4 个标签.
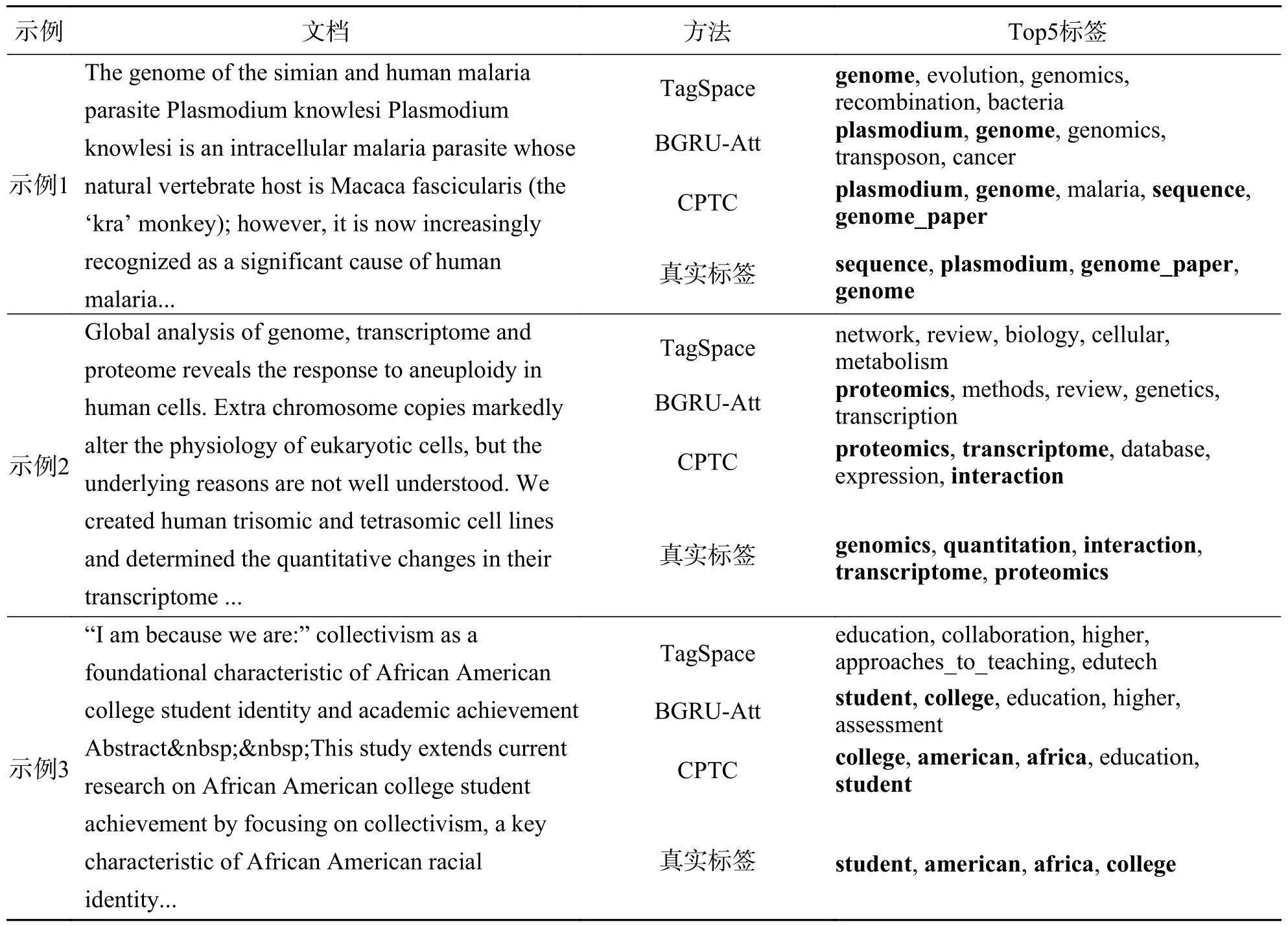
表7 示例分析结果Tab.7 Results of sample analysis
示例分析验证了CPTC 模型在文本多标签分类任务中的有效性,相较于基线模型可以更全面地预测出真实的标签,体现了聚类感知建模出不同语境下特征的作用.
3.7 参数分析模型中最重要的参数为簇心数量k,其代表了不同语境的数量,是影响模型效果的主要因素,在模型中簇心向量是额外引入的,可以任意更改其数量,其值使用随机初始化的方式产生,并在反向传播中更新.设置不同的簇心数量,保持其他条件不变,计算模型分类的精确度,得到的实验结果见图2.从图2 中结果可以看出在不同的数据集下,聚类中心数量从0 到7 的区间内,精确度整体上处于一直上升态势,说明随着建模中语境数量的增加,分类效果也在提升,在7 之后分类性能开始波动,可见在实验的4 个数据集中,语境数量在7 左右可以达到对精度提升的上限.同时也进一步验证了使用聚类感知方法建模出文档在不同语境下的不同特征对于分类任务是有效的.
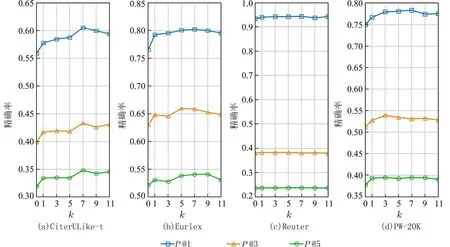
图2 不同簇心数量下模型精确率的表现Fig.2 Performance of model accuracy under different number of cluster centers
3.8 消融实验为了进一步验证聚类感知模型的有效性,保留原有模型的其他部分,去除聚类感知
部分,将文档经过深度模型的特征直接输出,将公式(7)改为:

保持模型其他参数一致的情况下,在原有4 个数据集上测试,得到去除聚类感知后模型的性能表现对比如图3 所示.图3 中CPTC-0 指不带有聚类感知的模型,CPTC-7 是指带聚类感知并且簇心数量为7 的模型,橙色的部分代表精确度的增量.从结果可以看出,聚类感知模块在所有数据集上都可以有效提升性能,其中在CiteULike-t 数据集上,相较于表现最好的基线模型BGRU-Att 在P@1 指标上取得了4.62%的效果提升.
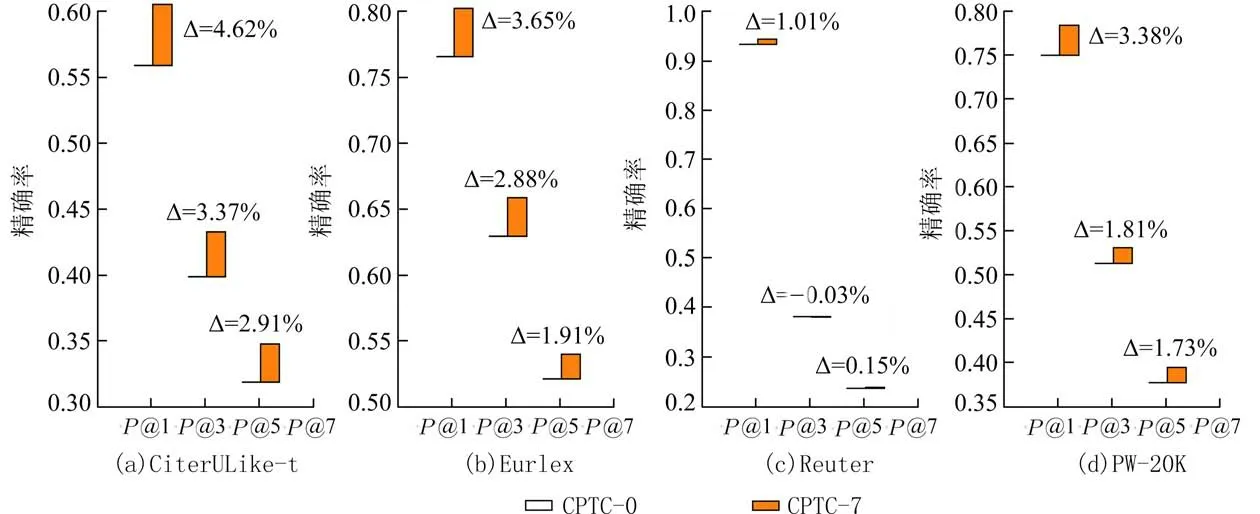
图3 聚类感知对模型的影响Fig.3 The effect of clustering perceptual on model
4 结论
本文从文本词语的多义性出发,提出了聚类感知文本分类模型.该模型使用深度模型获取文本的词隐含向量,通过聚类感知注意力机制来建模文档中词语在不同语境下的不同特征,增强了文本的特征表示.实验表明,与其他基线方法相比,本文提出的聚类感知文本分类模型在性能上取得了显著的效果提升.尽管模型更加充分地建模了文档和标签的隐含关系,但在多个文档特征和标签向量交互时采用了传统点积的方式,在处理标签规模大的数据集时需要占用大量空间,未来可以考虑采用基于树的方法对其进行优化.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
客联(2022年3期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
计算机应用与软件(2021年7期)2021-07-16
电脑爱好者(2021年9期)2021-05-12
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
电脑爱好者(2017年7期)2017-05-06
高中生学习·高三版(2016年9期)2016-05-14
