
结合平滑扩展卷积网络与注意力机制的低照度图像增强
2022-09-21 12:03李宇娇周冬明
云南大学学报(自然科学版) 2022年5期
李宇娇,周冬明,李 淼,杨 浩
(云南大学 信息学院,云南 昆明 650500)
在光照不足和背光环境下拍摄的图片会出现局部或者全局低亮度、低对比度、噪声影响严重的现象,这些问题不仅影响图片的视觉质量,还不利于进一步地进行计算机视觉任务,如物体识别、图像识别等.因此,低照度增强[1-3]是图像处理领域中一个十分热门的研究方向.低照度图像增强方法分为传统算法和深度学习法.传统算法主要包括基于Retinex 的方法[4-5]和基于直方图的方法[6].Retinex理论[4]是1963 年美国物理学家Land等提出的一个关于人类视觉系统如何调节感知到物体的颜色和亮度的模型.该理论对相同物体在不同光线或光源底下颜色为什么是恒定的做出了解释.之后有很多学者提出了基于Retinex 算法的不同变形,其中单尺度Retinex(Single Scale Retinex,SSR)[7]通过估算环境光照射分量计算物体的反射分量,而环境光照射分量可以通过高斯模糊和人眼中看到的图像做卷积运算求得;多尺度(Multi-Scale Retinex,MSR)[8]是由SSR 发展而来,运用了多个尺度的高斯模糊估算环境光照射分量,再对每个尺度求权重之和,提升了图片的色感一致性;具有色彩恢复的多尺度Retinex(Multi-Scale Retinex with Color Restoration,MSRCR)[8]在MSR 的基础上加入色彩恢复因子调整图像增强处理后的颜色失真.这些方法对图像处理的步骤基本相似,首先对原图像取对数,然后估计其亮度,得到亮度图像,再计算出待增强图像和亮度图像的差获取反射图像,最终获得一幅处理后的图像.基于Retinex 的方法[4-5]通常假定图像是无噪声和无颜色失真的,因此缺乏处理颜色失真的能力.基于直方图的方法[6]借助图像处理技术更改原始图像像素的灰度,对在图像中像素个数多的灰度级进行拓宽,对像素个数少的灰度级进行缩减,使图像对应的直方图变换为均匀分布的形式,从而增强图像的整体对比度.该方法注重于提高图像的对比度,但没有增强图像中黑暗区域的细节,因此将此方法用于处理彩色图像时往往存在色彩失真等问题.
深度学习在图像处理任务,如去噪、去雾、超分辨率等计算机视觉问题上取得了显著效果,在低照度图像增强方面也有越来越多的应用.其中,LLNet[9]是第一篇使用深度学习解决图像增强的论文,提出了一种堆叠稀疏去噪自编码器识别弱光图像中的信号特征,并在不过度放大图像较亮部分的情况下自适应地使图像变亮,但实验结果表明图像细节的清晰度和色彩复原度仍需改进.GLADNet[10]是一种基于CNN 的模型,它对图像进行下采样到统一大小,通过编码器获得全局光源估计,使用CNN 进行细节重建,但图像细节会在编解码的过程中丢失.MSR-net[8]是另一种基于CNN的模型,它将多尺度Retinex 理论和CNN 模型组成一个端到端模型,但在测试阶段当图像的噪声增加时,最终生成的图像清晰度有所下降.SSIENet[11](Self-Supervised Image Enhancement Network)是 一种基于自监督机制的方法,利用最大熵的Retinex模型可实现用极少量数据集极快地完成训练,但其测试结果并未达到最优.
针对以上问题,本文提出了一种结合平滑扩展卷积和注意力机制的低照度图像增强网络.与传统方法不同的是,该方法不需将图像分解为光照分量和反射分量,而是通过引入扩展卷积让感受野指数级增加,再加入分离共享卷积平滑扩展卷积所造成的网格伪影问题;同时使用通道域注意力机制改善卷积网络对全局特征提取不足的问题,再将两个支路提取的特征进行通道拼接输入到重构网络中,在该网络中用深度残差网络对图像进行重构.实验结果表明,该方法对低照度图像增强有很好效果,可较好地复原出图像中更多的颜色细节,并可高效稳定地应用于各种低照度图像.
1 相关知识
1.1 平滑扩展卷积网络扩展卷积网络广泛应用于各种任务中,包括语义分割、目标检测、机器翻译等.之前传统的卷积神经网络需对图像不断进行下采样降低图像精度,直到图像被表示为一个很小的特征图,以此达到扩大感受野和降低运算量的目的.这种情况会损失图像较多的细节信息、空间分辨率.因此Yu 等[12]提出扩展卷积网络,该网络可在不损失图像分辨率的条件下增大感受野,从而获取到更多的空间信息.扩展卷积可理解为在标准的卷积核中每两个相邻的权重值之间都插入r−1 个0 值.当设置不同扩展率时,感受野就会不一样,即获取了图像的多尺度信息.图1 显示了在二维情况下,卷积核大小为3×3、空洞率为r=2 时的扩展卷积有5×5 的感受野.从图1 可以看出,空洞率为2 的二维扩展卷积有5×5 感受野.然而,实际参与计算的像素只有25 个像素中的9 个,这意味着实际的感受野仍然是3×3,但分布稀疏.
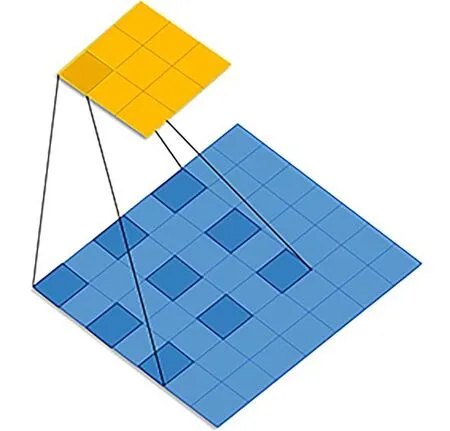
图1 扩展卷积核的感受野Fig.1 The receptive field of dilated convolution kernel
其数学模型[12]在一维情况时如下:
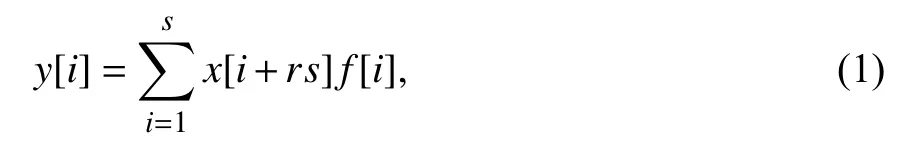
式中,x为一维输入,在位置i处通过尺寸为s的卷积核f输出的卷积结果为y,r为空洞率.当r=1 时,空洞卷积和标准卷积相同.级联多个扩展卷积时,卷积核的感受野将会指数级增大.
然而,在最近的语义图像分割研究[12]中发现,空洞率大于1 的扩展卷积都会产生所谓的网格效应.由其数学模型可推知,在得到的每一层卷积结果中,邻近的像素是从相互独立的子集中卷积得到的,相互之间缺少依赖,因此每一层的卷积结果之间均无相关性,造成了局部信息丢失.另外,由于扩展卷积中卷积核的不连续,导致图像中的某些像素未参加运算,影响了图像信息的连续性.上述现象被统称为网格伪影问题[12].级联两层扩展卷积,卷积核为3×3,空洞率为2 时网格伪影如图2 所示.在图2 中,用4 种不同颜色标记第i层的4 个相邻像素,在第i−1 层的实际感受野分别用相同的颜色标记出来.可以看出相邻像素块是由完全不同的输入集计算得到,导致了局部信息的不一致性,影响了扩展卷积的性能.
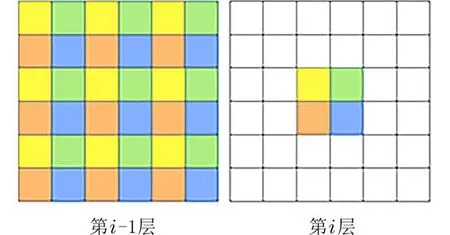
图2 网格伪影产生的图解Fig.2 The diagram of grid artifact generation
考虑到在扩展卷积中,所有相邻的像素都是由上一层中的独立像素群卷积而来,因此如果能够在扩展卷积进行周期性卷积计算之前,将图像的局部信息进行合并,就可以减轻网格伪影问题.所以在该方法中,我们引入了深度可分离的共享卷积层[13]来简单而有效的去除网格伪影带来的影响,效果如图3 所示.
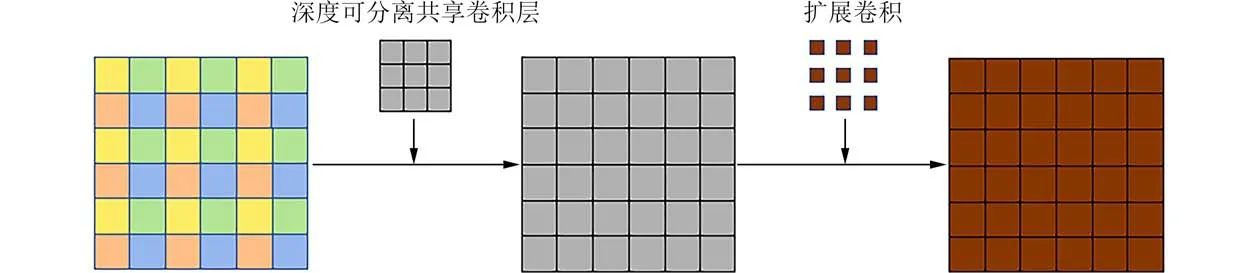
图3 网格伪影减弱的效果Fig.3 The effect of grid artifact weakening
深度可分离卷积[14]与标准卷积相比:标准卷积同时考虑了输入图像的空间信息和通道信息,它将所有的输入信道各用不同的卷积核得到不同的输出信道;深度可分离卷积先进行逐通道卷积,即每一个通道用一个卷积核卷积之后得到对应一个通道的输出,再通过逐点卷积将各通道信息进行融合.“共享”是指在使用深度可分离卷积的基础上,共享同一个卷积核.可分离共享卷积只用一个卷积核扫描了输入图像的空间信息,并在所有信道共享使用该卷积核.
1.2 注意力模块近年来,注意力机制在计算机视觉领域得到了广泛的应用,并且取得了不错的效果.注意力模块中应用较多的有Selective Kernel networks(SKnet)[13]、Squeeze-and-Excitation networks(SEnet)[15]、Convolutional Block Attention Module(CBAM)[16]等几种轻量嵌入式模块.SEnet[15]重点考虑图像通道之间的关系,提出了一种“特征重校准”策略的压缩激励算法,可学习到每个通道特征的权重值,权重值越大代表该通道与关键信息的相关度越高,增强有用特征,抑制不重要的特征.SKnet[13]可根据输入信息的不同自适应调节卷积核的大小.CBAM[16]是一种为卷积神经网络设计的注意力模块,同时考虑了图像通道和空间维度两个因素,即不仅给不同特征通道赋予不同的重要性,还考虑到同一个特征通道中不同位置的重要程度不同.通过实验对比,我们发现在该方法中使用CBAM 能得到更佳的结果.
1.3 残差网络研究[17]表明,随着神经网络的层数增多,网络会发生退化现象,即网络的损失函数不再下降或不减反增,这是因为在一层一层网络中将特征向前传递时,每一层所获得的特征将会逐层减少,而残差网络因加入了直接映射,所以可以较好地解决这个问题.残差网络是由一些残差块组成的,每一个残差块表示如图4 所示.
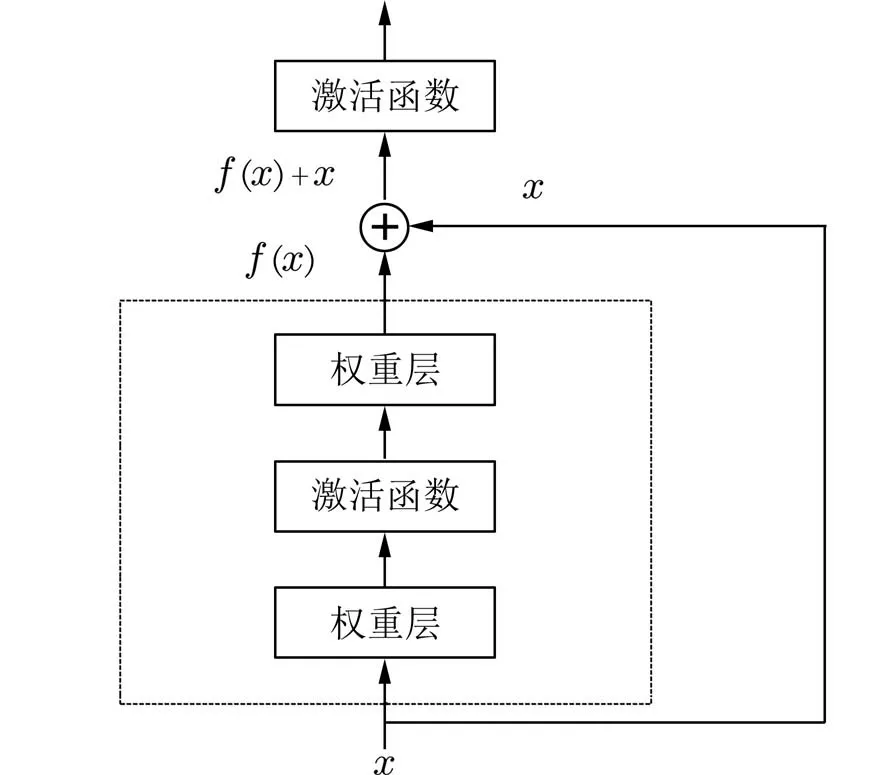
图4 残差块模型结构Fig.4 The model structure of the res-block
残差块将单元的输入x直接与单元输出f(x)加在一起,然后通过激活函数.一般的残差块有两到三层卷积,这样可以较好地保留图像特征,缓解网络退化问题.
2 本文算法
本文基于平滑扩展卷积网络与注意力机制构成特征提取部分,结合多层残差块构成图像重构模块.
2.1 模型结构本文网络结构主要由特征提取和图像重构两部分组成.特征提取模块采用了两路分支的端到端神经网络,图像重构模块利用多层跳跃连接的残差块构成.具体步骤如下:
步骤 1将低照度图像送入预提取特征层Pre_block,再将其结果分别送入上、下特征提取支路,得到特征F1、F2
步骤 2将两路分支结果通过拼接操作,即通过将通道数堆叠进行特征融合得到总特征F′.
步骤 3融合后的图像特征F′送入由残差块构成的重构网络中,得到最终的重构图像.
如图5 所示,L_input 代表低照度图像,特征提取网络主要由预提取特征层和两路主特征提取网络构成.预提取特征模块由4 个卷积层构成,每个卷积层使用大小为3×3 的卷积核,上支路首先通过深度可分离卷积层(Deep Separable_block)将图像局部信息进行合并,以减少引入扩展卷积层造成的网格伪影问题,随后通过3 层扩展率分别为1、3、5 的扩展卷积层,共同构成平滑扩展卷积模块.最后利用SEnet 通道注意力机制,为3 路扩展卷积层赋予不同的权重值,到此提取到图像特征F1;下支路通过4 组CBAM 和卷积层的组合得到图像特征F2,该支路可进一步加强对图像全局特征的提取.在特征提取网络的最后,通过拼接操作对F1、F2两特征进行融合,再将其送入重构网络中.
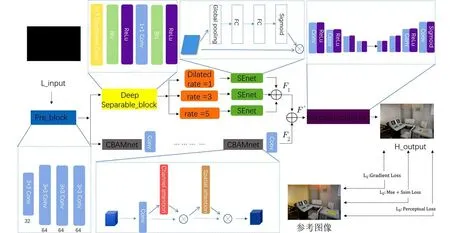
图5 本文提出的模型框架图Fig.5 The model frame diagram presented in this paper
重构网络主要由一系列卷积层组成的U-net构成,它将两路分支的输出作为输入,以获得增强图像.在该网络中我们使用卷积核数为16、16 和3的卷积层分别提取它们的特征.特别的,在最后一层卷积之后我们选择sigmoid 为激活函数.
得到H_output 增强图像之后,用由多个像素级损失和视觉损失组成复合损失函数计算出与参考图像Reference 的损失值,以此让该网络不断进行优化学习.
2.2 损失函数为了更好地实现低照度图像增强,本文的损失函数结合了多种传统损失函数.该复合损失函数包含3 部分.
在第1 部分中,为了使增强后的图像与输入的低照度图像保持一致性,在损失函数中使用梯度损失.且因最终生成的增强图像是RGB 彩色图像,所以需先将图像转换为灰度图像,数学模型如下:
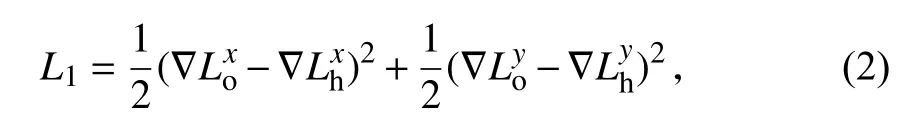
式中,L1表 示复合损失函数中的第1 部分,∇表示梯度算子,上标x和y分别表示按照图像的水平和垂直方向所求的梯度损失,Lo表示重构模型生成的增强后的图像,Lh表示参考图像.
在第2 部分中,使用最小相对误差(MSE)和结构相似损失(SSIM)[18]使增强后的图像保留更多的细节,从而得到更好的视觉效果.MSE 是l2 正则化,使用线性变换的方法对两幅图像进行比较,未考虑两幅图像之间的相关性,因此加入SSIM 损失函数.SSIM 是一个结构损失函数,综合考虑了图像的亮度、对比度及结构,其计算公式如下:
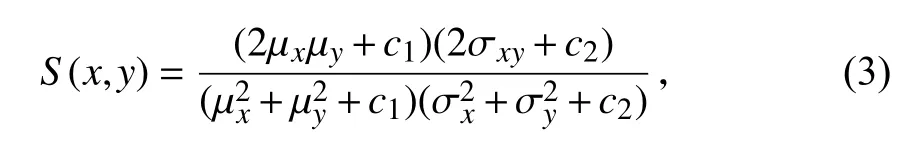
式中,S(x,y)为 SSIM 损失函数;µ、σ、σxy分 别表示x与y之间的均值、标准差和相关度;c1=(k1L)2,c2=(k2L)2,是用于避免当分母为0 时的不稳定情况的常数,其中L是像素值,k1=0.01,k2=0.03.结构相似损失函数的取值范围为−1 到1.当两张图像一模一样时,SSIM 的值S(x,y)等于1.因此第2 部分损失函数的数学模型如下:
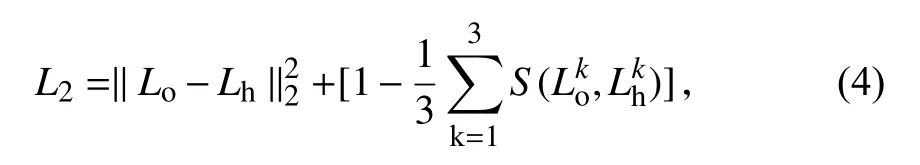
式中,k表示图像通道.
在第3 部分中,为了使增强后的图像效果与人眼感知的图像质量更加匹配,引入Vgg 感知损失[19],与MSE 有同样的计算模式,区别是将计算空间从图像空间变为特征空间.计算公式如下:Cj×Hj×Wj,φ 表示Vgg 损失网络,φj(o)表示该损
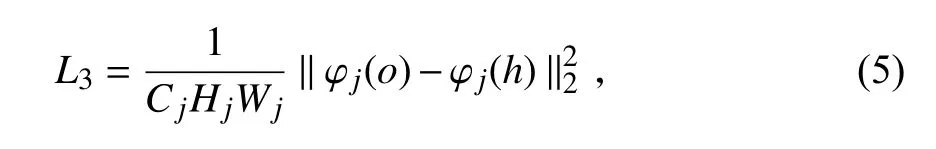
式中,j表示网络的第j层,第j层特征图的大小为失网络的输入为增强后的图像时第j层的输出,φj(h)表示该损失网络的输入为参考图像时第j层的输出.
因此,复合损失函数为:

3 实验及结果分析
3.1 模型训练及数据集该方法基于Tensorflow 1.15 开源框架在Nvidia gtx2080ti GPU、Intel core i7-9700kf 3.6 GHz CPU 和32 GB RAM 上 进行训练.由于现实生活中低光照图像很难成对获取,因此使用了经典的LOL 和SCIE 两个数据集作为训练集.LOL 数据集[20]用RetinexNet 方法构建,其中训练集中包含485 对图像,测试集中包含15 张低照度图像.SCIE 数据集[21]采用MEF 和HDR 技术生成,包含229 对高质量的低照度图像对.实验选择了LOL 中的480 对图像和SCIE 中曝光度最低的20对图像,并将它们裁剪为256×256 的统一大小组成混合训练集.用学习率为1×10−4的Adam 优化器进行训练,训练过程中批大小为2,训练次数为350 次.损失函数参数设置为α=0.1,β=0.2,γ=µ=1.
3.2 评价指标及对比分析
3.2.1 定性分析 将该方法与传统的低照度增强方法和深度学习法进行了对比分析.作为对比的传统方法有Dong[22]、LIME[23],BIMEF[24]、NPE[25]、RetinexNet[26],KinD[20],深度学习法有GLADNet[10]、SSIENet[11],MBLLEN[27].
从图6、7 中可以看出:与参考图像相比,SSIENet 和Dong 相似,对浅色部分过度曝光,细节处噪点明显,边缘轮廓被加重;BIMEF 对低照度图像的亮度提升不足,增强效果很差;NPE 和LIME一定程度上缓解了BIMEF 亮度不足的问题,增强后的图像效果较BIMEF 的结果稍好,但色彩深度保持得不够充分,处理后图像色调整体偏橙;MBLLEN 增强后的图像放大后细节清晰度很差,图像放大后物体轮廓均十分模糊,例如图7 中“控制台”桌面上的贴纸在放大后已不能分辨其轮廓;KinD 增强后的图像与前几种方法相比曝光度有所加重,导致原图像中亮色区域部分色彩失真,还原度不高;RetinexNet 处理后的图像中物体边缘过于突出,物体与背景分割明显,部分区域出现了伪影;GLADNet 对彩色部分,如红色、绿色、蓝色等的色彩保持较差,细节丢失,且放大图像中的噪点严重,例如图6 中,扩大的“衣柜”图像中色彩鲜艳的区域均噪点明显;本文方法效果与LIME 类似,但是处理后色彩协调性以及物体轮廓还原度的效果更佳.
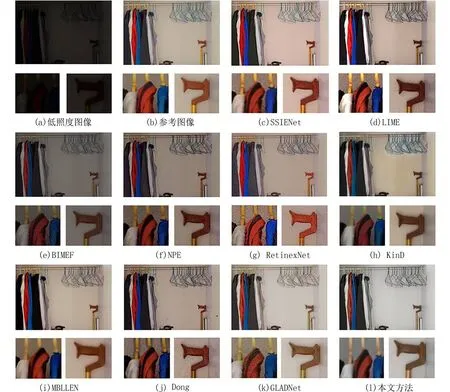
图6 基于图片“衣柜”与其他主流低照度增强方法进行视觉对比Fig.6 Visual comparison with state-of-the-art image enhancement methods in “wardrobe”

图7 基于图片“控制台”与其他主流低照度增强方法进行视觉对比Fig.7 Visual comparison with state-of-the-art image enhancement methods in “console”
3.2.2 定量分析 除了同主流方法进行了主观视觉上的效果对比,我们还采用了6 种客观的评价指标进行对比.分别是信噪比(SNR)、峰值信噪比(PSNR)、结构性检验标准(SSIM[18])、视觉信息保真度(VIF[28])、信息保真度(IFC[29])和噪声质量评估(NQM).SNR 代表图像中信号与噪声的比例,PSNR 是通过计算待测评图像与参考图像之间像素误差的总和判断图像质量,值越大,说明待测评图像与参考图像之间的失真度较小,图像质量较好.以上几个指标都是对图像像素值误差进行统计得到的,并没有考虑人眼的视觉观看效果.研究发现,很多高PSNR 或SSIM 图像没有很好的细节纹理,这些图片并不一定符合人眼的视觉习惯,所以我们还加入了以下几种评价指标.
SSIM 指数由3 个对比模块组成,分别是亮度、对比度、结构,其中亮度对比函数为:

对比度相似性定义为:
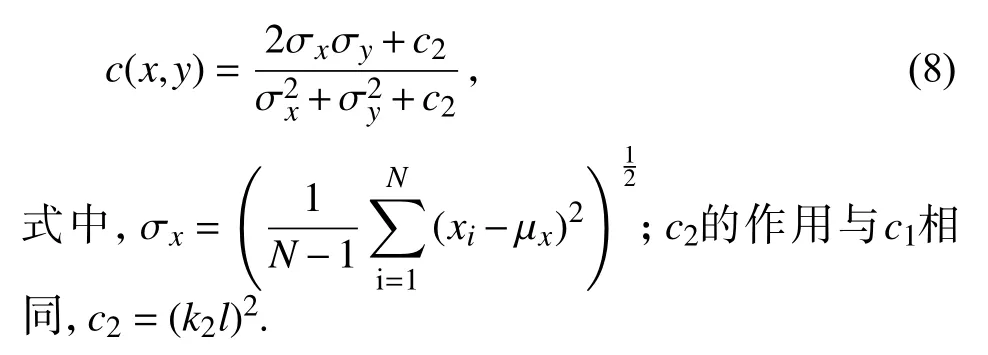
结构相似性定义为:

以上3 个对比函数共同构成SSIM 函数:
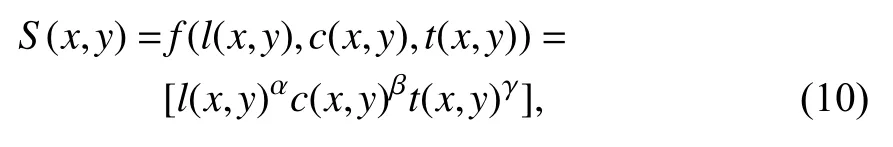
式中,α、β、γ>0,用以调整3 个模块的重要性,通常α=β=γ=1,c3=c2/2,则
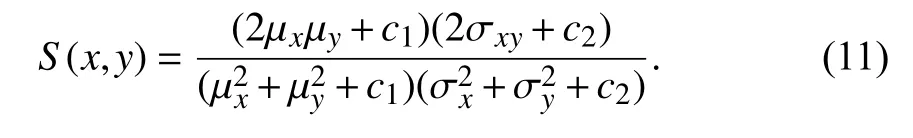
SSIM 函数的取值范围为[0,1],值越大说明待评估图像和参考图像越相似,失真度越小.
实验表明,VIF 指标与前几类指标相比,与人类的主管视觉体验有高度一致性,其值越大,说明图像质量越好.IFC 指标先利用大量的自然图像统计得到多尺度的高斯混合模型,再用它检测人眼较为敏感的高频信息的波形特征,以此衡量图像的信息损失程度.NQM 是噪声质量评估指标,可准确评估出图像中噪声影响的多少.以上几个指标的数值越高代表图像质量越好.由于篇幅有限,我们挑选3 张LOL 数据库中的测试图,用10 种方法进行客观定量对比,结果如表1~3 所示.最好的结果用加粗黑体字标出.从表中数据可看出,本文方法的大部分指标都优于其他方法,只有在表1、2 中的VIF 指标低于最好值,以及表1 中的NQM 低于最优.为了进一步分析,将LOL 数据集中的测试图像均作为对比对象,并计算出平均性能指标,如表3所示,可以看出,基于深度学习的方法在PSNR 和SSIM 上都有很出色的结果.本文方法的PSNR、SSIM 指标相较其它方法均有提升,SNR 指标的值位列第二,与第一相差很小.
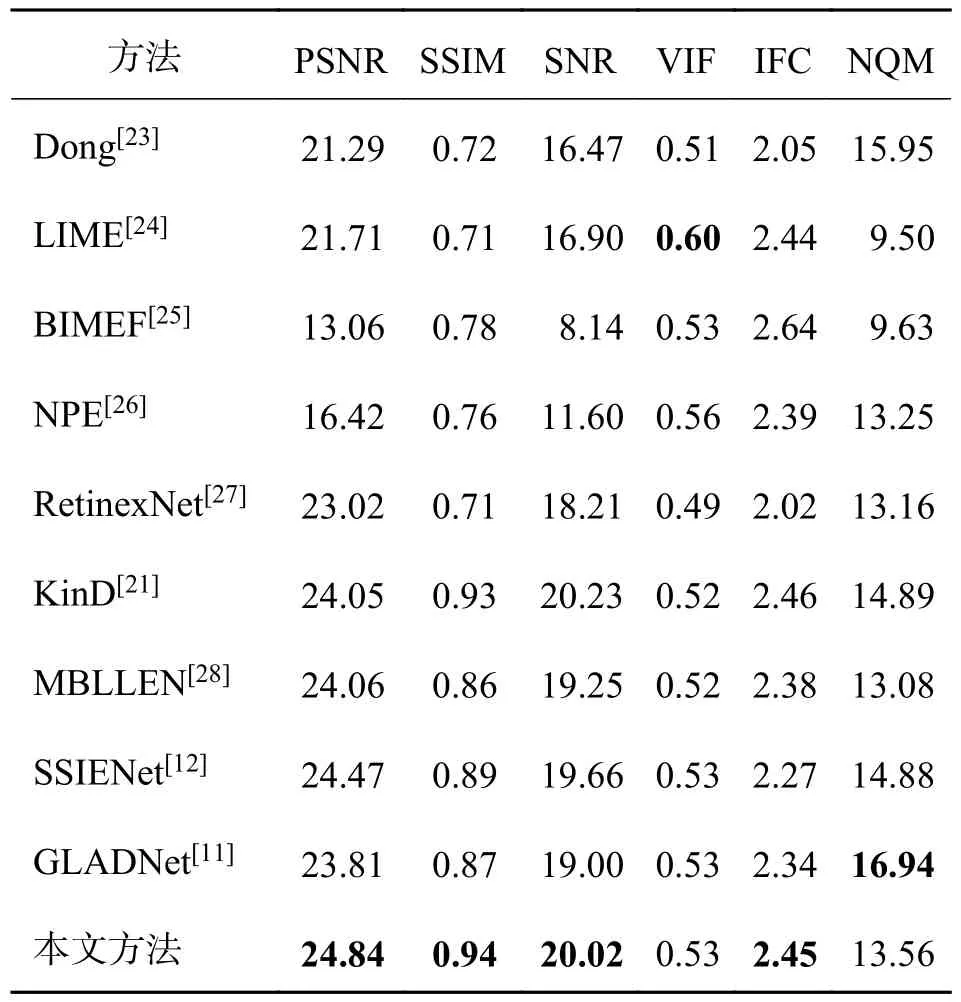
表1 不同方法对“衣柜”图像增强结果的定量评价Tab.1 Quantitative assessment comparison of different methods for the enhancement results of “wardrobe”
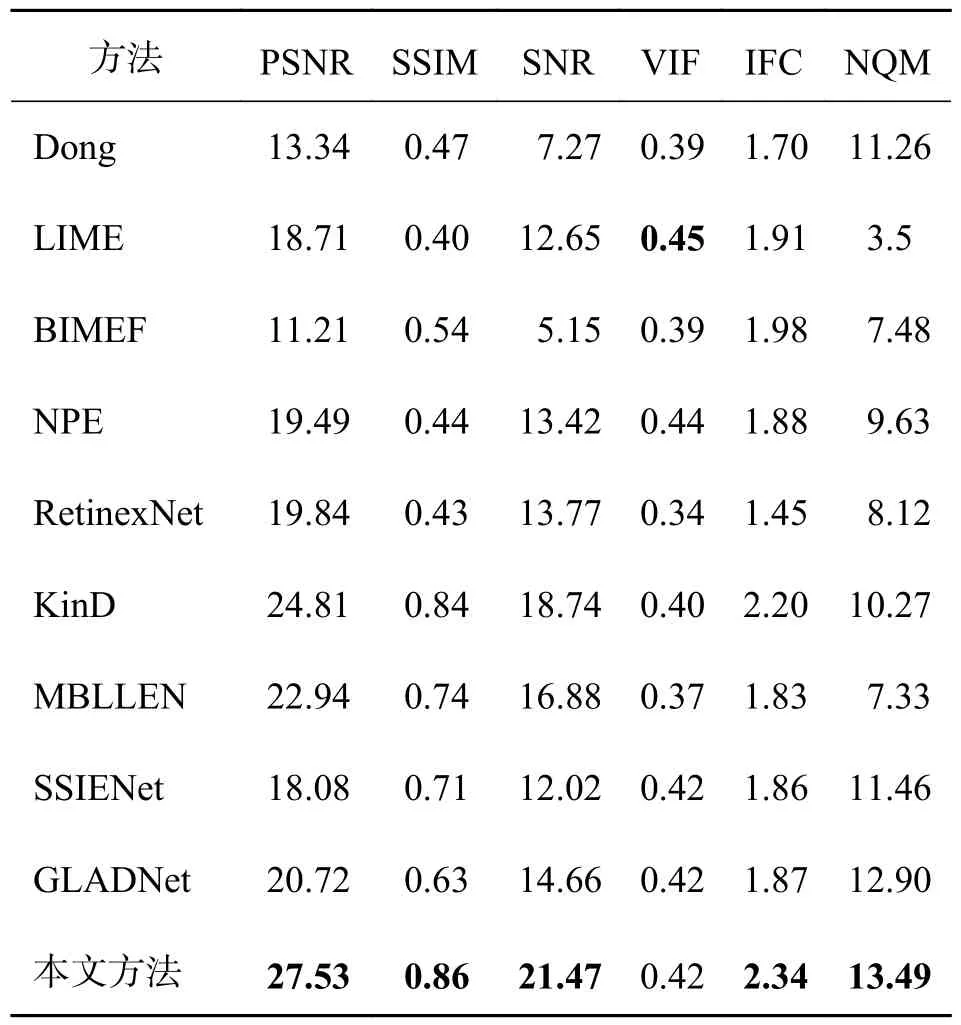
表2 不同方法对“控制台”图像增强结果的定量评价Tab.2 Quantitative assessment comparison of different methods for the enhancement results of “console”
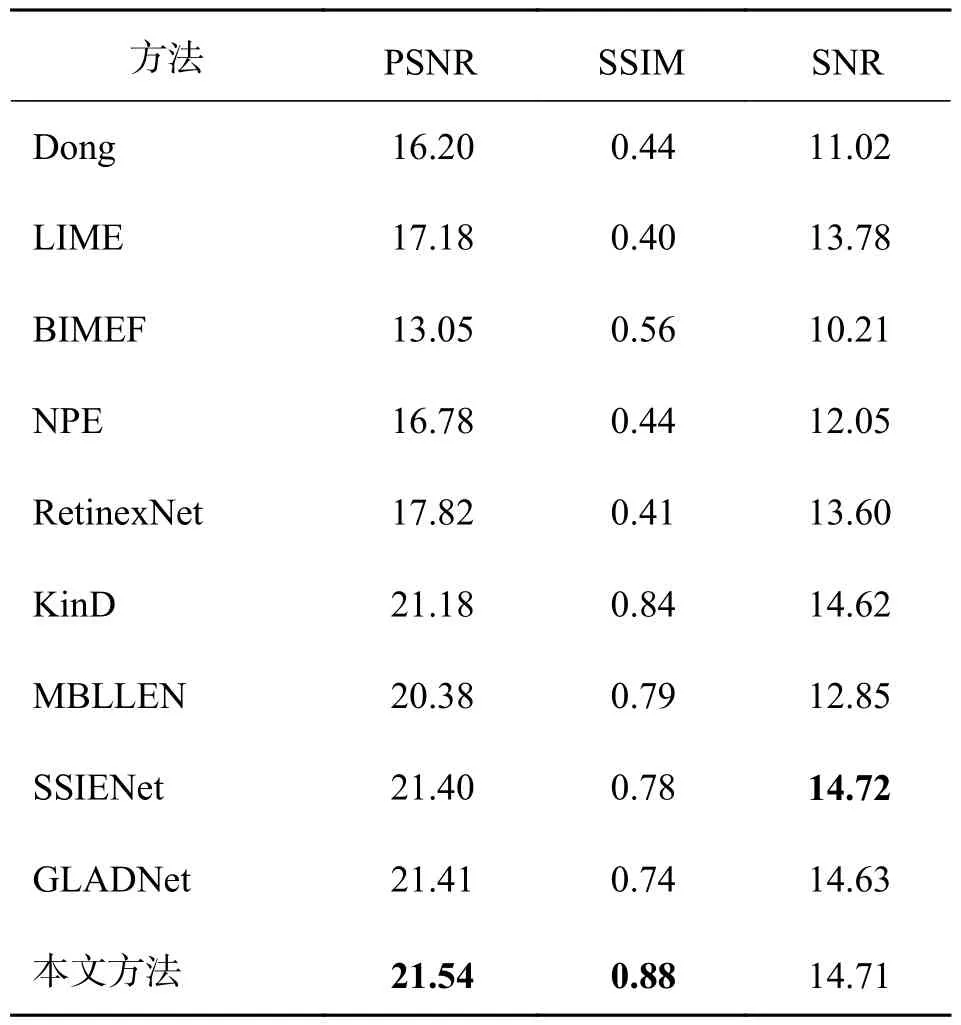
表3 不同方法对LOL 数据集增强结果的平均定量评价Tab.3 Average quantitative assessment comparison of different methods for the LOL-dataset
3.3 扩展实验由于篇幅限有限,我们任意挑选了两张低曝光度图像用不同方法增强后列出,分别为“建筑”“走廊”,除了做视觉对比,还用PSNR 和SSIM 两个客观指标进行评价,实验结果如图8 所示,客观指标如表4 所示.
由图8 可看出:KinD 依然是亮度最高的,但是细节颜色突变明显,在列举的两幅图像中均出现伪影,如“建筑”中的灰色拱门部分以及“走廊”的白色墙壁部分;BIMEF 的结果对比度很低,增强效果不佳;MBLLEN 的对比度相较于BIMEF 稍好,但是对浅色部分色彩保持不充分,在某些区域,例如走廊尽头处曝光度太弱,还原度低;NPE 在原图像对比度很低时,增强后的图像与参考图像相比,色彩深度更深;本文方法与GLADNet 很相似,但与之相比,本文方法在细节处层次更加真实,例如“走廊”中灯管的颜色更加接近参考图像中的淡蓝色而非GLADNet 中的白色,且在颜色较深的区域色彩还原度也更胜一筹.

图8 基于3 张图像与其他主流低照度增强方法进行视觉对比Fig.8 Visual comparison with state-of-the-art image enhancement methods in three different images
除了主观视觉上的对比,也可由表4 中的平均PSNR、SSIM 指标可知,对于这两幅图,本文方法的PSNR 分别高出排名第二的方法0.4 和1.23,说明提出的方法在几种对比方法中有良好的优势,鲁棒性强,且效果较为稳定.
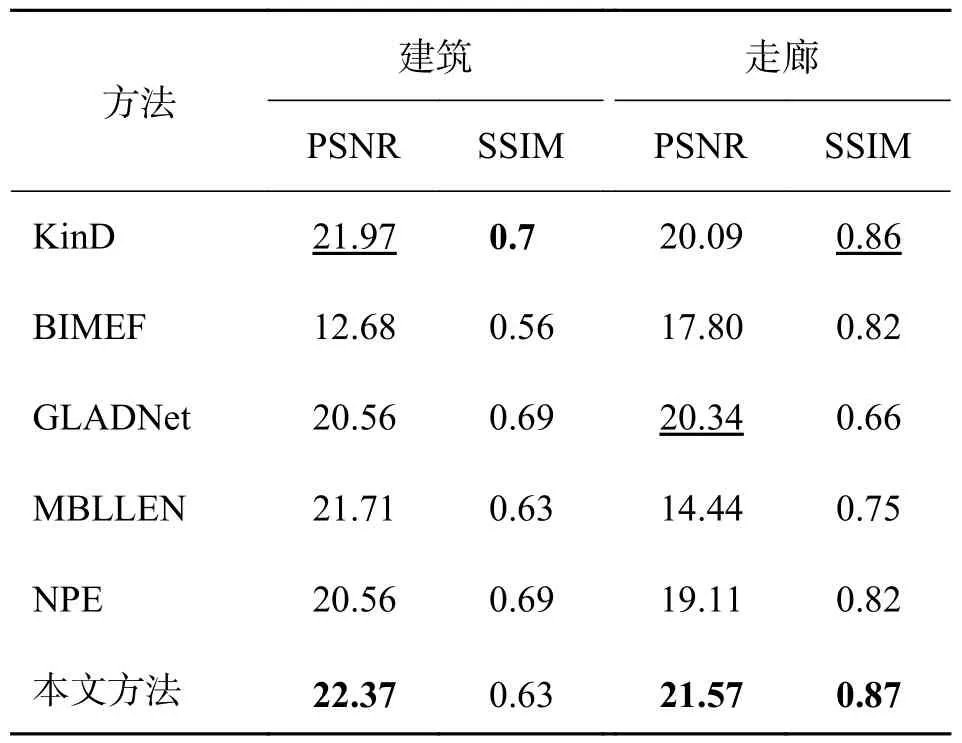
表4 不同方法对SCIE 数据集增强效果的定量评价Tab.4 Quantitative assessment comparison of different methods for the enhancement results of SCIE datasets
3.4 消融实验
3.4.1 参数选择 为了让提出的方法达到最好的增强效果,我们首先对比了不同参数对实验效果的影响,以此找到最优参数;接着,改变了损失函数中基于Vgg 的感知损失函数的占比,分别将λ设置为0、0.5、1、1.5,选择在LOL 数据集上作对比实验,实验结果如表5 所示.从表5 可以看出,当λ=1 时,客观指标PSNR、SSIM、SNR 均达到最佳,因此将损失函数中Vgg 的占比设定为1.
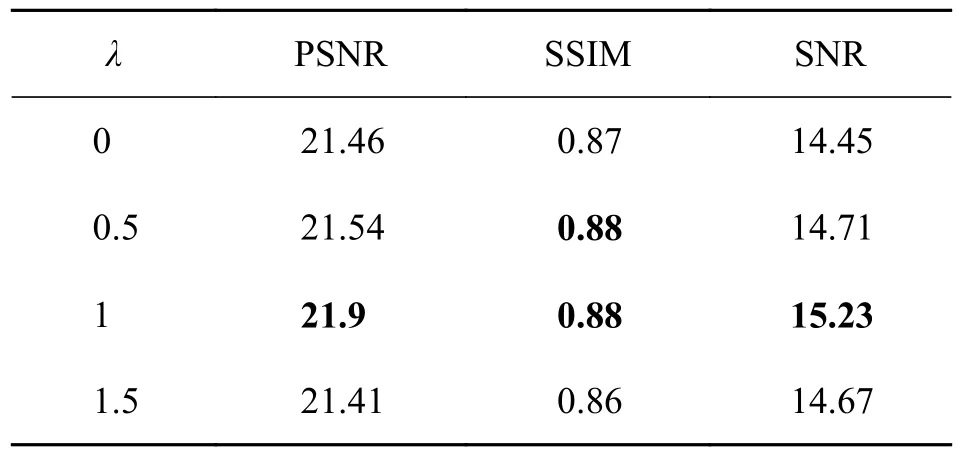
表5 不同参数对LOL 数据集增强效果的平均定量评价Tab.5 Quantitative evaluation of enhancement effect of LOL dataset by different parameters
3.4.2 结构消融 对所提出的模型进行了消融对比实验,首先我们对深度可分离共享卷积模块(Deep Separable_block)进行消融实验,将其结果标注为ABLATION-1.通过图9 可看出,在去掉深度可分离共享卷积模块后,特征提取能力显著下降,增强后的图像对比度低,色彩饱和度不足.由表6可更直观地看出,去掉该模块后,图像的PSNR、SNR 指标均下降,且部分图像降幅明显.说明该模块可较好地减弱扩展卷积的网格伪影问题,证明了本文提出方法的有效性.

表6 去掉平滑扩展卷积模块的消融实验定量对比Tab.6 Quantitative comparison of ablation experiments with removing smooth dilated convolutionalmodules

图9 去掉平滑扩展卷积模块的消融实验视觉对比Fig.9 Visual comparison of ablation experiments with removing smooth dilated convolutional modules
接着对注意力机制CBAM 模块进行消融实验,依次将其换为注意力机制SEnet 模块、注意力机制SKnet 模块.在图10 中,分别将其增强结果命名为ABLATION-2、ABLATION-3.由图10 可以看出,单看两组消融实验的增强结果,其结果还是较为理想的,亮度、对比度与原低照度图像相比均有较大提升,但本文方法的色彩饱和度更好,在细节轮廓和图像清晰度上有一定优势.在表7 中,客观指标方面,除了“POOL”图像的PSNR 的值29.97 略低于ABLATION-3 的30.60,“DOLL”图像的SSIM 的值0.71 略低于ABLATION-3 的0.73 外,其余指标均本文方法更优.这两幅图像的值未达到最优,是因为这两幅图像的真实图像偏暗,导致PSNR 和SSIM 的值偏小.但从总体来看,注意力模块选用CBAM 的实验整体效果要更优.

表7 更换注意力模块的消融实验定量对比Tab.7 Quantitative comparison of ablation experiments with replacement of attention module

图10 更换注意力模块的消融实验视觉对比Fig.10 Visual comparison of ablation experiments with replacement attention modules
综上所述,采用本文提出的模型结构和损失函数对低照度图像有较好地增强效果,优于其它方法,且具备较强的鲁棒性.
4 总结语
本文提出了一种端到端低照度图像增强网络,结合双路分支网络提取特征和多层残差块构成重构部分去训练模型.利用平滑扩展卷积和注意力模块这两路分支提取图像的局部特征和全局特征,并运用了复合损失函数.大量实验证明提出的方法可以很好地提取特征、重构图像,最终生成效果优异的增强图像,在主观视觉和客观评价指标中都优于对比的几种算法.为了使本文所提出的方法应用更加广泛有效,考虑在未来的研究中进一步优化损失函数,扩大数据集.
猜你喜欢
今日农业(2022年15期)2022-09-20
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
科学与生活(2021年14期)2021-09-10
小天使·二年级语数英综合(2019年10期)2019-11-08
船舶与海洋工程(2019年4期)2019-09-13
电子制作(2019年11期)2019-07-04
读者·校园版(2015年19期)2015-05-14
海外英语(2013年8期)2013-11-22
