
SOM在LTE小区性能分析中的应用
2022-09-02 10:52:44王少轩
微处理机 2022年4期
李 炜,王少轩
(1.陕西国防工业职业技术学院电子信息学院,西安 710300;2.加泰罗尼亚理工大学计算机学院,巴塞罗那 08034)
1 引言
随着LTE技术的广泛应用,为了给用户提供优质服务,电信运营商面临着处理大量网络数据的需要。如何快速准确分析不同小区的状态、评估小区的性能,已成为运营商首要关注的问题[1]。通常,4G/LTE蜂窝小区网络性能可以用多个不同的特征来表征,数据挖掘分析技术为蜂窝小区大型数据集的监控和获取提供了可能。其中,聚类作为一种处理大型数据集的常用方法,被广泛应用在工业、农业、经济等领域[2],相关研究也不断被提出。Barthel提出利用自动图像分类和基于SOM模型的半自动图像语义生成来改进图像检索[3]。Schreck等人提出了一种基于SOM的二维属性值抽象空间的轨迹数据可视化聚类分析方法[4],基于SOM通过选择两个相关的特征(即上行噪声和帧错误率)来寻找相似的行为单元,从而使移动运营商的优化任务更具成本效益。Savazzi等人提出了一种基于聚类算法的下行空间滤波新方法[5],用于UMTS-FDD蜂窝网络,使用kmeans算法,尽管成功地对用户进行了分组,但聚类偏差较大,简单网络场景计算时间超过1小时。由于该法仅使用k-means方法,在聚类处理前必须确定聚类数k,当k值不足时,便不能用于分类数据[6-8]。当输入数据来自未知的概率分布时,很难为k选择一个合适的值。
基于上述背景,本研究尝试使用SOM算法来分析LTE无线接入网的性能,并根据无线接入网中的参数将不同的LTE小区划分为不同的簇,以此来区分流量较大和流量较小的小区,以助于网络优化人员更好地进行网络频谱资源优化、改善用户体验。
2 聚类原理及流程
聚类是根据数据之间的相似度将数据分成相应的类,以此用来查看数据中类似的模式,是一个将物理或抽象对象的集合分成由类似的对象组成的多个类的过程。好的聚类方法可以产生高质量的聚类结果,所形成的簇也具有高的内部相异性。然而,对于未标记数据,聚类存在一定的难度。目前,没有特定标准的方法来判定未标记聚类的好坏;对于大量未标记数据需要人为干预才能完成适当的聚类。
SOM(Self Organizing Maps,自组织映射)是人工智能神经网络中的一种无监督学习神经网络模型,一般用于将高维输入数据表示在低维空间中,通常是将数据投影到二维神经元网格中。
自组织映射不同于其他人工神经网络之处在于,其采用竞争学习而不是错误校正学习,且使用邻域函数来保持输入空间的拓扑属性。模型可以分为输入层和竞争层两部分,如图1所示。输入层的输入神经元数量由输入网络中输入数据特征的数量决定。

图1 SOM网络拓扑结构
基于此模型,本研究将输入数据设置为不同的特征,并将这些特征作为训练数据集;同时选取整个小区的7种特征。
对于输入数据,将其设置为一个n维向量,可表示为X=[x1,x2,...,xn]T。进而可将输入向量设置为一个7×62的矩阵,表示含有62个单元格的静态数据和7个特征数据。
竞争层是由神经元按一定方式排列的二维节点矩阵,它主要用于聚类和高维降维可视化。SOM模型的竞争层为二维网格,网格大小设为p个节点,记为Y=[y1,y2,...,yn]T。通常,神经元选取越多,模拟的性能就越好,但对于很多神经元来说典型的选择方案可通过来计算。其中s为竞争层的神经元数量,N为输入样本,即LTE小区的特征。输入层的每个节点与第j个竞争层神经元之间的连接记录则为Wj=[wj1,xj2,...,xjn]T,其中j=1,2,…,p。
训练过程最终要在竞争层输出。在这一输出层中,赢得竞争的神经元将设置为1,其余节点没有输出将被设置为0。竞争的原则是:权向量神经元wq当中,距离最接近当前输入X的即为竞争的获胜者。可以记为:

SOM训练算法在执行之初,先给竞争层中每个神经元的每个权值向量wi赋一个初值,然后对模型进行反复的训练。在每个训练步骤中,从输入数据集中随机选择一个样本向量Xi。通过计算原型神经元与Xi之间的距离,得到最优匹配单元,即最接近Xi的权向量,匹配单元根据欧氏距离计算,公式如下:
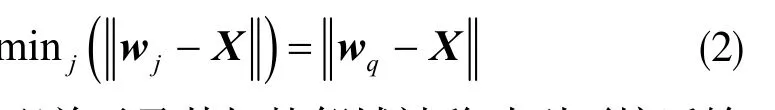
最优匹配单元及其拓扑邻域被移动到更接近输入向量的位置。此时神经元原型向量更新规则为:
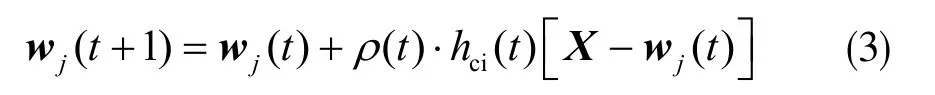
其中,t是时间;ρ(t)是学习速率,范围为0~1;hci(t)是邻域神经元,通常是一个高斯函数。
设t=t+1,重复公式(2)和(3)的运算,直到网络收敛为止。
基于上述流程,即可应用SOM算法来训练、分析移动通信RAN数据。
首先要经过多次路测分析得到一系列数据,计算其平均值。在仅考虑下行情况的前提下,选取:平均信道质量指标、数据流量、下行平均吞吐量、下行最大吞吐量、PRB(物理资源块)使用量、各小区内部eNB延迟和RRC丢包率共七种典型特征,用作聚类单元的输入特征向量。
按照分析目标考虑,关注重点在于SOM训练的数据,故此在MATLAB工具箱中建立一个包含16个map神经元的自组织映射,并利用特征数据矩阵进行训练;将待检测的竞争神经元的输出位置与输入特征数据的输出位置做比较,输出位置越相似,其特征越相似;至此,只需计算出基于这两种输出位置的欧氏距离,距离较近的将被划分为同一簇。
3 验证与分析
对于SOM训练,与每个神经元相关的权值向量会运动而成为一组输入向量中心。拓扑中相邻的神经元在输入空间中也会相互靠近,因此可在网络拓扑的二维中实现高维输入空间的可视化。MATLAB仿真结果如图2所示。
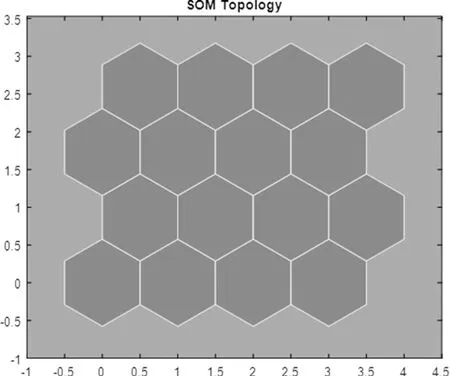
图2 SOM拓扑仿真图
图中每个六边形代表一个神经元,网格是4×4的,因此有16个神经元。每个输入向量有7个特征,所以输入空间是7维的。权重向量(聚类中心)属于这个空间。
对SOM领域权值距离的仿真结果如图3所示。图中,正六边形代表神经元,相邻神经元之间以直线连接。存在连线的区域以不同颜色标识神经元之间的距离。较深颜色代表较大距离,较浅颜色代表较小距离。从中心区域到左上区域有一段暗色线段。SOM网络将输入数据聚为两个不同的组。
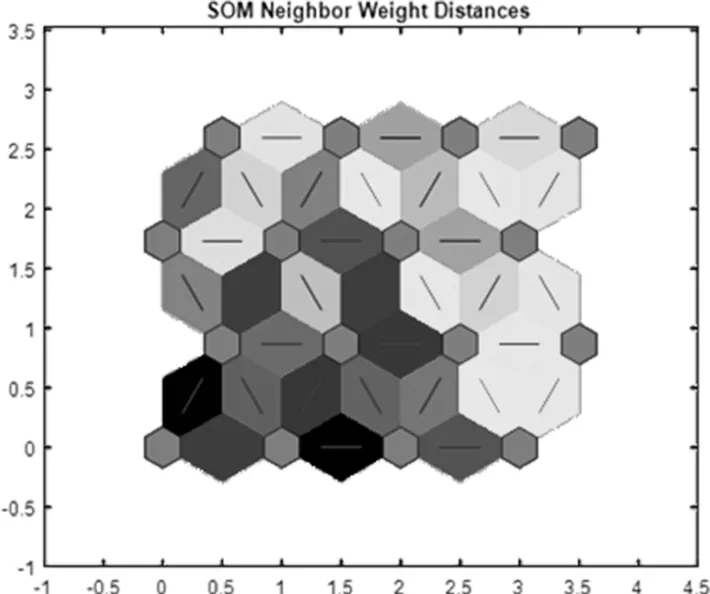
图3 SOM领域权值距离仿真
为了将输入向量划分为不同的簇,使用SOM权值平面来可视化SOM拓扑结构,仿真结果如图4所示。图中显示了输入向量的每个元素的权重平面,它们是连接每个输入到每个神经元的权重的可视化,颜色越深代表权重越大。如果两个输入的连接模式非常相似,即可认为输入是高度相关的。在本例中,输入2与5,输入3与4,输入6与7,都有非常相似的连接,它们之间有很高的相关性。以输入2和5为例,两者分别用来表示下行链路的数据流量和物理资源块使用量。在这两张图中,颜色的变化极为相似,都是从左下角到右上角颜色变暗,即是说左下角的PRB使用率和数据流量都低于右上方的区域。同样情况也适用于输入3(下行链路的平均吞吐量)和输入4(下行链路的最大吞吐量)。
对于输入6(内部eNB延迟)和输入7(RRC丢包率),性能几乎相反,即随着下行链路中PRB使用率和数据流量的增加,RRC丢包率和eNB延迟会降低,表明这四个特征具有很高的相关性。
剩下的输入1(信道质量指标)颜色变化不规则,表明其性能与其他六个权重输入皆不相关。
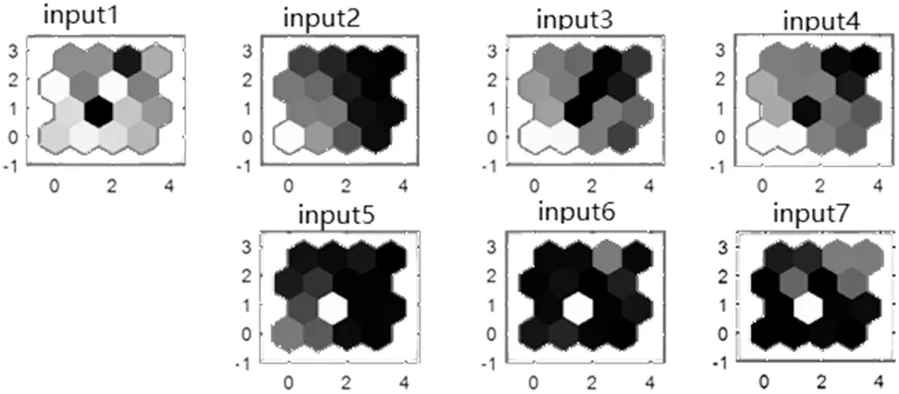
图4 不同特征的权重图
图5显示了神经元在拓扑中的位置,并表示了与每个神经元相关的训练数据的数量。
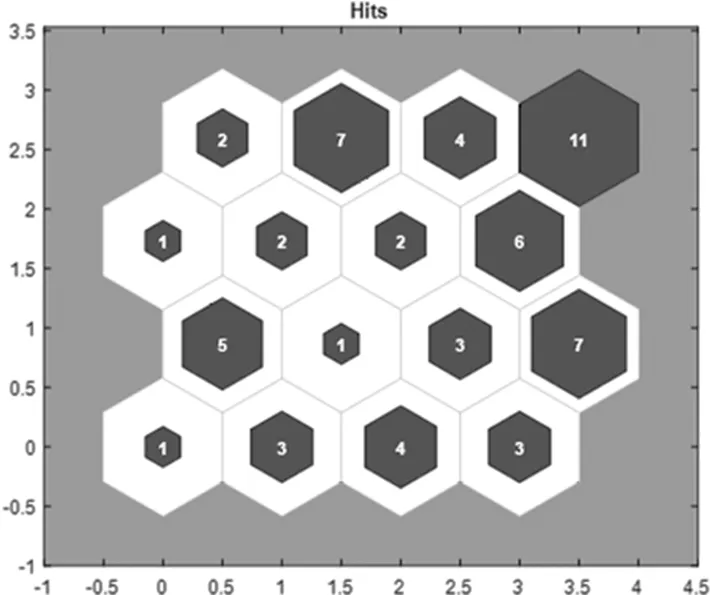
图5 测试数据在SOM拓扑上的分布
分析一个时间序列数据,与单个数据点不同,需要计算给定数据序列在每个数据簇中出现的频率或“命中”数量。一段时间内包含这些比例或“点击率”的矢量称为点击率直方图,描述一段时间内小区行为的特征,随后用于将小区聚类为行为类似的组。
与任何神经元相关的最大命中数是11。因此,该集群中有11个输入向量。另外可发现,“命中”在拓扑中的分布与图5中权重的分布相似。例如,命中11次的神经元(又称小区)具有数据量大、同时使用PRB的特点,并且它们的掉话率很低。相邻的神经元(即欧氏距离更近)也有类似的表现,例如命中4和6的神经元。与之相反的是左下角命中1的神经元,其均值和最大吞吐量较低;此外,与命中11次的神经元相比,它的掉话率更高。
通过上述实验表明利用SOM模型可以有效预测区分小区类型,帮助移动运营商节约成本,实现频谱资源的优化配置。
4 结束语
本研究应对的是LTE网络中不断增长的终端接入和高基站密度的挑战,利用大数据分析刻画了网络性能和终端体验。所建立的SOM神经网络模型成功地对LTE小区进行了聚类。实验证明了SOM用于小区聚类并发现相似行为小区的可能性,将有助于移动运营商节省更多的运营成本。在网络优化中使用大数据分析和挖掘,意味着可以通过一种高度可伸缩的方法来进行网络性能调优。利用大数据确定感兴趣的区域,对网络运营而言也具有极高的商业和实用价值。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
自然杂志(2021年6期)2021-12-23 08:24:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
现代装饰(2018年5期)2018-05-26 09:09:01
电子测试(2017年15期)2017-12-18 07:19:27
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
智能系统学报(2015年4期)2015-12-27 09:38:39
新高考·高二数学(2015年11期)2015-12-23 18:17:44
电源技术(2015年5期)2015-08-22 11:18:38
弹箭与制导学报(2015年1期)2015-03-11 15:32:06
