
基于ETL 及XML 技术的分布式数据库多层数据同步机制研究
2022-09-02 06:24刘雅莉
电子设计工程 2022年16期
刘雅莉
(商洛学院 经济管理学院,陕西商洛 726000)
随着网络技术的发展,各行各业对信息管理的需求日趋复杂,信息系统的性能、数据的安全性、数据的复用率成为系统使用者关注的问题。分布式数据库作为逻辑上的统一整体,满足信息既独立、又协同的处理需求,在不同节点数据库之间的数据传输、不同数据源异构数据的信息共享方面表现优异,而分布式数据库的同步机制直接影响系统性能,是系统开发过程中必须解决的问题,因此,建立一套性能优异的数据同步机制既能节省信息化系统建设成本,又能发挥出数据的最大价值。
1 现有同步机制分析
1.1 分布式数据库简介
分布式数据库通常由一组数据构成,数据分布于多个服务器,每个服务器均可执行局部应用,也可以利用部署的分布式集群网络实现全局应用。从逻辑表面看,数据比较分散,但实际上是一个整体。分布式数据库具有数据独立、站点自治、分布透明、冗余透明、系统分层、并行处理等特性,为多层级结构模式,在诸多领域的应用中有优异表现。
1.2 主流机制对比分析
目前,主流数据同步机制主要包括数据库复制技术、ETL 机制、SQLServer、Sybase 等。数据库复制技术利用自身同步机制进行定期巡检,发现不一致则进行复制并发送给其他站,融合能力较高且利于节点就近获取数据。ETL 机制可实现异构数据的采集、清洗、转换以及数据加载。SQLServer 和Sybase 都基于“Publisher-Subscriber”模式,区别在于SQLServer 主要支持快照、事务以及合并复制。Sybase 主要支持分布式主段、主复制等模式[1-2]。
1.3 同步机制设计目标
文件传输模式的数据同步由于固定间隔传输导致实时性欠佳,而数据库内嵌的复制同步机制如果频繁更新,则无法确保网络稳定性且存在数据一致性缺陷,因此多层分布式数据库同步机制的设计目标首先要保证数据准确,其次要保证同步效率。综合比较之下,该研究选择了触发器以及XML 技术,采用触发器技术记录数据库表更新情况并写入中间表;基于XML 弥补了触发器单表绑定的缺陷,实现了多表数据读取。
2 基于ETL的增量抽取机制
2.1 ETL技术简介
ETL(Extraction Transformation Loading)技术包括数据的抽取、转换、清洗以及装载。数据处理不是直接单一的存储和查询过程,而是多个ETL 过程。
1)数据抽取:主要是确定哪些数据与后续执行决策有关,收集这部分数据的字段信息,确定抽取间隔、传送格式,并传送到目标服务器。
2)数据转换:主要是将多源数据进行格式化,确保数据的一致性,便于应用系统进行操作。具体包括两个方面:一方面是将操作型数据转换为查询分析型数据,另一方面是在导入之前统一数据标识。
3)数据清洗:无效数据会影响后续的分析效果,因此需要校验源数据质量,针对容易出现的数据丢失、出错、冗余以及不一致的情况进行补充、修正或剔除,数据清洗过程也是数据的标准化过程,是提高源数据质量的有效方式。
4)数据装载:主要是将数据载入到目标数据库,包括全部装载、更新、刷新等几种方式。全部装载是对整个数据库进行装载,更新是对有变化的数据进行记录,刷新是在指定周期进行重新装载。
2.2 性能影响因子
网络中所有机器全部完成一次上传与下载所需时长是分布式数据库数据同步性能关键的判断标准。设网络内计算机记为S1,S2,S3,…,Sn,两台机器间传输带宽记为Wij,单位时间内同步数据量作为同步效率记为Kij,则两台计算机实现一次数据同步所需时间为tij=。通过带宽矩阵和效率矩阵获取所需的时间矩阵,得出耗时最长为tmax=max(t12,t13,t14…,t1m,t21,t22,…,t2m,…,tn1,tn2,…,tnm)。若各条带宽均相同记作,其中,B为总带宽,n为计算机总数,n(n-1)/2 为连接总数。那么可以得出t==Kijn(n-1)/2B。若计算机数量固定,同步效率低于带宽,则时间与效率、数量函数成正比,同时与Kij、B有关;同步效率高于带宽可能导致数据拥堵,从而导致同步效率下降。因此,影响分布式数据库数据同步性能的影响因子包括:同步效率Kij、计算机总数n、网络总带宽B[3-4]。
2.3 数据导入过程
海量数据时代涉及大量事务的分析与处理,机器自动化抽取、加载数据势在必行,相对于传统数据库,数据仓库更适用于对大量事务的分析与处理,因此,采用数据仓库中的ETL 工具来实现数据导入,为避免全量加载而影响性能,只需抽取增量更新数据。根据操作类型、是否更新等进行数据分类,然后将有记录时间的数据实行增量导入,没有记录时间的转为分析数据库日志。数据导入流程如图1 所示。
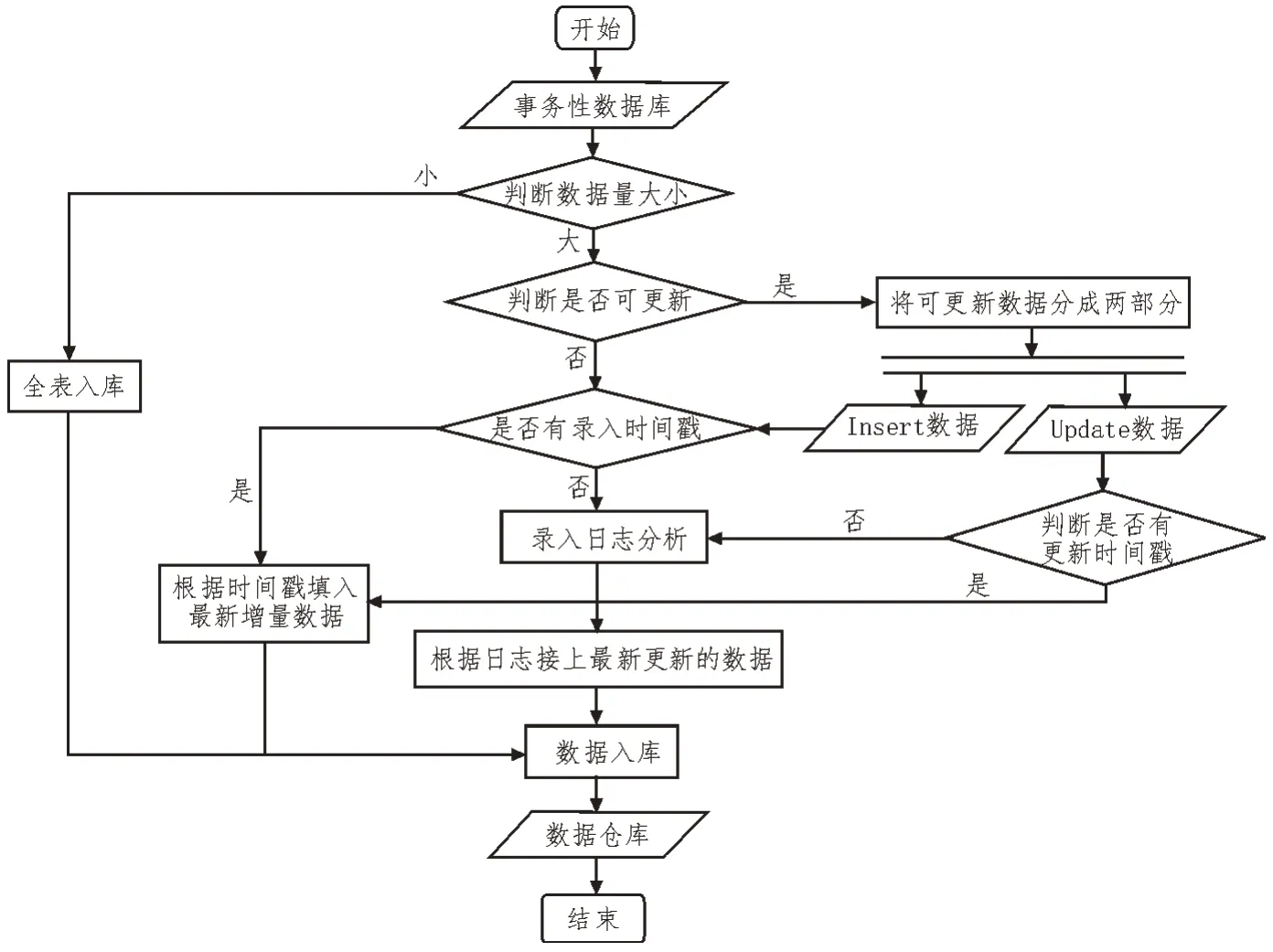
图1 数据导入流程
2.4 增量数据提取
在使用ETL 工具时,关键是如何判断数据的变化,文中采用触发器和时间戳相结合的方式,在待维护的数据表上建立插入、修改、删除三类触发器,当源表数据发生更新时,对应的触发器将数据写入维护表,并增加时间戳及标记操作类型[5-6]。触发器实现代码如下:

2.5 断点续传
对于由断电或其他网络因素导致传输中断的情况,恢复后从中断位置继续传输即可。在断点续传的过程中,主要包括请求、回复两个动作,在请求消息包中设置Range 关键字,记录开始传输的位置,实现代码如下:


回复消息的数据采用如下格式:

3 基于XML的异构数据同步实现
3.1 XML技术简介
XML(Extensible Markup Language)是一种可扩展的标记语言,利用自我定义的方式对存储的数据进行描述,描述信息不但包括各类数据内容,还包括数据相互间的关联关系。XML 技术具有可扩展性、结构性以及平台独立性,可以描述各种结构化以及非结构化的数据,可以有效解决两个系统之间、不同应用之间、不同数据源之间的数据同步问题。XML可以将多个程序的数据写入同一个XML 文件并进行传输,接收文件的服务器通过解析XML 文件获取信息,进而实现本地的编辑操作。鉴于XML 的优良特性,应用在数据同步机制中,不仅满足了转换需要,而且可以起到简化异构数据的效果,降低了同步模型的复杂程度。
3.2 异构数据同步模型
分布式数据库的数据同步过程包括采集、转换、传输以及导入四个阶段,利用数据仓库提取增量数据并存入缓存区;利用ETL 实现数据流转,增强数据一致性;经过XML 转换后传至其他节点,接收后进行反向转换,增强数据的规范性[7-8]。根据总体工作机制,构建异构数据同步模型如图2 所示。应用系统之间共享数据可通过不同服务器间接口,按照协议格式进行封装,通过XML 文档格式进行数据的加密、解密以及数据传输,利用转换模块实现XML 文档与数据库的正反映射,不同中心之间利用同步模块进行上传与下载,实现数据共享。

图2 异构数据同步模型
3.3 XML文档映射算法
XML文档包括包含描述信息的Schema文档以及包含表结构及关联关系的映射文档。首先,将关系模式映射为文档,确认全局变量。其次,在XML 中利用数据库名构建根元素,利用表名构建表元素。最后,建立类型与表字段结构一一对应。其中xs:schema包括标识、命名等信息,xs:element 代表数据库表字段,xs:sequece 代表顺序,xs:unique 代表是否唯一,xs:keyref 代表约束,PrimaryKet 代表元素主键[9-10]。
3.4 正向转换
XML 文档向数据库表正向转换:首先,校验文档格式是否符合标准。其次,利用读取函数生成创建语句。再次,从文档中读取相关属性和约束,生成insert、update 或delete 语句。最后,在数据库中执行语句并返回结果[11-12]。具体转换流程如图3 所示。
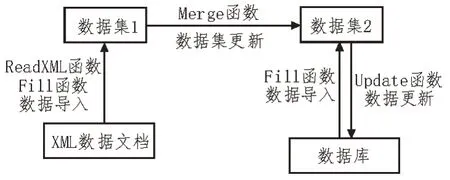
图3 正向转换流程
3.5 反向转换
从数据库到XML 文档的反向转换只针对有效数据,将数据库中提取出来的数据写入文档,转换流程如图4 所示。利用GerFileName 函数获取文件名,打开文件后,根据XML 文档映射算法写入Schema 格式的信息内容,然后完成转换[13-14]。
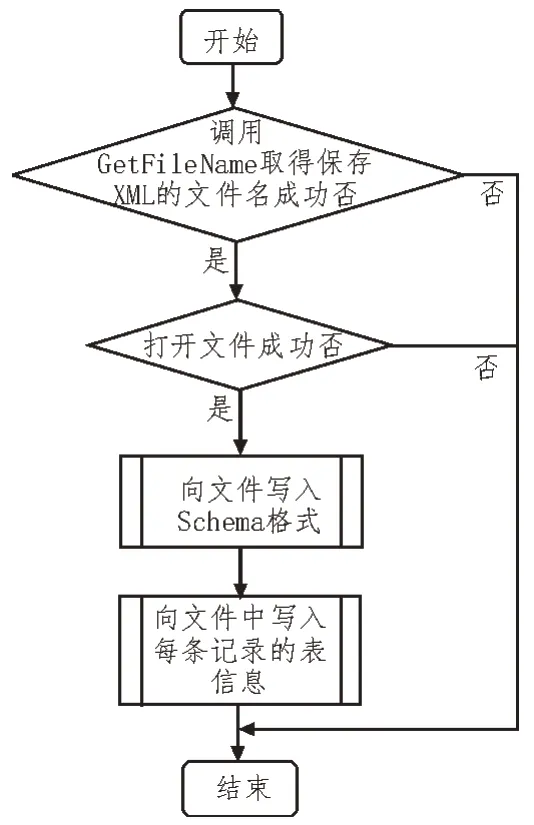
图4 反向转换流程
4 同步效果实证分析
为了验证所设计的数据同步机制的实际应用效果,获取国内某市医院数据库作为实验数据,在Matlab 上搭建实验平台,创建同步信息表sync_test,包含30 个字段,记录数据同步时间及数据完整性,结果如表1 所示。

表1 同步机制实证效果
随着数据量级的增长,同步模型时延始终控制在5 μs 以内且无数据丢失,同步效果较好且性能优异[15-16]。
5 结束语
为了实现分布式数据库多层数据同步,利用触发器、时间戳相结合的方法增量抽取待同步数据,经过实证分析,基于XML 构建的同步模型时延较小、性能良好。但同步机制尚未实现完全自动化,所采用的技术相对比较单一,在数据库访问效率方面的研究还有待提升。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
客联(2022年3期)2022-05-31
小学教学研究(2022年5期)2022-04-28
中国新闻周刊(2021年26期)2021-07-27
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
电脑知识与技术(2018年22期)2018-11-26
电脑爱好者(2017年7期)2017-05-06
科技传播(2012年12期)2012-07-05
