
基于改进XGBoost模型的信用风险评估研究
2022-09-02 10:53:02金库莹
微处理机 2022年4期
金库莹,郭 莹
(沈阳工业大学信息科学与工程学院,沈阳 110870)
1 引言
根据中国银行业监督管理委员会数据统计,2021年中国商业银行的不良贷款率为1.73%,精准识别良好用户与违约用户、评估银行用户的信用风险成为亟待解决的问题。信用风险评估是典型的二分类问题,目前已有很多分类算法应用到对银行用户的信用评估中,如逻辑回归[1]、朴素贝叶斯[2]、决策树[3]、随机森林[4]、XGBoost[5]等,但通常局限于将模型算法直接套用于对用户的信用风险研究,忽视了在信用风险领域中类别不平衡问题对于模型的影响。为解决数据不平衡的影响,学者们提出了相关采样算法,如过采样算法SMOTE[6]、欠采样算法EasyEnsemble[7]等。本研究基于现有成果,采用SMOTE与TOMEK算法相结合的采样方式处理不平衡数据集,提出一种改进的ST-XGB算法,旨在提高银行用户风险评估中的泛化能力,以更好地解决现实中的贷款人信用评估问题。
2 改进的XGBoost集成算法
2.1 SMOTE+TOMEK采样算法
由于SMOTE算法采样过程中易出现样本重叠问题,同时也存在合成数据具有边缘性与质量差的劣势,在对数据进行分类时,对于边界的临界点容易产生误判;TOMEK欠采样法解决的正是数据边界模糊不清的问题。以SMOTE+TOMEK的方式处理不平衡数据的步骤为:先使用SMOTE过采样,扩大样本后再对处在边界模糊的点用TOMEK进行删除,最终得到一个边界线较为清晰的数据集,最初的不平衡数据经过采样后正负样本也达到了平衡。处理前后的效果对比如图1所示。
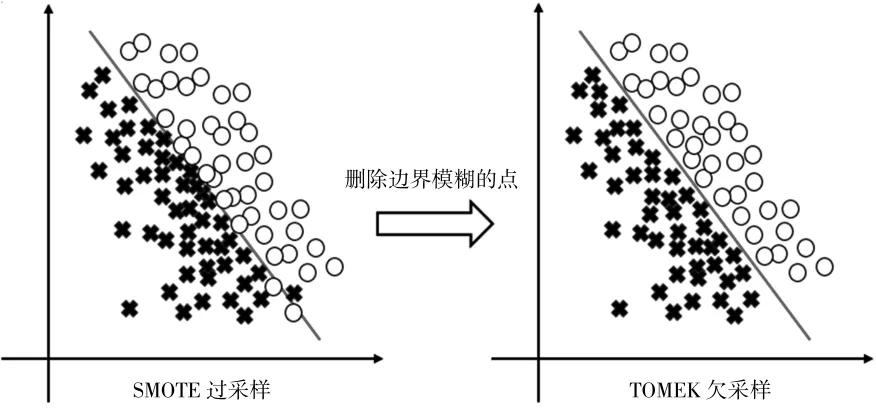
图1 SMOTE+TOMEK采样结果示意图
2.2 XGBoost集成算法
XGBoost模型是Boosting思想的另一种实现,其算法思想就是不断地添加新的树,每次添加的树本质是学习一个新函数,将上一棵树的损失函数梯度下降方向作为新函数优化目标,去拟合上一棵树预测的残差。
假定所使用的数据集为(xi,yi),其中xi∈Rm、yi∈Rm,即m维数据集;xi表示数据集中特征属性,yi表示样本数据的标签,则XGBoost的模型定义为:
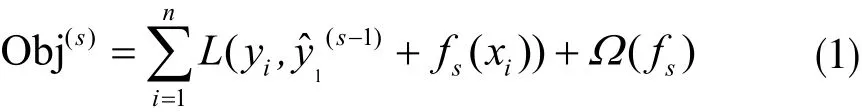
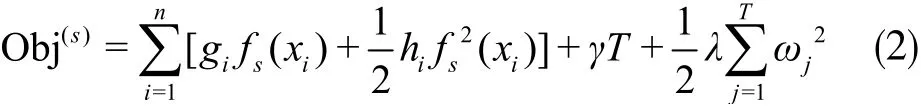
式中gi为损失函数的一阶梯度统计;hi为二阶梯度统计,ωj为叶子节点的权重。可以看出XGBoost的目标函数与传统梯度提升树的方法不同,XGBoost在一定程度上做了近似并通过一阶梯度统计和二阶梯度统计表示。
fs(xi)本质上是树模型,每个样本在每棵树中会落到对应的一个叶子节点,则式(2)可以改写成:
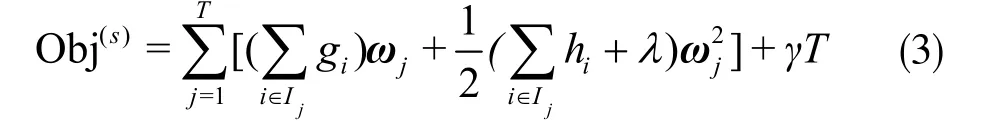
式中,Ij为叶子节点j的样本集,fs(xi)将样本划分到叶子节点,计算该叶子节点的权重ω,因此i∈Ij时,可以用ωj代替fs(xi)。Obj为目标函数,s为它进行迭代的轮数。
将式(3)看成以自变量ωj、因变量为Obj(s)的一元二次函数。根据最值公式,叶子节点j的最优权重ωj*为:
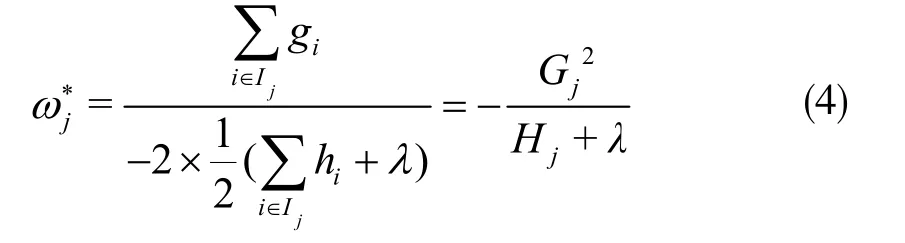
将式(4)代入式(2)中可以得出最优的目标函数值为:
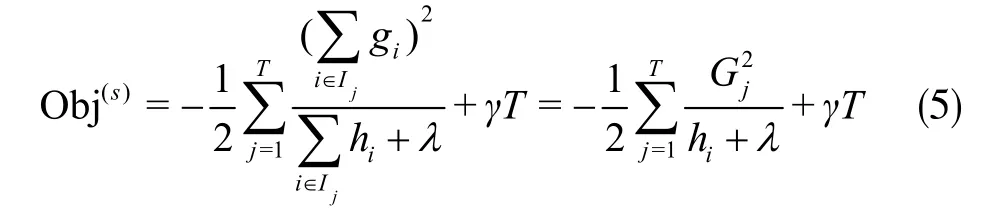
式(5)可以用作评分函数,分值越小表示该树模型性能越佳。在每次的迭代学习过程中,需对每棵树模型进行评分,并从中选出最佳,但候选树的数量是有限的。XGBoost采取贪心策略算法,从根节点开始计算目标函数值,如果节点分裂后的目标函数值相比于分裂前的目标函数值有所减少,则不进行分裂划分,之后将新生成后的预测函数加入模型中。
3 实验设计与数据处理
3.1 数据集
实验的任务是预测用户贷款是否存在潜在违约风险。选择信贷业务丰富的Lending Club数据集,采集的总数据量约为40万,良好用户与违约用户比例为4:1。实验选用的数据集包含27列变量信息,数值型变量13列,类别型特征14列,数值型变量中包括连续型变量11列,离散型变量2列。
3.2 数据预处理
数据处理包含缺失值处理、异常值处理、数据转换和数据不平衡处理。实验采用模型填充的方式处理数据中的缺失值,将数据中异常值删除,作为缺失值进行填充。对于类别型变量无法直接放入算法模型,根据类别型特征分类为有序型和无序型,其中无序型分为高维度与低维度两种。将有序型类别特征采用目标编码的方式进行处理;对于低维度无序型类别特征采用独热编码;高维度无序型类别特征采用频数编码。
3.3 特征工程
特征工程包括特征构造和特征筛选两部分。根据金融风控领域专家的知识构造可解释的银行信贷业务特征,以此增加模型的预测能力。在此基础上通过特征交叉和特征分箱的方式进一步衍生特征。通过特征构造衍生出的新特征不一定对模型的预测产生积极的影响,甚至会降低模型的泛化能力,因此实验采用IV值(Information Value)对数据的特征字段进行筛选。通过IV值计算评估每个指标的有效预测能力,筛选出IV值大于0.1的特征,共计25个。
4 实验与结论
从AUC分值、精准率和误判为违约用户三个方面对模型性能进行评价。采用传统的分类模型与改进的XGBoost模型进行实验对比分析,对比结果如表1所示。
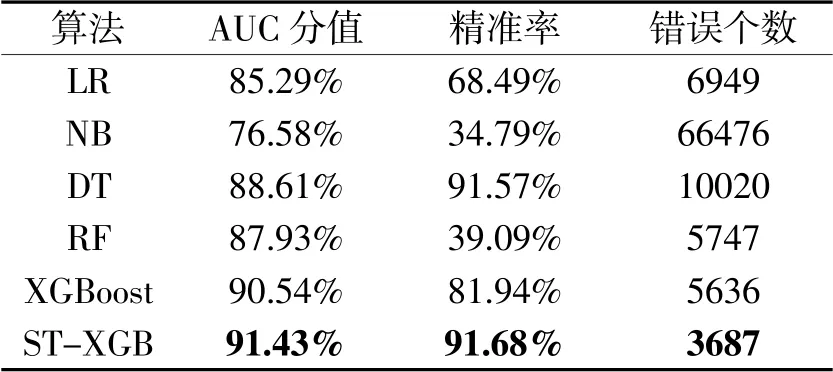
表1 模型性能对比
从表中可以看出,改进的XGBoost模型在AUC分数、精准率和判别错误个数三个方面均优于其它模型:AUC分值相比XGBoost模型提升了0.83%,精准率相比于决策树模型提升了0.11%,在判别错误个数方面相比于其它模型大幅度减少为3687个。
对于银行信贷部门来说,即使是提高1%的预测准确率,也可以极大地降低风险和损失[8]。在数据挖掘算法中,模型泛化能力的评判指标AUC分值若达到80%便证明了模型的预测能力。改进的STXGB模型的AUC分值达到了91.43%,模型的泛化能力较为理想,证明了改进算法的有效性。
5 结束语
针对银行信贷数据中用户类别不平衡的情况,通过SMOTE与TOMEK相结合的采样方式改进了XGBoost模型。ST-XGB模型有效地提高了对用户类别的识别精度,避免了不平衡数据对于判别结果过于乐观的弊端,为银行信贷业务人员的工作提供了更为有力的支持,更加避免了人工在办理业务时的主观性,对银行用户信用风险评估的进一步研究具有一定的意义。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
辽宁经济(2017年6期)2017-07-12 09:27:35
数学学习与研究(2017年3期)2017-03-09 18:12:42
当代经济(2016年26期)2016-06-15 20:27:18
中国老区建设(2016年1期)2016-02-28 09:32:00
新校长(2016年8期)2016-01-10 06:43:59
新疆财经大学学报(2015年3期)2015-12-10 03:49:13
特区实践与理论(2014年5期)2014-07-24 14:02:08
商事法论集(2014年1期)2014-06-27 01:20:42
