
大数据背景下基于GA-BP 神经网络算法的快递延迟分析
2022-09-02 06:24叶斌刘杰平徐金亚
电子设计工程 2022年16期
叶斌,刘杰平,徐金亚
(成都东软学院,四川成都 611844)
在第四十七次《中国互联网络发展状况统计报告》中显示,中国的网购用户已接近八亿,并且中国已连续多年成为全球最大的网上零售消费国。而网购过程中快递延迟等问题也越来越突出[1]。
根据王连震等在“大学校园快递服务满意度结构方程模型”论文中的调查分析,在网络购物中,快递的可靠性即在论文中所研究的快递能否及时到达的问题,是客户非常关注的问题,其会对用户的满意度造成很大的影响[2-3]。甚至因为快递延迟而给商家差评的占比达六成以上,充分说明无论是商家、快递公司或客户,对快递延迟都是非常关注的。
在现代快递企业中,对货物的运输时间控制会直接影响到客户关系的管理、供应链的管理和运输决策。如果能提前实现对货运时间的把握,并引用预警机制,对解决当前物流行业中的客户纠纷、建立企业的良好信誉以及调整运输策略有着重大意义[4]。基于此,该文将借助较为成熟的神经网络,对快递延迟原因进行探究,实现对延迟时间的预测。
1 总体构架设计
传统的原因分析一般是根据以往的成功经验,对企业中现有的原始资料加以分析,但当企业面临一个多变的市场,或者面临着众多的目标顾客时,就常常变得力不从心,而智能预警也无法起到其应有的效果。究其根本原因,就是企业无法高效地收集足够的数据,也无法全面地剖析整个物流活动中所涉及的所有原因。而在当今信息量日益扩大的信息时代,获取数据、整合数据、解析数据的复杂过程是传统的信息处理技术手段所无法实现的。而大数据分析等信息技术的诞生,给真正实用的物流智能预警系统发展带来了契机。其基本模型如图1所示。

图1 基于大数据快递延迟预测模型
模型主要包括了数据收集、数据储存、大数据运算、数据分析应用四大阶段[5]。在数据收集阶段,主要利用交通、气象等公共服务的网络平台,通过使用爬虫等手段就能有效收集关键数据,并利用数据收集接口完成数据收集[6];数据源包括亚马逊的ETL Manager 及Redshift 数据仓库、阿里天池系统以及彩云科技天气数据API。
在数据保存阶段,把数据分成了结构化和非结构化数据,使用了不同数据的存储技术,并分别存放在SQL、Hadoop 服务器中;在数据计算阶段,通过实时的数据计算汇总,并进行标准化处理,为下一步数据应用做准备;最后,在数据应用阶段,主要将标准化的数据连接到已训练好的神经网络模型中进行计算,并输出直观的结果,实现快递延迟预测。
2 预测模型指标准化处理
2.1 预测模型指标体系建立与量化
经过问卷分析与网络调查,结合随机森林的分类算法[7],对指标进行分析,实现特征的优化与量化。分析样本中影响延时的原因,相对集中的因素主要有运输距离、沿途主要天气、客户要求送达的时间、所到达地区。这些因素较广地覆盖了以上分析的7 大因素;同时,减小了分析指标,运算量相对较小,更有利于模型的应用。最后选取的指标体系如表1所示。
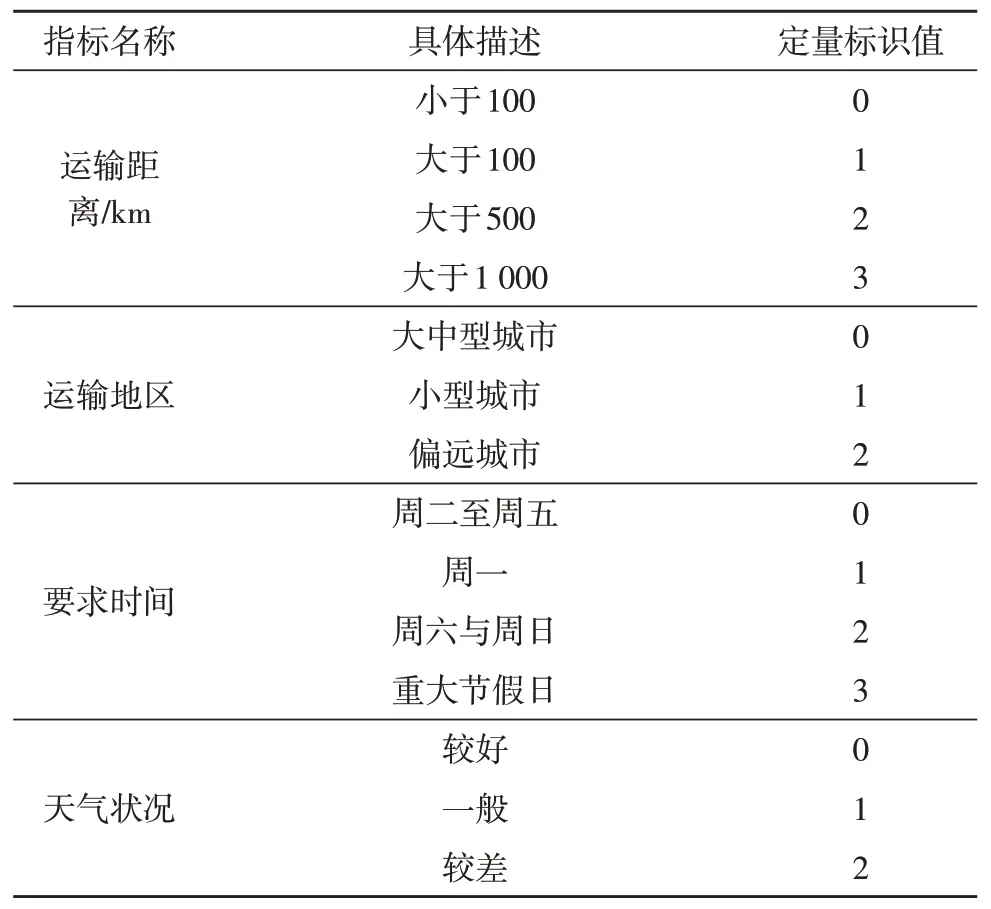
表1 优化后的分析指标描述与量化
在表1 中,运输距离方面,小于100 km,一般为市内运输;大于100 km 且小于500 km,主要表示跨市运输;大于500 km 且小于1 000 km,主要表示跨省运输;大于1 000 km,则为超远距离运输。要求时间指标中,时间为周二至周五,且无重大节假日,一般此时段为正常货运时间;周一有一定特殊性,一般为货运较为集中的时间;周六与周日,由于客户外出,或休假造成延时的可能性较大;重大节假日中,由于客户外出,或休假造成延时的可能性较大;天气状况指标中,分为较好,即温度适中,天气晴朗或多云等正常状况;一般,即小雨或小雾,中低温或中高温天气等稍差天气;较差,即为偶遇大雨、大雾、大风雪,雷电等恶劣天气。每一种定量值代表这个分析所对应的一种状态,虽然定量值有相同的,但代表的是神经网络的不同输入层的值,因而相互不受影响。
2.2 预测模型数据标准化处理
在BP 神经网络的延时预测模型接口中,输入层的四个信号输入指标在开始训练前就应该经过归一化处理过程,使之在[0,1]之间。其预期输出数值即是实际延迟值,作为测量误差的关键数据,来自于样本所对应的实际延迟时间,并同样对延迟的时间进行了归一化处理。处理的方法为将预定到达时间除以实到达时间,得到的值是一个小于1 的小数,所得的值越大则表示延迟率小,反之,则表示延迟时间越长。同时,也满足了归一化的要求。用T表示实际运输时间,用H表示预期运输时间,则其延迟率F的计算公式为:

在对样本处理时,对一些不符合要求的样本进行了剔除。例如,在现实生活中,实际到达时间有时会比预定时间短,这时不存在延迟的情况,在样本选择时将这部分进行了剔除。
3 预测模型的算法设计
为更准确地实现预测,并达到对预测模型的最优化,文中应用遗传算法(Genetic Algorithms)对BP 神经网络进行了优化设计。其基本流程如图2 所示。
在图2 中,左边部分自上而下的流程主要是遗传算法优化过程,右边部分自下而上的过程主要为BP 神经网络的执行过程。在遗传算法设计优化流程中,其技术重点包括群体建立、对个体的适合度估计、选择性控制以及交叉与突变的控制,其主要过程或计算方法如下:

图2 基于GA-BP的神经网络计算流程图
1)群体的初始化流程
将所有个体编号为一组实数,使所有的个体都形成了一条实数串,由以下四个部分构成:输入层、隐蔽层相互之间的链接系统数、隐蔽层的阈值函数、隐蔽层和输入输出层相互链接系数值,输入输出层阈值函数。个体已经具备了神经网络系统所有的权值与阈值,能够形成一种由整体结构、权值以及阈值组成的神经网络系统[8]。
2)训练误差值计算
BP 神经网络系统训练误差值的估计十分关键,因为它直接决定着对个体适应性度分配的值,在测算神经网络系统的初始权重和阈值时,用训练数据训练BP 神经网络后再计算整个系统的输出,个体的适应性度分配值F的计算公式为[9]:

式中,k是系数,第i个节点的期望输出用yi表示,i个节点的实际输出用oi表示,n为输出层的数目。
3)选择操作
选择操作的方法很多,例如常见的锦标赛算法、轮盘赌算法等。该文选取的是轮盘赌算法,其主要基于适应度比例的选择方式,在计算过程中,个体i的选择概率值pi计算公式如下:

式中,个体i的适应度用fi表示,系数是k;种群r的个体数量用N表示,在个体选择之前,对适应度求倒数,以便使适应度的值更小。
4)交叉操作
关于对个体的编号问题,要获得最优个体,必须对个体采用实数编码,在交叉操作中,可以使用实数交叉法,第k个染色体ak和第一个染色体al在j位的计算方法如下:

式中,b是[0,1]之间的随机数。
5)变异操作
对第i个个体的第j个基因aij进行变异,其计算公式如下:

式中,amax表示基因aij的最大值;amin表示基因的最小值;f(g)作为一个随机数;g表示迭代次数;Gmax表示最大的进化次数;r为在[0,1]之间生成的随机数。
该文所使用的BP 神经网络计算是多层前馈神经网络,原因是它能够在非线性连续函数问题计算中,更有效地处理隐藏层的连接权值调节问题[10]。BP 神经网络模块的拓扑构造基本分为三级,分别是输入层、隐藏层、输出层。
根据上文的分析,作为输入层的指标为“运输距离”、“运输地区”、“要求时间”、“天气状况”四项,输入层设计如图3 所示。

图3 输入层设计
针对输入层的数据,其线性变换公式为:

其作用为计算出与下一层节点的连接参数及偏置值。
同时为了使隐层具备真实分类函数的能力,使用的激活函数Sigmoid 为:

网络中输出层系数的计算方法为:

隐藏层的权值系数计算方法为:
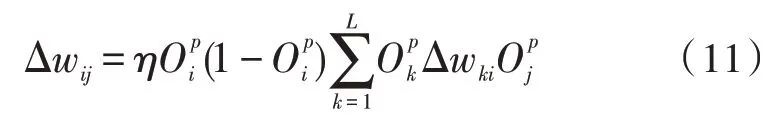
其中,最基础的机器学习原理就是运用梯度下降法则,运用反方向传播促进并持续调整网络系统的权重和阈值,使其进一步优化,同时使网络系统中的误差平方和最小化。
输出层的“延迟率”、隐藏层的数量和问题的求解对应输入输出的要求以及单元的数量,关系非常密切[10]。其经验计算公式为[11]:

式中,m和n分别代表输入数量和输出数量;L代表隐藏层的数量,在不同的网络设计中,可依据设定精度和收敛速度的不同进行调整[12]。
主要代码及算法步骤为:

4 算法结果对比分析
根据上文中经验公式(12),能计算出隐藏层的数量。通过计算,可以得出在不同隐层数时其实际训练步数和最大误差。当设计的学习精度为0.01时,分析隐藏层的数量,其计算结果如表3 所示。

表3 隐藏层数量对应误差、步数
通过结过分析可知,在隐层数为3 时,相对误差较小,且训练步数最小。
通过Matlab 的神经网络训练工具箱进行cart 决策回归训练,在文中充分考虑隐藏层数目后,后续重点考虑训练的精度及稳定性以及学习速率[14]。通过对比不同方法,该文采用能够进行自适应调整学习速率的梯度下降法[13],设定的学习速率是lr=0.06。
学习过程图如图4 所示。

图4 学习过程图
对程序结果进行归纳,部分数据训练结果如表4所示。
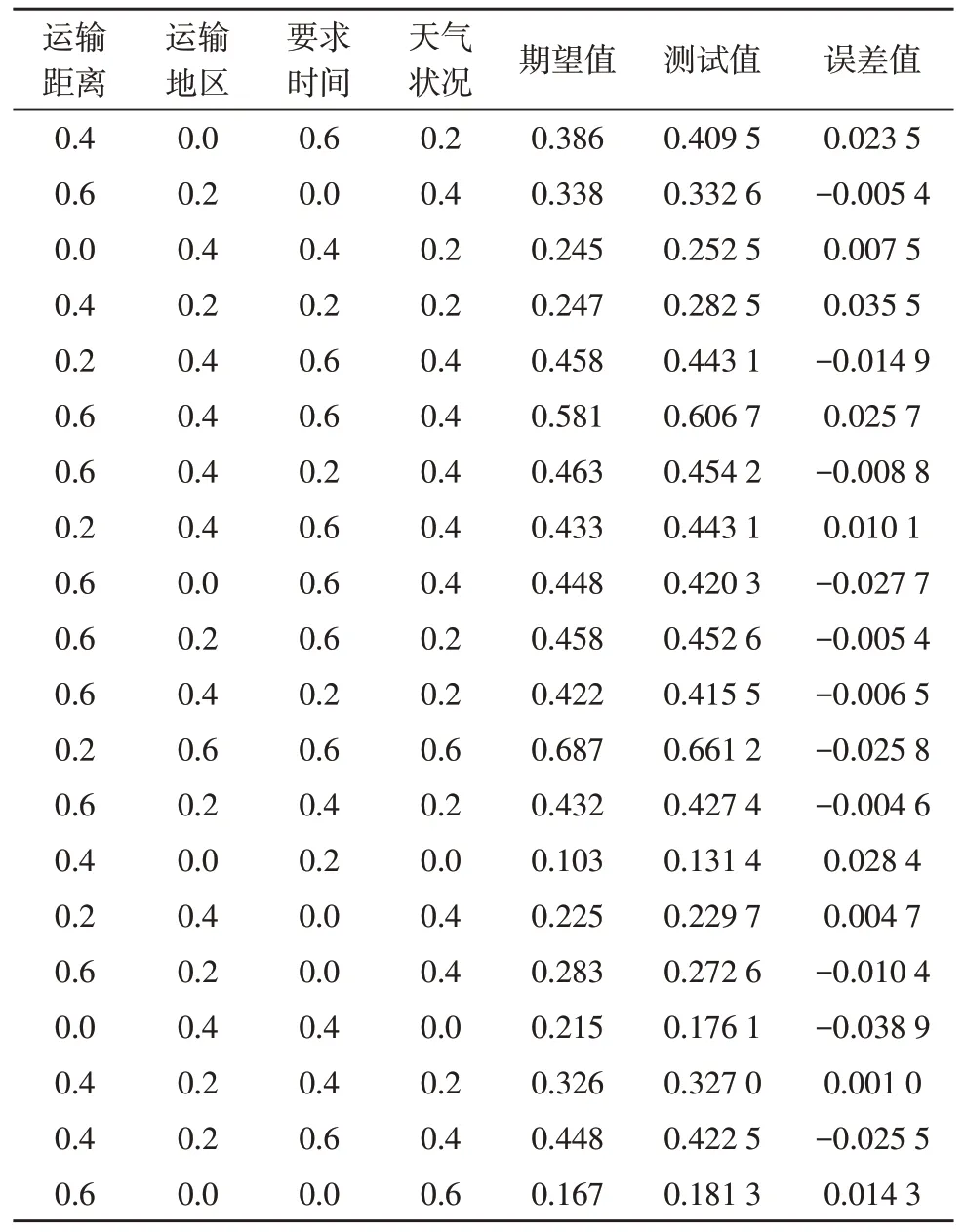
表4 部分样本训练结果
通这对测试样本的分析,当隐藏层神经元数目为3时,最大误差值是0.041 5,最小误差值是0.001 0,能够保持在0.11%~4.03%之间。从结果来看,该样本模型较好地满足了对快递延时的精度需求,充分表明该预测模型具备一定的可行性和有效性。
不同的算法模型可能会在不同行业,针对不同数据有不同的适应性,准确率不一定对所有行业或数据有效,为了验证该文算法对物流快递数据的适应性和预测的准确性,文中将BP 神经网络、基于GA的优化算法、支持向量机[15]及cart 决策回归树[16]四种方法的结果进行对比,平均准确率数据如表5 所示。
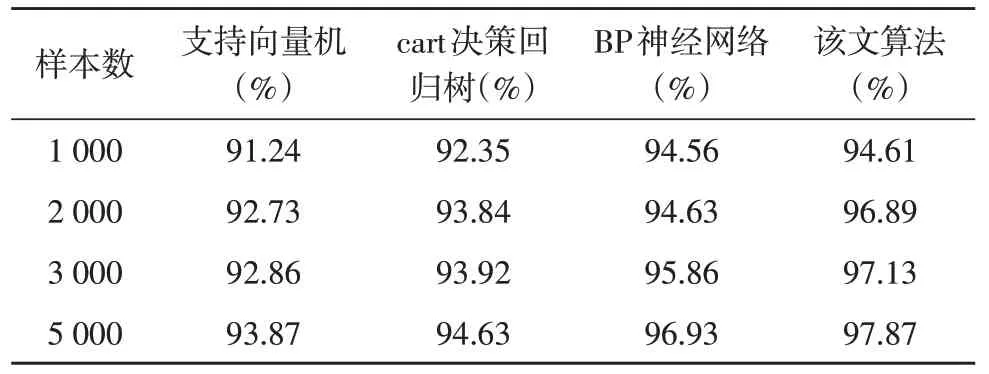
表5 不同算法预测准确率对比
通过表中的数据显示,在数据样本较少的情况下,各算法表现差别不大,当数据样本较多时,该文所采用的基于GA 的优化算法平均准确率较高。
5 结束语
通过训练结果和不同算法对比可以看出,该文所运用的GA 优化神经网络算法的预测模型能对货运延迟进行较为准确地预测。从而在实际应用中,在大数据环境下,可以在物流决策系统中引入预警机制,提前作出决策或是通知客户,使物流决策系统更完善,能有效地缓解由于延时而导致客户关系紧张等问题。
在大数据环境下,该模型也能作为电子商务系统的有力支持,使客户和商家以及物流公司对货物实现有效地监控。
猜你喜欢
现代电力(2022年2期)2022-05-23
电子制作(2019年19期)2019-11-23
劳动保护(2019年7期)2019-08-27
福建基础教育研究(2019年11期)2019-05-28
电子制作(2019年24期)2019-02-23
专用汽车(2016年4期)2016-03-01
专用汽车(2016年1期)2016-03-01
中学科技(2015年1期)2015-04-28
汽车维护与修理(2015年7期)2015-02-28
海军航空大学学报(2015年4期)2015-02-27
